
-
论文标题:VESPO: Variational Sequence-Level Soft Policy Optimization for Stable Off-Policy LLM Training -
论文链接:https://arxiv.org/pdf/2602.10693
TL;DR
在 LLM 的强化学习(RL)后训练阶段,Off-Policy(异策略)数据分布偏移是导致训练不稳定的核心原因。这种偏移通常源于策略过时(staleness)、异步训练架构以及训练与推理引擎之间的微小计算差异。传统的序列级重要性采样(Importance Sampling, IS)虽然理论无偏,但面临方差随序列长度指数级爆炸的问题。现有的解决方法如 PPO/GRPO 的 Token 级截断破坏了序列依赖性,而 GSPO 等长度归一化方法引入了偏差。
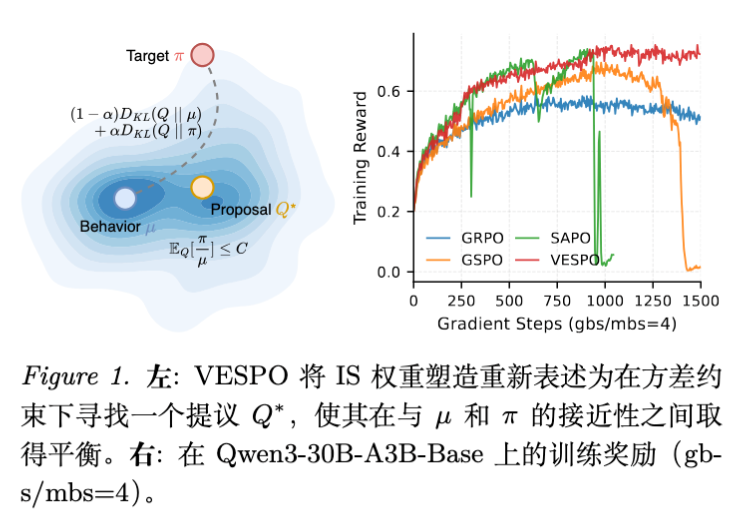
本文解读的论文 VESPO (Variational sEquence-level Soft Policy Optimization) 提出了一种基于变分原理的软策略优化方法。通过将重要性权重重塑(reshaping)问题建模为在方差约束下的变分分布对齐问题,作者推导出了一个闭式解的重塑核函数:。该方法无需长度归一化,直接在序列级操作,有效控制了方差。实验表明,在数学推理任务上,VESPO 在高达 64 倍的策略过时率和全异步训练设置下仍能保持稳定,并在 MoE 模型上取得了优于 GRPO 和 GSPO 的效果。
1. 引言
随着大语言模型(LLM)在复杂推理任务(如数学解题、代码生成)中的应用日益深入,强化学习(RL)已成为提升模型能力的关键技术。在实际的 RL 流水线中,Off-Policy 更新是不可避免的。这主要源于三个方面:
-
Mini-batch 更新导致的过时(Staleness):为了提高吞吐量,系统通常生成大批量的 Rollout 数据,然后将其切分为多个 Mini-batch 进行串行更新。后续的 Mini-batch 在更新时,基座模型参数已经发生变化,导致行为策略(Behavior Policy, )与当前策略(Target Policy, )不一致。 -
异步训练系统:在 AREAL 等大规模异步系统中,数据生成与模型训练完全解耦,导致 Rollout 数据的参数版本可能大幅滞后于当前训练版本。 -
训练-推理引擎失配:为了效率,推理常使用 vLLM/SGLang 等引擎,而训练使用 Megatron/FSDP。由于浮点数精度、归约顺序或 MoE 路由实现的细微差异,即使参数相同,输出分布也存在偏差。
1.1 序列级重要性采样的方差挑战
为了修正 Off-Policy 分布偏移,标准做法是使用重要性采样(IS)。对于序列生成任务,序列 的重要性权重 是所有 Token 级概率比的乘积:
与之对应的策略梯度为:
这里存在一个根本性的结构冲突:梯度是加和形式(Sum),而权重是乘积形式(Product)。即便每个 Token 的比率 仅有微小偏差,经过长序列的累积,权重 的方差也会随长度 指数级增长。这使得原始的序列级 IS 在长文本训练中几乎不可用。
2. 现有方法的局限性分析
为了解决方差问题,学术界和工业界提出了多种权重重塑(Reshaping)方法。论文从测度变换(Measure Change)的角度对这些方法进行了统一分析:任何对权重 的变换 ,实际上都隐式定义了一个新的提案分布(Proposal Distribution)。
其中 。
2.1 Token 级截断 (GRPO/PPO)
GRPO 和 PPO 采用了 Token 级的截断机制。从梯度视角看,GRPO 的梯度估计量为:
局限性:
-
破坏序列结构:同一条轨迹中的不同 Token 被赋予了不同的权重()。这在数学上无法对应到任何单一的序列级分布 。 -
一阶近似误差:论文在附录 A 中证明,Token 级 IS 实际上是序列级 IS 的一阶泰勒展开近似,它忽略了 Token 间的交叉项(Cross-token interactions)。这在策略处于 Near On-Policy 且序列较短时是可接受的,但在 Off-Policy 程度较高或长链推理任务中,近似误差会显著累积。
2.2 长度归一化 (GSPO)
GSPO (Geometric Mean Sequence Policy Optimization) 试图通过几何平均来控制方差,定义 。
局限性:
-
长度偏差(Length Bias):其隐式的提案分布为 。当 时,。这意味着对于长序列,模型几乎完全在优化行为策略 的分布,失去了向目标策略 优化的动力。 -
混淆不同轨迹:论文推导指出,如果两条轨迹长度不同但平均 Token 概率比相同,GSPO 会赋予它们相同的权重,即使它们的真实重要性权重 可能相差巨大(一个是 ,一个是 )。这导致模型无法正确区分样本的重要性。
2.3 启发式软截断 (SAPO)
SAPO 设计了针对 的分段函数进行软截断。虽然避免了硬截断的不可导问题,但其函数形式设计基于启发式规则,缺乏统一的理论指导,且需要手动调节多个超参数。
3. VESPO 理论框架
VESPO 的核心思想是:不依赖启发式设计,而是通过求解一个带约束的变分问题,直接推导出最优的权重重塑函数 。
3.1 变分目标:双重邻近性 (Dual Proximity)
我们需要找到一个提案分布 ,它需要满足两个看似矛盾的目标:
-
接近行为策略 :为了保证采样效率,避免由 生成的样本在 下概率过低导致有效样本量不足。 -
接近目标策略 :为了减少梯度估计的有偏性,使优化方向指向当前策略。
因此,目标函数定义为 和 的混合 KL 散度:
其中 是权衡系数。
3.2 方差约束
仅有分布接近是不够的,必须控制重要性权重的方差。在重要性采样中,估计量的方差主要由二阶矩 决定。在测度变换视角下,这对应于在 分布下的期望权重:
3.3 闭式解推导
将上述目标和约束结合,构建拉格朗日函数:
通过变分法求解 (详细推导见论文附录 B),可得最优分布形式:
利用 ,代入 ,整理可得重塑函数 的解析式:
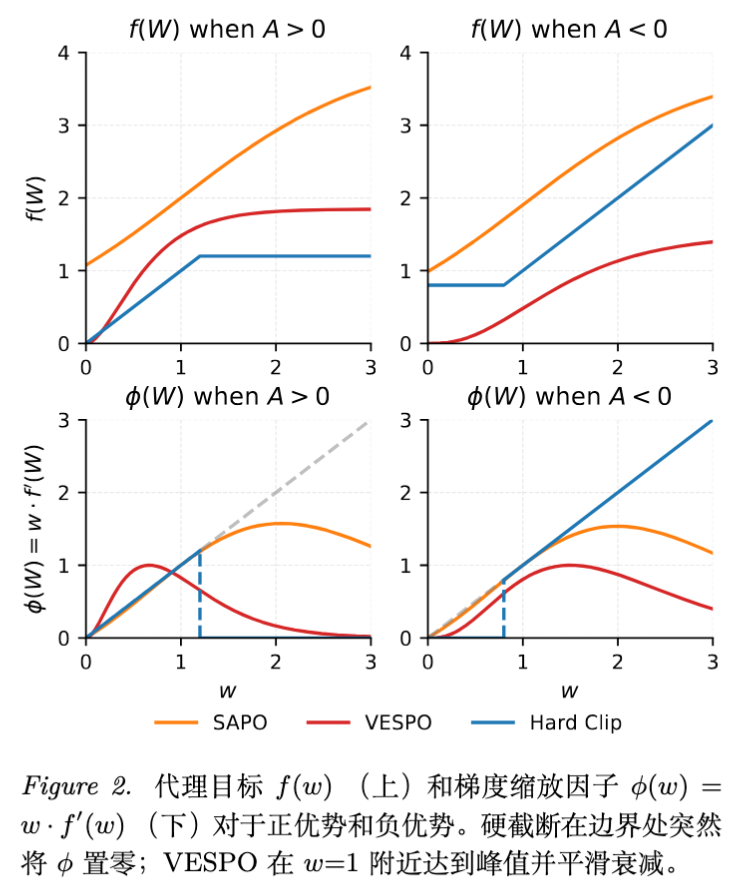
3.4 物理意义解读
该核函数由两部分组成:
-
幂次项 :根据 的取值,在 和 之间进行插值。这保留了样本区分度,给高似然比的样本更高权重。 -
指数项 :这是软抑制(Soft Suppression)的核心。当 过大时,指数项衰减速度快于幂次项增长,从而平滑地压制了极端权重,防止方差爆炸。
与硬截断(Hard Clipping)相比,VESPO 在 较大时提供了一个光滑的、逐渐衰减的梯度信号,而不是突然截断为常数或零。
4. 算法实现细节
在实际应用中,为了数值稳定性和对齐 On-Policy 行为,VESPO 进行了一些工程上的调整。
4.1 移位与归一化
为了确保 On-Policy 样本(即 )的权重为 1,且梯度更新幅度与标准方法一致,作者使用了移位形式:
这样当 时,。
4.2 非对称超参数 (Asymmetric Hyperparameters)
论文引用 Tang et al. (2025) 的研究指出,正优势(Positive Advantage, )和负优势(Negative Advantage, )的样本在训练中的动力学特性不同。
-
对于 的样本(通常对应 ):如果权重过大,会导致模型过度惩罚该样本,甚至引起长度坍塌。因此需要更强的抑制。 -
对于 的样本(通常对应 ):需要适度保留梯度信号以进行学习。
因此,VESPO 采用两组超参数:
-
: -
:
4.3 Log-Space 数值计算
由于序列级概率是连乘,直接计算会导致下溢。VESPO 全程在 Log 空间进行计算:
-
计算序列级 Log 权重:
-
计算 Log 重塑权重:
(注:原文公式 (22) 下方描述需注意, 在 Log 空间需先转回线性空间再计算,或者 的指数部分需小心处理。根据代码实现,是先算出 ,再算 。但在极值情况下需注意溢出。论文中提到 exponentiation 仅在最后一步进行。)
-
梯度估计器:
4.4 伪代码
def compute_policy_loss_vespo(log_pi, log_mu, advantages, mask, c_pos, c_neg):
# 1. 计算序列级重要性权重 (无长度归一化)
log_ratio = log_pi - log_mu
seq_log_w = (log_ratio * mask).sum(dim=-1)
W = exp(seq_log_w)
# 2. 非对称超参数选择
c1 = where(advantages >= 0, c_pos[0], c_neg[0])
c2 = where(advantages >= 0, c_pos[1], c_neg[1])
# 3. 计算 VESPO Kernel (在 log 空间组合,最后 exp)
# phi(W) = W^c1 * exp(c2 * (1-W))
# log_phi = c1 * log(W) + c2 * (1 - W)
log_phi = c1 * seq_log_w + c2 * (1 - W)
# 梯度截断,只用于 Scaling
phi = exp(log_phi).detach()
# 4. 策略梯度 Loss
# 注意:这里 phi 作为系数,advantages 也是系数
loss = -phi * advantages * log_pi.sum(dim=-1)
return loss.mean()
5. 实验
论文在数学推理基准(AIME 2024/2025, AMC 2023, MATH-500)上评估了 VESPO,使用了 Llama-3.2-3B, Qwen3-8B 和 Qwen3-30B-A3B (MoE) 模型。
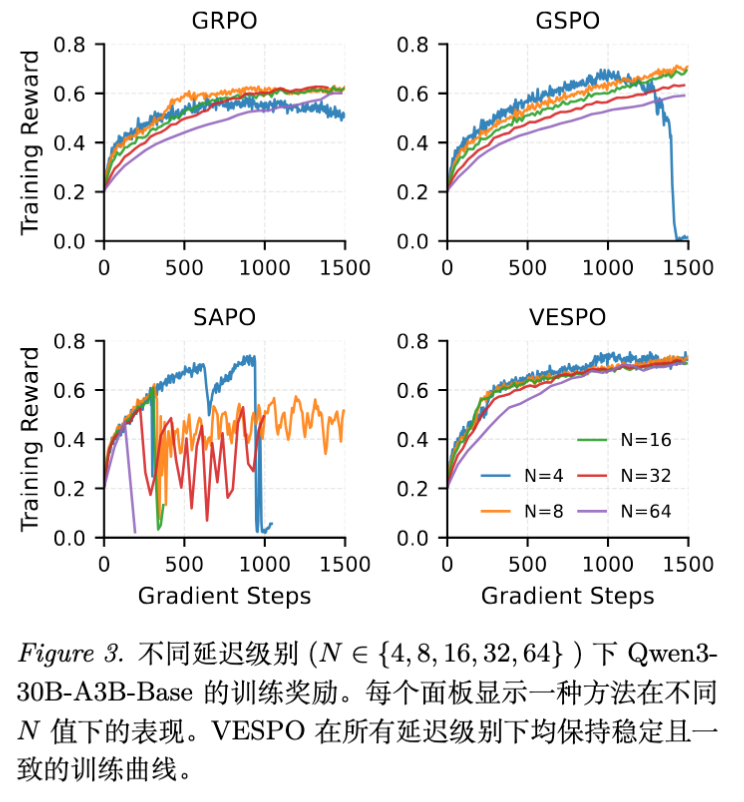
5.1 策略过时鲁棒性 (Robustness to Staleness)
为了模拟过时,实验设置了全局 Batch Size (gbs) 与 Mini-batch Size (mbs) 的比例 。 越大,后续 Mini-batch 的过时程度越严重。
-
基线表现: -
GRPO:在 时表现尚可,但随 增加,性能迅速饱和或下降。 -
GSPO:对 非常敏感,在 时即出现“长度爆炸”导致的训练坍塌(Reward 归零)。 -
SAPO:在 时训练完全崩溃。
-
-
VESPO 表现: -
在 到 的范围内,训练曲线几乎重合,表现出极强的稳定性。 -
最终 Reward 和各榜单准确率均显著优于基线。
-
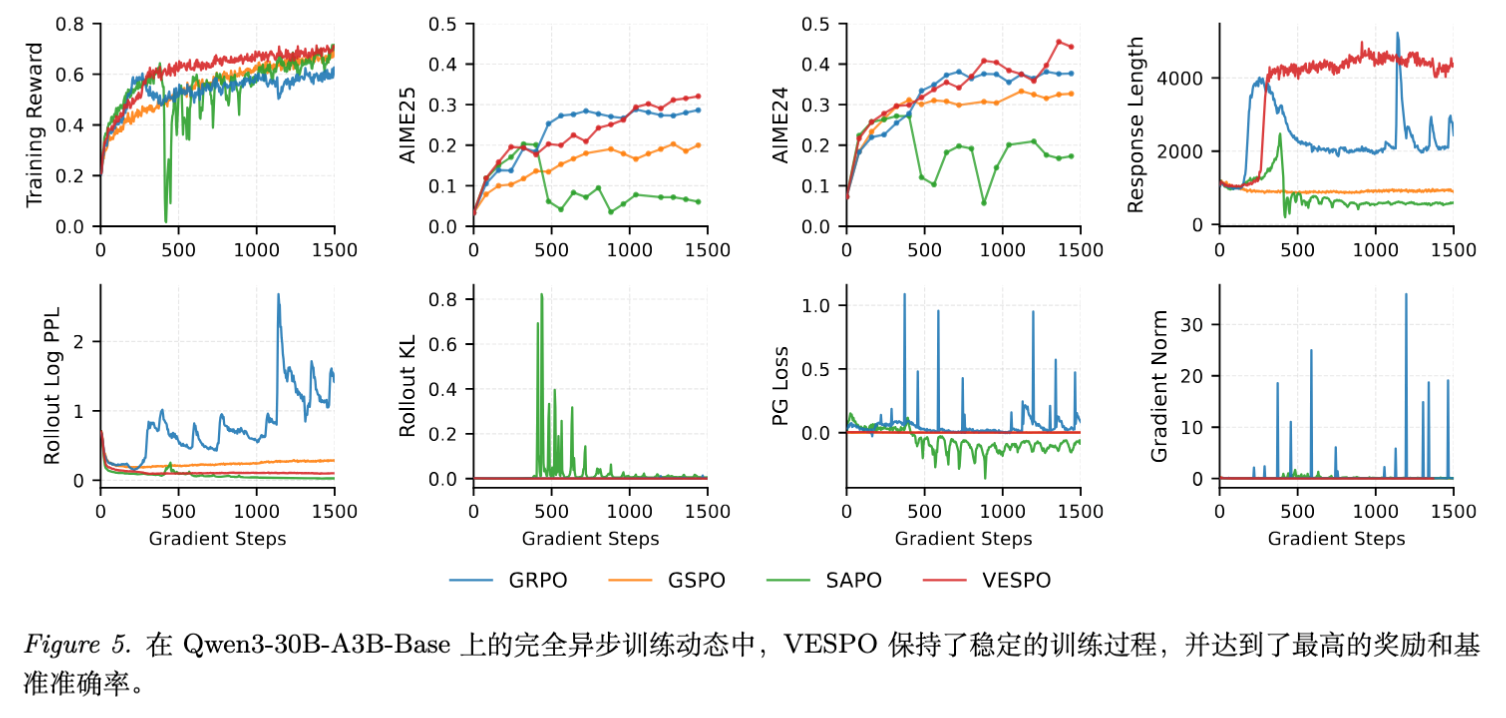
5.2 全异步训练 (Fully Asynchronous Training)
在全异步设置下(Rollout 和 Training 节点分离,参数更新滞后),环境更加恶劣。
-
GRPO:极不稳定,KL 散度和梯度范数频繁尖峰,响应长度剧烈震荡。 -
SAPO:早期坍塌。 -
VESPO:保持了低且稳定的 KL 散度、梯度范数和 Entropy,最终实现了最高的训练 Reward。
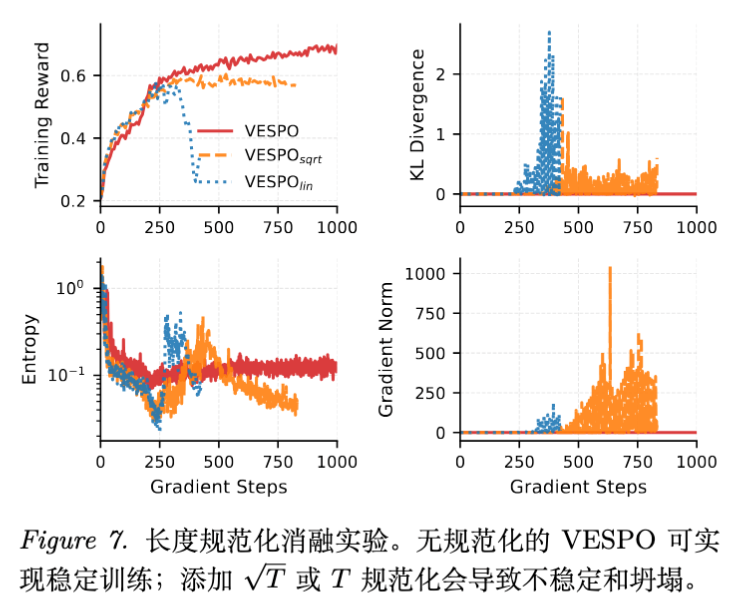
5.3 训练-推理失配与 MoE (Train-Inference Mismatch)
MoE 模型由于路由决策的非确定性,受训练-推理引擎失配(Mismatch)的影响最大。
-
现象:标准 GRPO 在 MoE 上训练时 Reward 难以提升,主要受到 Mismatch 干扰。 -
VESPO 的优势:即便不使用专门的工程修复(如 TIS 或 Routing Replay),VESPO 仅凭算法本身的软抑制能力,就能达到与 GRPO + Routing Replay 相当的稳定性。 -
叠加效应:VESPO + Routing Replay 能进一步提升上限,在 Qwen3-30B-A3B 上取得了最佳结果。
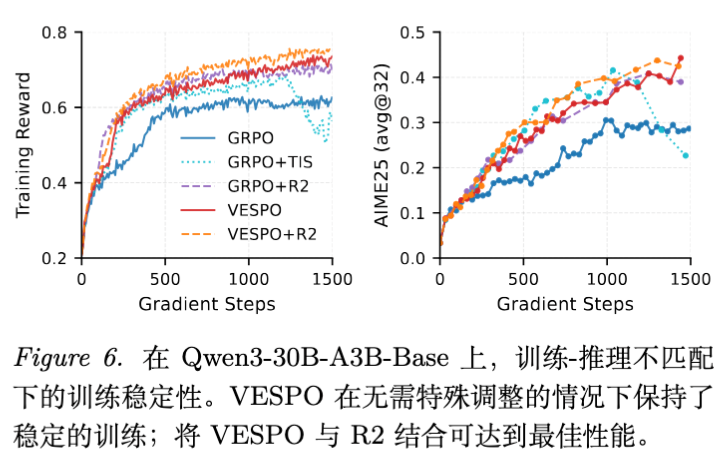
5.4 消融实验:长度归一化的危害
作者专门对比了 VESPO(无归一化)、VESPO-sqrt( 归一化)和 VESPO-lin( 归一化)。
-
结果显示,引入长度归一化(特别是 归一化)直接导致了训练的不稳定和崩溃。 -
原因分析:长度归一化使得长序列的权重被过度放大(因为分母 变大,导致 使得权重趋向于 1,难以被抑制),从而使模型偏向生成更长的序列,最终导致 OOM 或逻辑混乱。
6. 深入讨论
6.1 为什么 VESPO 比 Token 级截断好?
核心在于信用分配(Credit Assignment)的准确性。对于一道数学题,如果是中间某个步骤错了导致最终答案错误,Token 级方法(如 GRPO)可能会通过截断某些 Token 的梯度来“修补”更新量,但这破坏了序列的整体逻辑链。VESPO 则是从整条序列的维度,通过权重调整该条数据对梯度的贡献。如果一条数据严重 Off-Policy(权重极大或极小),VESPO 会整体降低其权重,而不是扭曲其内部结构。
6.2 为什么 VESPO 不需要长度归一化?
以往方法(如 GSPO)引入长度归一化是因为 方差太大。VESPO 通过指数项 提供了极强的尾部抑制能力。无论序列多长,只要 变得过大,指数项就会将其压制回来。这种机制比硬性的长度除法更符合统计学规律,因为它保留了 在序列间的相对大小关系(Monotonicity),只是压缩了数值范围。
6.3 与 PPO 的关系
PPO 的 Clip 操作本质上是一种 Trust Region 的近似实现。VESPO 可以被视为一种在序列级别上的、软性的 Trust Region 方法。它不强制将更新限制在某个 邻域内,而是通过降低远离 的样本的权重来实现类似效果。
更多细节请阅读原文。
往期文章:


