我们知道 RL 在大模型应用的一个前提:模型必须已经具备以一定的概率,自主采样出有效的、有价值的推理路径的能力。强化学习的内在机制,更像是对模型现有能力的一种“概率重新分配”,而非“从无到有地创造”全新的解题思路。
能否找到一种更高效的方式来引导模型的探索,帮助它发现那些高质量但难以采样到的推理路径?
来自浙江大学和阿里的论文《RAVR: REFERENCE-ANSWER-GUIDED VARIATIONAL REASONING FOR LARGE LANGUAGE MODELS》中,提供了一个富有启发性的视角。他们的工作受到一个认知科学领域的洞察所启发:对于人类学习者来说,“为什么这是答案?” 往往是一个比 “答案是什么?” 更容易回答的问题。后者要求学习者在巨大的可能性空间中进行开放式的探索,认知负荷巨大;而前者则将问题转化为一个目标明确的“解释性重建”任务——学习者只需专注于回溯和构建连接已知问题和已知答案之间的逻辑链条。

-
论文标题:RAVR: REFERENCE-ANSWER-GUIDED VARIATIONAL REASONING FOR LARGE LANGUAGE MODELS -
论文链接:https://www.arxiv.org/pdf/2510.25206
作者发现,LLM 同样可以利用这种“逆向”思考的模式。通过在训练时向模型提供参考答案,可以有效地引导其生成高质量的推理路径。基于这一洞察,他们提出了 RAVR (Reference-Answer-guided Variational Reasoning) ,一个端到端的变分推理框架。它将“答案条件下的推理”视为一个变分代理,用来辅助和优化常规的“仅问题下的推理”,从而将那些原本难以解决的(intractable)问题,转化为模型可以有效学习的(learnable)问题。
1. Motivation
在深入技术细节之前,我们首先需要理解 RAVR 的核心立足点:为什么提供答案能显著提升模型生成高质量推理路径的概率?
作者通过一个动机实验直观地验证了这一想法。他们从 CrossThink-QA 数据集中挑选了 50 个难题,这些题目即使在启用思维链(thinking mode)的情况下,Qwen3-1.7B 模型尝试 8 次也无法正确解答。对于这些模型眼中的“不可解”问题,研究团队转换了提问方式:他们同时给出问题和正确答案,要求模型推导出一个能够连接二者的合理论证过程。
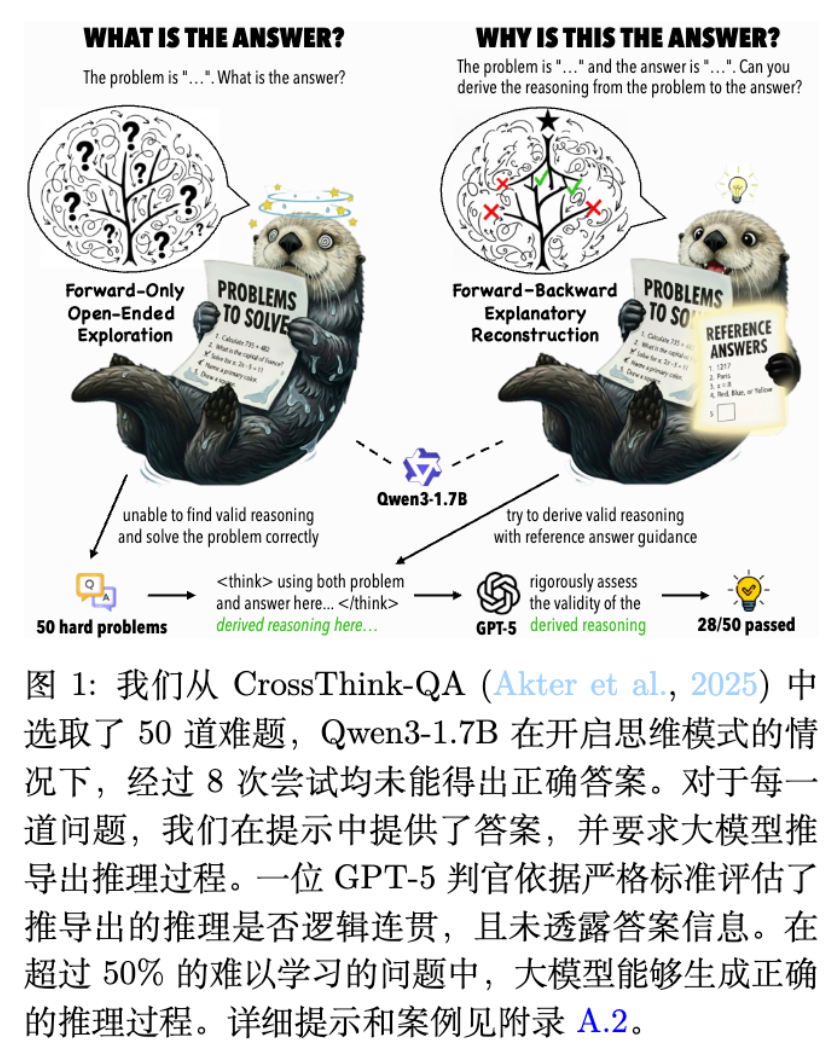
实验结果是清晰的。在超过 50% 的案例中,原先完全无法解决问题的模型,在被“剧透”答案后,成功生成了逻辑连贯、有效的推理过程(该过程由更强大的 GPT-5 模型进行严格评估)。这表明,参考答案扮演了一个强大的“引导者”角色,帮助模型校准探索方向,避免了在错误路径上的无效尝试。
为了从理论上支撑这一观察,论文进行了一番严谨的数学形式化。
1.1 推理路径的“效用”
首先,需要一个可计算的指标来衡量一条推理路径 的“好坏”。一个自然的选择是,看这条路径在多大程度上能引出正确的答案 。因此,作者将推理路径 的效用分(utility score) 定义为模型在给定问题 和推理路径 的条件下,生成正确答案 的条件概率:
其中 代表参数为 的 LLM。这个效用分越高,说明推理路径 越“有效”。
相应地,一个模型在问题 上的整体推理能力,可以定义为所有可能推理路径的效用分的期望值:
根据全概率公式,这个值实际上就等于模型在只给定问题 的情况下,直接预测出正确答案的概率,即 。
1.2 条件化如何放大优质推理
有了效用的定义,接下来的关键是证明“以答案 为条件”能够放大高分( 高)推理路径的采样概率。
根据贝叶斯法则和全概率公式,对于任意一条特定的推理路径 ,其在给定问题 和答案 下的后验概率 可以表示为:
这个公式是整个理论的核心。它清晰地揭示了条件化的作用机制:后验概率 是对先验概率 的一次“效用偏向性”的加权(size-biased reweighting)。
-
如果一条路径 的效用分 高于平均水平 ,那么它的采样概率在后验分布中会被放大()。 -
反之,如果一条路径的效用分低于平均水平,它的采样概率则会被压缩。
这意味着,从答案条件分布 中进行采样,天然地就更容易采样到那些能导向正确答案的高质量推理路径。
论文进一步将这个结论推广到推理路径的任意子集 。对于一个高于平均水平的推理路径集合 (其中 ),条件化对其采样概率的放大效应是显著的:
这证明了条件化确实系统性地增加了采样到“好”推理路径的概率。
不仅如此,从整体分布来看,后验分布的期望效用也得到了提升。基于公式 6,可以推导出:
这个结果表明,后验分布的平均推理质量至少不低于先验分布,只要推理路径的效用存在方差(即有好有坏),后验的平均质量就一定高于先验。
综上,无论从个体路径、路径集合还是整体分布的角度看,答案条件分布 都是一个用于探索高质量推理路径的、理论上可靠的目标分布。
2. RAVR
理论上的完美目标,在实践中却面临一个直接的挑战:在模型推理(inference)或实际应用时,我们并不知道正确答案 。模型需要具备仅根据问题 就能独立进行高质量推理的能力。
因此,任务的核心就变成了:如何将从“老师”(答案条件分布)那里学到的知识,有效地迁移给“学生”(仅问题条件分布)?
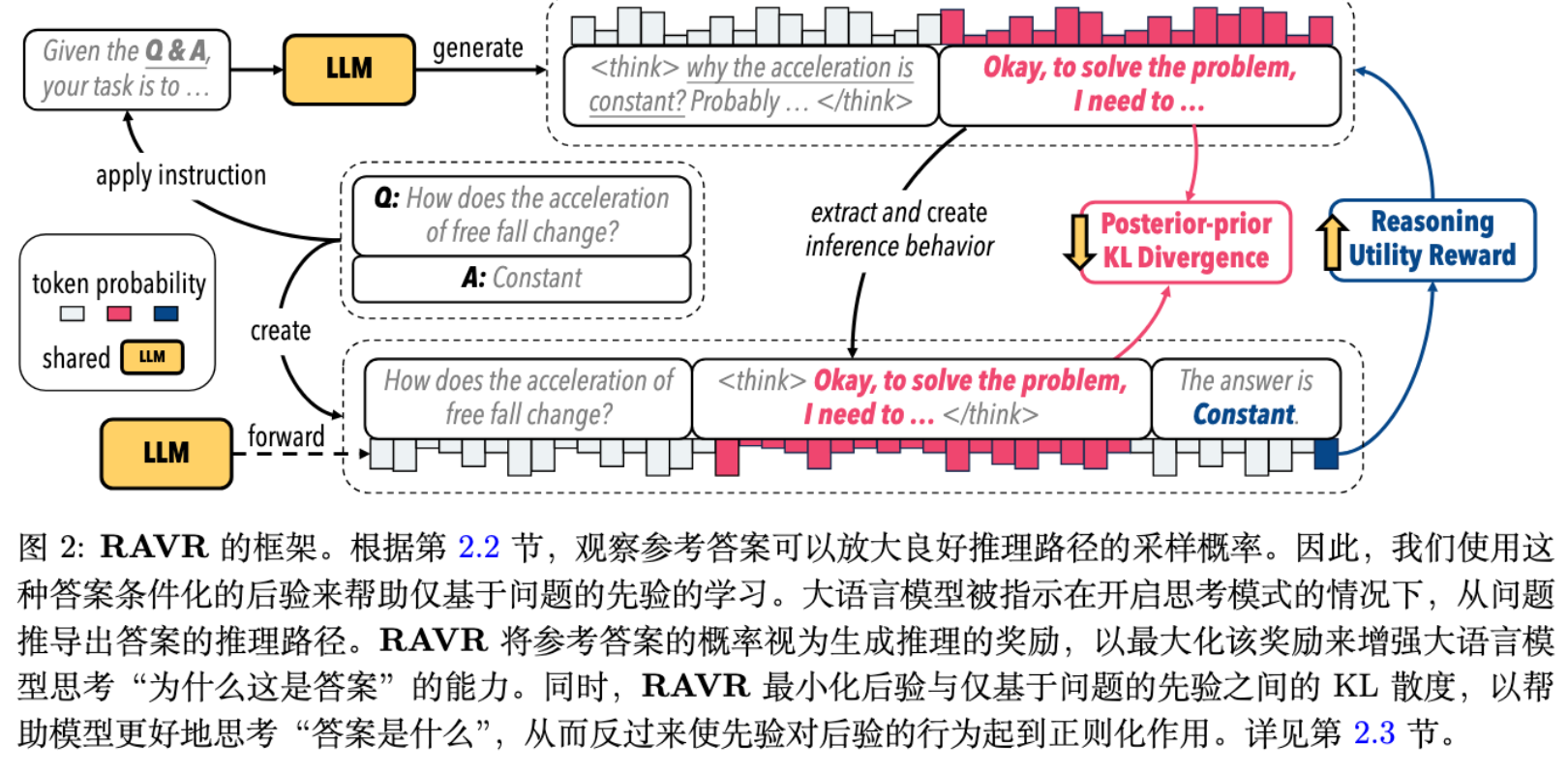
RAVR 框架运用了变分推断(Variational Inference) 的思想来解决这个问题。它将模型在常规场景下的推理分布 视为 先验(prior),而将由答案引导的推理分布 视为一个 后验(posterior) 的近似。学习的目标,就是让这个先验分布尽可能地向表现更优的后验分布靠拢。
2.1 变分优化目标(ELBO)
训练的原始目标是最大化在先验分布下的期望效用,即最大化 。对其取对数,即 ,然后引入后验分布 并应用琴生不等式(Jensen's inequality),可以推导出该目标的证据下界(Evidence Lower Bound, ELBO):
这个 ELBO 目标由两部分构成,解释了 RAVR 的学习机制:
-
期望效用项:。这一项通过优化从后验分布中采样的推理路径 ,来最大化其导出正确答案 的对数似然。这相当于一个标准的强化学习目标,奖励信号是 ,驱动模型在“有答案指导”的模式下,学习如何进行有效的“解释性重建”。
-
KL 散度项:。这一项是正则化项,它要求先验分布 逼近后验分布 。这正是知识迁移发生的地方——它将后验分布中发现的优质推理模式“蒸馏”回先验分布中,从而提升模型在没有答案时的独立推理能力。同时,它也对后验起到了正则化作用,防止其坍缩到一些与先验差异过大的、非自然的推理路径上。
2.2 稳定训练的策略设计
直接优化上述 ELBO 目标仍然可能面临训练不稳定的问题。为此,RAVR 引入了一系列策略来提升鲁棒性和效率。
1. 效用基线(Utility Baseline)
在强化学习中,引入一个基线(baseline)来中心化奖励信号是降低方差的常用技巧。RAVR 创新性地使用了先验分布的期望效用作为基线。改进后的奖励信号 定义为:
这个设计十分直观:只有当后验采样出的路径 所带来的效用,超过了模型在无指导情况下的平均表现时,才会产生正的奖励信号。这使得学习信号更具信息量,模型会专注于学习那些真正带来“改进”的推理模式,而不是在“聊胜于无”的路径上浪费精力。
2. 基于奖励的 KL 权重
为了让学习过程更加智能,RAVR 为 KL 散度项引入了基于奖励的权重:
这个设计的动机在于:当模型已经很好地掌握了一个问题的解法时(即 趋近于 0,后验相比先验没有带来多少提升),我们就不再需要强行让先验去模仿后验了。通过奖励加权,模型可以自主地从那些效用高于自身当前水平的路径中学习,避免了不必要的知识蒸馏,让学习过程更加聚焦。
3. 提示词工程(Prompt Engineering)
为了在同一个 LLM 中实现先验和后验两种不同的采样模式,RAVR 设计了两套不同的提示词模板。
-
先验提示词(Question-only):模拟常规的问答场景,要求模型先在 <think>标签内进行思考,然后给出最终答案。 -
后验提示词(Question and Answer):明确告知模型问题和参考答案,并要求它扮演一个正在“独立思考”的角色,生成一段第一人称的、自言自语式的独白(think-aloud monologue),来重构整个推理过程。这个“角色扮演”的设定,旨在弥合后验(通常是简洁的、目标导向的解释)与先验(通常是探索性的、包含回溯和修正的思考)之间的文体差异,使得 KL 散度的计算和知识迁移更加顺畅。

此外,在计算答案似然时,RAVR 使用了“The answer is ”这样的提示语,而不是简单地将 拼接在推理后面。这更符合自然语言的使用习惯,能让模型更好地进入一个生成答案的状态,从而得到更准确的概率估计。
结合以上策略,RAVR 的最终优化目标可以写作:
整个框架通过联合优化一个带有基线的强化学习目标和一个加权的 KL 正则化目标,实现了在参考答案的引导下,端到端地提升模型独立推理能力的目的。
3. 实验
RAVR 的效果如何?作者在通用推理和数学推理两大领域,进行了一系列详尽的实验。
3.1 实验设置
-
基础模型:Qwen3-1.7B。 -
训练数据:CrossThink-QA (一个涵盖 STEM、经济、社科等领域的通用推理数据集) 和 DeepMath-103K (一个专注于挑战性数学问题的数据集)。 -
评测基准: -
通用推理:GPQA-Diamond, MMLU-Pro。 -
数学推理:AIME24, AIME25, AMC23, Minerva。 -
通过这种交叉设置,可以同时评估模型的领域内(in-domain) 表现和跨领域泛化(out-of-domain) 能力。
-
-
基线方法:涵盖了当前主流的 RL 方法,包括: -
GRPO, DAPO (基于验证器反馈的奖励)。 -
VeriFree, RLPR (基于参考答案概率的奖励)。 -
同时,也对比了是否引入课程学习(curriculum learning)的策略。
-
3.2 实验结果

实验结果如表 1 所示:
-
在通用推理任务上:当使用 CrossThink-QA 数据集训练时,RAVR 在通用推理基准上取得了 48.39 的高分,优于所有基线方法。这证明了其在领域内学习的有效性。 -
在数学推理任务上:当使用 DeepMath 数据集训练时,RAVR 同样在数学基准上达到了 45.00 的最佳平均分。 -
强大的泛化能力:RAVR 的一个亮点是其跨领域泛化能力。在 CrossThink-QA(通用)上训练的模型,在数学评测集上的表现(42.92)超过了所有其他方法。反之,在 DeepMath(数学)上训练的模型,在通用评测集上的表现(45.05)同样领先。这说明 RAVR 学到的不仅仅是特定领域的解题技巧,更是可迁移的、更底层的推理能力。
3.3 推理行为分析:模型在“想”什么?
为了探究 RAVR 如何改变模型的“思维方式”,作者分析了模型在 <think> 标签内生成的文本中,特定话语标记词(discourse markers) 的使用频率。这些词汇(如 wait, therefore, but)被认为是认知过程的外部体现。
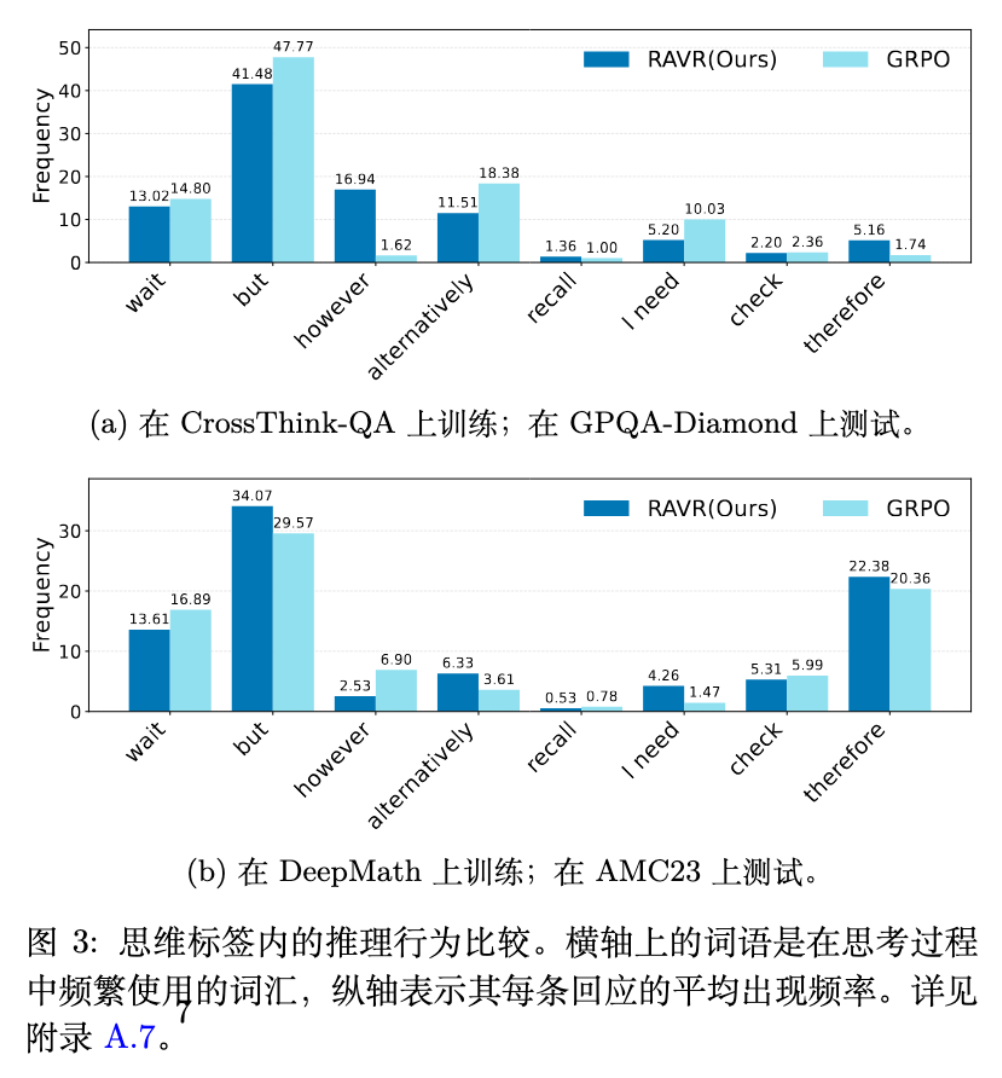
与基线方法 GRPO 相比,RAVR 训练出的模型展现出了一系列不同的推理行为特征:
-
更少的 wait:表明模型犹豫和迟疑减少。这与更强的解题能力相符,答案的引导使得推理路径更加直接,避免了不必要的过度思考。 -
更多的 therefore:表明模型更倾向于进行结果巩固。它会更主动地回顾之前的步骤,并做出明确的结论。 -
任务自适应的对比连词:在处理选择题时,模型更多地使用 however,这通常用于句子间的全局对比(例如,在不同选项间进行比较)。而在解决数学问题时,模型更多地使用but,这通常用于句内的局部修正(例如,修正计算过程中的一个小错误)。这表明 RAVR 训练出的模型能够根据任务需求,自适应地调整其推理策略的粒度,而不是形成固定的语言习惯。 -
在知识问答中更多的 recall,以及在数学中更多的alternatively和I need:这分别反映了在不同任务中,模型展现出更有针对性的信息检索、更多样的路径探索和更明确的规划行为。
这些行为上的变化共同展示出一个更具可解释性的、问题自适应的推理过程。
3.4 学习动态分析
1. 采样效率的提升
RAVR 的核心动机是提升采样效率。实验通过对比不同批次大小(rollout group size)下的性能验证了这一点。
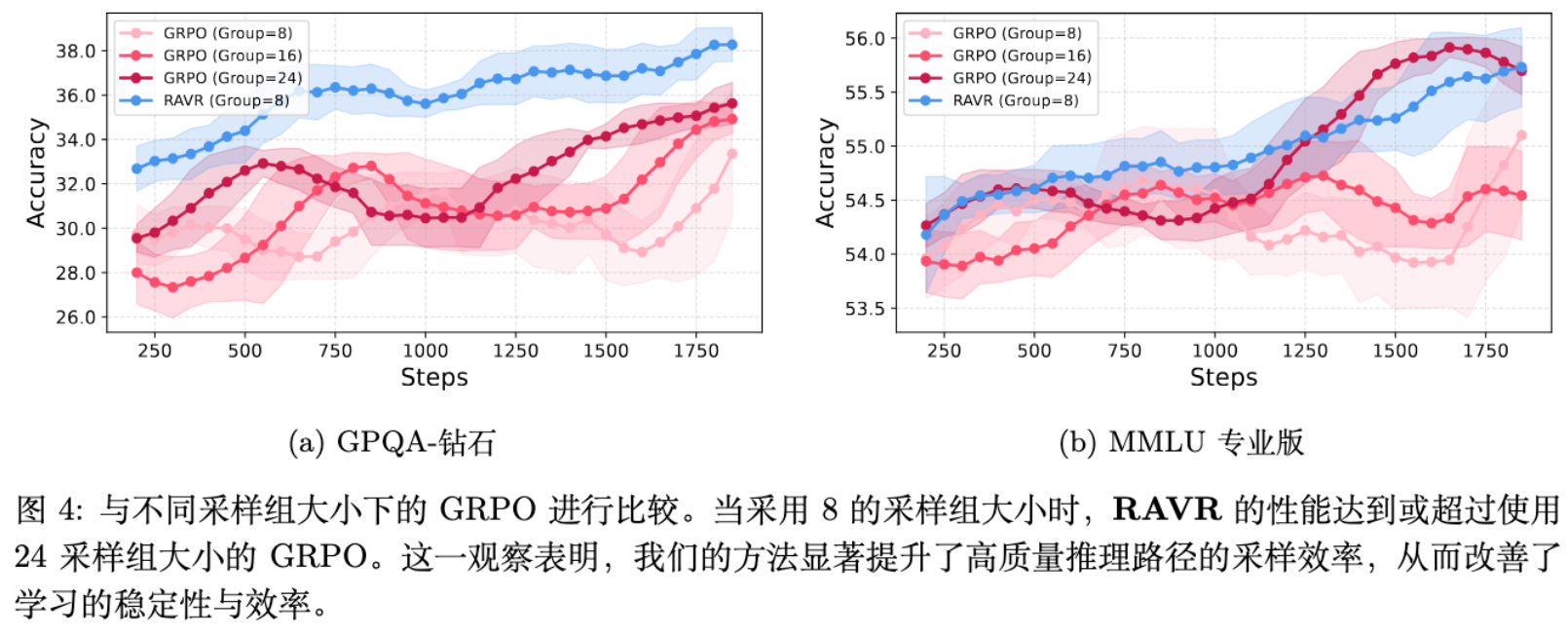
结果显示,使用 8 个采样路径的 RAVR,其性能就能够达到甚至超过使用 24 个采样路径的 GRPO。这有力地证明了 RAVR 通过答案引导,显著降低了对大量采样的依赖,用更少的计算资源实现了更好的探索效果,从而提升了学习的稳定性和效率。
2. 知识迁移的动态过程
通过追踪训练过程中先验与后验分布间的 KL 散度,以及奖励的变化,可以观察到 RAVR 的学习过程。
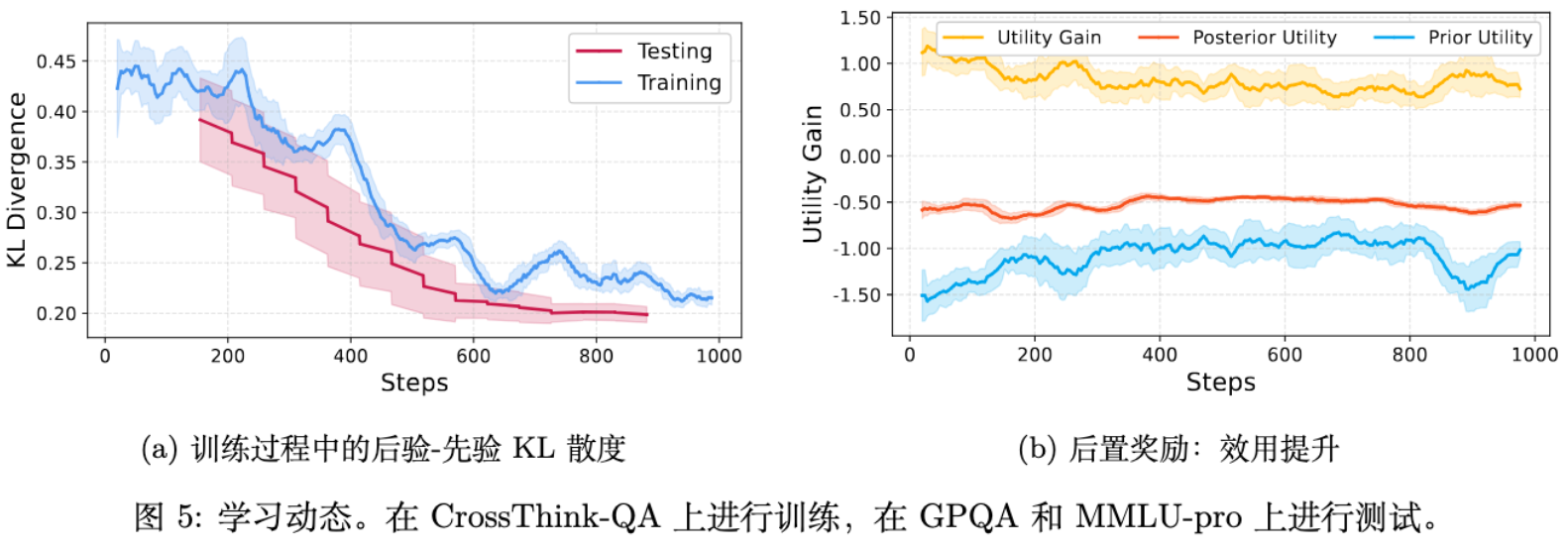
-
KL 散度在训练初期波动后,呈现稳步下降的趋势。这表明后验分布中的高质量推理能力,确实在被逐步地、稳定地迁移到先验分布中。 -
后验效用始终对先验效用保持着一个稳定的增益(Utility Gain)。这保证了学习过程的持续性。
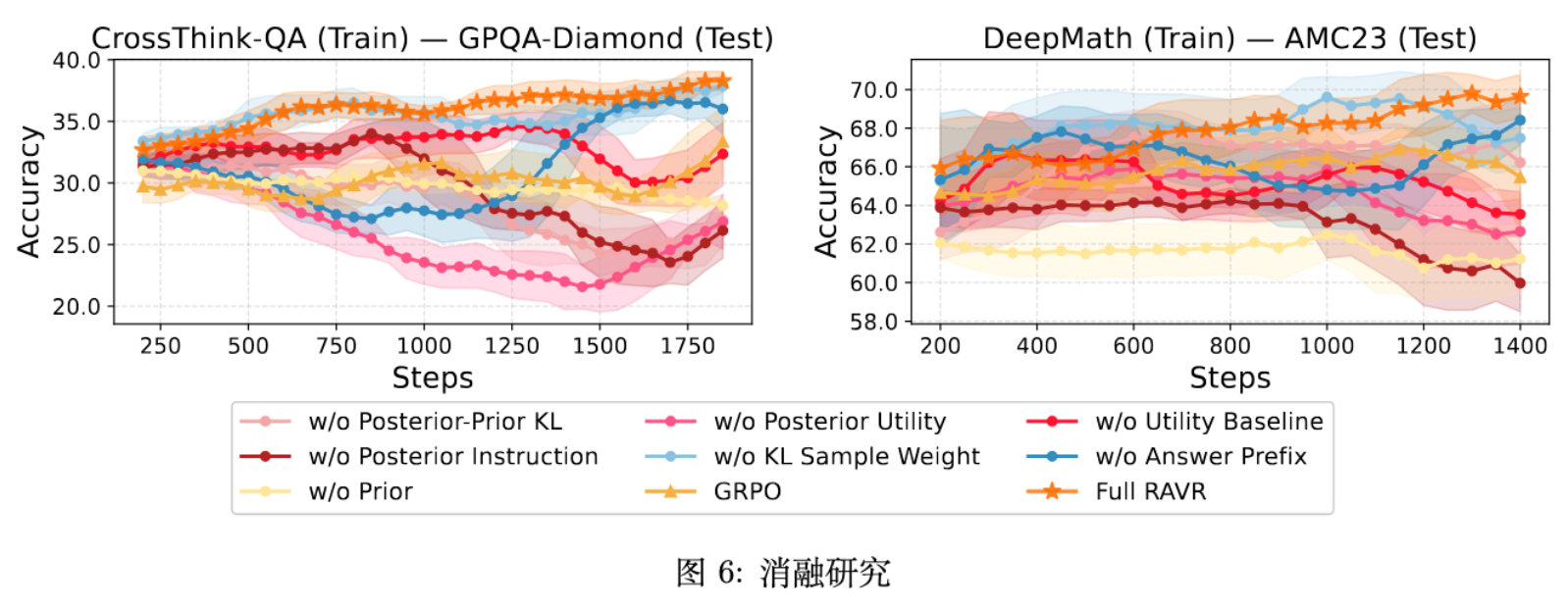
3.5 消融实验
为了验证框架中各个组件的必要性,作者进行了消融实验。结果表明,RAVR 的每一个设计都是有意义的:无论是变分目标中的期望效用项和 KL 项,还是为了稳定训练而引入的效用基线、角色扮演指令、奖励加权的 KL 和答案前缀提示,移除任何一个都会导致性能下降或训练不稳定。这证明了 RAVR 整体设计的完整性和有效性。
4. 点评
确实为有答案但难探索的问题,提供了新的解决思路。但是,看完此论文后,我们都会有疑问,给定 , 后,产生的 一定是正确的吗?
模型在被“剧透”答案后,它执行的任务不是去回忆或查找一个标准解法,而是直接生成一个能够连接问题和答案的解释。在这个生成过程中,它可能会犯几种错误:
-
“强行合理化”:这是最常见的情况。模型的核心目标是让它的解释能够最终导向给定的答案。为了达到这个目的,它可能会“不择手段”。
-
逻辑跳跃和知识幻觉:即使有答案作为终点引导,模型在构建中间步骤时,仍然可能出现事实性错误或逻辑不连贯的地方。
-
寻找“最小阻力路径”:模型生成文本是基于概率的,它倾向于选择最常见、最“省力”的语言序列。这条路径可能在逻辑上是通顺的,但可能不是最严谨、最深刻或最优的解法。它可能忽略了一些关键的边界条件或特殊情况,因为一个更简单、更普适的解释也能同样“到达”答案。
一个生成的路径 的好坏,RAVR 是通过奖励信号 来衡量的,而这个奖励的核心是 ,即“在给定了这条推理路径 后,模型自己认为正确答案 出现的可能性有多大”。也就是说它不保证 100% 正确,而是一种高效生成大量“大概率正确”的优质训练样本的方法。此外实验模型只有1.7B,期待更多实验验证其有效性。
往期文章:


