在深入 Seed Diffusion 的技术细节之前,我们有必要先回顾一下扩散模型的基本原理,以及它如何从图像领域“跨界”到自然语言处理领域的。
扩散模型的核心思想
扩散模型的基本思想源于非平衡热力学。它包含两个核心过程:
-
前向过程(Forward Process / Corruption Process):这是一个固定的、无需学习的过程。它通过多步(timesteps)迭代,逐渐向原始的、干净的数据(如一张图片 )中添加高斯噪声。经过足够多的步数 后,原始数据最终会变成一个纯粹的、无规律的噪声分布(通常是标准正态分布)。这个过程可以看作是信息被逐步“破坏”或“扩散”的过程。
-
反向过程(Reverse Process / Denoising Process):这是模型需要学习的关键过程。它的任务是逆转前向过程,即从一个纯噪声输入 开始,通过 步迭代,逐步地、精细地去除噪声,最终恢复出原始的、干净的数据 。这个过程训练的是一个深度神经网络(通常是 U-Net 架构),在每一步都预测应该如何去噪,以使数据分布更接近于真实数据分布。
这种“先破坏,后重建”的范式,使得模型能够学习到数据分布的复杂结构,从而生成高质量、高保真度的样本。
从连续到离散:扩散模型在文本生成中的挑战
当我们将这一套成功的范式从图像领域迁移到文本领域时,一个根本性的问题摆在了面前:文本是离散的。图像的像素值是连续的,我们可以很自然地通过添加高斯噪声来对其进行“腐蚀”。但是,对于由一个个离散的词符(token)组成的句子,我们无法直接“加上一点点噪声”。一个 token 要么是它本身,要么就变成了另一个 token,不存在中间状态。
为了解决这个问题,研究者们提出了多种离散扩散模型(Discrete Diffusion Models) 的方案。这些方案大致可以分为两类:
-
连续隐空间投影:将离散的 token 投影到一个连续的向量空间(如词嵌入空间)。然后在这个连续空间中执行标准的扩散过程。生成时,再从去噪后的连续向量映射回离散的 token。 -
离散状态空间直接定义:直接在离散的 token 空间中定义状态转移矩阵,来描述前向和反向过程。例如,前向过程可以被定义为以一定概率将原始 token 替换为一个特殊的 [MASK]token,或者随机替换为词汇表中的其他 token。
Seed Diffusion 采用的正是第二种方法,即直接在离散状态空间上构建其扩散过程。这种方法避免了在连续和离散空间之间转换可能带来的信息损失,理论上更加直接。近年来,随着模型架构和训练方法的改进,离散状态扩散模型已经展现出了良好的可扩展性和有效性。
然而,即便解决了离散性的问题,语言领域的扩散模型依然面临两大挑战,这也是 Seed Diffusion 论文开篇就指出的核心痛点:
-
对 token 顺序建模的归纳偏置(Inductive bias on token-order modeling):自然语言具有极强的顺序性结构(从左到右)。而离散扩散模型理论上可以按任意顺序生成 token,这种灵活性固然强大,但也意味着模型在训练时需要从海量的、甚至是冗余或无效的生成顺序中进行学习。这可能导致学习效率低下,甚至对模型性能产生负面影响。 -
推理效率低下(Inference inefficiency):虽然扩散模型是非自回归的,但其生成过程需要进行多步迭代去噪。每一步迭代都需要对整个模型进行一次完整的前向传播,这带来了巨大的计算开销,严重影响了其相对于传统自回归模型的速度优势。
正是为了直面并解决这两大挑战,Seed Diffusion 提出了一系列创新的技术方案。
Seed Diffusion 核心技术深度解析
Seed Diffusion Preview 作为 Seed Diffusion 系列的第一个实验性模型,专注于代码生成任务。它采用了标准的密集 Transformer 架构,并在此基础上,引入了多项关键的技术创新,旨在构建一个既高效又强大的性能基线。
1. TSC: 两阶段课程学习,为稳健扩散训练保驾航
为了训练出一个既能理解文本内在结构又能高效去噪的扩散模型,Seed Diffusion 设计了一套名为 TSC (A Two-Stage Curriculum for Robust Diffusion Training) 的两阶段课程学习策略。这个策略通过组合两种不同的前向“腐蚀”过程,让模型在不同阶段学习不同的能力。
第一阶段:基于掩码的前向过程 (Mask-based Forward Process)
在训练的前 80% 步骤中,模型采用的是一种标准的、基于掩码的腐蚀方法。对于一个原始的 token 序列 ,其腐蚀过程 被定义为对每个 token 进行独立处理的乘积:
其中,在任意一个时间步 ,序列中的每个 token 会根据一个噪声调度器 的设定,被独立地处理。其边际概率 定义如下:
这里, 代表特殊的 [MASK] token,而 是一个随时间步 从 0 到 1 单调递增的函数。这意味着,在训练初期( 较小),大部分 token 保持不变;随着训练的进行( 增大),越来越多的 token 会被替换成 [MASK] 符号。这种方法的好处是提供了一个低方差的训练目标。
第二阶段:基于编辑的前向过程 (Edit-based Forward Process)
在训练的后 20% 步骤中,研究者引入了一种额外的、基于编辑的腐蚀过程 作为数据增强。这么做的目的是为了提升模型的校准能力,并消除一些意外行为,比如在生成过程中出现不必要的重复。
该方法通过控制编辑距离(Levenshtein distance)来定义信噪比。具体来说,模型会预先定义一个编辑操作集合 (例如,删除、插入、替换)。对于一个原始序列 ,前向过程会对其执行 次编辑操作,从 开始,通过 迭代 次,得到腐蚀后的序列 :
目标编辑次数 由一个调度器 控制, 代表了近似的信噪比:
为了保持模型在第一阶段学习到的密度估计能力, 的值被限制在一个较小的范围内,例如 (论文中表述为at lie in the range [0,0.1],这里应理解为噪声水平)。
论文中特别提到一个重要的设计选择(Remark 3.1):与一些先前的工作不同,Seed Diffusion 不采用“直接复制未掩码 token” 的策略。虽然直接复制可以降低困惑度(perplexity),但它会引入一个有害的归纳偏置,即模型会错误地学习到“未被掩码的 token 永远是正确的”,从而丧失了在推理过程中进行自我修正的能力。而基于编辑的增强迫使模型重新评估所有 token,包括那些未被直接编辑的 token,从而缓解了模型的过自信问题。
整体学习目标
模型的最终学习目标是最大化证据下界(Evidence Lower Bound, ELBO)。对于掩码过程,ELBO 的一个可处理的简单形式如下:
其中 是指示函数。这个式子由一个重构损失和在所有被掩码位置上的加权对数似然期望组成。
最终,在两阶段课程学习中,模型将基于编辑过程的去噪损失与基于掩码过程的去噪损失结合起来。通过用基于编辑过程的重构损失替换掉式 (5) 中的第一项,得到最终的扩散损失函数 :
2. 定制扩散轨迹空间:让模型学会“走捷径”
标准的掩码扩散模型需要从所有可能的生成顺序中学习。其本质与任意顺序自回归建模(any-order autoregressive modeling)等价,其目标函数可以表示为在所有可能排列 上的期望对数似然:
其中 是所有可能排列的对称群。这是一个非常复杂且低效的学习问题,导致了扩散语言模型在性能上通常会落后于同等规模的自回归模型。为了理解轨迹,论文给出了从时间步 到 () 的转移概率:
为了解决这个问题,Seed Diffusion 提出了一种约束顺序的扩散训练过程 (constrained-order diffusion training process) 。这个过程在上述两阶段学习之后进行,可以看作是一个精调(fine-tuning)阶段。其核心思想是:与其让模型在所有可能的“去噪路径”中盲目探索,不如先用一个已经训练好的模型,筛选出一批高质量的“最优路径”,然后让模型专注于学习这些“最优路径”。
具体步骤如下:
-
生成候选轨迹:对于一个给定的样本,使用预训练好的 Seed Diffusion 模型,大规模地生成多个候选的去噪轨迹(trajectory)。一个轨迹 就是一个从全掩码序列 开始,逐步去噪直到生成完整序列 的完整步骤序列。 -
筛选高质量轨迹:使用一个选择标准,即最大化证据下界(ELBO),从候选池中筛选出高质量的轨迹。这些轨迹可以被认为是更高效、更合理的生成路径。 -
模型微调:将筛选出的高质量轨迹集合 作为新的“蒸馏”数据集,对模型进行微调。其约束顺序训练的损失函数形式如下:
其中 是用于平衡不同噪声水平损失的权重,而 是一个类似于 的数据增强函数。
通过这种方式,模型被引导去学习更符合自然语言或代码结构的生成顺序,从而弥补了与自回归模型之间的性能差距。
3. 在线策略扩散学习:为推理速度“踩油门”
解决了性能问题,下一个目标就是攻克速度瓶颈。传统扩散模型为了保证生成质量,通常需要较多的采样步骤,这使得单次生成的延迟很高。
为了充分释放并行解码的潜力,Seed Diffusion 提出了一种简单而有效的在线策略学习范式 (on-policy learning paradigm) 。其核心目标是直接在训练过程中最小化生成所需的轨迹长度(即采样步数)。优化的目标函数如下:
其中, 是模型根据给定的 prompt 生成的一个完整轨迹, 是轨迹的长度(即采样步数)。 是一个基于模型的验证器(verifier),用于确保采样过程最终能够收敛到一个合理/正确的样本,这一项可以通过对数求导技巧(log-derivative trick)进行优化。
直接最小化轨迹长度 可能会导致训练不稳定。因此,研究者们优化了一个代理损失(surrogate loss),其基于一个事实:轨迹长度与轨迹中任意两点之间的 Levenshtein 距离之和是成正比的。
通过最小化轨迹步骤之间的编辑距离,可以有效推动模型学会用更少的步骤完成去噪过程,从而缩短轨迹长度。
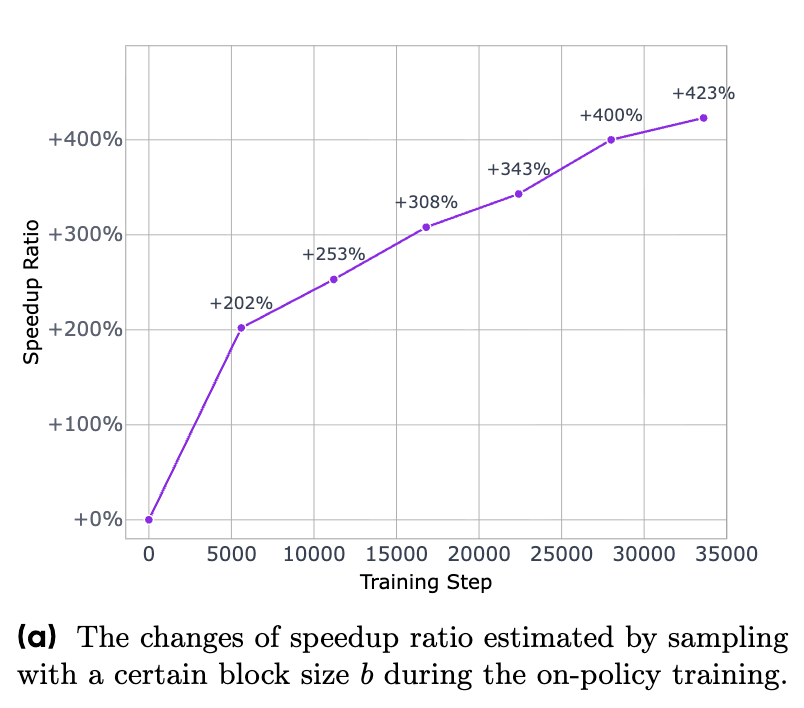
如上图所示,在采用在线策略训练的过程中,模型的速度提升比率(Speedup Ratio)随着训练步骤的增加而显著提高,最终达到了超过 400% 的加速。
4. 推理与基础设施优化:软硬件协同的最后一公里
为了在实际应用中实现低延迟,算法层面的优化还不够,必须与高效的推理基础设施相结合。Seed Diffusion 采用了一种块级并行扩散采样方案(block-level parallel diffusion sampling scheme),这是一种半自回归(semi-autoregressive)的策略。
该方案将整个生成序列划分为多个块(block),在块与块之间保持因果顺序,但在每个块内部,所有 token 则通过扩散模型并行生成。具体来说,当生成第 个块 时,其反向过程的条件概率表示为:
其中 是先前已经生成的所有块的内容。为了在生成后续块时能够高效利用前面已生成块的信息,模型使用了 KV-caching 技术。
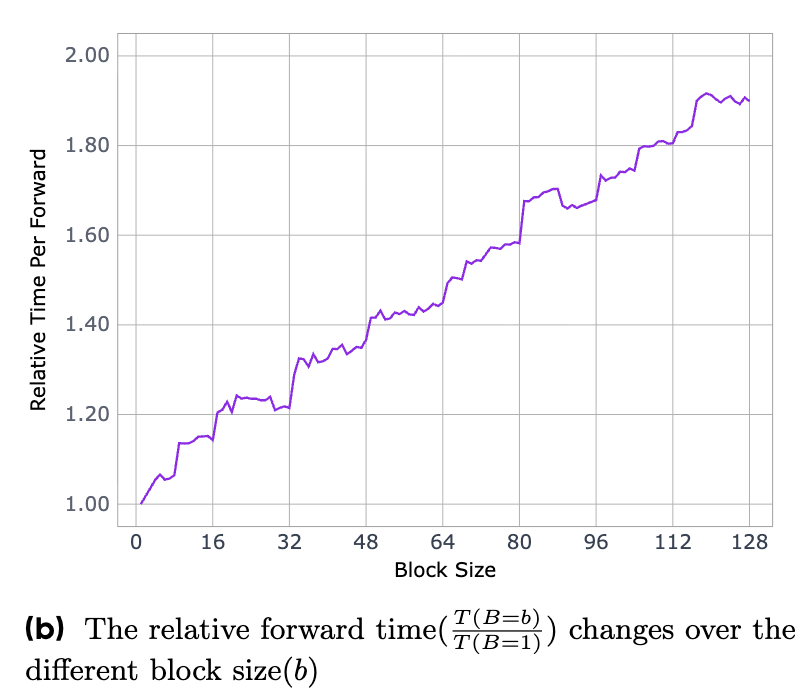
上图展示了不同的块大小(Block Size)对单次前向传播相对时间的影响。通过这样的分析,团队可以找到一个最优的块大小,以平衡单次前向传播的延迟和总体的 token 生成速率,从而实现最佳的实际推理性能。
实验与性能评估:速度与质量的双重验证
为了全面评估 Seed Diffusion Preview 的性能,研究者们在一系列广泛的代码相关任务上进行了基准测试,并将其与当前最先进的扩散语言模型(Mercury, Gemini-Diffusion)以及一系列强大的自回归代码模型进行了对比。
评测基准
论文中使用的评测基准非常全面,覆盖了从基础代码能力到复杂竞赛编程的多个维度:
-
HumanEval & MBPP: 评估模型基础 Python 编程能力的经典基准。 -
BigCodeBench: 一个更贴近真实世界编程场景的基准,涉及多工具使用和复杂的函数调用。 -
LiveCodeBench: 一个持续更新的竞赛编程基准,包含了来自 LeetCode、AtCoder 等平台的题目,并且通过时间戳严格防止数据污染。 -
MBXP: 一个多语言版本的 MBPP,用于评估模型在 Python, Java, C++ 等十多种编程语言上的能力。 -
NaturalCodeBench (NCB): 一个旨在提供更真实评估环境的基准,包含 402 个来自真实用户查询的 Python 和 Java 问题。 -
Aider & CanItEdit: 两个专注于评估代码编辑能力的基准。模型需要根据指令修改已有的代码,这对模型的理解和精确控制能力提出了更高的要求。
性能对比分析
实验结果清晰地展示了 Seed Diffusion 在速度和质量上的双重优势。
速度:一骑绝尘
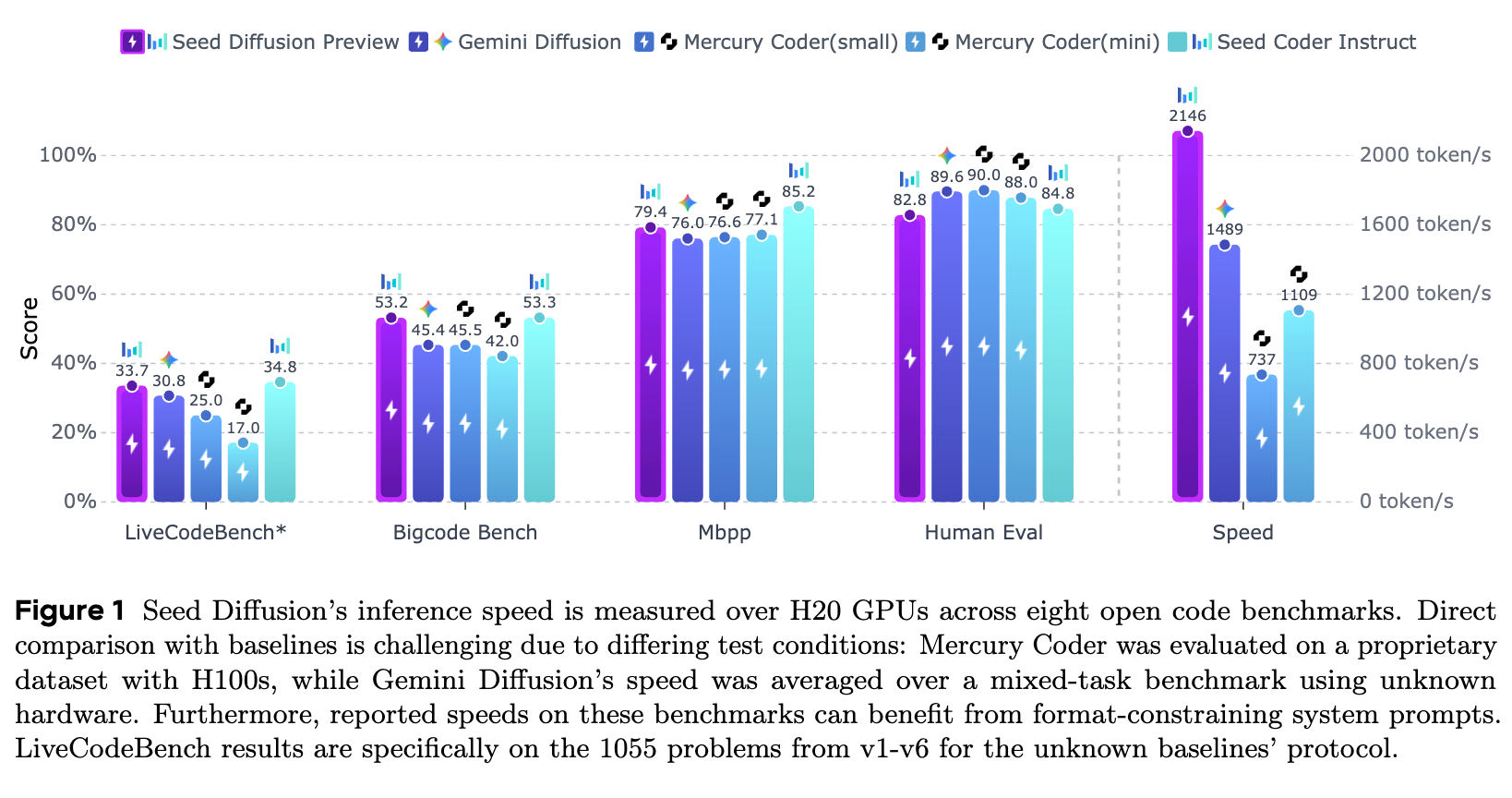
上图是论文中最引人注目的结果之一。在 H20 GPU 上,Seed Diffusion Preview 实现了 2,146 token/s 的推理速度。相比之下,其他模型的速度数据虽然由于测试条件(如硬件、数据集)不同难以直接精确对比,但 Seed Diffusion 的数量级优势是显而易见的。图中标注的 Gemini Diffusion 速度为 1489 token/s,而 Mercury Coder(small) 约为 1109 token/s。这种高速推理能力使其在需要快速代码补全或生成的场景中具有巨大的应用潜力。
质量:全面且有竞争力
在生成质量方面,Seed Diffusion Preview 同样表现出色,在多个基准上都达到了与顶尖自回归模型相当甚至超越的水平。
-
代码编辑能力超群:
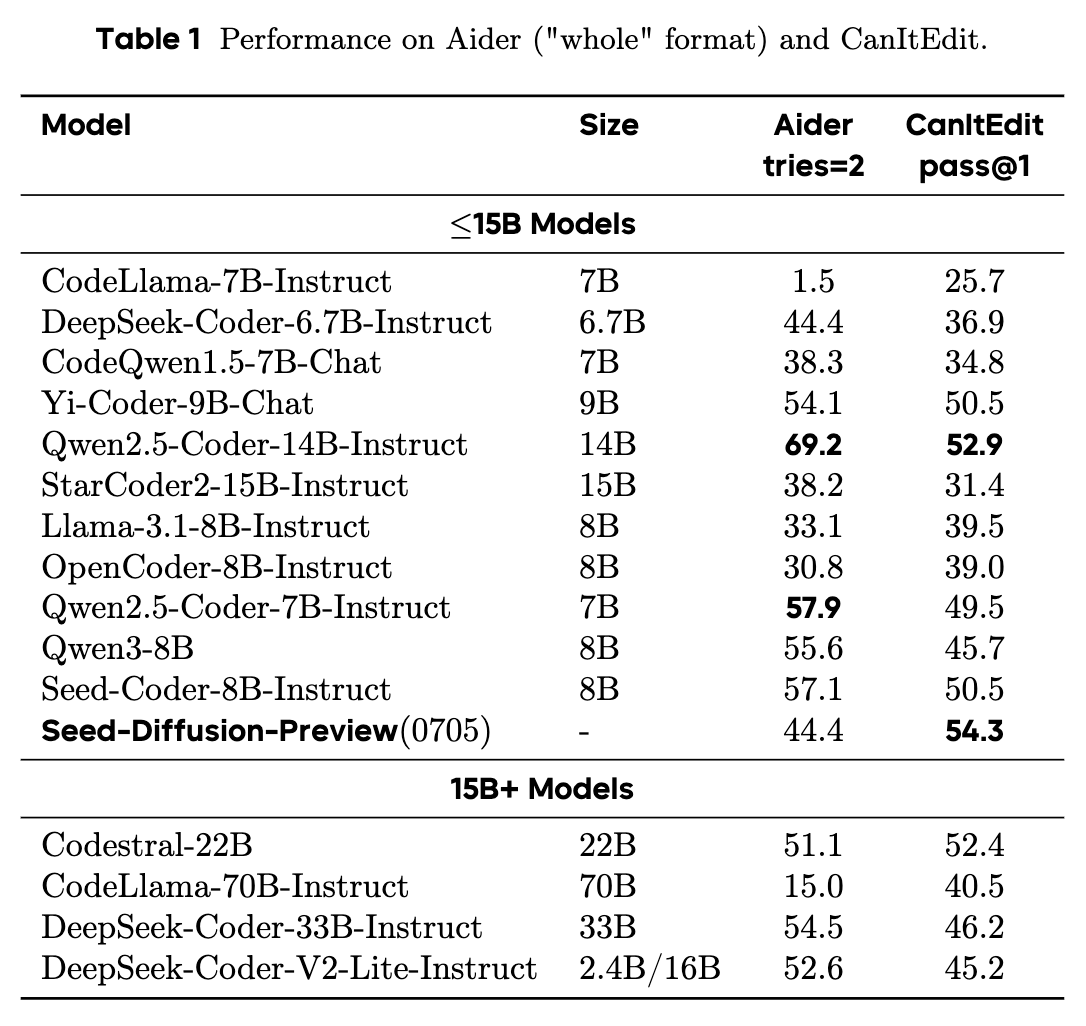
在 Table 1 展示的 Aider 和 CanItEdit 两个代码编辑基准上,Seed Diffusion 的表现尤为亮眼。在 CanItEdit (pass@1) 指标上,它取得了 54.3 的高分,超过了包括 Qwen2.5-Coder-14B (52.9)、Yi-Coder-9B-Chat (50.5) 和 Codestral-22B (52.4) 在内的所有同量级和更大规模的模型。这表明,扩散模型在理解和执行编辑指令方面可能具有独特的优势,这或许与其非串行的、全局性的修改能力有关。
-
多语言代码能力稳健:
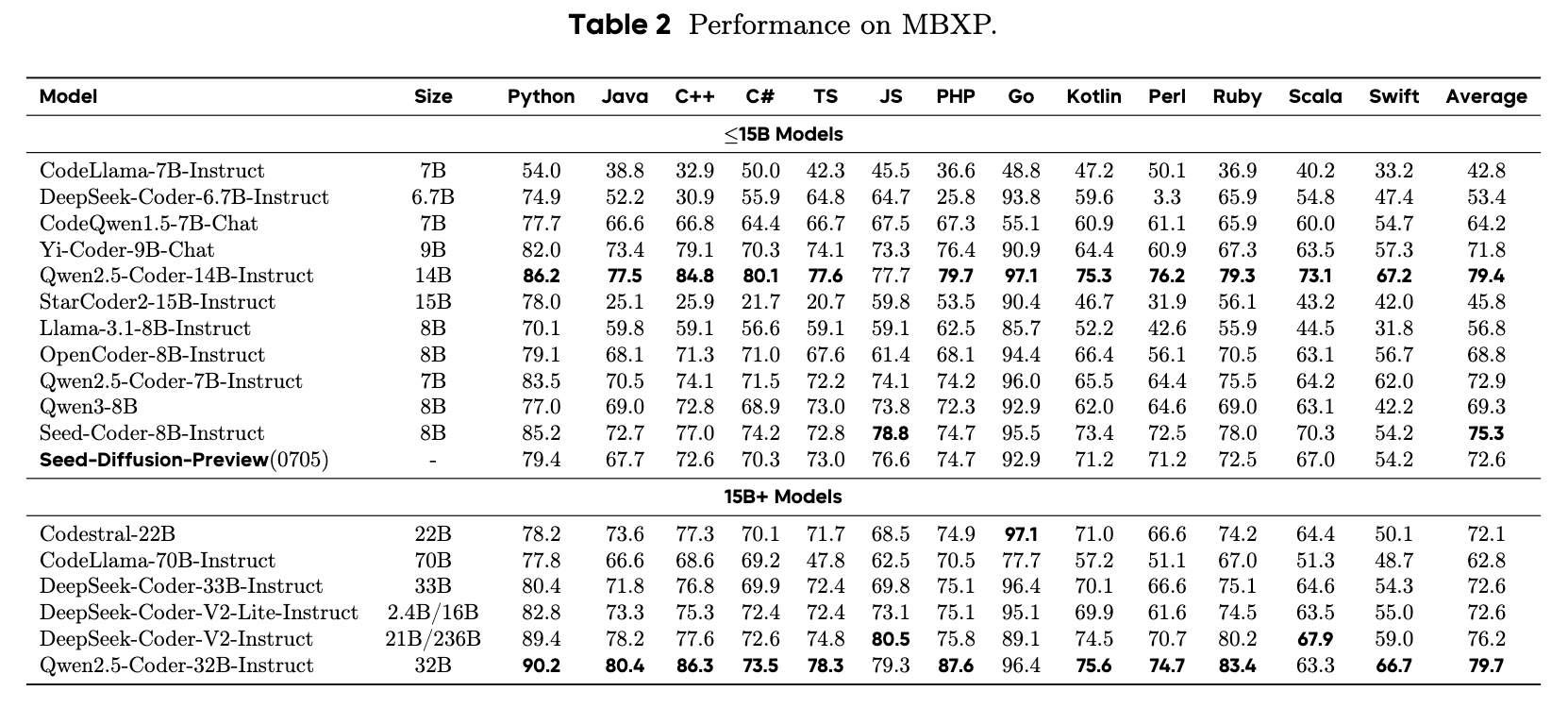
在 Table 2 的多语言 MBXP 基准测试中,Seed Diffusion (0705) 的平均分达到了 72.6,虽然略低于 Seed-Coder-8B (75.3) 和 Qwen2.5-Coder-14B (79.4) 等顶尖自回归模型,但仍然超过了许多其他强大的基线模型,展示了其在多种编程语言上扎实的生成能力。
-
真实场景应用潜力:
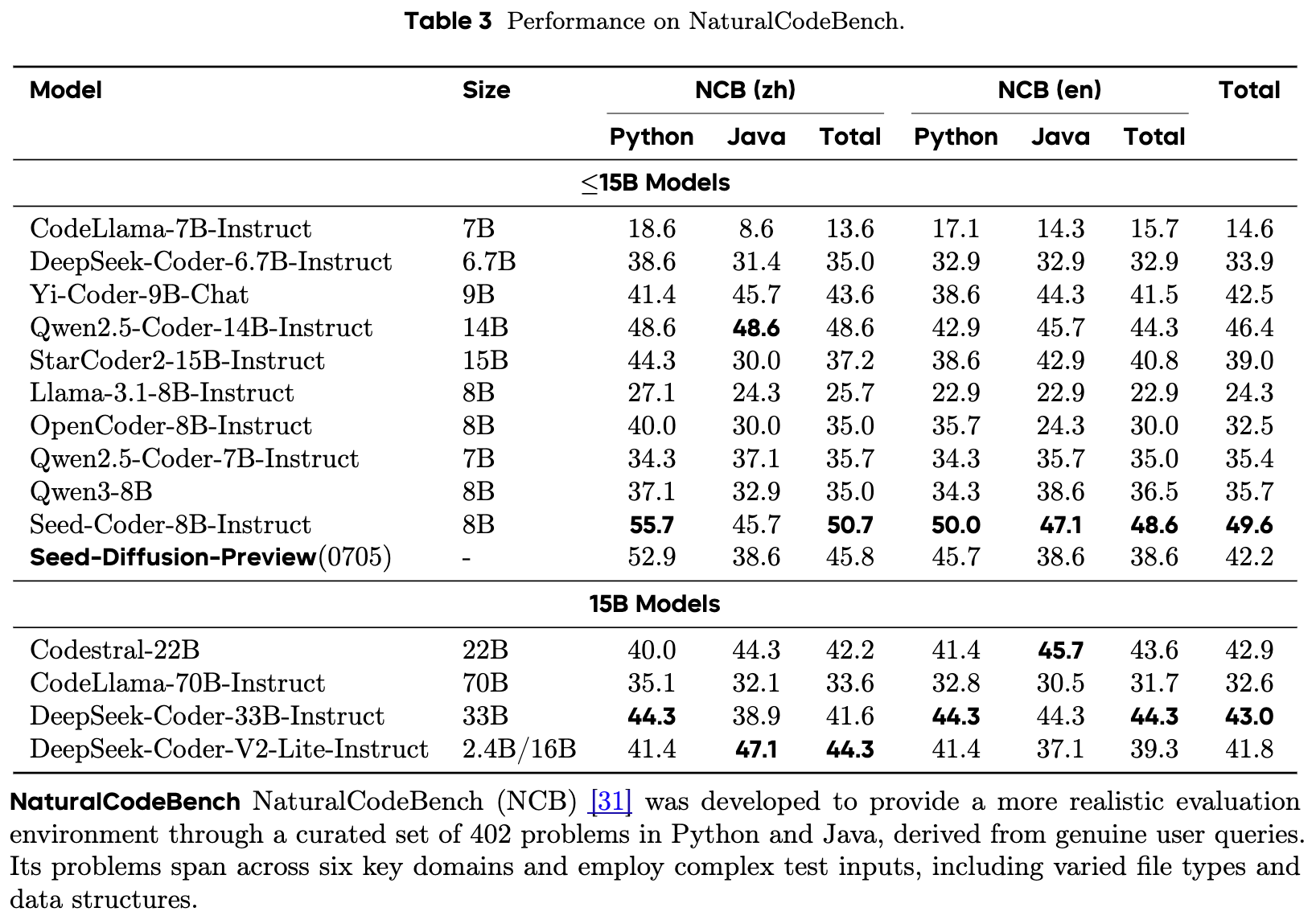
在更接近真实用户查询场景的 NaturalCodeBench (Table 3) 上,Seed Diffusion 的总体得分为 42.2,虽然不如其自回归兄弟模型 Seed-Coder-8B (49.6),但也展现了有竞争力的性能。
往期文章:


