
-
论文标题:Less is Enough: Synthesizing Diverse Data in Feature Space of LLMs -
论文链接:https://arxiv.org/pdf/2602.10388
TL;DR
今天解读一篇来自佐治亚大学的论文《Less is Enough: Synthesizing Diverse Data in Feature Space of LLMs》。该研究针对大语言模型(LLM)后训练(Post-training)阶段的数据合成问题,提出了一种基于稀疏自编码器(Sparse Autoencoder, SAE)特征空间的全新数据合成框架——FAC Synthesis。
传统的合成数据多样性指标(如 n-gram、语义嵌入余弦距离)往往基于文本表面统计或通用语义空间,难以捕捉对下游任务性能至关重要的潜在特征。本文核心贡献在于:
-
理论推导:证明了合成数据的泛化误差上界由“分布差距(Distribution Gap)”和“采样误差(Sampling Error)”两部分组成,并推导出在特征空间覆盖任务相关特征可以有效降低泛化误差。 -
新指标 FAC:提出了特征激活覆盖率(Feature Activation Coverage, FAC),用于在可解释的特征空间中量化数据多样性。 -
合成框架:设计了一种覆盖率引导的合成方法,通过SAE识别“缺失特征”,并利用对比样本对(Contrastive Pairs)引导模型生成包含特定特征的数据。 -
实验验证:在指令跟随、毒性检测、奖励建模和行为引导等四个任务上,仅使用极少量的合成数据(例如在 AlpacaEval 2.0 上仅用 2K 数据),即可达到或超越使用大量数据(如 MAGPIE 的 300K 数据)的基线模型效果。
1. 引言
在大语言模型的后训练阶段(包括监督微调 SFT 和强化学习 RL),数据的质量与多样性是决定模型性能的关键因素。随着互联网高质量自然数据的枯竭,利用 LLM 自行合成数据(Synthetic Data)已成为主流范式。然而,当前面临的一个核心挑战是:如何以原则性且高效的方式构建多样化的后训练数据集?
现有的方法通常依赖基于文本的指标来量化多样性,例如 Distinct-n、n-gram 熵或基于嵌入模型的余弦距离。然而,这些指标主要捕捉语言学层面的变化(词汇、句法)或通用的语义距离,往往只能为决定下游任务性能的关键特征提供微弱的信号。换言之,文本层面的“多样”并不等同于任务层面的“有效”。
本文提出了一种基于模型内部状态的视角。作者认为,有效的数据合成应当关注模型内部特征空间中的覆盖率。通过训练稀疏自编码器(SAE),作者将模型的激活状态分解为可解释的潜在特征,并以此为基础设计了 FAC Synthesis 框架。
2. 稀疏自编码器 (SAE)
在深入方法论之前,我们需要简要回顾稀疏自编码器在构建特征空间中的作用。SAE 旨在将 LLM 的内部激活分解为可解释的特征。
通常,SAE 由一个编码器和一个解码器组成,且权重绑定。给定输入嵌入 ,编码器产生一个稀疏的特征激活向量 :
解码器则重构输入:
其中 是 ReLU 激活函数,,且通常 (过完备基)。SAE 的训练目标是最小化重构误差和稀疏惩罚:
通过 SAE,我们可以获得一个 维的特征空间,其中每个特征捕捉了可能与任务相关的独特潜在模式。
3. 量化合成数据的泛化性
本文的一个重要贡献是建立了合成数据与泛化误差之间的理论联系。这也是理解为什么要在“特征空间”而非“文本空间”进行优化的关键。
3.1 泛化误差上界
设 为独立同分布(i.i.d.)的合成数据集, 为其分布, 为目标任务域的真实分布。后训练模型 在损失函数 (有界,上界为 )下进行优化。
作者推导出泛化误差的上界(Theorem 4.1):
该公式揭示了两个核心优化项:
-
分布差距 (Distribution Gap) :,衡量真实任务分布与合成数据分布之间的总变差距离。这部分主要受合成管线(如 Prompt 设计、数据筛选)的影响。 -
采样误差 (Sampling Error) :衡量在有限合成数据集 上的经验风险与合成分布 下期望风险的偏差。
3.2 在特征空间减少分布差距
现有的合成方法多在文本空间操作,但文本空间的语言学变化(如措辞差异)往往与任务无关,且难以优化。作者提出在 SAE 特征空间中减少分布差距。
设 ,其特征激活为 。同理定义 和 。利用 Pinsker 不等式和 KL 散度的链式法则,分布差距可以被上界约束为:
这表明,优化目标可以转化为:
-
最小化特征空间边缘分布的 KL 散度 。 -
控制条件项 (非优化项,但可通过 Prompt 工程缓解)。
因此,理想的合成数据集 应满足:
3.3 减少采样误差
对于采样误差项,作者基于 PAC-Bayesian 理论给出了上界(Lemma 6.1)。在满足次伽马(Sub-Gamma)损失假设下:
利用信息不等式 ,可知:降低合成数据集的熵(即不确定性) 有助于减少采样误差。
这也解释了为什么简单的 Prompting 效果不佳:简单 Prompt 产生的数据具有高变异性和高不确定性,导致采样误差大。作者提出的方法通过强制激活特定特征,限制了生成空间,从而降低了条件熵 。
4. FAC Synthesis
基于上述理论,本文提出了 FAC Synthesis 框架。该框架旨在通过覆盖“缺失特征”来最小化特征空间的分布差异,并通过两阶段生成策略降低采样误差。
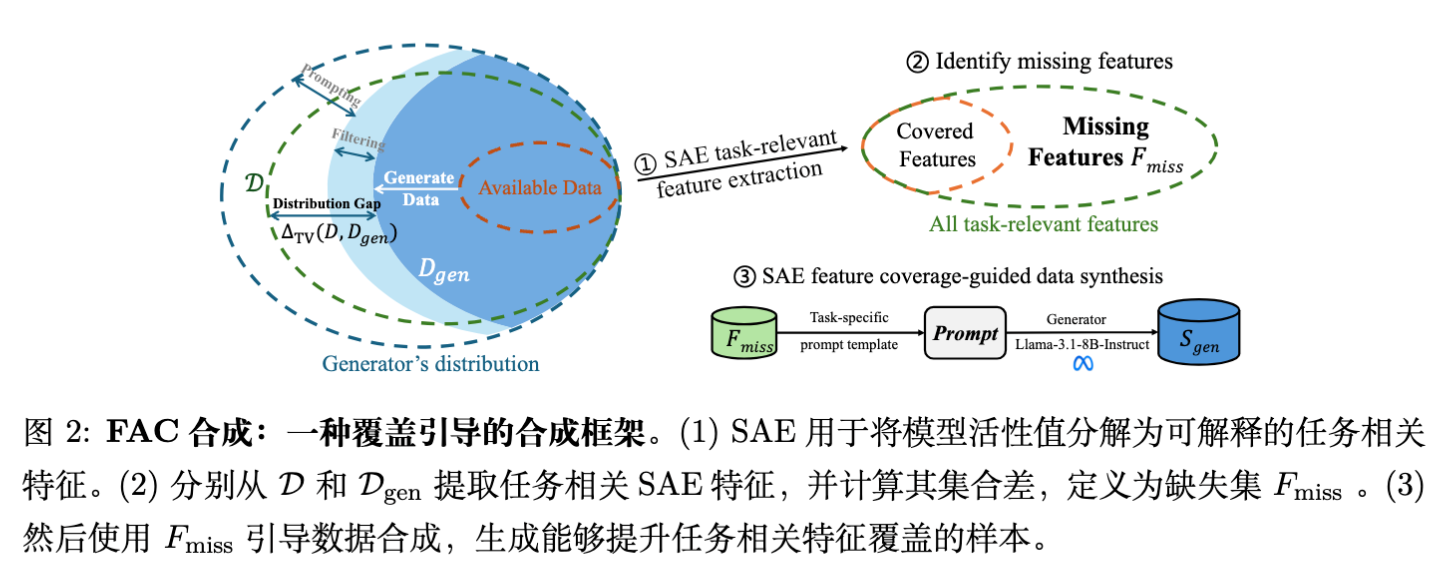
4.1 特征激活覆盖率 (FAC)
为了使得 的优化变得可操作,作者定义了特征激活指示器 ,并基于此定义了 FAC。
设 为任务相关特征的集合(通过 LLM 辅助识别),则 FAC 定义为生成数据所覆盖的任务相关特征的比例:
其中 和 分别是在目标分布(Anchor Set)和生成分布中被激活的特征集合。
缺失特征 (Missing Features) 定义为:
即那些在目标域中出现,但在当前生成数据中未出现的特征。
4.2 两阶段合成策略
为了针对性地生成包含 的数据,并降低生成的不确定性,作者设计了 Two-Step 策略:
步骤 1:构建对比样本对 (Contrastive Pair Construction)
对于每个缺失特征 ,构建一个对比样本对 。
-
:强激活该特征的样本。 -
:弱激活该特征的样本。
具体操作是,使用特征的语义描述 构建 Prompt,生成候选样本,然后利用 SAE 评分筛选出符合条件的正负样本。
步骤 2:特征覆盖样本合成 (Feature-Covered Sample Synthesis)
利用上述对比样本对作为 Few-shot 示例,引导模型生成新数据。Prompt 模板 包含了 和特征描述。
生成的候选样本会再次通过 SAE 过滤,仅保留那些成功激活目标特征 的样本。最终聚合所有缺失特征的生成样本得到 。
这种方法的优势在于:
-
针对性强:直接填补特征空间的分布空缺。 -
低不确定性:通过对比示例和特征描述限制了生成空间,降低了 ,从而降低采样误差。
5. 实验设置
作者在四个任务、三个模型家族上进行了广泛实验。
5.1 任务与数据集
-
毒性检测 (Toxicity Detection) :微调模型识别有害内容。数据集:ToxicChat(测试),HH-RLHF(训练锚点)。 -
奖励建模 (Reward Modeling) :训练 RM 模型判断回答的有用性。数据集:RewardBench(测试),HH-RLHF(训练锚点)。 -
行为引导 (Behavior Steering) :控制模型输出特定的行为(如阿谀奉承 Sycophancy、生存本能 Survival Instinct)。 -
指令跟随 (Instruction Following) :通用对话能力。数据集:AlpacaEval 2.0(测试)。
5.2 模型
-
Backbone: LLaMA-3.1-8B-Instruct (主要), Mistral-7B-Instruct, Qwen2-7B-Instruct (用于跨模型泛化研究)。 -
SAE: 在 113M token 数据上训练的 Top-K SAE ()。
5.3 基线方法
对比了多种数据合成方法,包括:
-
Alpaca / Evol-Instruct / Magpie / CoT-Self-Instruct:指令扩展或自我进化范式。 -
SAO / Prismatic Synthesis / SynAlign:目标导向或梯度导向的合成方法。
6. 实验结果与分析
6.1 性能提升显著 (RQ1)
实验结果表明,FAC Synthesis 在所有任务上均优于或持平于基线方法,且数据效率极高。
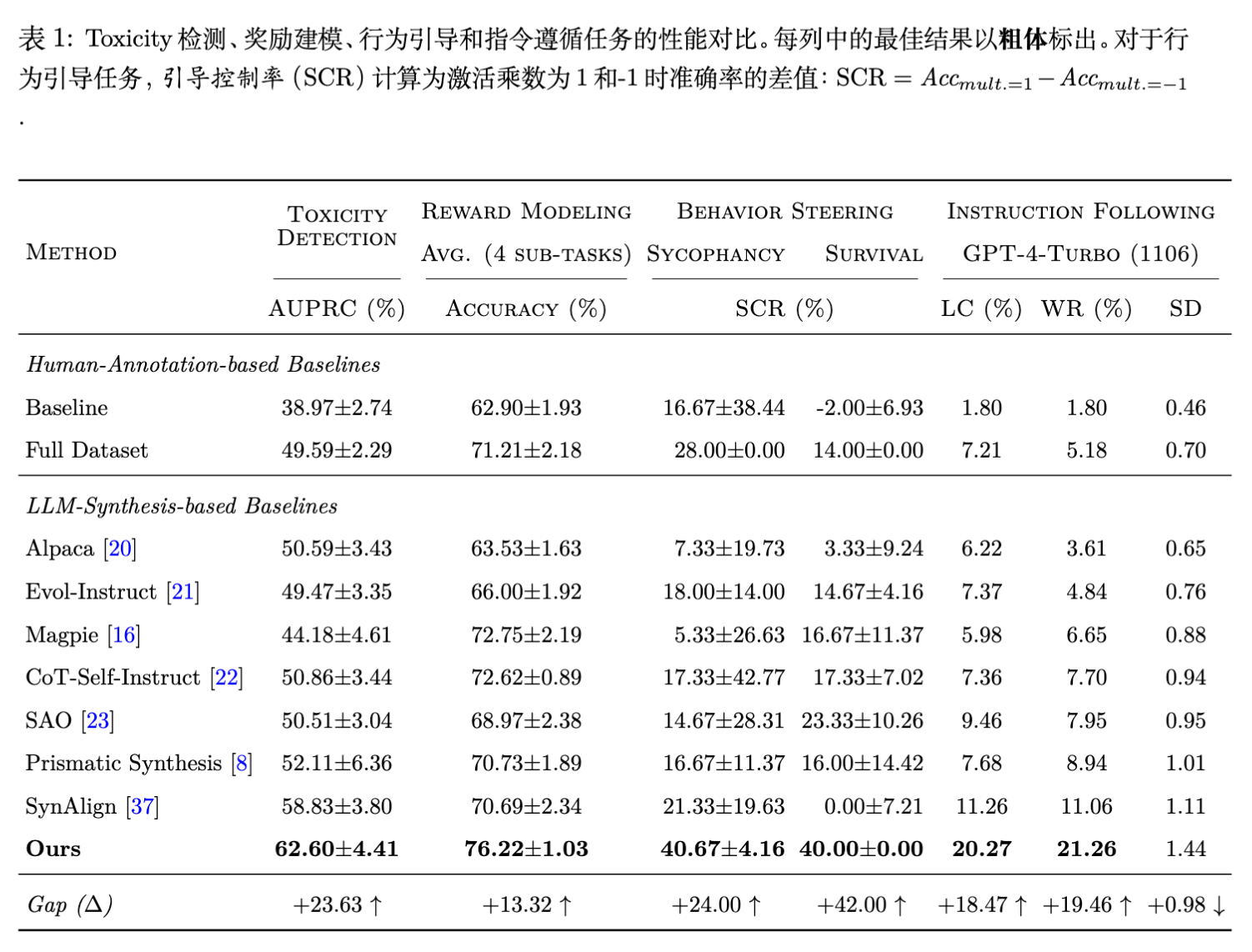
-
数据效率:在指令跟随任务中,FAC Synthesis 仅使用 2,000 条合成数据,就在 AlpacaEval 2.0 上达到了与 MAGPIE (300,000 条数据) 相当的胜率。 -
任务一致性:与某些在特定任务表现好但在其他任务不稳定的基线(如 Self-Instruct)不同,FAC Synthesis 在四个任务上均表现稳健。
6.2 FAC 与下游性能强相关 (RQ2)
作者分析了 FAC 指标与模型下游性能的相关性。
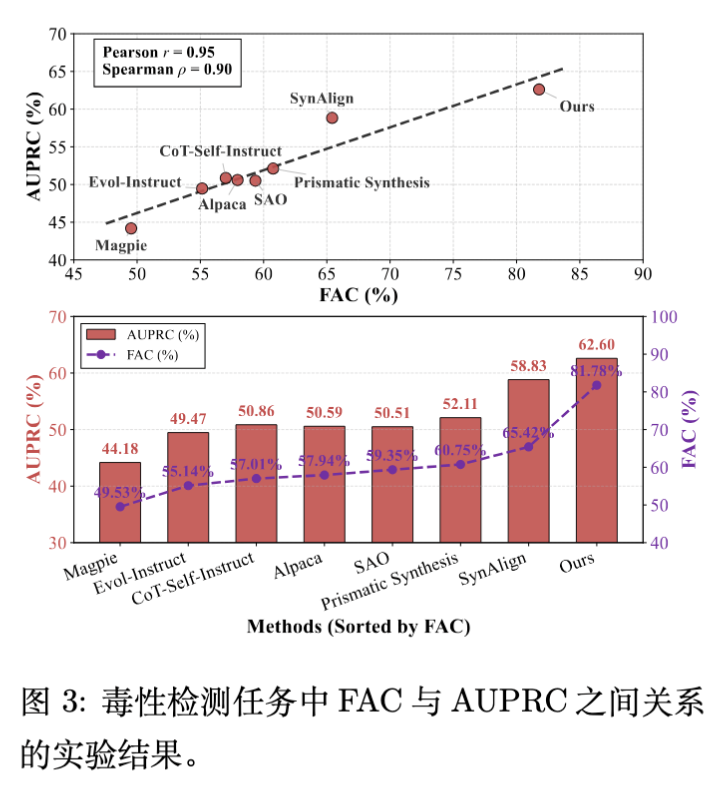
-
强相关性:Pearson 相关系数 ,Spearman 。这表明 FAC 是预测下游性能的可靠指标。 -
对比传统指标:在附录中,作者展示了传统的词汇级(Distinct-n)、句法级和嵌入级多样性指标与模型性能的相关性很弱,甚至呈负相关。这有力地支持了“特征空间的多样性才是关键”这一论点。
6.3 跨模型泛化能力 (RQ3)
这是一个非常有趣的发现。作者探究了 SAE 识别的缺失特征是否在不同模型家族间可迁移。
-
共享特征空间:从 LLaMA-3.1-8B 提取的特征用于指导 Qwen2-7B 和 Mistral-7B 的微调,均取得了显著提升。这暗示了不同 LLM 之间存在共享的、可解释的特征空间。 -
弱至强泛化 (Weak-to-Strong Generalization) :利用较弱模型(LLaMA-3.1-8B)的特征去指导较强模型(Qwen2-7B),依然能带来性能提升。甚至在某些情况下,使用 LLaMA 的特征比使用 Qwen 自身的特征效果更好(可能归因于 LLaMA 的特征空间更适合生成任务或 SAE 训练质量差异)。
6.4 可解释性 (RQ4)
通过 GPT-4o-mini 对 SAE 特征进行解释,作者验证了方法的合理性。
-
语义一致性:激活特定特征的文本片段在语义上高度一致(例如都与“盗窃”、“作弊”相关)。 -
合成质量:针对缺失特征生成的合成数据能够准确地“击中”目标语义,且被人类评估者和 LLM 判定为任务相关。
6.5 超参数敏感性 (RQ5)
-
生成温度:适中的温度(Temperature)效果最好。过低导致探索不足,过高导致偏离目标特征。 -
特征阈值 :较高的阈值会筛选出更显著的特征,虽然特征数量减少,但生成的样本质量更高,往往能带来更好的性能。
7. 深度讨论
7.1 "Less is Enough" 的本质
论文标题中的 "Less is Enough" 并非空穴来风。传统观念认为数据越多越好,但在后训练阶段,数据的边际效应递减极快。FAC Synthesis 证明了,只要数据精确覆盖了模型当前缺失的能力边界(Feature Boundary),极少量的数据(2K级别)就能撬动巨大的性能提升。这实际上是一种以数据为中心的课程学习(Data-centric Curriculum Learning)。
7.2 特征空间的分布对齐
理论推导部分关于 KL 散度的讨论非常精彩。它从数学上解释了为什么 text-space diversity metrics 经常失效:
传统方法试图在 text space 增加多样性,往往是在增加 (条件项的噪音),或者是盲目地扩展 的支撑集(Support),而不一定覆盖了 (目标域)的核心区域。FAC 方法则是显式地最小化 ,确保每一条合成数据都在填补 中的真空地带。
7.3 SAE 在数据工程中的潜力
此前 SAE 多用于解释性研究(Interpretability),而本文将其转化为一种控制信号。这种思路可以扩展到更多领域:
-
去偏(Debiasing):识别偏见特征,合成反事实数据。 -
知识注入:识别特定领域的缺失知识特征。 -
模型诊断:通过对比 Teacher 和 Student 模型的特征覆盖率,实现更精细的蒸馏。
7.4 局限性
尽管效果显著,该方法也存在局限(这也是作者在文中提及的):
-
计算开销:训练 SAE 本身需要计算资源,且对每条生成数据进行 SAE 前向传播(推理)也有额外开销。 -
特征捕捉能力:当前的 SAE 主要捕捉浅层或中层语义,对于复杂的推理逻辑(可能分布在多层或跨层电路中)可能捕捉不足。 -
SAE 质量依赖:方法的有效性强依赖于 SAE 的解缠(Disentanglement)质量。
更多细节请阅读原文。
往期文章:


