
-
论文标题:MiMo-V2-Flash Technical Report -
论文链接:https://arxiv.org/pdf/2601.02780
TL;DR
小米 LLM-Core 团队近期发布了 MiMo-V2-Flash 技术报告。
核心技术要点:
-
架构创新:采用混合注意力机制,以 5:1 的比例交替使用滑动窗口注意力(SWA,窗口大小仅 128)和全局注意力(GA),并引入可学习的 Attention Sink Bias,在大幅降低 KV Cache 的同时维持了长文性能。 -
多 token 预测 (MTP) :引入轻量级 MTP 模块作为推测解码的草稿模型,在推理阶段实现了最高 2.6 倍的加速。 -
MOPD 后训练范式:提出“多教师在线蒸馏”(Multi-Teacher On-Policy Distillation),通过三个阶段(通用 SFT -> 领域专家 RL -> 学生模型 MOPD)解决了传统模型合并中的能力互斥问题,使单一模型能同时掌握多个领域专家模型的巅峰能力。 -
基础设施:引入 Rollout Routing Replay (R3) 解决 MoE 在 RL 训练中的路由不一致问题,并构建了支持大规模 Agent 训练的仿真环境。
1. 引言
在大语言模型(LLM)向通用人工智能(AGI)演进的过程中,推理链(Reasoning Chains)和自主 Agent 工作流是两个关键驱动力。然而,构建可扩展的推理模型和 Agent 面临着一个共同的瓶颈:长上下文建模必须兼顾速度与性能。
MiMo-V2-Flash 通过 MoE 架构减少计算量,通过极度激进的滑动窗口注意力机制降低显存占用,并通过多 Token 预测(MTP)加速训练和推理。特别是在后训练阶段,该报告详细阐述了如何通过大规模强化学习(RL)和一种新的蒸馏范式(MOPD)来提升模型的综合能力。
2. 模型架构:效率与性能的权衡
MiMo-V2-Flash 基于标准的 Transformer 架构,但在注意力机制和前馈网络(FFN)的设计上进行了显著的优化。
2.1 整体参数配置
-
总参数量:309B -
激活参数量:15B -
层数:48 层 Transformer Block -
隐藏层维度:4096 -
MoE 配置: -
除第一层外,其余层均采用稀疏 MoE FFN。 -
专家总数:256 -
每 Token 激活专家数:8 -
专家中间维度:2048 -
路由机制:无共享专家(No shared experts)
-
-
第一层设计:使用全局注意力(GA)和密集 FFN(Dense FFN),用于稳定早期表征学习。
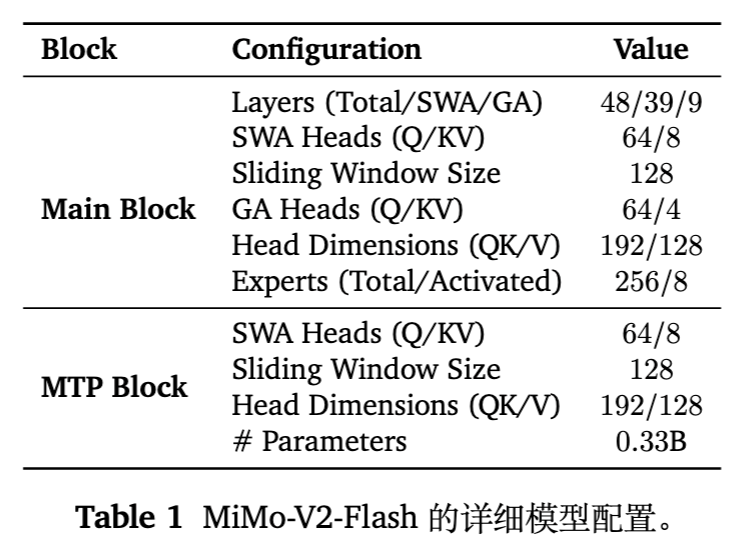
2.2 混合滑动窗口注意力架构 (Hybrid SWA)
为了缓解全注意力机制带来的 复杂度,MiMo-V2-Flash 采用了一种混合注意力架构,交替堆叠滑动窗口注意力(SWA)和全局注意力(GA)。
2.2.1 激进的窗口设计与混合比例
-
混合比例:每 5 层 SWA 后接 1 层 GA(5:1)。 -
窗口大小:。这是一个非常小的窗口设置,相比于常见的 4096 或 2048 窗口,这种设计可以极大地减少 KV Cache 的显存占用和注意力计算量。
2.2.2 可学习的 Attention Sink Bias
先前的研究(如 Gemma Team)表明,过小的滑动窗口或过高的 SWA:GA 比例会导致模型性能下降,特别是在长上下文任务中。为了解决这一问题,MiMo-V2-Flash 引入了可学习的 Attention Sink Bias(注意力汇聚偏置)。
其核心思想是在 Softmax 分母中引入一个可学习的项,允许模型在不需要关注当前窗口内 Token 时,将注意力分配给一个虚拟的 Sink,从而避免强制关注不相关的局部信息。
具体公式如下:
设 和 分别为 token 的查询向量和 token 的键向量, 为头维度。单头的注意力 logits 计算为:
引入可学习标量 作为偏置,注意力权重 计算如下:
其中 是为了数值稳定性引入的最大值项:
最终输出为:
2.2.3 架构消融实验分析
报告中的消融实验(见报告中 Table 2 和 Table 3)揭示了两个反直觉但关键的发现:
-
Attention Sink 的必要性:在 的设置下,如果不加 Sink Bias,模型在 MMLU、GSM8K 等基准上的性能有明显下降。加入 Sink Bias 后,性能恢复甚至超过了全 GA 基线。 -
小窗口 (128) 优于大窗口 (512) : -
在通用基准上, 与 表现相近。 -
但在长上下文扩展(Long Context Extension)和长文 SFT 后, 的版本在 GSM-Infinite 和 MRCR 等长文任务上显著优于 版本,也优于全 GA 基线。
-
原理解读:研究人员假设, 的极小窗口迫使 SWA 层专注于极局部的上下文,作为一种归纳偏置(Inductive Bias),减少了对虚假模式的过拟合。同时,这种强约束迫使模型将长程依赖的处理完全“外包”给 GA 层,导致了更清晰的劳动分工(Division of Labor)。相反, 处于中间地带,导致 SWA 试图处理部分长程依赖但能力不足,模糊了局部与全局的分界线。
2.3 轻量级多 Token 预测 (MTP)
MiMo-V2-Flash 集成了 MTP 模块,不仅为了提升训练效率,更作为一种原生的推测解码(Speculative Decoding)草稿模型。
-
设计原则:轻量化。MTP 模块不应成为推理瓶颈。 -
结构: -
使用 Dense FFN 而非 MoE(减少参数量,单 MTP 块仅 0.33B 参数)。 -
使用 SWA 而非 GA(减少 KV Cache 开销)。
-
-
训练与推理: -
预训练时使用单个 MTP 头。 -
后训练阶段,将该头复制 次形成 步 MTP 模块,联合训练。 -
推理时,MTP 模块并行生成 Draft Tokens,主模型并行验证,从而在不增加 KV Cache I/O 的情况下提升算术强度(Arithmetic Intensity),实现 Token 级并行。
-
3. 预训练:从 32K 到 256K 的演进
预训练数据量达到 27T tokens,数据处理流程强调长文网页文档和高质量代码库(包括 commit history, issues 等)。
3.1 数据调度器 (Data Scheduler)
预训练分为三个阶段,逐步提升上下文长度和推理能力:
-
阶段 1 (0 - 22T) :
-
目标:通用基础能力。 -
上下文:原生 32K 长度。 -
设置:RoPE base frequency = 640,000 (GA) / 10,000 (SWA)。
-
-
阶段 2 (22 - 26T) :
-
目标:强化逻辑推理和代码能力。 -
数据变化:上采样以代码为中心的数据,加入约 5% 的合成推理数据。
-
-
阶段 3 (26 - 27T) :
-
目标:长上下文扩展。 -
上下文:扩展至 256K。 -
数据变化:上采样具有长依赖关系的数据。 -
设置:RoPE base frequency 调整为 5,000,000 (GA)。
-
3.2 混合精度训练
采用类似于 DeepSeek-V3 的 FP8 混合精度框架:
-
BF16:保留给 Attention 输出投影、Embedding、输出头参数。 -
FP32:MoE 路由参数(保证路由稳定性)。 -
FP8:其他大部分计算。
4. 后训练:多教师在线蒸馏 (MOPD)
这是 MiMo-V2-Flash 最核心的创新部分。目前的后训练流水线面临两大挑战:
-
能力不平衡 (Capability Imbalance):提升某项能力(如数学)往往导致其他能力(如通用对话)下降,即“跷跷板效应”。 -
学习效率低下:单一模型难以同时从多个异构数据源中高效学习。
为此,MiMo-V2-Flash 提出了 MOPD (Multi-Teacher On-Policy Distillation) 范式,包含三个阶段。
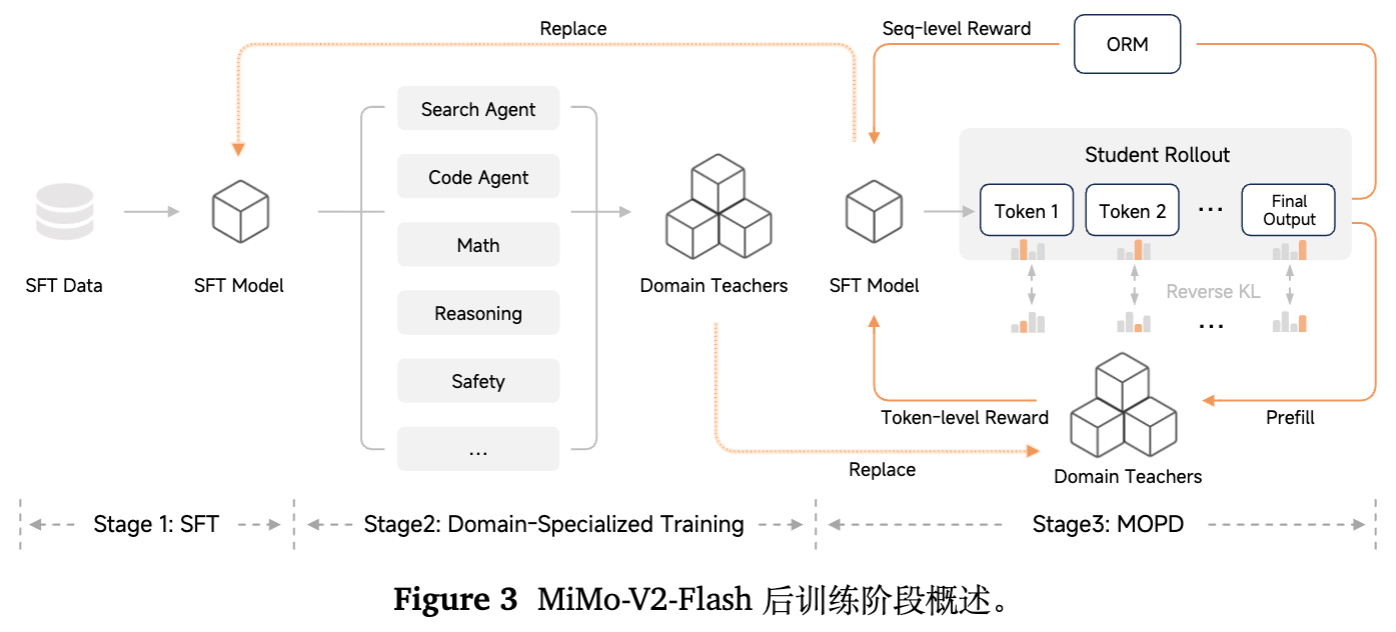
4.1 第一阶段:有监督微调 (SFT)
SFT 的目标是激活模型的基础指令遵循能力。
MoE 训练的稳定性监控:
报告提出利用 num-zeros (梯度为零的参数数量)作为监控 MoE 负载均衡和过拟合的关键指标。
-
num-zeros增加:意味着专家负载严重不平衡。 -
num-zeros减少:意味着模型正在过拟合。 -
稳定性控制:为了保持 num-zeros稳定,AdamW 的 被设置为 ,MoE expert bias update rate 设为 。
4.2 第二阶段:领域专家模型的构建 (Domain-Specialized Training)
与其试图训练一个全能模型,不如先训练多个在特定领域达到巅峰的“教师模型”。这些教师模型通过特定领域的 RL 进行优化。
4.2.1 非 Agent 类 RL (Non-Agentic RL)
针对单轮推理任务(数学、代码、逻辑)。
-
奖励信号: -
客观任务(数学/代码):程序化验证 + LLM Judge。 -
主观任务(安全性/有用性):基于详细评分标准的 LLM Judge。
-
4.2.2 Agent 类 RL (Agentic RL)
针对多轮交互环境,强调规划和工具使用。MiMo-V2-Flash 构建了多样化的 Agent 训练环境:
-
Code Agent:基于 GitHub Issues,涉及文件读写、命令执行。构建了包含 100k+ 任务的轻量级 Agent 脚手架。 -
Terminal Agent:基于 Stack Overflow,涉及 Docker 环境下的复杂运维操作。 -
Web Development Agent:基于网页生成与 Playwright 视觉验证。 -
General Agent:基于搜索和知识图谱扩展的通用任务。
这一阶段产生了一系列在各自领域(如 AIME 数学竞赛、SWE-Bench 代码工程)表现优异的教师模型。
4.3 第三阶段:多教师在线蒸馏 (MOPD)
这是将专家能力融合回统一学生模型的关键步骤。
核心理念:不是简单的参数合并(Parameter Merging),也不是离线数据蒸馏,而是将多教师知识融合形式化为一个在线强化学习 (On-Policy RL) 过程。学生模型从自身的采样分布中学习,并接受来自领域专家的 Token 级监督。
4.3.1 数学形式化
设 为学生策略, 为针对提示词 所在领域的专家教师策略。
反向 KL 散度损失 (Reverse KL Loss) 定义为:
MOPD 的代理损失 (Surrogate Loss) :
类似于 PPO,MOPD 引入了重要性采样和截断机制:
其中 是基于重要性比率(Importance Ratio)的截断系数(类似 PPO 的 clip),而优势函数(Advantage) 定义为学生与教师 Logits 的对数差:
结合结果奖励 (Outcome Rewards) :
MOPD 可以无缝结合基于结果的奖励模型(ORM),例如 GRPO。最终的优势函数为:
4.3.2 MOPD 的优势
-
解决能力互斥:表 7 显示,MOPD 后的学生模型在 AIME(数学)、LiveCodeBench(代码)等任务上不仅没有下降,反而接近或超过了最佳教师模型的性能。 -
避免分布偏移:由于是 On-Policy 的(在学生模型生成的样本上计算教师的 Logits),避免了离线蒸馏中的 Exposure Bias。 -
模块化与可扩展性:可以灵活加入新的领域教师,甚至学生模型本身也可以经过新一轮 RL 成为下一代的教师,形成“迭代协同进化”(Iterative Co-Evolution)。
5. RL 基础设施与工程优化
为了支撑大规模 MoE 的 RL 训练,技术报告披露了几个关键的基础设施优化。
5.1 Rollout Routing Replay (R3)
问题:MoE 模型在推理(Rollout)和训练(Train)阶段,由于数值精度(BF16 vs FP32)、并行切分方式的不同,可能导致对同一输入的专家路由(Router)选择不一致。这会导致 RL 训练不稳定,因为策略更新不仅改变了概率,还隐式改变了生效的模型参数子集。
解决方案 R3:
记录推理阶段选中的专家索引,并在训练反向传播时强制重用这些专家路由。这消除了路由的不确定性,使得 RL 训练更加稳定。小米团队通过优化数据类型和通信重叠,使这一机制的额外开销几乎可以忽略不计。
5.2 数据调度器 (Data Scheduler) 与部分采样
针对 RL 训练中不同任务生成长度差异极大导致的 GPU 空闲(Straggler)问题:
-
细粒度序列调度:不再以 Micro-batch 为单位,而是以序列为单位调度。 -
部分 Rollout (Partial Rollout) :将过长的轨迹(Trajectory)切分为多个步骤进行,配合“陈旧度感知的截断重要性采样”(Staleness-aware truncated importance sampling)来修正因数据滞后带来的偏差。
5.3 附录中的上下文管理 (Context Management)
针对 Agent 任务中无限增长的上下文,报告在附录 C 中提到了一种 Unix 风格的抽象:
-
Context Augmentation:将工具、文档、数据库统一抽象为文件,允许模型通过 Bash 命令检索。 -
Context Consolidation:对抗“Lost in the Middle”。当上下文利用率低时,系统强制模型生成摘要,将历史归档为文件,并在上下文中清除。实验表明,这种“少即是多”的策略在 Deep Research 类任务上提升了 5-10% 的准确率。
6. 性能评估
6.1 通用与推理能力
在 MMLU-Pro, GPQA-Diamond, AIME 2025 等基准上,MiMo-V2-Flash (309B/15B Active) 展现了与 DeepSeek-V3.2 (671B/37B Active) 和 Kimi-K2 相当的竞争力。
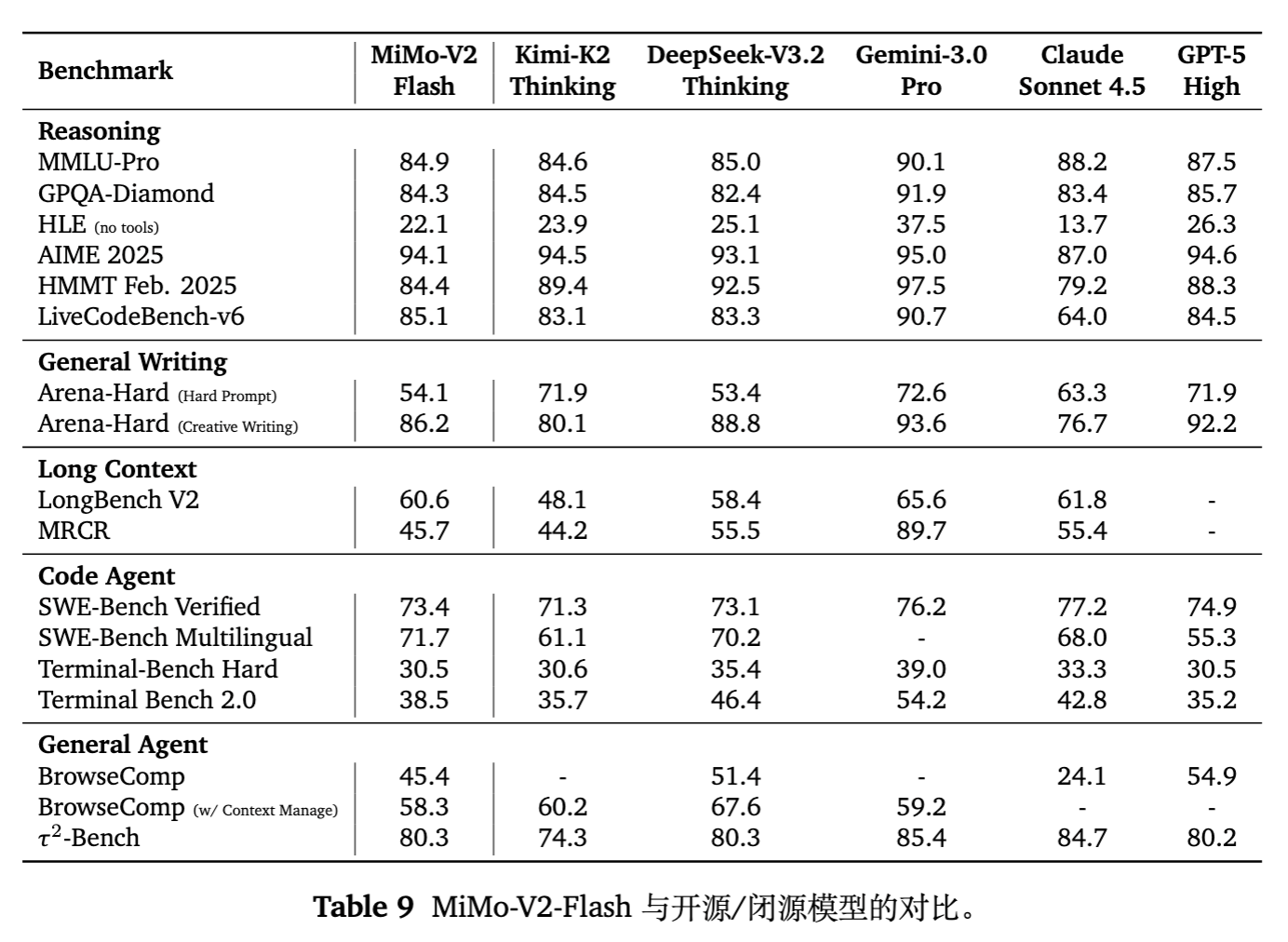
特别值得注意的是 SWE-Bench Verified(软件工程 Agent 任务):
-
MiMo-V2-Flash 达到 73.4% 的解决率。 -
SWE-Bench Multilingual 达到 71.7% 。 -
这确立了其作为当前最强开源代码 Agent 模型的地位,性能接近 GPT-5-High(报告中引用的基准)。
6.2 长上下文能力
得益于混合 SWA 架构:
-
在 NIAH-Multi (大海捞针) 测试中,从 32K 到 256K 均保持近乎 100% 的成功率。 -
在 GSM-Infinite (超长文数学推理) 中,从 16K 到 128K 的性能衰减极小。相比之下,DeepSeek-V3.2-Exp(全注意力/稀疏注意力)在 64K 和 128K 长度下出现了显著的性能下降。这证明了 混合注意力在处理噪声和长程依赖上的鲁棒性。
6.3 MTP 加速效果
报告分析了 MTP 的接受长度(Acceptance Length)与 Token 熵(Entropy)的关系(图 7)。
-
在确定性高的任务(如 WebDev 代码生成)中,平均接受长度可达 3.6 tokens。 -
在不确定性高的任务(如 MMLU Pro)中,接受长度较短。 -
推理加速:使用 3 层 MTP,在不同 Batch Size 下可实现 1.8x 到 2.6x 的解码加速(表 10)。
7. 结论
MiMo-V2-Flash 技术报告展示了小米在高效大模型领域的深入探索。其核心贡献不仅在于训练了一个高性能的 MoE 模型,更在于提出了一套完整的“效率-能力”协同方案:
-
架构侧:证明了极度稀疏的混合滑动窗口注意力(SWA W=128)配合 Attention Sink,可以在不损失长文能力的前提下大幅降低开销。 -
训练侧:MOPD 范式为解决多任务能力平衡提供了一个优雅的 On-Policy RL 解法,使得模型能够吸收多个领域专家的长板。 -
工程侧:MTP 和 R3 等技术的应用,确保了从训练到推理的全流程高效与稳定。
尽管在绝对知识容量(如 SimpleQA)上,受限于 15B 的激活参数量,该模型与超大规模模型仍有差距,但在推理、代码和 Agent 任务上,MiMo-V2-Flash 已经证明了“小”参数量(Active Params)也能实现强性能。
更多细节请阅读原文。
往期文章:


