当我们试图通过在特定领域(如数学推理)的数据集上进行监督微调(Supervised Fine-Tuning, SFT)来提升模型性能时,常常会观察到一个性能瓶颈:在初始阶段,模型的表现会随着训练数据的增加而提升,但很快就会达到一个停滞期。此时,即便是投入更多同类型的数据,模型的性能也几乎不再有任何改善。这种现象在经过大规模预训练和指令微调的模型上尤为明显。
这种饱和现象揭示了传统 SFT 方法的内在局限性。标准的 SFT 采用的是一种“数据驱动”的范式,其核心假设是“更多的数据等于更好的性能”。然而,当模型已经基本掌握了训练分布中的大部分知识模式后,这种训练方式效率变得低下。其根本原因在于,标准的损失函数(如交叉熵损失)在整个数据集上进行平均,这导致了训练信号的稀释。对于模型已经能够正确解决的大部分样本,损失值很小;而对于少数模型仍然会犯错的难题,其产生的损失信号被淹没在了整体的平均值中,无法对模型参数进行有效和针对性的更新。此外,训练时采用的 next-token prediction 损失与评估时使用的 auto-regressive generation 过程之间存在的固有差异,也使得平均损失无法精确捕捉到生成过程中出现的具体、细微的推理错误。
现有的改进方法,如仅使用数据集中的难题(例如 MATH-Hard)进行训练,或是基于嵌入相似度来选择与验证集中错误样本相似的训练数据,虽然在一定程度上缓解了问题,但并未从根本上解决问题。这些方法仍然停留在“数据表面特征”的层面,而没有深入探究模型能力上的“技能短板”。
来自普林斯顿大学的研究者们在他们的论文《Skill-Targeted Adaptive Training》中,为解决这一饱和问题提供了一个全新的视角。他们提出的 STAT (Skill-Targeted Adaptive Training) 框架,从根本上将微调范式从“数据驱动”转向了“技能驱动”。STAT 的核心思想借鉴了人类教育学的理念:优秀的教学不是盲目地让学生“刷题”,而是首先诊断出学生知识体系中的薄弱环节(即“缺失的技能”),然后提供针对性的练习来“对症下药”。STAT 将这一理念迁移到 LLM 的训练中,通过一个强大的“教师模型”来诊断“学生模型”在解决问题时所暴露出的技能缺陷,并以此为依据,自适应地构建一个能够高效弥补这些缺陷的训练集。

-
论文标题:Skill-Targeted Adaptive Training -
论文链接:https://arxiv.org/pdf/2510.10023
1. STAT 方法论
STAT 的整体框架可以被概括为一个包含三个核心阶段的流水线:1. 识别疑难问题;2. 诊断缺失技能;3. 构建目标训练集。这个流程系统性地回答了三个关键问题:模型在哪些问题上表现不佳?导致这些表现不佳的根本技能缺陷是什么?以及,如何高效地弥补这些技能缺陷?
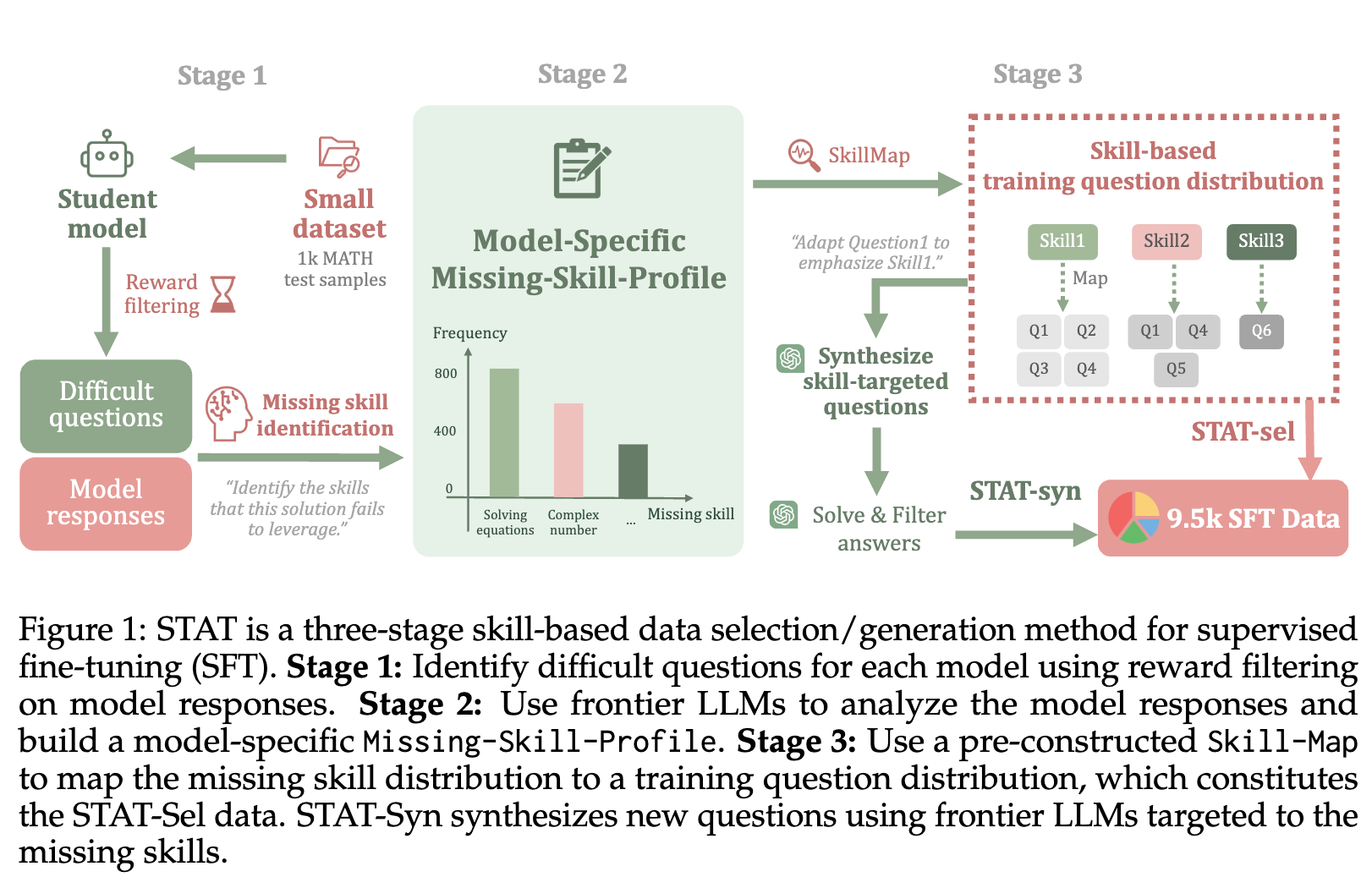
上图直观地展示了 STAT 的工作流程。接下来,我们将对每个阶段进行详细的拆解。
1.1 基于奖励模型识别“困难问题”
传统上,判断一个问题对模型是否“困难”,最直接的方法是看模型的最终答案是否正确。但这种方法有两个局限:首先,它需要访问带有标准答案的标签数据;其次,它是一种“结果论”,无法捕捉到那些“侥幸做对”(即推理过程有误但答案凑巧正确)的情况。
为了克服这些局限,并使方法更具通用性,STAT 采用了一个过程奖励模型(Process Reward Model, PRM)来评估学生模型生成解题步骤的质量,而不是仅仅评估最终答案。这个奖励模型本身是一个预训练好的语言模型,它被训练用于为解题过程中的每一步打分。
给定一个问题 和学生模型为其生成的包含 个步骤的解答,奖励模型会输出一个分数序列 。STAT 设计了一个阈值过滤函数 来判断该问题是否为“疑难问题”(difficult question),其中 代表“困难”, 代表“简单”。其判断逻辑如下:
这个公式包含了三个并列的判定条件,满足任意一个,问题 就会被归类为“疑难问题”:
-
最终步骤奖励低 (): 这直接对应了最终答案错误或格式不规范的情况。 -
平均步骤奖励低 (): 这捕捉了整个解题过程质量普遍不高的情况,即使最终答案可能正确。 -
任意中间步骤奖励过低 (): 这是一个严格的条件,用于识别那些解题过程中存在严重逻辑跳跃或计算错误,但后续步骤可能掩盖了该错误的情况。
通过这个过程,STAT 能够从一个验证集 中筛选出一个模型特定的、更为精确的疑难问题子集 。这个子集不仅包括了模型答错的问题,还包括了那些推理过程存在瑕疵的问题,为下一阶段的技能诊断提供了高质量的输入。
1.2 构建模型 Missing-Skill-Profile
在识别出学生模型难以解决的问题之后,下一步是深入探究“为什么”这些问题是困难的。STAT 在此阶段引入了一个能力更强的“教师模型”(在实验中使用了 GPT-4o-mini),利用其强大的元认知(meta-cognition)能力来扮演诊断专家的角色。
这个过程依赖于两个预先构建的核心组件:
-
技能列表 (Skill Set, ): 这是一个预定义的、涵盖了特定领域(如数学)所需的基础技能的列表。例如,在数学领域,这个列表可能包含“代数表达式化简”、“一元二次方程求解”、“组合计数”、“模块化算术”等 128 种细分技能。 -
技能-问题映射 (Skill-Map, ): 这是一个从每个技能到训练数据集 中需要该技能的问题的映射。这个映射本身也是通过教师模型对整个训练集进行标注而得到的。
对于在阶段一中筛选出的每一个疑难问题 ,STAT 会将该问题 、学生模型的错误解答、以及相关的技能列表一同输入给教师模型。教师模型被要求完成以下任务:
-
判断 学生模型的解答是否正确。 -
分析 如果解答不正确,具体错误的原因是什么。 -
识别 学生模型在该解答中未能成功运用或缺失了哪些关键技能。
通过对 中的所有问题进行这样的分析,STAT 构建了一个模型特定 Missing-Skill-Profile。这是一个从疑难问题到其所需缺失技能集合的映射: (其中 是技能集 的幂集)。这个图谱是 STAT 的核心,它精确地刻画了当前学生模型的能力短板。
1.3 选择或合成基于技能的训练数据
有了精确的 Missing-Skill-Profile,最后一步就是构建一个能够弥补这些技能短板的目标训练集 。STAT 在此提出了两种具体的策略:选择式(STAT-Sel)和生成式(STAT-Syn)。
1.3.1 STAT-Sel
STAT-Sel 是一种相对经济的方法。它的核心思想是:与其创造新数据,不如引导学生模型重新关注现有训练集中那些能够锻炼其薄弱技能的样本。
其具体流程如下:
-
遍历所有疑难问题 及其对应的缺失技能列表 。 -
对于每一个缺失的技能 ,利用预先构建好的 Skill-Map,从原始的大规模训练集 中,随机抽样出若干个(例如 5 个)需要技能 的训练样本。 -
将所有这些被抽样出的样本汇总起来,构成新的目标训练集 。
通过这种方式,STAT-Sel 动态地调整了训练数据的分布,使得训练过程的“火力”集中在模型的知识盲区。一个技能被诊断为缺失的次数越多,与之相关的训练样本在新的训练集中出现的频率就越高。
1.3.2 STAT-Syn
STAT-Syn 是一种更主动、也更强大的方法。它不再局限于现有的训练数据,而是利用教师模型来合成全新的、专门针对缺失技能的训练样本。
其流程更为精细:
-
与 STAT-Sel 类似,首先识别出疑难问题 及其对应的缺失技能 。 -
利用 Skill-Map从训练集 中找到若干个(例如 3 个)与技能 相关的样本作为“上下文示例”(in-context examples)。 -
将这些示例和缺失技能 的描述一同输入给教师模型,并要求它创造一个全新的、需要运用到技能 的问题及其解答。 -
为了保证合成数据的质量,STAT-Syn 引入了一个一致性过滤步骤。教师模型会被要求为每个新问题生成多个(例如 3 个)独立的解法。只有当至少有两个解法的最终答案一致时,这个问题才被认为是有效的,并被保留下来。 -
最终,这些高质量的、由教师模型合成的的问答对构成了训练集 。
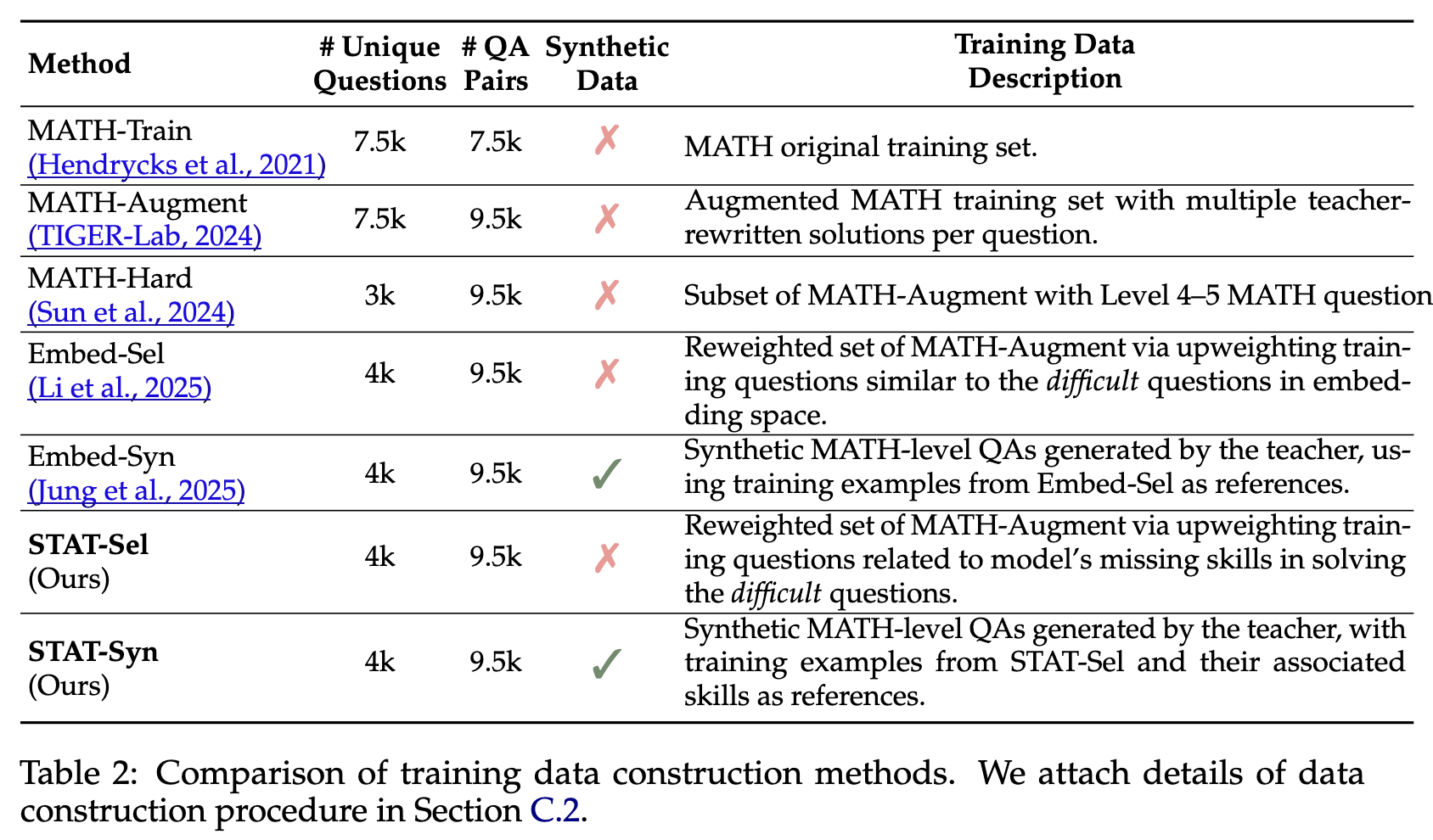
总的来说,STAT-Sel 通过重采样来“盘活存量”,而 STAT-Syn 通过合成来“创造增量”。两者都实现了从“盲目刷题”到“精准练习”的转变,构成了 STAT 框架的核心驱动力。
2. 实验
为了验证 STAT 框架的有效性,研究者们在 Llama 和 Qwen 系列的多个模型上,围绕数学推理任务进行了一系列详尽的实验。
2.1 实验设置
-
学生模型: Llama-3.2-3B-Instruct, Qwen2.5-3B 等中小型模型,这些模型在数学任务上仍有明显的性能提升空间。 -
教师模型: GPT-4o-mini。 -
核心数据集: MATH 数据集作为主要的训练和分布内(in-distribution)评估基准。 -
泛化能力评估: 使用了一系列分布外(Out-of-Distribution, OOD)数据集,包括 GSM8K, MATH², MATH-perturb, AMC23, AIME 等,以测试模型学到的技能是否具有通用性。 -
基线方法: -
Base Model: 未经任何微调的原始模型。 -
MATH-Train: 使用原始 MATH 训练集进行标准 SFT。 -
MATH-Augment: 使用教师模型重写过的答案进行 SFT,以消除原始答案质量的影响。 -
MATH-Hard: 仅使用 MATH 数据集中 Level 4-5 的难题进行 SFT。 -
Embed-Sel/Embed-Syn: 基于嵌入相似度的自适应方法,作为 STAT 最主要的竞争对手。该方法选择或合成与疑难问题在嵌入空间中语义相似的训练样本。
-
2.2 核心发现
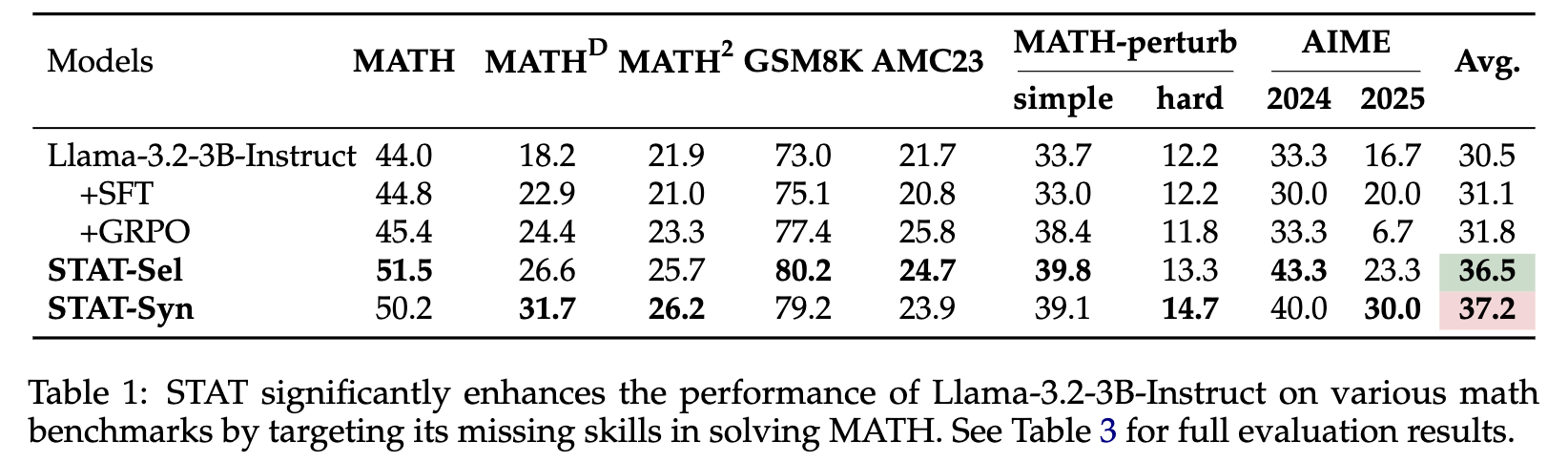
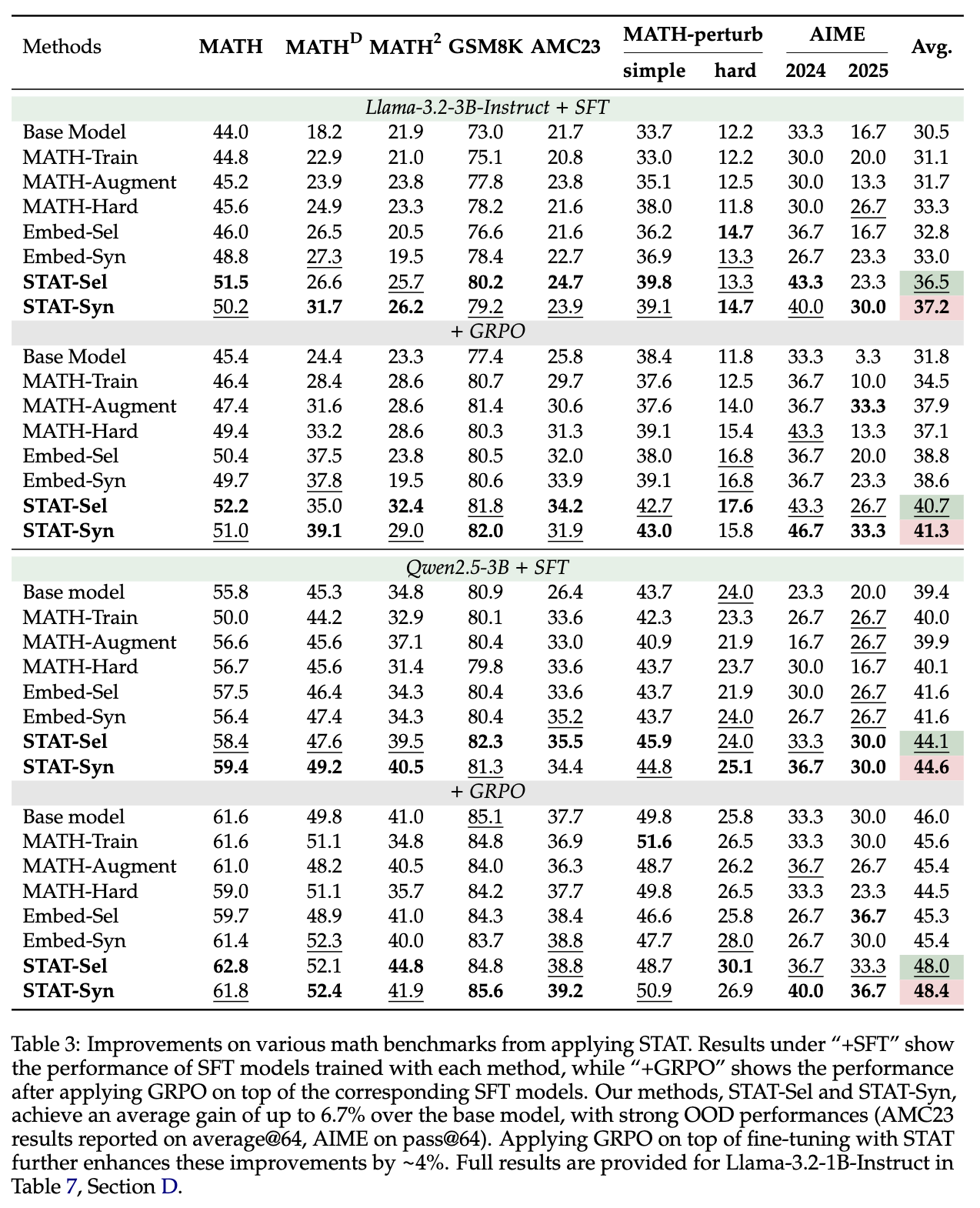
通过对实验结果的细致分析,可以总结出以下几个核心发现:
2.2.1 标准 SFT 增益饱和,STAT 提升显著
实验结果清晰地表明了“饱和”现象的存在。在 Llama-3.2-3B-Instruct 模型上,MATH-Train 和 MATH-Augment 相较于 Base Model 在 MATH 基准上的提升仅有约 1%。即使是只使用难题的 MATH-Hard,提升也有限。这证明了简单地增加数据量或数据难度,并不能有效突破性能瓶颈。
相比之下,STAT 方法取得了显著的性能提升。STAT-Sel 和 STAT-Syn 在 MATH 数据集上的 Pass@1 准确率分别提升了 7.5% 和 6.2% 。
2.2.2 强大的分布外 (OOD) 泛化能力
一个关键的问题是:STAT 带来的性能提升,究竟是源于对特定数据集的过拟合,还是真正学到了可迁移的技能?实验中对多个 OOD 基准的评估给出了答案。
结果显示,STAT 在 AIME, AMC23, MATH-perturb 等高难度、形式多样的 OOD 数据集上同样表现出色。例如,在 Llama-3.2-3B-Instruct 上,STAT-Syn 的平均性能(Avg.)达到了 37.2,相较于基座模型的 30.5 有着接近 7 个点的巨大提升,也远超其他所有基线方法。这表明,STAT 促使模型学习到的不仅仅是解决 MATH 数据集中特定问题的“套路”,而是更底层的、通用的数学推理技能,这些技能可以被成功迁移到未见过的任务上。
2.2.3 与强化学习 (RL) 表现出互补性
在当前的 LLM 训练流程中,SFT 之后通常会进行强化学习(如 RLHF 或其变体 GRPO)来进一步优化模型。一个自然的问题是,STAT 这种优化的 SFT 方法是否会与后续的 RL 阶段产生冲突或效果重叠?
实验结果给出了一个令人振奋的答案:STAT 与 RL 是互补的。研究者们在经过各种 SFT 方法训练后的模型基础上,继续使用 GRPO 进行强化学习。结果发现,在 STAT-Sel 和 STAT-Syn 的基础上进行 GRPO 训练,所达到的最终性能远高于在其他基线 SFT 模型上进行 GRPO 训练。例如,STAT-Syn + GRPO 的组合在 Llama-3.2-3B-Instruct 上取得了 41.3 的平均分,是所有方法中的最高值。
这个发现具有重要的实践意义。它表明 STAT 可以无缝地嵌入到现有的“SFT+RL”训练 pipeline 中。STAT 在第一阶段通过精准填补技能空白,为模型打下坚实的基础;而 RL 则在第二阶段,在这个更强的基础上进一步优化生成策略和对齐偏好,两者相得益彰。
2.2.4 对持续学习和任务演进的适应能力
在现实应用中,模型需要面对不断变化的、难度递增的任务。STAT 框架的诊断式流程天然地支持这种持续学习的需求。
研究者们进行了一个模拟实验:首先使用 STAT 在 MATH 数据集上训练模型,然后将模型置于一个更难的 MATH-perturb-hard 数据集环境中。他们将 MATH-perturb-hard 作为新的验证集,重新执行 STAT 的第一、二阶段来构建一个新的 Missing-Skill-Profile,并利用这个新的 Profile 从原始的 MATH 训练集中筛选或合成数据,对模型进行进一步的“强化训练”。
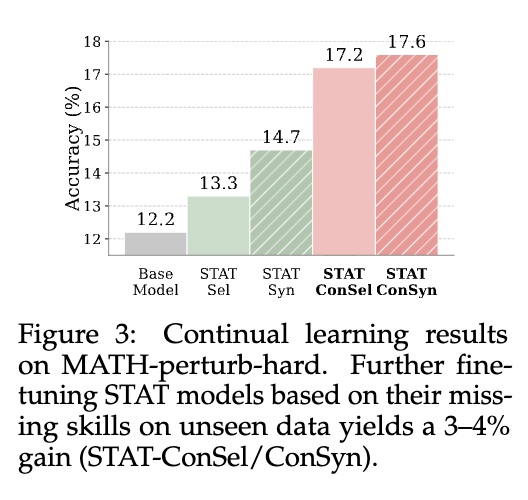
结果显示,经过这一轮的持续自适应训练后,模型在 MATH-perturb-hard 上的性能获得了进一步的显著提升(约 3-4%)。这证明了 STAT 框架的灵活性和可扩展性。只要有新的评估基准来暴露模型的不足,STAT 就可以被重新调用,以一种数据高效的方式(仍然使用旧的训练数据源)来驱动模型的持续进步。
3. 分析
STAT 之所以能够超越其他基线方法,其根本原因在于它精确地识别并解决了“训练数据技能分布”与“模型实际缺失技能”之间的错位(misalignment)问题。
研究者们通过对 Llama-3.2-1B-Instruct 模型的 Missing-Skill-Profile 进行深入分析,揭示了几个深刻的洞见:
模型的核心短板在于基础运算技能

上图(左侧部分)展示了模型最常缺失的 Top 10 技能。一个出乎意料的发现是,尽管模型在 MATH 这样的数据集上经过了广泛训练,但其最频繁的短板并非出现在那些高深的数学概念上,而是集中在非常基础的技能领域,例如:
-
求解方程 (Solving Equations) -
基础算术运算 (Basic Arithmetic Operations) -
代数变换 (Algebraic Manipulation) -
计算与转换 (Calculation and Conversion)
这表明,即便是强大的 LLM,在进行复杂的多步推理时,也常常因为基础运算能力的不扎实而“翻车”。
基线方法的“文不对题”
上图(中间和右侧部分)进一步对比了不同方法所侧重的训练技能分布。MATH-Train 的技能分布反映了原始数据集中最常见的技能,例如“多项式概念”和“素数理论”。Embed-Sel 作为基于嵌入相似度的方法,其选择的训练数据在技能分布上与 MATH-Train 高度相似。
问题在于,这些数据集中最高频的技能,与模型实际最缺失的技能,存在着巨大的差异。基线方法不断地给模型“复习”它已经掌握得比较好的知识(如多项式概念),却忽略了它真正薄弱的基础环节(如解方程)。这就是“技能错位”。
而 STAT 通过其诊断机制,完美地解决了这个问题。STAT-Sel 所选择的数据,其技能分布与模型实际的缺失技能分布(图左)高度吻合。它做到了真正的“缺什么,补什么”,从而实现了训练效率和效果的最大化。
目标合成的有效性

一个具体的案例可以生动地说明 STAT-Syn 与 Embed-Syn 的本质区别。假设原始的疑难问题是一个关于“椭圆性质”的问题,但学生模型在最后一步“解方程”时出错了。
-
Embed-Syn: 由于它关注的是语义相似度,它可能会合成另一个与“椭圆性质”相关的新问题。这个问题虽然在主题上相关,但并没有针对性地锻炼模型薄弱的“解方程”能力。 -
STAT-Syn: 它接收到的指令是明确的——针对“解方程”这个缺失技能来创造问题。因此,它会合成一个形式简洁、但直击要害的代数方程求解问题。
这个对比清晰地表明,基于语义相似度的自适应方法在面对推理任务时可能会失效,因为它无法穿透文本的表层含义,触及底层的逻辑和技能需求。
4. 总结
总结来说,STAT 的主要贡献和优势包括:
-
提出了一套创新的三阶段训练框架:通过“识别疑难问题-诊断缺失技能-构建目标训练集”的闭环,实现了对模型能力短板的提升。 -
验证了“技能错位”是导致饱和的关键原因:揭示了传统 SFT 和嵌入式自适应方法效率低下的根本机制。 -
实现了显著的性能提升和强大的泛化能力:不仅在分布内任务上效果斐然,更在多个 OOD 基准上证明了所学技能的可迁移性。 -
展示了与强化学习的互补性:为构建更强大的“SFT+RL”训练 pipeline 提供了新的思路,具有很高的实践价值。
往期文章:


