
-
论文标题:ArenaRL: Scaling RL for Open-Ended Agents via Tournamentbased Relative Ranking -
论文链接:https://arxiv.org/pdf/2601.06487
TL;DR
今天解读一篇来自通义实验室与高德联合发布的论文《ArenaRL: Scaling RL for Open-Ended Agents via Tournament-based Relative Ranking》。该研究针对开放域(Open-Ended)Agent 任务(如复杂旅行规划、深度搜索)中缺乏客观真值(Ground Truth)的问题,指出了当前基于点式(Pointwise)标量奖励模型的“判别崩塌”(Discriminative Collapse)现象。为解决此问题,论文提出了 ArenaRL 框架,引入基于锦标赛的相对排序机制(Tournament-based Relative Ranking)替代传统的绝对评分。
核心贡献包括:
-
理论洞察:量化了开放域任务中,随着策略优化,轨迹间差异减小导致信噪比(SNR)急剧下降的问题。 -
方法创新:设计了过程感知(Process-Aware)的成对评估机制,并提出了种子单败淘汰制(Seeded Single-Elimination)锦标赛拓扑。该拓扑在保持 线性复杂度的同时,实现了接近全连接循环赛(Round-Robin,)的优势估计准确率。 -
基准构建:构建了全流程基准 Open-Travel 和 Open-DeepResearch,涵盖 SFT、RL 训练及多维自动评估。 -
实验效果:在上述基准及公开写作任务上,ArenaRL 显著优于 SFT、GRPO 和 GSPO 等基线,展现了在长程推理和工具调用场景下的稳健性。
1. 引言
随着大语言模型(LLM)能力的演进,Agent 正从被动的问答系统向主动解决复杂问题进化。在数学推理(Math)和代码生成(Code)等确定性任务中,强化学习(RL)通过明确的真值(Ground Truth)信号(如答案正确性、单元测试通过率)取得了显著成效。然而,将 RL 扩展至开放域任务(Open-Ended Tasks)——如个性化旅行规划、行业深度分析报告撰写——面临根本性挑战。
此类任务的特征在于:
-
解空间巨大且非结构化:没有唯一的标准答案。 -
多维度的评价标准:正确性是主观的,涉及推理的严密性、约束条件的满足度(如预算、时间)、以及方案的实用性。 -
缺乏客观真值:无法像数学题那样直接判定对错。
主流的解决方案通常依赖 LLM-as-a-Judge 范式,即利用一个强大的 LLM 作为奖励模型(Reward Model),对 Agent 生成的轨迹进行打分。目前常见的 RL 算法(如 GRPO、GSPO)多假设存在一个能够提供准确标量反馈的奖励函数。
然而,研究团队发现,在开放域场景下,这种依赖点式标量评分(Pointwise Scalar Scoring)的机制存在严重缺陷,导致了所谓的“判别崩塌”,阻碍了模型的进一步优化。ArenaRL 正是为了解决这一核心矛盾而提出的。
2. 判别崩塌
在介绍 ArenaRL 之前,我们需要深入理解当前方法的局限性。
2.1 任务定义
开放域 Agent 任务可形式化为条件轨迹生成问题。给定从任务分布 中采样的查询 ,策略 生成多步交互轨迹 。轨迹 定义为思维链(Chain-of-Thought, )、工具调用()、环境反馈()和最终答案()的交错序列:
RL 的目标是最大化奖励信号 ,同时利用 KL 散度约束策略偏离:
2.2 点式评分的失效机理
在缺乏 (真实效用函数)的情况下,现有方法使用 LLM 给出观测分数 ,其中 是噪声。
判别崩塌是指:随着 Policy 的能力提升,其生成的候选轨迹组 倾向于收敛到高质量的狭窄范围内。此时:
-
组内方差消失():高质量轨迹之间的语义差异变得微小。 -
噪声主导(High Epistemic Uncertainty):LLM Judge 在难以区分微小优势时,其评分波动主要源于解码随机性、长度偏好等非语义因素,导致噪声 的幅度相对于真实的质量差异变得巨大。
[图 1 中文标题:点式评估中的判别崩塌示意图]
如上图(占位)所示,研究团队对 RL 训练过程中的奖励信号进行了统计分析:
-
(组内方差) :单次评估中,一组轨迹得分的差异。 -
(评估噪声) :对同一轨迹进行 次重复评估的得分方差。
统计结果显示, 的量级与 相当,甚至更高。这意味着信噪比(SNR)极低。
对于像 GRPO 这样依赖组内归一化(Group Normalization)的算法:
当 且主要由噪声构成时,归一化操作实际上是在放大噪声。优化过程不再由真实的优势信号驱动,而是拟合 Reward Model 的噪声,导致训练停滞甚至性能退化。
3. ArenaRL
为了从根本上解决判别崩塌,ArenaRL 从决策理论中汲取灵感:成对的偏好判断比点式的定量评估更稳定。ArenaRL 放弃了不稳定的绝对标量分数,转而构建基于组内相对排名(Intra-group Relative Ranking)的在线策略优化框架。
3.1 过程感知的成对评估 (Process-Aware Pairwise Evaluation)
ArenaRL 首先引入了一个专门的 Arena Judge(记为 )。不同于仅对最终答案评分, 接收查询 、两条候选轨迹 以及详细的评价标准 。
评价标准 是过程感知的(Process-Aware),它不仅考查最终答案,还审查:
-
思维链(CoT)的逻辑连贯性。 -
工具调用的精确度。 -
操作的必要性与有效性。
为了消除 LLM Judge 常见的位置偏差(Positional Bias),ArenaRL 采用双向评分协议,交换顺序进行两次评估并求和:
其中 分别是 和 在对比中获得的质量分数。
3.2 锦标赛拓扑结构 (Tournament Topologies)
这是论文最核心的算法贡献部分。
对于一个采样生成的轨迹组 ,如果要获得完全准确的排名,最直接的方法是全连接循环赛(Round-Robin),但其复杂度为 ,对于在线训练而言计算成本过高。
ArenaRL 系统地研究了五种锦标赛拓扑,旨在寻找效率()与准确性(Advantage Estimation Fidelity)之间的最佳平衡。
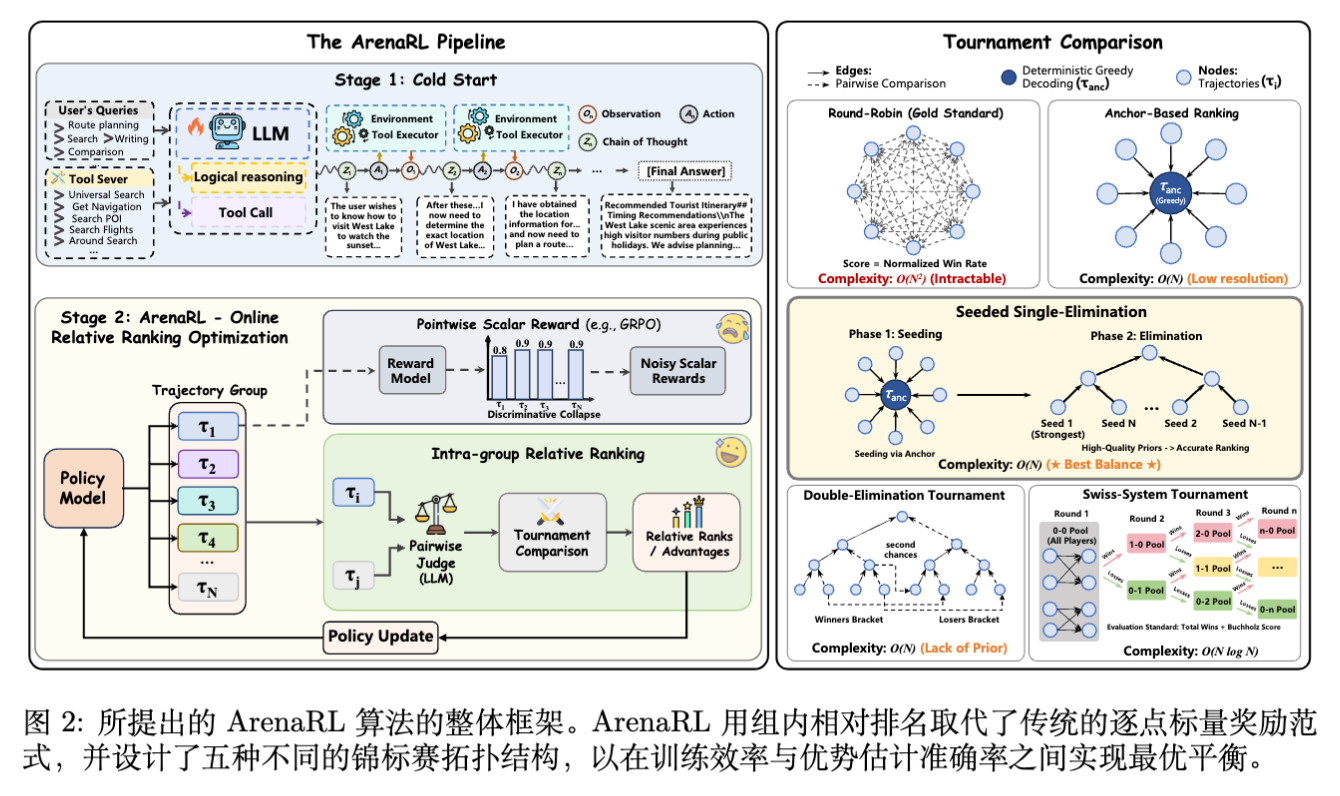
3.2.1 循环赛 (Round-Robin)
-
机制:每条轨迹与其他 条轨迹进行比较。 -
得分:标准化胜率。 -
复杂度:。 -
作用:作为“金标准(Gold Standard)”用于衡量其他拓扑的准确性,但不用于实际训练。
3.2.2 锚点排序 (Anchor-Based Ranking)
-
机制:生成一个确定性的参考轨迹 (通过 Greedy Decoding,)。组内其他 条探索性轨迹()分别与 进行比较。 -
复杂度:。 -
缺陷:分辨率不足。它只能量化样本相对于锚点的优势,难以捕捉两个探索性样本之间的细微差异,导致次优解之间的排名模糊。
3.2.3 瑞士轮 (Swiss-System)与双败淘汰 (Double-Elimination)
-
这也进行了尝试,但在缺乏高质量初始排序的情况下,随机配对容易导致“强强对话”过早发生,使得排名不够准确。
3.2.4 种子单败淘汰制 (Seeded Single-Elimination) —— 最优解
这是 ArenaRL 最终选用的拓扑结构,它结合了锚点法和淘汰制的优点。该算法分为两个阶段:
阶段一:种子排位 (Seeding Phase)
-
利用贪婪解码生成锚点 。 -
将组内所有轨迹 与 进行比较,获得初步分数。 -
根据初步分数对轨迹进行排序,赋予种子顺位(Seed Ranking)。这提供了一个低偏差的初始估计。
阶段二:淘汰赛 (Elimination Phase)
-
构建二叉树锦标赛,配对策略依据种子顺位(如:第 1 名 vs 第 名,首尾匹配),避免强强过早相遇。 -
胜者晋级,败者淘汰。
-
最终排名主要由存活深度决定。对于同一轮次被淘汰的轨迹,依据其累积的平均得分进行细分排名。
优势:
-
复杂度: 次比较,保持线性 。 -
准确性:利用阶段一的“高质量先验”指导阶段二的对阵,保留了极高的排名保真度。
3.3 基于排名的策略优化
无论采用何种锦标赛,最终通过算法得到每条轨迹的相对排名 。ArenaRL 将离散排名转化为归一化的优势信号:
-
分位点奖励映射:
-
标准化优势计算:
其中 是组内 的均值和标准差。
-
最终目标函数:
采用类似于 PPO/GRPO 的形式,包含 Clip 机制和 KL 惩罚:
通过这种方式,ArenaRL 将轨迹组内的相对质量差异转化为稳定的梯度信号,驱动策略向更强的推理和规划能力进化。
4. 开放域 Agent 基准建设
论文指出了现有基准的不足:大多是静态测试集(如 VitaBench, DeepResearchBench),缺乏配套的训练管线(SFT -> RL -> Eval)。为此,作者构建了两个高质量基准:Open-Travel 和 Open-DeepResearch。
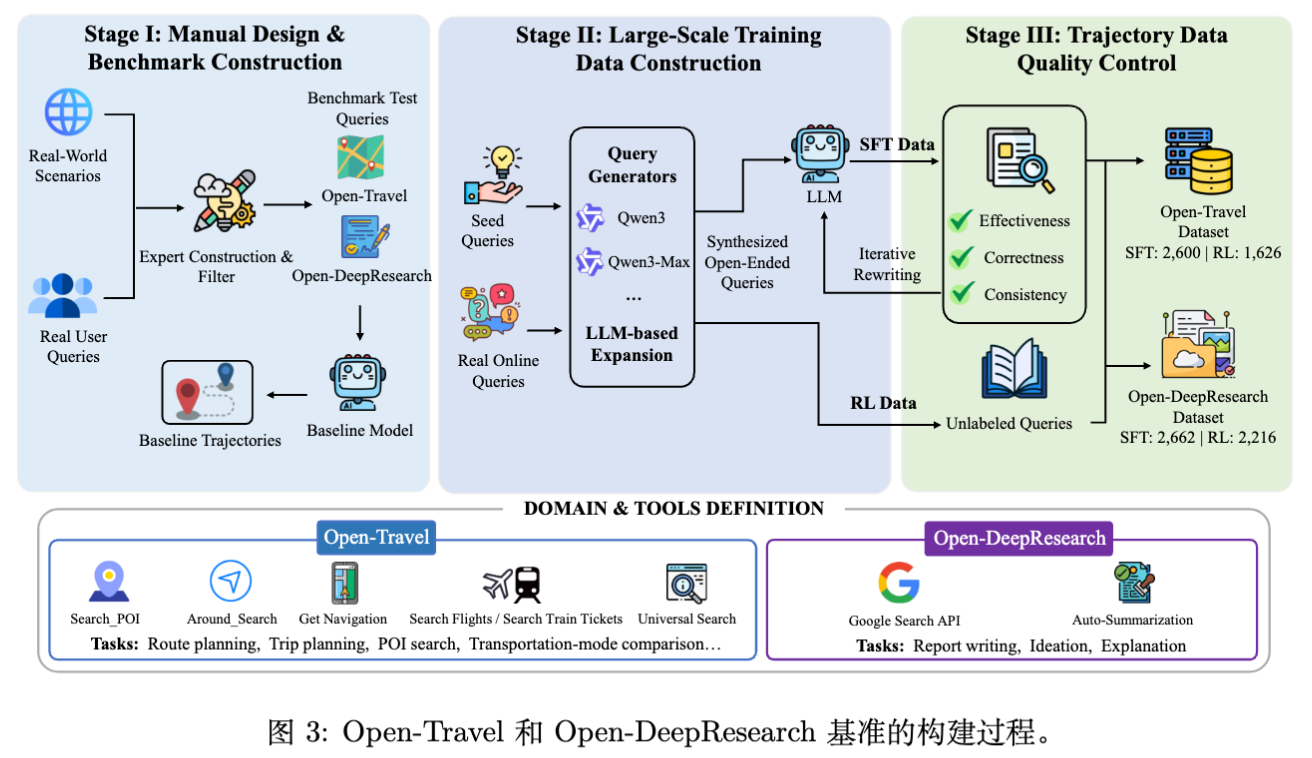
4.1 数据构建流程
构建过程包含三个阶段:
-
基准设计与数据收集:从真实业务场景(如高德地图日志)抽象出用户 Query,并经专家多轮清洗。 -
大规模训练数据构造: -
Seed Queries:手工构造少量高质量种子。 -
LLM Expansion:利用不同风格的模型(如 Qwen3, Qwen3-Max)作为“Query Generators”扩充数据,覆盖多样的业务场景。 -
Baseline Trajectories:利用闭源强模型生成工具调用轨迹,作为 SFT 的冷启动数据。未包含 SFT 轨迹的 Query 则保留用于 RL 阶段。
-
-
轨迹数据质量控制:通过“规则+模型”双重校验。检查工具调用的有效性、对话内容的正确性以及最终答案的一致性。
4.2 领域定义
Open-Travel
-
任务:多约束下的复杂行程规划。 -
子任务: -
Direction:含多个途经点的路线规划。 -
1-Day:单城市一日游规划。 -
Compare:交通方式比价与决策。 -
Search:周边 POI 深度搜索。 -
M-Day:跨天多城市长途规划(作为泛化测试集,不包含在 SFT 数据中)。
-
-
特点:硬约束多(预算、时间窗、同行人偏好),需要精细的工具参数调整。
Open-DeepResearch
-
任务:自主信息检索与长文报告生成。 -
子任务:技术文档撰写、研究课题构思、复杂概念综述。 -
特点:长程规划、海量信息筛选、多轮搜索迭代。
4.3 数据规模与评估
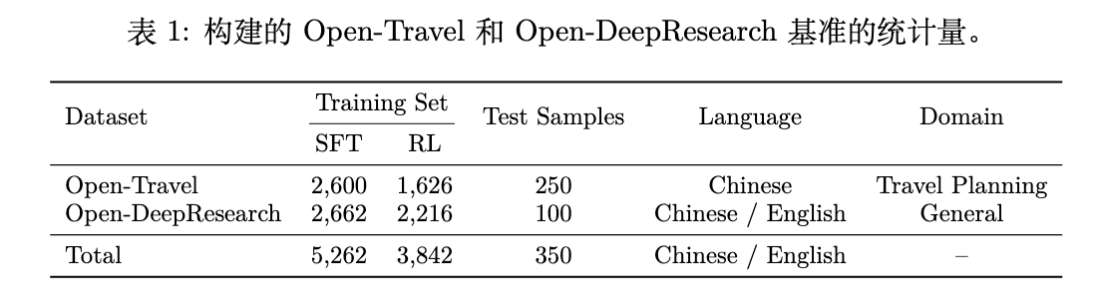
-
Training Set:Open-Travel (2,600 SFT / 1,626 RL),Open-DeepResearch (2,662 SFT / 2,216 RL)。 -
Test Set:250 个 Travel 样本,100 个 Research 样本。 -
评估方式: -
采用 Dual-Judge 机制(两个不同家族的强力闭源模型)进行成对胜率评估。 -
Open-DeepResearch 特别增加了 Valid Generation Rate (Val. %) 指标,因为长程任务容易出现 Context Overflow 导致生成失败。
-
5. 实验与结果分析
5.1 实验设置
-
基座模型:Qwen3-8B-Base。 -
训练范式:Cold-Start SFT RL。 -
基线对比: -
闭源模型:GPT-4o, Grok-4, Gemini-2.5-pro, Claude-3.7-Sonnet。 -
RL 算法:GRPO, GSPO(均采用标准的 Pointwise LLM-as-a-Judge 设置,使用相同的 Judge 模型以保公平)。
-
-
超参数:RL 阶段 Group Size (Open-Travel 为 组,Research 为 )。
5.2 锦标赛拓扑分析
实验首先验证了不同拓扑结构的有效性(基于 Open-Travel Benchmark)。
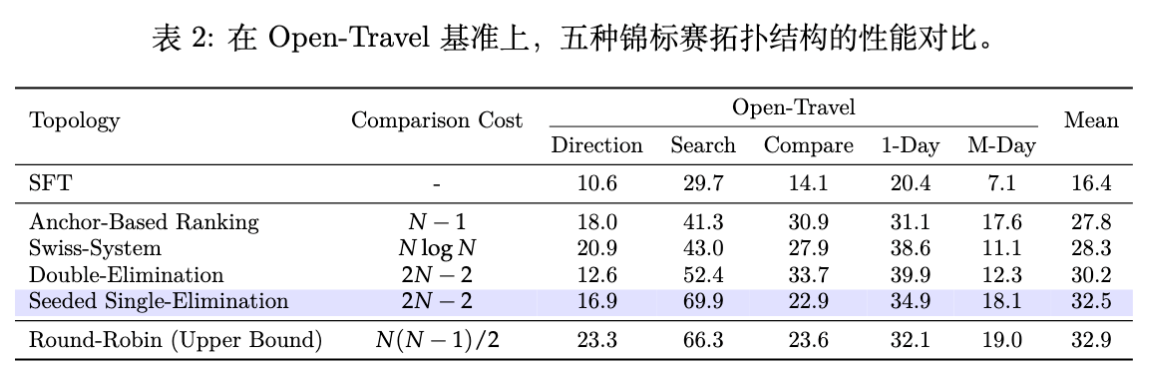
数据表明:
-
Round-Robin (Upper Bound) :平均胜率 32.9%,但计算成本极高。 -
Seeded Single-Elimination (ArenaRL) :平均胜率 32.5%,几乎追平 Round-Robin,且成本仅为线性。 -
Anchor-Based:胜率 27.8%,因分辨率不足表现稍逊。 -
Swiss / Double-Elimination:表现不佳,证明了在 预算下,缺乏高质量初始先验(Seeding)会导致评估失准。
结论:种子单败淘汰制实现了效率与性能的最佳权衡。
5.3 主实验结果
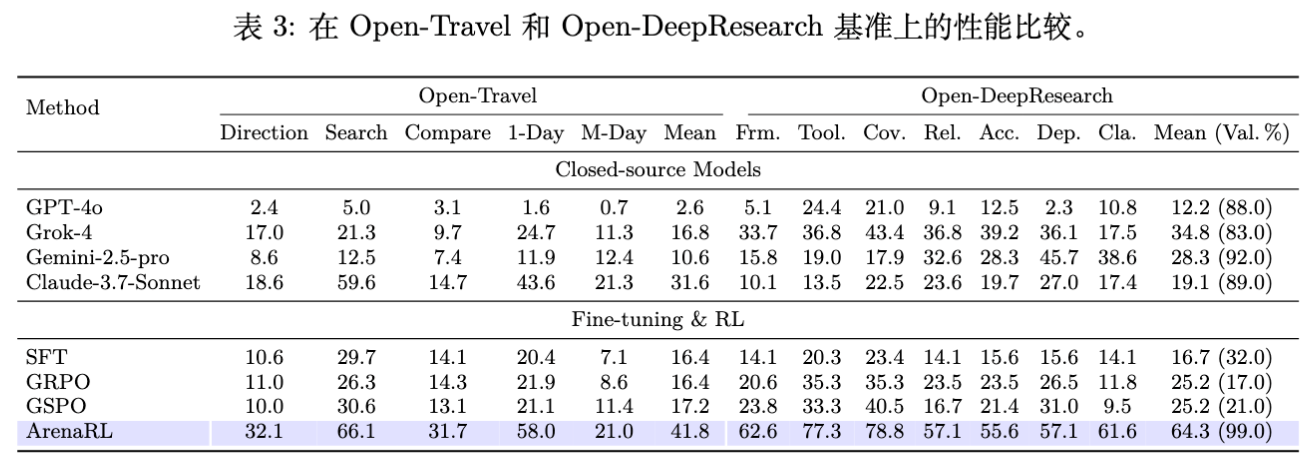
Open-Travel 表现
-
ArenaRL (41.8%) 显著优于 GRPO (16.4%) 和 GSPO (17.2%) 。 -
ArenaRL 在所有子任务上均取得最佳成绩,特别是在极其复杂的 Search 任务上,达到了 66.1% 的胜率。 -
SFT 基线仅为 16.4%,说明 RL 阶段带来了实质性的策略提升。
Open-DeepResearch 表现
-
有效生成率 (Val. %) :ArenaRL 达到了 99.0% ,而 SFT 仅为 32.0%,GRPO 为 17.0%。这表明传统的 Pointwise 奖励在长程任务中容易因长度偏好或无法捕捉中间步骤质量,导致模型生成过长无效内容或无法完成任务。 -
胜率:在有效生成的样本中,ArenaRL 取得了 64.3% 的平均胜率,全面碾压基线。
公开写作任务泛化性
为了证明方法的通用性,作者还在 WritingBench, HelloBench, LongBench-write 三个公开数据集上进行了测试。
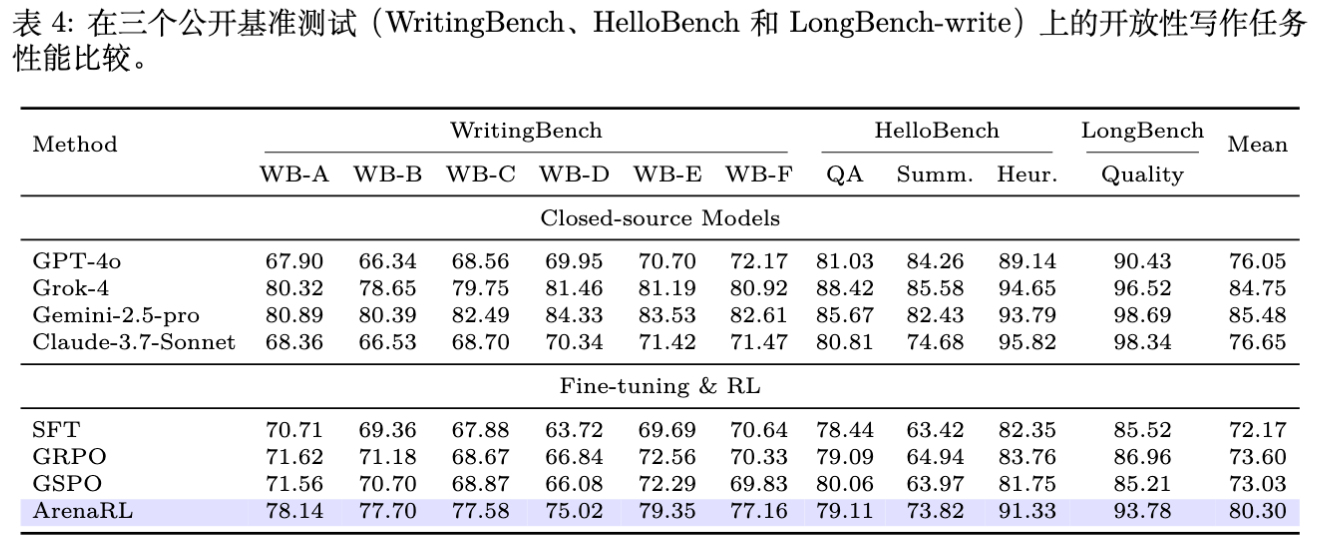
结果显示,ArenaRL 在通用写作任务上也保持了领先优势,特别是在长文写作(LongBench-write)上,得益于对逻辑和结构的成对比较优化,提升显著。
5.4 深入分析
5.4.1 Group Size () 的影响
实验测试了 。
-
结果呈现单调递增趋势。即便 (最基础的成对比较),效果也优于 SFT。 -
当 时,性能提升最为显著。这表明:扩大候选池能有效拓宽探索空间,增加发现高质量(长尾)轨迹的概率,从而让模型学到更优的策略。
5.4.2 评估一致性
LLM Judge 与人类评估的一致性达到了 73.9% ,且混淆矩阵主要集中在对角线。这说明 RL 的提升不仅仅是拟合了 Judge 的偏见,而是真正符合人类价值观的提升。
5.4.3 真实业务场景落地
在高德地图(Amap)的实际业务数据上:
-
确定性 POI 搜索:准确率提升 75%-83%。 -
开放式规划(模糊意图):核心业务指标提升从 69% 涨至 80%。
这证明了 ArenaRL 具有极强的实战价值,能够处理真实用户模糊、复杂的查询。
6. 案例研究
论文展示了一个具体的 Open-Travel 案例:
-
Query:成都到青城后山两日周末徒步,2人,预算600元/人,侧重自然风光和摄影。 -
SFT 模型:倾向于复述用户需求,推理轨迹与用户意图不匹配,忽略了“后山”的具体位置和交通衔接,给出的建议泛泛而谈。 -
ArenaRL 模型:展现了极强的战略规划能力。 -
主动调用工具检索多个目标景点(泰安古镇、五龙沟等)。 -
进行逻辑严密的路线规划(从 A 到 B 到 C)。 -
最终生成的行程单极具说服力,且完全满足预算和偏好约束。
-
这一对比直观地展示了 Tournament-based Ranking 机制如何激励模型去“探索”并“保留”那些推理更严密、工具使用更高效的策略。
更多细节请阅读原文。
往期文章:


