让每一项优秀工作,被更多人看见:点击进入投稿通道

-
论文标题:LEARNING MORE WITH LESS: A DYNAMIC DUAL-LEVEL DOWN-SAMPLING FRAMEWORK FOR EFFI-CIENT POLICY OPTIMIZATION -
论文链接:https://arxiv.org/pdf/2509.22115
TL;DR
今天解读一篇来自微信团队的论文《LEARNING MORE WITH LESS: A DYNAMIC DUAL-LEVEL DOWN-SAMPLING FRAMEWORK FOR EFFICIENT POLICY OPTIMIZATION》。当前大语言模型(LLM)的对齐训练中,无评论家(Critic-free)的强化学习算法(如 GRPO 和 GSPO)通过在一个采样组(Group)内计算相对优势,缓解了传统 PPO 算法带来的内存瓶颈。然而,这类方法在提升显存利用率的同时,通常需要较大的采样组来估计优势,这会导致有效学习信号被大量无信息样本和词元(Tokens)稀释,从而降低策略优化的效率并拉长收敛时间。
为解决这一权衡问题,作者提出了动态双层下采样(Dynamic Dual-Level Down-Sampling,简称 D3S)框架。该框架包含三个核心机制:
-
样本级下采样:放弃了直接最大化奖励方差(Reward Variance)的常规做法,转而在全局批次中选择最大化优势方差(Advantage Variance)的样本子集。作者通过严格的理论证明表明,这种选择方式与策略梯度范数的上界呈正相关,从而能够产生更大的策略梯度,加速训练。 -
词元级下采样:引入了基于熵与优势乘积()的词元重要性评估指标,将模型更新的计算资源集中在策略不确定性较高且对最终奖励有较大影响的决策节点上。 -
动态下采样调度:采用类似课程学习(Curriculum Learning)的策略,在训练初期进行激进的下采样以加速收敛,在训练后期逐渐放宽下采样比例,引入更多样化的样本以防止过拟合并提升泛化能力。
在 Qwen2.5 和 Llama3.1 模型上的广泛数学推理基准测试表明,将 D3S 集成到 GRPO 和 GSPO 中,可以在减少样本和词元消耗的前提下,取得优于基线算法的性能。
1. 引言
大语言模型(Large Language Models, LLMs)在遵循人类指令和处理复杂逻辑推理任务方面取得了显著进展。在这个过程中,强化学习(Reinforcement Learning, RL)成为了将模型行为与人类偏好或客观事实对齐的关键技术。传统的近端策略优化(Proximal Policy Optimization, PPO)算法在这一领域占据了主导地位。PPO 包含一个策略模型(Actor)和一个价值模型(Critic/Value Model),价值模型用于估计每个状态的预期回报,从而计算优势函数(Advantage Function)以指导策略的更新。
尽管 PPO 在诸多任务中表现稳定,但在 LLM 训练中,由于模型参数量庞大,同时在显存中维护策略模型、参考模型(Reference Model)、价值模型以及奖励模型(Reward Model)会带来巨大的内存开销。为了缓解这一内存瓶颈,研究社区提出了一系列无评论家(Critic-free)的方法,其中最具代表性的是组相对策略优化(Group Relative Policy Optimization, GRPO)和组序列策略优化(Group Sequence Policy Optimization, GSPO)。
GRPO 等方法的核心思路是对同一输入提示(Prompt)进行多次采样,生成一组回复(Responses),并在该组内部计算相对奖励,以此对奖励进行标准化并作为优势函数的估计值。这种设计不仅移除了独立的价值网络,节省了内存,还通过相对比较的方式降低了优势估计的方差。
然而,内存瓶颈的缓解并未完全消除效率挑战。GRPO 和 GSPO 算法在实际应用中遇到了一个新的权衡困境:
-
大组采样的信息稀释问题:为了获得准确的相对优势估计,通常需要设置较大的组大小(例如 或更大)。但在某些任务(特别是具有二元奖励属性的数学推理任务)中,大量的采样回复可能是同质化的。例如,当问题较简单时,组内大部分甚至所有回复都是正确的;当问题较难时,几乎所有回复都是错误的。在这两种情况下,标准化后的优势值接近于零。这些缺乏梯度的“无信息样本”不仅浪费了计算资源,其平均效应还会掩盖少数关键样本和关键词元带来的有效学习信号,导致策略收敛缓慢。 -
小组采样的多样性不足问题:如果单纯为了减少计算量而缩小组大小(例如 ),虽然可以加快单步更新的计算速度,但较小的采样组难以覆盖复杂的搜索空间,难以产生具有差异化的正确和错误回复,同样会导致优势估计不稳定和策略陷入局部最优。
为了应对这一挑战,部分先期研究(如 PODS 等)发现,提高奖励信号的方差()能够使得优化地形更加陡峭,从而加速模型收敛。然而,对于 GRPO 及其变体而言,其优势值是通过在组内(或选定的子集内)进行标准化计算得到的。这意味着无论原始奖励的方差如何,标准化后的优势方差始终被固定为 1。
针对上述背景与局限性,本文作者研究了 GRPO 的梯度范数上界,提出了 D3S 框架。该研究不仅在理论层面指出了最大化优势方差(而非奖励方差)的合理性,还在工程实现上构建了涵盖样本层面、词元层面以及时间调度层面的综合优化系统。
2. 前置知识:GRPO 与 GSPO 算法回顾
在深入解析 D3S 框架之前,需要系统性地回顾其所基于的基础强化学习算法:GRPO 和 GSPO。这两个算法为 D3S 提供了基础的优化目标和优势估计范式。
2.1 组相对策略优化(GRPO)
假设有一个来自数据集 的输入查询 。具有参数 的大语言模型被定义为策略 。对于每一个查询 ,策略 会生成 个不同的回复,形成一个大小为 的组。设第 个回复为 ,该回复包含的词元数量记为 。
GRPO 移除了传统 PPO 中的价值网络,直接通过组内相对奖励来估计优势。GRPO 的优化目标定义如下:
其中:
-
是重要性采样比率(Importance Ratio),定义为当前策略与旧策略在特定词元上的生成概率之比:
-
是裁剪的超参数,用于限制单步策略更新的幅度,防止策略偏离过远。 -
是 KL 散度(Kullback-Leibler divergence)的惩罚系数,用于约束策略模型 不要在分布上偏离参考模型 太多,从而防止奖励作弊(Reward Hacking)。 -
是词元级别的组归一化优势值。在 GRPO 的标准实现中(特别是数学任务中),优势通常在序列级别计算,然后分配给序列中的所有词元。对于第 个回复,其奖励信号为 ,优势的计算方式是通过在组内对奖励进行标准化得到的:
这里, 表示样本标准差。标准化操作确保了在一个组内,优势信号的均值为 ,方差为 。如果在一个组内,所有回复的奖励相同(例如全部正确获得满分,或全部错误获得零分),则标准差为零,此时通常将该组内所有优势值设为零,使得这些样本不对模型梯度产生贡献。
2.2 组序列策略优化(GSPO)
在 GRPO 的基础上,Zheng 等人提出了 GSPO 算法。GSPO 同样采用无评论家的架构,但它将整个序列作为上下文进行下一个词元的预测优化,并引入了一种基于整个序列似然度的新型重要性比率。这种改变意在进一步提升序列级别的信用分配(Credit Assignment)和训练稳定性。
GSPO 的优化目标定义为:
这里的重要性比率 采用了与 GRPO 不同的计算方式,它融合了序列级的似然度并使用了停止梯度(Stop-gradient)操作 :
虽然 GSPO 改变了重要性比率的构建方式,但其优势值 的计算机制与 GRPO 完全一致,依然依赖于组内相对奖励的标准化。因此,GRPO 中存在的“大组信息稀释”问题在 GSPO 中同样存在。
3. 理论分析:为什么最大化优势方差有效?
为了从根本上解决大组信息稀释的问题,下采样(选取信息量最大的子集进行更新)成为一种直观的解决方案。之前的研究(如 PODS)主张选取使得原始奖励方差 最大的子集。然而,本文作者通过严密的数学证明指出,在 GRPO 及其变体的标准化机制下,由于子集内的优势会被强制重新标准化,最大化奖励方差并不能提升策略梯度范数的上界。相反,应当在全局计算优势后,选择最大化优势方差()的子集。
本节将详细梳理作者提出的三个理论核心:命题 1、命题 2 以及引理 1。
3.1 命题 1:标准 GRPO 梯度范数的固定上界
命题 1: GRPO 目标函数的梯度范数满足如下不等式:
其中, 表示一个与输入 和模型参数 相关的静态标量参数。
理论推导详析:
在参考策略点(此时重要性比率等于 1,不触发裁剪操作)对目标函数求梯度。为简化分析,我们考虑序列级别的优势值 (这也是目前数学任务中基于结果奖励的 GRPO 实现主流方式)。目标函数梯度可展开为:
为了放缩这个梯度,对于任意常数 ,可以将累加和根据优势值的绝对值大小进行拆分。拆分为两项:(I) 优势绝对值 的样本,和 (II) 优势绝对值 的样本。
对于第 (I) 项,当 时:
由于策略是对数似然,且模型的输出概率和独热(one-hot)标签之间的差值向量的 L1 范数最多为 2(即 ),我们可以将梯度范数的期望部分用一个静态项 来表示。从而得到:
对于第 (II) 项,当 时:
其中 是指示函数。因为在 GRPO 的机制中,优势值是被组内标准化的,具有 和 的属性,从而 。利用精炼的切比雪夫不等式(Refined Chebyshev inequality),可以得出:
所以对于第二项的边界为:
将两项的边界结合起来,我们得到:
为了使得右侧的上界最紧致(最小化),根据基本不等式,当 时取得最小值,最终得到:
结论意义: 命题 1 揭示了基于组的算法的一个关键属性。只要模型参数和输入给定,策略梯度的范数就会被一个严格的理论值()作为上界所限制。更重要的是,这个上界与显式的奖励方差()没有任何关系。这意味着,如果我们先选出一个具有高 的子集,然后在子集内部重新进行归一化使得 ,梯度的上限依然是死板的,无法通过这种数据选择策略带来额外的优化空间。
3.2 命题 2:子集优化的可变梯度上界
既然在子集内重新标准化行不通,作者提出了一种新的思路:在整个包含 个样本的组内计算并固定标准化优势 ,然后在这个已经标准化完毕的池子中,挑选出一个子集。对于这个子集,我们不再进行二次标准化,直接用于计算损失。
命题 2: 如果从原始组(大小为 )中选择一个子集,并在该子集上执行 GRPO 更新(记为 ),则其梯度满足如下不等式:
其中, 表示被选中子集的优势信号的方差。
理论推导详析:
在这个基于 驱动的下采样机制中,子集的优势分布不再满足 。
首先估计 的最大可能值。在二元奖励(0 或 1,数学推理任务常见)且标准化的情况下,当组内只有一个样本获得 1 分,其余 个样本获得 0 分(或反之)时, 达到极大值:
将这一最大值条件代入前文的第二项(大于阈值 的部分),根据概率定义,有:
于是,包含子集方差 的整体边界变为:
为了找到最紧致的边界,将上式对 求导并令其等于 0:
将 代回原方程,化简后即得到命题 2 的最终不等式形式。
结论意义: 命题 2 的形式发生了一个根本性的变化。相比于命题 1 固定死板的边界,下采样策略下的梯度范数上限是一个可变量,并且该变量与所选子集的优势方差 成正相关(成 1/3 次方关系)。这从严密的数学逻辑上证明了:在一个预先标准化的组中,挑选出优势方差 更大的子集,能够抬高策略梯度范数的上限,从而允许更强、更清晰的梯度信号来加速模型的收敛。这也暴露出以往最大化奖励方差 方法的两个主要局限:第一,受限于二次归一化,梯度上界不变;第二,在更小的偏置子集内进行归一化会导致优势估计极不稳定。
3.3 引理 1:高方差子集存在的保证
知道了选择高方差子集有益处,那是否在数学上保证一定能从任意标准化组中选出一个方差大于等于 1 的子集呢?
引理 1: 设 是一个包含 个元素的集合,且已标准化满足 且 。对于任意满足 的整数 ,必定存在一个子集 ,其大小 ,并且满足 。
证明思路: 作者采用后向数学归纳法证明。
-
基础情况 () :直接选取整个集合 ,此时 ,显然成立。 -
归纳步骤:假设对于某个 (其中 ),存在一个大小为 且方差大于等于 1 的子集 。我们需要证明:通过移除该子集中的某一个特定元素 ,可以形成一个大小为 的新子集 ,且新子集的方差 。
根据方差的定义及其递归关系:
要满足 ,必须找到一个元素 ,使得:
因为 是集合中所有元素到均值距离平方的平均值,总有至少一个元素(最靠近均值的那个元素)其平方距离小于或等于平均距离。因此,剔除掉那个离均值最近(最缺乏变化、最没有特征)的元素 ,剩余的元素所构成的子集方差一定会大于或等于原方差。通过数学推导,该逻辑在 时普遍成立。
通过这一系列扎实的理论推导,作者为接下来的算法设计(最大化 以加速收敛)奠定了坚实的数学基础。
4. D3S 框架详解
基于前述理论洞见,作者构建了动态双层下采样(Dynamic Dual-Level Down-Sampling, D3S)框架。该框架在两个粒度层面(样本级和词元级)进行信息筛选,并利用动态时间调度机制进行整体调控。
4.1 样本级:跨组优势驱动的下采样 (Sample-Level)
基于命题 2 的指导,D3S 并非根据原始奖励来选择样本,而是根据组相对的估计优势来识别核心样本子集。这确保了所选子集内优势信号的方差能够被最大化。
给定一个查询 及其 个采样的回复集合 ,选取大小为 的子集 的目标函数为:
具体实现上,如何从 种组合中高效挑出方差最大的子集?一种有效且直观的做法是,选取优势值最极端(即偏离均值最远)的样本。作者采用了将最高正优势的样本与最低负优势的样本组合的方式,构成目标子集。
跨组操作(Cross-Group Operation):
在实际训练中,梯度更新是以批次(Batch)为单位进行的。由于数学推理任务中不同查询的难度存在较大差异,优势值在不同组之间的分布差异显著。例如,对于一个非常简单的提示,模型生成的 32 个回复全对,导致这一组内的相对优势全部为零(无信息)。如果仅在组内进行下采样,选出的依然是零优势样本。
为此,D3S 引入了跨组操作(Cross-group operation)。假设一个批次包含 个查询,构成整个批次的采样池 。框架直接在全批次层面选出方差最大的 个样本():
值得强调的是,在此过程中保留了原始在各自组内计算出的优势值,不再进行任何额外的标准化。这使得跨组选取能够有效剔除掉那些全体回复同质化的平庸组,将有限的训练预算集中在存在强烈正反例对比(产生有效梯度)的高价值样本上。
4.2 词元级:基于熵与优势加权的选择 (Token-Level)
除了样本级别的冗余,一条回复内部也存在大量信息量低迷的词元。在语言模型生成的长序列中,通常由三种词元组成:
-
简单词元:模型既自信又准确(例如公式推导中显而易见的连词或基本常数)。 -
中性词元:对最终结果的正确与否影响微弱的格式性词元。 -
关键词元:模型在此处存在不确定性,且该位置的决策严重影响最终的奖励走向(例如决定推导方向的关键定理选择、核心计算步骤)。
策略熵(Policy Entropy)被视为模型不确定性的度量工具。相关研究表明,占据最高熵值前 20% 的词元主导了策略梯度的方向。将所有词元等同对待,相当于用大量噪声平均了有意义的信息,从而稀释了梯度信号。
基于此,D3S 提出了一种将生成熵与词元级优势结合的统一重要性评估指标,用于在所有选中样本的所有词元中进行排序。
对于第 个回复的第 个词元,其策略熵 定义为词表 上概率分布的熵:
综合评估指标定义为优势的绝对值与熵的乘积:
该指标的合理性分析:
-
较大的 意味着模型在该节点感到犹豫、缺乏置信度,这恰好是策略模型最需要探索和学习的知识盲区。 -
较大的 则意味着该位置上的选择对于最终策略的改进具有很高的潜在影响(无论是带来高正向奖励的正确路径,还是导致严重惩罚的错误路径)。 -
二者相乘,确保了只有在既具备高不确定性又对结果影响深远的决策节点,模型才会消耗算力去更新参数。
随后,D3S 选出整个批次中该指标排名前 的词元集合 :
在每次梯度更新时,只有集合 中的词元才会对策略参数 的梯度产生贡献,进而引导策略去解决关乎奖励成败区域的不确定性问题。
4.3 动态下采样调度 (Dynamic Down-Sampling Schedule)
上述样本级和词元级的策略通过优先利用高信号的数据,大幅加快了前期的收敛速度。然而,强效的梯度信号也伴随着副作用:模型可能会在训练后期过度利用(Over-exploit)少数几条具有高信息的轨迹,陷入奖励欺骗(Reward Hacking)或过拟合的风险中。在早期极具信息量的样本,随着模型能力的提升,可能不再能反映模型当前的缺陷,而此时一味追求高方差反而限制了模型对泛化规律的探索。
为了解决这一问题,D3S 引入了一个动态的下采样调度机制。该机制受到课程学习(Curriculum Learning)由简入难原则的启发,通过随训练进度线性增加保留的样本数量和词元比例,来逐渐降低下采样的强度。
假设训练进度 (由当前的步数或周期决定)。采用线性调度函数在初始激进配置 和最终宽松配置 之间进行插值运算。具体而言,当前进度下的保留样本数 和词元比例 计算如下:
-
在训练初始阶段(),模型采取极低比例的采样,专门挑拣出最明显的正误对比例子,从而获得明确、强烈的更新方向,快速跨越性能低谷。 -
随着训练深入(), 和 的阈值不断放宽,更多样化、相对平庸的信号被引入训练池。这一过程强制模型不偏废细枝末节的知识,丰富了策略的多样性,确保了长期的稳健表现并有效防止了过拟合现象。
4.4 D3S 的完整优化目标
结合上述跨组样本选择机制和词元级熵-优势加权选择机制,D3S 重新定义了最终的优化目标函数:
通过这个目标函数,模型仅在经过精挑细选的高效用集合上进行反向传播更新,从而将有限的算力用在了“刀刃”上。
5. 实验
为了验证 D3S 框架的有效性和可扩展性,作者进行了详尽的实验,不仅跨越了多种算法基线,还在不同尺度和对齐状态的大模型上进行了验证。
5.1 数据集与评估基准
训练过程使用了 DeepScaleR 提供的数据集。该数据集包含了丰富的数学问题,例如 1984 年至 2023 年的 AIME(美国数学邀请赛)问题、2023 年以前的 AMC(美国数学竞赛)问题以及其他来源的复杂数学题。
在训练期间,为了实时监控策略在分布外(Out-of-Domain)数据上的泛化表现,作者选用了 AIME24 作为实时的验证集。
评估基准(Benchmarks) 囊括了当前大模型数学推理能力评估的标准集合,具有较高的挑战性:
-
AIME25 和 AIME24 -
AMC23 -
GSM8K(小学级别数学应用题) -
MATH(高难度综合数学竞赛题) -
MinervaMath -
OlympiadBench(奥林匹克级别的顶级难度题)
评价指标:对于每个基准测试中的每一个问题,系统会利用当前策略模型并行生成 32 个独立的回答,并计算 Pass@k 指标(主要是 Pass@1 和 Pass@8 甚至 Pass@16/32)。只要前 k 个生成的回答中有至少一个是正确的,就判定该题成功解决。最终的奖励函数判定基于 math_verify 工具进行严格的规则验证。
5.2 模型与算法基线配置
模型选择:
为了全面评估 D3S,作者选择了不同特性的模型作为骨干网络(Backbones):
-
Qwen2.5-Math-7B:经过预对齐(Pre-aligned)操作,专门针对数学任务优化的 70 亿参数模型,基础能力很强。 -
Qwen2.5-Math-1.5B:同系列的较小参数模型,用于测试方法在有限容量模型上的扩展性。 -
Llama3.1-8B-Instruct:通用目的指令微调模型,并未经过专门的数学领域预对齐处理。 -
OpenMath2-Llama3.1-8B:基于 Llama3.1-8B 微调的数学专属变体,用作对比验证。
所有模型都采用其官方推荐的生成温度(Temperature)和截断概率(Top-p)进行采样。
算法基线(Baselines):
-
GRPO:标准的无评论家算法,目前开源社区进行数学推理对齐的主力。 -
GSPO:改进了序列级优势估计和重要性比率的最新变体。 -
PODS:一种通过最大化奖励方差()进行下采样的最新代表性方法。
此外,为了验证 D3S 内部模块的贡献,还设置了多个退化变体进行消融实验:
-
D1S:仅使用样本级下采样(在组内最大化优势方差)。 -
D1S-C (w/Cross) :包含跨组操作(Cross-group)的样本级下采样。 -
D2S:结合了样本级和词元级下采样,但不包含动态下采样调度(即参数 和 固定不变)。
模型采样组大小统一设置为 。D3S 的动态调度中,起始样本数 ,结束样本数 ;起始词元比例 ,结束词元比例 。
6. 核心实验结果与分析
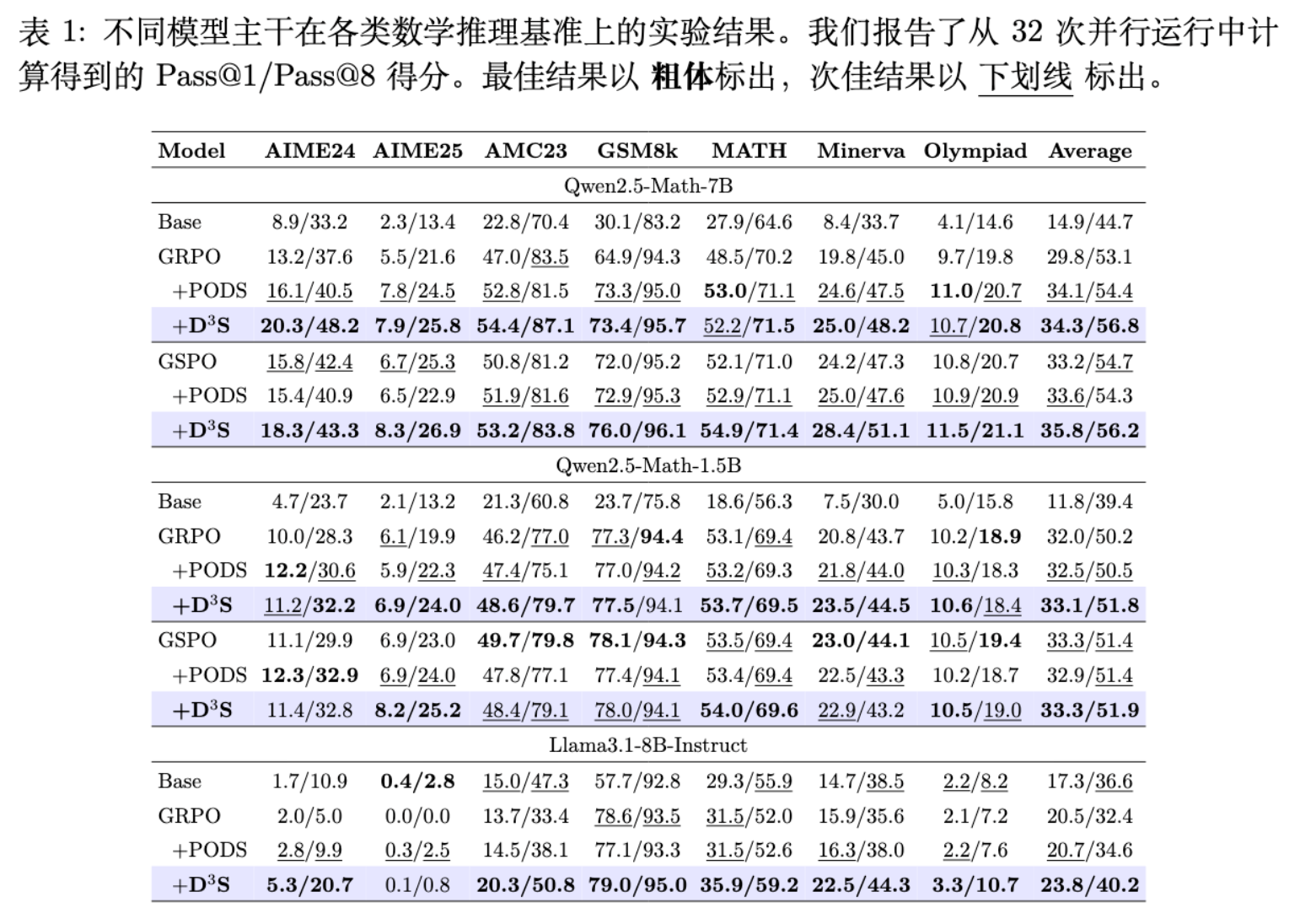
6.1 各项指标的全面领先
首先,将 D3S 引入 GRPO 和 GSPO 算法后,几乎在所有骨干模型和所有测试集上都取得了性能提升。这证明了 D3S 具有跨越模型类型和基础算法的广泛适应性。
-
以能力最强的 Qwen2.5-Math-7B 为例,配合 GRPO+D3S,其在所有基准测试上的平均 Pass@1 达到了 34.3%,平均 Pass@8 达到了 56.8%。相比之下,原始 GRPO 的平均 Pass@1 为 29.8%,Pass@8 为 53.1%。D3S 分别带来了 4.5 个点和 3.7 个点的显著提升。 -
D3S 在表现上也明显优于此前提出的 PODS 方法。在相同配置下,PODS 的平均表现为 34.1%/54.4%,在多项难图如 AIME24 上均落后于 D3S 的 20.3%/48.2%。这实证印证了理论部分中“最大化优势方差优于最大化奖励方差”的结论。
6.2 对通用基础模型的显著改进
对于未在数学领域进行过深度预对齐的 Llama3.1-8B-Instruct,传统的 GRPO 似乎在探索数学推理空间时遇到了困难。原版 GRPO 的平均 Pass@1 仅为 20.5%,在难度极高的 AIME25 上甚至得分为 0.0/0.0。
然而,当引入 D3S 机制后,GRPO+D3S 的平均 Pass@1 提升至 23.8%,Pass@8 提升至 40.2%。这表明,D3S 中对关键不确定性词元的关注以及跨组的优质样本筛选,赋予了通用模型更强效的局部爬山能力,帮助其跳出低质量梯度的泥沼。
6.3 与新型算法的高兼容性
GSPO 是在序列级重要性采样上做出改进的先进方法,自身已经具备较强的基线实力(在 Qwen 7B 上平均达到了 33.2%/54.7%)。即便如此,引入 D3S 后(GSPO+D3S),性能依然稳定增长至 35.8%/56.2%,并在最高难度的 AIME 基准上进一步拔高了上限。这充分说明 D3S 并非修补某种特定算法漏洞的补丁,而是一套可以无缝插拔、放大各类组相对强化学习算法收益的通用数据效用优化组件。
6.4 在有限参数模型上的可扩展性
在较小规模的 Qwen2.5-Math-1.5B 模型上,D3S 同样实现了最优的平均表现。GRPO+D3S 的得分为 33.1%/51.8%,优于原版 GRPO 的 32.0%/50.2%。这也暗示了在小模型因容量有限而对噪声数据更为敏感的情况下,剔除无关信息带来的纯净梯度信号依然具有正向增益。
7. 深入解析与消融实验
为了剥丝抽茧,详细了解 D3S 各个子模块在训练过程中的具体作用机制,作者进行了一系列消融实验与训练动态(Training Dynamics)监控。
7.1 模块贡献消融分析
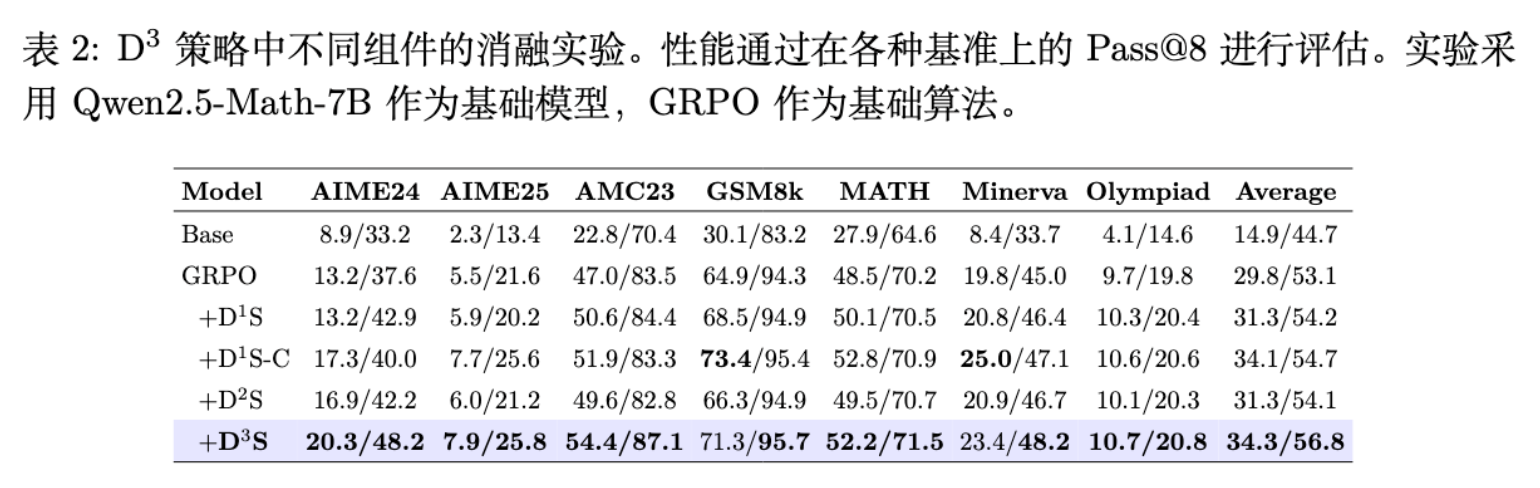
-
基础模型 -> GRPO:Pass@8 均分从 44.7 提升至 53.1。 -
+D1S (单组内样本下采样) :提升至 54.2。这说明摒弃无梯度样本已经能够带来收益。 -
+D1S-C (跨组样本下采样) :进一步提升至 54.7。这反映了在整个批次内寻找方差最大化样本能够更有效地避开同质化的无效探索。 -
+D2S (添加固定比例的词元级下采样) :得分为 54.1,相较 D1S-C 出现了些许回落,且在某些难集(如 AIME24)上表现出不稳定性。这正是因为固定的下采样机制在训练后期会引发过拟合,模型过于执着于极个别的标记和样本,失去了对整体分布的适应能力。 -
+D3S (完整配置带动态调度) :均分跃升至 56.8,不仅克服了 D2S 的不稳定性,还在所有基准上创下最佳。这证明了课程学习式动态放宽约束的设计是兼顾“快速收敛”与“稳健泛化”的唯一通道。
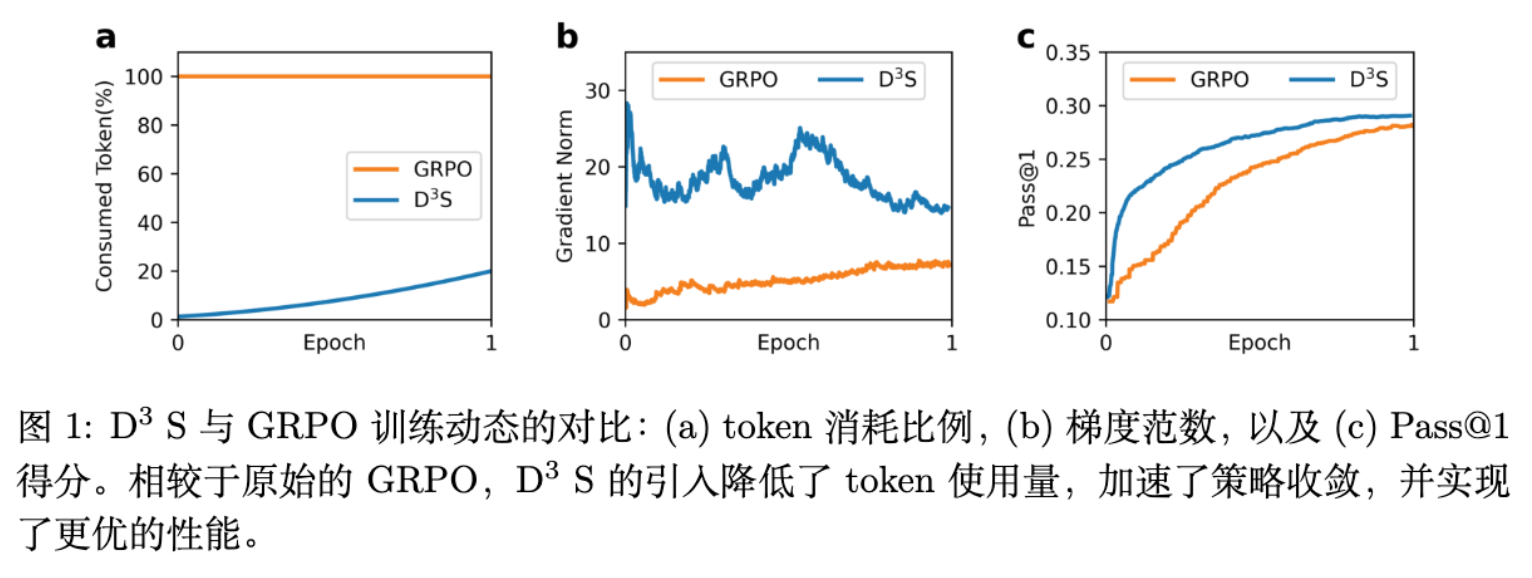
7.2 训练效率与资源节约
D3S 被命名为 "Learning More with Less"(用更少学更多),其核心亮点体现在训练时间与资源的高效利用上。

7.3 动态调度对抗过拟合的具体机制
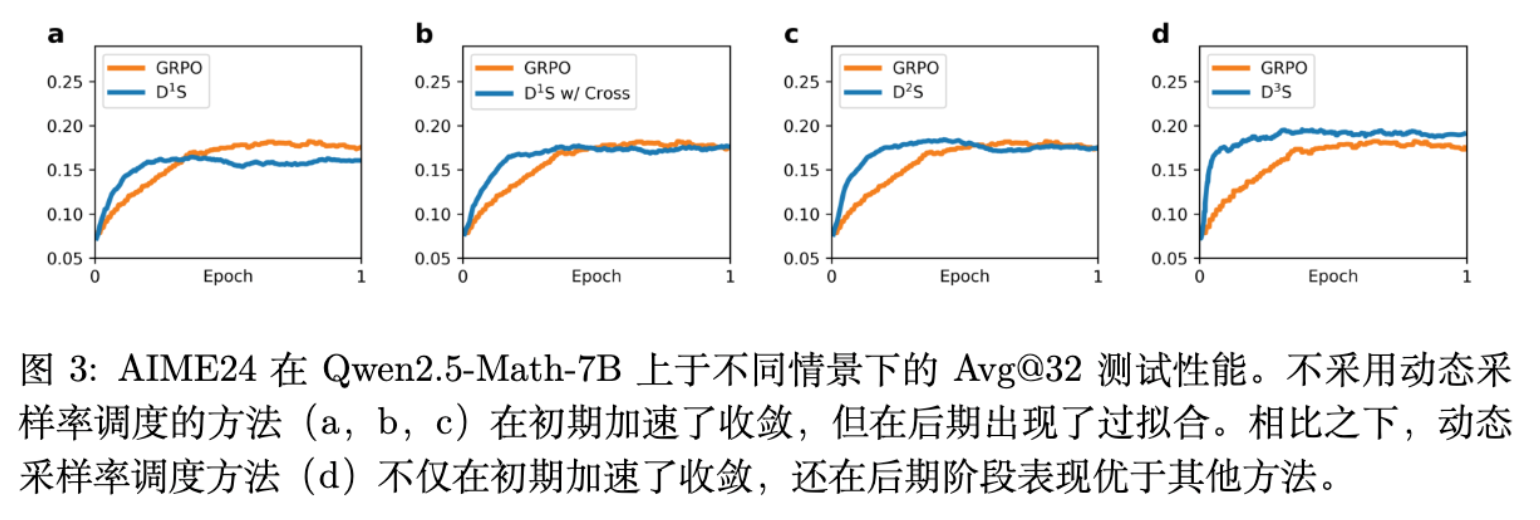
通过追踪训练过程中的监控指标,可以更直观地理解动态下采样是如何防止模型崩溃的。
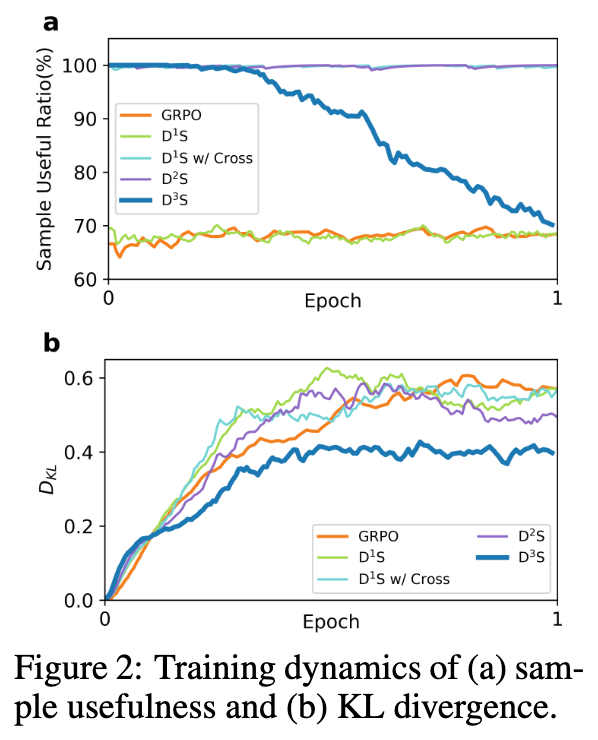
-
样本有用率(SUR, Sample Usefulness Rate):衡量每个批次中具有非零优势的组的比例。
在图 2 中,普通的 GRPO 和不带跨组机制的 D1S,其 SUR 指标大约在 70% 左右波动。一旦引入跨组操作(D1S-C 和 D2S),前期的 SUR 会瞬间飙升至接近 100%。这意味着系统有效地排除了同质化的无效组。然而,对于完整的 D3S 来说,随着训练的推进( 的增大),算法主动放宽选择条件,导致 SUR 逐渐从 100% 滑落到 70% 的水平。 -
KL散度(KL Divergence, ):反映策略模型相对于初始参考模型的偏移程度。
在未采用动态调度的 D1S 和 D2S 曲线中, 在早期迅速攀升,表现出极强的优化冲动,但也更快地触及了惩罚边界。而带有动态调度的 D3S 曲线,其 增长更加温和、受控,最终的偏离度也小于其他强下采样方法。 -
测试集表现演变:图 3 显示,没有动态调度的下采样方法(D1S, D2S)在早期能迅速攀升并超越 GRPO,但随后曲线变得平缓甚至出现掉头向下的衰退现象(标准的过拟合特征)。而引入调度方案的 D3S 则在整个训练周期内保持了坚挺的上升通道,在后期彻底拉开了与其他方法的差距。
7.4 熵的动态演化分析
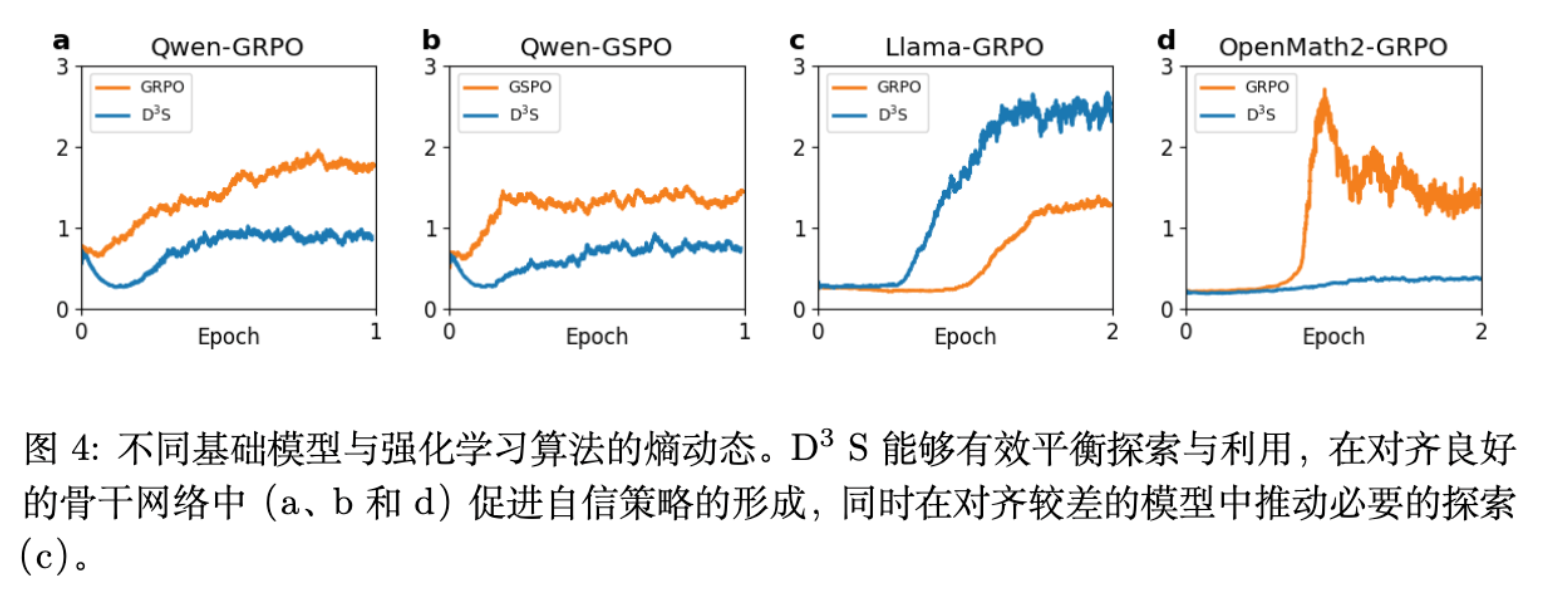
词元级下采样的依据是策略熵(Policy Entropy)。图 4 呈现了 D3S 对模型内在信心的调优能力。
在使用 Qwen 等对齐程度较高的模型时,标准 GRPO 的整体熵处于一个较高位且充满波动的状态。而 D3S 通过将 的乘积作为加权条件,强迫模型在那些“具有重大结果影响、但模型自身又犹豫不决”的词元上进行坚决更新。因此,我们观察到 D3S 的策略熵曲线不仅始终处于较低水平,而且走势非常平滑。这种低均值的策略熵意味着模型学会了更加果断、自信的推理行为,摒弃了模糊的试探。
7.5 特别分析:基于未对齐 Llama 模型上的跨组副作用
研究中还暴露了一个值得注意的异常现象。当在通用基础模型 Llama3.1-8B-Instruct 上进行操作时,如果在其上使用跨组下采样(Cross-group),反而会造成模型性能下降。在该模型上,仅使用组内下采样加动态调度(即 D3S-I 变体,去掉了跨组机制)的平均表现达到了 24.0/40.2,反而高于完整 D3S 的 23.8/40.2。
作者在附录 D.1 中通过深入分析解释了这一差异。对于缺乏特定领域预对齐的 Llama 模型,其在面对不同难度的数学提示时,输出质量表现出极其巨大的异质性(Heterogeneity)。如果强行采用跨组全局采样(D3S 的深蓝色曲线),会将学习信号过度集中在全批次中极个别的几个离群样本(Outliers)上。这种极端聚焦导致了策略梯度出现了剧烈的不稳定震荡,并且导致 急剧飙升,打断了正常的优化节奏。
而在 D3S-I(取消跨组采样,只在同一个 prompt 生成的回复中挑出好坏样本)的干预下,每个提示都保留了局部区域内的有效对比,从而提供了更温和、局部的稳定更新信号,帮助未对齐模型稳健地完成知识迁跃。当使用领域对齐过的 OpenMath2-Llama3.1-8B 时,组间质量差异变小,跨组操作的风险随之消除,完整的 D3S 便再次恢复了竞争力。这为实际部署此类框架提供了重要的指导意义:采样策略的最优结构应视初始模型的基准对齐水平进行适应性微调。
8. 相关工作回顾与拓展
论文对旨在提升大模型 RL 训练效率与信用分配的现有技术进行了系统的梳理和对比。
旨在提升训练效率的数据筛选策略:
随着模型与训练集的不断扩大,如何提取具有高信息增益的训练样本成为痛点。Razin 等人(2024; 2025)最先提出增大奖励信号方差能使优化地形更陡峭的理论。Lu 等人(2024)的 SEAM 指标通过衡量策略模型与奖励模型判断差异来过滤样本。Gou & Nguyen 开发了 MPO(混合偏好优化)技术,主张分阶段在不同奖励差距的成对数据上训练。Pattnaik 等人的 Curry-DPO 则完全基于难度排布偏好对进行课程学习。Chen 等人的 LPPO 动态调整边缘样本的权重。相较于这些主要在数据集层面或经验层面设计权重或过滤规则的方法,D3S 是首个通过严格理论推导(从梯度范数上界的数学角度)确立起“优势方差最大化(而非奖励方差最大化)”优越性的框架,具有更强的泛用性和可解释性。
在词元级运用熵控制的方法:
在长序列推理中,不同词元对结果的贡献千差万别。Cui 等人(2025)用实证数据证明了性能提升、策略熵下降与探索能力损耗之间的深层关联。Wang 等人观察到前 20% 高熵词元对策略梯度的压倒性主导作用。基于此,Cui 进一步提出了 Clip-Cov 和 KL-Cov 等方法,试图通过裁剪行动概率与优势值协方差过高的更新来止损熵的流失。Wen 等人的 ETPO 则致力于重构奖励分配机制。Shen 提出的 AEnt 在被截断的高置信度词元上计算自适应熵系数。与上述将被动控制熵作为防退化手段的思路不同,D3S 采取了更为主动出击的资源再分配理念:它直接将熵和优势结合作为筛选杠杆,将最为宝贵的反向传播计算完全聚焦于具备“高影响、高存疑”属性的词元集合。这种聚焦,相当于给策略模型装上了一个能够自动追踪自身逻辑漏洞并精准缝合的反馈调节器。
9. 总结
该研究最重要的理论贡献在于,揭示了在应用类似于 GRPO 的基于组相对优势的训练算法中,策略梯度范数的理论上界其实与“优势方差(Advantage Variance)”存在着严密的数学正相关关系,而传统的追求奖励方差在组内标准化面前是无效的。
作者提出了一套行之有效的工程框架 D3S。它通过在全批次中执行跨组下采样,最大化了所选样本的梯度牵引力;通过融合熵值分析锁定了高价值的关键词元进行定点更新;更进一步利用动态的课程学习时间表机制抑制了算法后期追求极高方差带来的过拟合。
更多细节请阅读原文。
往期文章:


