让每一项优秀工作,都被更多人看见:点击进入投稿通道

-
论文标题:LK Losses: Direct Acceptance Rate Optimization for Speculative Decoding -
论文链接:https://arxiv.org/pdf/2602.23881
TL;DR
在投机采样(Speculative Decoding)中,草稿模型(Draft Model)的训练目标通常是最小化与目标模型(Target Model)之间的 KL 散度。然而,投机采样的核心加速指标是接受率(Acceptance Rate)。Nebius 团队发表的这篇论文 LK Losses: Direct Acceptance Rate Optimization for Speculative Decoding 指出,由于草稿模型容量有限,最小化 KL 散度并不等同于最大化接受率。
本文提出了一组新的损失函数——LK Losses,旨在直接优化接受率。通过梯度分析,作者揭示了 Total Variation (TV) 距离虽然理论上对应接受率,但存在梯度消失和优化困难的问题。LK Losses 通过两种变体(基于负对数接受率的损失和自适应混合损失)解决了这一问题。实验表明,在从 Llama-3.1-8B 到 DeepSeek-V3 (685B) 的多种模型和架构上,该方法均能带来显著的接受长度(Acceptance Length)提升。
1. 背景
1.1 投机采样的本质瓶颈
大语言模型(LLM)的推理过程受限于内存带宽而非计算能力。自回归生成的串行特性导致了内存访问的低效。投机采样通过“草稿-验证”(Draft-then-Verify)范式来解决这一问题:
-
草稿阶段:使用轻量级模型快速生成 个候选 token。 -
验证阶段:目标模型并行验证这些 token。
这一过程的加速比主要取决于接受率(Acceptance Rate, AR),即草稿 token 被目标模型接受的期望概率。
1.2 标准训练目标的错位
目前,训练草稿模型的主流方法(如 MEDUSA, EAGLE 等)通常采用知识蒸馏(Knowledge Distillation, KD),其损失函数为前向 KL 散度(Forward KL Divergence):
其中 是目标分布, 是草稿分布。
核心问题在于: KL 散度和接受率虽然在全局最优解()处是一致的,但在草稿模型容量受限(通常只有目标模型参数的 1-5%)的次优解处,两者的优化方向存在分歧。
-
KL 散度 (Forward KL) :具有“平均覆盖”(Mode-covering)特性,倾向于让 覆盖 的所有支撑集,以避免 而 时的无限惩罚。这会导致草稿模型在低概率尾部浪费概率质量。 -
接受率优化:实际上等价于最小化总变差距离(Total Variation, TV Distance)。TV 距离倾向于最大化两个分布的重叠面积,即使这意味着完全放弃某些低概率模式。
1.3 动机示例
论文通过一个高斯混合分布的拟合实验直观地展示了这种差异:
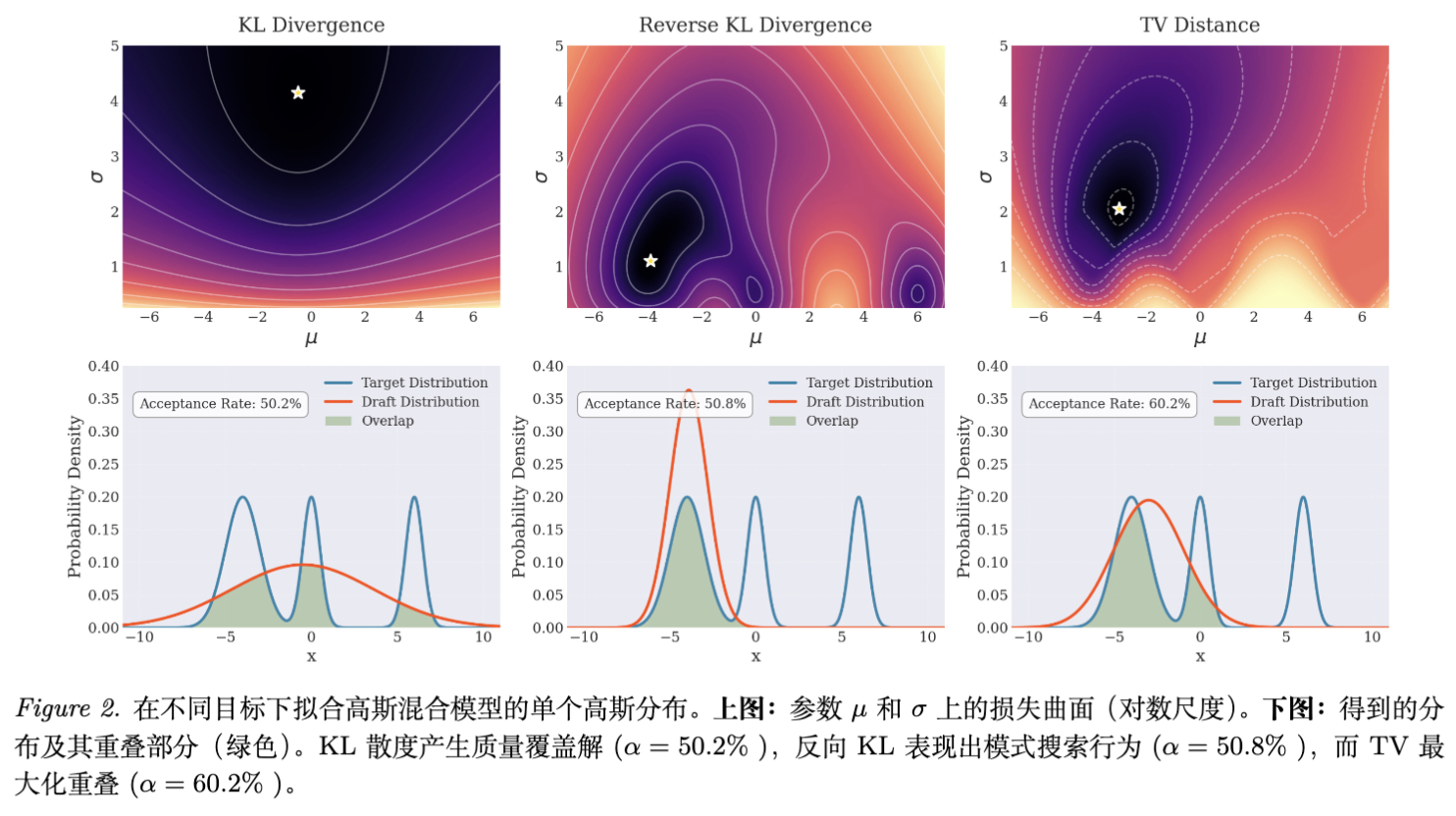
-
KL 散度:拟合出的分布试图覆盖两个峰,导致中间低概率区域被过度覆盖,实际重叠面积(接受率)仅为 50.2%。 -
TV 距离:拟合出的分布集中在主峰,放弃了次峰,从而获得了最大的重叠面积(接受率 60.2%)。
对于容量有限的草稿模型,直接优化接受率(即最小化 TV)显然比最小化 KL 更能提升推理速度。
2. 理论基础与梯度分析
为了理解为何之前的工作大多使用 KL 而非 TV,作者深入分析了两种损失函数的梯度特性。
2.1 符号定义
-
:目标模型输出的概率分布(固定)。 -
:草稿模型输出的概率分布,其中 为 logits。 -
:投机采样算法中的接受概率。 -
:期望接受率。
根据 Leviathan et al. (2023) 的推导,期望接受率与 TV 距离有如下关系:
其中 。
2.2 KL 散度的梯度
前向 KL 散度关于 logits 的梯度形式非常简洁(推导见附录 A.2):
-
物理意义:梯度直接正比于预测概率与目标概率的误差。 -
量级分析:在训练初期,假设 集中在 个 token 上,而 接近均匀分布(词表大小 )。此时 。这意味着即使在随机初始化阶段,KL 也能提供强有力的指导信号。
2.3 TV 距离的梯度与困境
TV 距离关于 logits 的梯度形式较为复杂(推导见附录 A.3):
其中 , 表示逐元素相乘。
-
物理意义:梯度方向仅取决于误差的符号,而与误差的大小无关。这在优化上是不利的,微小的误差和巨大的误差产生的梯度信号强度相同。 -
梯度消失问题:在训练初期( 均匀, 稀疏),由于 ,梯度范数 。对于现代 LLM,词表 通常很大(>100k),导致起始梯度极小,无法有效训练。 -
非光滑性:TV 的损失曲面在 处不可微,存在优化困难。
3. 方法论:LK Losses
为了结合 KL 良好的优化动力学特性和 TV 对接受率的直接对应性,作者提出了两种 LK (Loss-for-K) Losses。
3.1 : 负对数接受率损失 (Negative Log-Acceptance)
受最大似然估计(MLE)的启发,作者将接受率 视为边缘概率,提出最小化负对数接受率:
关键洞察:
对该损失求导(推导见附录 A.4),得到:
这个公式揭示了 的本质:它是带有自适应梯度缩放的 TV 优化。
-
当接受率 很低(如训练初期)时,系数 会放大梯度,正好抵消了 TV 梯度中 的缩放因子,解决了梯度消失问题。 -
当 时,梯度行为回归到标准的 TV 优化。
3.2 : 自适应混合损失 (Hybrid Objective)
另一种方法是显式地混合 KL 和 TV,并设计一个动态权衡策略。
自适应调度(Adaptive Schedule):
作者提出根据当前的接受率 动态调整 :
其中 表示停止梯度(stop-gradient)。
-
机制: -
初期 () :,损失函数主要由 KL 主导。利用 KL 平滑的梯度快速将草稿分布拉近目标分布。 -
后期 () : 衰减,TV 项权重增加。在分布大致对齐后,利用 TV 进行精细调整,直接最大化接受率。
-
-
解释:这类似于“信赖域”(Trust Region)方法。KL 项充当软约束,确保 不会偏离 太远,从而保证 TV 的梯度在有效范围内。
3.3 词表截断(Vocabulary Truncation)的处理
现代草稿模型(如 EAGLE-3, FR-Spec)为了提升速度,常采用截断词表,即只保留 top-k 高频 token,其余 token 的 logit 设为 (概率为 0)。
-
KL 的缺陷:如果目标模型 在截断区域有非零概率(即 且 ),KL 散度会趋向无穷大。现有方法通常需要修改目标分布 (重归一化),这引入了近似误差。 -
LK 的优势:接受率计算公式 天然处理截断。对于截断区域,。因此,LK Losses 可以直接针对原始目标分布 进行优化,无需任何修改。
4. 实验设置
论文进行了广泛的实验来验证 LK Losses 的有效性。
4.1 模型配置
实验涵盖了参数量跨越三个数量级的模型,包含稠密模型和 MoE 模型:
-
目标模型 (Target Models): -
Dense: Llama-3.1-8B-Instruct, Llama-3.3-70B-Instruct. -
MoE: gpt-oss-20b, gpt-oss-120b, Qwen3-235B-A22B-Instruct, DeepSeek-V3 (685B).
-
-
草稿架构 (Draft Architectures): -
EAGLE-3 (Transformer-based, state-of-the-art). -
MEDUSA (Multi-head MLP). -
MLP Speculator. -
DeepSeek-V3 MTP (Multi-Token Prediction head).
-
4.2 数据集与评估
-
训练数据:Infinity-Instruct-0625 中的 660K prompt,由各目标模型生成回复(蒸馏数据)。 -
测试基准: -
MT-Bench (通用对话). -
HumanEval (代码). -
GSM8K (数学).
-
-
评估指标:平均接受长度 (Mean Acceptance Length) 。计算公式为 。
5. 实验
5.1 主要结果
在 Llama-3.1-8B 上的对比实验表明,LK Losses 在所有架构和采样温度设置下均优于 KL 基线。
[表 1 中文标题]:Llama-3.1-8B-Instruct 上不同草稿模型和损失函数的平均接受长度 对比。
-
EAGLE-3: 在 Temperature=1 (随机采样) 设置下,混合损失 在 HumanEval 上将 从 4.31 (KL) 提升至 4.52,提升显著。 -
MEDUSA & MLP: 相对简单的架构受益更大。例如 MEDUSA 在 GSM8K 上提升约 6-8%。这印证了模型容量越小,直接优化接受率的收益越大的理论推断。
5.2 跨模型扩展性
实验进一步验证了 LK Losses 在不同规模目标模型上的表现(从 8B 到 685B)。
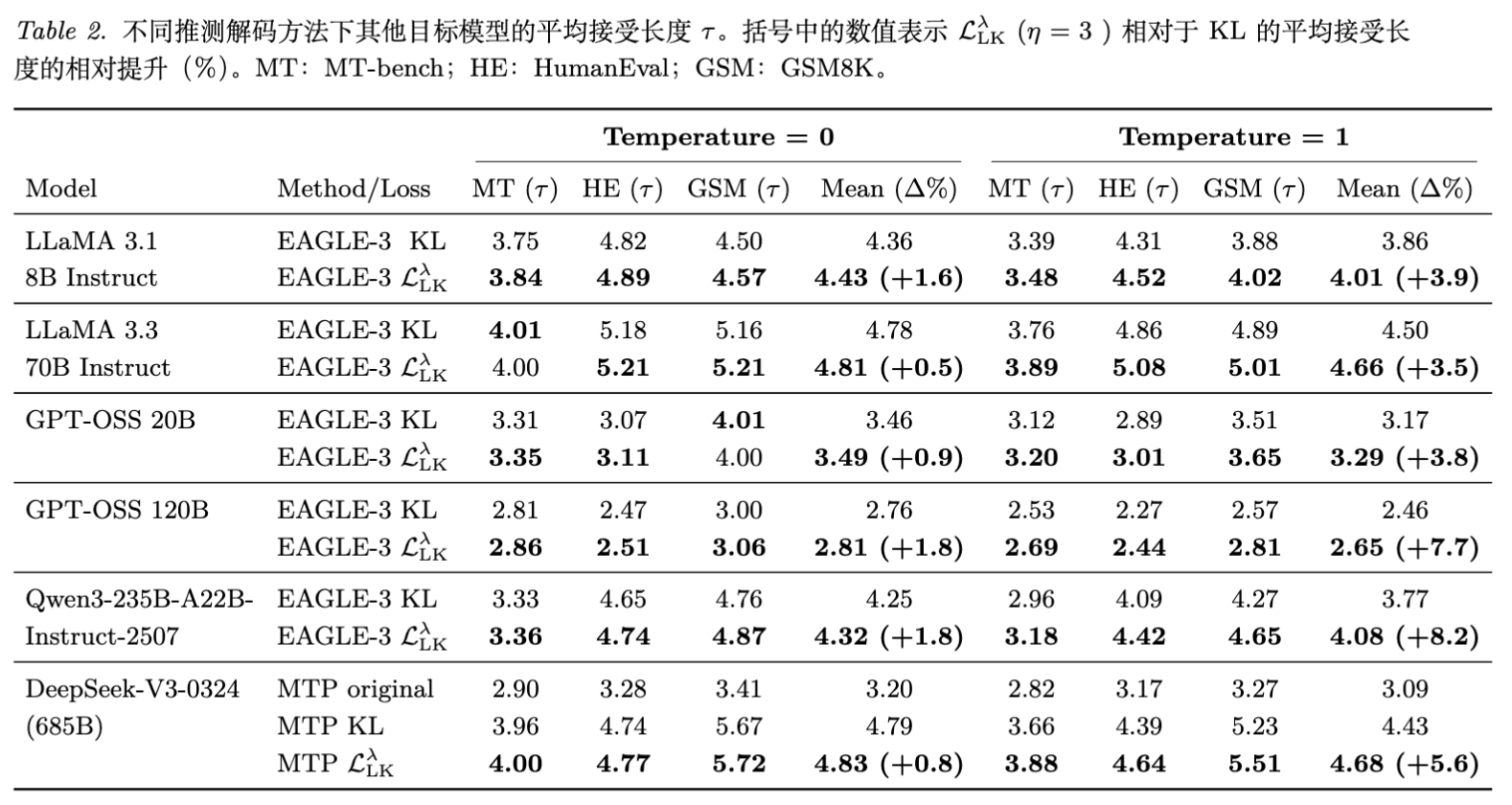
-
DeepSeek-V3: 对 DeepSeek-V3 的 MTP 模块进行微调。原始 MTP 并非专为投机采样训练(而是用于训练稳定性)。微调后,KL 版本提升明显,而 LK Losses 进一步将 GSM8K 的接受长度从 5.67 (KL) 提升至 5.72,相比原始 MTP (3.41) 有质的飞跃。 -
Qwen3-235B: 实现了最大的相对提升 (+8.2%)。作者假设这是因为大参数差异导致“容量缺口”更严重,此时 KL 的次优解问题更突出,LK Losses 的修正作用更明显。
5.3 消融研究
-
纯 TV 损失: 实验证实,直接使用纯 TV 损失训练会导致极差的性能( 远低于 KL),这验证了梯度分析中指出的优化困难。 -
固定权重混合: 使用固定的 效果不如纯 KL,说明静态混合无法平衡训练初期和后期的需求。 -
自适应调度: 参数对 很重要。 越大,向 TV 优化的过渡越快。对于 EAGLE-3 这种强草稿模型, 较好;对于 MEDUSA,需要更大的 以补偿较慢的学习率。
6. 代码实现细节
为了方便研究员复现,这里总结关键的实现逻辑(基于 PyTorch 风格):
6.1 梯度实现
对于 ,在 PyTorch 中可以直接通过自动微分实现,但需注意数值稳定性。
对于 ,核心在于计算 并 detach 梯度用于计算 :
def compute_lk_hybrid_loss(logits_q, probs_p, eta=3.0):
probs_q = torch.softmax(logits_q, dim=-1)
# 计算逐样本的接受率 alpha
# alpha = sum(min(p, q))
min_probs = torch.minimum(probs_p, probs_q)
alpha = min_probs.sum(dim=-1) # shape: [batch_size, seq_len]
# 计算自适应 lambda
# sg[alpha] 表示不传导梯度
lambda_weight = torch.exp(-eta * alpha.detach())
# KL 散度项
# 注意:PyTorch 的 KLDivLoss 默认输入是 log_prob
log_probs_q = torch.log_softmax(logits_q, dim=-1)
kl_loss = torch.sum(probs_p * (torch.log(probs_p + 1e-10) - log_probs_q), dim=-1)
# TV 距离项
tv_loss = 0.5 * torch.sum(torch.abs(probs_p - probs_q), dim=-1)
# 组合损失
loss = lambda_weight * kl_loss + (1 - lambda_weight) * tv_loss
return loss.mean()
6.2 词表截断处理
如果使用了 FR-Spec 风格的词表截断,probs_q 只在部分索引上有值,其余为 0。计算 min_probs 时,未选中索引处的 min(p, 0) 自然为 0,不影响 alpha 的计算。而计算 KL 时需要特别小心 probs_q 为 0 的位置导致 log(0),通常需要 mask 掉这些位置或使用 LK Losses 避免此问题。
7. 总结与展望
7.1 核心结论
-
目标错位确认:KL 散度在草稿模型容量有限时,并非最大化接受率的最佳代理。 -
LK Losses 有效:通过自适应混合或对数接受率损失,可以在不增加推理开销的情况下,显著提升投机采样的加速比。 -
通用性强:该方法对模型结构(Transformer, MLP)、模型规模(8B-685B)和领域(代码、数学)均表现出鲁棒的提升。
7.2 局限性与未来工作
-
超参数敏感性:自适应调度的衰减系数 需要根据草稿模型的收敛速度进行调整。 -
系统效率优化:目前的优化目标是接受率 ,未来可以进一步探索直接优化端到端的系统延迟(System Efficiency),例如考虑不同位置 token 的验证开销。
更多细节请阅读原文。
往期文章:


