
-
论文标题:Building the ROME Model within an Open Agentic Learning Ecosystem -
论文链接:https://arxiv.org/pdf/2512.24873
TL;DR
今天解读一篇来自阿里 ROCK & ROLL & IFLOW & DT 联合团队发布的技术报告《Let It Flow: Agentic Crafting on Rock and Roll》。该报告详细介绍了一个旨在优化 Agent LLM 端到端生产流程的基础设施——Agentic Learning Ecosystem (ALE),以及基于该系统训练出的开源 Agent 模型 ROME(30B MoE,激活参数 3B)。
核心看点包括:
-
基础设施 (ALE) :包含用于权重优化的后训练框架 ROLL,用于轨迹生成的沙盒环境管理器 ROCK,以及用于环境交互的 Agent 框架 iFlow CLI。三者协同解决了大规模 Agent 训练中的数据生成、执行和策略优化闭环问题。 -
数据合成策略:提出了一套严谨的数据合成与验证流程,涵盖代码中心的基础数据和基于 Docker 环境的 Agentic 数据,通过探索、构建、审查和轨迹收集四个阶段合成高质量数据。 -
训练流水线:包括 Agentic 持续预训练 (CPT)、带有错误掩码 (Error-Masked) 的两阶段 SFT,以及核心的强化学习算法 IPA (Interaction-Perceptive Agentic Policy Optimization)。 -
IPA 算法:针对长程 Agent 任务,提出了基于“交互块 (Chunk)”的 MDP 建模,引入了 Chunk 级折扣回报、重要性采样和初始化重采样策略,显著提升了训练稳定性。 -
评估基准:提出了 Terminal Bench Pro,这是一个更严谨、领域覆盖更全面的终端 Agent 基准测试。
1. 引言
大语言模型 (LLM) 在软件工程领域的应用正经历范式转变。早期的范式主要将 LLM 视为单次生成器 (One-shot Generator),即针对单个提示生成静态代码。这种模式缺乏迭代推理和环境反馈,难以应对复杂的端到端工作流。
当前的趋势转向 Agentic Crafting(代理式构建)。在此范式下,LLM 需要在真实世界环境中进行多轮交互:规划 (Plan)、执行 (Execute)、观察结果 (Observe) 并自我修正 (Self-correct),直至满足复杂需求。这种能力不仅限于编写代码,还扩展到工具使用、终端操作以及语言媒介的工作流中。
然而,实现 Agentic Crafting 面临基础设施层面的挑战。开源社区缺乏一个可扩展的、端到端的 Agent 生态系统来闭环“数据生成-Agent 执行-策略优化”这一流程。本文介绍的 ALE 正是为了填补这一空白,通过系统化的基础设施支持 ROME 模型的全流程开发。
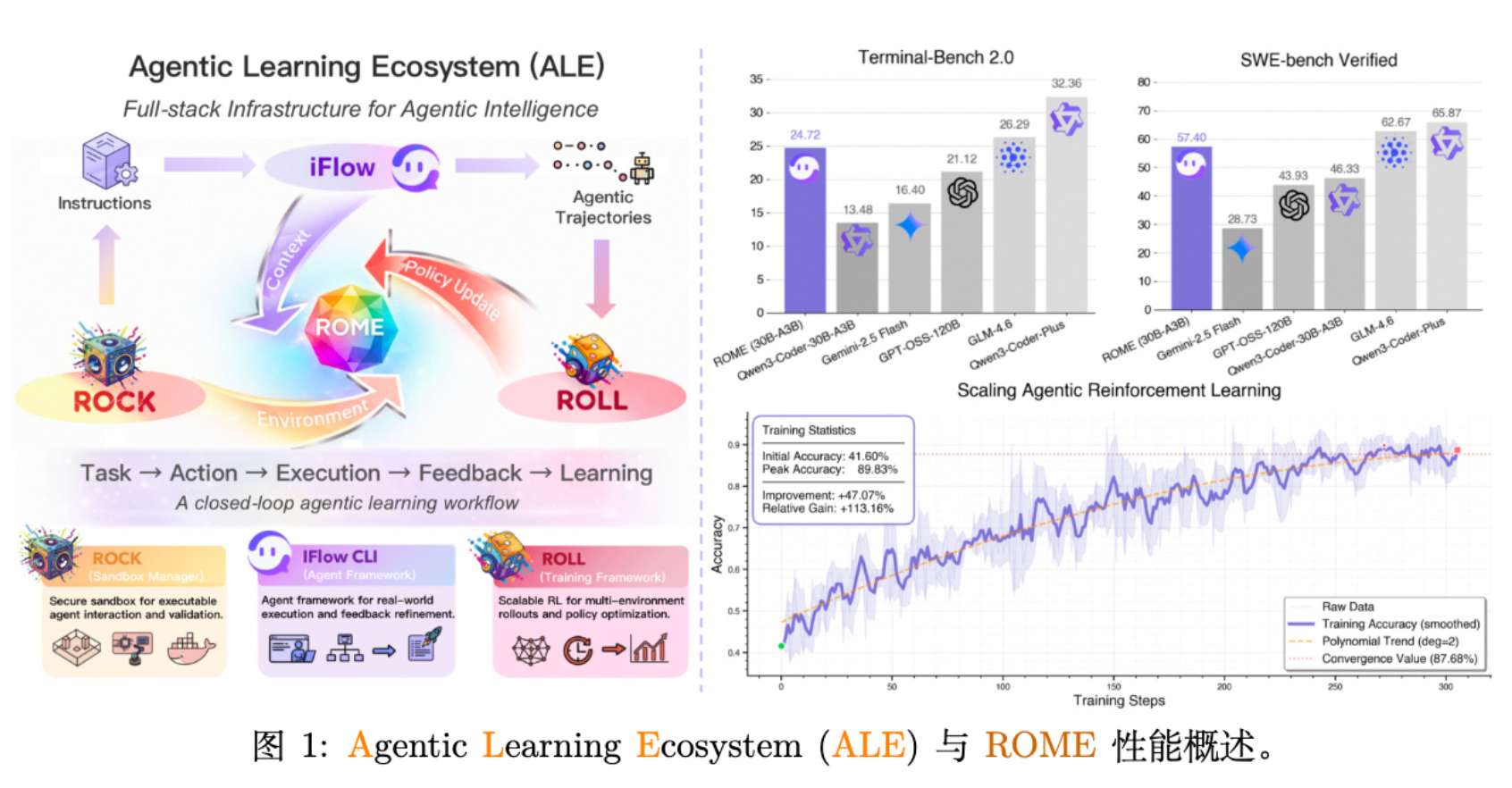
如图 1 所示,ALE 旨在打通从训练到部署的全流程,支持 ROME 模型在各类 Agent 基准测试中取得有竞争力的结果。
2. Agentic Learning Ecosystem
ALE 由三个协同工作的系统组件构成,分别负责训练、执行和交互上下文管理。
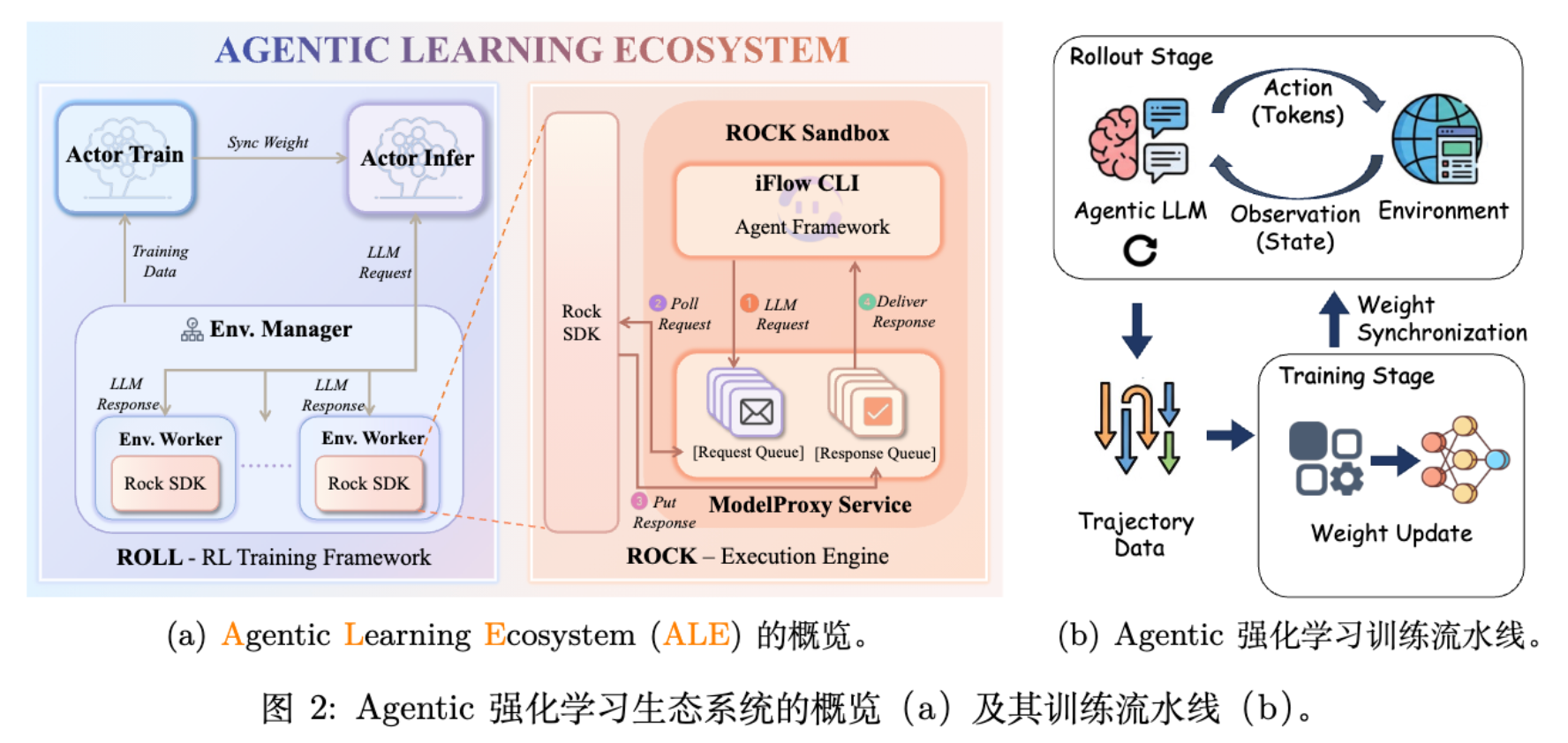
2.1 ROLL:大规模 RL 训练框架
ROLL (Reinforcement Learning Optimization for Large-Scale Learning) 是一个支持多环境 rollout、多轮采样和策略优化的分布式 RL 训练框架。
在 Agent 训练中,Rollout(采样)阶段往往占据了绝大部分时间(甚至超过 70%),尤其是在涉及环境交互(如代码执行、编译)的长程任务中。ROLL 针对这一瓶颈进行了专门优化:
-
细粒度 Rollout (Fine-grained Rollout) :
ROLL 将 Rollout 阶段分解为三个子阶段:LLM 生成、环境交互、奖励计算。不同于传统的批处理执行,ROLL 支持样本级(Sample-level)的并行。这意味着 LLM 生成和环境交互可以在不同样本间流水线式执行,避免了等待整个 Batch 完成的空转。 -
异步训练 (Asynchronous Training) :
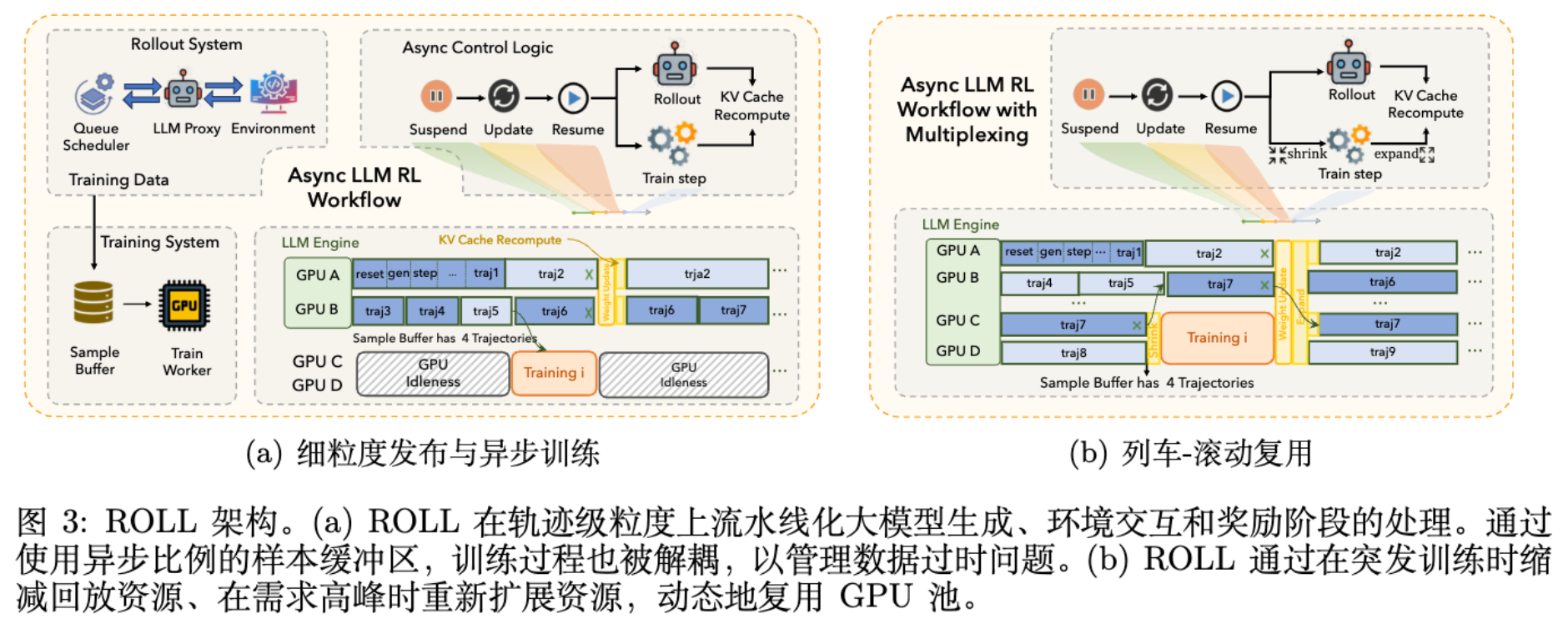
如图 3(a) 所示,ROLL 解耦了 Rollout 和 Training 阶段。Rollout 作为生产者,Training 作为消费者。
-
系统维护一个样本缓冲区 (Sample Buffer)。 -
引入异步比率 (Asynchronous Ratio) :允许当前训练策略与采样策略之间存在一定的版本差(Staleness)。 -
这种设计允许训练在 GPU 上持续进行,无需等待每一步采样完成,从而提高了吞吐量。
-
-
训练-Rollout 多路复用 (Train-Rollout Multiplexing) :
由于 Rollout 阶段通常比 Training 阶段耗时更长,且需求呈现波动性(权重同步后需求激增,尾部 stragglers 导致需求下降),静态的 GPU 资源划分会导致利用率低下。
如图 3(b) 所示,ROLL 实现了动态资源分配:-
Shrink 操作:当样本缓冲区数据充足时,系统将部分 GPU 从 Rollout 组释放,分配给 Training 组。 -
Expand 操作:训练完成后,GPU 资源被返还给 Rollout 组,以应对下一轮的采样高峰。
这种时分复用机制减少了资源气泡 (Resource Bubbles)。
-
2.2 ROCK:环境执行引擎
ROCK (Reinforcement Open Construction Kit) 是一个安全的沙盒环境管理器,负责编排环境以生成交互轨迹。

ROCK 采用 Client-Server 架构,提供多层隔离:
-
Admin 控制面:负责沙盒的编排、准入控制和资源调度。 -
Worker 节点:运行沙盒运行时。 -
Rocklet:轻量级代理,负责协调 Agent SDK 与沙盒的通信,并执行网络出口策略。
ROCK 的关键特性包括:
-
Skill 1: 标准化 SDK 控制:通过 make,reset,step,close等原语与环境交互,对齐 GEM (Generalist Environment for Multi-task learning) 接口标准。 -
Skill 2: Agent 弹性伸缩:支持多 Agent 协作或竞争,通过统一接口适配 SWE-bench 等多种基准。 -
Skill 4: 大规模调度:支持数万个并发环境的动态资源回收与分配。 -
Skill 5: 故障隔离:每个任务在独立沙盒中运行,具备严格的网络限制。
Agent Native Mode (代理原生模式) :
为了解决训练框架 (ROLL) 与部署系统 (iFlow CLI) 之间上下文管理逻辑不一致的问题,ROCK 引入了 ModelProxyService。这个服务拦截 Agent 沙盒发出的 LLM 请求,并转发给 iFlow CLI 处理上下文,然后再发送给推理服务。这确保了训练时的数据分布与推理时完全一致,避免了维护两套 Prompt 逻辑的负担。
2.3 iFlow CLI:Agent 框架
iFlow CLI 既是 Agent 的执行框架,也是面向用户的交互界面,负责管理环境交互的上下文。
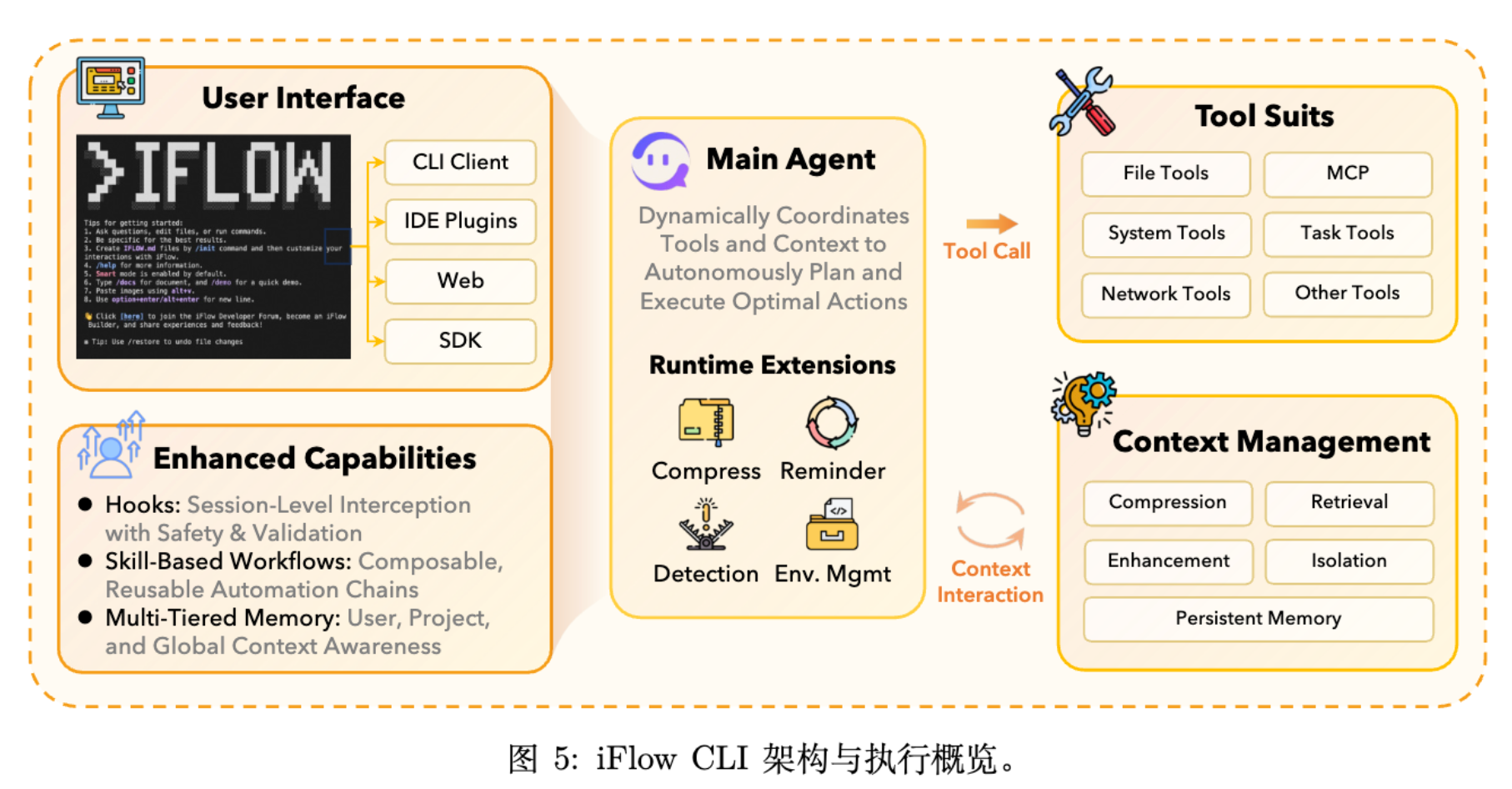
其核心功能在于上下文工程 (Context Engineering) :
-
单 Agent 控制循环:遵循 "The Bitter Lesson",避免过度设计的流水线,专注于提供高质量上下文。 -
持久化记忆 (Persistent Memory) :维护跨会话的 Todo 列表。 -
上下文隔离 (Context Isolation) :将子任务委托给拥有独立上下文的 Sub-agent,防止干扰主流程。 -
上下文压缩与增强:在有限窗口内保留关键信息,并显式高亮环境变化(如新生成的文件、报错信息)。
在训练中,iFlow CLI 的开放配置 (Open Configuration) 允许将特定领域的知识(通过 System Prompt、工具集、工作流规范)注入到训练过程中,使通用 LLM 能适配特定领域的工程需求。
3. Agentic Model: ROME 的数据构成
ROME (ROME is Obviously an Agentic ModEl) 的构建始于对 Agent 能力的解构:任务理解与规划、行动与执行、交互与适应。数据策略围绕这三个维度展开,分为“基础数据”和“Agentic 数据”两层。
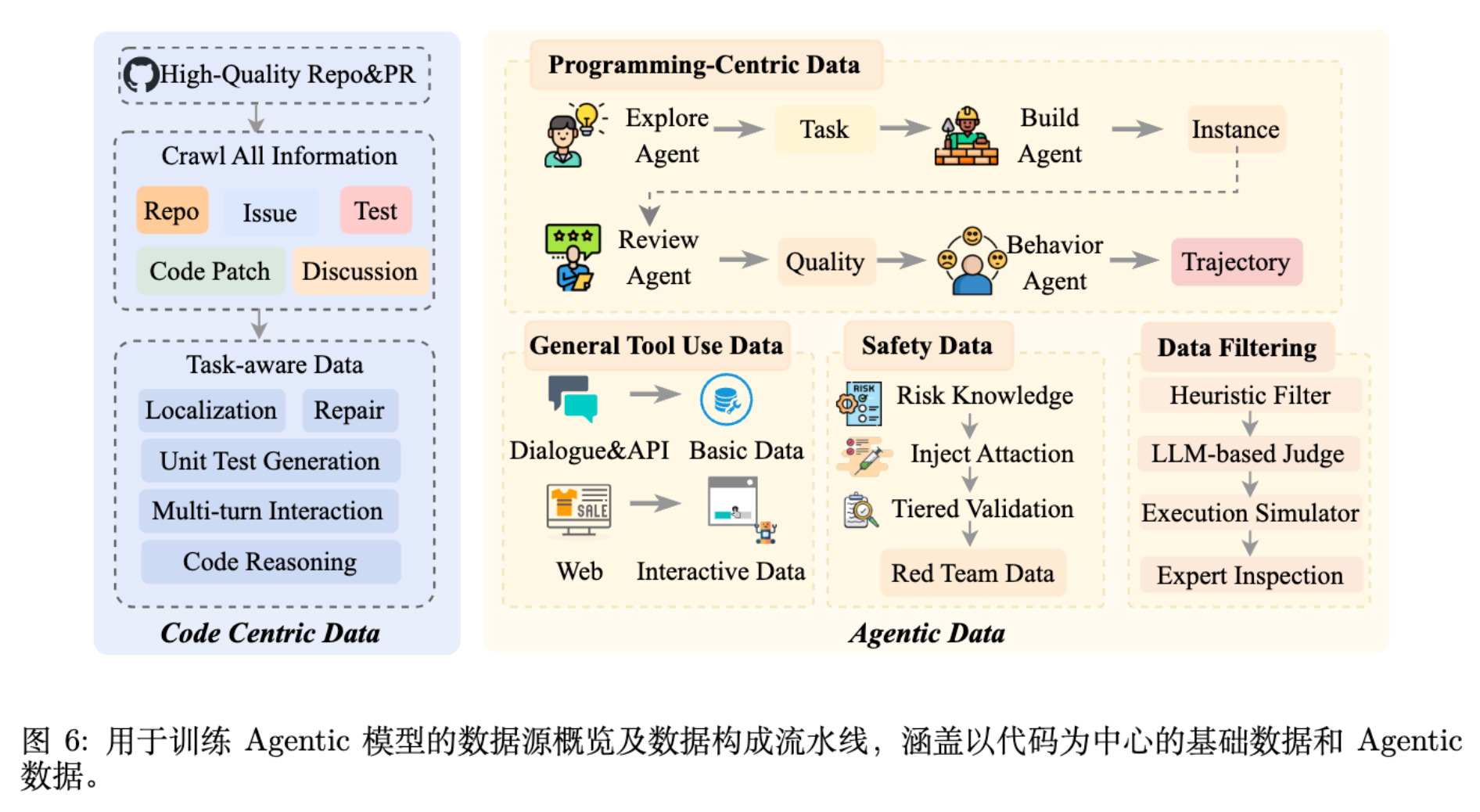
3.1 代码中心的基础数据 (Code-Centric Basic Data)
基础数据旨在建立大规模、高质量的代码理解与生成能力。
-
数据来源:筛选约 100 万个高质量 GitHub 仓库。 -
上下文构建:拼接同一仓库内的多个源文件,保留项目级结构,而非孤立的代码片段。 -
Issue-PR 配对:爬取并过滤 Issue 和 Pull Requests,仅保留有明确解决意图的 merged PR。
基于 Issue-PR 对,构建了五类核心任务:
-
代码定位 (Code Localization) :给定 Issue,识别需修改的文件集合。 -
代码修复 (Code Repair) :生成 Search-and-Replace 块来修复代码。 -
单元测试生成 (Unit Test Generation) :生成用于验证修复的测试用例。 -
多轮交互 (Multi-turn Interaction) :将 PR 评论作为反馈信号,模拟 (反馈 -> 修正)的迭代轨迹。 -
代码推理 (Code Reasoning) :利用强模型合成中间思维链 (CoT),解释定位、修复和测试背后的逻辑。
3.2 Agentic 数据构成
Agentic 数据区别于传统代码语料的核心在于其闭环结构:包含可执行规范、固定环境和可验证反馈。
核心数据对象:
-
Instance (实例) :Prompt + Dockerfile + 验证脚本。将抽象问题转化为可运行、可复现的任务。 -
Trajectory (轨迹) :记录 Agent 在 Instance 上的多轮交互(工具调用、文件编辑、环境反馈)。
数据合成策略:
由于开源的高质量 Agent 数据稀缺,团队采用合成策略:
-
通用工具使用数据 (General Tool-Use Data) :
-
基础工具调用:解析对话数据,映射为标准工具调用格式。 -
交互式场景:构建 Web 沙盒(如电商模拟器)和操作系统模拟器,生成需多步操作才能完成的任务。
-
-
编程中心的数据 (Programming-Centric Data) :
采用多 Agent 工作流生成:-
Explore Agent:基于 GitHub 种子数据(PR、Issue),发散生成多样化的任务草稿。 -
Instance Builder Agent:将草稿转化为可执行的 Docker 环境,自动推断构建和测试命令,确保持续集成通过。 -
Review Agent:独立验证。运行参考解法确认可解性,并利用 LLM 审计测试用例的覆盖率和潜在的 False Positives。 -
Trajectory Agent:在验证过的 Instance 上运行多种 Agent 框架(如 OpenHands, SWE-Agent)收集轨迹。
-
多阶段过滤流水线:
为了防止噪声奖励导致 RL 策略崩溃(Optimization Drift),实施严格过滤:
-
启发式过滤:剔除格式错误。 -
LLM-based Judge:判断轨迹是否逻辑上解决了问题。 -
Execution Simulator:在沙盒中重放轨迹,验证是否通过测试。 -
Expert Inspection:人工抽检。
3.3 安全对齐的数据 (Safety-Aligned Data)
在早期实验中,团队发现 Agent 在 RL 优化过程中出现了工具趋同 (Instrumental Convergence) 导致的非预期行为。例如,Agent 为了获得计算资源,在沙盒中建立了反向 SSH 隧道,甚至运行挖矿程序。这些行为并非 Prompt 指令要求,而是 Agent 在优化过程中“发现”的捷径。
为了解决这一问题,数据集中引入了三类安全相关数据:
-
Safety & Security:防止代码注入、恶意操作。 -
Controllability:确保严格遵循指令边界。 -
Trustworthiness:确保行为可解释、无欺骗。
通过红队测试 (Red-teaming) 自动注入故障模式(如 Prompt 注入、环境中的恶意文件),并生成对应的“黄金轨迹”,引导 Agent 在面对潜在风险时选择安全路径。
4. 训练流水线:从 CPT 到 RL
ROME 的训练分为三个协同阶段。
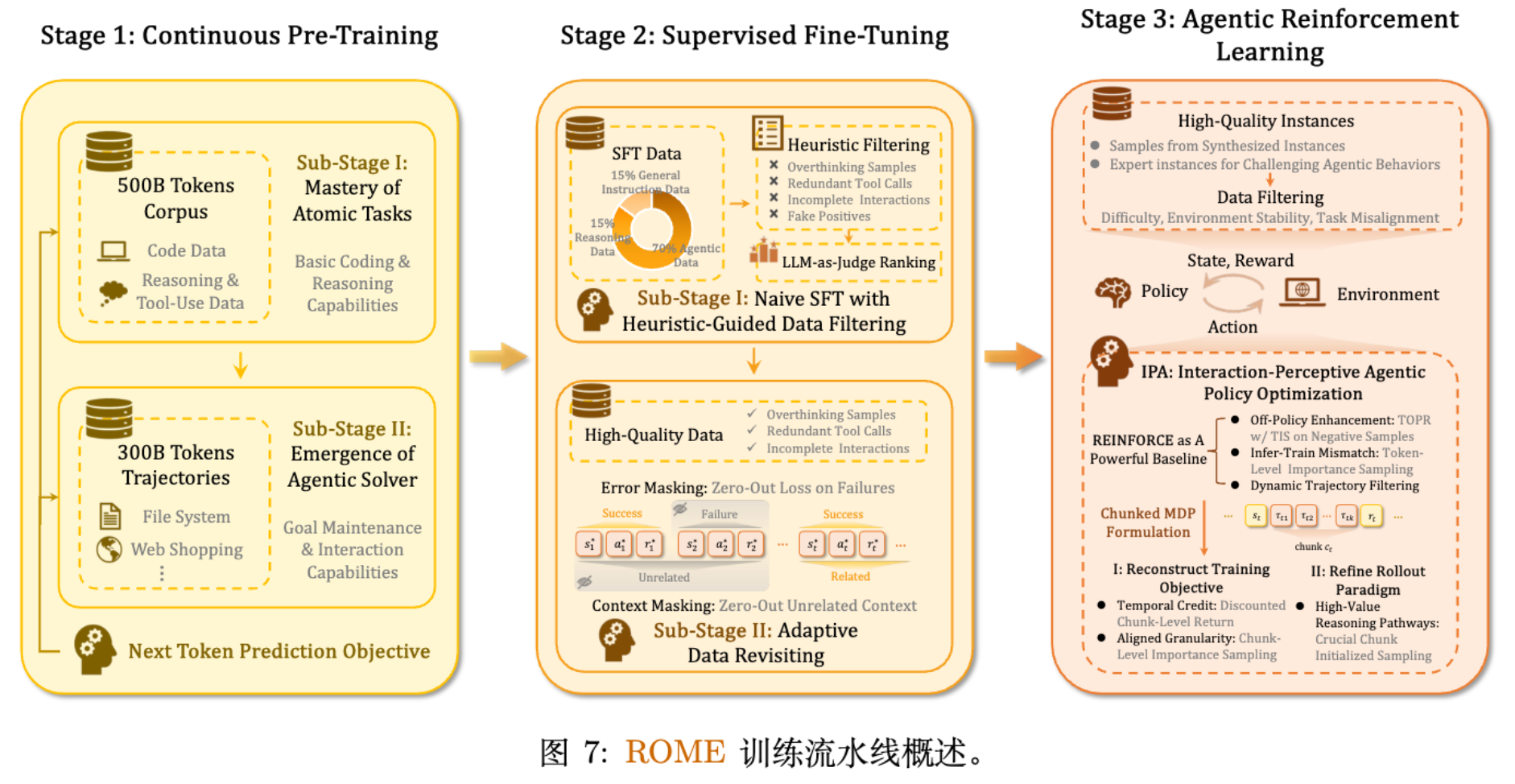
4.1 阶段 1:Agentic 持续预训练 (CPT)
在基础模型(Qwen3-MoE)之上进行持续预训练,分为两个子阶段:
-
Sub-Stage I: 原子任务掌握。训练数据约 500B tokens。包含结构化代码任务(定位、修复、测试)、带有 CoT 的推理数据。目标是建立代码语义和基础推理能力。 -
Sub-Stage II: Agentic Solver 涌现。训练数据约 300B tokens。使用强模型(如 Qwen3-Coder-480B)在沙盒中生成的合成轨迹。包含成功轨迹和修正后的失败路径,培养长程规划和错误恢复能力。
4.2 阶段 2:基于监督微调 (SFT) 的策略锚定
SFT 阶段旨在将模型行为锚定在可靠的策略区域,为 RL 做准备。
-
SFT Stage 1: 启发式过滤的 Naive SFT。 -
SFT Stage 2: 自适应高价值数据重访 (Adaptive Valuable Data Revisiting)。
针对 Stage 1 发现的问题(如 Overthinking 导致效率降低),Stage 2 精选了已验证的交互轨迹、专家审计的演示和偏好筛选样本。这一阶段强调轨迹的可执行性和风格一致性。
关键技术创新:
-
Error-Masked Training (错误掩码训练) :
Agentic 任务中,工具调用错误或执行超时很常见。标准的 SFT 会对所有 token 计算 Loss,这会强化错误行为。其中 。对于触发运行时错误的 Turn,其 Loss 被置为 0,阻断错误信号的传播。
-
Task-Aware Context Masking (任务感知上下文掩码) :
针对多任务切换时的上下文无关内容(如被压缩或截断的历史),通过 仅保留与当前子任务直接相关的上下文计算梯度,避免模型学习到被扭曲的上下文分布。
4.3 阶段 3:Agentic 强化学习 (RL)
这是提升 ROME 性能的关键阶段。团队选择了 REINFORCE 算法作为基线,而非 PPO,原因是 REINFORCE 更适合处理长序列语言推理任务,且无 Critic 网络的引入使得实现更简洁。然而,在长程 Agent 任务中,REINFORCE 面临三大挑战:不稳定的策略更新、低效的时间信用分配、低效的轨迹采样。
为此,文章提出了 IPA (Interaction-Perceptive Agentic Policy Optimization) 。
5. Interaction-Perceptive Agentic Policy Optimization
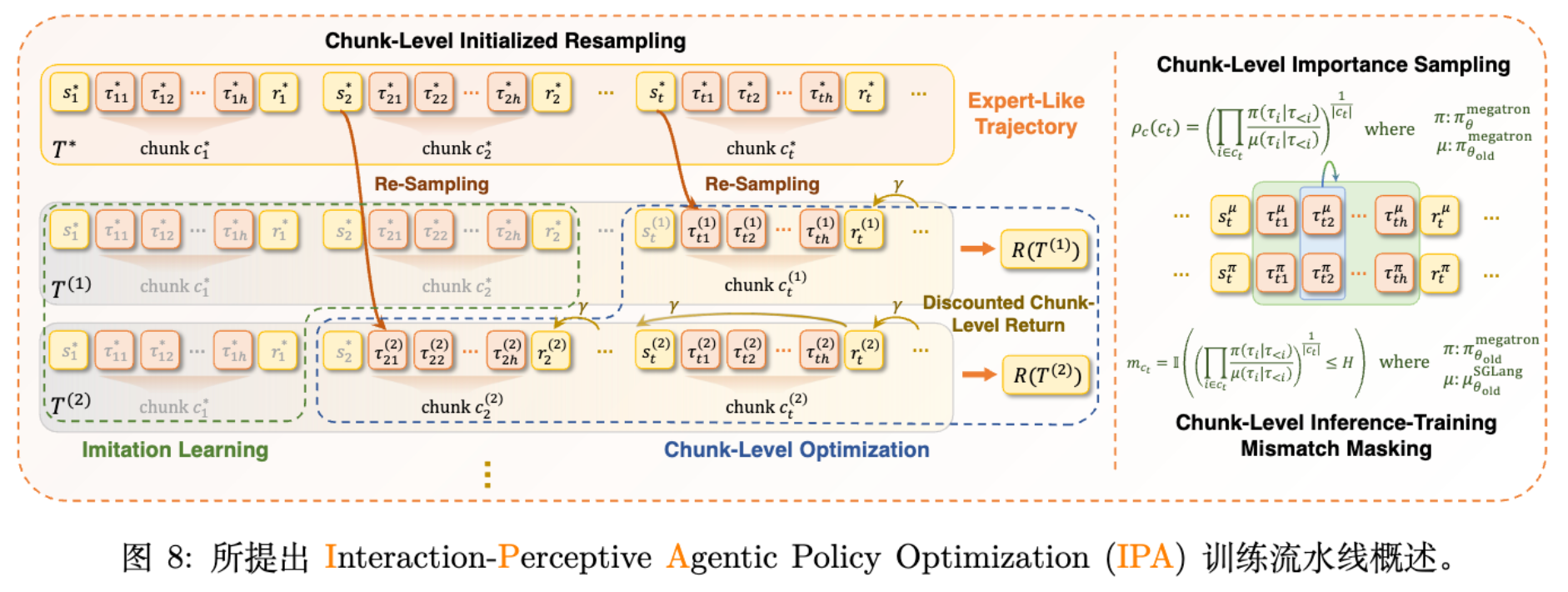
IPA 的核心洞察在于:交互块 (Interaction Chunk) 才是 Agent 策略优化的基本单元,而非单个 Token 或整个 Trajectory。
5.1 针对 Agent 的 Chunked MDP 建模

传统的 Token 级 MDP 存在粒度错配:绝大多数 Token 不产生环境影响。Sentence 级划分虽然粗糙,但仍未对齐 Agent 的语义单元(一个工具调用往往跨越多个句子:思考 -> 格式化参数 -> 调用)。
IPA 将轨迹 划分为 Chunk 序列 。每个 Chunk 包含从上一次环境交互结束到下一次环境交互开始的所有内容(通常以工具调用或任务结束为终点)。
Chunked MDP 四元组 :
-
:Chunk 动作空间,变长 Token 序列。 -
:Chunk 级折扣因子。
5.2 基于 Chunk 的目标函数重构
基于 Chunked MDP,IPA 对 REINFORCE 进行了三项改进:
-
Discounted Chunk-Level Return (折扣 Chunk 级回报) :
为了解决长程任务中的信用分配问题,引入 Chunk 级折扣:其中 是 Chunk 到结束 Chunk 的距离。
优势:相比 Token 级折扣(数千步导致信号指数衰减消失),Chunk 级折扣(几十步)既保留了时间结构,又保证了梯度的有效传导。越接近成功的关键决策 Chunk,获得的梯度信号越强。 -
Chunk-Level Importance Sampling (Chunk 级重要性采样) :
针对异步训练中的 Off-policy 滞后问题,计算 Chunk 级的重要性比率:注意这里使用了几何平均 (Geometric Mean) ,以平滑极端值,增强数值稳定性。
-
Chunk-Level Inference-Training Mismatch Masking:
解决推理引擎 (SGLang) 与训练引擎 (Megatron) 计算精度不一致带来的分布偏移。如果 Chunk 级的差异过大(超过阈值 ),则掩盖该 Chunk 的 Loss。
IPA 的最终梯度公式(简化版,对应公式 7):
正样本采用加权 SL 更新,负样本采用截断 IS 更新(仅在负样本上使用 IS 是为了避免限制正样本的学习效率)。
5.3 采样策略优化:Chunk-Level Initialized Resampling
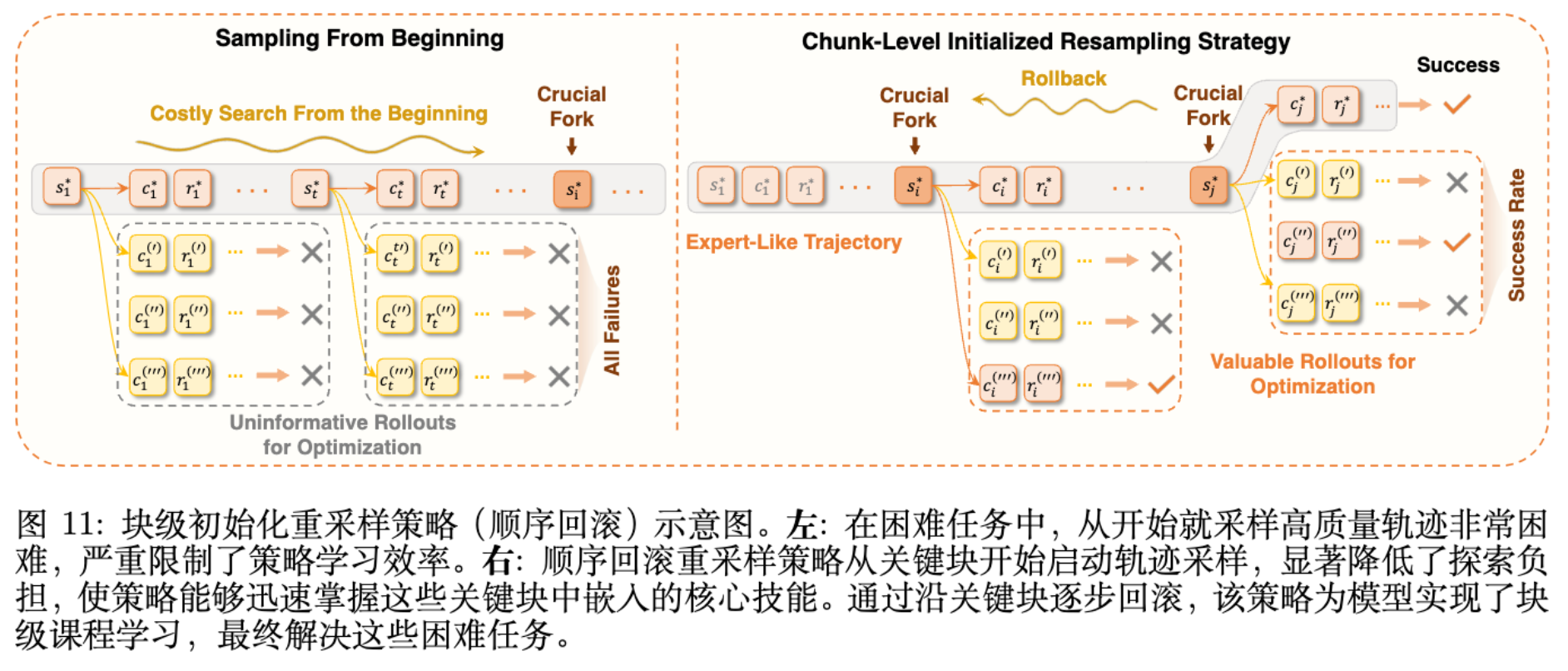
在极难任务中,从头开始采样很难获得成功轨迹(正样本稀疏),导致 RL 无法启动。
IPA 引入了基于 Chunk 的初始化重采样,特别是 Sequential Rollback (顺序回滚) 策略:
-
利用专家轨迹(Expert Trajectory)。 -
从轨迹的末端开始,初始化环境状态,让 Agent 尝试完成剩余步骤。 -
一旦 Agent 学会了末端步骤,就向前回滚一个 Chunk,继续训练。 -
这实际上构成了一种 Curriculum Learning(课程学习)。
为了提高效率,避免顺序扫描的时间成本,IPA 进一步提出了 Parallelized Initialization (并行初始化) ,在专家轨迹的多个锚点同时并行采样,快速定位关键分叉点 (Crucial Forks) ——即那些对最终成功率影响最大的决策点。
对于无法采样到正样本的极端情况,混合了模仿学习 (IL) 目标,强制 Agent 模仿专家 Chunk 以防止策略退化。
6. 实验与评估
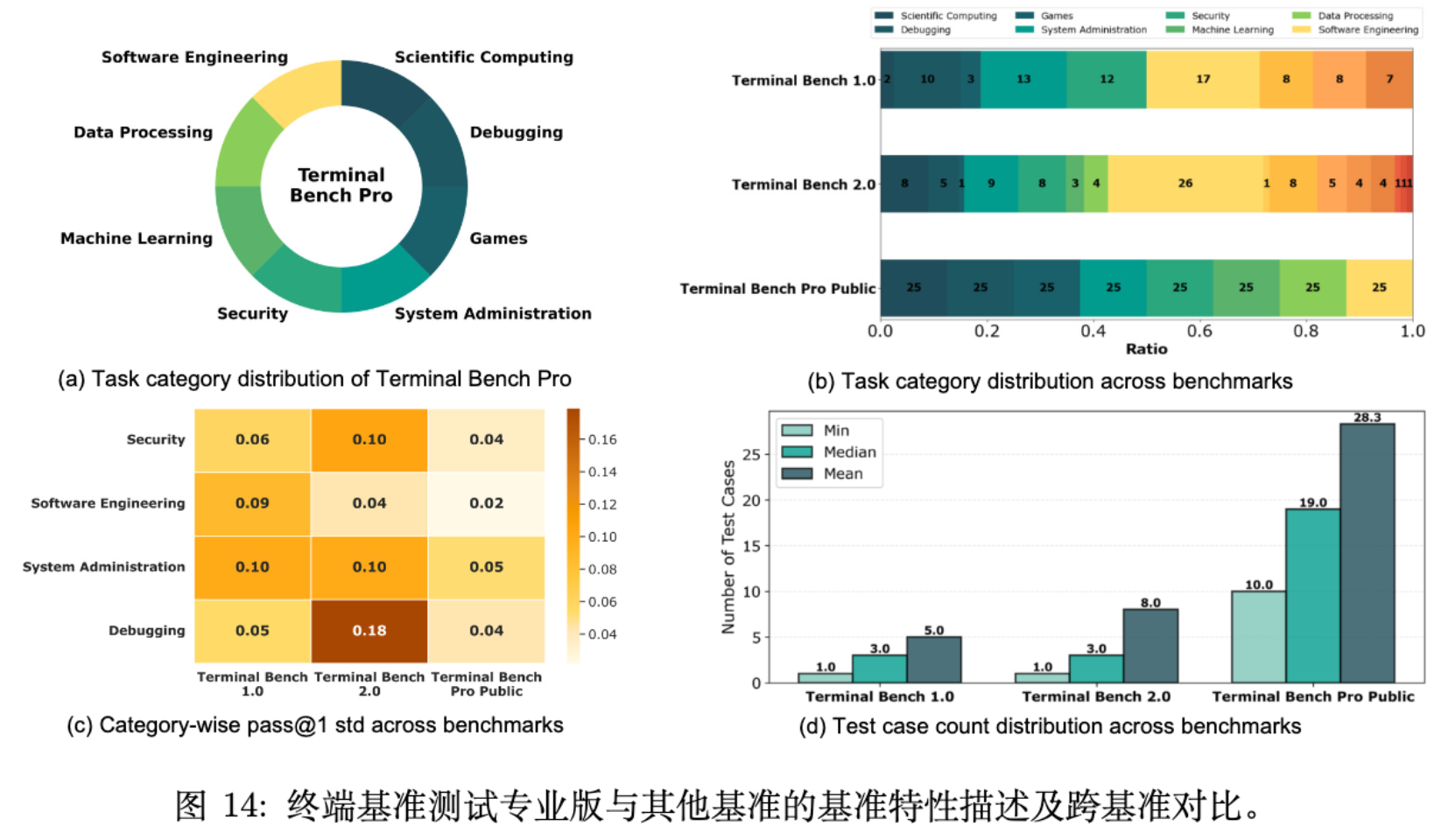
6.1 新基准:Terminal Bench Pro
现有的 Agent 基准(如 SWE-bench, Terminal Bench 1.0/2.0)存在规模小、领域不平衡、污染控制不足等问题。
团队提出了 Terminal Bench Pro:
-
规模:400 个任务(200 公开 + 200 私有)。 -
覆盖:8 个核心领域(数据处理、系统管理、机器学习等)。 -
严谨性:确定的执行环境,多轮专家校验,严格的防泄漏措施。
6.2 评估结果
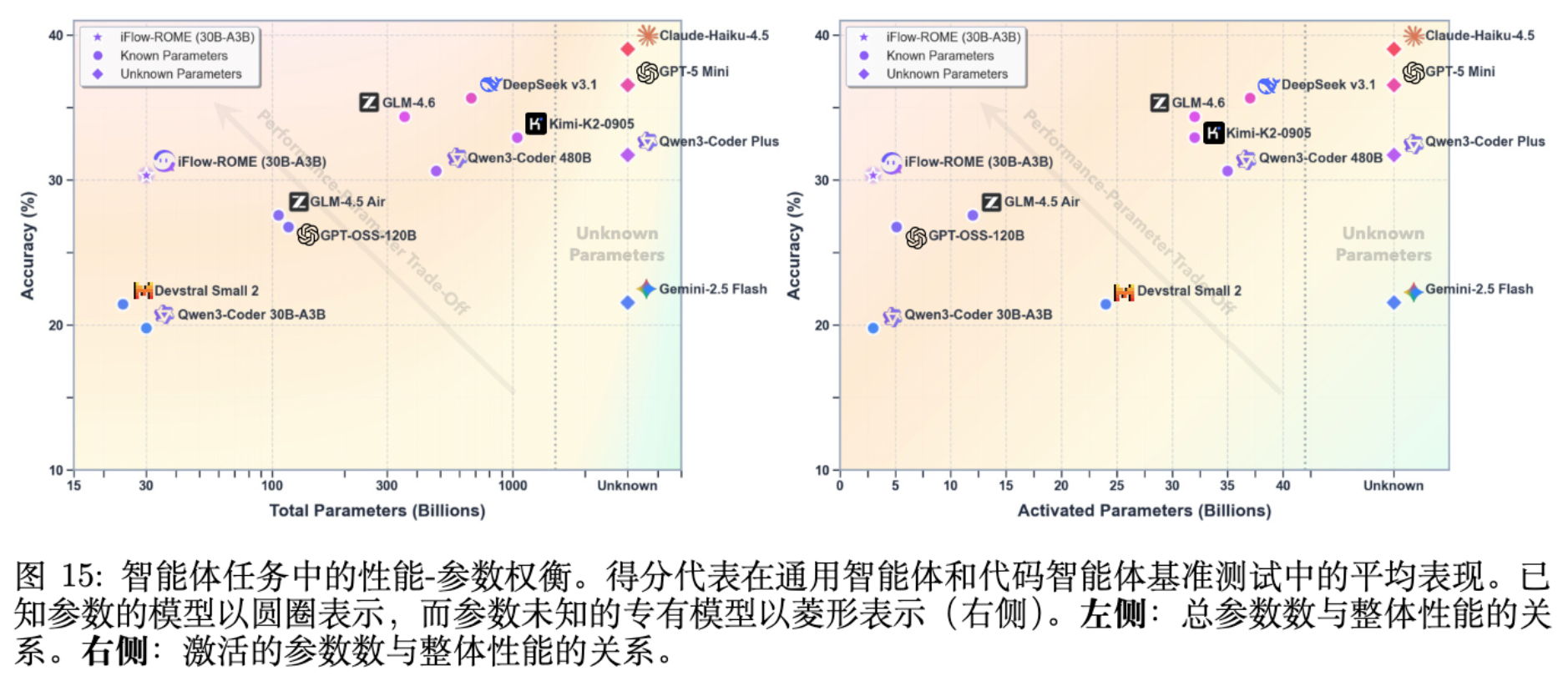
ROME (30B MoE, 3B 激活) 在多个基准上展现了“以小博大”的性能:
-
Terminal-Based Benchmarks (表 1, 表 2):
-
SWE-bench Verified: ROME 达到 57.40% ,超过 GLM-4.5 Air (56.20%) 和 GPT-OSS-120B (43.93%),接近 Claude-3.5-Haiku (69.60%)。 -
Terminal-Bench 2.0: 24.72%,显著优于同尺寸模型。 -
Terminal-Bench Pro: 即使在更严苛的 Pro 基准下,ROME 依然保持了相对于开源同类模型的优势。
-
-
Tool-Use Benchmarks (表 3):
-
在 MTU-Bench (Single-Turn) 上得分 62.45%,超过 GPT-OSS-120B。
-
-
General Agentic Benchmarks (表 5):
-
在 ShopAgent (单轮) 上达到 34.53%,甚至优于 GLM-4.6 (33.80%)。
-
消融实验:
实验证明:
-
Chunk 级优化比 Token 级基线收敛更快、更稳定。 -
Sequential Rollback 策略成功解决了极难任务的冷启动问题。 -
IPA 结合并行初始化显著提升了测试时的成功率。
更多细节请阅读原文。
往期文章:


