
-
论文标题:PretrainZero: Reinforcement Active Pretraining -
论文链接:https://arxiv.org/pdf/2512.03442
TL;DR
今天解读一篇在预训练阶段应用强化学习的论文《 PretrainZero: Reinforcement Active Pretraining 》,该工作提出了一种名为 PretrainZero 的框架。不同于依赖高质量合成数据或特定验证器的现有方法,PretrainZero 能够在纯生预训练语料(如 Wikipedia)上,无监督微调(SFT)冷启动、无外部奖励模型的情况下,直接对 Base 模型进行强化学习预训练。其核心机制引入了主动学习(Active Learning)视角,通过一个对抗式的 Mask 生成与预测博弈,让模型主动挖掘语料中具有高信息量且处于“学习边界”的内容进行推理训练。实验表明,PretrainZero 在 Qwen3-4B/8B 等基座模型上显著提升了数学和通用推理能力,并能作为更优质的基座服务于后续的 RLVR(带验证器的强化学习)流程。
1. 引言
1.1 大模型训练范式的演进与瓶颈
当前大语言模型(LLM)的主流训练范式通常包含三个阶段:自监督预训练(Self-Supervised Pretraining)、监督微调(SFT)以及基于强化学习的对齐(RLHF/RLVR)。预训练阶段主要依赖于“预测下一个 token”(Next Token Prediction, NTP)的目标,利用海量低成本数据构建模型的通用能力。而在后训练(Post-training)阶段,强化学习(RL)被证明能够有效激发模型的推理潜能(如 DeepSeek-R1, OpenAI o1 等工作所示)。
然而,将强化学习的应用局限在后训练阶段面临着显著的 “数据墙”(Data-Wall) 问题:
-
RLVR(Reinforcement Learning with Verifiable Rewards) 依赖于领域特定的验证器(如数学题答案、代码编译器),这使得其难以扩展到缺乏明确真值的通用推理领域。 -
RLHF(Reinforcement Learning from Human Feedback) 依赖于人类标注或奖励模型,面临奖励黑客(Reward Hacking)风险,且难以支持大规模的长程推理训练。
因此,一个自然的探索方向是:能否将强化学习前置到预训练阶段? 即在海量无标注的预训练语料上直接进行强化学习,从而利用廉价数据突破数据瓶颈。
1.2 现有“强化预训练”的局限性
虽然已有工作(如 Quiet-STaR, RLPT 等)尝试在预训练阶段引入 RL,但在实现“完全独立且通用的强化预训练”方面仍存在不足:
-
依赖合成数据:部分方法(如 RLPT)依赖 OmniMath 等带有思维链(CoT)标注的高质量合成数据,这本质上带有监督学习的影子,而非纯粹的从预训练语料中学习。 -
依赖 SFT 冷启动:通常需要先进行 SFT 以具备基本的指令遵循或推理能力,增加了流程复杂度。 -
依赖奖励模型:需要训练好的奖励模型提供信号,而非直接利用数据本身的一致性。 -
训练坍塌风险:在真实的、充满噪声的预训练语料(如 Wikipedia)上,简单的策略(如随机掩码或基于熵的掩码)往往导致训练不稳定或效率低下。
PretrainZero 的提出正是为了解决上述问题,实现一种端到端、完全自监督、基于真实语料的强化预训练方法。
2. 预备知识与问题定义
在深入 PretrainZero 之前,我们先形式化定义自监督预训练和基础的强化预训练(RLPT)范式。
2.1 自监督预训练 (Self-Supervised Pretraining)
传统的预训练通常采用预测下一个 token 的任务。给定上下文 ,模型预测 :
另一种是掩码预测任务(Masked Token Prediction, MTP),利用双向上下文预测被掩盖的 token:
2.2 基础强化预训练 (Reinforcement Pretraining, RLPT)
RLPT 试图将推理过程引入预训练。给定一个序列 ,将某个 token 视为真值(Ground Truth),模型需要基于上文 生成一段思维链(CoT),最终预测出 。
若采用 GRPO(Group Relative Policy Optimization)算法,组大小为 ,奖励函数 定义为预测值 与真实值 的精确匹配(Exact Match):
RLPT 的目标函数为:
2.3 为何现有策略在真实语料上失效?
作者在 Wikipedia 数据集上建立了基线模型,尝试了三种不同的掩码(Masking)策略进行 RLPT:
-
随机下一词推理(Random Next Token)。 -
随机掩码跨度推理(Random Masked Span)(类似于BERT的预训练任务)。 -
基于熵的下一词推理(Entropy-based Next Token):选择熵最高的 top 20% token 进行掩码,认为这些位置最难,信息量最大。
实验发现:
-
随机策略效率低:虽然能训练,但学习效率低下,难以捕捉深层语义。 -
基于熵的策略导致坍塌:如图 3 所示,Entropy-based 方法在真实语料上会导致奖励迅速退化。
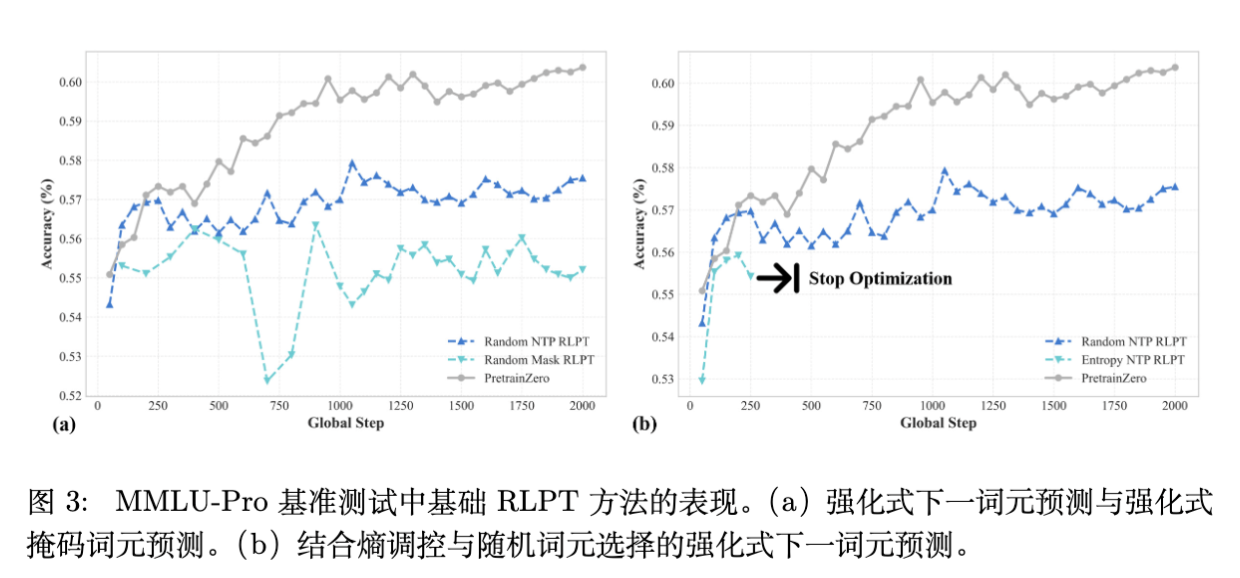
深度分析 Findings 2:在合成数据(如 OmniMath)上,高熵确实代表“困难但可学习”的逻辑点。但在真实语料(Wikipedia)中,高熵往往对应着数据噪声、不一致性或不可预测的专有名词。模型通过学习这些噪声无法获得泛化能力,导致训练失败。这表明:在真实数据分布下,简单的启发式掩码策略不再有效,必须让模型“主动”寻找可学习的内容。
3. PretrainZero 方法详解
PretrainZero 的核心思想受人类主动学习(Active Learning)启发:人类在学习时,会主动关注那些既有信息量(Informative)又是自己当前能力尚未掌握但能够掌握(Verifiable and Not-yet-mastered)的内容,而非随机浏览或死磕完全无法理解的噪声。
为此,PretrainZero 提出了一个双层(Bi-level)优化框架,包含两个耦合的策略:
-
Mask Generator(掩码生成器,):负责主动探索并选择要掩盖的文本跨度(Span)。 -
Mask Predictor(掩码预测器,):负责通过思维链(CoT)推理来恢复被掩盖的内容。
两者共享同一个 LLM 参数 (或部分共享)。
3.1 任务流程
如图 4 所示,PretrainZero 的训练包含两个阶段的循环:
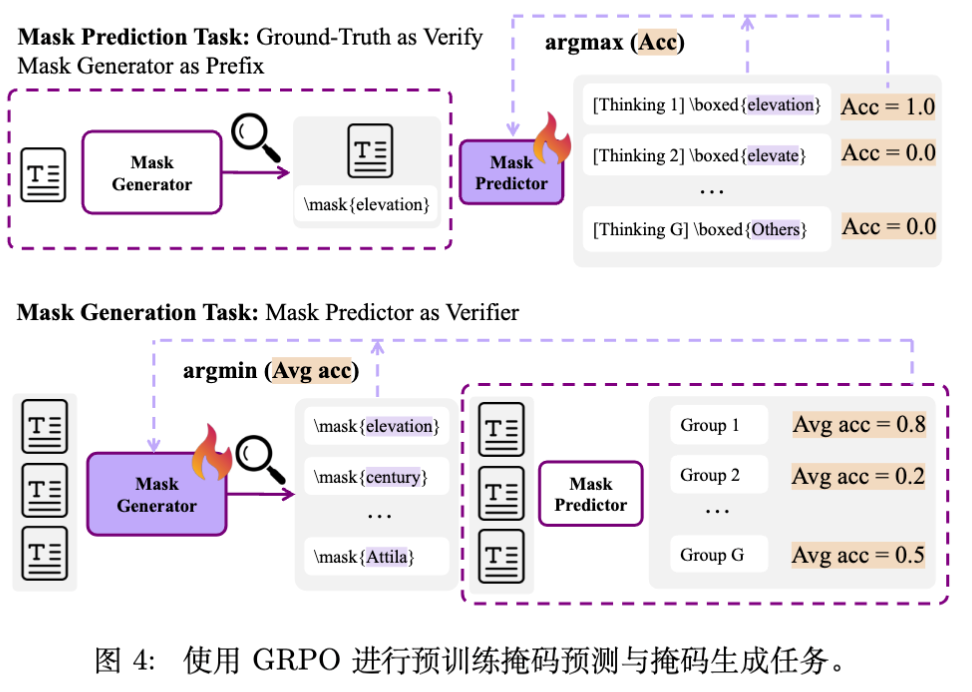
3.1.1 掩码生成 (Mask Generation)
给定预训练文本 ,策略 首先生成一段思考过程,然后输出一个文本跨度 用于掩码。
Prompt 示例见图 5。模型被要求生成一个“对于当前能力适度挑战且答案唯一”的掩码。

3.1.2 掩码预测 (Mask Prediction)
基于生成的掩码 ,原文本 中的对应跨度 被替换为 [mask] 标记。预测策略 需要生成 CoT 并预测被掩盖的内容 。
这是一个可验证的 RL 任务,因为原始文本 就是天然的 Ground Truth。
3.2 强化主动学习目标
这是一个对抗式的最大最小(Min-Max)博弈过程。
-
预测器目标:最大化恢复被掩盖内容的准确率。 -
生成器目标:最小化预测器的准确率(即寻找预测器当前无法解决的弱点),但前提是生成的掩码本身是合理的(避免纯噪声)。
定义最终的预测奖励为 。总体目标函数 衡量预测器在给定生成器策略下的表现:
生成器试图最小化该目标(增加难度),预测器试图最大化该目标(解决难题)。优化问题形式化为:
3.3 强化学习优化与奖励设计
为了利用 GRPO 算法优化上述 Min-Max 目标,论文巧妙地设计了两个策略的奖励函数。
3.3.1 预测器奖励 ()
这部分很直观,即预测结果与真值的精确匹配:
这直接对应内部的 Maximization 目标。
3.3.2 生成器奖励 ()
生成器的目标是让预测器“难受”,即预测准确率低。因此,生成器的奖励定义为预测器在当前掩码下的负准确率:
关键细节:为了防止生成器通过生成“完全无法预测的噪声”(如随机字符)来“作弊”获得高分,论文增加了一个约束:如果预测准确率为 0,则生成器奖励也设为 0(或者说,生成器只有在预测器“部分能答对但感到困难”时才能获得高分,或者是为了避免无效数据,这里原文表述是 “in order to avoid rewarding the noisy masks that are not predictable... when the mask prediction accuracy is zero, we further define the generator's reward to be 0”)。这意味着生成器必须寻找那些有解但难解的样本。
3.3.3 GRPO 统一更新
论文证明了在 GRPO 框架下,生成器的优势函数(Advantage)计算与 Min-Max 目标是一致的。
对于生成器,其 Advantage 计算如下:
这意味着生成器会朝着“降低预测器 Advantage”的方向更新,从而实现对抗训练。
最终的损失函数是两个策略的 GRPO 损失之和(实际上通过拼接数据在同一步更新):
4. 实验设置
PretrainZero 的实验设置强调在受限资源和纯净环境下的有效性。
-
模型:覆盖 3B 到 30B 参数量级。 -
Qwen3-4B-Base -
Qwen3-8B-Base -
SmolLM3-3B-Base -
Qwen3-30B-A3B-MoE-Base -
注意:全部从 Base 模型开始,无 SFT 冷启动(除了 SmolLM 先跑了 100 步 Random RLPT 热身)。
-
-
数据:仅使用 Wikipedia。这是为了模拟最通用的真实语料分布,排除 OmniMath 等高质量合成数据的干扰,验证方法的核心有效性。 -
训练细节: -
训练 2000 步。 -
GRPO 组大小 。 -
掩码生成 Batch Size = 32,每个生成 8 个掩码。 -
掩码预测 Batch Size = 256 (32 x 8),每个预测再采样 8 次。 -
总 Batch Size 约为 288 (32 + 256)。
-
-
评估基准: -
通用推理:MMLU-Pro, SuperGPQA, BBEH。 -
数学推理:Math 500, GSM8K, AIME24 等 6 个数据集。
-
5. 实验结果与分析
5.1 预训练阶段性能表现
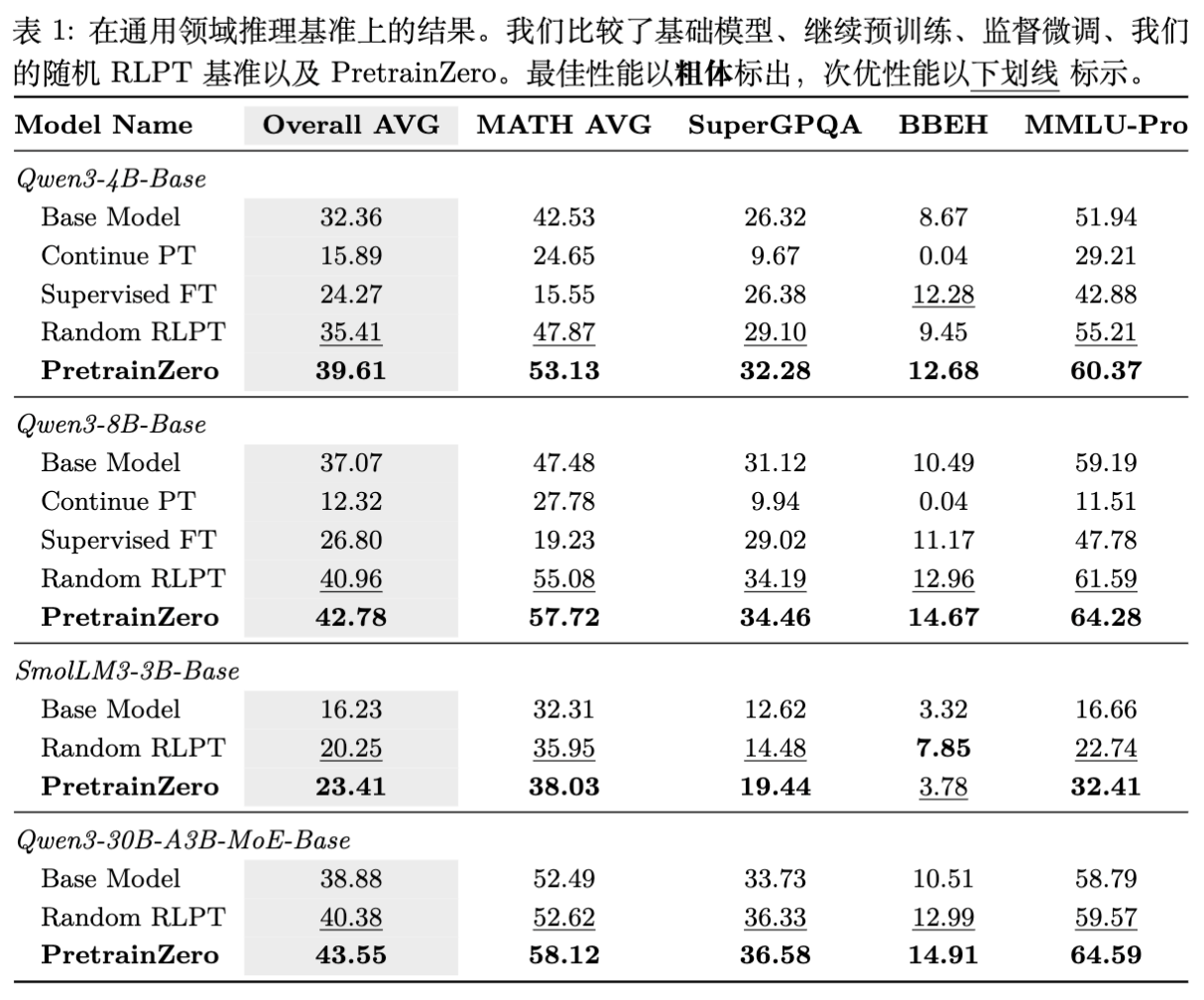
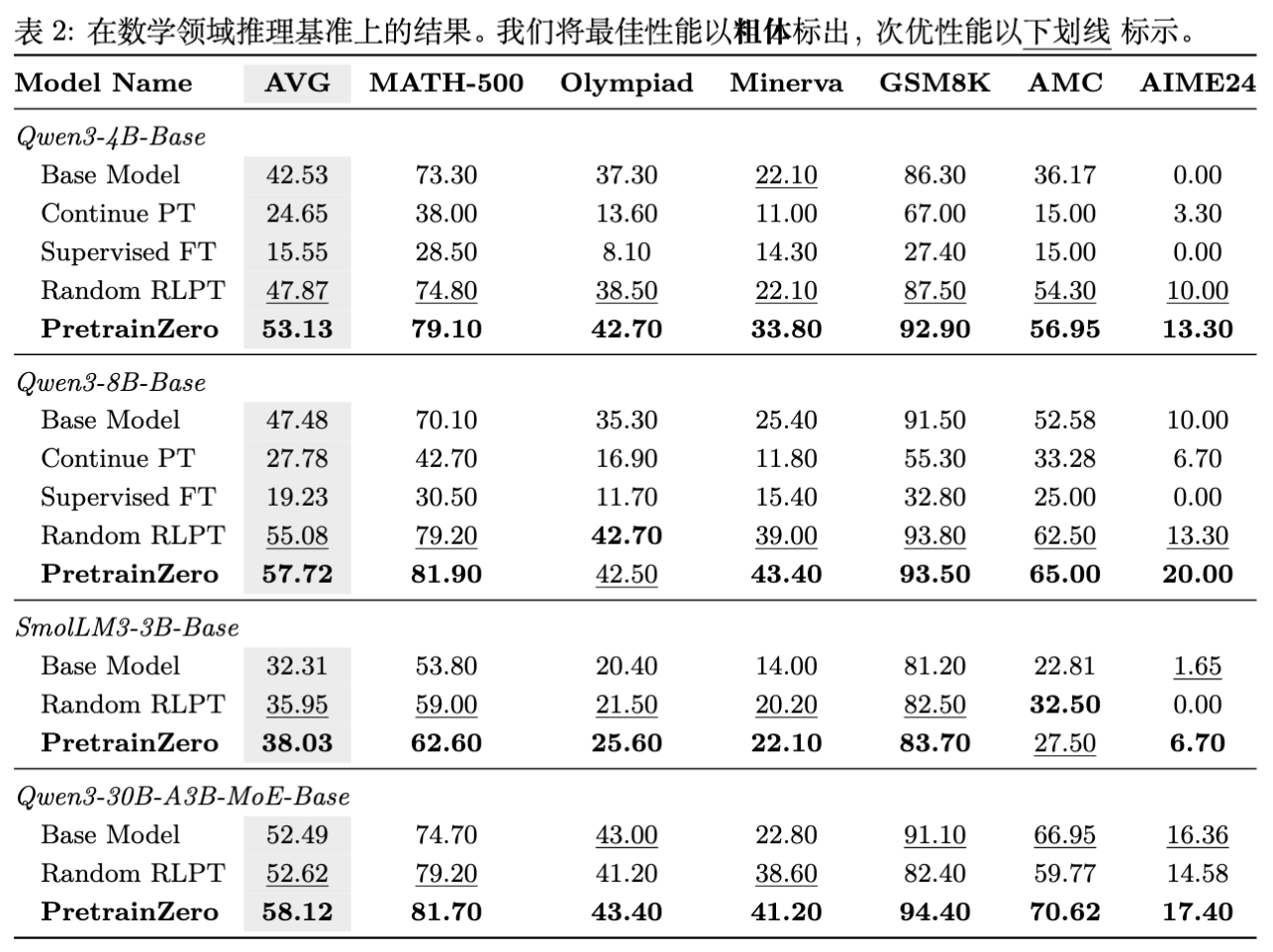
实验结果(如表 1 和表 2 所示):
-
显著优于 Base 和 SFT:
-
在 Qwen3-4B-Base 上,PretrainZero 在 MMLU-Pro 上达到了 60.37,远超 Base 模型的 51.94 和监督微调(Supervised FT)的 42.88。 -
注意:SFT(将掩码预测作为 QA 对训练,无 CoT)性能反而下降,说明在低质量数据上强行进行监督学习会破坏模型原有分布。
-
-
优于 Random RLPT:
-
相比于随机掩码的 RLPT,PretrainZero 在所有指标上均有一致性提升。例如在 GSM8K 上,Qwen3-4B 从 87.50 提升至 92.90。这证明了主动掩码策略的有效性。
-
-
扩展性验证:
-
在 Qwen3-8B 和 30B MoE 模型上,规律依然成立,说明该方法具有良好的 Scaling 潜力。
-
5.2 训练动态与推理模式分析
作者深入分析了训练过程中的指标变化:
-
CoT 长度增长:如图 6 所示,PretrainZero 的回复长度(CoT Length)随训练步数增加而自然增长,且比 Random RLPT 更长。这说明主动对抗机制逼迫模型进行更深度的思考。
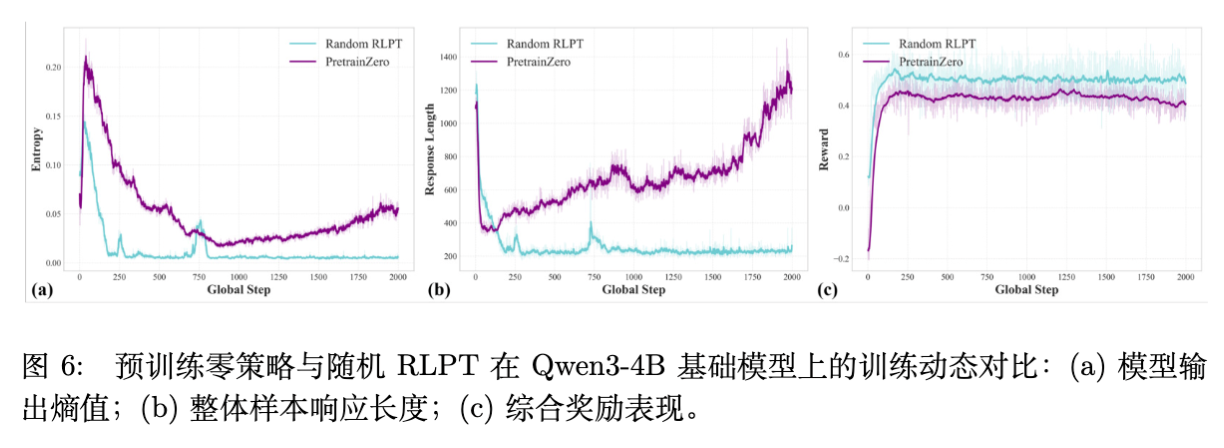
-
熵的变化:PretrainZero 训练中模型输出的熵保持在较合理的水平,没有出现 Entropy-based 方法那样的坍塌。
-
推理模式(Reasoning Pattern):

Random RLPT 与 PretrainZero 的推理模式对比 -
Case Study 显示,Random RLPT 倾向于直接猜测答案。而 PretrainZero 展现出了结构化的推理步骤:分析句子结构 -> 识别缺失词 -> 考虑上下文 -> 确定最合适词 -> 总结。这种行为是在没有人类演示(Demo)的情况下自发涌现的。
-
5.3 后训练(Post-Training)的增益
PretrainZero 预训练的模型是否适合作为后续 RLVR 的基座?作者在 PretrainZero 2000 步的基础上,进行了标准的 RLVR(使用 Math 验证器)训练。
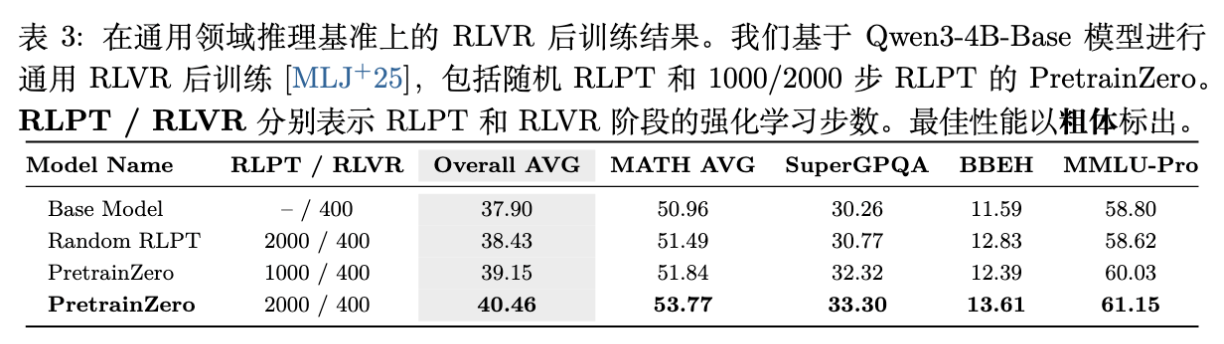
结果表明:
-
更好的起点:PretrainZero 模型作为起点,经过 RLVR 后,最终性能显著高于 Base 模型经过同样 RLVR 的性能。 -
端到端提升:在 MMLU-Pro 上,PretrainZero + RLVR 比 Base + RLVR 高出约 2.35 分。这意味着预训练阶段获得的推理能力是可以成功转移并被进一步放大的。
5.4 消融实验
-
数据领域影响:比较了 Wikipedia(通用)和 MathPile(数学)。结果发现,使用通用 Wikipedia 数据反而能在数学任务上取得不错的效果,且通用能力更好。这暗示推理能力的本质可能与具体的数学知识解耦,更多在于逻辑模式的学习。 -
掩码正则化:对比了不同的掩码过滤策略(如只保留单词、只保留出现次数少的实体)。PretrainZero 的自适应策略在稳定性上优于硬编码规则。
6. 讨论与相关工作对比
6.1 与 Quiet-STaR 的对比
Quiet-STaR (Zelikman et al., 2024) 也是在预训练中引入推理,但它是在 token 级别(Token-level)进行隐式推理(Thought Tokens),且计算开销巨大。PretrainZero 则是 Span-level 的显式推理,直接生成自然语言 CoT,更接近 RLVR 的范式,且便于解释和调试。
6.2 与 RLPT (Dong et al., 2025) 的对比
Dong 等人的 RLPT 工作是该领域的先行者,但其严重依赖 OmniMath 合成数据。本论文的实验表明,直接将 RLPT 搬到 Wikipedia 上效果有限。PretrainZero 通过引入主动掩码生成(Mask Generation),解决了真实数据信噪比低的问题,这是对 RLPT 范式的重要补充。
6.3 验证数据墙 (Verification Data Wall)
目前的 RLVR(如 DeepSeek-R1 Zero)非常成功,但局限于数学/代码等容易验证的领域。PretrainZero 提供了一种思路:利用文本自身的内在一致性(Self-Consistency within Context)作为验证信号。原始文本就是“答案”,被掩盖的部分就是“问题”。这使得 RL 可以在任何文本域上进行,极大地拓展了 RL 的适用边界。
7. 结论与展望
PretrainZero 是一项具有开创性的工作,它证实了在纯生预训练语料上,通过完全自监督的强化学习,可以有效提升模型的基础推理能力。
核心贡献总结:
-
Stand-alone RLPT:证明了无需 SFT 冷启动、无需外部奖励模型、无需合成数据,仅靠 Base 模型和 Wikipedia 也能跑通推理强化学习。 -
Active Pretraining 机制:提出了 Generator-Predictor 的对抗博弈框架,解决了低信息密度数据下的采样效率问题。 -
性能突破:在通用和数学基准上均取得了显著提升,并验证了其作为 Scaling Law 新维度的潜力。
未来展望:
-
多模态扩展:类似的掩码生成-预测机制完全可以迁移到图像或视频预训练中。 -
更复杂的生成策略:目前的 Mask Generator 还比较简单,未来可以引入更复杂的策略,甚至针对特定下游任务进行定向的掩码生成。 -
与长上下文结合:在长文档中进行跨度极大的掩码预测,可能会激发更强的长程推理能力。
往期文章:


