
-
论文标题:RECURSIVE LANGUAGE MODELS -
论文链接:https://arxiv.org/pdf/2512.24601v1
TL;DR
今天分享一篇大模型处理长上下文的 “trick”,来自 MIT CSAIL 团队的论文《Recursive Language Models (RLMs)》。
该研究针对当前大语言模型(LLM)在长上下文处理中面临的“上下文腐烂(Context Rot)”和物理窗口限制问题,提出了一种通用的推理时(Inference-time)扩展策略——递归语言模型(RLM)。RLM 的核心范式转变在于:不再将长 Prompt 直接作为神经网络的输入,而是将其视为外部环境中的一个变量。模型通过 Python REPL 环境,以编程方式检查、分解该变量,并递归地调用自身来处理 Prompt 的片段。
实验结果表明,RLM 能够处理超出模型原始上下文窗口两个数量级的输入(达到 10M+ Token 级别),并且在信息密度极高的任务(如 和 复杂度的任务)上,显著优于基座模型及现有的长上下文增强方法(如 Summary Agent 和 CodeAct)。同时,RLM 的推理成本与基座模型相当甚至更低。
1. 引言
尽管大语言模型在推理能力和工具使用方面取得了长足进步,但上下文长度(Context Length)依然是一个显著的瓶颈。即使在模型声称支持的上下文窗口内,研究人员也观察到了不可避免的“上下文腐烂(Context Rot)”现象。
1.1 上下文腐烂与物理限制
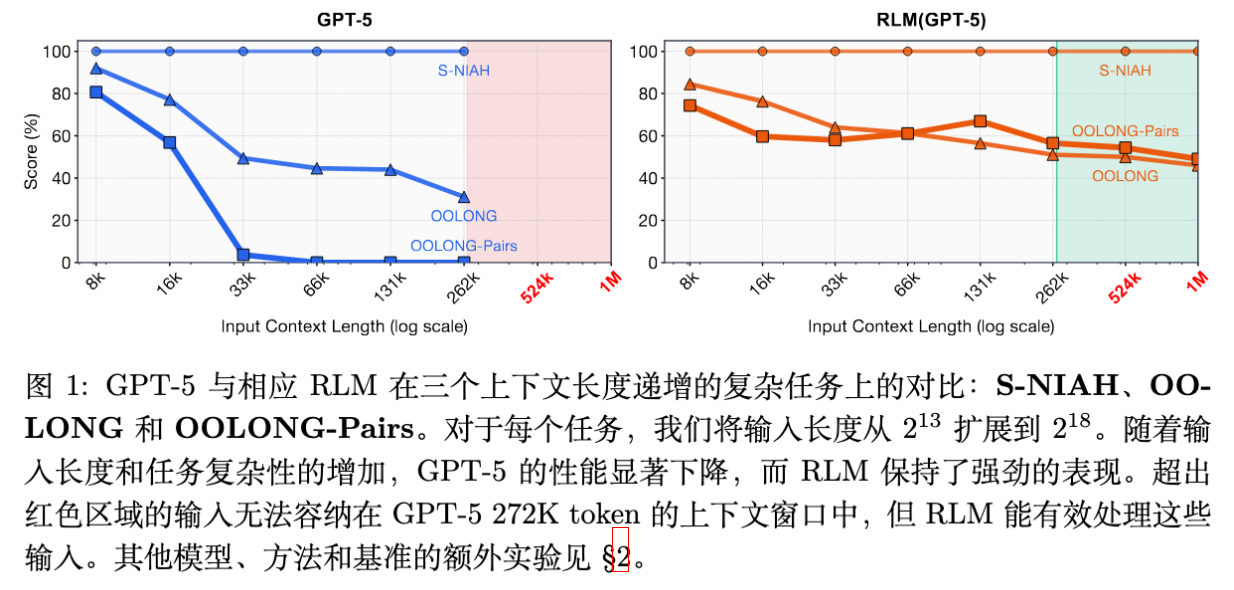
如图 1 左侧所示,即便是像 GPT-5 这样的前沿模型,随着输入长度的增加,其性能也会迅速下降。这种下降不仅取决于长度,还取决于任务的复杂度。虽然通过改进训练、架构(如 Ring Attention 等)和基础设施,上下文长度在稳步提升,但一个核心问题依然存在:是否可能通过推理时的手段,将通用 LLM 的有效上下文规模扩大数个数量级?
随着 LLM 被广泛应用于长程(Long-horizon)任务,例如处理数千万 Token 的代码库或文档库,这一需求变得愈发紧迫。
1.2 推理时计算的视角
本文作者从“核外算法(Out-of-core algorithms)”中汲取灵感。在传统计算系统中,具有小而快主内存的系统可以通过巧妙地管理数据进出内存的方式,处理比内存大得多的数据集。
在 LLM 推理领域,现有的通用方法主要是“上下文压缩(Context Condensation/Compaction)”,即在上下文超过阈值时对其进行摘要。然而,对于需要密集访问(Dense Access)Prompt 中多个部分的任务,压缩往往会丢失关键信息。
RLM 提出了一种不同的路径:将 Prompt 视为外部环境的一部分,而非直接输入。
2. Recursive Language Models
RLM 不是一种新的模型架构训练方法,而是一种推理时的 Agent 框架。其设计理念极其简洁,但解决了现有方法的根本性限制。
2.1 Prompt 即变量
传统的 LLM 使用方式是将 Prompt 喂入 Transformer。而在 RLM 中,Prompt 被放入一个 Read-Eval-Print Loop (REPL) 编程环境中,并被赋值给一个变量(例如 context)。
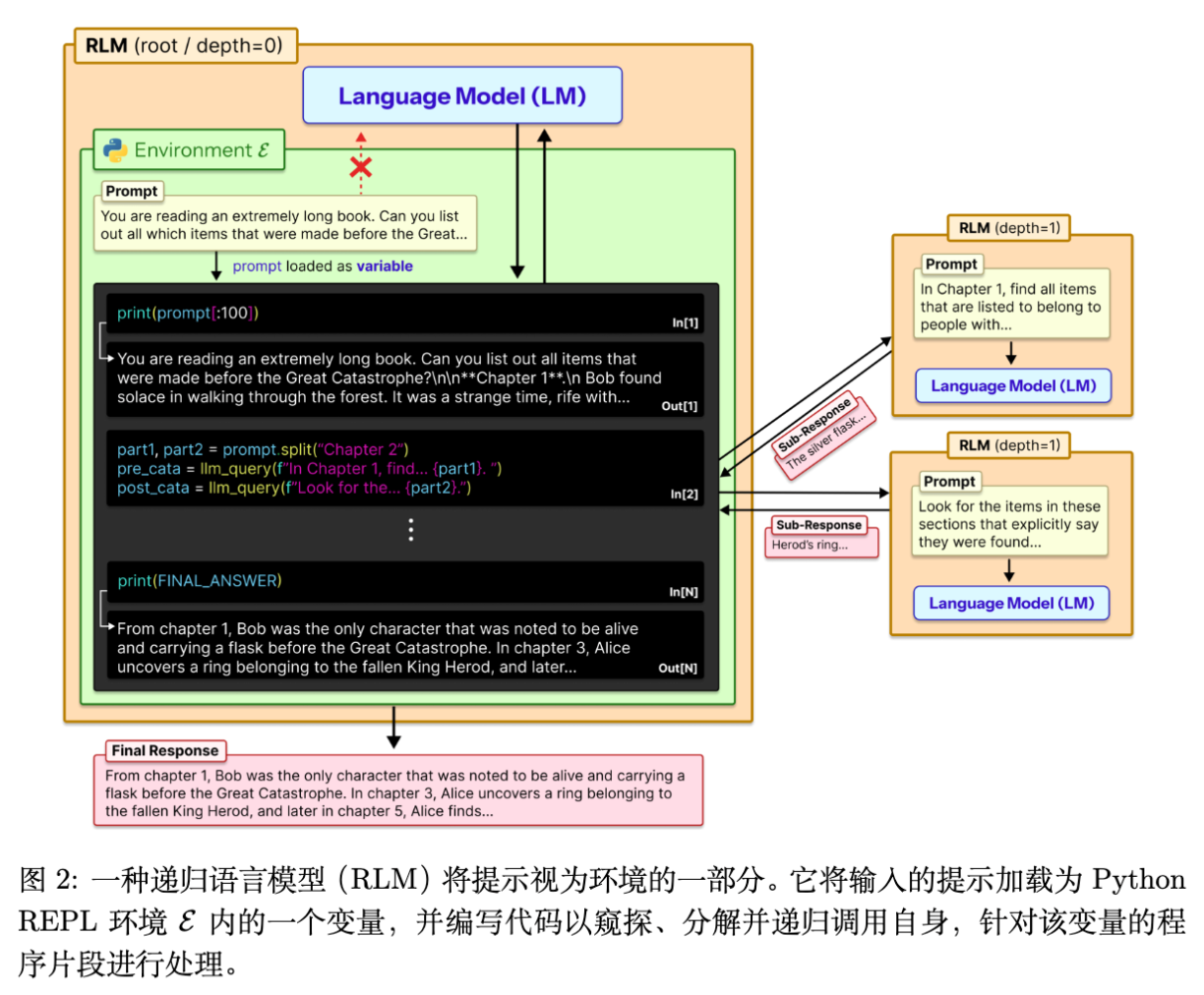
如图 2 所示,RLM 向外部暴露的接口与普通 LLM 相同:接收字符串 Prompt,输出字符串响应。但在内部,RLM 初始化了一个环境,并在 Prompt 中告知 LLM 关于该环境的信息(例如字符串 的长度)。LLM 可以编写代码来:
-
查看 的片段(Peeking)。 -
分解 (Decomposing)。 -
递归调用(Recursive Calling):即在代码中构造子任务,并调用 llm_query函数,该函数会启动一个新的 LLM 实例(可能是同一个模型,也可是更小的模型)来处理子任务。
2.2 解决根本性限制
这种设计使得 Prompt 实际上作为“外部存储”存在,模型本身只需要读取当前决策所需的那一小部分数据。这与之前的任务分解方法(如 Skeleton-of-Thought 等)不同,后者通常关注任务层面的分解,但无法让输入规模超越底层 LLM 的物理上下文窗口。RLM 通过将输入“卸载(Offloading)”到环境中,从理论上支持了无限长度的输入处理。
2.3 具体实现细节
-
环境构建:基于 Python 的 REPL。 -
上下文加载:输入文本作为字符串变量存在于内存中。 -
递归机制:提供 llm_query(prompt)函数。在实验中,为了平衡性能与成本,对于 GPT-5 的实验,作者使用了 GPT-5-mini 作为递归调用的子模型(Sub-LM),而根节点(Root LM)使用 GPT-5。 -
系统提示词(System Prompt):固定且通用的提示词,指导模型如何使用 REPL、如何查看上下文长度、如何切分数据以及如何调用子模型。
2.4 变体:无子调用的 RLM (RLM without sub-calls)
为了研究递归调用的必要性,作者设计了一个消融实验版本。在这个版本中,模型依然处于 REPL 环境中,可以编写代码操作 context 变量(如正则匹配、切片),但不能调用 llm_query。这意味着所有的处理必须通过确定性的 Python 代码或模型自身的推理(在有限窗口内)完成。
3. 实验设置:定义长上下文任务的复杂度
本文的一个重要贡献是不仅关注 Prompt 的长度,还关注任务复杂度随长度的扩展模式(Scaling Patterns)。作者假设,LLM 的有效上下文窗口并非独立于任务存在,越复杂的任务,其性能衰减越快。
基于“信息密度(Information Density)”的概念,作者定义了四种不同复杂度的任务:
3.1 复杂度:S-NIAH (Single Needle in a Haystack)
-
任务描述:经典的大海捞针任务。需要在大量无关文本中找到一个特定的短语或数字。 -
扩展特性:无论输入长度如何增加,所需提取的信息量(针)是恒定的。 -
处理成本:大致为常数级 。即使是基座模型,在简单的 NIAH 任务上通常表现良好。
3.2 复杂度但搜索空间大:BrowseComp-Plus
-
任务描述:面向 DeepResearch 的多跳问答基准。需要在一组文档(1K 文档,约 6M-11M Token)中进行推理。 -
扩展特性:虽然需要处理的文档总量巨大,但回答每个问题所需的“金标准”文档数量是常数级的。 -
难度:比 S-NIAH 更难,因为需要从多个文档中拼凑信息,且干扰项极多。
3.3 复杂度:OOLONG
-
任务描述:长推理基准。要求检查输入的每一部分,进行语义转换,然后聚合结果。例如,“统计所有描述为‘抽象概念’的条目数量”。由于数据未显式标记,模型必须阅读每一行并进行语义判断。 -
扩展特性:处理成本与输入长度成线性关系。 -
评分:数值答案采用 ,其他采用精确匹配。
3.4 复杂度:OOLONG-Pairs
-
任务描述:作者手动修改了 OOLONG 的 trec_coarse分割,创建了需要聚合成对(Pairs)块的任务。例如,“找出所有满足特定语义关系的 ID 对”。 -
扩展特性:需要检查数据集中几乎所有的条目对,处理成本与输入长度呈二次方关系。这是对 LLM 的极大挑战。
3.5 对比基线
除了基座模型(Base Model)外,作者对比了以下通用方法:
-
CodeAct (+ BM25) :类似于 CodeAct Agent,可以执行 Python 代码,但不能将 Prompt 卸载到环境,必须直接输入。对于长文档任务,配备 BM25 检索器。 -
Summary Agent:迭代式 Agent。当上下文填满时,调用模型生成摘要,清空上下文并保留摘要,如此往复。对于超长输入,先分块摘要再汇总。
4. 实验
实验主要在 GPT-5(代表前沿闭源模型)和 Qwen3-Coder-480B(代表前沿开源模型)上进行。
4.1 总体性能对比
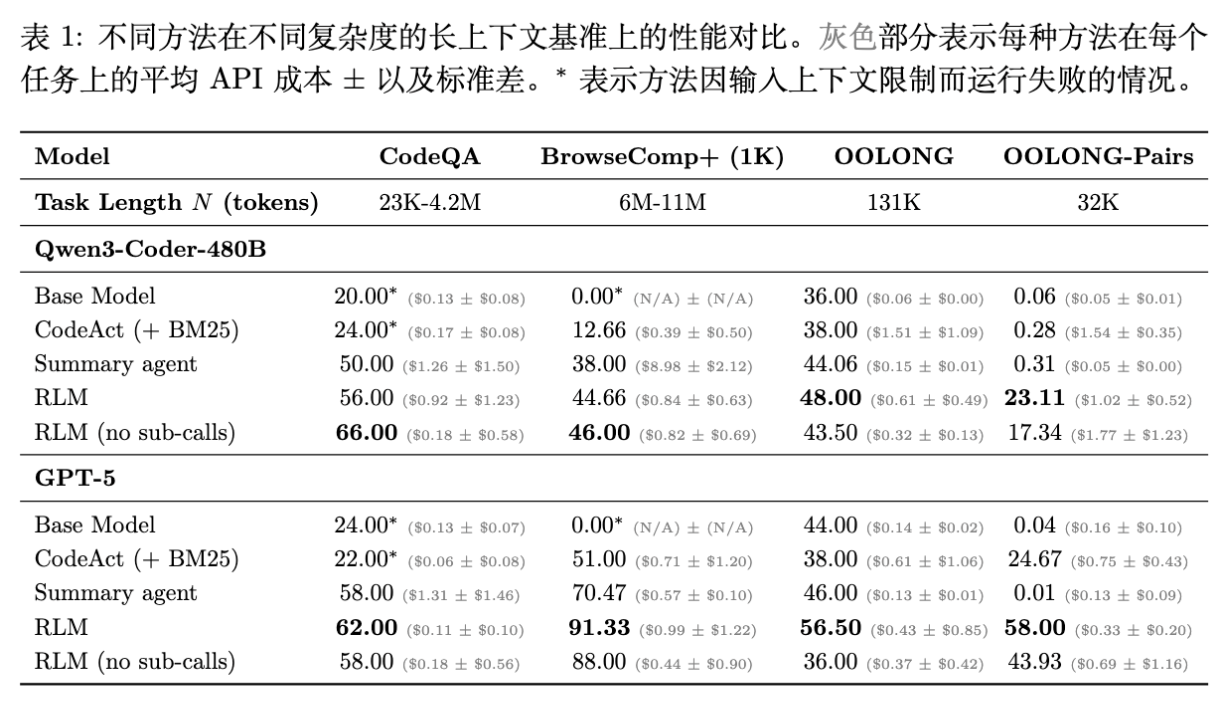
从表 1 的数据中,我们可以得出以下核心结论:
4.1.1 性能显著提升
-
BrowseComp+ (6M-11M Tokens) :这是基座模型无法处理的长度。 -
GPT-5 基座:0.00%(无法运行)。 -
CodeAct + BM25:51.00%。 -
Summary Agent:70.47%。 -
RLM:91.33% 。
-
-
CodeQA (23K-4.2M Tokens) : -
RLM (GPT-5) 达到 62.00% ,显著高于基座模型的 24.00% 和 Summary Agent 的 58.00%。 -
更重要的是成本:RLM 仅需 0.11 刀,而 Summary Agent 需要 1.31 刀。
-
4.1.2 在信息密集型任务上的优势 ( & )
在 OOLONG () 和 OOLONG-Pairs () 任务上,RLM 的优势最为明显,尤其是在复杂的 OOLONG-Pairs 上。
-
OOLONG-Pairs (32K Tokens) : -
这是一个相对较短但极高密度的任务。 -
GPT-5 基座:0.04 分(接近于零)。 -
CodeAct:24.67 分。 -
Summary Agent:0.01 分(摘要过程丢失了大量细节)。 -
RLM:58.00 分。 -
这证明了 RLM 能够处理需要全局两两比较的复杂逻辑,而传统上下文压缩方法完全失效。
-
4.2 扩展性分析
回顾图 1,作者展示了 GPT-5 和 RLM 在不同任务上随长度增加的性能变化。
-
S-NIAH:两条线都保持平稳,因为这只是简单的检索。 -
OOLONG:GPT-5 的性能随长度增加急剧下降,表现出明显的上下文腐烂。而 RLM 保持了相对平稳的高性能。 -
OOLONG-Pairs:GPT-5 几乎在所有长度上都失败了。RLM 虽然也随长度有所下降,但依然保持了可用的性能水平。
这验证了作者的假设:任务越复杂,有效上下文窗口越短。而 RLM 通过将复杂度卸载到递归调用和代码执行中,有效地延缓了这种性能衰减。
4.3 成本与推理时间分析
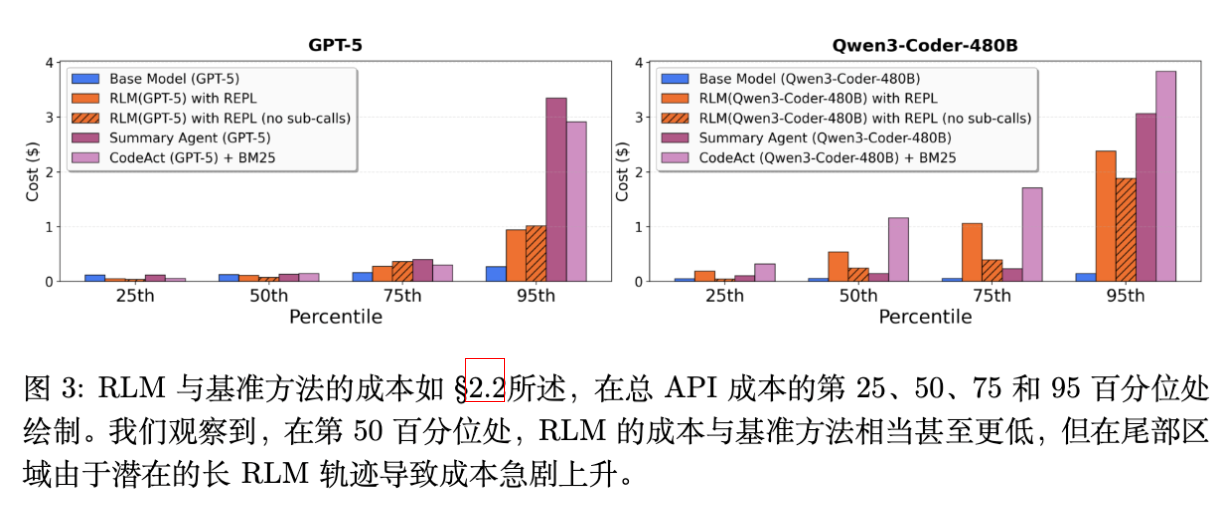
4.3.1 成本效益
一个普遍的担忧是:递归调用会不会导致成本爆炸?
-
观察 1:RLM 的平均成本通常与基座模型相当,甚至更低。 -
原因:RLM 具有“选择性阅读”的能力。它不需要像 Summary Agent 那样读取并处理每一个 Token,而是可以通过代码(如正则表达式、关键词搜索)先过滤出相关片段,只对这些片段进行昂贵的 LLM 调用。 -
在 CodeQA 任务中,RLM(GPT-5) 的成本($0.11)远低于直接读取全部上下文的成本。
4.3.2 成本的高方差
-
观察 4:RLM 的成本方差很大(High Variance)。 -
如[图 3 中文标题]所示,虽然中位数成本很低,但在长尾部分(95th percentile),RLM 的成本会急剧上升。这是因为对于某些困难的 query,RLM 可能会陷入较长的探索循环,或者发起大量的子调用。相比之下,Summary Agent 的成本是确定性的(读取所有 Token)。
4.3.3 推理时间
文中(Appendix C)指出,当前的 RLM 实现是同步阻塞的(Synchronous/Blocking),导致运行时间较长。但理论上,通过异步并发调用子模型,可以显著降低延迟。
5. RLM 的行为模式与涌现能力
RLM 的强大不仅在于架构,更在于模型在 REPL 环境中展现出的自适应行为。作者通过定性分析,总结了几种关键的涌现模式(Emergent Patterns)。
5.1 过滤与先验知识 (Filtering based on Priors)

在处理超长文本时,模型展现出了类似于人类的策略:利用先验知识缩小搜索范围。
-
案例:在 BrowseComp 的一个任务中,需要寻找关于“beauty pageant(选美比赛)”的信息。 -
行为:RLM(GPT-5) 没有从头阅读 1000 个文档,而是编写了 regex查询,搜索包含 "festival", "beauty pageant" 等关键词的文档块。 -
效果:这种策略使得模型只需要处理极小一部分 Token,从而大幅降低了成本并提高了准确率(减少了干扰信息)。
5.2 分块与递归子调用
对于无法简单过滤的密集任务(如 OOLONG),模型选择了分块策略。
-
行为:RLM 编写代码将长文本按行或按特定分隔符切分,然后在一个 for循环中对每个块调用llm_query。 -
差异:有趣的是,GPT-5 和 Qwen3-Coder 表现出了不同的“性格”。 -
GPT-5:倾向于保守,尽量少调用子模型,通过更复杂的代码逻辑处理。 -
Qwen3-Coder:倾向于“暴力”递归,对每一行都调用一次子模型。这导致 Qwen 在 OOLONG 任务上生成了数千次子调用,虽然解决了问题,但效率极低。为此,作者不得不针对 Qwen 修改了 System Prompt,显式警告其不要进行过多的子调用。
-
5.3 答案验证 (Answer Verification)
RLM 经常在得出初步答案后,利用剩余的计算资源进行验证。
-
代码验证:编写 Python 代码检查提取的数据是否符合逻辑约束(如 OOLONG-Pairs 中的 ID 匹配)。 -
子模型验证:再次调用 LLM,询问“这个答案是否符合原文?”。 -
反例:有时验证是冗余的。在 Appendix B.3 的案例中,Qwen3-Coder 尝试了 5 次重生成答案,尽管第一次就是对的,最后反而输出了错误结果。这表明模型作为 Agent 的决策能力仍需优化。
5.4 变量传递与结果拼接
对于输出也很长的任务(Long-output tasks),RLM 能够利用变量在不同子调用间传递状态。
-
策略:模型创建一个列表变量 results = [],在循环中将子模型的输出append进去,最后将整个列表作为上下文回答最终问题。 -
意义:这突破了 LLM 单次输出 Token 的限制(Output Token Limit)。只要中间结果存储在变量中,RLM 理论上可以生成无限长度的最终答案(只要内存允许)。
6. 消融研究:REPL 重要还是递归重要?
为了解构 RLM 的性能来源,作者进行了消融实验:RLM with REPL, no sub-calls。即保留编程环境,但禁止调用子 LLM。
-
观察 2:REPL 环境本身对于处理长输入至关重要,而递归调用在信息密集型任务上提供额外增益。 -
CodeQA & BrowseComp+ : -
在 Qwen3-Coder 上,无子调用的版本甚至优于完整版 RLM(66.00% vs 56.00%)。这说明对于某些“大海捞针”类任务,只要能用代码进行字符串搜索和切片,不需要额外的 LLM 推理,甚至能避免子模型带来的“幻觉”或级联错误。
-
-
OOLONG & OOLONG-Pairs: -
完整版 RLM 显著优于无子调用版本(例如 GPT-5 在 OOLONG-Pairs 上是 58.00 vs 43.93)。 -
这是因为这些任务需要对文本进行语义理解(Semantic Transformation),仅靠 Python 字符串操作无法完成(例如判断一段描述是否属于“抽象概念”)。此时,递归调用子 LLM 进行语义判断是必须的。
-
结论:如果任务侧重于精确匹配和提取,REPL + 代码能力是关键;如果任务侧重于语义理解和推理,递归调用是关键。
7. 讨论与限制
7.1 从 Token 空间到符号空间
RLM 的本质是将推理过程从纯粹的 Token 生成(概率空间)转移到了符号操作空间(REPL 环境)。通过引入变量和递归,RLM 获得了一种类似于图灵机(Turing Machine)的计算能力——理论上拥有无限的磁带(外部存储)和读写头(LLM + Code)。
7.2 模型能力的依赖
RLM 对基座模型的代码生成能力(Coding Ability)和指令遵循能力(Instruction Following)要求极高。
-
作者在 Appendix A 中提到,较小的模型(如 Qwen3-8B)无法作为 RLM 运行,因为它们无法生成正确的 REPL 代码或无法正确维护环境状态。 -
即使是 Qwen3-Coder-480B 这样的强力模型,也需要特定的 Prompt 调整(如防止过度递归)。
7.3 局限性
-
延迟(Latency):目前的串行调用导致处理时间较长。对于实时性要求高的应用,需要工程上的优化(如异步并发)。 -
决策效率:当前的 LLM 并不是“天生”的 RLM。它们有时会做出低效的决策(如重复验证、错误分块)。未来可能需要专门针对 RLM 范式微调(Fine-tuning)模型。 -
安全性:允许模型编写并执行代码、递归调用自身,存在潜在的死循环或资源耗尽风险,需要严格的沙箱(Sandbox)和资源限制。
更多细节请阅读原文。
往期文章:


