让每一项优秀工作,被更多人看见:点击进入投稿通道

-
论文标题:BandPO: Bridging Trust Regions and Ratio Clipping via Probability-Aware Bounds for LLM Reinforcement Learning -
论文链接:https://arxiv.org/pdf/2603.04918
TL;DR
今天解读一篇来自 OpenMOSS 团队的一篇论文《BandPO: Bridging Trust Regions and Ratio Clipping via Probability-Aware Bounds for LLM Reinforcement Learning》。大语言模型(LLM)的强化学习(RL)通常采用近端策略优化(PPO)及其变体(如GRPO)中的概率比值裁剪机制来保证训练稳定性。然而,该论文指出,固定边界的裁剪机制会对低概率动作施加严格的向上更新限制,导致尾部策略的探索受到抑制,引发策略熵过早崩塌。为此,作者提出了Band约束策略优化(BandPO)算法,引入Band算子,将基于 -散度定义的信赖域投影为动态的、概率感知的裁剪区间。该问题被建模为凸优化问题,并提供了针对KL散度的数值求解方法以及部分散度的闭式解。实验表明,BandPO在多个数学推理基准测试中提升了模型的性能,并缓解了熵崩塌现象。
1. 引言
在大语言模型的后训练阶段,基于人类反馈的强化学习(RLHF)以及近期发展的基于可验证奖励的强化学习(RLVR)成为了对齐模型与复杂指令的核心手段。在这些范式中,策略梯度的优化需要引入近端约束(Proximal Constraints),以在优化稳定性与有效探索之间取得平衡。
1.1 从信赖域到比值裁剪
在策略梯度方法的演进中,Schulman等人最初提出了信赖域策略优化(TRPO)。TRPO通过计算Fisher信息矩阵并采用共轭梯度法,在每一更新步中确保新策略分布与旧策略分布之间的KL散度不超过给定的阈值 。其优化目标可以表示为带约束的优化问题:
由于计算高维连续状态或海量参数模型的Fisher信息矩阵成本过高,Schulman等人后续提出了PPO算法。PPO采用了一种计算上更为高效的替代方案,即比值裁剪(Ratio Clipping)。它将新旧策略的概率比值 限制在一个固定的区间 内。通过裁剪操作,PPO避免了显式求解复杂的带约束优化问题。该机制由于其简单性和经验上的有效性,已成为目前LLM强化学习的默认配置。
1.2 GRPO算法中的裁剪机制
近期,为了进一步降低批评者模型(Critic Model)带来的显存和计算开销,Shao等人提出了GRPO(Group Relative Policy Optimization)。GRPO继承了PPO的比值裁剪机制,但通过对同一提示词采样一组回复,并在组内标准化奖励来估计优势函数,从而省去了Critic模型。
假设给定来自数据集 的提示词 ,模型生成一组大小为 的回复 。GRPO的优化目标 为每个输出词元(token)目标的聚合:
其中,对于每个特定的词元,其带有不对称边界的替代目标函数 定义为:
这里, 是概率比值, 是通过组内标准化计算得到的优势估计, 是用于保持语言连贯性的正则化惩罚项。PPO通常使用对称边界(),而这里的表达形式对其进行了泛化。
2. 传统裁剪机制的理论瓶颈
尽管经典裁剪机制在模拟信赖域更新方面提供了稳定性,但已有研究(如DAPO的Clip-Higher策略)指出,它会对策略熵施加负面偏置,从而抑制探索。论文在这一部分详细且形式化地分析了传统裁剪机制中存在的结构性瓶颈。
2.1 固定边界导致的线性依赖
经典裁剪机制将概率比值 限制在固定的常量区间 内。将其表示为不等式:
定义在状态 下采取动作 的概率变化量为 。我们将上述不等式的各项同时乘以严格大于0的 ,并减去 ,可以得到允许的概率变化量集合 :
从理论上讲,由于新策略概率 必须位于概率单纯形 内(即所有动作概率之和为1,且每个概率在0到1之间),概率变化的理论极限范围是从 (降至0)到 (升至1)。定义该最大可行集合为 :
利用关系 ,我们可以将单纯形约束映射回比值空间,得到 的理论上下限:
2.2 瓶颈剖析:低概率动作的探索瘫痪
通过对比 和 ,论文揭示了一个核心矛盾:固定比值裁剪所允许的概率变化量 严格线性依赖于旧策略概率 。
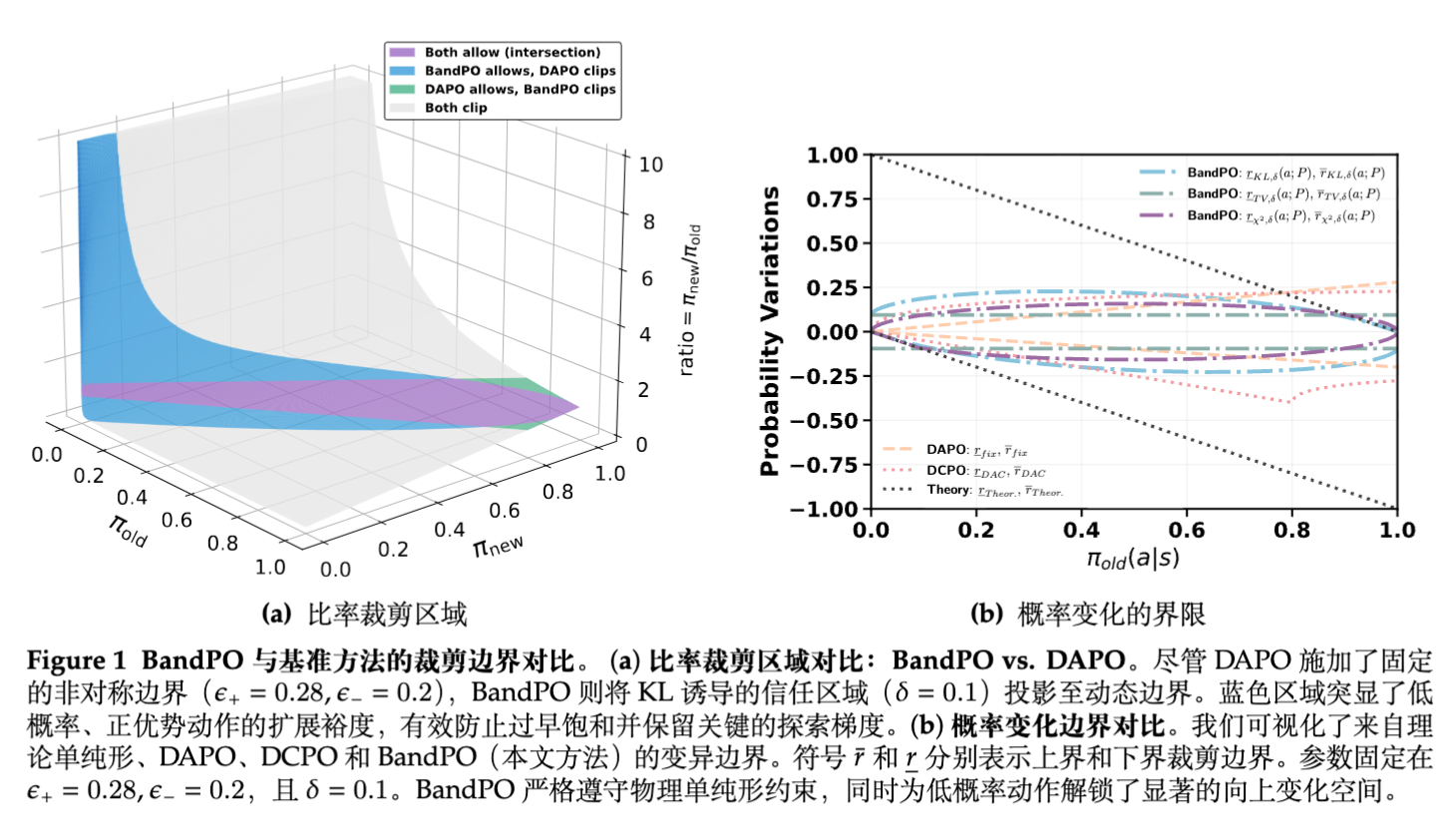
在具有正优势(需要提高概率)的动作中,如果该动作当前的概率很低(即尾部策略),其允许的向上增长空间 将趋于0。这与理论上限 形成了鲜明矛盾。
数值案例说明:
假设存在一个尾部词元,其当前概率 ,系统设定裁剪上界 。
在该设定下,允许的最大概率增长量为 。相比于其理论上可以增长的空间 ,这一变化幅度可忽略不计。
如果试图通过增大 来提供实质性的探索空间(例如希望允许 ),则需要将 提升至 左右。然而,将全局裁剪上界设置为 会导致高概率动作的约束完全失效。例如,对于一个头部词元 ,设定 将允许 ,这显然超越了其剩余可增长的物理极限 ,使该约束失去了意义。
这种矛盾导致了传统静态裁剪无法同时满足高概率动作的稳定优化与低概率优势动作的有效探索。由于低概率且高优势的动作在梯度更新中过早触发裁剪,其梯度信号变为0,模型无法通过这些动作探索新的策略。这种对探索的抑制加剧了模型的概率分布向头部集中,引发熵崩塌(Entropy Collapse)。
3. 相关工作对比
在解决LLM强化学习中的裁剪问题上,近期有一些启发式改进工作。
Clip-Higher (DAPO): DAPO提出了解耦裁剪边界,并单独放宽上界。它尝试缓解上述的熵崩塌问题,但由于其放宽缺乏理论指导,且上界对于所有概率值是固定的,因此不仅在低概率处仍受线性依赖约束,且在饱和后容易导致性能崩溃。
DCPO (Dynamic Clipping Policy Optimization): DCPO通过不等式放宽,推导了动态裁剪边界函数。它的边界随动作概率动态调整,在低概率处允许更大的比值。然而,DCPO的边界在部分高概率区域超出了概率单纯形的物理上限,缺乏严格的几何一致性。
这些启发式的方法表明了动态调整边界的必要性,但也凸显了当前方法缺乏能够通过单一、可解释参数控制裁剪边界的理论框架。
4. BandPO方法论与理论分析
为了解决上述问题,论文提出了BandPO(Band-constrained Policy Optimization)。BandPO的核心在于Band算子,该算子将通用的基于 -散度引导的信赖域,精确投影为各个动作概率比值的动态标量区间。
4.1 -散度引导的信赖域
设定固定状态 。令 和 分别表示旧策略和新策略在词汇表 上的概率分布。
使用 -散度家族来形式化信赖域。令 为严格凸函数,且满足 。从分布 到 的 -散度定义为:
以 为锚点,半径为 的信赖域 构成概率单纯形 上的一个凸集:
这是一个具有泛化性的几何表达。例如,当选择生成函数 时,即可恢复TRPO中采用的前向KL散度约束 。
4.2 Band算子的优化问题建模
为了推导由几何约束 引起的目标动作比值边界,我们将候选分布 视为变量。对于任何满足 的词元 ,定义比值函数为:
最优动态边界:概率比值的上限可以通过在约束 下最大化目标动作的概率 来确定。这构成了一个凸优化问题:
对称地,可容许的最小概率比值通过求解最小化问题得出:
因为约束集是凸集且目标函数是线性的,这两个问题都是标准凸规划问题,局部最优即全局最优。Band算子定义为将比值严格限制在由上述问题求解所得的上下限内的裁剪操作:
与传统固定边界 不同,Band生成的是概率感知的边界,仅由单一、可解释的信赖域半径 控制。
4.3 降维优化:均匀补集重缩放引理(Lemma 1)
直接在包含数万个词汇的高维单纯形()上进行凸优化计算代价不可接受。论文通过挖掘散度约束的结构对称性,证明了该高维问题可严格降维为单变量方程。
Lemma 1(均匀补集重缩放的最优性):给定参考分布 (全支撑,即对于所有词元概率非零),动作 ,上述极限优化问题的最优解 必须严格保持补集 内的相对概率比例。也就是说,对于所有非目标动作,概率比值是一个常数:
缩放因子 唯一地由单纯形归一化约束 确定。
推导过程:
为了最大化(或最小化)目标动作 的概率 ,剩余概率质量 必须以使得其余动作产生的散度贡献最小化的方式分配给补集 。该子问题为:
由于目标函数是严格凸函数 的和,变量 的出现具有对称性。根据严格凸性(Jensen不等式),如果不同非目标动作的比值不同,我们总可以将其拉平(求均值)以获得更小的散度。因此全局极小值必须满足似然比恒定条件。代入约束,设 :
由于 ,我们得到 。这就将原来 中数万个变量全部映射为单个变量 。
4.4 标量化与求根问题转化(Theorem 1)
基于 Lemma 1,将 代回散度公式,高维散度约束坍缩为一个只关于目标动作比值 的单变量函数 :
Theorem 1(信赖域约束的精确标量化):假设生成函数 严格凸且 。对于 ,前面的优化问题等价于求标量函数 的根:
服从可行性约束 。 具有几个重要性质:
-
它对于 是严格凸的(二阶导数恒大于0)。 -
在 处达到全局最小值 0。
因此,对于任何有效的半径 ,方程 恰好具有两个唯一根,分别对应:
5. Band边界函数的理论性质
论文推导了基于上述方程求出的边界具有什么样的数学和物理性质,以此证明 Band 算子从根本上解决了传统裁剪中的探索瓶颈。
5.1 边界的渐近行为(Proposition 1)
当概率 接近单纯形边界(0和1)时,边界函数的极限表现如下:
数学与直觉解释:
对于尾部动作(),上限 趋于正无穷大。回想传统裁剪中,上限被死死限制在 ,这正是阻碍探索的原因。BandPO允许低概率动作的比值在理论容许范围内极大扩展,这就彻底打通了低概率正优势动作的上升通道。
对于头部动作(),由于概率之和不能超过1,当该动作本身概率趋近于1时,它能增长的空间(比值大于1)被物理单纯形边界挤压,因此上限必然收敛到1。BandPO在形式上完全自洽地遵守了这一几何要求,而DCPO等启发式方法在 较大时常会给出超出理论极限的值。
5.2 边界的严格单调性(Proposition 2)
给定了 ,上界 随概率 严格递减,下界 随概率 严格递增。
证明思路(隐函数求导):
设 。根据隐函数定理:
经过偏导数计算,论文引入了Bregman散度,证明了 始终为正。对于上界(),,故 ,严格递减。对于下界(),,故 ,严格递增。
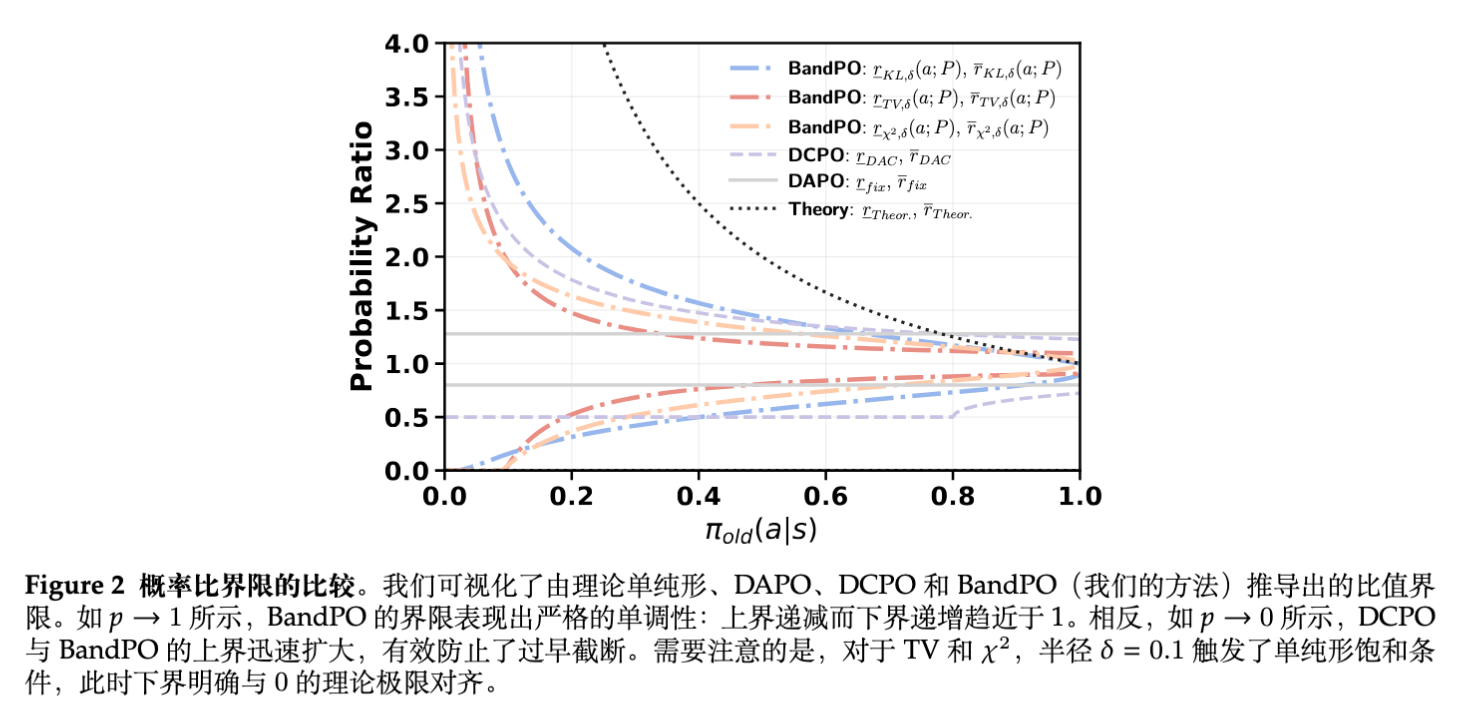
由于具备严格的单调性,Band边界天然地形成了一个类似喇叭口的形状。在低概率区域,区间张开口度最大;在概率趋于1时,区间收缩。
5.3 单纯形饱和现象(Proposition 3)
在实际求解时,如果 给得过大,由散度定义的信赖域可能部分溢出了概率单纯形 的边界(即比值上限超过了 或者下限小于 0)。为了保证解在物理空间内合法,论文定义了“单纯形饱和”条件。
记单纯形边界为 和 。如果 ,这意味着即使将该动作的概率拉满到1,仍然在信赖域的容量内。此时上界饱和,直接返回 。同理,若 ,则下界饱和返回0。
6. 求解Band边界:解析解与数值解
尽管方程被降维至标量 ,但由于 函数的具体形式不同,能否求得显式的闭式解(Closed-form solution)也不尽相同。
6.1 部分散度的闭式解(Proposition 4)
论文为总变差(Total Variation, TV)和Pearson 散度提供了精确的闭式解。这在实际部署时计算效率极高。
全变差(TV)的推导:
令 。代入 :
将第二项化简:。代回方程得到:
解方程 ,即可得到上限和下限(且与概率成反比):
Pearson 的推导:
令 。类似地进行代数化简,方程最终化简为:
求解得到与几率(odds)平方根成反比的边界:
在应用时,还需配合公式结合单纯形边界进行钳制(Clamping)。
6.2 基于二分法的全局收敛数值求解器
对于像前向KL散度(TRPO标准指标)这样由 生成的散度,代入后构成了包含对数项的超越方程:
由于该方程无初等解析解,必须依赖数值求解。论文在定理2中证明了,在有效区间内,函数严格单调。因此可以采用标准的二分查找法(Bisection)或者Brent方法进行求根,且具备线性全局收敛保证。
7. BandPO算法实现
基于上述计算出的动态边界,BandPO框架对现有的GRPO目标函数进行了替换。使用 Band 算子替代经典的 clip 操作,其单词元替代目标函数 为:
通过投影出的特定于目标动作的概率感知标量区间,Band 算子能够严密地将比值控制在理论上可行的域内。
计算实现逻辑概括(伪代码形式):
def compute_band_bounds_kl(p, delta, epsilon_tol=1e-6):
# p is the probability of the chosen action
# Implement parallel bisection for KL divergence
r_max_limit = 1.0 / p
# Upper bound bisection
L, R = 1.0, r_max_limit
while (R - L) > epsilon_tol:
m = (L + R) / 2.0
if g_kl(p, m) <= delta:
L = m
else:
R = m
upper_bound = L
# Lower bound bisection
L, R = 0.0, 1.0
while (R - L) > epsilon_tol:
m = (L + R) / 2.0
if g_kl(p, m) <= delta:
R = m
else:
L = m
lower_bound = R
return lower_bound, upper_bound
在实际的张量计算框架(如 PyTorch / Triton)中,可利用CUDA实现并行的二分查找以提升效率,消除显式循环带来的开销。
8. 实验设计与结果分析
为了验证提出方法的有效性,论文在多个具有挑战性的数学推理基准上进行了详尽的实验。
8.1 实验设置
模型基座:Qwen2.5-3B-Instruct,以及DeepSeek-R1-Distill系列的1.5B、7B、Llama-8B等多个维度的模型。
数据集:DAPO合并数据集以及MATH Levels 3-5进行微调训练。
评测基准:评估指标分为 pass@32(反映理论能力峰值的多发成功率)和 mean@32(反映策略鲁棒性的平均准确率),评测任务包括 AMC2023、AIME2024、AIME2025。
对比基线:
-
GRPO: 传统对称裁剪机制(通常 )。 -
GRPO w/ Clip-Higher: 采用不对称启发式裁剪,作为当前最优的基线( 或其他设定)。 -
GRPO w/ BandPO(本文方法):采用Band算子并固定信赖域参数 。
8.2 主实验结果与剖析
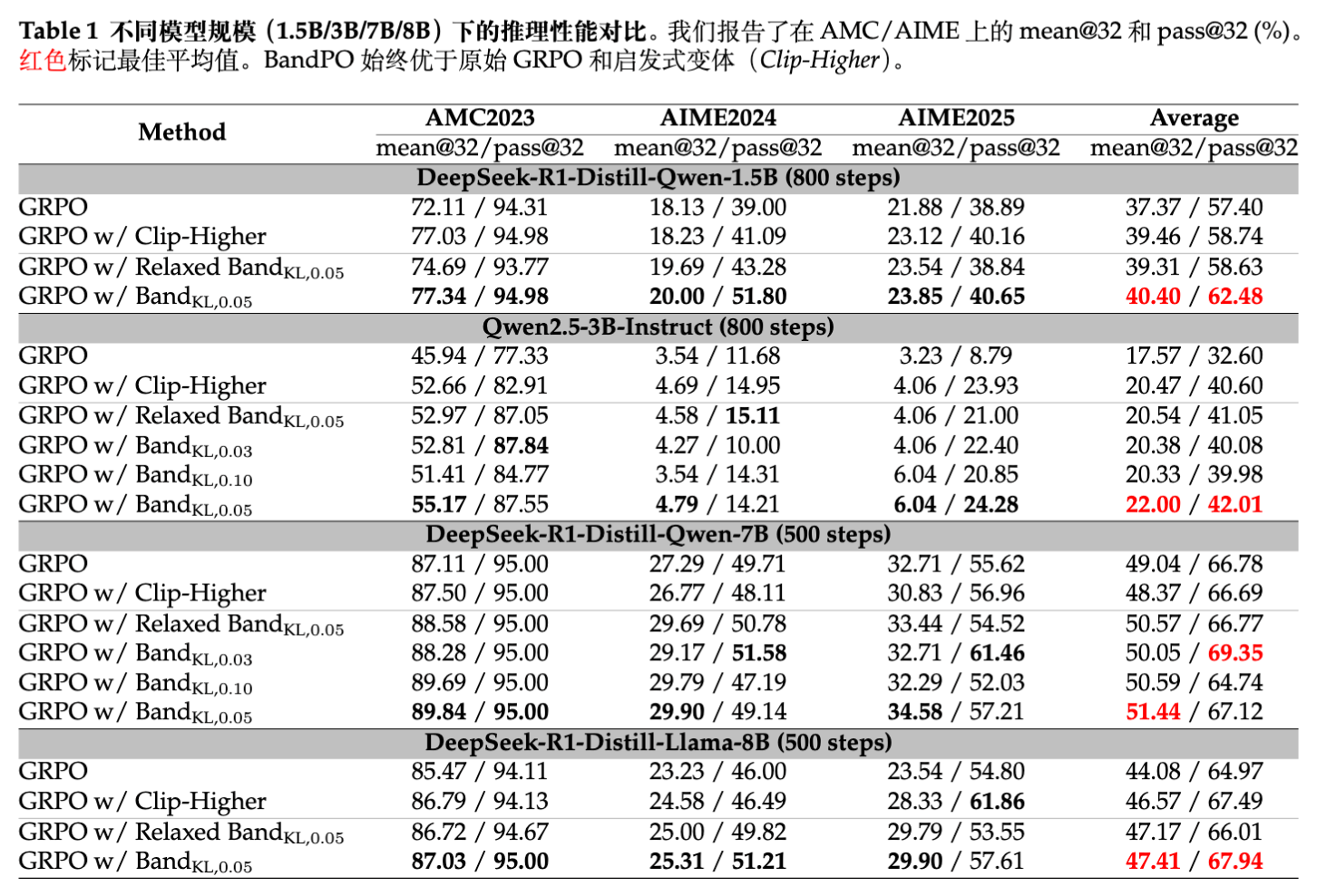
从表1可知,BandPO在多个模型与数据集组合下,在 mean@32 核心指标上实现了一致的性能提升。
以Qwen2.5-3B为例,在AMC2023任务中,原版GRPO平均分为45.94,而BandPO将其提升至55.17(提升接近10个点)。不仅如此,BandPO在应对部分基线出现的剧烈训练震荡现象时表现出了较强的鲁棒性。例如在1.5B级别的实验中,原版GRPO容易在训练的第340步附近遭遇严重的性能崩塌,而BandPO凭借严密的几何下限和宽裕的尾部上限支撑,免于此难。
性能增益的来源:
传统PPO通过限制策略改变幅度来维稳,但在低概率(即模型起初不倾向于使用,但验证给出了高奖励的高级推理逻辑)区域锁死了上升空间。BandPO解除这一封锁后,模型能迅速吸收这些稀疏但高价值的长链推理策略,反映在 pass@32 上的提升尤为明显(3B模型上存在相对28.9%的增益)。
8.3 放宽 Band 边界的消融实验
观察图1a可知,BandPO在低概率区允许极大的放宽,但在高概率区(),基于散度几何算出的理论边界比固定边界(如DAPO的 )还要严格。
为了探究“是否直接把Band的高概率边界放宽至Clip-Higher的程度会更好”,作者评估了带有松弛机制的 Band (Relaxed Band)。
实验表明,引入松弛会导致整体性能一致性下降。在7B和8B模型上 mean@32 下降了约0.5,而在1.5B模型上 AIME2024 pass@32 甚至跌去了接近8个点。这说明,高概率区域的收紧不是副作用,而是维持策略稳态必须的“几何配重”。任何偏离严格理论推导的启发式修改都会破坏散度的闭环,带来负面影响。
8.4 超参数 的敏感性
传统裁剪通过经验搜索确定 。BandPO统一为一个物理参数 。
论文在Qwen2.5-3B和7B上对 进行了敏感度测试。结果表明 稳定占据最优解。有趣的是,3B模型对 表现出更强的敏感度:在非最优参数下性能下降幅度超过10%;而7B模型的性能波动局限在2-3%以内。这反映出较小规模的参数空间更需要精准的信赖域管控来避免策略崩溃,大规模模型对粗糙更新具有更强的容忍度。
8.5 训练动态剖析:打破探索瓶颈的实证
为了直观证明定理成立,作者抽取了训练过程中的几个特征指标随迭代步数演变的数据。
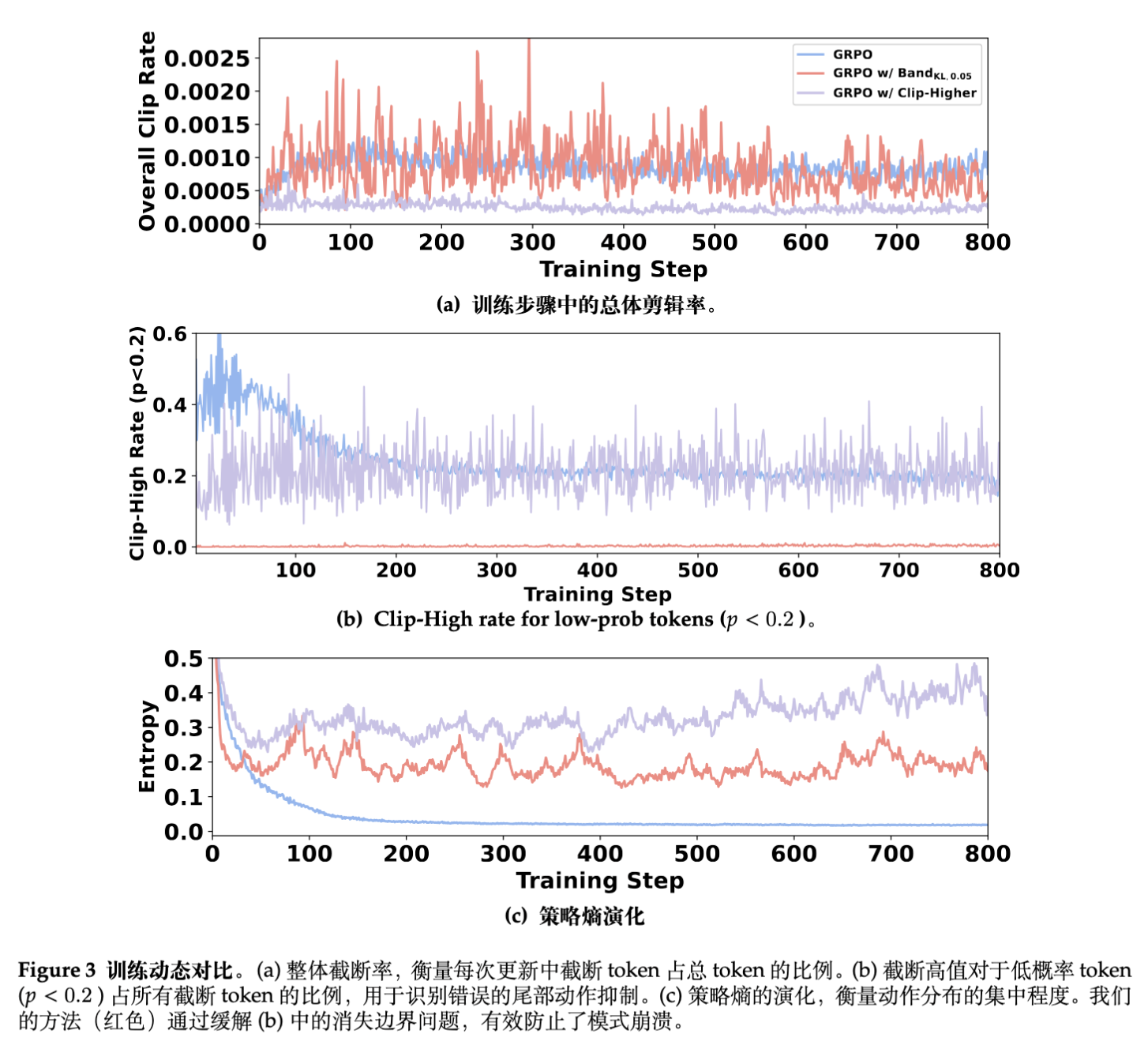
-
整体裁剪率(Overall clip rate):所有设定下触发裁剪的词元占总词元的比例。BandPO 的整体裁剪率和原版 GRPO 相当,且显著高于 Clip-Higher 设定的较低裁剪率。这说明 BandPO 在整体上并没有减少约束总量,依然在约束大部分常规动作。 -
尾部高概率裁剪率(Clip-High rate for low-prob tokens ):专门统计那些初始概率极低但被截断阻碍上涨的词元比例。原版 GRPO 和 Clip-Higher 在训练早期(前50步)竟然有高达60%的低概率优势词元被粗暴截断。在 BandPO 训练下,这条曲线几乎贴在0线上。这意味着 BandPO 定点清除了针对尾部优质动作的错误压制。 -
策略熵演化(Entropy evolution):熵衡量了模型分布的多样性。在传统 GRPO 下,由于尾部探索被截断,分布迅速向前排塌缩,导致熵值跳水(熵崩塌)。引入 BandPO 后,熵的曲线能够维持在一个数量级更高的健康水平(约0.2对比0.02)。
通过这一连串观测得出结论:BandPO 成功的关键并非盲目降低裁剪的总量,而是进行了科学的预算重分配。它在高概率节点上拧紧螺丝防范崩溃,而在低概率节点上松开镣铐以激励创新推理。
9. 讨论与未来工作
9.1 计算开销及求解器优化
相比于只需要标量加减和大小判断的原版裁剪,BandPO 引入了必须对各词元分布进行的凸约束求根计算,这在计算复杂性上无疑是一种额外开销。
特别是 KL 散度这种必须迭代数值求解的场景,不可避免会产生延迟。论文讨论了相关的缓解策略:鉴于 Band 边界严格的单调性质和仅依赖概率 这单一标量的特性,完全可以离线预先计算出高精度的查找表(Lookup Table),将复杂的运行时期求根过程降级为 的内存访问,这为大规模部署铺平了道路。对于 TV 和 ,其存在的解析解更使其运算成本可以直接同传统标量操作对标。
9.2 全局静态信赖域的局限
目前框架中存在的一个假设是对整条序列、所有词元施加单一全局的信赖域半径 。这在语言生成任务中抹平了不同层级语义的信息量差异。在实际推理过程中,常规的句法连接词(如“因为”、“所以”)与核心推理步骤词元承载着完全不同的稳定性要求。统一的 在某种意义上是对这种差异性的妥协:可能对句法部分偏宽泛引发细微不稳定,对深层推理可能依然显保守。
9.3 迈向自适应Band算子
一个顺理成章的未来方向是将当前的静态 Band 进化为自适应的 Band。未来的研究可以探索利用词元级的度量指标(例如策略熵本身或语义不确定性度量)来动态调制信赖域半径 。对低熵的确定性过渡施加紧致的约束,而对高风险、高回报的跳跃推理步释放更大的活动边界,有望进一步解耦稳定性和探索深度之间的矛盾。
10. 结论
该论文直面了目前大模型强化对齐过程中一个被长期忽略的底层机制痛点——传统裁剪算法导致策略在尾部概率区探索能力的丧失。通过数学上严密的视角,论文定义了基于 -散度信赖域映射的 Band 算子,完成了一套理论闭环。它用单参数 替换了容易引发坍缩的启发式约束范围,不仅在数学上通过单变量映射、渐近分析及二分求解器保证了严格的一致性和可解性,且在从 1.5B 到 8B 的多个模型级别的实验中展现出显著缓解“熵崩塌”并提升数学推理能力的潜能。BandPO 无疑展现了在利用强化学习优化大模型复杂推理策略方向上,通过严谨几何约束替代静态启发式规则所具备的深刻价值。
更多细节请阅读原文。
往期文章:


