
-
论文标题:Agentic Reasoning for Large Language Models: Foundations, Evolution, Collaboration -
论文链接:https://arxiv.org/pdf/2601.12538
TL;DR
今天解读一篇智能体推理相关的综述论文《Agentic Reasoning for Large Language Models: Foundations, Evolution, Collaboration》。
这篇论文是由 UIUC 领衔,联合了 Meta、Amazon、Google DeepMind、UCSD 以及 Yale 等顶尖学术界与工业界机构的近 30 位研究人员共同完成的。这种跨学术界与工业界的庞大合作阵容,确保了该综述不仅在理论框架上具有深度,同时对实际应用落地和前沿技术趋势有着敏锐的洞察。
核心内容摘要:
该论文将大语言模型(LLM)的推理范式从静态的“思维链”(Chain-of-Thought)扩展为动态的“智能体推理”(Agentic Reasoning)。不同于仅依赖测试时计算(test-time computation)的传统方法,智能体推理强调测试时交互(test-time interaction),即通过规划、行动和环境反馈的循环来提升推理能力。
文章构建了一个三层分类体系:
-
基础层(Foundational):单智能体的核心能力,包括规划、工具使用和搜索。 -
进化层(Self-evolving):通过反馈、记忆和持续适应机制,实现推理能力的自我优化。 -
协作层(Collective):多智能体通过角色分工、协作和共同进化来解决复杂问题。
本文将从理论框架、核心机制、应用场景及未来挑战等方面,对该综述进行详细拆解。
1. 引言
大语言模型在数学解题、代码生成等封闭域任务中表现出了推理能力。然而,传统的推理增强技术(如 CoT、Few-shot Prompting)本质上是静态的:模型在固定的上下文中进行单次或多次生成,缺乏对环境变化的适应能力。
智能体推理(Agentic Reasoning) 的核心在于将推理视为一个行动(Action)过程。在这个范式下,LLM 不再是将被动的文本生成器,而是自主的决策实体。推理不仅发生在模型内部的隐层状态中,更外化为对环境的探索、对工具的调用以及对记忆的读写。
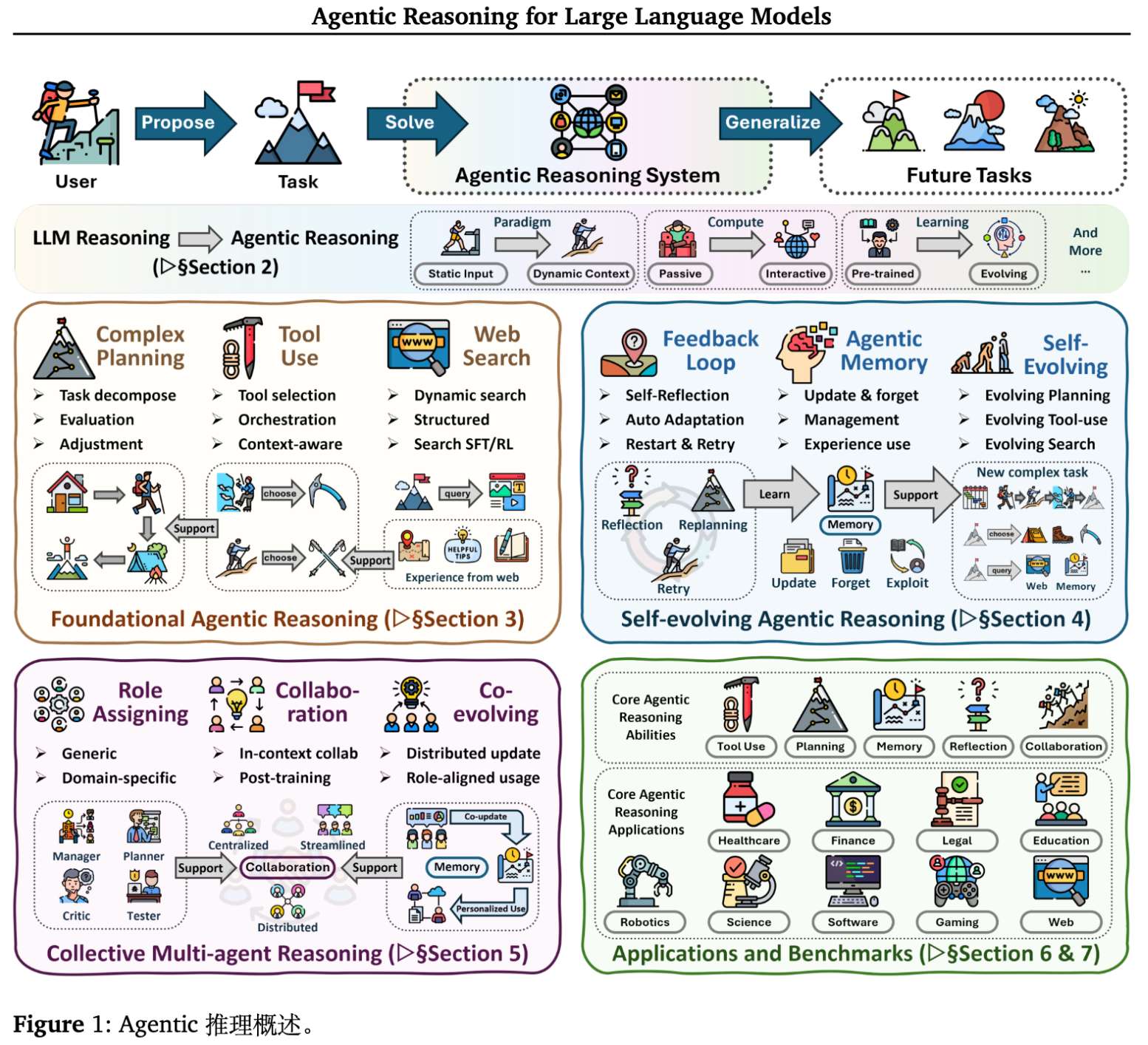
如上图所示,智能体推理在以下维度上与传统 LLM 推理存在本质区别:
-
范式:从被动的静态输入转变为交互式的动态上下文。 -
计算:从单次内部计算转变为包含反馈的多步计算。 -
状态:从仅依赖上下文窗口转变为依赖外部记忆和状态追踪。 -
学习:从离线预训练转变为持续的自我进化。
2. 理论框架
为了统一描述单智能体、多智能体及进化过程,论文提出了一个基于部分可观测马尔可夫决策过程(POMDP)的控制论框架。
环境被建模为元组 ,其中关键变量引入了推理轨迹空间(Reasoning Trace Space) 。
在时间步 ,智能体的策略 被分解为两个阶段:
其中:
-
:内部思维过程(Internal Thought),生成推理轨迹 (如 CoT、潜在规划)。 -
:外部行动过程(External Action),基于历史 和思维 执行动作 (如调用 API)。
这种分解明确了智能体系统的核心特征:在行动 之前,先在 空间进行计算(思考)。
2.1 优化模式
论文贯穿始终地将推理能力的获取分为两种互补模式:
-
上下文内推理(In-Context Reasoning):
-
定义:冻结模型参数 ,通过在推理空间 进行搜索来最大化启发式价值函数 。 -
形式:
-
典型方法:ReAct, Tree of Thoughts (ToT)。这本质上是在进行推理解码时的搜索(Inference-time Search)。
-
-
后训练推理(Post-Training Reasoning):
-
定义:直接优化参数 ,使其策略符合长程奖励 。 -
形式:使用强化学习(RL),特别是组相对策略优化(GRPO)。对于同一提示 生成的一组输出 ,GRPO 目标函数为:
其中 是组归一化优势函数:
-
典型方法:DeepSeek-R1, Toolformer。这旨在将推理模式内化到模型权重中。
-
3. 基础层
智能体推理的基石在于单智能体在稳定环境中的操作能力,主要包含规划、工具使用和搜索。
3.1 规划推理
规划使智能体能够分解目标并进行前瞻性决策。
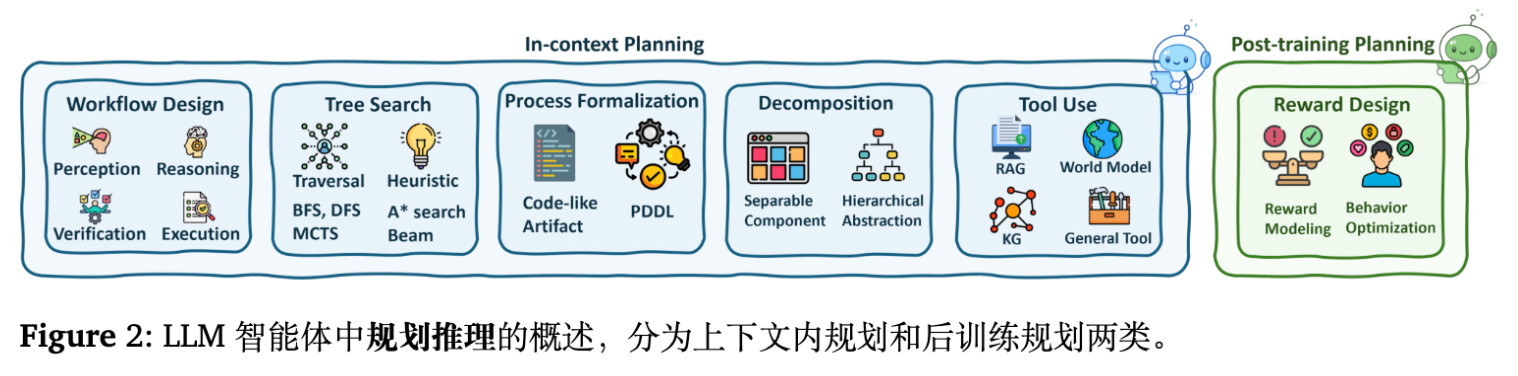
-
上下文内规划:
-
工作流设计:通过 Prompt 工程构建“感知-推理-执行-验证”的显式阶段。例如,ReWOO 将观察与推理模块解耦。 -
树搜索/算法模拟:利用 MCTS、BFS 或 DFS 探索思维空间。例如,ToT 在思维节点上进行搜索;LATS (Language Agent Tree Search) 结合 MCTS 与外部反馈。 -
过程形式化:将计划转化为 PDDL 或代码形式(如 CodePlan),利用符号求解器辅助规划。
-
-
后训练规划:
-
奖励设计与控制:通过 RL 优化规划策略。例如,Reflexion 利用语言反馈作为奖励信号;Search-R1 利用结果奖励训练模型生成搜索标记。
-
3.2 工具使用优化
工具使用扩展了模型的能力边界(计算精度、实时信息)。
-
上下文内集成:
-
ReAct 范式:交替生成推理文本和工具调用指令。 -
动态选择:使用轻量级模型或检索机制从工具库中选择工具(如 AnyTool)。
-
-
后训练集成:
-
SFT 引导:如 Toolformer 通过自监督方式在文本中插入 API 调用;ToolLLM 通过构建大规模指令微调数据增强工具规划能力。 -
RL 强化:ToolRL 和 ReTool 通过环境反馈(成功/失败)强化正确的工具调用路径,解决 SFT 带来的幻觉和过拟合问题。
-
3.3 智能体搜索
不同于静态的 RAG,智能体搜索动态决定“何时搜”、“搜什么”以及“何时停止”。
-
交互式搜索:模型在生成过程中主动发出 <Search>令牌,根据中间结果修正查询。 -
结构化增强:结合知识图谱(KG)进行多跳推理和路径遍历(如 Agent-G)。 -
自适应检索:根据当前推理的不确定性,动态调整检索粒度和策略。
4. 进化层
基础能力使智能体能完成任务,而进化机制使智能体能从经验中学习。这涉及反馈机制和记忆管理。
4.1 反馈机制
反馈是自我纠正的驱动力。
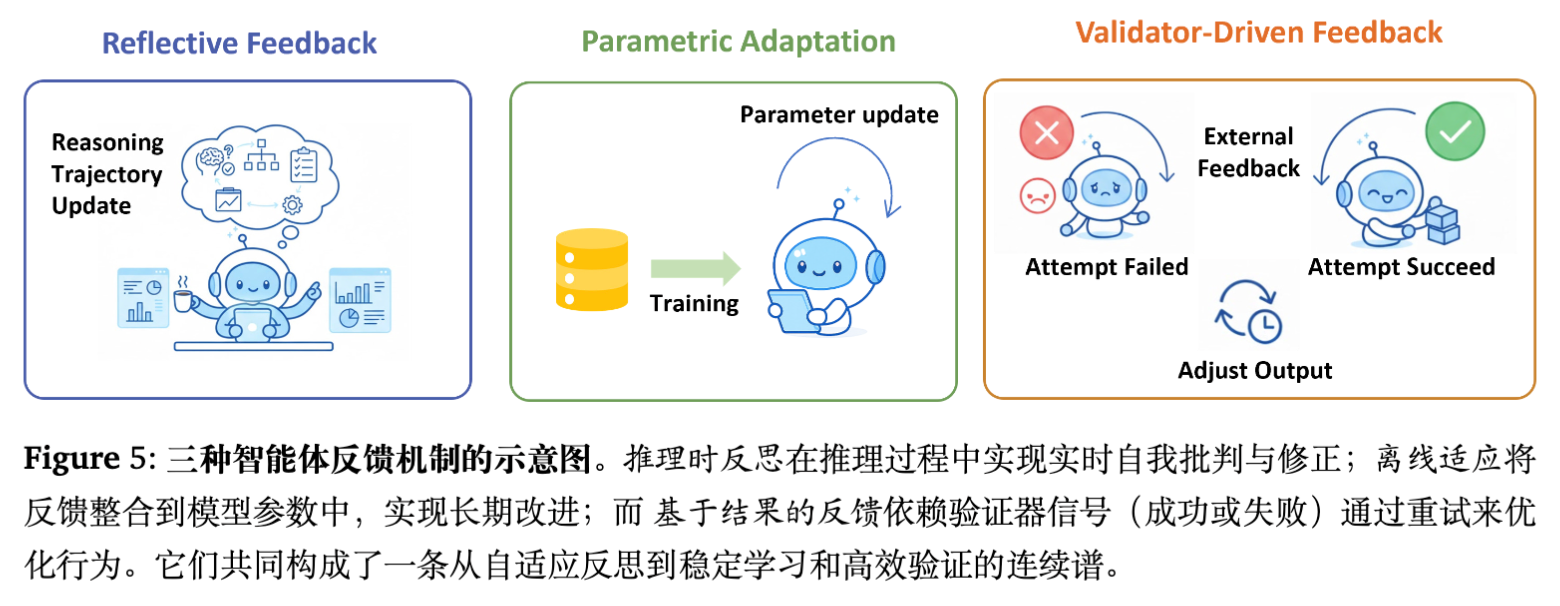
-
反思性反馈:
-
推理时:模型生成自我批评(Self-critique),作为下一次生成的上下文。例如,Reflexion 生成语言形式的失败原因分析。 -
特点:无需参数更新,灵活但受限于上下文窗口。
-
-
参数化适应:
-
训练时:将高质量的推理轨迹(包括修正后的轨迹)用于 SFT 或 RL。例如,ReST (Reinforced Self-Training) 迭代地生成、过滤并微调数据。 -
特点:能力内化,长期有效。
-
-
验证器驱动反馈:
-
结果导向:利用单元测试、模拟器或奖励模型提供的二值信号进行重采样(Rejection Sampling)或树搜索剪枝。
-
4.2 智能体记忆
记忆将推理从无状态转变为有状态,是实现长期进化的关键。
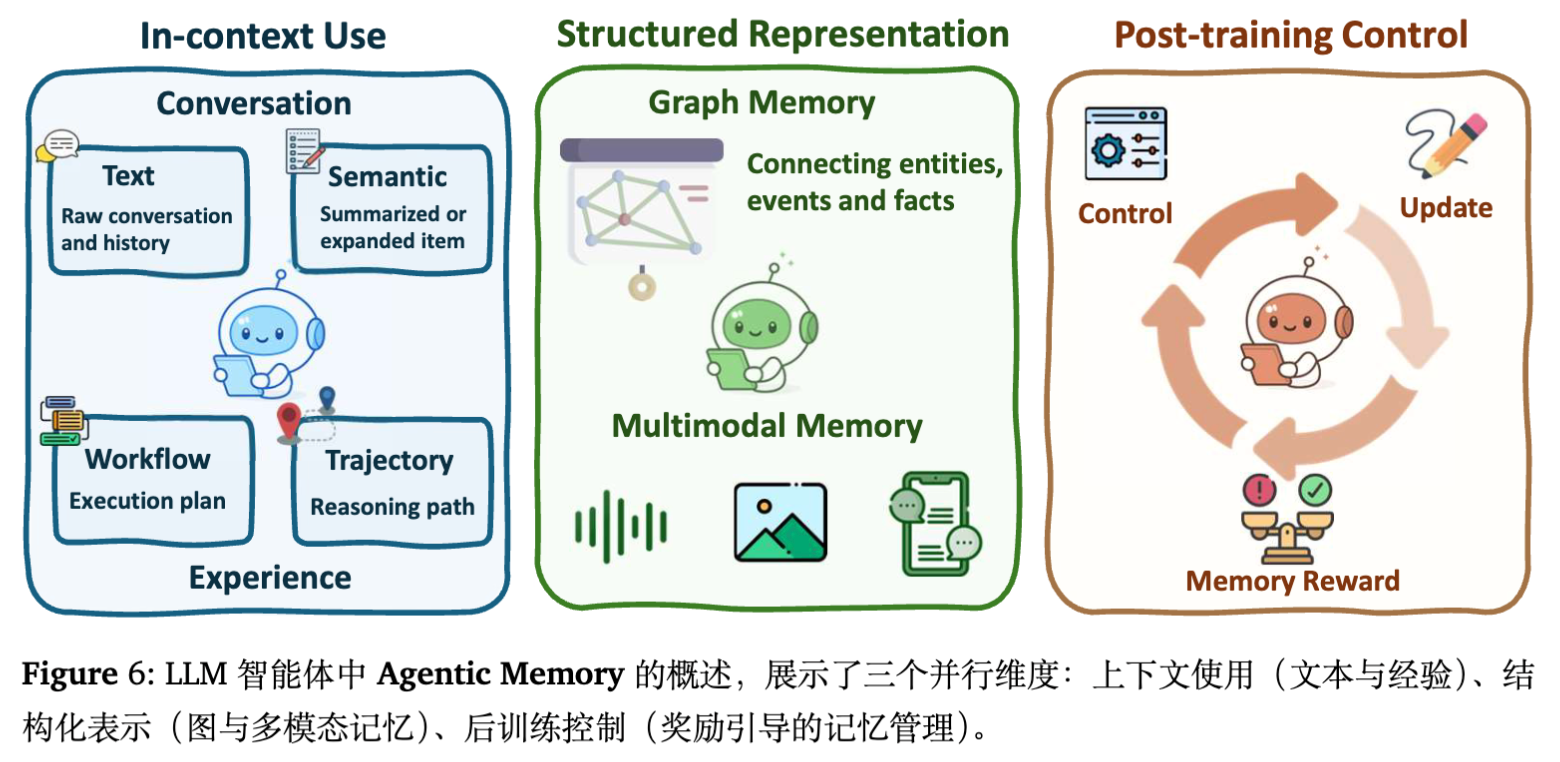
-
扁平记忆的智能体化:
-
上下文管理:如 MemGPT,通过类似操作系统的分页机制管理无限上下文,区分工作记忆(Context Window)和长期记忆(外部存储)。 -
经验记忆:不仅存储事实,还存储“推理模式”和“错误教训”(如 Generative Agents 中的反射流)。
-
-
结构化记忆:
-
图与树:使用知识图谱或层级树组织记忆,支持多跳检索。 -
多模态记忆:存储视觉-文本对齐的经验(如 Embodied 场景)。
-
-
后训练记忆控制:
-
将记忆的读写操作视为动作(Action),通过 RL 训练模型主动决定何时写入、何时遗忘(如 Memory-R1)。这比基于规则的检索更具适应性。
-
4.3 能力的共同进化
-
自进化规划:通过生成合成任务或修改自身代码(如 Voyager)来扩展技能库。 -
自进化工具:模型编写代码创建新工具(Tool creation),而不仅仅是使用现有工具。
5. 协作层
当任务复杂度超出单个智能体能力时,多智能体系统(MAS)通过协作涌现出更强的推理能力。
5.1 角色分类学
-
通用角色:Leader(协调)、Worker(执行)、Critic(评估)、Memory Keeper(记忆维护)。 -
领域特定角色: -
软件工程:产品经理、架构师、工程师、测试员(如 MetaGPT)。 -
医疗:分诊员、专科医生、主治医生。
-
5.2 协作与分工
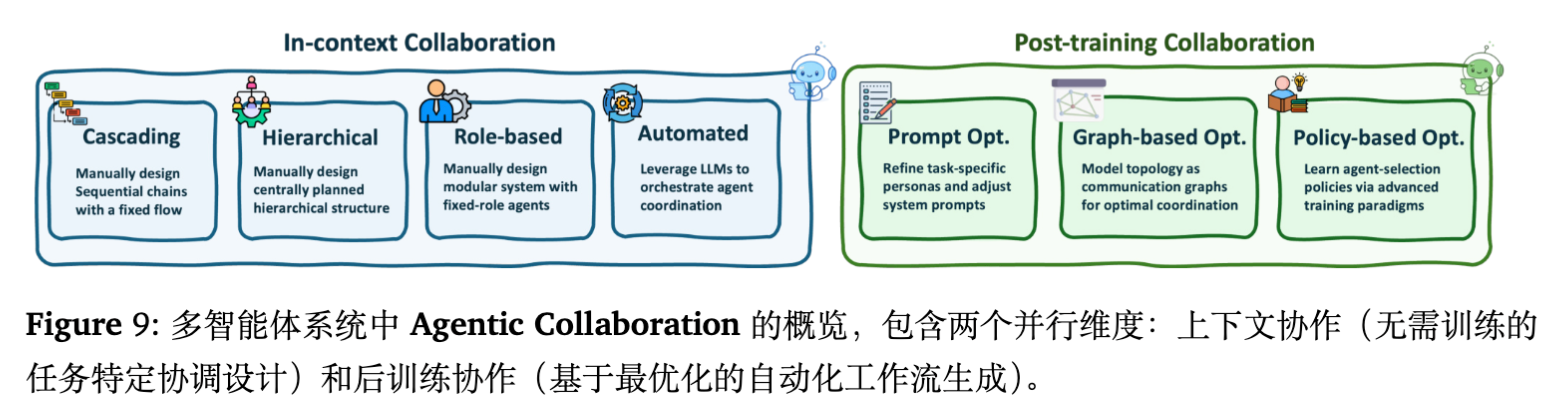
-
上下文内协作:
-
手动编排:预定义的交互流程(如瀑布流、SOP)。 -
动态路由:利用 LLM 作为路由器(Router),根据问题动态组建团队或选择专家。 -
辩论与协商:智能体之间通过多轮对话消除分歧(如 Multi-agent Debate)。
-
-
后训练协作:
-
通信拓扑优化:将协作关系建模为图,通过梯度下降或演化算法优化通信结构(如 GPTSwarm)。 -
多智能体 RL (MARL) :在通信环境中训练智能体,使其学会高效沟通。
-
5.3 多智能体进化
多智能体系统的进化不仅是个体的提升,更是组织结构的优化。
-
群体记忆:共享的知识库或技能库,允许新加入的智能体快速获取团队经验。 -
协作策略学习:通过元学习或进化算法,自动发现最优的组队方式和交互协议。
6. 应用场景
论文详细回顾了智能体推理在具体领域的落地,展示了不同推理机制的实例化。
6.1 数学探索与 Vibe Coding
-
数学:从解题(GSM8K)转向探索(FrontierMath)。AlphaGeometry 等系统结合了符号推理引擎与 LLM 的直觉,展示了神经-符号系统的威力。 -
代码:Vibe Coding(通过自然语言交互式编程)成为新范式。智能体不仅生成代码,还负责运行、调试、解释错误并迭代修复(如 OpenHands)。
6.2 科学发现
-
自主实验室:智能体规划实验步骤,调用机器人执行(如 Coscientist)。 -
文献研究:通过 RAG 和引用图谱进行假设生成和验证。 -
机制:强调长程规划和严格的验证反馈(如物理模拟器的反馈)。
6.3 具身智能
-
感知-行动循环:LLM 作为大脑,VLM 作为感知器。 -
世界模型:利用生成式世界模型(Generative World Models)进行想象和规划(如 DreamerV3 思想的 LLM 化)。 -
Sim-to-Real:利用模拟环境中的 RL 训练策略,迁移到真实机器人。
6.4 医疗与网络智能体
-
医疗:多智能体模拟医患对话,或多专家会诊系统。强调安全性和知识准确性。 -
Web Agents:在真实网页环境中进行 DOM 树操作。面临动态环境和长程依赖的挑战(如 WebArena)。
7. 基准测试
评估智能体推理需要超越简单的准确率(Accuracy)。
7.1 能力中心评估(Mechanism-centric)
-
工具使用:ToolBench, API-Bank。评估 API 选择准确率、参数填充正确性。 -
搜索:WebGPT, Mind2Web。评估信息检索的覆盖率和路径效率。 -
记忆:MemBench。评估长下文中的召回和状态更新能力。
7.2 应用中心评估(Application-centric)
-
SWE-bench:解决真实的 GitHub Issue,评估端到端代码工程能力。 -
WebArena:在模拟互联网环境中完成购物、预订等任务。 -
ScienceWorld:文本冒险游戏形式的科学实验环境。
8. 开放问题与未来方向
论文最后指出了当前领域的局限和未来的高价值研究方向:
-
用户为中心的个性化推理:目前的智能体多为任务导向。未来的智能体需要对用户建立长期模型(User Modeling),实现个性化服务。 -
长程交互中的信贷分配(Credit Assignment):在数千步的操作中,如何确定哪一步推理导致了最终的成功或失败?这是 RL 训练智能体的核心难点。 -
世界模型(World Models):智能体需要一个内部环境模型来进行“试错”和“反事实推理”,以减少在真实环境中的探索成本。 -
多智能体训练:目前多智能体多基于 Prompt 工程。如何在大规模多智能体系统中进行端到端的梯度训练(如 MaaS)是一个开放难题。 -
潜在空间推理(Latent Agentic Reasoning):目前的 CoT 是显式语言。未来的推理可能发生在压缩的潜在向量空间中,以提高效率。 -
治理与安全:随着智能体自主性增强,如何确保其行为符合人类价值观,且在失控时可被干预。
总结
论文通过三层架构系统地梳理了 LLM 向智能体演进的技术路径。核心观点在于:推理不再是静态的文本生成,而是动态的、交互式的、具身的计算过程。
以下几个技术点值得特别关注:
-
System 2 思维的内化:如何利用 RL(如 DeepSeek-R1 的方法)将推理时的搜索计算量转化为模型本身的直觉。 -
记忆的参数化控制:从基于规则的 RAG 转向模型自主控制的记忆读写策略。 -
多智能体的梯度优化:超越简单的 Prompt 角色扮演,探索多智能体通信协议的可学习性。
更多细节请阅读原文。
往期文章:


