
-
论文标题:mHC: Manifold-Constrained Hyper-Connections -
论文链接:https://arxiv.org/pdf/2512.24880
TL;DR
这两天被 DeepSeek 的新论文《mHC: Manifold-Constrained Hyper-Connections》刷屏了。不得不说,DeepSeek 确实有“每逢佳节必整活”的传统,照这个节奏,春节或许真能等来 DeepSeek V4 。
回到技术本身,该研究针对近年来兴起的超连接(Hyper-Connections, HC)架构在扩展残差流宽度时引入的训练不稳定性与系统开销问题,提出了一种基于流形约束的解决方案——mHC。
核心观点与贡献:
-
问题识别: 指出无约束的 HC 架构破坏了残差连接的“恒等映射”(Identity Mapping)属性,导致深层网络中的信号发散(爆炸或消失),且宽残差流带来了严重的显存访问(I/O)瓶颈。 -
算法创新: 提出将残差映射矩阵投影到双随机矩阵(Doubly Stochastic Matrices)构成的流形(Birkhoff 多胞形)上。通过 Sinkhorn-Knopp 算法实现这一约束,在数学上保证了信号传播的范数有界性()和凸组合特性,从而恢复了恒等映射的稳定性。 -
系统优化: 针对引入的学习参数和宽流带来的计算与存储压力,设计了基于 TileLang 的算子融合、分块重计算(Block-wise Recomputing)策略以及扩展的 DualPipe 通信重叠机制,将 扩展率下的训练时间开销控制在 6.7%。 -
实验验证: 在 27B 参数规模的模型上,mHC 相比 HC 显著降低了梯度范数波动,消除了 Loss 尖峰,并在多个下游任务中取得了优于 Baseline 和 HC 的性能。
1. 背景
1.1 标准残差连接的局限与优势
标准的 Transformer 层架构遵循经典的残差公式:
其中 是第 层的输入, 是残差函数(如 Attention 或 FFN)。这种形式最核心的优势在于其 恒等映射(Identity Mapping) 属性。当我们将公式递归展开:
信号 可以不经衰减地直接传播到深层 。这一属性是训练超深层网络的关键,它保证了前向传播的信号强度和反向传播的梯度流不会随深度指数级衰减或爆炸。
1.2 Hyper-Connections (HC) 的引入
Hyper-Connections (HC) 试图打破标准残差流宽度(通常等于隐藏层维度 )的限制。HC 将残差流扩展了 倍,即引入了一个隐藏矩阵 (实际上可以看作 个并行的残差流)。
单层 HC 的传播公式如下:
这里引入了三个可学习的线性映射矩阵来处理维度不匹配问题:
-
:负责在 个残差流之间混合信息。 -
:将 的残差流聚合为 维向量输入到层函数 。 -
:将层函数 的输出映射回 的残差流。
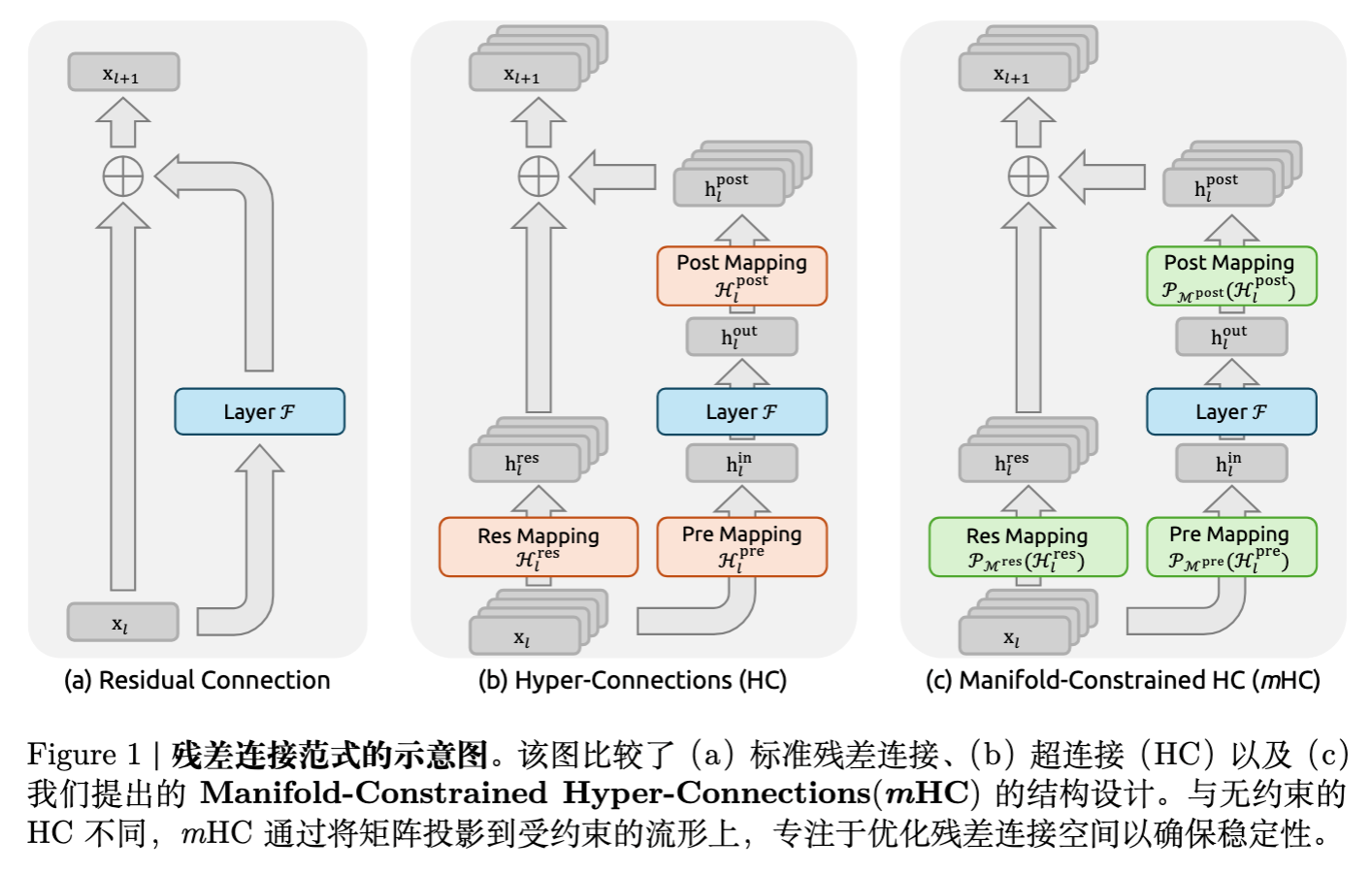
HC 的设计初衷是通过解耦残差流宽度与计算层宽度,在不显著增加 FLOPs 的前提下提升拓扑复杂度。然而,这种设计破坏了“恒等映射”这一核心假设。
2. 问题分析:HC 为何在大规模训练中失效?
论文指出了 HC 在大规模训练场景下面临的两大核心挑战:数值不稳定性和系统开销过大。
2.1 数值不稳定性:恒等映射的丧失
在 HC 架构下,多层传播的公式变为:
注意第一项 。在标准 ResNet 中,这对应于单位矩阵 。但在 HC 中, 是无约束的可学习矩阵。
问题在于: 无约束矩阵的连乘积无法保证特征的全局均值或范数守恒。
-
前向传播: 信号幅度可能随层数指数级放大(Explosion)。 -
反向传播: 梯度可能随层数指数级消失或爆炸。
论文通过 "Amax Gain Magnitude" 指标量化了这种不稳定性。该指标分别计算复合映射矩阵在行方向(对应前向信号)和列方向(对应反向梯度)的最大绝对值和。
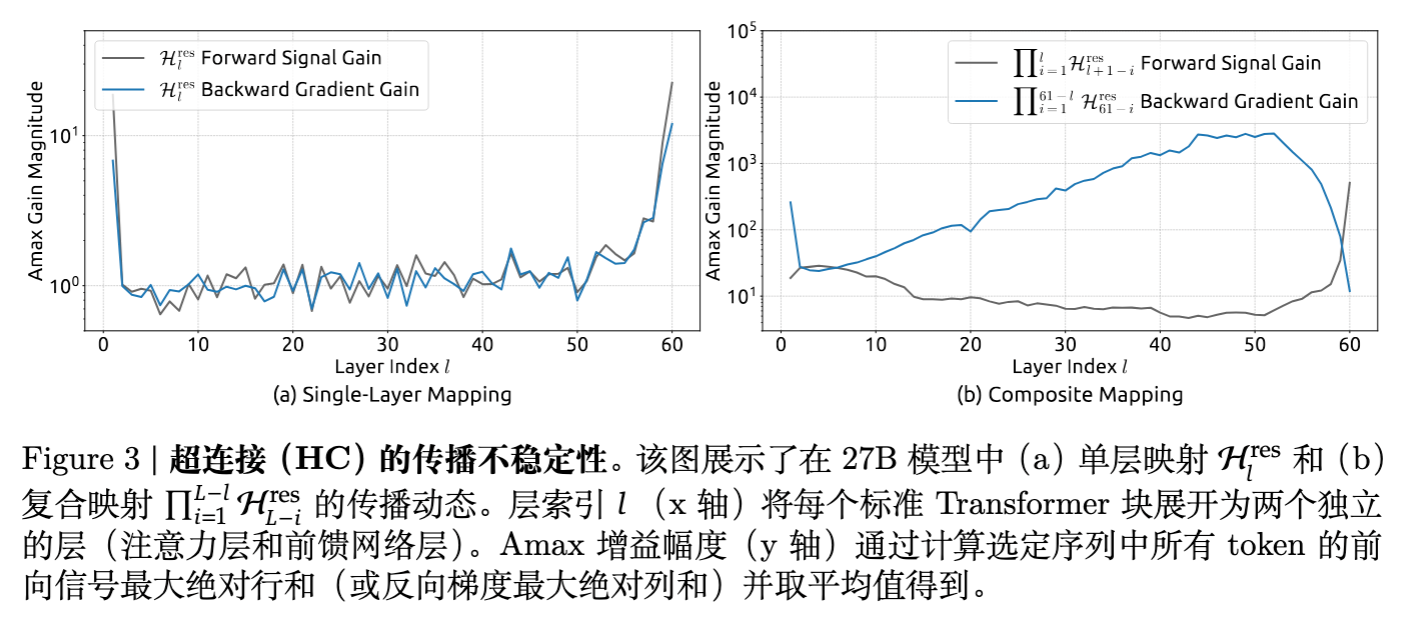
实验数据表明,HC 在训练约 12k 步后出现了 Loss 突增和梯度范数剧烈震荡,这直接印证了上述理论分析。
2.2 系统开销:遭遇“内存墙”
虽然 HC 的 FLOPs 增加有限(线性映射计算量相对于 Attention/FFN 较小),但其引入的 显存访问(Memory Access / IO) 开销是巨大的。
在现代 GPU 架构中,计算能力往往远超显存带宽,这被称为“内存墙(Memory Wall)”问题。HC 将残差流扩大了 倍,导致在每个残差连接处读写的数据量成倍增加。
具体对比见下表:
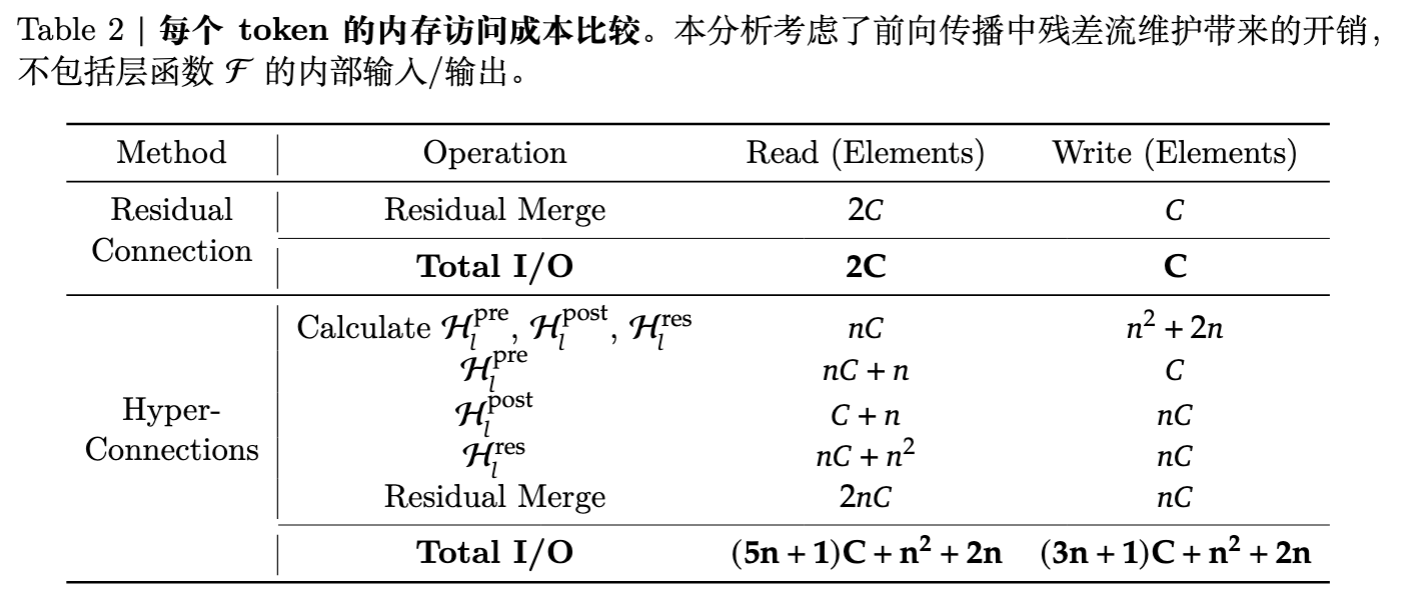
当 时,HC 的 I/O 开销约为标准残差连接的 11 倍以上。如果不进行底层优化,这将导致严重的训练吞吐量下降。此外,保存 倍的中间激活用于反向传播也会导致显存占用激增。
3. Manifold-Constrained Hyper-Connections
为了解决上述问题,作者提出了 mHC。其核心思想是:与其让 自由学习,不如将其约束在一个能保证数值稳定性的特定流形上。
3.1 数学原理:投影到 Birkhoff 多面体
mHC 将残差映射矩阵 约束为 双随机矩阵(Doubly Stochastic Matrix)。
双随机矩阵满足以下条件:
-
非负性:所有元素 。 -
行和为 1:。 -
列和为 1:。
由所有 双随机矩阵构成的集合被称为 Birkhoff 多面体(Birkhoff Polytope),记为 。
为什么选择双随机矩阵?
这种约束赋予了 mHC 三个对大规模训练至关重要的性质:
-
范数保持(Norm Preservation):
双随机矩阵的谱范数(Spectral Norm)以 1 为界,即 。这意味着映射是非扩张的(non-expansive),从根本上消除了梯度爆炸的数学基础。 -
组合封闭性(Compositional Closure):
双随机矩阵的乘积仍然是双随机矩阵。这意味着无论网络堆叠多少层,复合映射 依然保持在 Birkhoff 多面体内,稳定性不会随深度衰减。 -
几何解释:
Birkhoff 多面体是置换矩阵(Permutation Matrices)的凸包。这意味着 实际上是对输入特征进行了一种“凸组合(Convex Combination)”式的混合。这保证了特征的均值守恒,且信号混合过程是良态的。
3.2 参数化与 Sinkhorn-Knopp 算法
在具体实现中,网络并不直接学习双随机矩阵,而是学习其参数化形式,并通过投影算法将其映射到流形上。
动态与静态参数
mHC 沿用了 HC 的动态选通机制,系数由输入依赖部分(Dynamic)和全局部分(Static)组成:
其中 是线性投影矩阵。
流形投影
得到原始系数 后,应用以下约束:
-
对于 和 : 使用 Sigmoid 函数()确保非负性,防止正负系数抵消导致的信号消除。
-
对于 : 使用 Sinkhorn-Knopp 算法。
该算法通过迭代的方式,交替对矩阵的行和列进行归一化,最终收敛到双随机矩阵。迭代过程(从 开始):
其中 和 分别代表行归一化和列归一化。实验中,作者发现迭代 20 次()即可获得足够的精度。
4. 基础设施优化
虽然 mHC 解决了理论上的不稳定性,但引入的 Sinkhorn 迭代和 倍宽度的残差流依然带来了巨大的计算和 I/O 压力。DeepSeek 团队为此设计了一套高效的基础设施方案。
4.1 内核融合 (Kernel Fusion)
为了减少对显存的反复读写,作者利用 TileLang 开发了定制的融合算子(Kernel)。
-
RMSNorm 重排序与融合: 观察到 RMSNorm 在高维状态 上操作延迟较高,作者将其除以范数的操作重新排序到矩阵乘法之后。这允许将 RMSNorm 的权重吸收到后续的线性投影系数中。 -
统一扫描内核(Unified Scan Kernel): 将计算 所需的两次对 的扫描操作融合为一个 Kernel,充分利用矩阵乘法单元(Tensor Cores)并最大化内存带宽利用率。 -
Sinkhorn 融合: 将 Sinkhorn-Knopp 的 20 次迭代完全在一个 Kernel 内完成,中间结果保留在片上缓存(On-chip memory),避免了极其昂贵的全局显存读写。 -
应用内核融合: 将 和 的应用与残差合并操作融合。这一步至关重要,它将读数据量从 降低到了 ,写数据量从 降低到了 。
4.2 选择性重计算 (Selective Recomputing)
由于残差流宽度是 ,在前向传播中保存所有中间激活供反向传播使用会导致显存爆炸。作者采用了一种块级重计算策略。
-
策略: 不保存 mHC 算子的中间输出。在反向传播时,通过重执行前向计算来恢复这些数据。 -
优化: 由于 mHC 算子不包含繁重的层函数(如 Attention/FFN),重计算成本较低。 -
分块管理: 为了平衡重计算带来的计算开销和存储开销,作者将 层网络划分为若干块(Block),每块包含 层。只持久化存储每个块的输入 。
最优块大小 的理论推导公式为:
在实际中,为了配合流水线并行(Pipeline Parallelism),块的边界与流水线阶段(Stage)边界对齐。

4.3 DualPipe 中的通信重叠优化
在大规模训练中,DualPipe 调度策略被用于重叠计算和通信。然而,mHC 引入了跨流水线阶段的 倍通信量(因为传递的是 维的 ),且重计算步骤引入了额外的计算延迟。
作者对 DualPipe 进行了扩展(见图 4):
-
高优先级流(High-Priority Stream): 将 MLP(FFN)层的 内核放在专用高优先级流上执行,以防止阻塞通信流。 -
非持久化 Attention: 避免在 Attention 层使用长期占用的持久化内核,允许在需要时抢占计算资源,从而更灵活地调度重叠操作。 -
解耦重计算: 重计算过程不依赖于流水线通信(因为输入已本地缓存),因此可以更自由地填充到流水线气泡中。
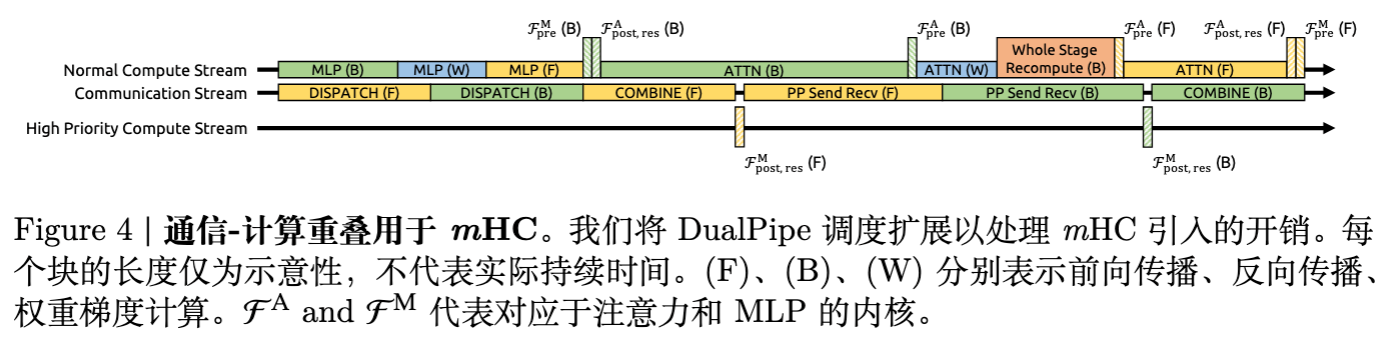
通过这些优化,在 的配置下,mHC 相比 Baseline 仅增加了 6.7% 的训练时间,这在工程上是可以接受的。
5. 实验结果与分析
作者在 3B、9B 和 27B 参数规模的模型上进行了预训练实验,采用 MoE 架构(基于 DeepSeek-V3)。
5.1 训练稳定性
这是 mHC 最核心的改进点。
-
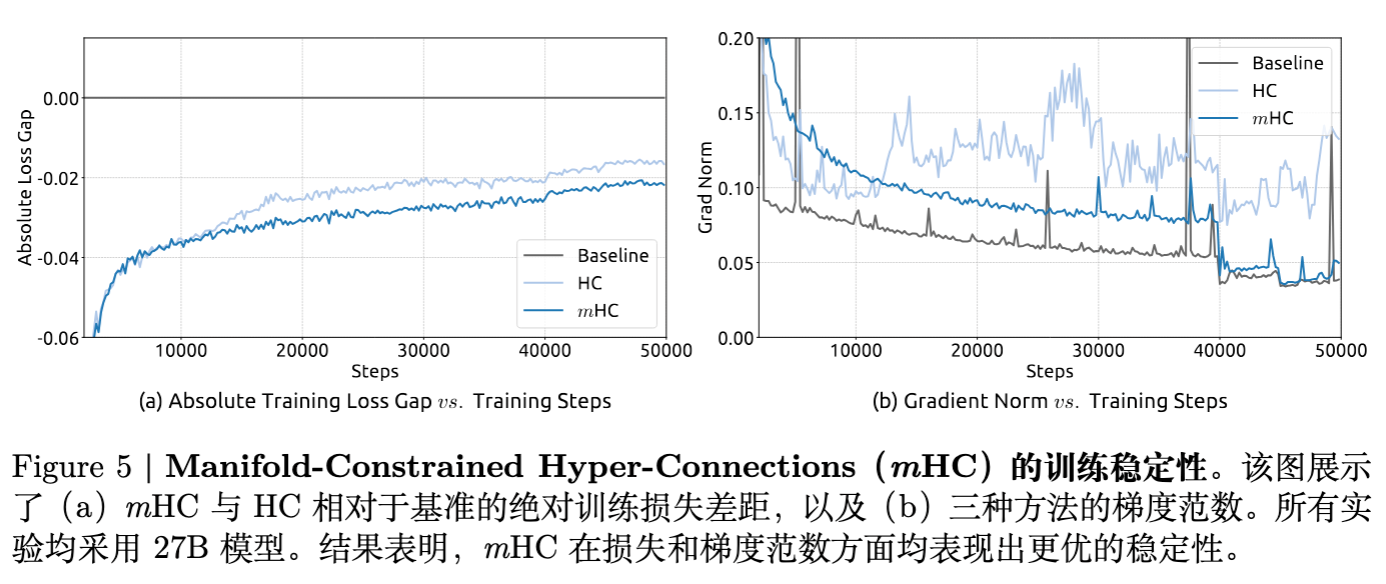
Loss 曲线: 27B 模型的训练曲线显示,HC 在中途出现了明显的 Loss 尖峰,而 mHC 全程保持平滑,且最终 Loss 比 Baseline 低 0.021,比 HC 更优。 -
梯度范数(Gradient Norm): HC 的梯度范数在训练中期出现剧烈震荡,而 mHC 的梯度范数曲线与标准残差连接(Baseline)几乎一致,证明了流形约束的有效性。
5.2 下游任务性能
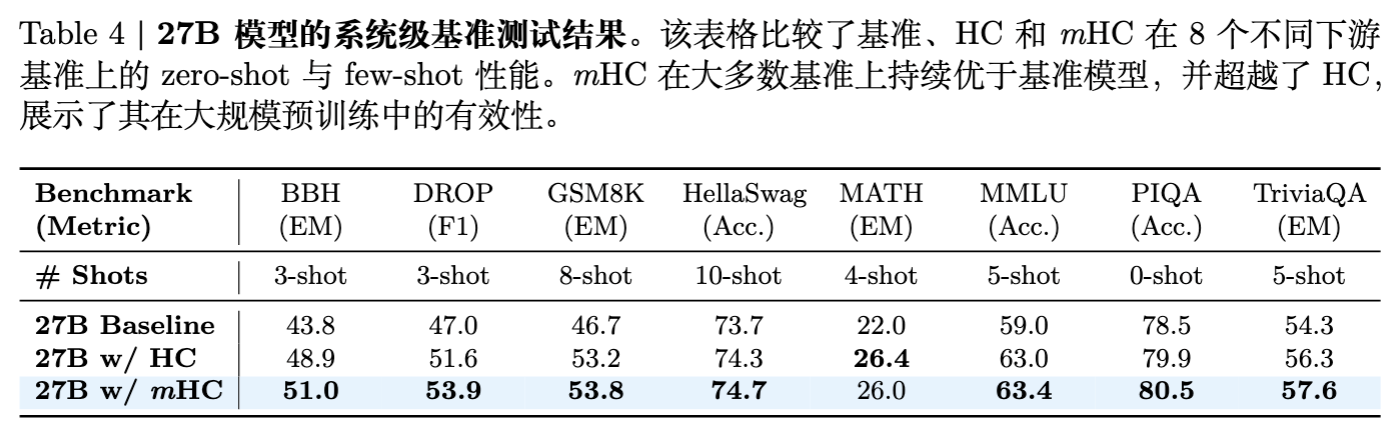
在 BBH、DROP、GSM8K、MATH 等 8 个基准测试中,mHC 相比 Baseline 取得了全面的提升,并且在绝大多数任务上超过了未加约束的 HC。
例如:
-
BBH (3-shot): Baseline 43.8 -> mHC 51.0 -
DROP (3-shot): Baseline 47.0 -> mHC 53.9 -
MATH (4-shot): Baseline 22.0 -> mHC 26.0
这说明 mHC 并不是通过牺牲性能来换取稳定性,而是通过更好的优化性质提升了最终效果。
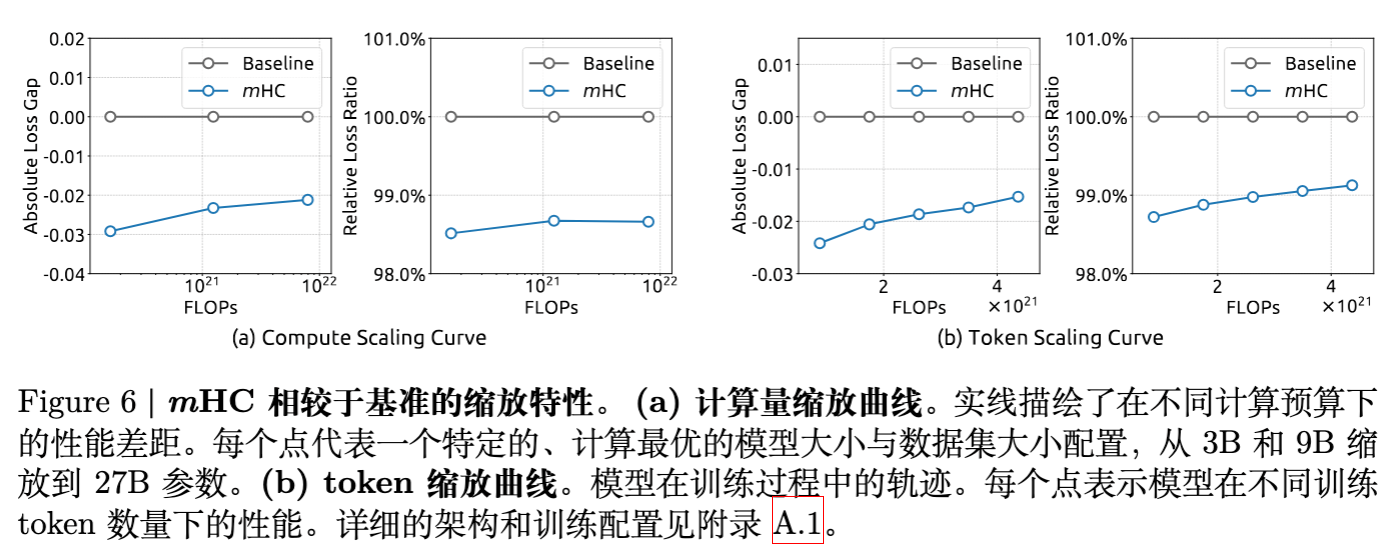
5.3 扩展性 (Scaling)
-
Compute Scaling: 从 3B 到 27B,mHC 始终保持相对于 Baseline 的 Loss 优势。虽然优势幅度随规模略有收窄,但依然稳健。 -
Token Scaling: 在 1T Token 的训练过程中,mHC 持续保持领先。
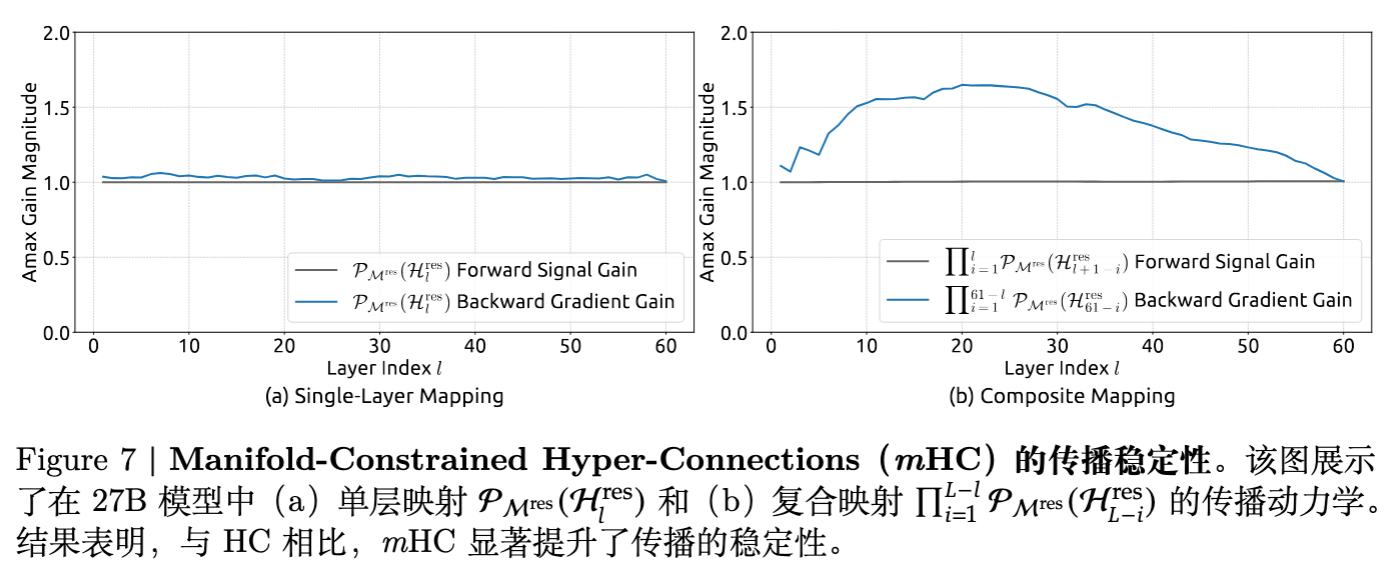
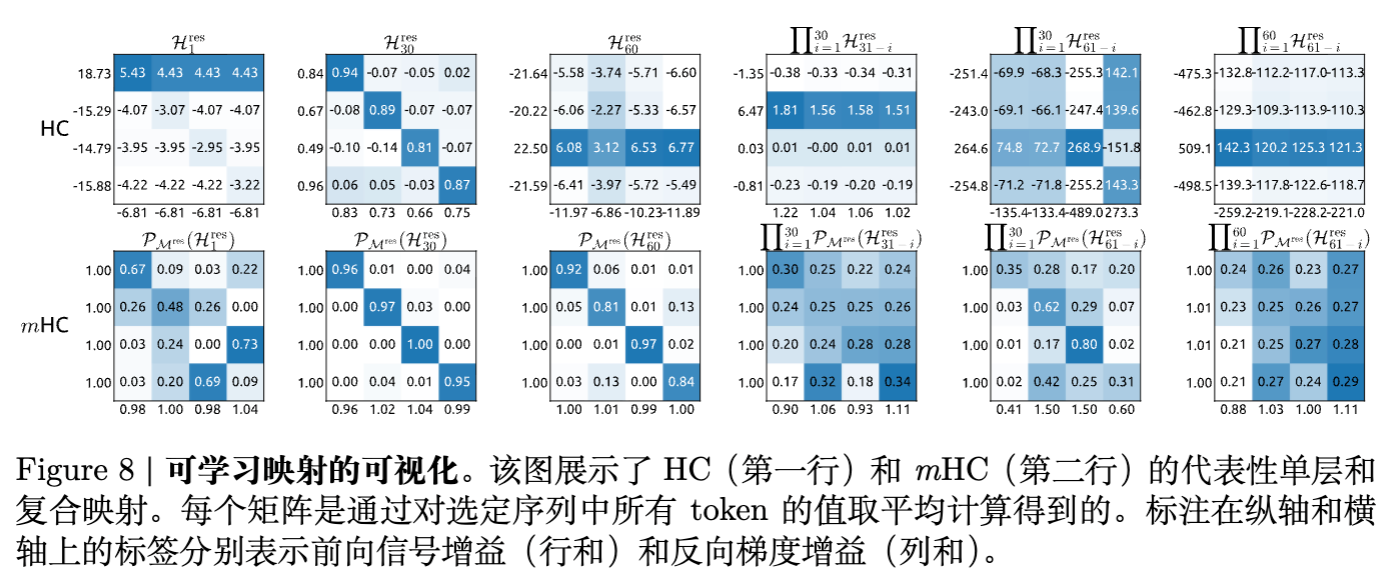
5.4 传播特性可视化
为了验证理论假设,论文可视化了 矩阵:
-
单层视角: 理想的双随机矩阵行列和应为 1。由于 Sinkhorn 迭代次数有限(20次),实际反向梯度增益略有偏差(约 1.0~1.6),但这远好于 HC 的 3000 倍增益。 -
矩阵热力图: HC 的矩阵呈现出 chaotic 的数值分布,且数值巨大。而 mHC 的矩阵数值分布均匀且受控,呈现出良好的混合特性。
6. 总结与展望
DeepSeek-AI 的这项工作为大模型的宏观架构设计提供了一个极具价值的案例:如何通过严格的数学约束将“不羁”的复杂拓扑结构驯化为可扩展的架构。
mHC 的贡献在于:
-
明确指出了 HC 失效的根源是恒等映射属性的破坏和 I/O 瓶颈。 -
利用 Birkhoff 多面体投影(双随机矩阵)从理论上重构了信号传播的稳定性。 -
通过内核融合和通信重叠,将理论复杂度极高的 Sinkhorn 投影和宽残差流在实际算力集群上高效跑通。
这项技术不仅是对 HC 的修复,也为未来探索更复杂的神经网络拓扑结构(如各种 Differentiable Neural Computer 或复杂路由网络)指明了方向:几何约束(Geometric Constraints)可能是平衡模型可塑性(Plasticity)与稳定性(Stability)的关键。
更多细节请阅读原文。
往期文章:


