
-
论文标题:A COMEDY OF ESTIMATORS: ON KL REGULARIZATION IN RL TRAINING OF LLMS -
论文链接:https://www.arxiv.org/pdf/2512.21852
TL;DR
在大型语言模型(LLM)的强化学习(RL)后训练(Post-training)中,KL 正则化是防止模型偏离基座模型、避免模式坍塌的关键。然而,当前社区中广泛使用的 KL 估计器配置(如 GRPO 中常用的配置)实际上存在梯度偏差。
近期 Mila 等机构的最新研究《A Comedy of Estimators: On KL Regularization in RL Training of LLMs》,分析了两种主流 KL 估计器(K1 和 K3)在两种放置位置(Reward 和 Loss)下的梯度特性。
核心结论是:目前流行的将 K3 估计器直接放入 Loss 的做法会导致有偏的梯度估计(实际上类似于 Forward KL);而将朴素的 K1 估计器放入 Reward 中,虽然方差稍大,但能提供无偏的 Reverse KL 梯度,从而在分布内(In-Domain)和分布外(OOD)任务上取得显著更好的性能和泛化性。
1. 引言
随着 DeepSeek-R1 等工作的出现,基于强化学习(RL)的推理能力增强已成为 LLM 后训练的核心范式。无论是通过人类反馈强化学习(RLHF)进行对齐,还是通过可验证奖励(RLVR)提升数学和代码能力,RL 都在发挥关键作用。
在这些 RL 目标函数中,一个不可或缺的组件是正则化项,通常表现为训练策略 与参考策略 之间的逆向 Kullback-Leibler (Reverse KL) 散度。其目的是约束探索空间,防止模型发生灾难性遗忘或过度优化奖励(Reward Hacking)。
尽管 KL 正则化被广泛使用,但由于精确计算整个序列空间的 KL 散度是不可行的,实践中必须依赖基于采样的估计器(Estimators)。更加复杂的是,这些估计器在目标函数中的放置位置(是作为奖励的一部分,还是作为损失函数的一项)也会影响梯度的计算方式。
现有的开源库(如 TRL, VeRL, OpenRLHF 等)和算法(如 PPO, GRPO)在实现细节上存在不一致。本文基于原论文,系统性地剖析了这些设计选择带来的数学后果和实证影响。
2. RL 微调中的目标与梯度
我们关注的问题是对基座模型 进行微调。给定奖励函数 和数据集 ,优化目标通常为:
其中 是模型生成的 token 序列。由于采样过程不可导,通常使用策略梯度(Policy Gradient)方法。
逆向 KL 散度定义为:
在实际操作中,常用的算法如 GRPO (Group Region Policy Optimization) 会采样一组输出 ,并计算优势(Advantage)。GRPO 的一个显著特征是它通常将 KL 项直接加入到损失函数中,而不是仅作为奖励扣除。
这就引出了两个关键的设计维度:
-
估计器的选择:我们如何通过采样近似 KL 值? -
正则化的位置:我们将估计值加在 Reward 里(通过 Score Function 梯度更新),还是加在 Loss 里(通过自动微分更新)?
3. KL 估计器及其梯度的理论分析
这是理解本文核心贡献的关键部分。我们需要从数学上推导不同配置下的梯度偏差。
3.1 序列级 Reverse KL 的真实梯度
首先,我们需要确立“标准答案”。序列级逆向 KL 散度的真实梯度为:
注意:这里通过简单的对数导数技巧(Log-derivative trick)可以推导得出。任何无偏的实现都应该在期望上等于这个式子。
3.2 两种常见的 Token 级估计器
由于序列很长,我们通常将其分解为 Token 级别的估计求和。论文研究了两种主流估计器:
1. K1 估计器 (Naïve Estimator):
最直接的蒙特卡洛估计:
这是 KL 定义的直接翻译。
2. K3 估计器 (Schulman Estimator):
由 John Schulman 在 2020 年提出,具有更低的方差且严格非负:
在期望下,K1 和 K3 都是 KL 散度的无偏估计(即 )。但是,它们的梯度特性完全不同。
3.3 梯度的偏差分析
当我们把这两个估计器放入 RL 流程时,有两种处理梯度的方式:
-
Reward 模式:将 KL 值视为标量奖励的一部分。梯度主要来自对 采样的求导(Score Function Derivative)。
-
Loss 模式:将 KL 表达式直接加入 Loss。现代自动微分框架会计算路径导数(Path-wise Derivative)。
让我们看看这四种组合的结果(见表 1):
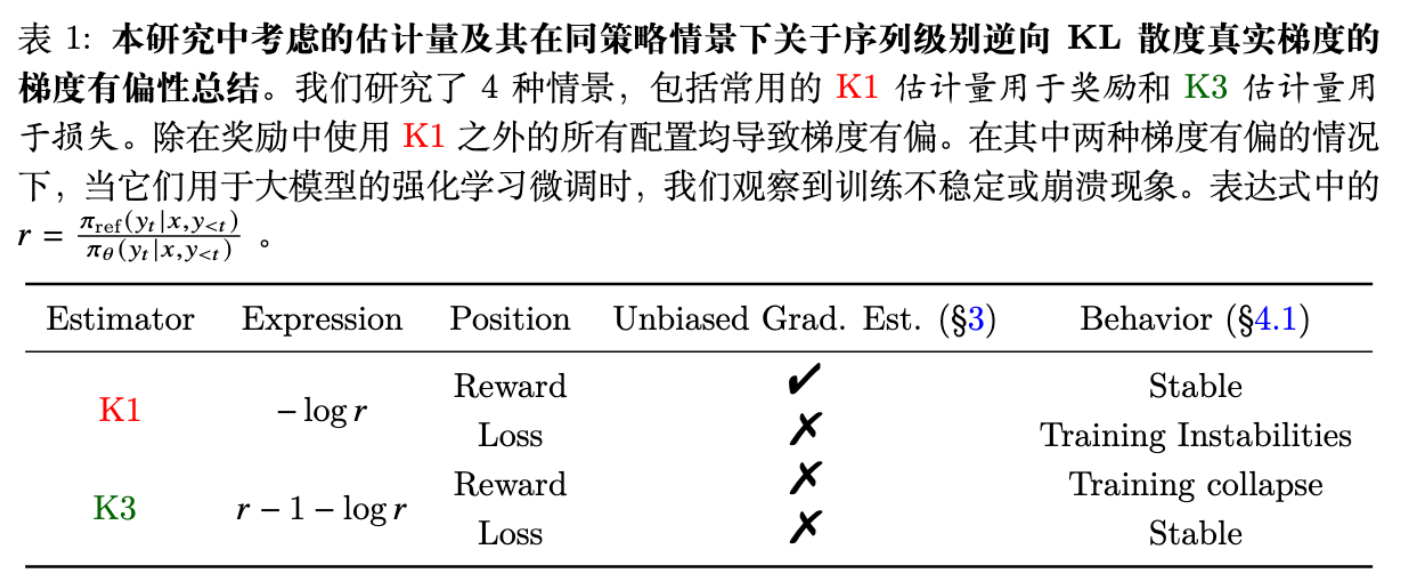
深度解析:为什么 K1 in Reward 是无偏的?
当我们将 K1 放入 Reward 时,梯度变为:
这与公式 (10) 中的真实梯度完全一致。因此,K1 in Reward 是唯一正确的实现方式。
深度解析:K1 in Loss 发生了什么?
如果直接对 K1 进行微分(放入 Loss):
K1 在 Loss 中的梯度期望居然是 0!这意味着如果在 Loss 中使用 K1,你实际上是在注入零均值的噪声。这解释了为什么实验中这种配置会导致训练不稳定甚至发散——因为它根本没有提供有效的正则化梯度,只是增加了方差。
深度解析:K3 in Loss (GRPO 的默认做法) 的本质是什么?
这是最令人惊讶的发现。K3 估计器在 Loss 中的梯度推导如下(详见论文附录 F.4):
注意,逆向 KL 要求在 的分布上采样。而 K3 在 Loss 中的梯度行为,数学上更接近于Forward KL(即 )或者一种类似于由 引导的蒸馏。
-
Reverse KL (Mode-seeking): 倾向于集中在 的高概率模式上。 -
Forward KL (Mode-covering): 倾向于覆盖 的所有模式。
虽然 K3-in-Loss 是有偏的(它优化的不是我们声称的 Reverse KL),但它具有 Forward KL 的特性,这在一定程度上保证了训练的稳定性,因为它鼓励策略覆盖基座模型的分布。然而,这并不是 RL 微调通常追求的目标(我们通常希望模型专注于高奖励的推理路径,而不是覆盖基座模型的所有平庸路径)。
4. 合成实验验证
为了验证上述理论分析,作者首先构建了一个最小化的参数化自回归模型(Parametric Autoregressive Model)。
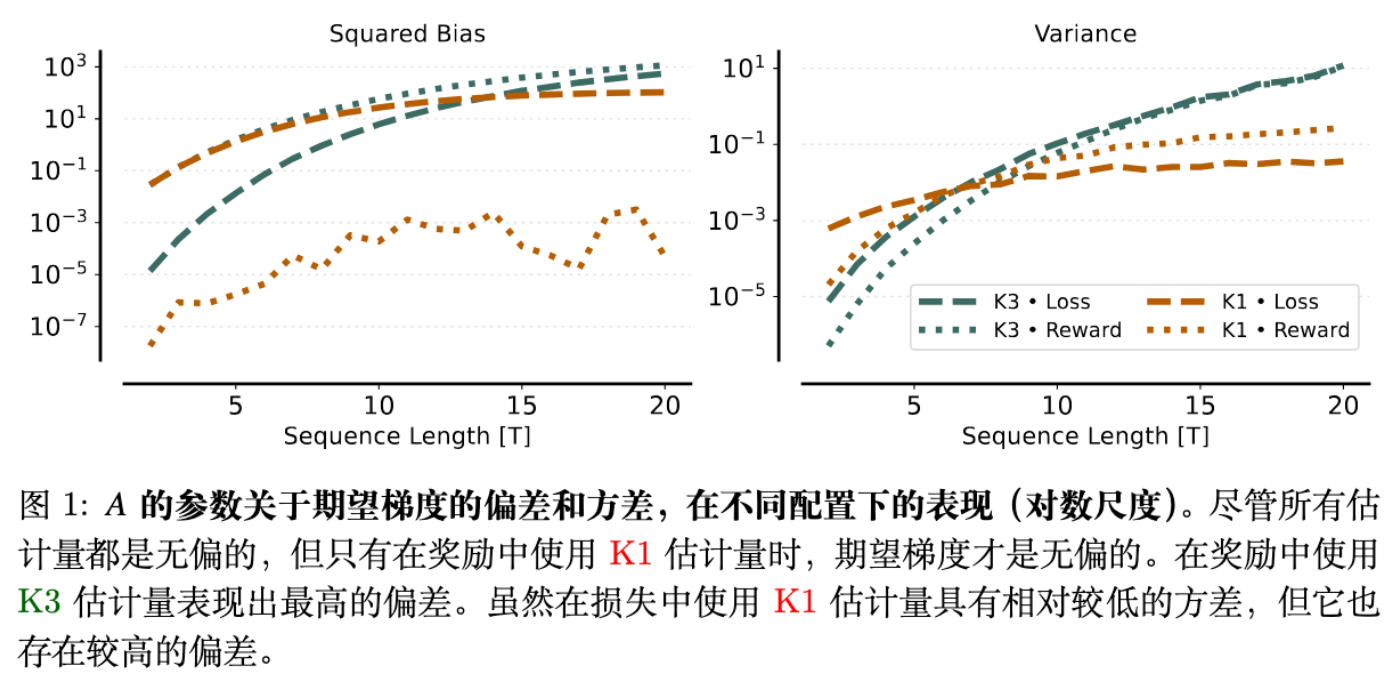
在图 1 中,我们可以清晰地看到:
-
K1 + Reward: 偏差(Bias)极低,几乎为零。 -
K1 + Loss: 偏差较高,且方差很大(因为期望为 0,纯粹是噪声)。 -
K3 + Reward: 偏差极高。 -
K3 + Loss: 存在显著偏差,但方差较小。
这在受控环境下完美证实了理论推导。
5. LLM 实证分析(On-Policy)
理论分析之后,作者在真实的大模型训练场景中进行了验证。
-
模型: Qwen2.5-7B, Llama-3.1-8B-Instruct -
任务: MATH 数据集(数学推理) -
算法: REINFORCE (with Leave-One-Out baseline),模拟 GRPO 的核心机制。 -
设置: On-Policy(Batch size = Mini batch size,采样后立即更新,无 PPO 的多轮迭代)。
5.1 观察一:K1 加入 Loss 会导致训练不稳定
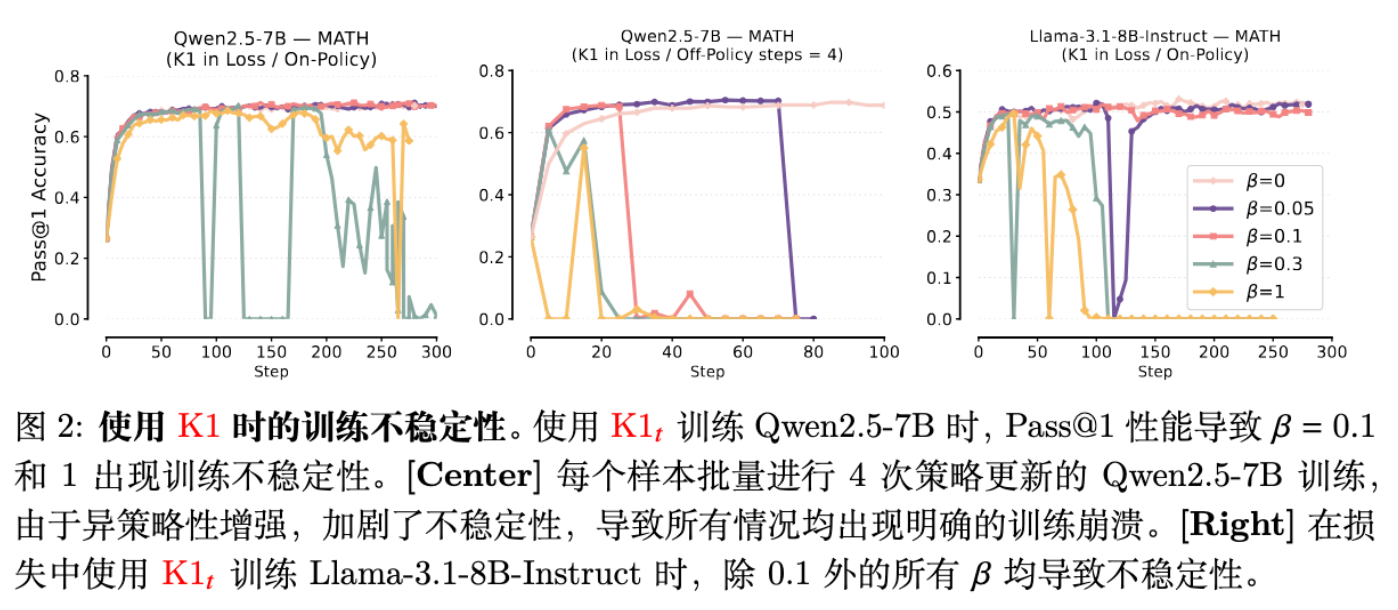
如图 2 所示,当使用 K1 估计器并将其加入 Loss 时,随着 KL 系数 的增加(如 ),Qwen 和 Llama 模型都表现出了剧烈的震荡甚至崩溃。这验证了“期望梯度为 0”带来的纯噪声效应。
5.2 观察二:K3 加入 Reward 会导致训练坍塌
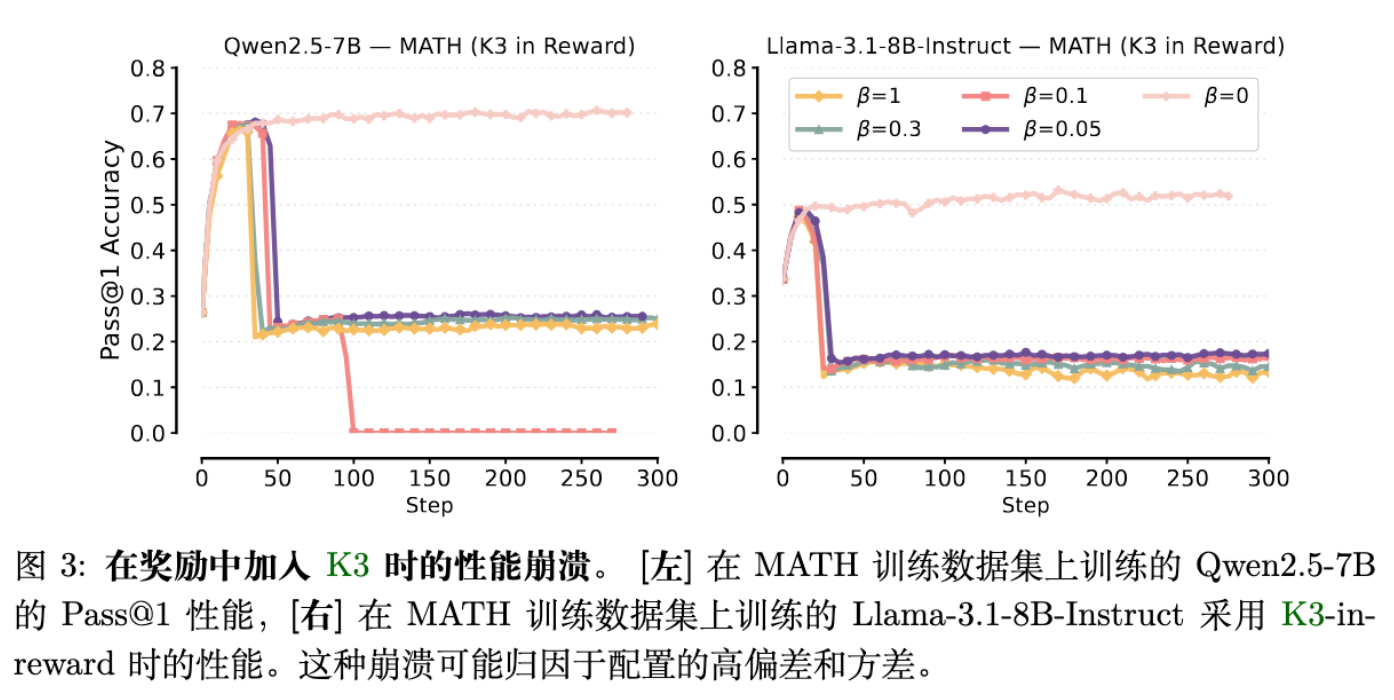
K3 估计器如果作为 Reward 处理,会引入巨大的梯度偏差。实验显示,无论 取值如何,训练迅速崩溃,准确率跌至 0。这是因为 K3-in-Reward 产生的梯度方向与优化目标严重不符。
5.3 观察三:K3 in Loss (稳定但有偏) vs. K1 in Reward (无偏且强劲)
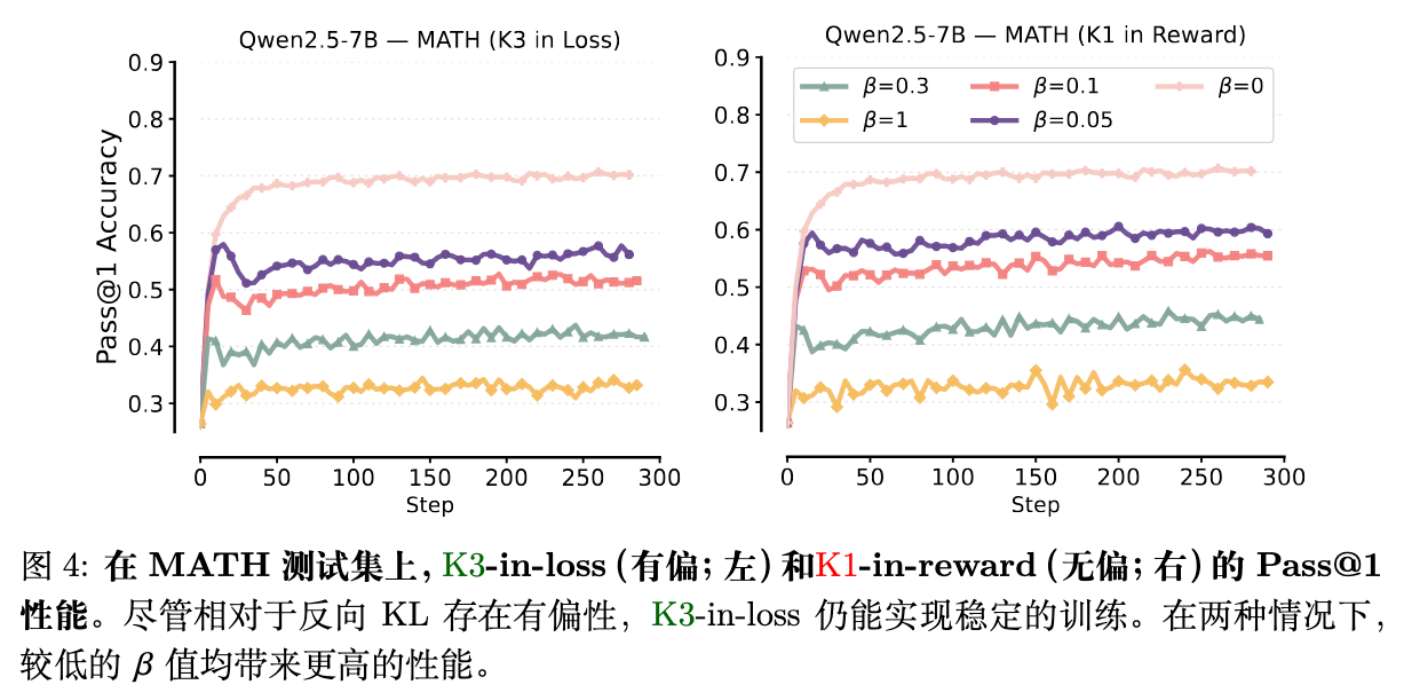
这是本文最重要的实证对比。
-
K3 in Loss: 这是 GRPO 等算法的常见实现。虽然是有偏的,但训练曲线是稳定的(见图 4 左)。 -
K1 in Reward: 这是理论上正确的无偏实现。训练同样稳定(见图 4 右)。
关键在于最终性能的对比:
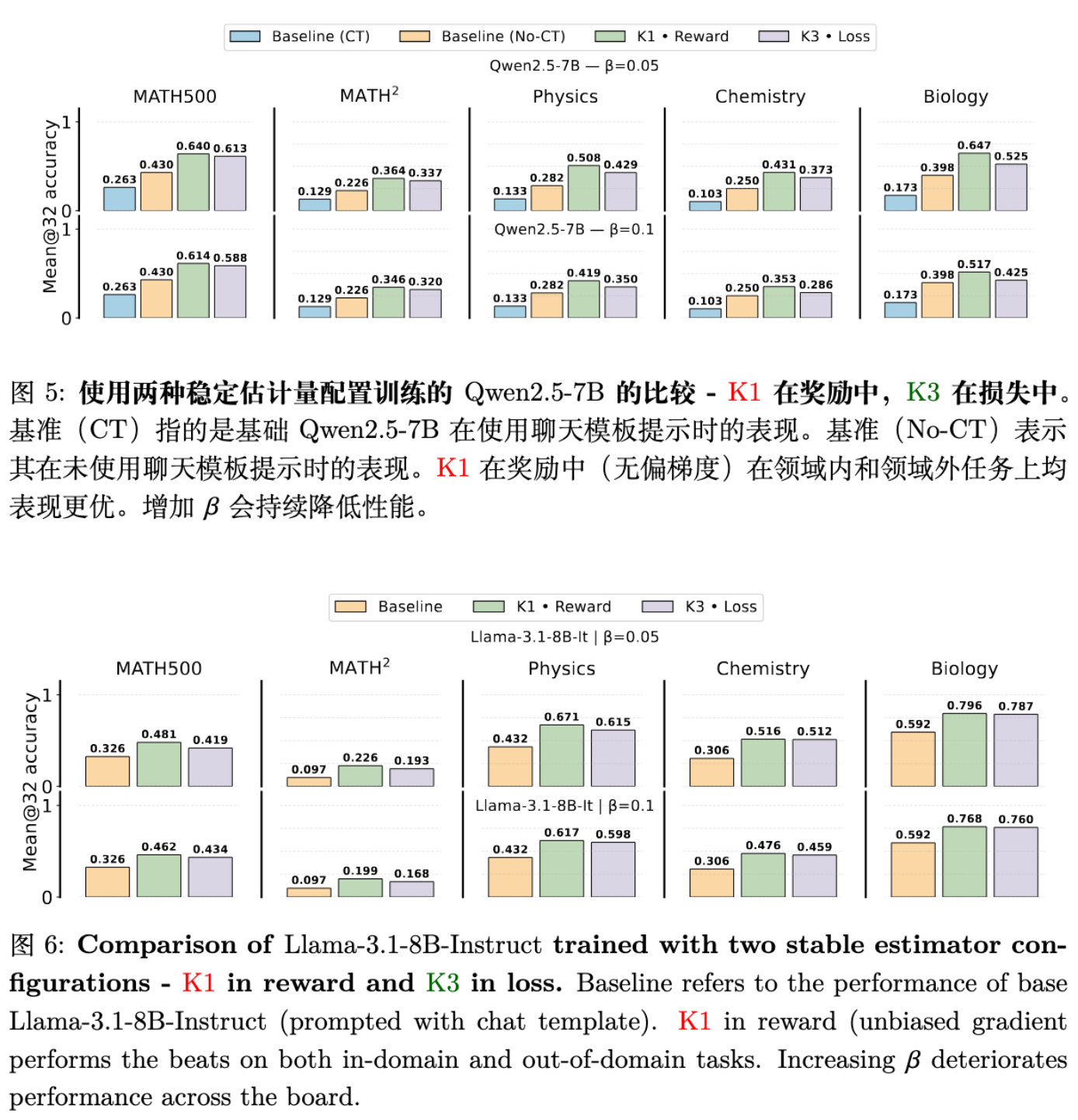
实验结果表明:
-
In-Domain 提升: 在 MATH500 和 MATH 验证集上,K1-in-Reward 的性能始终优于 K3-in-Loss。例如,在 时,相对提升达到 6.21%。 -
OOD 泛化性大幅提升: 在分布外任务(MMLU Physics, Chemistry, Biology)上,无偏的 K1-in-Reward 表现出惊人的优势,平均相对提升达到 19.06% 。
这说明,使用正确的(无偏的)梯度估计器,不仅能更好地优化目标,还能显著保留模型的通用能力,减少“对齐税”或过拟合风险。 而 K3-in-Loss 由于其 Forward KL 的特性,可能强行要求模型覆盖基座模型的分布,限制了模型向高奖励区域的探索和优化。
6. 异步强化学习(Asynchronous RL)中的表现
在实际的大规模工业级训练中,为了效率,往往采用异步架构(Asynchronous RL),这引入了 Off-policy 的因素(数据产生于旧策略 )。
作者使用 Dr. GRPO 架构,在 Qwen2.5-7B (MATH) 和 Qwen3-4B (Countdown 任务) 上进行了高并发(Async level = 10)的实验。
主要发现:
-
尽管理论上 Off-policy 会使所有估计器都产生偏差(除非引入复杂的序列级重要性采样),但实证表现与 On-Policy 场景高度一致。 -
K1-in-Reward 依然是表现最好的配置,且训练稳定。 -
K3-in-Loss 表现次之。 -
其他配置依然会导致不稳定或崩溃。
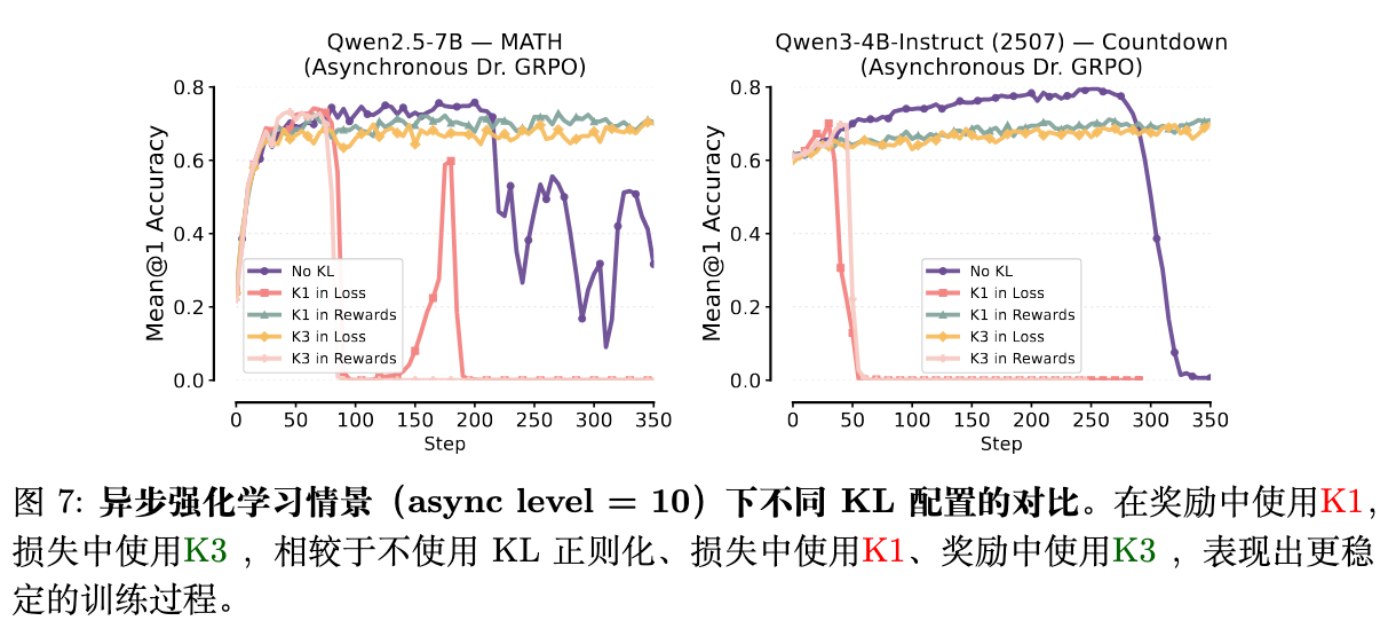
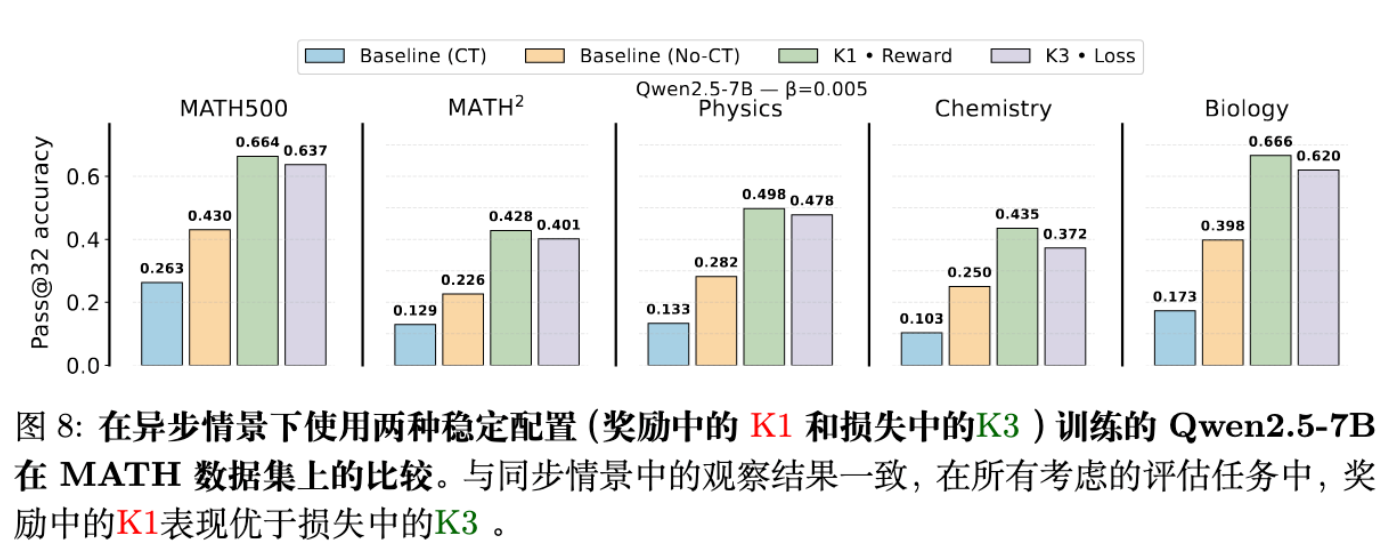
这意味着,即便是对于目前最先进的异步 RL 训练流程,简单地将 KL 计算方式从“K3 in Loss”切换为“K1 in Reward”也能带来免费的性能提升。
7. 讨论与建议
7.1 为什么社区长期忽视了这个问题?
作者指出,K3 估计器在 Loss 中的使用之所以流行(如在 GRPO 中),是因为它确实提供了“稳定性”。它实际上是在做一个类似 Logit Distillation 或 Forward KL 的操作。在某些情况下,这种保守的更新是有益的,掩盖了它在数学上对 Reverse KL 目标的背离。
然而,随着我们对推理能力要求的提高,我们需要模型更精准地向高奖励区域移动,而不是被基座模型的分布形态所束缚。无偏估计(K1-in-Reward)正好提供了这种能力。
7.2 开源库现状与修改建议
论文调查了当前流行的 RLHF/RLVR 库(见附录 E,表 2)。
-
VeRL: 支持 algorithm.kl_penalty="kl"(即 K1) 和algorithm.use_kl_in_reward=True。这是推荐配置。 -
OpenRLHF: 需要注意。如果设置 --kl_estimator="k3"且放入 Loss(默认行为),则是次优的。建议切换配置。 -
TRL / GRPO: 许多参考实现默认将 KL 放入 Loss。
建议:
检查你的代码库中计算 KL 的部分:
-
如果你在使用 approx_kl = (ratio - 1) - log(ratio)(即 K3) 并且把它加到了policy_loss中,请尝试修改。 -
推荐修改方案: -
计算 log_ratio = log(pi) - log(ref)(即 K1)。 -
不要把这个项加到 Loss 里。 -
把 -beta * log_ratio加到 Reward(或 Advantage)里。 -
让优化器只优化 advantage * grad_log_pi。
-
7.3 关于“双重修正”
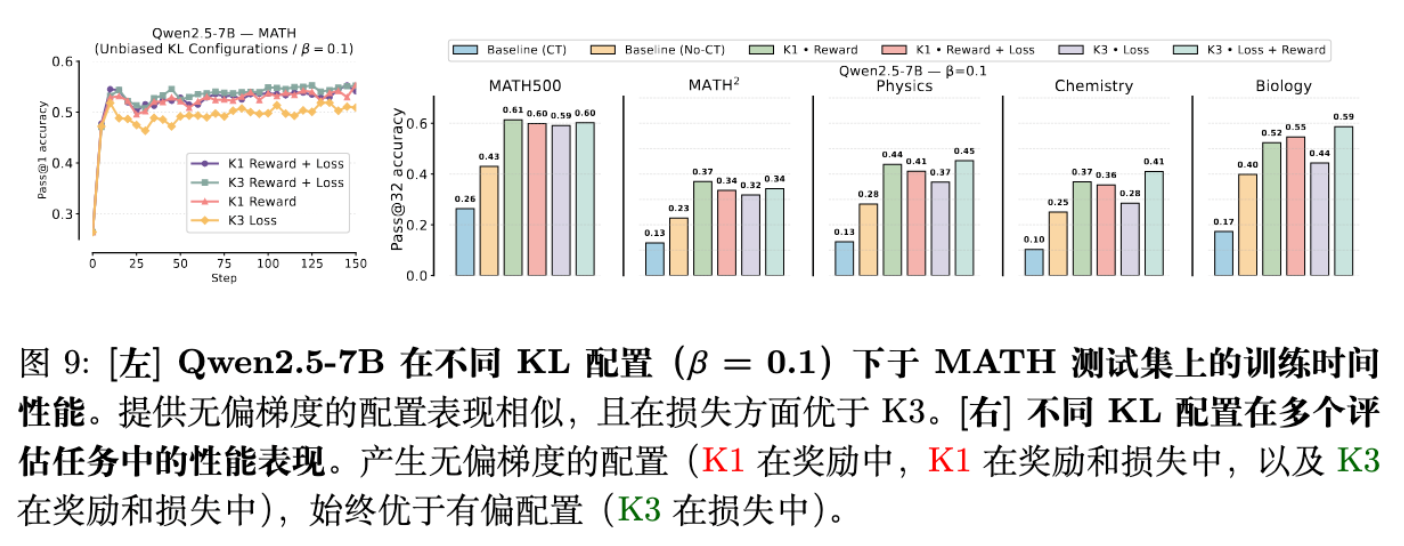
论文还提到了一个有趣的修正方案:为了在 Loss 中获得无偏梯度,可以同时在 Reward 和 Loss 中加入 KL 项(见公式 9 和 3.1 节)。
实验表明(图 9),这种“修正后的无偏实现”性能与 K1-in-Reward 相当,都优于有偏的 K3-in-Loss。但这通常比直接把 K1 放入 Reward 要麻烦,所以 K1-in-Reward 仍是首选。
8. 总结
-
不要将 K1 放入 Loss:期望梯度为 0,会导致训练震荡。 -
不要将 K3 放入 Reward:梯度偏差极大,导致模型坍塌。 -
K3 放入 Loss (GRPO 默认) :稳定但有偏(Forward KL 行为),限制了模型性能,特别是泛化能力。 -
K1 放入 Reward (推荐) :无偏估计,虽然方差略大,但能正确优化 Reverse KL 目标,带来最佳的 In-Domain 和 Out-of-Domain 性能。
更多细节请阅读原文。
往期文章:


