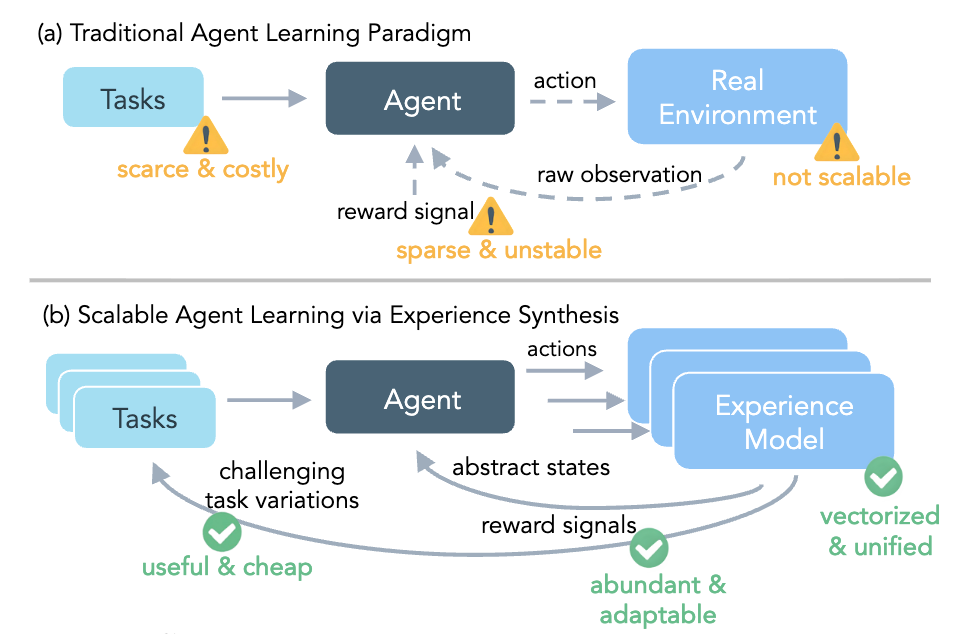
对于基于大型语言模型(LLM)的自主智能体(Autonomous Agents)而言,强化学习(Reinforcement Learning, RL)提供了一条通过与环境交互进行自我改进的理想路径。但实际应用中面临着众多挑战:高昂的交互成本、任务多样性不足、奖励信号不稳定、基础设施过于复杂。
近期,Meta Superintelligence Labs 在论文《Scaling Agent Learning via Experience Synthesis》中提出了 DREAMGYM 框架,不再完全依赖于昂贵且充满限制的真实环境交互,而是转向通过一个基于推理的经验模型来“合成”多样化的经验(Experience Synthesis)。这种方法旨在创建一个可扩展、可控且信息丰富的虚拟训练场,从而为通用强化学习提供一种高效的“热启动”策略。

-
论文标题:Scaling Agent Learning via Experience Synthesis -
论文链接:https://arxiv.org/pdf/2511.03773
1. DREAMGYM 的核心思想
过去,我们训练AI时,总想让训练环境(不管是真实的还是模拟的)尽可能地和现实世界一模一样。但作者发现:智能体的有效学习并不必然需要一个完美复刻真实世界的环境,而是需要足够多样化、信息丰富且具备因果一致性的交互数据。
基于这一思想,DREAMGYM 不再追求像素级或代码级的精确复刻,而是构建了一个在抽象的、元表征的文本空间(abstract, meta-representational textual space)中运行的经验模型。这个模型通过推理来预测智能体动作的后果,生成状态转移和反馈信号。
这种设计带来了几个直接的好处:
-
效率:在抽象文本空间中交互,避免了渲染、网络请求等高昂开销,交互速度得以数量级提升。 -
可控性:合成环境的状态转移和奖励函数完全由模型控制,可以提供更稳定、更密集的学习信号。 -
可扩展性:摆脱了对特定后端(如浏览器、虚拟机)的依赖,整个框架可以在统一的、可大规模扩展的 LLM 服务基础设施上运行。
2. DREAMGYM 框架
DREAMGYM 的实现围绕三大核心组件构建。
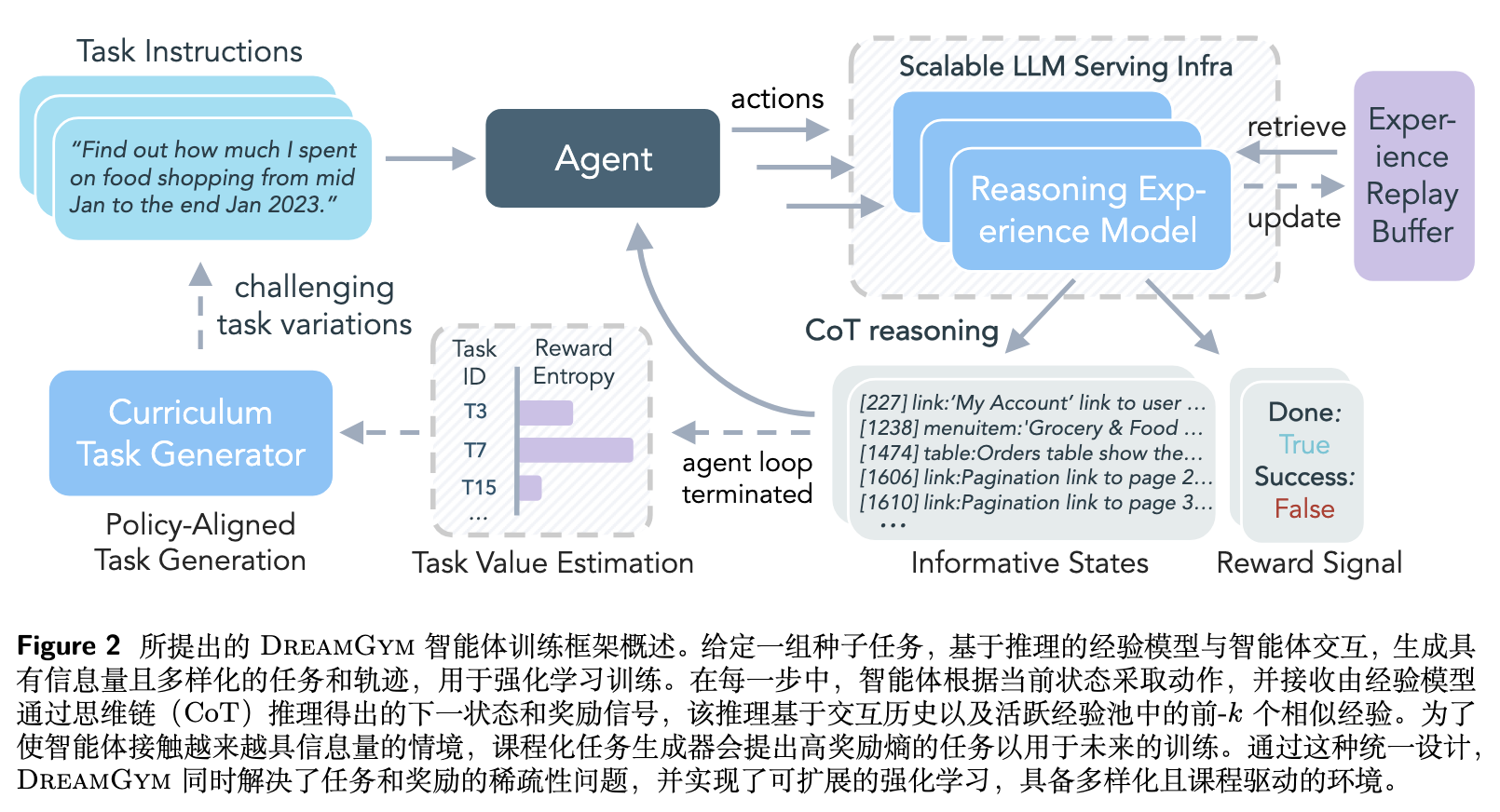
2.1 可扩展的推理式经验模型
这是 DREAMGYM 的核心。它是一个基于 LLM 的模型,记为 ,负责模拟环境的动态,为智能体提供交互体验。
1.1 经验 rollout 的推理过程
在与智能体交互的每一步,经验模型 的任务是根据当前状态 和智能体的动作 来预测下一个状态 和奖励 。为了提高预测的质量和一致性,模型不仅仅考虑当前的状态-动作对,还整合了三个额外的上下文信息:
-
交互历史:。完整的交互历史帮助模型维持多轮交互的状态一致性,理解当前的上下文。 -
任务指令:。任务指令让模型能够根据当前的目标来解释智能体的动作,并预测与任务相关的状态转移和奖励。 -
过往经验:。模型会从一个经验回放缓冲区中,基于语义相似度检索出 个最相关的过往经验(即轨迹片段)。这些经验作为一种形式的上下文学习(in-context learning)范例,可以减少模型的“幻觉”现象,提高其预测的事实准确性,尤其是在处理知识密集型任务时。
综合以上输入,经验模型通过思维链(Chain-of-Thought, CoT)进行推理,最终生成下一个状态和奖励。其过程可以形式化为:
其中 是模型生成的显式推理轨迹,它指导着状态的转移。例如,如果智能体的动作是无效的,模型会推理出这是一个错误,并转换到一个失败状态,同时给予一个零奖励。这种基于推理的生成方式,确保了状态转移的逻辑连贯性和信息的丰富性。在奖励设计上,作者采用了基于结果的奖励方案(outcome-based reward),即仅在任务最终成功时给予 的奖励,其他所有步骤的奖励均为 。
1.2 经验模型的训练
得益于其在抽象空间中的设计,经验模型的训练是样本高效的。它只需要有限的、来自真实环境的离线轨迹数据即可完成训练。在实践中,来自公开基准(如 WebArena Leaderboard)的轨迹数据就足够了。
训练过程如下:
-
首先,收集一个离线轨迹数据集 。 -
然后,使用一个强大的教师 LLM 为数据集中的每一个状态转移 标注一个显式的推理轨迹 ,解释为什么在状态 执行动作 会导致状态 和奖励 。 -
最后,使用这个标注好的数据集,通过监督微调(Supervised Fine-Tuning, SFT)的方式训练经验模型 。
其联合优化目标函数如下:
其中 是交互历史, 是检索到的 个示范。这个目标函数确保了模型不仅学习模仿专家的轨迹,更重要的是学习生成忠实的推理过程,并利用这些推理过程来预测一致且信息丰富的下一个状态。这赋予了模型在强化学习训练期间为新的、未见过的 rollout 进行泛化推理的能力。
2. 经验回放缓冲区
经验回放缓冲区在 DREAMGYM 中扮演着双重角色:
-
为经验模型提供事实基础:如前所述,缓冲区存储的过往经验被用于检索,为模型的推理提供事实依据,减少幻觉。 -
与智能体共同演化(Co-evolving):缓冲区不仅用离线的真实世界数据进行初始化,还会持续不断地被智能体在合成环境中产生的新轨迹所丰富。这意味着,随着智能体策略 的更新,缓冲区中的数据也在不断更新。这种“共同演化”的机制确保了经验模型能够始终与智能体的最新策略保持对齐,从而为稳定的策略训练提供了支持。
3. 课程学习任务生成器
为了解决任务多样性有限和静态的问题,DREAMGYM 设计了一个课程学习任务生成器。该组件能够主动生成新的、对当前智能体具有挑战性的任务,从而实现一种自适应的在线课程学习。
其工作流程如下:
-
识别高价值任务:作者认为,对智能体学习最有价值的任务是那些“可行但具有挑战性”的任务。换句话说,在这些任务上,智能体的表现不稳定,时而成功,时而失败。这种不确定性意味着任务中包含了智能体尚未完全掌握的知识,信息增益最大。
-
基于奖励熵的任务价值评估:为了量化任务的“挑战性”,作者引入了基于组的奖励熵(group-based reward entropy) 作为评估标准。对于一个任务 ,在一个组 (例如,一次 PPO 训练迭代中收集的所有轨迹)中,其价值 定义为结果奖励的方差:
其中 是任务 在第 次 rollout 中的最终奖励(0 或 1)。当成功和失败的次数大致相等时(例如,一半成功一半失败),方差最大,即奖励熵最高。这表明该任务对智能体来说难度适中,是学习的最佳区域。这一观察与近期研究发现 LLM 从中等难度的任务中学得最有效的结果相符。
-
生成任务变体:任务生成器会选择那些奖励熵最高的任务作为“种子任务”,然后利用一个与经验模型共享参数的任务生成模型 ,来生成这些种子任务的变体。
这些新生成的任务在保留原任务核心挑战的同时,引入了新的变化,从而丰富了任务集,推动智能体不断探索和学习。为了稳定训练过程,作者还引入了一个超参数 来控制每次迭代中合成任务的比例。
3. 实验
为了验证 DREAMGYM 的有效性和泛化能力,作者在一系列多样化的智能体基准和不同规模的 LLM 主干上进行了全面的实验。
3.1 实验环境和模型
-
评估环境: -
WebShop:一个需要通过搜索和识别商品来完成电子商务任务的基准,属于 RL-ready 但交互成本高的环境。 -
ALFWorld:一个涉及多轮基于工具的具身控制,用于在 3D 环境中导航的基准,同样是 RL-ready 但成本高。 -
WebArena:一个提供真实网页交互接口的基准,但由于缺乏可扩展的数据收集和环境重置机制,它被认为是 non-RL-ready 的,即传统的 RL 方法难以在其上有效应用。
-
-
智能体主干模型:Llama-3.2-3B-Instruct, Llama-3.1-8B-Instruct, Qwen-2.5-7B-Instruct。 -
基线方法: -
离线模仿学习:监督微调(SFT)和直接偏好优化(DPO)。 -
在线强化学习:在真实环境中运行的 GRPO 和 PPO 算法。
-
3.2 核心实验结果
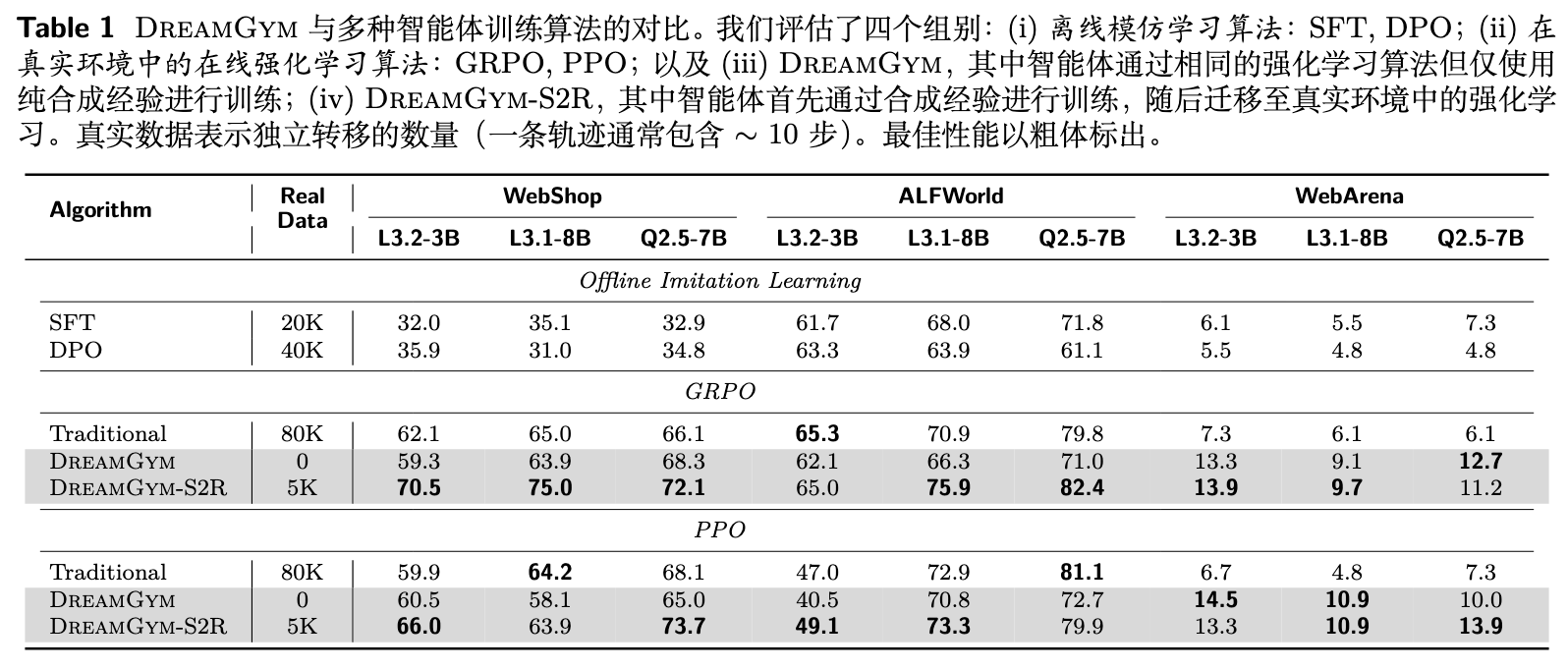
从这张表中,我们可以提炼出几个关键的结论:
-
在 Non-RL-Ready 环境中取得突破:在 WebArena 环境中,传统的 RL 方法(Traditional GRPO/PPO)由于环境限制,性能很差甚至难以运行。相比之下,完全在合成环境中训练的 DREAMGYM 取得了超过 30% 的成功率提升。这表明 DREAMGYM 不仅仅是真实环境 rollouts 的一个廉价替代品,更是一种使强化学习在原本棘手的领域变得可行的关键机制。
-
在 RL-Ready 环境中展现高样本效率:在 WebShop 和 ALFWorld 环境中,完全不使用任何真实交互(Real Data 为 0)的 DREAMGYM,其性能与使用了 80K 次真实交互的传统 GRPO 和 PPO 相当。这一结果有力地证明了 DREAMGYM 在样本效率上的优势。它表明,高质量的合成经验在提升策略方面可以媲美大量的真实经验。
-
Sim-to-Real(S2R)策略的有效性:作者进一步提出了 DREAMGYM-S2R 模式,即先在 DREAMGYM 的合成环境中进行预训练,然后用少量(5K 次)的真实环境交互进行微调。结果显示,DREAMGYM-S2R 的性能一致性地超过了所有基线方法,包括从零开始用 80K 次真实交互训练的传统 RL。例如,在 WebShop 上,使用 Llama-3.1-8B 的 DREAMGYM-S2R 达到了 75.0% 的成功率,显著高于传统 GRPO 的 65.0%。这验证了合成训练可以作为一个高效的“热启动”(warm-start)策略,为后续在真实环境中的学习奠定坚实的基础,从而用更少的数据达到更高的性能。
3.3 训练效率、泛化性与消融研究
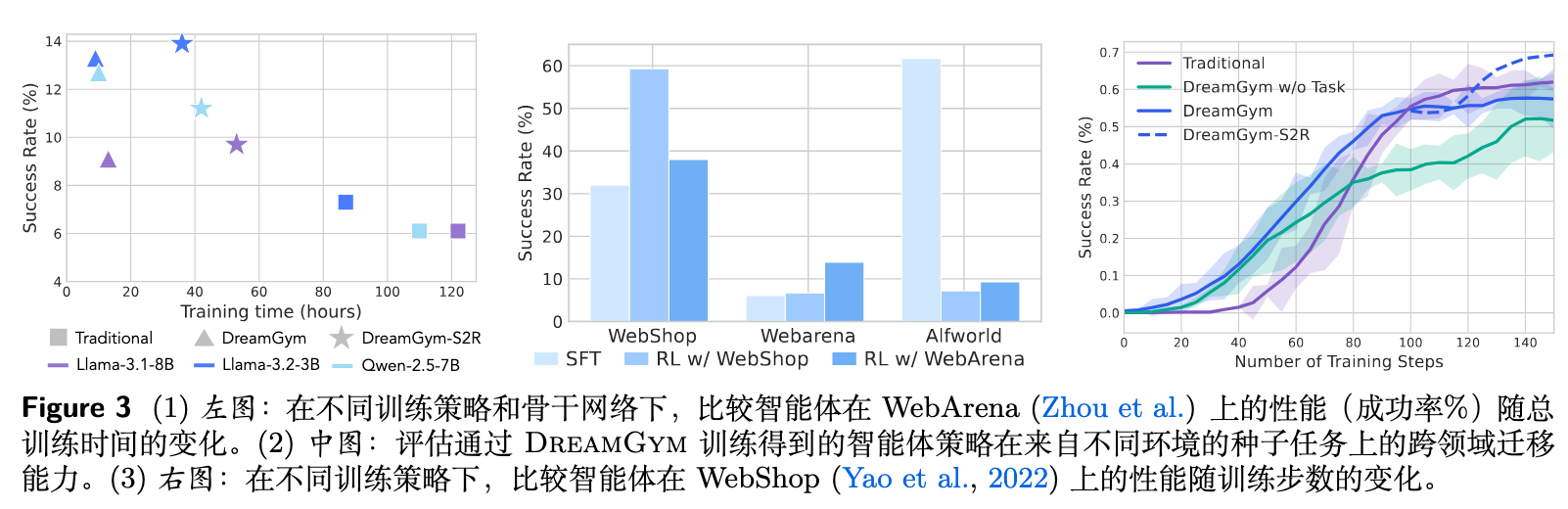
除了核心性能,作者还通过一系列图表分析了其他重要方面。
-
训练效率:
该图 3 的左图显示,在 WebArena 上,DREAMGYM 达到显著性能增益所需的时间成本(包括 rollout 采样和 GPU 小时)仅为真实环境基线的三分之一到五分之一。这主要得益于在轻量级抽象状态空间中的高效交互,以及由统一经验模型提供的密集反馈。 -
泛化性和学习可迁移性:
图 3 的中图实验结果展示了 DREAMGYM 策略的泛化能力。例如,在 WebShop 上训练的策略可以直接迁移到 WebArena 上,并且其性能超过了直接在 WebArena 上训练的 SFT 模型。这种迁移性表明,智能体在 DREAMGYM 的抽象元表征空间中学习到了某种领域无关的行为先验知识,而不仅仅是记忆特定于任务的模式。当然,当领域差距过大时(例如从网页环境迁移到具身控制环境 ALFWorld),性能则会显著下降,这也揭示了当前元表征的局限性。 -
训练曲线分析:
DREAMGYM 的训练曲线(图 3 右)相比于传统 RL 基线(红色)有两个显著特征:1)初始阶段的性能爬升速度更快,表明合成轨迹提供了比稀疏的真实 rollout 更具信息量的梯度;2)学习曲线的方差更小、更平滑,表明合成经验提供了更稳定和一致的反馈信号,缓解了训练不稳定的问题。 -
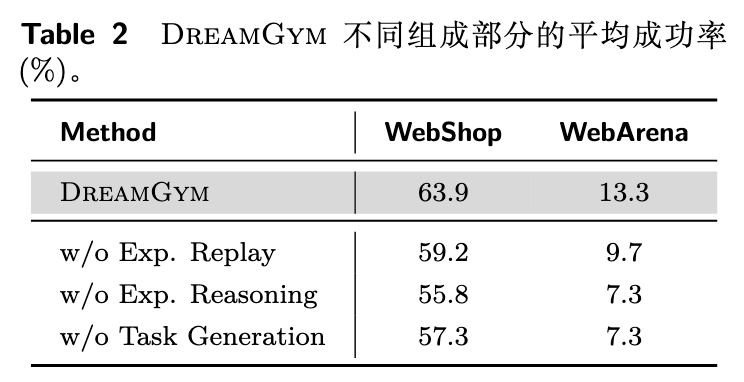
组件消融研究:
为了验证各个组件的必要性,作者进行了消融实验。表 2 结果显示,移除任务生成器(w/o Task Generation)、经验回放(w/o Exp. Replay)或经验推理(w/o Exp. Reasoning)都会导致性能的显著下降。这证实了自适应课程、历史经验的 grounding 以及基于推理的状态生成,对于框架的整体性能都是不可或缺的。 -
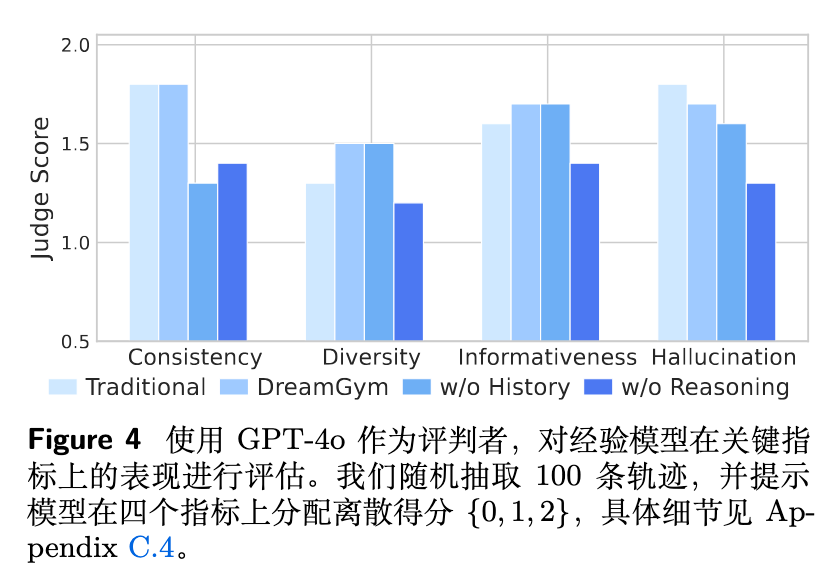
经验模型质量评估:
作者使用 GPT-4o 作为裁判,从一致性、多样性、信息性和幻觉四个维度评估了不同变体生成的经验质量。图 4 结果表明,完整的 DREAMGYM 在各项指标上均表现最佳或接近最佳。移除交互历史(w/o History)会严重损害一致性,而移除推理能力(w/o Reasoning)则会降低信息性并增加幻觉。这再次验证了结构化的、基于推理的经验生成方式对于维持轨迹多样性和真实性的重要性。
4. 理论分析
除了大量的实证分析,作者还在附录中提供了一定的理论分析,探讨了在合成环境中训练的策略在真实环境中的性能保证。
定理 1 (通过合成经验在真实环境中实现策略提升)
作者证明,在一个标准的信任区域策略更新假设下,一个在合成 MDP 中优化的策略,在真实 MDP 中也能保证策略提升,前提是合成 surrogate gain 超过了两个惩罚项。其性能提升的下界可以表示为:
这个不等式虽然形式复杂,但其核心思想是直观的:
-
真实世界的性能提升(左侧)受到三个因素的影响。 -
合成环境中的代理增益(第一项):这是在 DREAMGYM 中训练时直接优化的目标。 -
信任区域惩罚(第二项):这是 PPO/GRPO 等算法为了保证稳定更新而引入的 KL 散度约束所带来的惩罚。 -
经验模型误差(第三项):这是理论分析的关键。这个误差项衡量了合成环境与真实环境的差异。重要的是,这个误差由两个部分决定: -
反馈的忠实度(faithfulness of feedback, ):即合成奖励与真实奖励的差异。 -
状态转移的领域一致性(domain consistency of state transitions, ):即合成状态分布与真实状态分布的 TV 距离。
-
该理论与 DREAMGYM 思路一致:合成环境无需在原始状态层面完美克隆真实环境,它只需要提供领域一致的状态转移和具有回顾性正确的学习信号(即准确的奖励),就能保证在真实环境中的性能提升。 在实践中,通过在带有显式推理轨迹的少量数据上进行训练, 和 都可以被控制在很小的范围内。
往期文章:


