利用强化学习(RL)提升大型语言模型(LLM)的推理能力,即RL4LLM,已成为人工智能领域炙手可热的研究方向。然而,该领域的飞速发展也带来了一系列严峻挑战:各种RL技术层出不穷,却缺乏统一的使用标准和深入的机理分析;不一致的实验设置、训练数据和模型初始化导致了相互矛盾的研究结论,让从业者在技术选型时倍感困惑。本文旨在拨开迷雾,通过一个统一的开源框架,对当前广泛应用的RL技术进行了系统性的复现和评估。通过对不同难度数据集、模型规模和架构下的细致实验,我们深入剖析了每种技术的内部机制、适用场景和核心原则,为从业者提供了一份清晰、可靠的RL4LLM技术选型与实践路线图。更令人惊喜的是,研究发现,一种仅包含两项核心技术的极简PPO方法——“Lite PPO”,其性能竟能稳定超越如GRPO和DAPO等更为复杂的知名算法。
引言:RL4LLM的“战国时代”与实践者的困境
近年来,从OpenAI的GPT系列到DeepSeek的数学大模型,我们见证了大型语言模型(LLM)在复杂推理任务(如数学解题、代码生成)上取得的惊人突破。 在这背后,强化学习(RL)扮演了至关重要的角色,它能够引导LLM超越预训练阶段所能达到的性能上限,解锁更高级的推理能力。这个被称作“RL for LLM”或“RL4LLM”的新兴领域,在2025年迎来了研究热潮,arXiv和各大顶会上涌现出数百篇相关论文,涵盖了从算法创新到工程实践的方方面面。
然而,繁荣的背后也隐藏着混乱。当前的RL4LLM研究如同一个“百家争鸣”的战国时代,各种技术和“tricks”层出不穷,但缺乏统一的评估标准和清晰的使用指南。这给广大AI从业者和研究者带来了巨大的困惑:
-
结论相互矛盾:不同的论文对同一个问题给出了截然不同的解决方案。例如,在归一化策略上,GRPO算法 [Shao et al., 2024] 推荐使用“组级别(group-level)”归一化来增强稳定性,而REINFORCE++ [Hu et al., 2025] 则认为“批次级别(batch-level)”归一化效果更佳。更有甚者,Dr. GRPO [Liu et al., 2025a] 建议在GRPO的基础上移除方差归一化,以避免引入偏差。 -
实现细节模糊:在损失计算上,GRPO采用“响应级别(response-level)”的损失聚合,而DAPO算法 [Yu et al., 2025] 则采用“令牌级别(token-level)”的聚合。这些看似细微的差别,背后却可能隐藏着截然不同的优化哲学和适用场景。 -
技术组合爆炸:除了上述核心技术,还有大量的“正交”技术,如裁剪(Clipping)、过长过滤(Overlong Filtering)等,可以相互组合。面对如此众多的技术选项,从业者如同进入了一个迷宫,难以抉择如何搭配才能在特定场景下发挥LLM的最大潜力。
这些混乱现象的根本原因在于,各个研究的实验设置(如模型、数据、初始化参数)千差万别,导致结论难以横向比较和推广。因此,整个社区迫切需要回答一个核心问题:
在不同的场景下,现有的这些RL技术分别适用于什么情况?是否存在一种简单而通用的技术组合,能够普适地增强策略优化的效果?
这篇由阿里巴巴集团、北京交通大学、香港科技大学、南京大学、北京大学等机构的研究人员共同完成的论文——《Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning》,正是为了解决这一核心痛点而生。
该论文借鉴了经典RL机制分析的方法,在一个名为ROLL (Reinforcement Learning Optimization for Large-scale Learning)的统一开源框架下,对主流的RL技术进行了系统性的复现、隔离评估和深入分析。他们不仅考察了这些技术在不同难度数据、不同模型尺寸和类型下的表现,还深入探讨了其理论基础和实现细节。
最终,该研究不仅为从业者提供了一份宝贵的“避坑指南”和“实践路线图”,更提出了一个极简却高效的算法——Lite PPO。该算法证明,仅通过两种精心挑选的技术(优势归一化和令牌级损失聚合),就能在无价值函数(critic-free)的策略上,利用原始的PPO损失函数,实现超越主流复杂算法的性能。
接下来的内容,我们将以万字篇幅,详细拆解这篇重磅论文,带你深入RL4LLM的“技术腹地”,探寻那些真正有效的“技巧”,避开那些华而不实的“陷阱”。
第二章:预备知识 - PPO、GRPO与DAPO
在深入论文的实验分析之前,我们首先需要了解几个关键的强化学习算法,它们是本文讨论的基础。
2.1 近端策略优化 (Proximal Policy Optimization, PPO)
PPO [Schulman et al., 2017] 是目前RL领域,尤其是RLHF(Reinforcement Learning from Human Feedback)中应用最广泛的算法之一。它属于“行动者-评论家(Actor-Critic)”框架,通过优化一个“裁剪后(clipped)”的替代目标函数来提升策略的稳定性。其核心思想是在鼓励策略向好的方向更新的同时,通过一个裁剪超参数 ε 来限制新旧策略之间的差距,防止因单步更新过大而导致训练崩溃。
PPO的目标函数可以表示为:
其中:
-
是新旧策略在状态 下采取动作 的概率比。 -
是在时间步 的优势函数估计值,通常使用广义优势估计(GAE, Generalized Advantage Estimation)[Schulman et al., 2018] 计算得出。它表示在当前状态下,采取某个动作比平均水平好多少。 -
clip函数将概率比限制在 区间内。
这个min操作是PPO的精髓:
-
当优势 (即这是一个好动作)时,目标函数变为 。这鼓励我们增大 ,但增幅被 限制,防止策略更新过于激进。 -
当优势 (即这是一个坏动作)时,目标函数变为 (因为为负,所以min变成了max)。这鼓励我们减小 ,但减幅被 限制,同样是为了稳定。
2.2 组相对策略优化 (Group Relative Policy Optimization, GRPO)
GRPO [Shao et al., 2024] 是DeepSeek在训练其数学大模型DeepSeekMath时提出的一种方法。它对PPO进行了简化和改进,核心特点是去掉了价值网络(Critic),直接通过对同一提示(prompt)产生的多个输出(responses)的奖励进行归一化来估计优势。
具体来说,对于一个提示 ,模型生成了 个不同的响应,每个响应对应一个奖励 。GRPO计算第 个响应的归一化优势为:
这种“组内相对归一化”的方法,可以看作是一种奖励重塑(reward shaping)。它强调了同一提示下不同输出之间的相对好坏,即使在奖励非常稀疏(比如只有对和错两种)的情况下,也能提供有效的梯度信号。
此外,GRPO还直接在损失函数中加入了KL散度惩罚项,以约束训练后的策略 不要偏离一个参考策略 太远。其总目标函数为:
2.3 解耦裁剪与动态采样策略优化 (Decoupled Clip and Dynamic Sampling Policy Optimization, DAPO)
DAPO [Yu et al., 2025] 是另一个针对LLM推理优化的新方法。它在GRPO的基础上做了进一步的扩展,主要特点包括:
-
解耦裁剪范围:传统的PPO使用对称的裁剪范围 。DAPO认为,为了更好地鼓励探索,应该对优势为正和为负的情况使用不同的裁剪范围,即 。 -
动态采样过滤:DAPO会动态地过滤掉那些所有响应都正确或所有响应都错误的样本组,认为这些样本提供的信息量较少。 -
令牌级损失聚合:如前所述,DAPO在令牌级别计算和聚合损失。 -
特殊奖励重塑:对过长或被截断的响应进行特殊的奖励处理。
DAPO的目标函数形式上与PPO类似,但其优势计算、裁剪方式和数据处理策略都更加复杂。
这三种算法代表了当前RL4LLM领域从经典到前沿的不同技术路线,也是本文后续实验分析和比较的主要对象。
第三章:实验设计 - 在统一的竞技场上量化“真功夫”
为了确保所有比较的公平性和可复现性,论文作者精心设计了一套统一且全面的实验环境。
3.1 实验设置
-
训练框架:所有实验均在阿里巴巴开源的ROLL (Reinforcement Learning Optimization for Large-scale Learning)框架上进行。这是一个专为LLM强化学习设计的高效、可扩展平台。 -
基线算法:为了隔离和评估各种“trick”的真实效果,作者采用了一个非常“朴素(naive)”的RL基线:使用PPO的损失函数形式,但优势值 直接使用REINFORCE算法计算(即蒙特卡洛回报),不包含复杂的价值网络。 -
超参数:为了与现有研究保持一致,全局批次大小设置为1024。对于每个prompt,采样8个响应,最大响应长度为8192个token。学习率设置为 1e-6。文本生成时,top_p为0.99,top_k为100,temperature为0.99。
3.2 基础模型
实验覆盖了两种不同参数规模的模型,以评估技术在不同模型容量下的表现:
-
Qwen3-4B 和 Qwen3-8B
并且,对于每种尺寸,都包含了两种版本:
-
Base模型:即预训练后未经过指令微调的原始模型。 -
Aligned模型(或Instruct模型):经过指令微调,对人类指令有更好理解的模型。
这使得研究能够评估RL技术在不同起点(未对齐 vs 已对齐)上的增益效果。
3.3 训练与评估数据集
-
训练数据:为了全面考察难度对技术效果的影响,作者从开源数据集SimpleRL-Zoo-Data和DeepMath中构建了三个不同难度的训练集,每个包含5000个样本:
-
简单数据(Easy Data): 从GSM8K和MATH-500-level中抽样。 -
中等数据(Medium Data): 从DeepMath-103k数据集中选取最简单的5000个样本。 -
困难数据(Hard Data): 从DeepMath-103k数据集中按难度比例抽样,难题占比更高。
一个有趣的细节是,作者在数据处理时,特意移除了那些答案仅仅是“True”或“False”的样本。因为他们发现,模型有时会通过错误的推理链条“蒙对”这种二元答案,这种“虚假阳性(ostensible positive)”现象会引入噪声,影响训练质量。
-
-
评估基准:所有实验都在六个公开的数学数据集上进行评估,覆盖了从基础算术到竞赛级数学的广泛难度范围:
-
MATH-500 -
OlympiadBench -
MinervaMath -
AIME24-25 (美国数学邀请赛) -
AMC23 (美国数学竞赛)
-
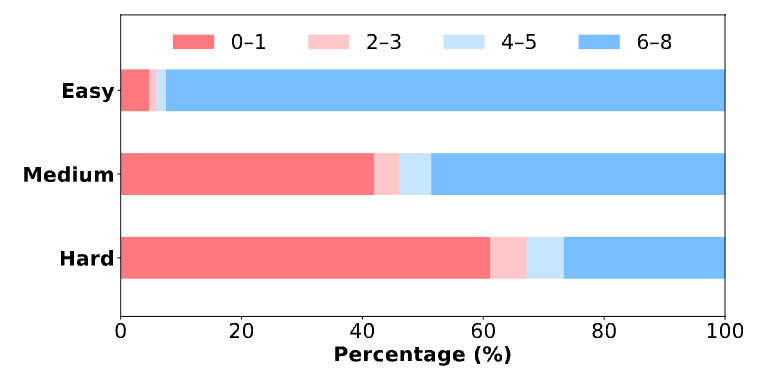
3.4 基线结果观察
在正式分析具体技术前,作者首先运行了基线实验,得到了一些有趣的初步观察:
-
数据难度影响显著:如下图所示,随着训练轮数增加,模型在不同难度数据集上的准确率轨迹差异巨大。面对更难的样本,模型需要生成更长的token来拟合复杂的推理模式。
-
对齐模型提升空间有限:与Base模型相比,Aligned模型在训练初期就表现出高得多的准确率和更长的平均响应长度。然而,经过RL训练后,Aligned模型的性能提升非常有限(约2%)。这表明,对于已经经过高度优化的对齐模型,当前的RL4LLM算法能带来的边际效益不大。这反过来也说明,Base模型是测试RL算法潜力更好的“试金石”。
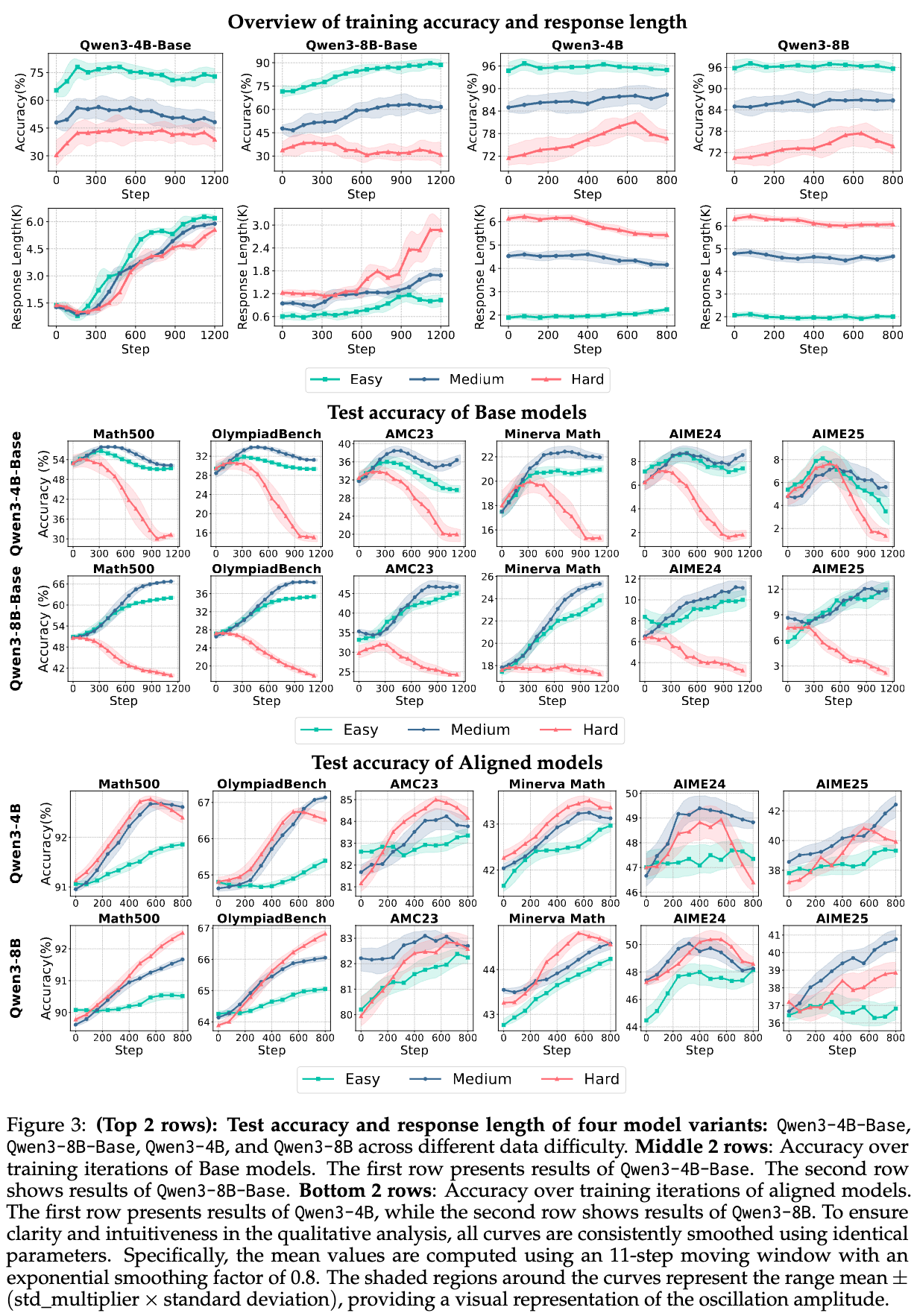
有了这个统一、公平且全面的实验设计,我们终于可以开始逐一解剖那些在RL4LLM中广为流传的“技巧”了。
第四章:核心分析 - 逐一拆解四大关键技术
本章是论文的核心,作者聚焦于四个最关键的技术领域:归一化(Normalization)、裁剪(Clipping)、损失聚合(Loss Aggregation) 和 过滤(Filtering),并对它们进行了深入的实验和分析。
4.1 归一化 (Normalization):稳定训练的基石
优势归一化是稳定策略梯度训练的常用技术,但具体如何实现却众说纷纭。核心争议点在于:应该在“组内(group-level)”还是“批次内(batch-level)”进行归一化?以及,归一化时是否必须使用标准差(standard deviation)?
4.1.1 优势归一化对奖励机制的敏感性
Takeaway 1: 组级别归一化在各种奖励设置下都表现出鲁棒的效率。批次级别归一化在大学习率设置下提供更稳定的改进。
作者在一个统一的训练框架下,比较了三种设置:无归一化、批次级别归一化和组级别归一化。为了凸显差异,实验主要在改进潜力更大的Base模型上进行。
-
默认奖励设置():即答案正确奖励为1,错误为0。
-
结果显示,在4B和8B模型上,组级别归一化都表现出了最稳定的训练动态和最高的最终性能。 -
相比之下,批次级别归一化对奖励分布的偏斜非常敏感。当一个批次中大部分样本奖励相同(例如大部分都错误),少数几个异常样本(例如一两个正确答案)会主导优势的计算,导致性能崩溃。
-
-
更大范围的奖励设置():将错误答案的奖励从0变为-1,增大了奖励的区分度。
-
有趣的是,在这种设置下,批次级别归一化的性能得到了显著的恢复和提升。
-
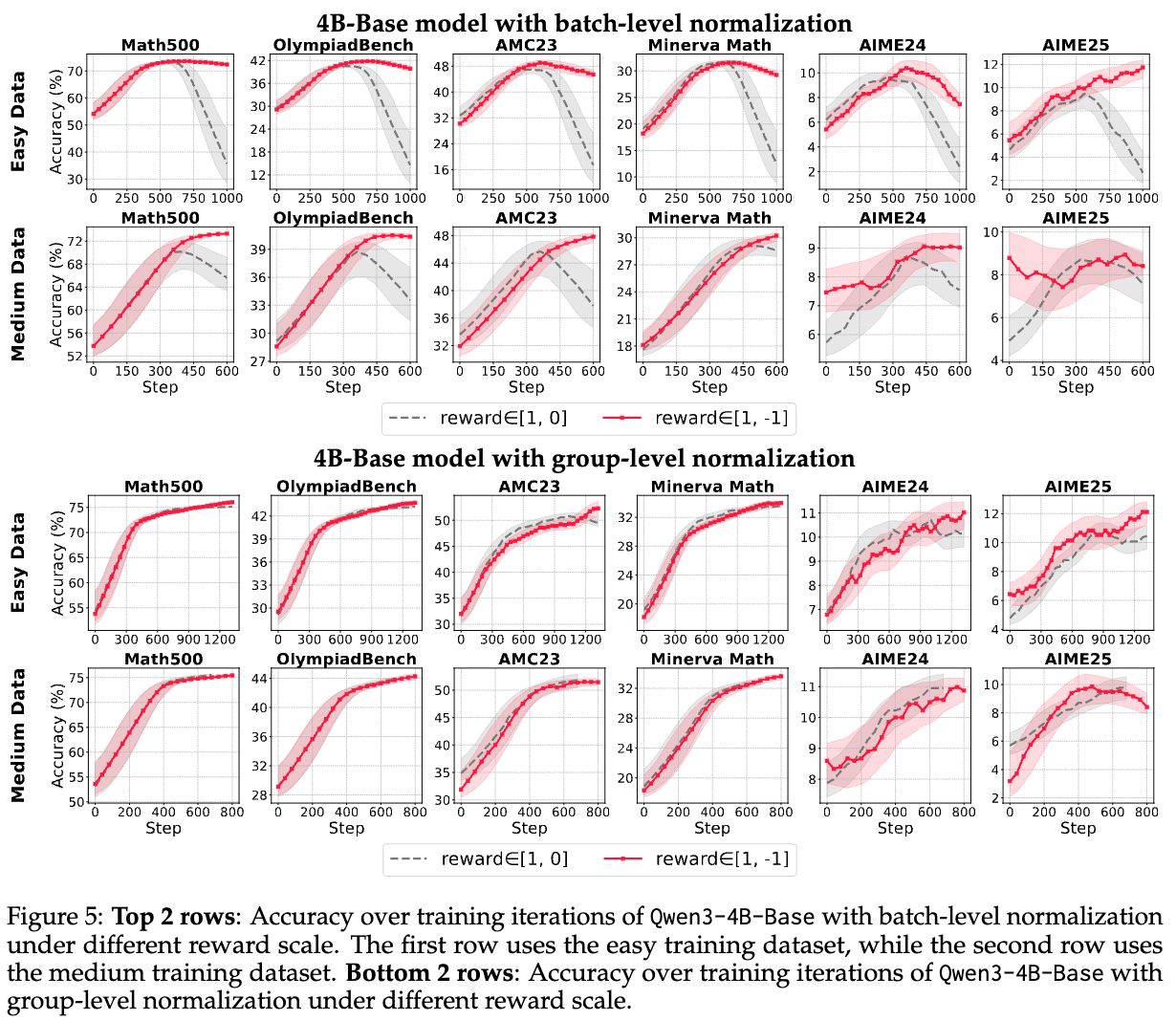
这个实验有力地证明了优势归一化技术对奖励机制的敏感性。组级别归一化因为它只在prompt内部进行比较,所以更加鲁棒。而批次级别归一化虽然在奖励信号强且分布均衡时可能有效,但在稀疏奖励下风险很高。
4.1.2 标准差项在归一化中的作用
Takeaway 2: 当奖励分布高度集中时(例如,在简单的训练数据上),移除标准差项可以增强模型训练的稳定性和有效性。
上一个实验引发了一个新问题:是什么导致了这种敏感性?一个合理的猜测是标准差项。当一个组或一个批次内的响应奖励高度相似时(例如,在简单任务上,模型很快学会全部答对),标准差会变得非常小。此时,用一个极小的标准差去做除法,会导致归一化后的优势值被过度放大,引起梯度爆炸,破坏训练稳定性。这类似于Dr. GRPO论文中提到的“难度偏差(difficulty bias)”现象。
为了验证这个猜想,作者进行了一项消融实验,比较了包含标准差的归一化和只减去均值的归一化(即 )。
-
在简单数据上: -
训练初期,奖励的标准差迅速下降到一个很低的水平。 -
此时,移除标准差的归一化方法(仅减去均值)表现出了明显更优的性能和稳定性。而包含标准差的方法,由于优势被放大,训练过程非常不稳定。
-
-
在困难数据上: -
奖励的标准差在整个训练过程中都维持在较高水平。 -
此时,两种归一化方法(包含或不含标准差)的性能差异不大,训练都比较稳定。
-
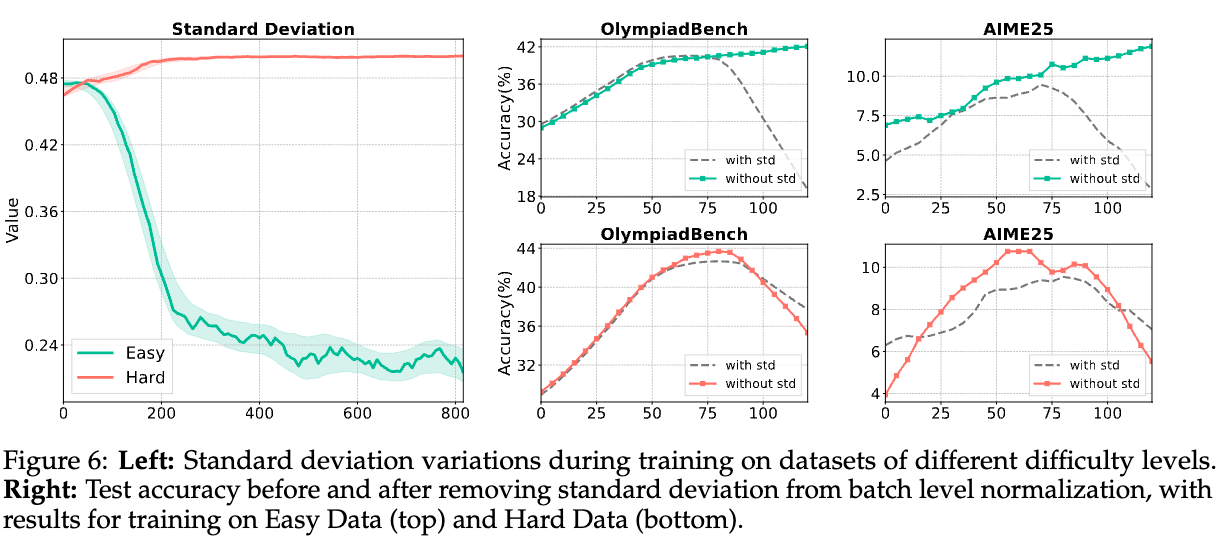
这个实验清晰地揭示了标准差项在归一化中的关键作用,并给出了明确的实践指导:在任务简单、奖励信号集中的场景下,考虑去掉标准差项,只做中心化处理,可能会获得更稳定的训练效果。
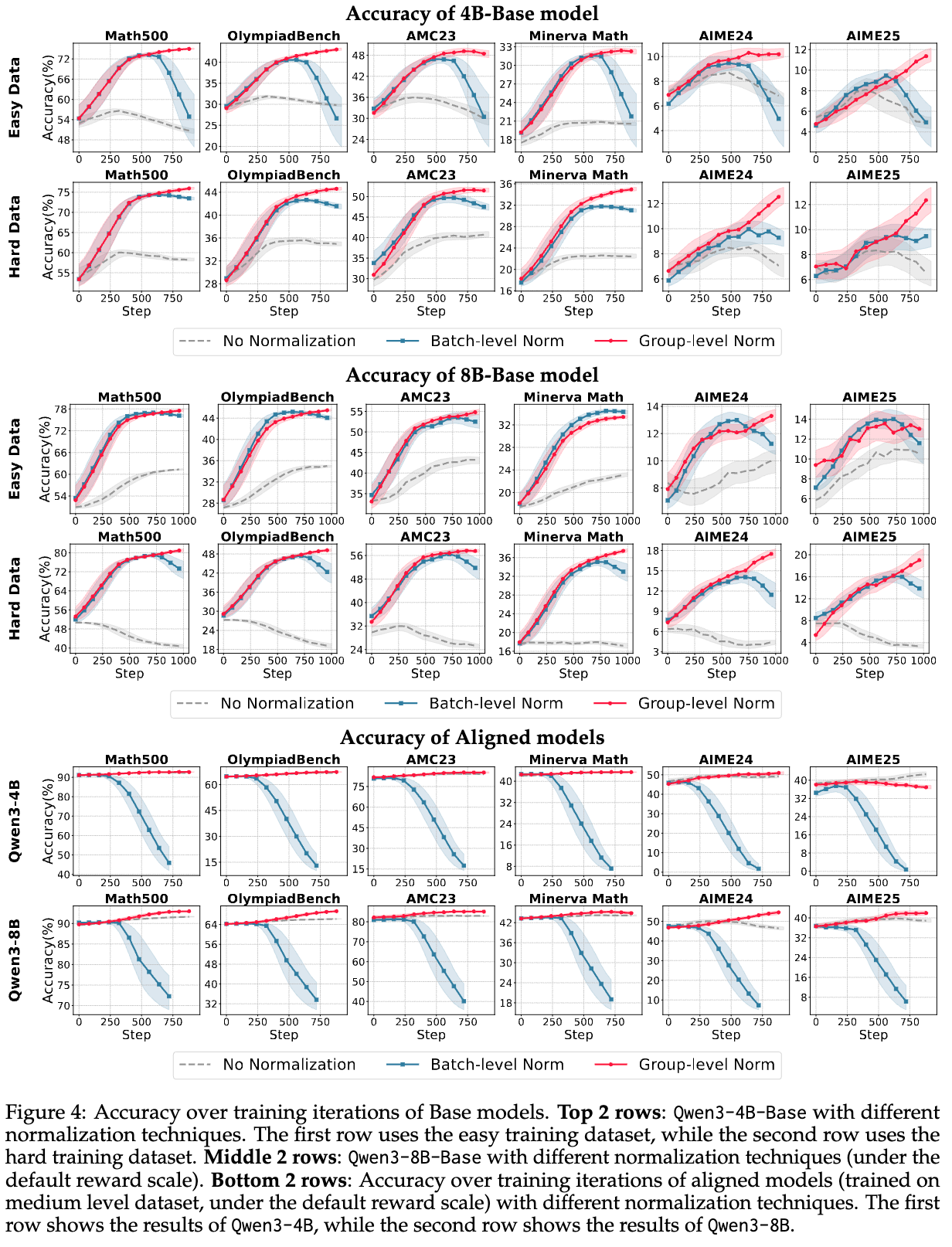
4.1.3 重构一个鲁棒的归一化技术
Takeaway 3: 在局部(组)级别计算均值,并在全局(批次)级别计算标准差,可以实现更鲁棒的奖励重塑。
综合前两个实验的结论,作者提出了一个最终的问题:是否存在一种更鲁棒、更有效的均值和标准差组合方式?他们尝试了两种计算标准差的方法,都搭配稳定的组级别均值:
-
局部标准差(Local std):即标准的组级别归一化。 -
全局标准差(Global std):均值在组内计算,但标准差在整个批次上计算。
实验结果(如下图7所示)明确显示,全局标准差(Global std)的方法表现出了明显的优势。作者认为,这是因为批次级别的标准差提供了更强的归一化效果,有效减小了梯度的大小,从而防止了策略的过度更新。这种方法更适应稀疏奖励和粗粒度优势拟合的场景,带来了更稳定和鲁棒的学习行为。
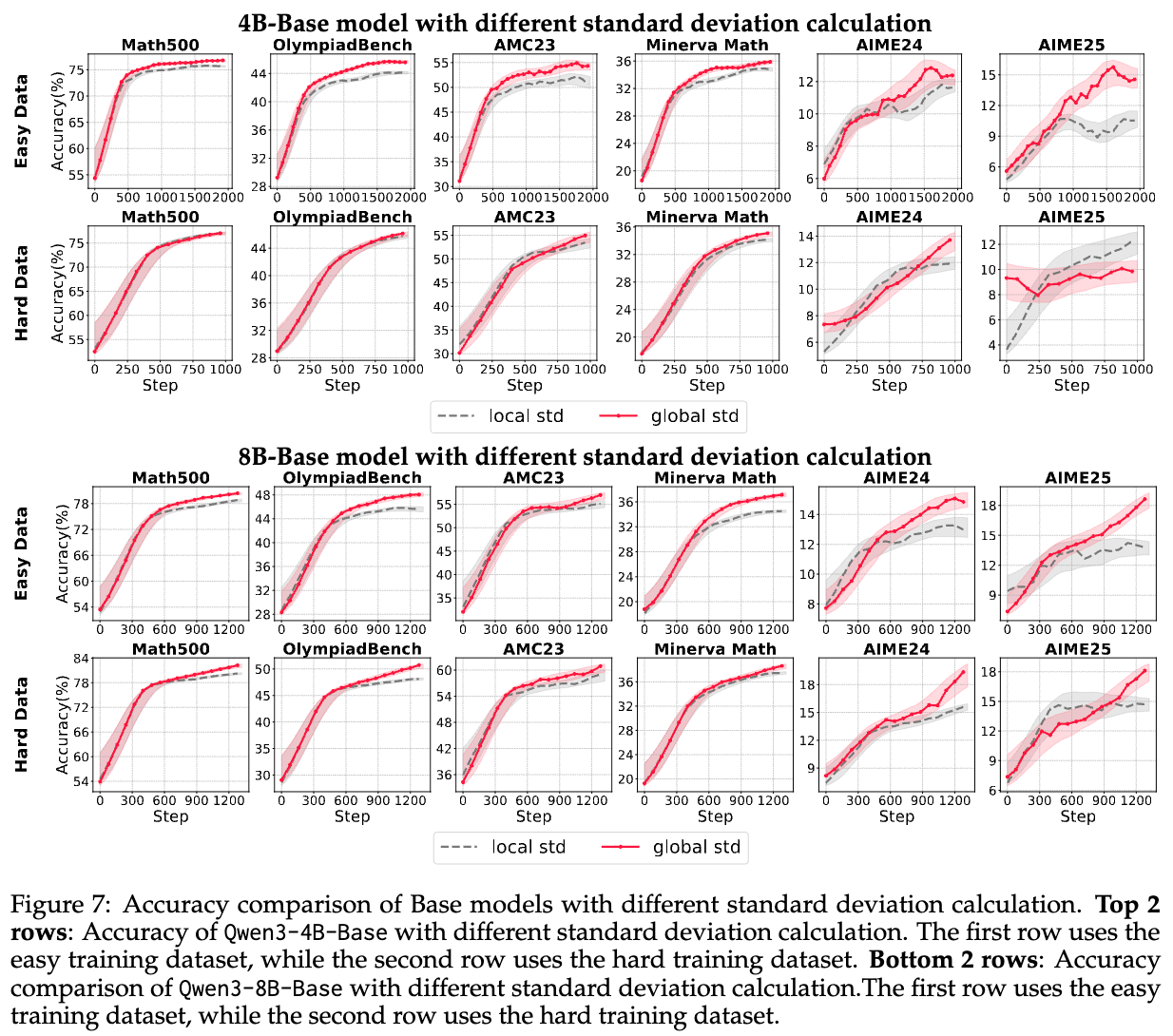
这一发现与Hu等人(2025)的观点不谋而合,即批次级别的归一化,或者在某些场景下“减去局部均值,除以全局标准差”,是一种更优的实践。
4.2 裁剪 (Clipping):探索与稳定的平衡艺术
PPO中的裁剪机制是保证训练稳定的核心,但它也可能带来一个严重问题:熵坍塌(entropy collapse)。它会过度抑制低概率令牌(token)的探索,导致模型的生成策略变得单一和确定性,缺乏多样性。这在需要创新性思维的复杂推理任务中是致命的。
为了解决这个问题,DAPO等工作引入了Clip-Higher机制,即放宽PPO裁剪范围的上限(),给低概率、但可能带来高回报的token更大的探索空间。其形式化表示为:
然而,这个 该如何设置?在什么场景下应该使用Clip-Higher?这些问题一直缺乏深入分析。
4.2.1 Clip-Higher的适用场景
Takeaway 4: 对于基础推理能力更强的模型(如Aligned模型),提高裁剪上限参数更可能促进对更优解路径的探索。
作者通过实验发现,Clip-Higher的效果是模型依赖(model-dependent)的。
-
对于Base模型:提高裁剪上限几乎没有带来熵的改善,甚至损害了最终性能。这是因为Base模型本身的策略表达能力有限,策略更新的偏离度很小(clipping rate ≈ 0.003),即使放宽上限,它也难以探索到新的高奖励路径。
-
对于Aligned模型:结果截然不同。提高裁剪上限显著减缓了熵的下降速度,并带来了下游评估指标的持续提升。
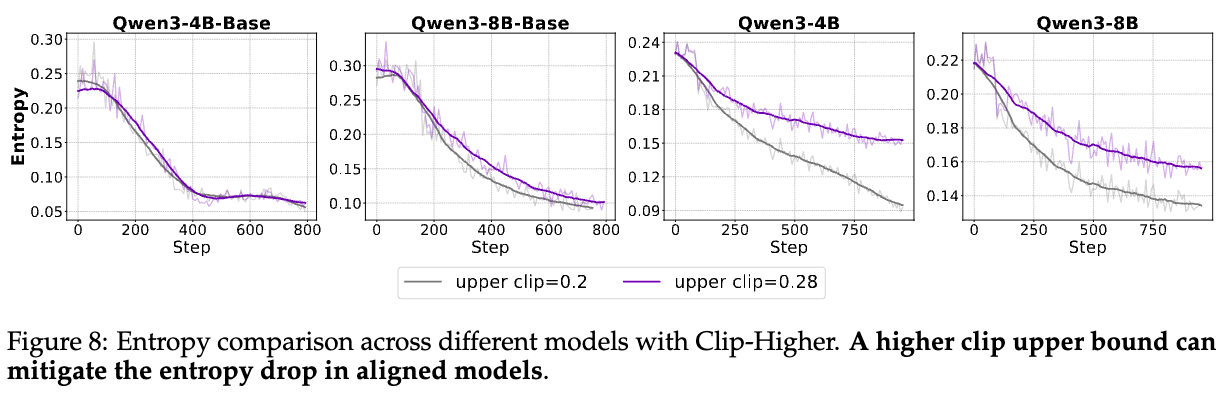
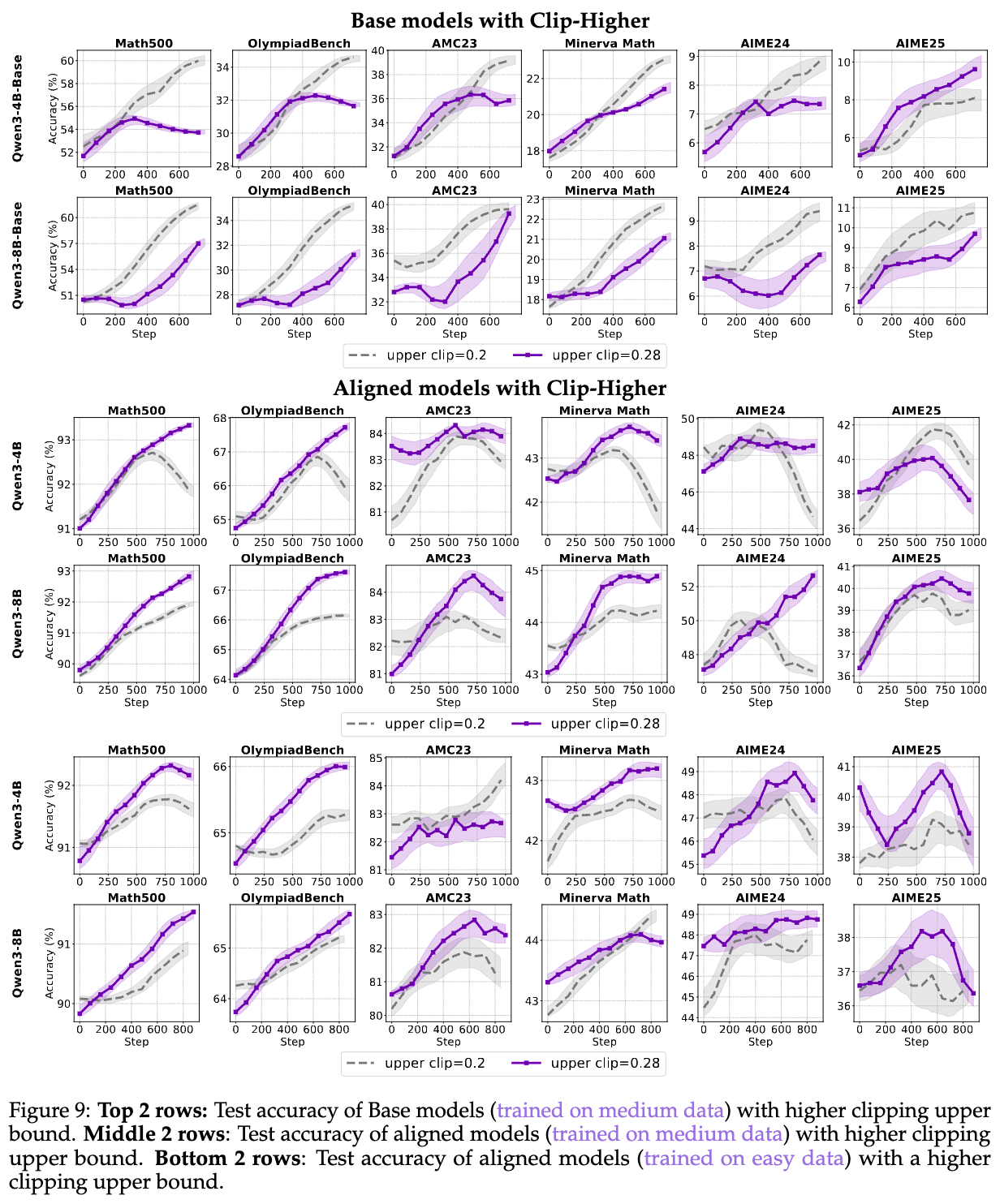
这种差异的根源在于模型的初始能力。Aligned模型已经具备了较好的推理和泛化能力,但其初始策略可能仍然存在一些“偏好”,导致某些关键的推理步骤(token)概率较低。如下图10所示,与Base模型相比,Aligned模型在初始阶段具有高概率的“首选”token非常少。提高裁剪上限,可以有效弥合这些关键token与高概率token之间的差距,缓解熵坍塌,促进更多样化的动作采样,从而找到更优的解法。
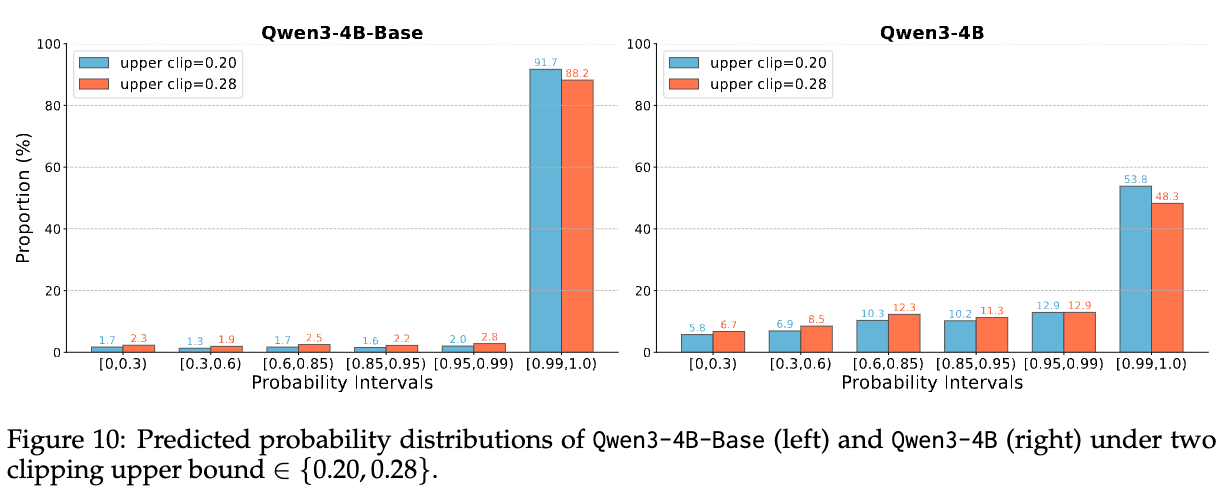
4.2.2 从语言学角度分析Clip-Higher的有效性
Takeaway 5: 传统裁剪可能限制模型生成创新性推理结构的能力。Clip-Higher允许模型探索更广泛的话语推理结构。
为了更深入地理解Clip-Higher的机制,作者从令牌级别的语言学角度进行了分析。
-
当裁剪上限较低时(如传统的0.2),被裁剪得最频繁的往往是连接性词汇,如 "therefore", "if", "but" 等。这些词汇通常出现在句首,标志着推理方向的转变。PPO的优化机制会积极地抑制这些引入新方向的词汇,以保证稳定性,但这也限制了模型生成多样化论证结构的能力。
-
当裁剪上限提高到0.28时,被裁剪的重点从连接词转向了高频的功能性词汇,如 "is", "the", "a" 等。这些词汇在句子中普遍存在,上下文依赖性较弱,其概率估计对新旧策略的差异更敏感。
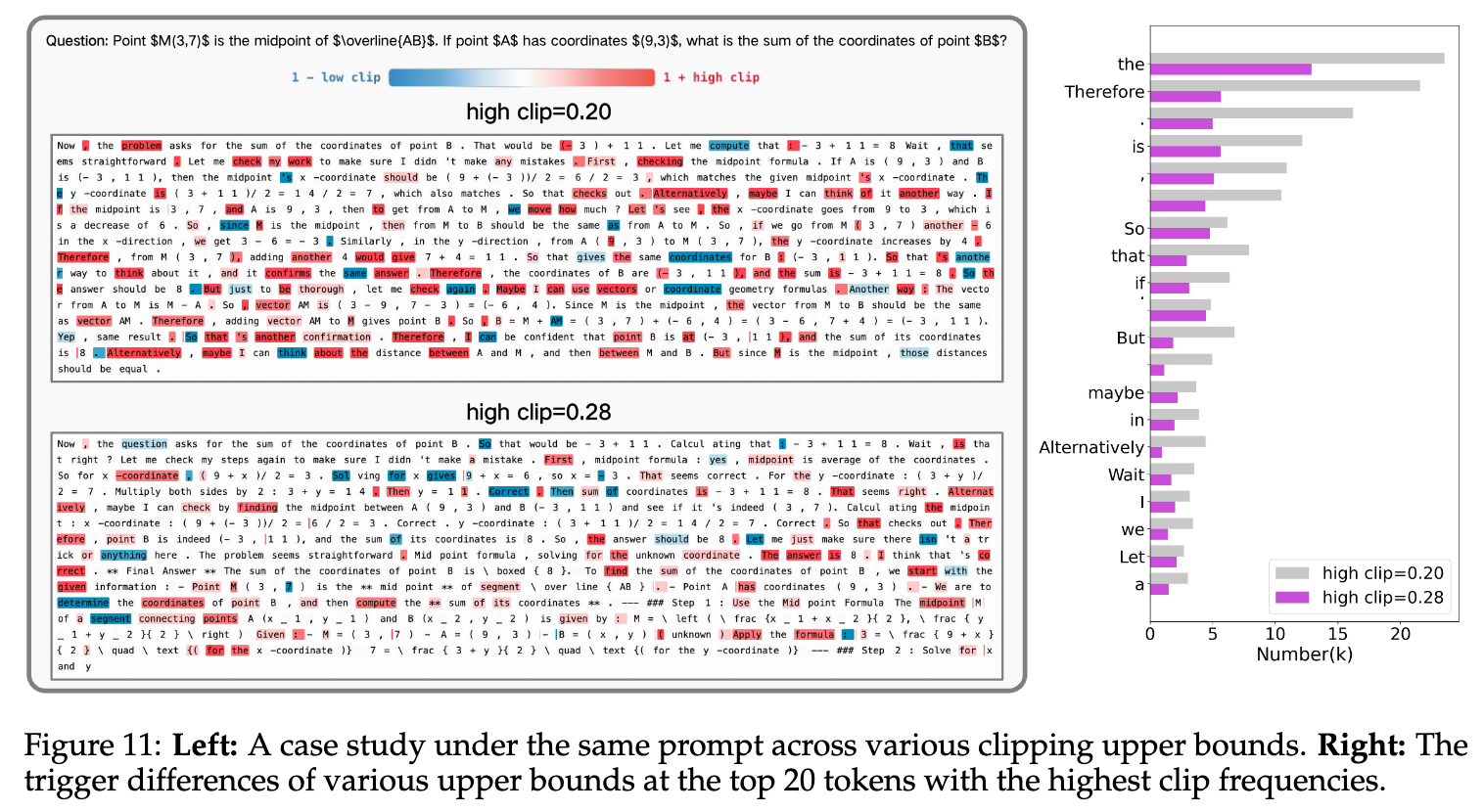
这种转变允许模型在话语结构层面(discourse level)进行更广泛的探索,生成更多样的推理路径,而对核心句子结构的稳定性影响较小。
4.2.3 如何设置优势裁剪的上限?
Takeaway 6: 在小尺寸模型上,性能与裁剪上限之间似乎存在一种“缩放定律(scaling law)”,但在大模型上则不然。
既然Clip-Higher有效,那么上限值()到底设为多少最合适呢?目前大多数工作都直接沿用了DAPO中0.28的默认值。作者认为,不同模型对此参数的偏好应该不同。
为此,他们进行了一系列超参数搜索实验,在0.2到0.32的范围内探索裁剪上限。
-
对于小模型(4B):随着裁剪上限的增加,模型性能也随之逐步提升,在0.32时达到最佳。这呈现出一种清晰的“缩放定律”。
-
对于大模型(8B):性能的提升并非单调的。当上限设置为0.28时,性能最为突出,而继续增大上限反而可能导致性能下降。
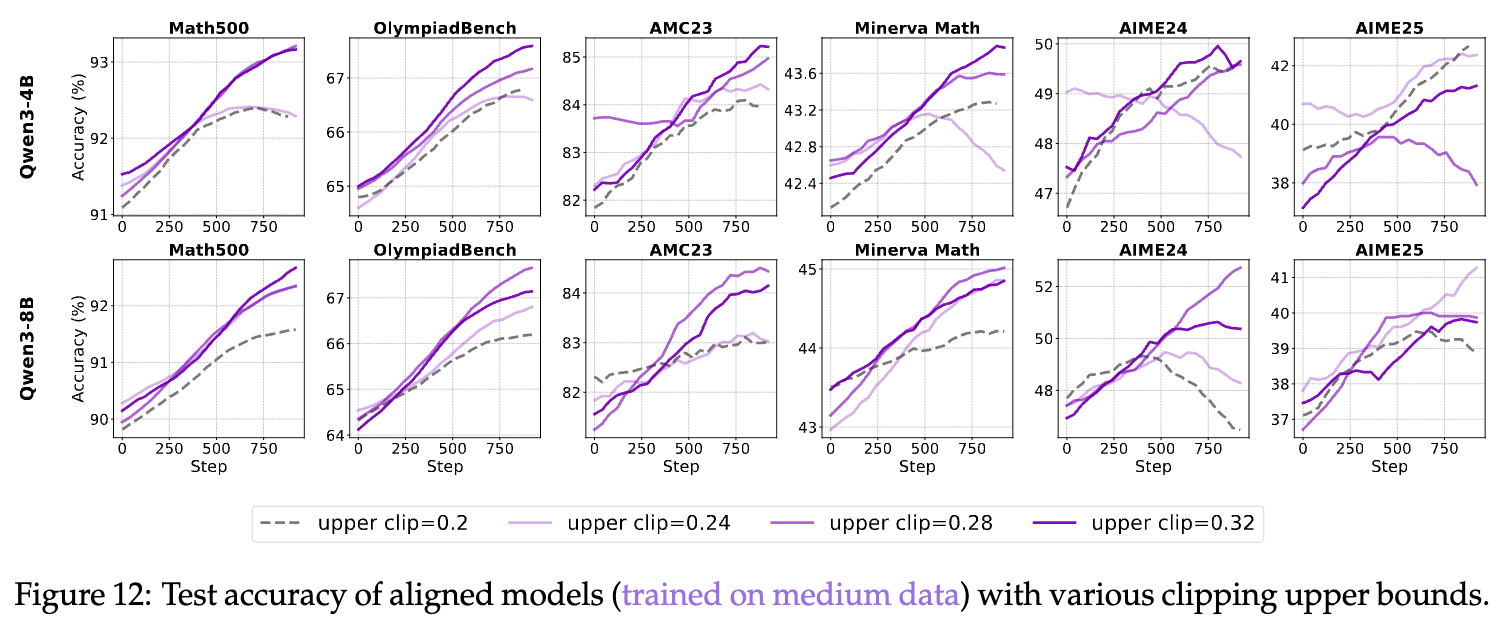
这个发现为从业者提供了宝贵的实践建议:对于小模型,可以大胆尝试更高的裁剪上限;而对于大模型,0.28可能是一个更优的甜点值(sweet spot)。
4.3 损失聚合 (Loss Aggregation):令牌级 vs. 序列级
损失聚合策略决定了每个样本或每个token对总梯度的贡献。主流方法有两种:
-
序列级聚合(Sequence-level):先计算每个响应序列的平均损失,再对整个批次的序列损失求平均。这是GRPO采用的方法。这种方法给予每个响应同等的权重,无论其长短。 -
令牌级聚合(Token-level):将批次中所有响应的所有token的损失加起来,再除以总token数。这是DAPO采用的方法。这种方法保证了每个token对总梯度的贡献是相等的。
Yu等人(2025)指出,序列级聚合存在一个缺陷:它会降低长响应中每个token的影响力,可能导致模型偏向于生成更短的答案,并且无法充分从长而复杂的正确推理中学习。
4.3.1 令牌级损失聚合是否适用于所有场景?
Takeaway 7: 与序列级计算相比,令牌级损失在Base模型上更有效,但在Instruct模型上改进有限。
作者在Qwen3-8B的Base和Aligned版本上,对这两种聚合策略进行了系统性比较。
-
对于Base模型:令牌级损失聚合在收敛速度、峰值精度和鲁棒性上都全面优于序列级聚合,尤其是在困难数据集上。这验证了令牌级聚合能确保每个token(尤其是长序列中的token)都得到平等优化的猜想。
-
对于Aligned模型:结果再次反转。序列级聚合在大多数数据集和设置下,都比令牌级聚合表现得更好。
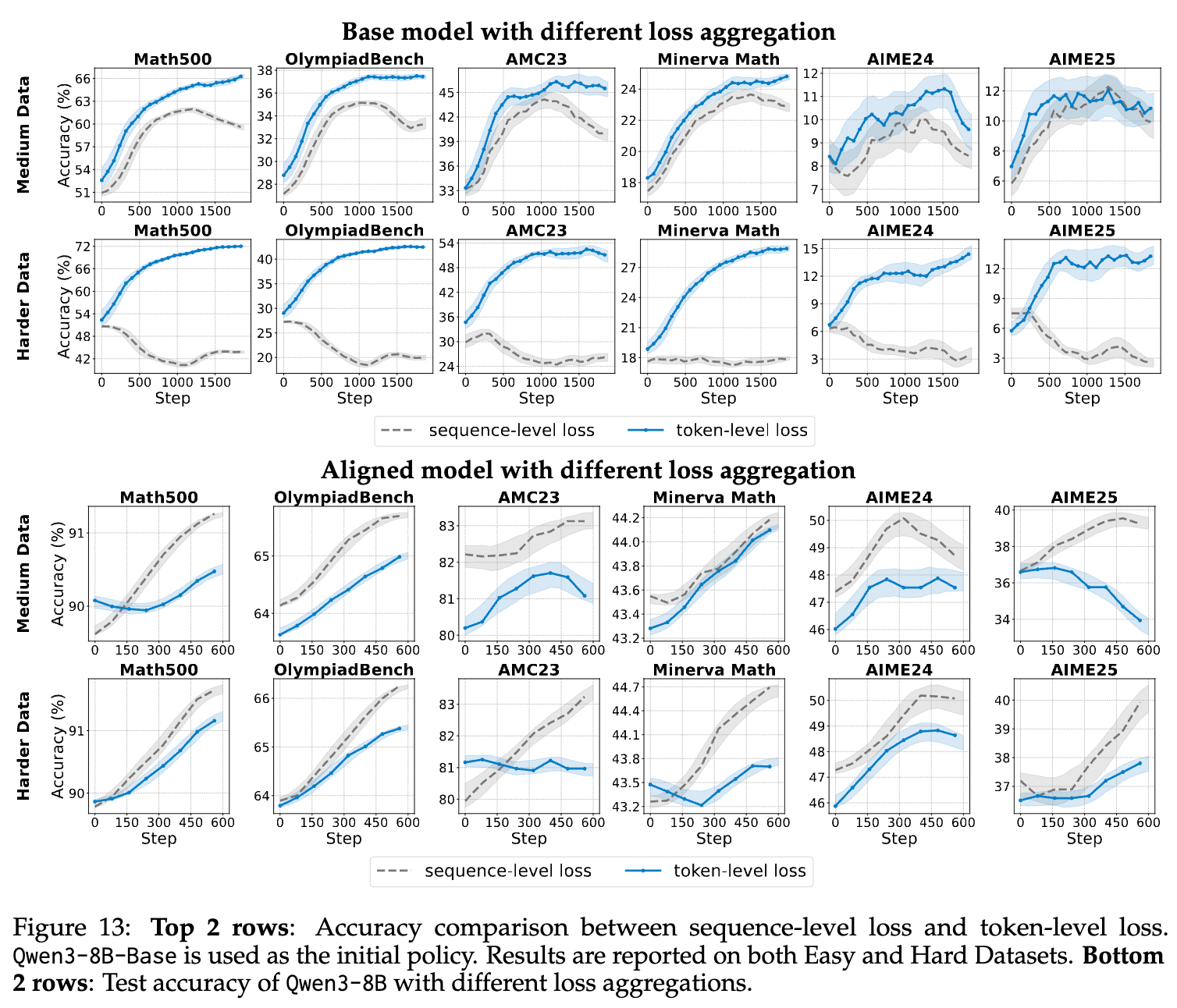
为什么会这样?作者分析,Aligned模型本身已经具备了强大而稳定的推理能力,强制让每个token的梯度贡献均等化,反而可能是非必要甚至有害的。在这种情况下,序列级聚合更好地保留了高质量、对齐输出的整体结构和一致性。
这个发现再次强调了“没有免费的午餐”这一原则。最优的技术选择,深度依赖于你的初始模型状态。对于从零开始训练的Base模型,令牌级聚合是更好的选择;而对于已经良好对齐的Instruct模型,序列级聚合可能更优。
4.4 过长过滤 (Overlong Filtering):效率与性能的权衡
在训练LLM时,为了效率和计算成本,通常会设置一个最大生成长度。但对于复杂的推理任务,这个截断操作可能会在模型推理到一半时就强行终止,导致一个原本可能正确的推理过程被错误地标记为负样本。这种噪声会污染训练信号,降低学习效率。
为了解决这个问题,Yu等人(2025)引入了过长过滤(overlong filtering)技术,即直接屏蔽掉那些因为达到最大长度而被截断的样本的奖励信号。
4.4.1 何时应该使用过长过滤?
Takeaway 8: 过长过滤对长尾推理任务的效果有限;然而,它可以提高中短长度推理任务的准确性和响应清晰度。
尽管近期的工作验证了过长过滤的好处,但过滤阈值(即最大长度)如何影响该技术,仍不清楚。作者使用了Qwen3-8B模型,比较了不同最大生成长度(8k, 16k, 20k)下的训练动态。
实验结果(如下图14)显示:
-
当过滤阈值较短(如8k)时,使用过长过滤带来了显著的好处。 -
但随着阈值增长到20k,过长过滤带来的收益就变得微乎其微。
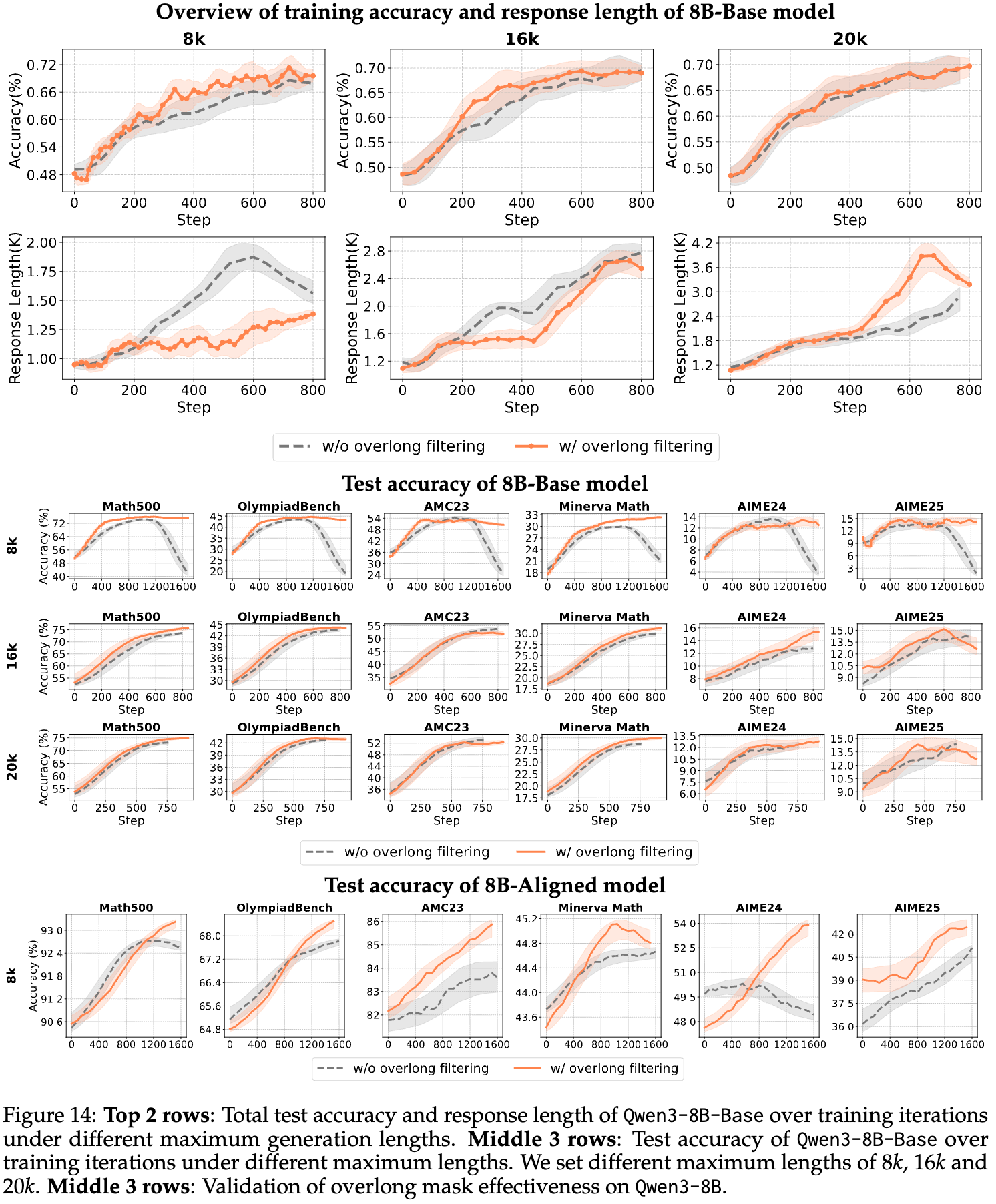
通过检查响应长度,作者发现了其中的奥秘。当阈值设为20k时,使用了过长过滤的模型倾向于生成比不使用该技术的模型更长的响应。反之,8k的短阈值则会促使模型生成更短的响应。
进一步分析被过滤掉的样本(如下图15),发现在20k的设置下,被过滤的样本大多是由于重复或无法终止的退化生成(degenerate generation)导致的,这些本就是对学习贡献不大的“负”样本。而在RL训练中,模型“重复但无法正常终止”的比例会逐渐增加,这表明模型学习正确建模EOS(end-of-sequence)标记的能力在退化。引入过长过滤机制后,这种异常样本的比例显著下降。
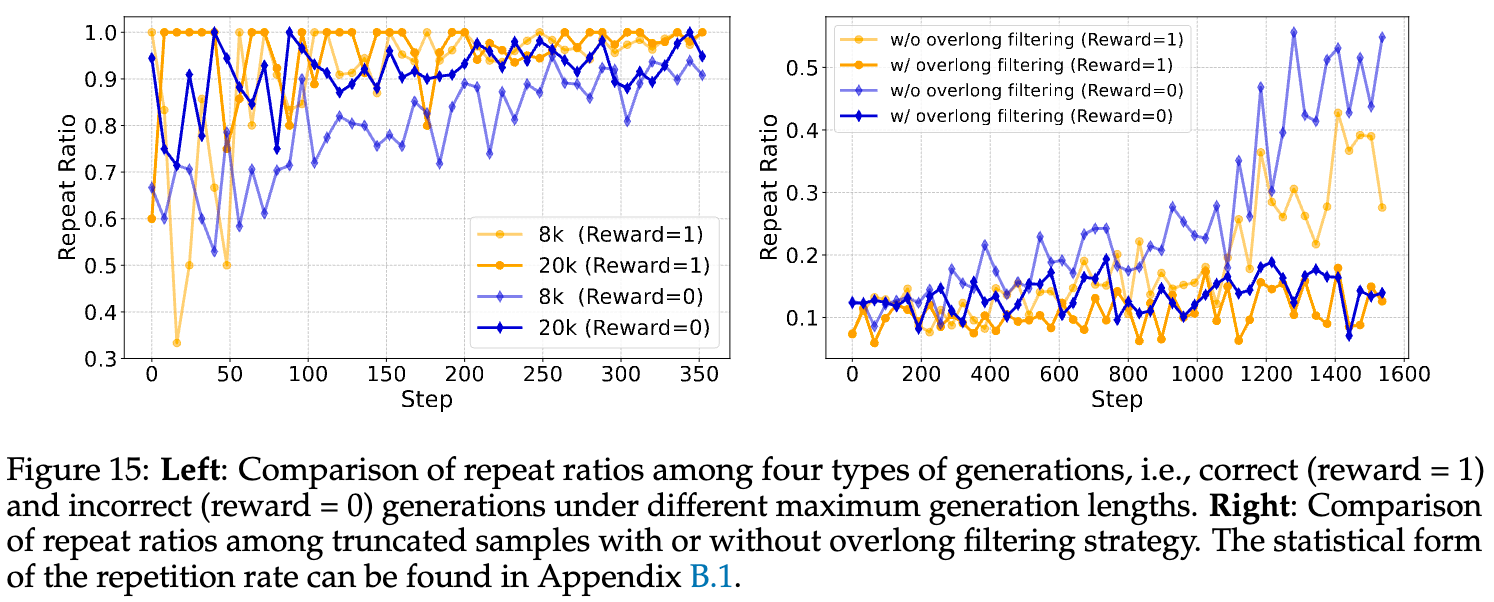
这表明,过长过滤机制的核心作用,是帮助模型更准确地区分“已完成的生成”和“被截断的生成”,避免了对未完成推理的错误惩罚。这个机制可能解锁了策略模型准确建模终止行为的能力。
因此,对于需要长链推理的任务,简单地增加长度限制可能不是最佳选择,过长过滤的效果会减弱。但对于中短长度的推理任务,它能有效提升性能和生成质量。
第五章:一个简单的组合:Lite PPO
在前面章节深入的机制分析和实证评估的基础上,作者为非对齐模型(non-aligned models)提炼出两条关键的技术指南:
-
对于中小型非对齐模型(如4B-Base和8B-Base),最能显著提升性能的技术是优势归一化(Advantage Normalization)。具体而言,是“组级别均值 + 批次级别标准差”的组合,它能将稀疏的奖励信号塑造为更鲁棒的指导信号。(来自 4.1.3) -
令牌级损失聚合(Token-level Loss Aggregation) 是另一个对Base模型架构非常有效的技术。(来自 4.3.1)
基于这两个发现,作者提出了一个经验驱动的假设:既然这两种技术各自都表现优越,那么它们的协同组合应该能在策略优化中展现出强大的鲁棒性。
于是,Lite PPO 诞生了。
作者将这两种技术集成到一个不带价值网络(critic-free)、使用原始PPO损失的非对齐模型中。这个组合极其简约,却威力惊人。
如下图16所示,作者将Lite PPO与两个技术更“重”的算法进行了对比:
-
DAPO:集成了组级归一化、Clip-Higher、过长奖励重塑、令牌级损失、动态采样等多种技术。 -
GRPO:强大且被广泛使用的RL4LLM算法。
实验结果令人振奋:
-
在小模型(4B-Base)上,Lite PPO表现出稳定的上升趋势,而其他策略在达到峰值后迅速崩溃。这种显著优势源于Lite PPO的归一化技术(Takeaway 3),它有效对抗了在奖励不均衡(简单和困难数据混合)的数据集上产生的干扰。 -
在更大规模的Base模型(8B-Base)上,Lite PPO同样表现出色,尤其是在具有内在长尾生成能力的困难数据集上。这种提升源于Lite PPO: -
放弃了过长过滤(这通常会限制小模型生成复杂长尾输出的能力,见Takeaway 8)。 -
转向了令牌级损失聚合(这对Base模型更有效,见Takeaway 7)。
-
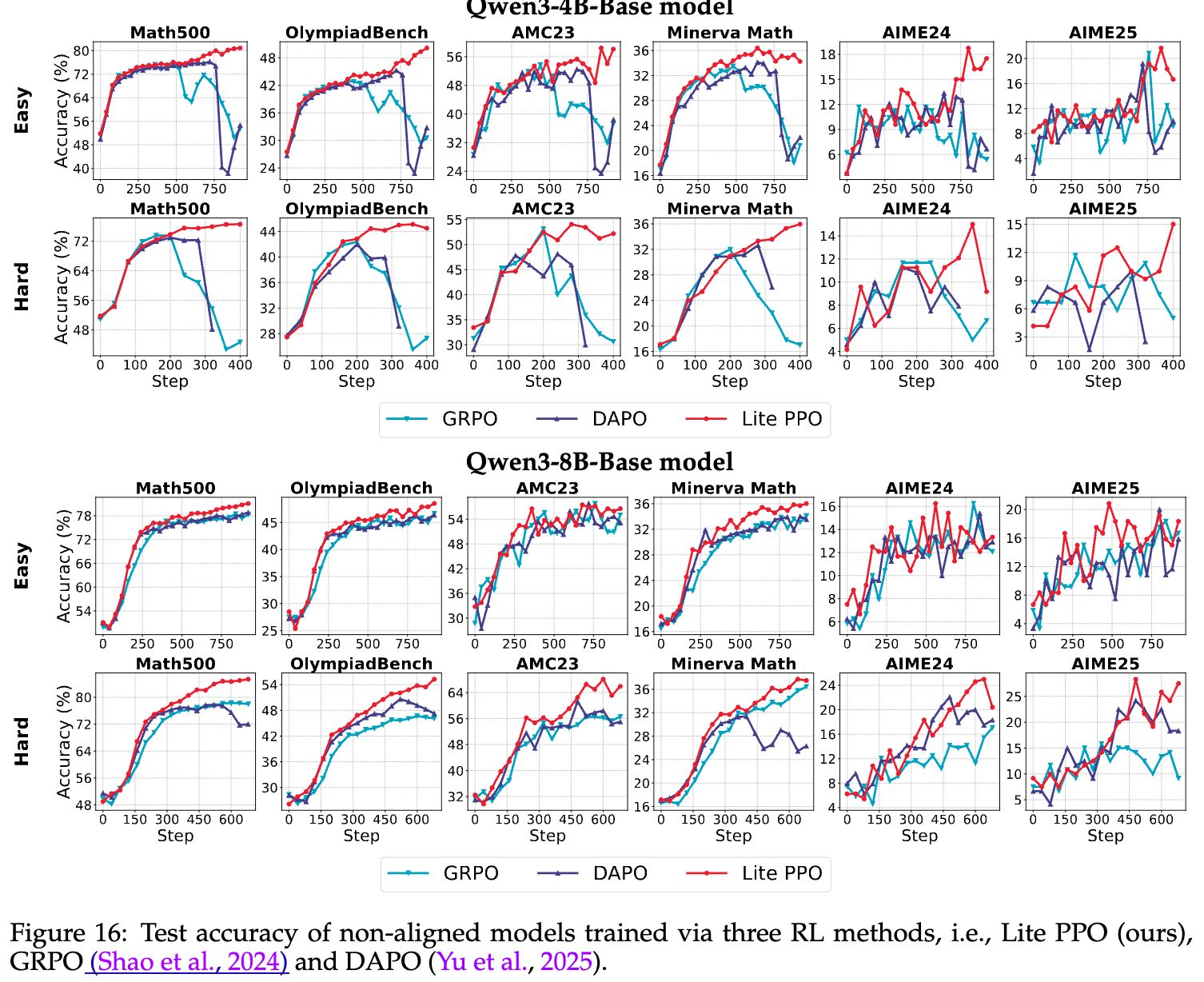
Lite PPO的成功,有力地挑战了当前RL4LLM领域一种“过度工程化(over-engineering)”的趋势,即试图通过堆砌大量复杂的组件来提升性能。它雄辩地证明了:简单可以胜过复杂(simplicity can outperform complexity)。通过深入理解核心技术的机制,并根据具体场景(如模型是否对齐)进行上下文自适应的选择,一个极简的组合就能取得SOTA(state-of-the-art)的效果。
往期文章: