一个长期以来的问题:大型语言模型究竟能否通过强化学习(RL)获得真正意义上的新推理策略,还是说 RL 仅仅是对其在预训练或后训练阶段已存在能力的放大?
一些研究认为,RL 的能力上限被其基础模型(base model)的表征能力所束缚。RL 能够优化和提炼模型已有的启发式策略,使其在小样本场景下(例如 pass@k 中 k 较小时)表现更佳,但当给予基础模型足够多的尝试机会时(k 很大时),其性能表现会追平甚至超过 RL 训练后的模型。这种观点暗示,RL 无法让模型“学会”其参数空间中原本不支持的全新能力。
另一些研究则展示了 RL 在解锁模型涌现(emergent)解题能力方面的潜力,尤其是在一些复杂的推理任务上。然而,这些研究的证据通常来自大规模、异构的训练语料库。这使得我们难以精确分离出:RL 究竟是如何以及为何能发现新策略的?是数据本身的多样性带来的提升,还是 RL 方法论的根本优势?
我们缺乏一个足够干净、受控的实验环境来系统性地回答两个核心问题:
-
可学习性(Learnability): 对于一个基础模型完全无法解决的问题集(即 pass@K=0,即使在大量采样后成功率为零),RL 能否通过训练使其获得解决该问题的能力? -
可迁移性(Transferability): 如果模型确实学到了新能力,这种能力是仅仅记住了训练分布中的模式,还是能够系统性地迁移到分布外(Out-of-Distribution, OOD)的测试集上?
来自UC Berkeley、UW、AI2 等机构联合团队的论文《RL Grokking Recipe: How Does RL Unlock and Transfer New Algorithms in LLMs?》引入了一个精心设计的基准测试集 DELTA,并提出了 “RL Grokking Recipe” 训练策略,明确展示了 RL 不仅能够放大已有能力,更能够解锁基础模型完全不具备的全新能力。其核心发现是一种引人注目的 “Grokking” 现象:模型在经历了长时间的低奖励探索期后,会突然顿悟,性能跃升。

-
论文标题:RL Grokking Recipe: How Does RL Unlock and Transfer New Algorithms in LLMs? -
论文链接:https://arxiv.org/pdf/2509.21016 -
代码库:https://github.com/sunblaze-ucb/rl-grok-recipe
1. DELTA
要验证 LLM 是否能“学会”新知识,而不是“回忆”起预训练时见过的东西,一个核心前提是评估环境的“纯净度”。当前主流的编程或数学基准,如 Numina-Math、DeepMath 等,虽然推动了领域发展,但也存在一些固有问题:
-
主题混杂: 这些基准通常混合了多种不同类型和难度的问题,使得模型性能的提升难以归因于特定能力的获取。 -
数据污染风险: 鉴于 LLM 的预训练数据规模庞大,这些公开基准中的问题很可能已经以某种形式出现在训练集中,这使得我们无法确信模型是在进行推理,还是在进行模式匹配。 -
难以区分“放大”与“学习”: 在这些基准上,强大的基础模型通常已经具备了一定的基础成功率。RL 的介入究竟是在此基础上进行优化,还是教会了模型全新的解题范式,界限是模糊的。
为了克服这些限制,研究者设计了 DELTA (Distributional Evaluation of Learnability and Transferrability in Algorithmic Coding)。DELTA 是一个围绕可学习性与可迁移性这两个核心概念构建的、程序化的、受控的合成代码问题基准。
相较于之前的 OMEGA 数学基准,DELTA 转向了编程领域,这带来了几个独特的优势:
-
新颖的、完全 OOD 的问题集(Manufactoria): DELTA 的核心创新之一是引入了
Manufactoria。这是一个基于 2010 年的经典 Flash 游戏的编程任务,研究者为其设计了一套全新的、程序化的领域特定语言(DSL)。这个任务之所以是真正的 OOD,原因有三:-
语法新颖: 其 DSL 语法是全新设计的,在任何 LLM 的预训练语料库中都不可能存在。 -
问题原创: 游戏中的谜题由研究者全新合成,而非复用旧有关卡,确保了问题的未见性。 -
推理模式独特: Manufactoria的解题逻辑类似于构建有限状态自动机,其推理模式与传统的编程或图灵机任务有本质区别,需要模型发现独特的解题策略。
-
-
丰富的奖励信号(Rich Reward Signal): 这是选择编程任务的关键优势。与数学题通常只有一个最终答案(对或错)不同,一个程序可以通过一组单元测试用例来评估。这自然地提供了一个密集的、细粒度的奖励信号——“per-test pass rate”(单个测试用例的通过率)。例如,一个程序通过了 10 个测试用例中的 7 个,就可以获得 0.7 的奖励。这种非二元的奖励信号对于引导模型在解空间中进行有效探索至关重要,我们将在后续章节详细探讨其作用。
-
难以通过工具“作弊”: 许多合成数学任务可以通过调用 Python 解释器等外部工具来“捷径”解决。而在 DELTA 中,任务目标是合成程序本身,模型必须生成正确的代码逻辑,而无法将计算委托给外部工具。
DELTA 基准由五个主要领域的问题家族构成,如下图所示。
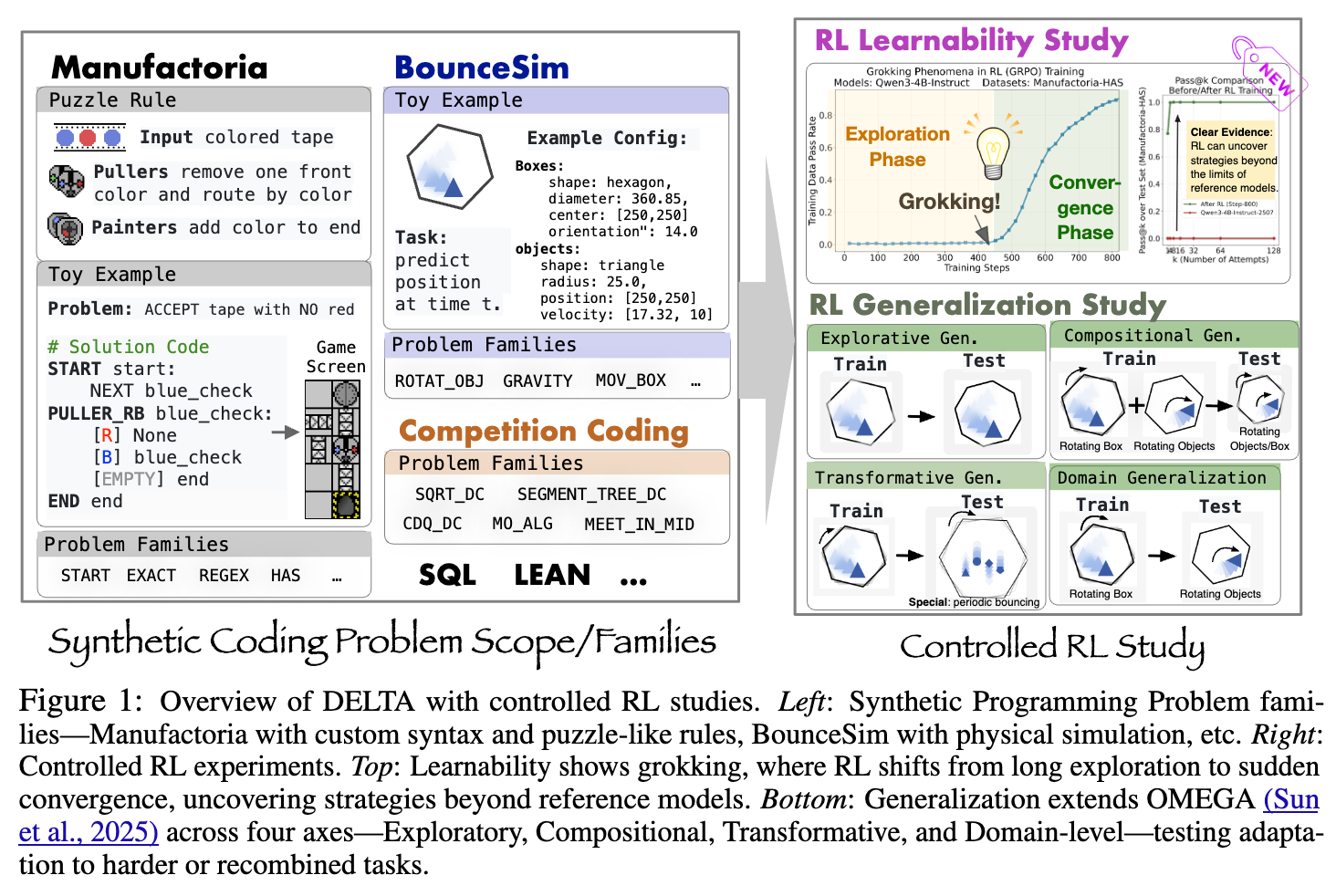
DELTA 内部包含多个精心设计的问题域,分别用于测试不同的能力维度。
-
Manufactoria(用于可学习性研究):
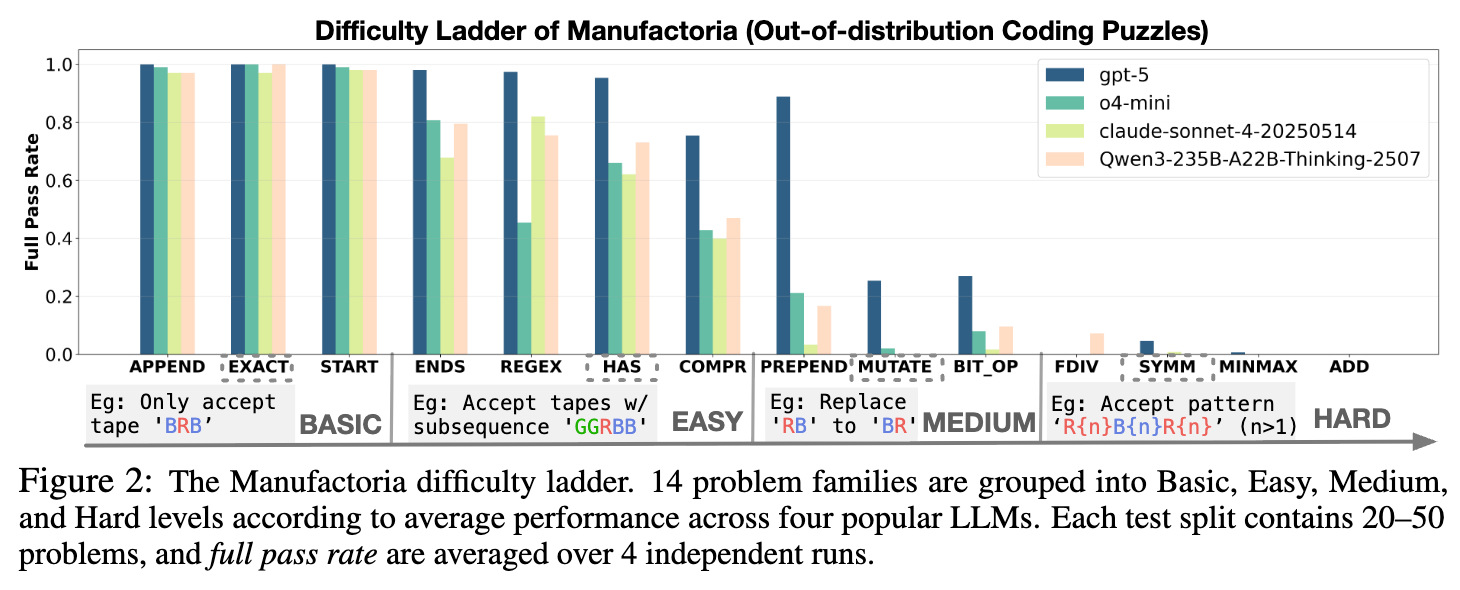
Manufactoria内部构建了一个难度阶梯(Difficulty Ladder),包含 14 个问题家族,从BASIC、EASY到MEDIUM和HARD。研究者首先用当前最强的闭源模型(如论文中的gpt-5占位符)对这个阶梯进行了评估。
如上图 2 所示,即使是gpt-5级别的模型,在MEDIUM难度以上的问题上也开始表现挣扎,而在HARD难度的问题上则完全失败。这清晰地界定出了当前 LLM 的能力边界,为研究pass@K=0任务提供了理想的实验对象。 -
BouncingSim(用于泛化性研究):
这是一个 2D 物理模拟编程任务,要求模型编写程序来预测一个多边形物体在多边形容器中经过弹性碰撞后的精确位置。这个任务被设计用来系统性地评估模型学习到的物理和几何推理能力的泛化性。研究者依据 Boden 的创造力理论,设计了三个正交的泛化轴:-
探索式泛化(Exploratory): 能力不变,但参数和复杂度增加(例如,容器的多边形边数更多,物体运动速度更快)。 -
组合式泛化(Compositional): 将独立训练的多种能力进行组合(例如,分别训练模型处理旋转的物体和旋转的容器,测试模型能否处理两者同时旋转的场景)。 -
转换式泛化(Transformative): 引入与训练数据在动力学上完全不同的新场景(例如,需要发现新的物理不变量才能解决的周期性运动)。
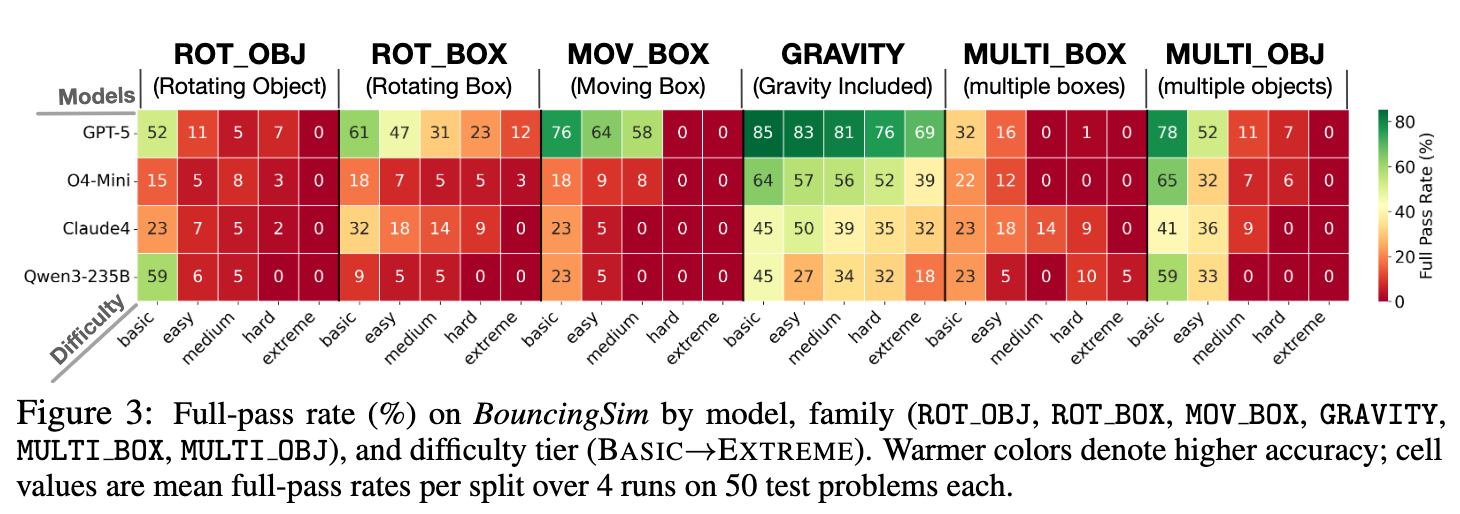
下图展示了不同模型在
BouncingSim六个不同能力家族和五个难度等级上的性能。结果显示,随着难度和组合复杂性的增加,所有模型的性能都显著下降,这为测试 RL 训练后的模型泛化能力提供了充足的挑战。 -
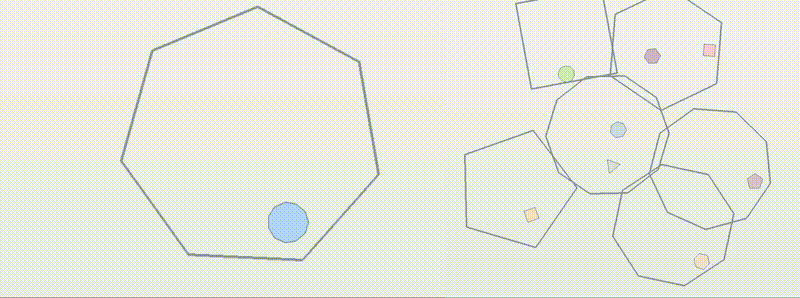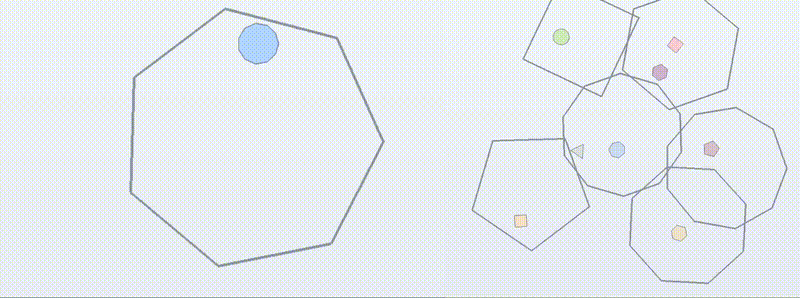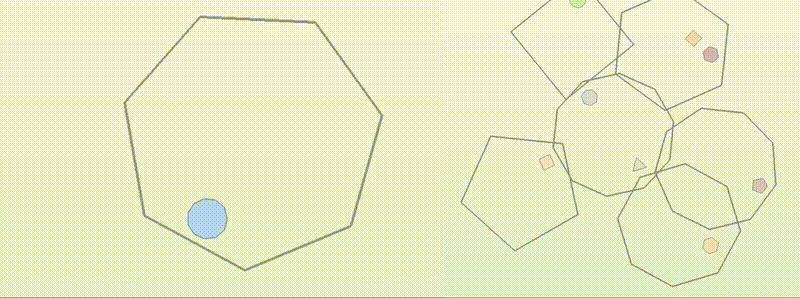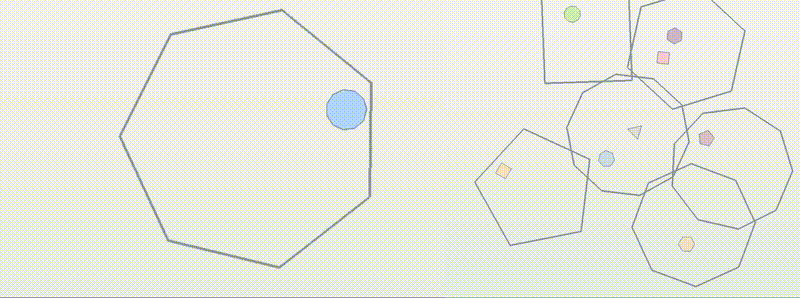
-
其他领域:
DELTA 还包含了竞赛编程、SQL 和 LEAN(一个形式化定理证明器)等领域,以扩展基准的广度和真实性,尽管论文的核心实验聚焦于Manufactoria和BouncingSim。
2. RL 可学习性研究
本研究的核心问题是:当一个强大的基础模型在某个任务上表现为 pass@K=0 时,RL 能否使其“从无到有”地学会解题?
研究者以 Manufactoria 的 HAS 家族(一个 MEDIUM 难度的任务)作为主要实验对象,所选用的基础模型 Qwen3-4B-Instruct-2507 在此任务上的 pass@128 成功率为 0%。这意味着,即使让模型尝试 128 次,也从未生成过一个能通过所有测试用例的正确程序。
2.1 pass@K=0 任务
标准 RL 算法(如 PPO 或论文中使用的 GRPO)依赖于对不同轨迹(rollouts)奖励的比较来计算策略梯度。在一个 pass@K=0 的任务中,由于所有尝试都失败,它们获得的奖励(基于“完整通过/full pass”的二元奖励)全都是 0。一个全为 0 的奖励序列无法提供任何有效的梯度信号,导致学习过程完全停滞。这正是怀疑论观点的理论基础:没有初始的成功信号,RL 就无法启动学习。
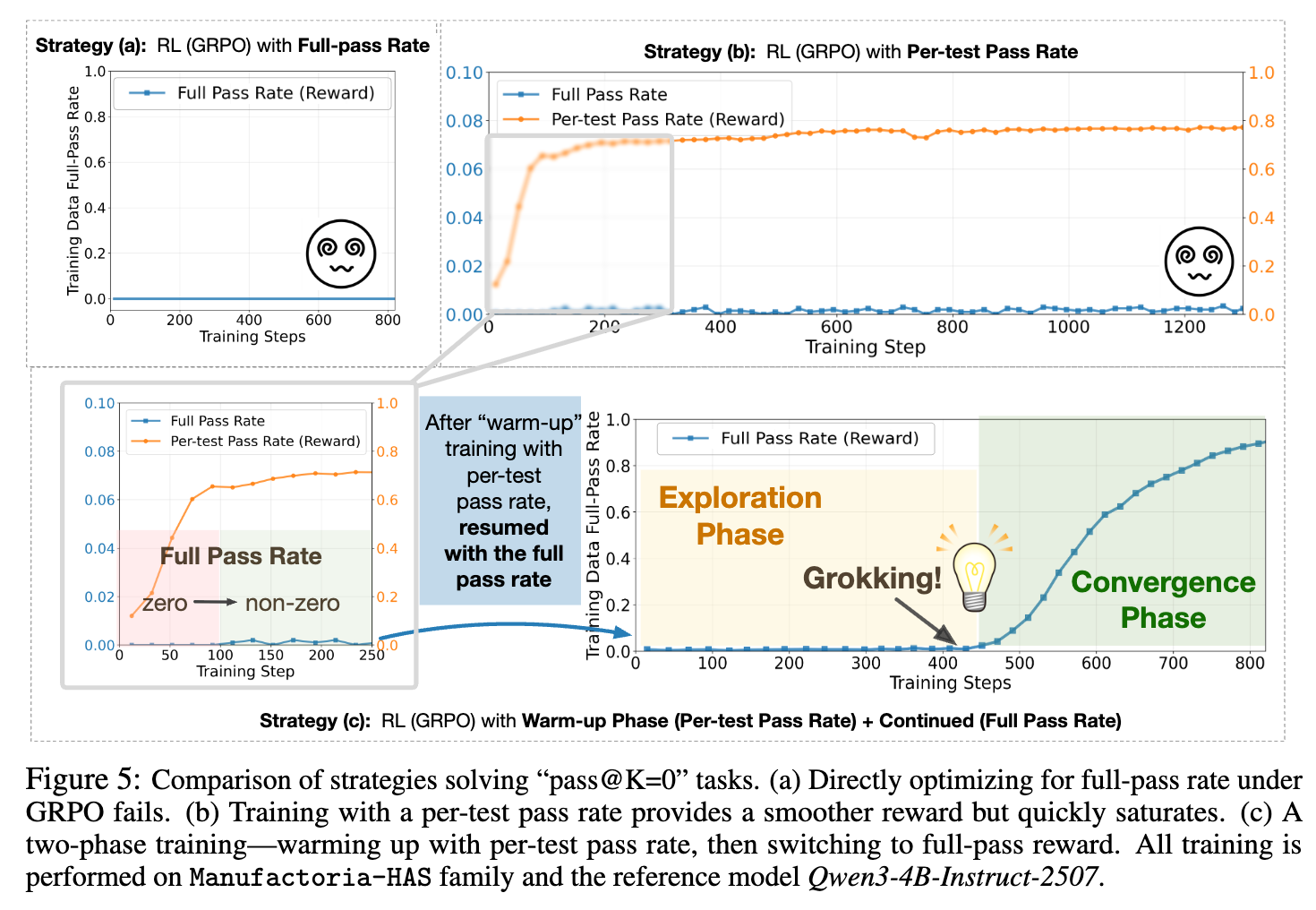
如上图 5a 所示,当直接使用二元奖励信号进行训练时,模型的训练数据完整通过率始终停留在 0,学习完全没有发生。
2.2 RL Grokking Recipe
为了解决“零奖励信号”,研究者提出了一个两阶段训练策略,即 “RL Grokking Recipe”:
第一阶段:Warm-up(预热)
-
目标: 将模型“推”出零奖励的“死亡区域”。 -
方法: 在训练初期,不使用严苛的二元“完整通过”奖励,而是采用前文提到的、由 DELTA设计提供的密集奖励信号——“per-test pass rate”(单个测试用例通过率)。 -
效果: 这个介于 [0, 1]之间的连续奖励为模型的学习提供了宝贵的“部分信用”(partial credit)。即使生成的程序不完全正确,但只要它能通过一部分测试用例,就能获得正向奖励信号。这使得模型能够学习到一些有用的代码片段或局部逻辑,并逐渐向正确的解法靠近。
然而,如图 5b 所示,单纯使用这个密集奖励信号本身并不足以完全解决问题。模型的学习会在达到一定的测试用例通过率后迅速饱和,但其“完整通过率”仍然接近于零(<0.01%)。这表明,密集奖励虽然能引导模型进入一个“有希望”的解空间区域,但它本身不足以作为最终正确性的完美代理指标。
第二阶段:Exploration & Grokking(探索与涌现)
-
目标: 在“有希望”的区域内发现并掌握完整的正确策略。 -
方法: 从预热阶段得到的模型检查点(checkpoint)出发,将奖励信号切换回严苛的、二元的“完整通过”奖励。 -
效果: 这一阶段的动态是整个研究中最有趣的部分。
如图 5c 所示,在切换回二元奖励后,模型进入了一个漫长的 探索期(Exploration Phase)。在这期间(大约 450 个训练步骤),模型的完整通过率仍然极低,几乎没有变化。然而,在某个时刻,一个 Grokking Moment 突然出现:模型的性能曲线急剧、陡峭地向上攀升。这标志着模型“顿悟”了解决该问题家族的关键策略。随后,训练进入 收敛期(Convergence Phase),RL 的作用转变为稳定和强化这个新发现的正确推理路径,最终使模型的完整通过率达到近 100%。
为了最终证明 RL 确实解锁了新能力,研究者比较了训练前后模型在测试集上的 pass@k 性能。
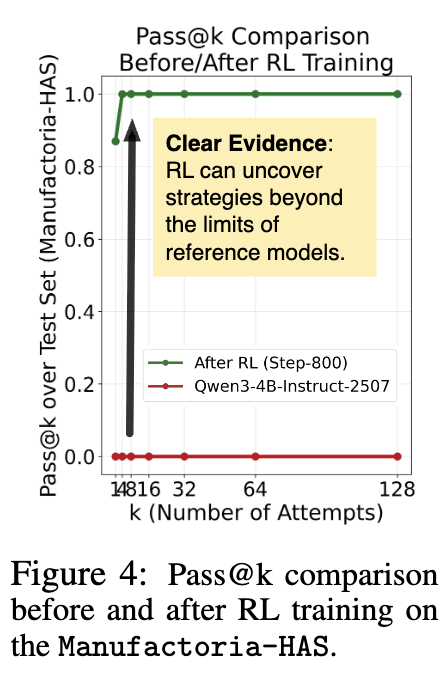
结果一目了然。训练前,Qwen3-4B 模型的 pass@128 成功率为 0。经过“RL Grokking Recipe”训练后,其 pass@k 成功率在 k 很小时就迅速达到了 100%。这清晰地表明,RL 并非简单地提高了采样效率,而是从根本上赋予了模型一种它之前完全不具备的、新的算法能力。这个发现在一个完全受控的、OOD 的环境中,为 RL 的“能力发现”作用提供了强有力的支持。
2. 加速 RL Grokking 的探索
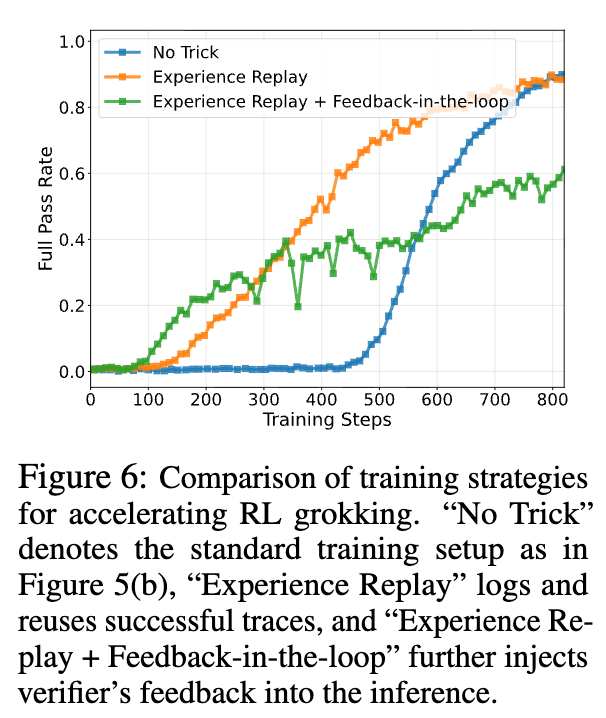
虽然“Grokking Recipe”效果显著,但漫长的探索期也意味着训练效率有待提高。研究者进一步探究了三种可能加速 Grokking 过程的策略。
-
经验回放(Experience Replay):
-
思路: 将训练过程中偶然出现的成功轨迹存储起来,并在后续的训练中重新注入,以增加正奖励信号的密度。 -
结果: 经验回放确实能让 Grokking 现象提前出现。然而,其收敛速度慢于基准的 GRPO 算法。研究者推测,这可能是因为重放的轨迹是“离策略”(off-policy)的,可能会对训练稳定性造成一定干扰。
-
-
在线反馈(Feedback-in-the-loop):
-
思路: 在生成过程中直接将验证器(verifier)的反馈(例如,失败的测试用例)注入,引导模型进行修正。 -
结果: 这种方法也能加速 Grokking 的到来,但代价是训练稳定性的降低。一个常见的失败案例是,模型在接收到明确的反馈后,仍然固执地坚持其最初的错误答案。
-
-
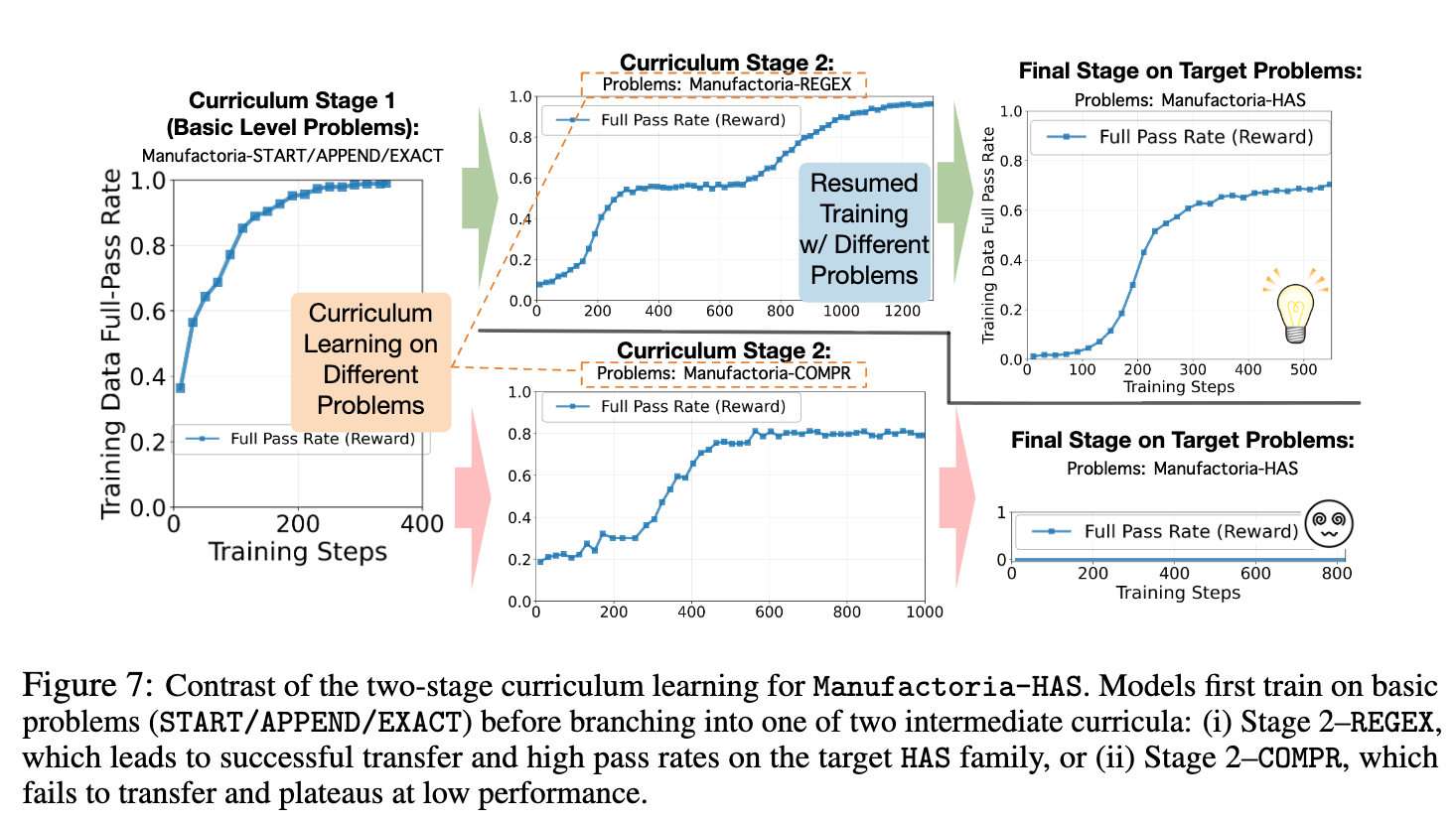
课程学习(Curriculum Learning):
-
思路: 能否用一个结构化的、由易到难的任务序列来替代密集奖励的预热阶段?
-
实验设计: 研究者设计了一个三阶段课程。首先,在
BASIC级别的简单任务(如START/APPEND/EXACT)上训练模型。然后,将其转移到两个难度相似但结构不同的MEDIUM级中间任务之一(REGEX或COMPR)。最后,在目标任务HAS上进行最终训练。 -
结果与分析: 实验结果揭示了课程学习的巨大潜力和固有的脆弱性。
-
成功的路径 ( REGEX->HAS):REGEX课程取得了巨大的成功。模型在REGEX任务上学习到的能力被有效地迁移到了HAS任务,并最终取得了近乎完美的性能。 -
失败的路径 ( COMPR->HAS):COMPR课程则完全失败,模型在最终阶段的性能停滞在很低的水平。
-
-
深层原因: 差异源于 任务的结构相似性。
REGEX(正则表达式匹配)和HAS(子序列查找)在底层逻辑上都依赖于“子模式匹配”。而COMPR(数值比较)则需要模型进行“数值解释和分支测试”,与HAS的核心能力不兼容。 -
结论: 有效的课程学习不仅要求难度上的递进,更要求任务之间核心推理结构的对齐。寻找这样的“桥梁”任务本身就是一个难题。相比之下,基于密集奖励的预热方法虽然可能不是最高效的,但其适用性更广,因为它不依赖于额外的问题集设计。
-
4. RL 泛化性研究
学会一个任务是一回事,能将学到的能力泛化到新场景则是更高层次的要求。研究者使用 BouncingSim 环境,系统地评估了模型在 RL 训练后获得的程序综合能力的泛化表现。
-
实验设置: 在 BouncingSim的六个单一能力家族的Basic难度混合数据上进行训练。基础模型在这些Basic任务上已有非零的成功率,因此可以直接使用二元“完整通过”奖励进行训练。
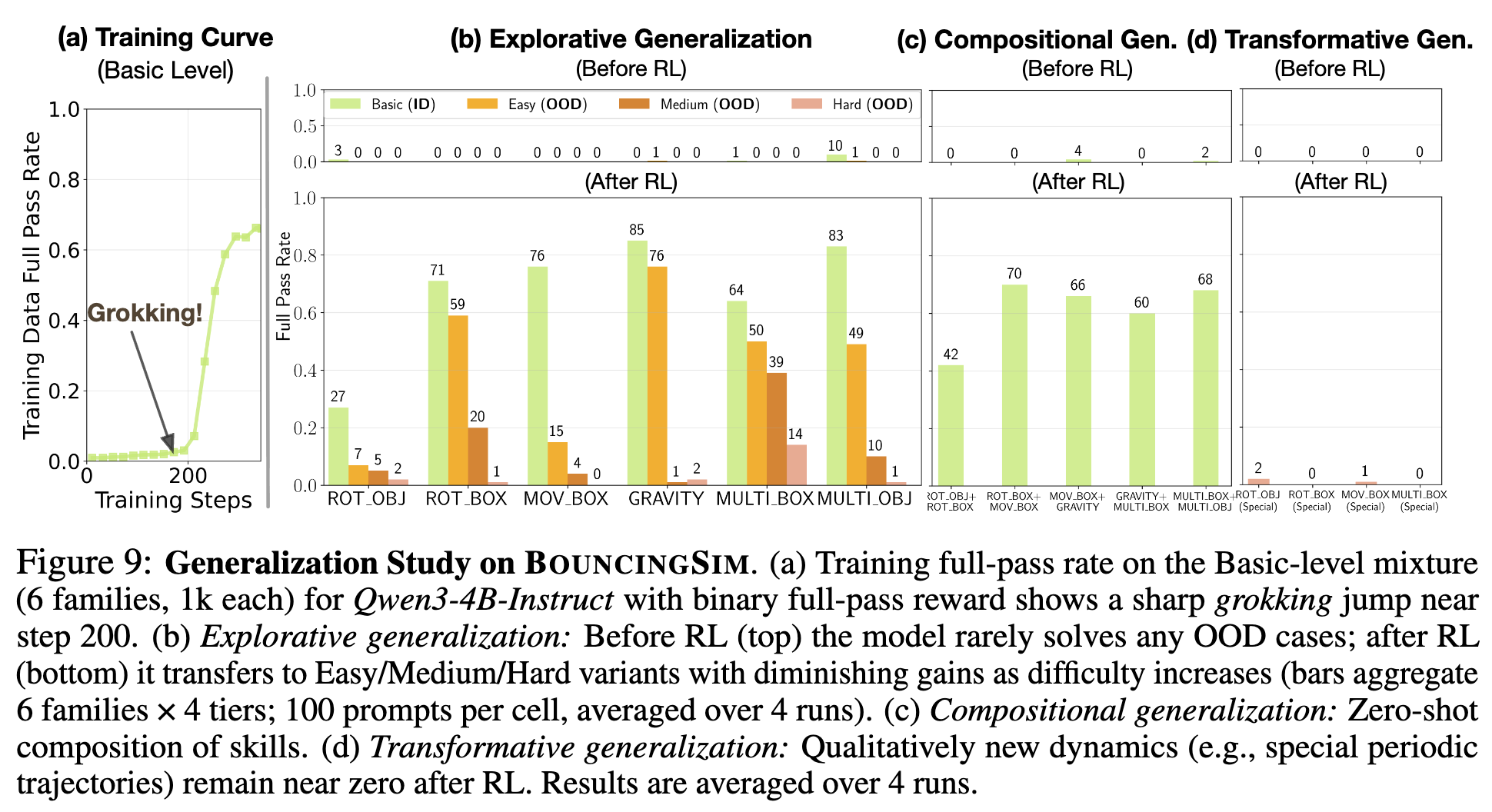
训练过程图 9a 再次呈现了清晰的 Grokking 现象,表明该动态在多任务学习场景下依然存在。模型在约 200 步后突然掌握了处理弹性碰撞的稳定模拟代码。
-
泛化能力评估:
-
探索式泛化(参数化迁移):
图 9(b) 探索式泛化结果。模型将在Basic难度上学到的能力迁移到同一能力的Easy、Medium、Hard难度。结果显示,模型向Easy和Medium的泛化能力较强,但随着难度(如几何形状更复杂、速度更快)的增加,性能逐渐下降,在Hard难度上几乎消失。这表明 RL 学习到的能力在一定参数范围内是鲁棒的,但面对极端参数变化时会失效。 -
组合式泛化(结构化组合):
图 9(c) 组合式泛化结果。这是本次泛化研究中最令人惊喜的发现之一。模型在分别学习了“旋转的物体”和“旋转的容器”后,在测试时面对一个“物体和容器同时旋转”的全新组合场景,表现出了强大的零样本组合能力,许多组合任务的通过率达到了 60-70%。这与 OMEGA 数学基准上观察到的弱组合泛化能力形成了鲜明对比。研究者认为,这可能因为编程任务的组合更倾向于“结构性”组合(例如,将两个独立的模拟模块代码合并),而符号数学任务的组合则需要“策略性”组合(即,发明新的推理步骤),前者对当前的模型架构更为友好。 -
转换式泛化(质变迁移):
图 9(d) 转换式泛化结果。测试模型能否处理具有完全不同动力学特性的场景,如特殊的周期性轨迹。在这类任务上,模型的性能始终接近于零。这表明,RL 训练出的模型能够应用和组合已知的解题“模式”(schemas),但难以在需要发现全新不变量或创造全新解题模式的任务上取得成功。这一发现与数学领域的泛化挑战高度一致。
-
5. 实践启示
改变奖励函数:对于模型难以解决的复杂任务(pass@K=0),不要使用二元奖励。这会导致模型因始终得不到正反馈而无法学习。
采用“Grokking”训练流程:
-
热身期:用密集奖励训练,直到性能饱和。 -
探索期:切换到稀疏奖励,并保持耐心。模型性能可能在很长一段时间内没有起色,这是在为“顿悟”(Grokking)积累探索。 -
收敛期:性能跃升后,稍作巩固训练并及时停止,以防过拟合导致性能崩溃。
精准评估:只看整体平均分会产生误导,让你以为模型变强了,但它可能只是在简单问题上做得更好。在你的评估集中,专门分离出那些基础模型完全无法解决的“硬核子集”。将模型在这个子集上的性能提升,作为衡量其是否真正学会新能力的核心指标。
校准泛化预期:组合能力强,创造能力弱。RL微调学到的新技能,其泛化能力是有边界的。模型很擅长组合已知的技能来解决新问题(例如,混合使用它已知的API)。模型很难创造出一种全新的、本质不同的解题思路。
往期文章:


