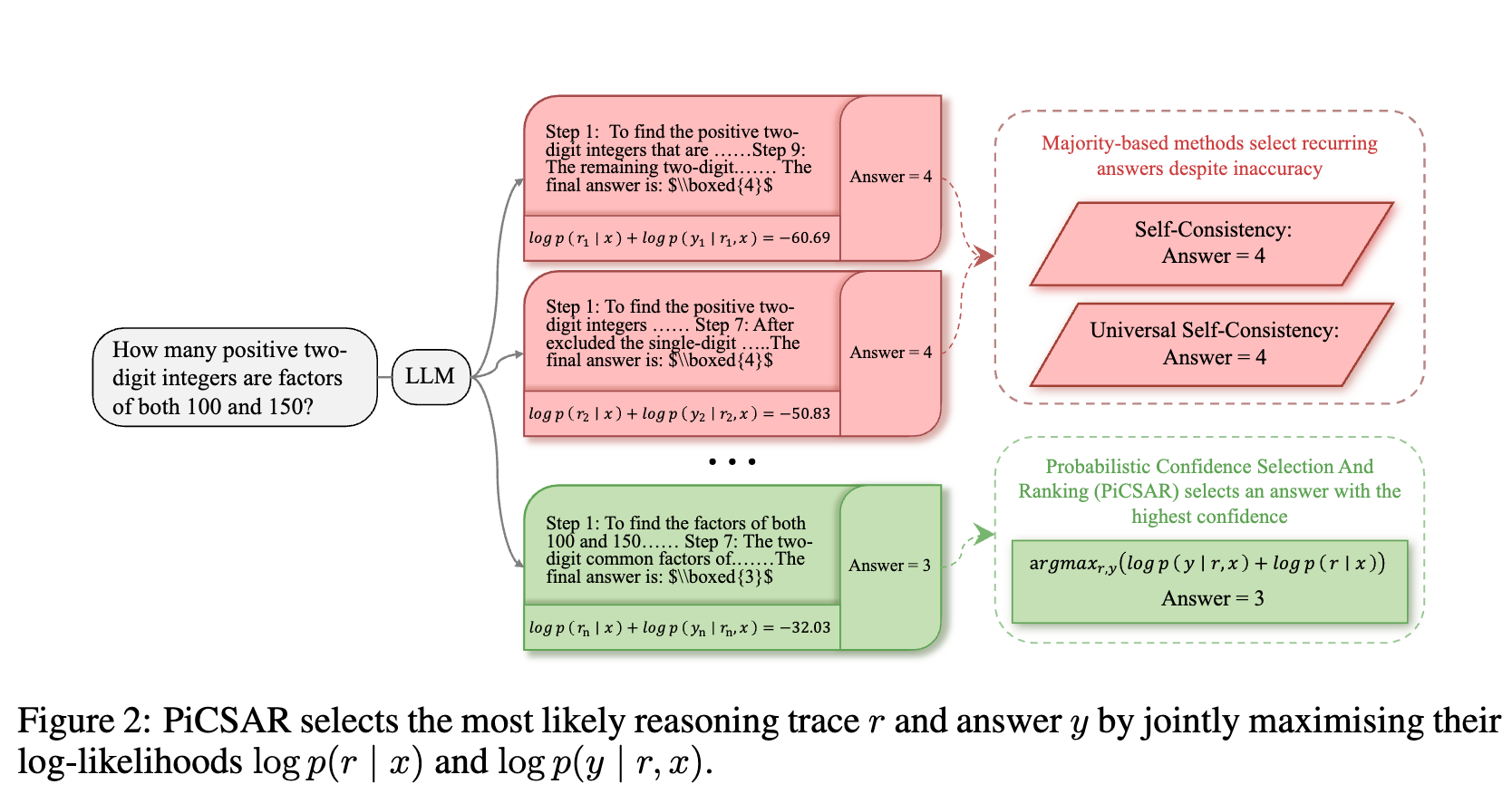
BoN (Best-of-n) 策略的成败关键在于如何设计一个有效的评分函数(Scoring Function),用以在没有真实答案作为参照的情况下,准确地识别出哪条推理链是正确的。目前,一种常见且简单的方法是“自洽性”(Self-Consistency)。它通过在多个生成结果中进行“投票”,选择出现频率最高的答案。这种方法虽然在一定程度上提升了性能,但其局限性也显而易见:它完全依赖于最终答案,忽略了推理过程本身的质量。当模型“自信地”犯错时,多个错误的推理过程可能导向同一个错误答案,从而误导选择。
为了应对这一挑战,来自帝国理工学院、爱丁堡大学等机构的研究人员提出了一种名为 PICSAR (Probabilistic Confidence Selection And Ranking) 的新方法。PICSAR 是一种简单且无需额外训练的推理时(inference-time)工具,它通过评估每个候选方案的“推理过程”和“最终答案”的联合概率,来挑选出最可靠的解答。

-
论文标题:PiCSAR: Probabilistic Confidence Selection and Ranking for Reasoning Chains -
论文链接:https://arxiv.org/pdf/2508.21787
PICSAR详解
PICSAR 的核心思想是,一个高质量的推理链不仅应该得出一个可信的答案,其推理过程本身也应该是合理且流畅的。因此,PICSAR 的评分机制不再仅仅关注最终答案,而是通过一个联合概率模型来同时评估推理过程和最终答案。
核心思想与评分函数
给定一个输入提示(prompt) ,模型会生成一系列候选的推理链(reasoning chain) 及其对应的最终答案(answer) 。PICSAR 的目标是从这些候选的 对中,找到联合条件概率 最大的那一个。
根据概率论的链式法则,这个联合概率可以分解为两个部分的乘积:
为了便于计算和分析,PICSAR 在对数空间(log-space)中定义其评分函数。这样,乘法就转换为了加法,最终的评分函数 由两个关键部分相加而成:
这个公式优雅地将评分标准分解为两个直观且互补的维度:推理置信度 (Reasoning Confidence) 和 答案置信度 (Answer Confidence) 。
1. 推理置信度 (Reasoning Confidence)
推理置信度由 项表示。它衡量的是在给定输入 的条件下,模型生成特定推理链 的概率。这个值是通过将推理链中每个词元(token)的对数概率进行累加得到的。
其中, 是推理链中的第 个词元。
作用:推理置信度可以被视为一个“粗粒度过滤器”。它评估的是整个推理路径的“似然性”或“流畅度”。一个在语言模型看来非常“自然”、概率高的推理过程,通常意味着其逻辑更加连贯,更符合模型在训练数据中学到的模式。这个指标能够有效筛除那些逻辑跳跃、不连贯或者包含模型自身不确定步骤的推理链。
2. 答案置信度 (Answer Confidence)
答案置信度由 项表示。它衡量的是在给定输入 和已经生成的推理链 的条件下,模型对最终答案 的确信程度。
在实际操作中,直接计算这个概率存在一个挑战:模型在生成推理链 之后,可能会继续生成其他文本,导致答案 的概率难以界定。为了解决这个问题,PICSAR 采用了一种巧妙的技巧:它在推理链 之后附加一个特定的指令提示(instruction prompt),记为 ,例如:“根据前面的推理,请直接给出最终答案”。然后,模型在这个增强后的上下文 中生成最终答案 ,并计算其对数概率。因此,实际计算的是 。
作用:答案置信度可以被视为一个“细粒度鉴别器”。它关注的是推理过程和最终结论之间的逻辑蕴含关系。即使两条推理链的“流畅度”(推理置信度)相似,但如果其中一条能让模型更有把握地得出最终答案,那么这条推理链的质量通常更高。这个指标在多个候选推理链看似都合理时,能够起到决定性的区分作用。
通过结合这两个互补的信号,PICSAR 能够识别出那些不仅过程合理,而且结论可靠的推理链,从而避免了仅依赖最终答案投票所带来的问题。
PICSAR 算法流程
PICSAR 的实现过程非常直接,可以总结为以下几个步骤,如论文中的算法1所示。

-
生成候选集:针对一个给定的问题 ,使用语言模型进行 次采样,生成 个独立的候选推理链 。 -
评分候选集: -
对于每一个候选推理链 : -
提取答案:从 中解析出最终答案 。 -
计算推理置信度:从生成过程中直接获取 。 -
计算答案置信度:将 与特定指令 拼接,计算模型在此基础上生成答案 的对数概率 。 -
计算最终得分:将推理置信度和答案置信度相加,得到 Score()。
-
-
-
选择最佳:在所有候选者中,选择得分最高的那一个,其对应的推理链 和答案 即为最终输出。
此外,研究者还提出了一个变体 PICSAR-N,它对推理置信度项进行了长度归一化(除以推理链的词元数量 N)。这种归一化方法旨在消除模型对生成较短或较长推理链的固有偏好,在某些模型和任务上可能会带来更好的效果。
实验设置
为了全面评估 PICSAR 的有效性,研究者们在一系列模型、数据集和基线方法上进行了广泛的实验。
-
模型:实验覆盖了多个主流的 LLM 和 LRM 家族,包括: -
LLMs: Llama-3.1-Instruct (8B, 70B), Gemma-2-Instruct (9B), Qwen3 (8B, 32B)。 -
LRMs: DeepSeek-R1 系列的蒸馏模型 (DS-distill-Llama-3.1-8b, DS-distill-Qwen-2.5b) 和开启了思维模式的 Qwen-3-8B。
-
-
数据集:评估采用了多个公认的、具有挑战性的推理基准测试: -
LLM 评估: GSM8K (小学数学应用题), SVAMP (不同结构数学应用题), MATH500 (高中竞赛数学题), GPQA-Diamond (研究生水平高难度问答)。 -
LRM 评估: 除了上述数据集,还增加了难度更高的 AIME2024 和 AIME2025 (美国数学邀请赛题目)。
-
-
基线方法:PICSAR 的性能与以下几种方法进行了对比: -
Greedy Decoding: 确定性解码,总是选择概率最高的词元。 -
Self-Consistency (SC): 基于最终答案投票的常用方法。 -
Universal Self-Consistency (USC): SC 的一种扩展,利用 LLM 自身来判断哪个答案最一致,适用于自由格式的回答。 -
Self-Certainty: 一种利用模型置信度进行选择的方法。
-
实验结果
实验结果有力地证明了 PICSAR 的有效性和样本高效性。
在大型语言模型(LLMs)上的表现
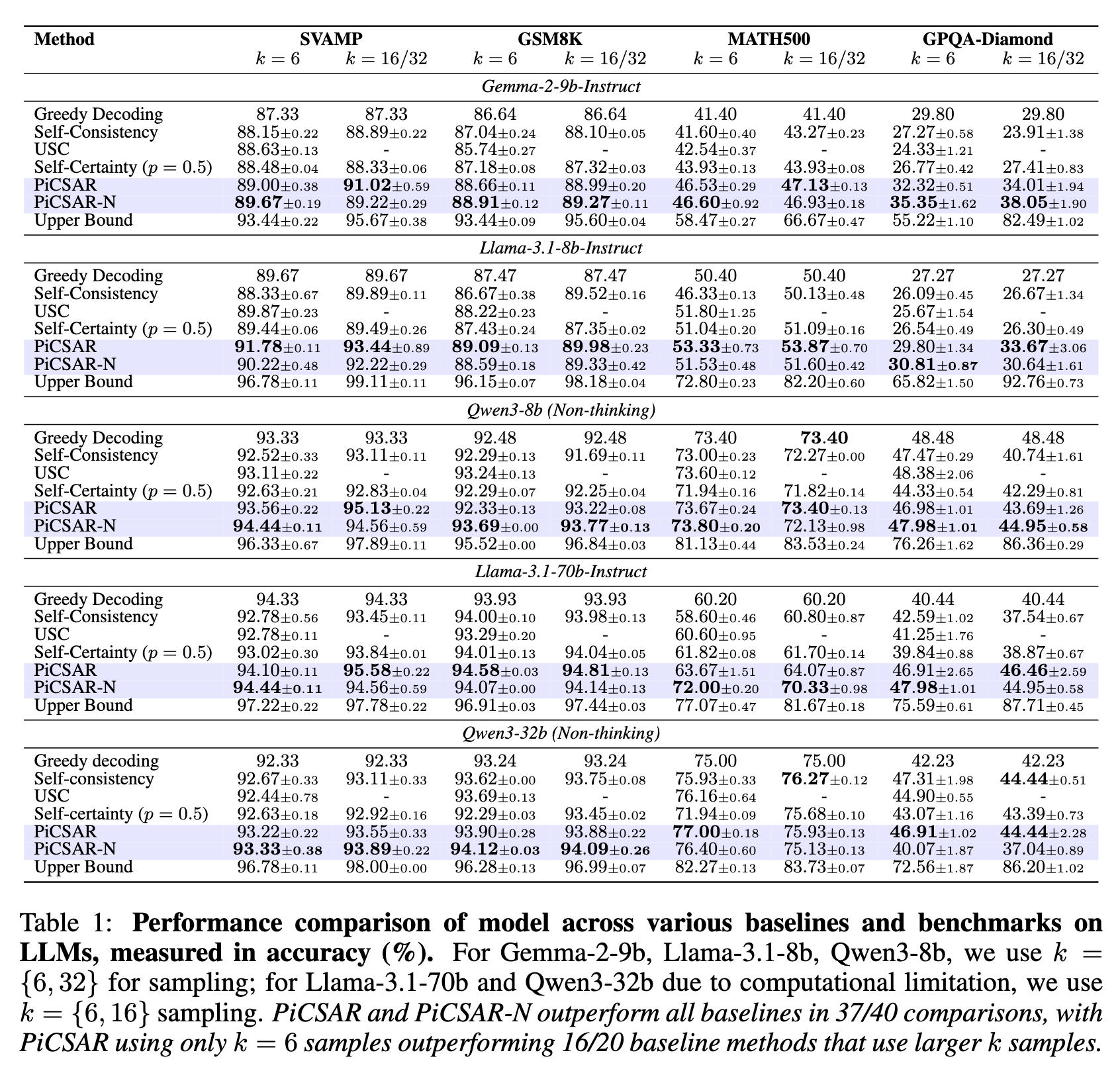
如论文中的表1所示,在40组对比实验中,PICSAR 和 PICSAR-N 在37组中超过了所有基线方法。这一结果验证了论文的核心假设:模型的概率置信度提供了比基于频率的选择更丰富、更有效的信息。
一个值得关注的发现是 PICSAR 的样本高效性 (Sample Efficiency) 。在使用少量样本(例如 k=6)的情况下,PICSAR 的性能常常能够超越使用更多样本(k=16 或 k=32)的 Self-Consistency 等基线方法。这表明,正确的推理链往往存在于一个较小的候选集中,提升选择算法的质量比单纯增加样本数量更为重要。例如,在 MATH500 数据集上,使用 Llama-3.1-70B 模型和 k=6 的 PICSAR-N,准确率达到了 72.00%,而 k=16 的 Self-Consistency 准确率仅为 60.80%。
在大型推理模型(LRMs)上的表现
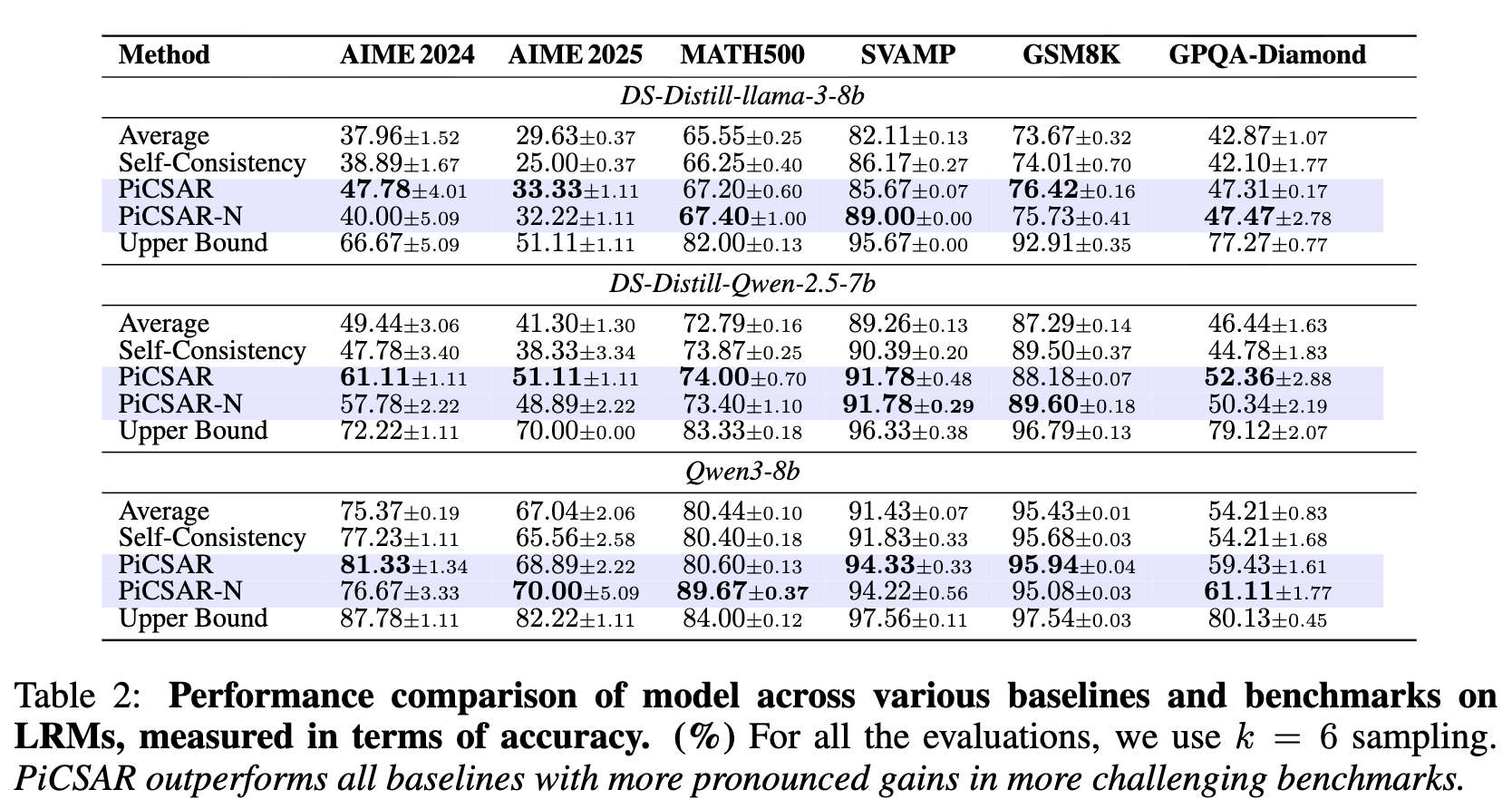
在更专业的 LRMs 上,PICSAR 的优势表现得更为明显,尤其是在高难度任务上。如表2所示,PICSAR 在所有18组对比中均优于基线方法。
-
在 AIME2024 和 AIME2025 数据集上,相对于 Self-Consistency,DS-Distill-Llama-3-8B 模型使用 PICSAR 后准确率分别提升了 8.89% 和 8.33%。 -
DS-Distill-Qwen-2.5-7B 模型的提升更为显著,分别达到了 12.33% 和 12.78%。 -
在 GPQA-Diamond 数据集上,PICSAR 同样带来了 5% 到 7% 的准确率提升。
这些结果表明,当模型本身具备较强的推理能力时,PICSAR 的双重置信度评估框架能更有效地从高质量的候选者中筛选出最优解。
置信度信息平面 (Confidence Information Plane) 分析
为了更直观地理解 PICSAR 为何有效,研究者们提出了“置信度信息平面”的可视化分析。他们将生成的样本点绘制在一个二维平面上,其中 x 轴代表推理置信度,y 轴代表答案置信度。
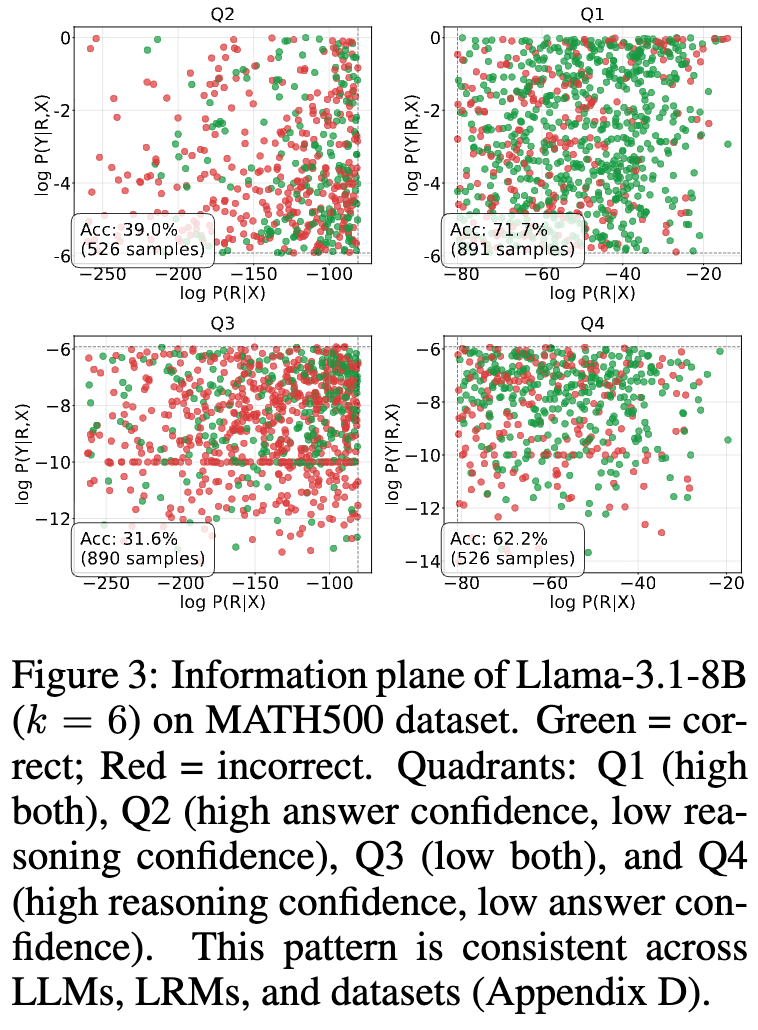
从上图可以清晰地看到一个显著的模式:正确的答案(绿色点)压倒性地集中在右上角区域,即同时具有高推理置信度和高答案置信度的区域。而错误的答案(红色点)则分布在其他区域。具体来看,右上象限 (Q1) 的准确率达到了 71.7%,远高于其他象限。
这个发现为 PICSAR 的设计提供了有力的经验支持。通过最大化推理置信度和答案置信度的联合得分,PICSAR 正是在这个高准确率的“黄金象限”中寻找最佳答案。
置信度可移植性:解耦生成与评估
PICSAR 的一个有趣且具有实践价值的特性是其置信度的可移植性。研究者们设计了一项解耦实验:使用一个模型(生成模型, )来产生推理链,然后使用另一个不同的模型(评估模型, )来计算答案置信度 。
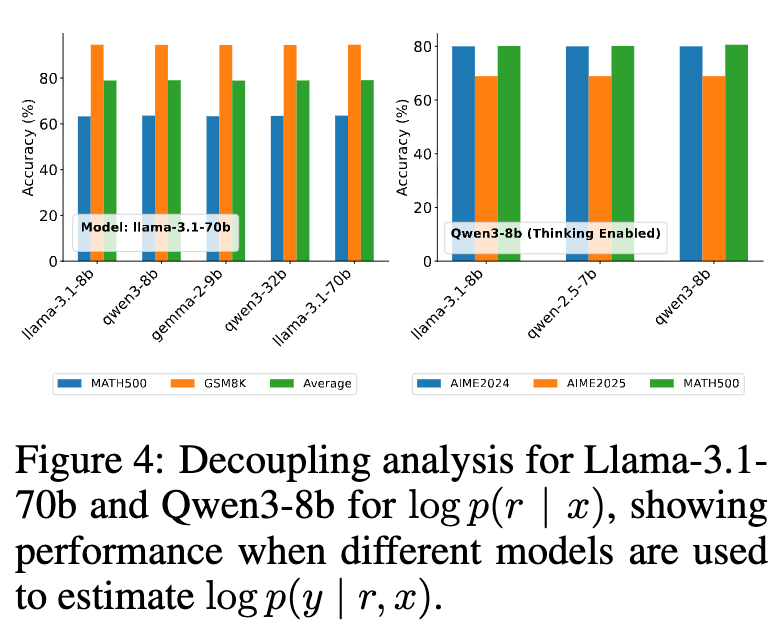
实验结果显示,即使评估模型比生成模型小得多,最终的准确率也仅有轻微下降。例如,使用强大的 Llama-3.1-70b 作为生成模型,而使用小得多的 Llama-3.1-8b 或 Gemma-2-9b 作为评估模型,系统整体性能依然保持在较高水平。
这一发现意义重大。它表明答案置信度 并非仅仅是特定模型的内部产物,而是在一定程度上捕捉到了推理链 和答案 之间更本质的逻辑蕴含关系。在实际应用中,这意味着我们可以使用一个计算成本高昂的先进模型来生成高质量的推理过程,然后将评分任务“外包”给一个更小、更经济的本地模型来完成,从而在保持高性能的同时,显著提升了计算效率和部署灵活性。
模型内可靠性 vs. 模型间差异性
进一步的分析揭示了 PICSAR 分数的双重特性:
-
模型内可靠性 (Intra-Model Reliability):对于同一个模型而言,PICSAR 的置信度分数是预测答案正确性的可靠指标。回归分析显示,置信度分数与答案正确率之间存在显著的正相关关系。 -
模型间差异性 (Inter-Model Variance):不同模型或不同架构的置信度分数的绝对值是不可直接比较的。例如,实验发现 Qwen 家族模型的准确率和置信度分数随模型尺寸的变化并非单调递增,这与 Llama 家族的行为不同。
这意味着,虽然我们不能用 PICSAR 分数来评判哪个模型更好,但它可以作为一个稳定有效的工具,在任何给定的模型内部,从多个候选答案中选出最好的一个。
句子级置信度动态:正确推理更“信息密集”
为了探究推理过程内部的动态变化,研究者分析了答案置信度在逐句处理推理链时的演变过程。他们定义了一个“峰值句”(peak),即那些使得答案置信度超过某个阈值(例如95分位数)的句子。通过计算“峰值句与总句子数的比率”,他们发现:
-
更高得分的推理链具有更高的“峰值句比率”。 -
更高准确率的推理链也具有更高的“峰值句比率”。
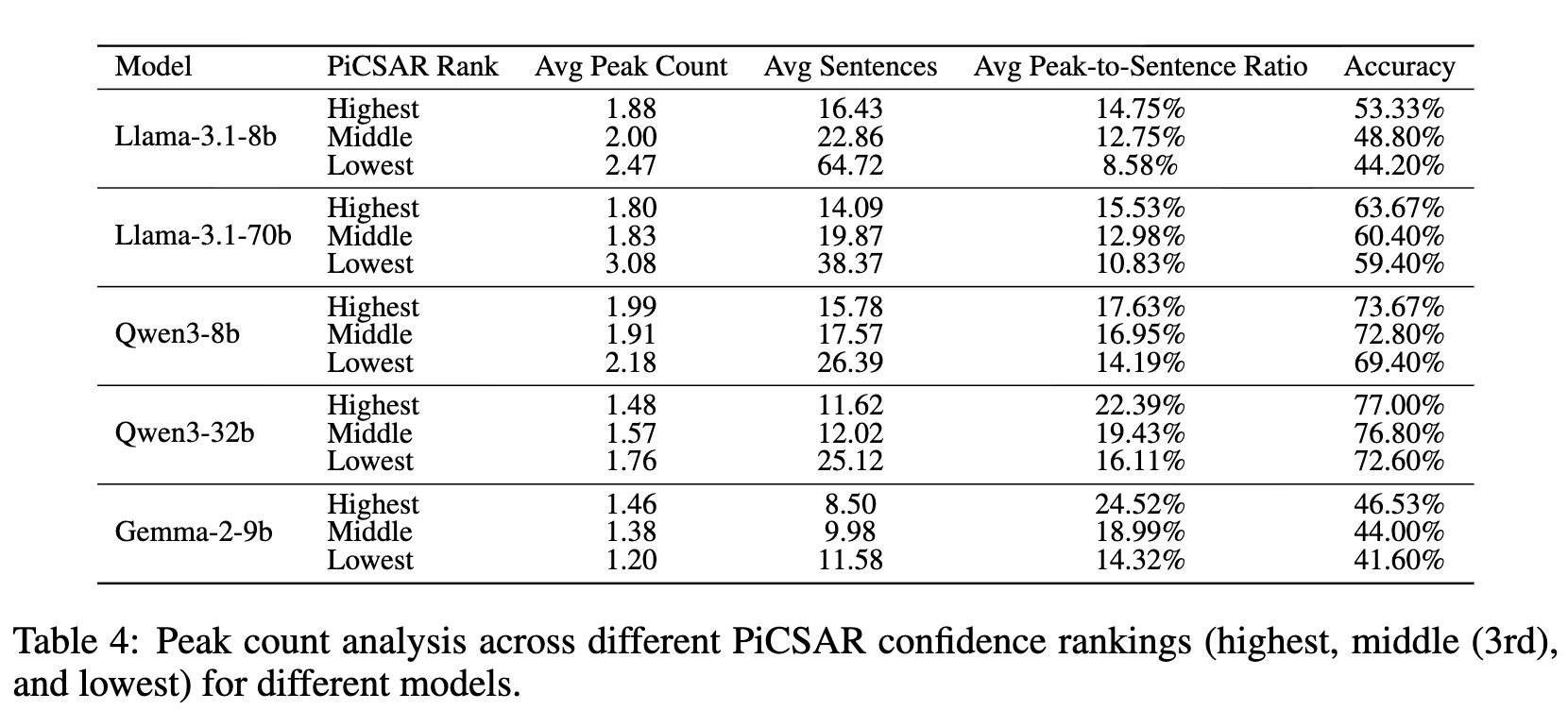
如表4所示,以 Llama-3.1-8b 为例,PICSAR 评分最高的组别,其峰值句比率为 14.75%,准确率为 53.33%;而评分最低的组别,峰值句比率仅为 8.58%,准确率也降至 44.20%。
同时,研究还发现,更长的推理链并不一定意味着更高的准确率。评分最低的组别平均句子数(64.72句)远多于评分最高的组别(16.43句),但准确率反而更低。这表明正确的推理过程往往更加简洁、高效和“信息密集”,能够在关键步骤上迅速提升模型对最终答案的信心。
往期文章:
-
-
DeepSeek V3.1 翻车了!字节 Seed 提出 Inverse IFEval 判断大型语言模型能否听懂“逆向指令”?
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
蚂蚁浙大提出基于“评分细则”(Rubric)的奖励机制,仅靠5000+样本,让30B轻松击败671B DeepSeek V3
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-



