
-
论文标题:Ministral 3 -
论文链接:https://arxiv.org/pdf/2601.08584
TL;DR
Mistral AI 近期发布了 Ministral 3 的技术报告,今天我们来解读一下。Ministral 3 系列包含 3B、8B 和 14B 三种参数规模,均提供 Base(基座)、Instruct(指令微调)和 Reasoning(推理)三个版本。该系列模型并未从零开始预训练,而是采用了一种被称为“级联蒸馏”(Cascade Distillation)的策略,从 Mistral Small 3.1(24B)这一父模型通过迭代式的剪枝(Pruning)和蒸馏(Distillation)获得。
核心技术亮点包括:
-
级联蒸馏(Cascade Distillation):通过循环执行“剪枝-蒸馏”过程,依次生成 14B、8B 和 3B 模型,实现了计算与数据的高效利用。 -
多维剪枝策略:结合了层剪枝(基于输入输出范数比)、隐藏层维度剪枝(基于 PCA)和前馈网络维度剪枝(基于激活值重要性)。 -
推理能力增强:采用 SFT -> GRPO -> ODPO 的三阶段后训练流程,显著提升了小模型的复杂逻辑推理能力。 -
关于教师模型的实证发现:研究指出,在预训练阶段,并非教师模型越强越好(存在容量差距限制),但使用经过人类偏好对齐(Preference Tuned)的教师模型进行蒸馏,能显著提升学生模型的最终表现。
1. 引言
随着大语言模型(LLM)在各类应用中的普及,如何在计算资源受限和内存受限的端侧设备(Edge Devices)上部署高性能模型成为研究热点。传统的做法通常是针对特定参数规模(如 3B 或 8B)从零开始预训练(Training from Scratch),但这往往需要消耗巨大的算力和数万亿 token 的数据。
Ministral 3 的工作探索了一条不同的路径:从一个较强的父模型出发,通过结构化剪枝和知识蒸馏,向下衍生出一系列子模型。 与 Qwen 3 或 Llama 3 动辄使用 15T 至 36T token 进行训练不同,Ministral 3 利用 Mistral Small 3.1(24B)作为父模型,仅使用了 1T 至 3T 的 token 进行蒸馏训练,便获得了具有竞争力的性能。这种方法不仅降低了训练成本,还通过继承父模型的知识,缓解了小模型训练中的数据效率问题。
2. 模型架构与规格
Ministral 3 系列模型基于标准的 Transformer Decoder-only 架构,但在具体组件上结合了当前社区的主流优化实践。
2.1 核心参数配置
所有模型均使用 131K 大小的词表,并支持高达 256k 的上下文长度(Reasoning 版本为 128k)。具体的架构超参数如下表所示:
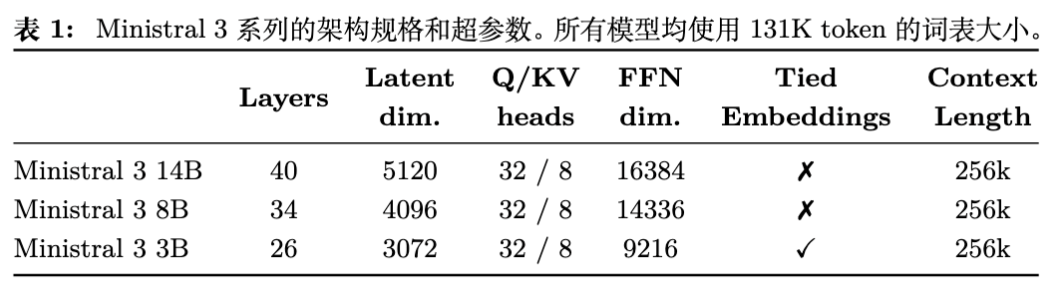
从架构细节来看,Ministral 3 采用了以下设计选择:
-
注意力机制:使用分组查询注意力(Grouped Query Attention, GQA),配置为 32 个 Query 头和 8 个 KV 头。这种设计在保证性能的同时显著降低了推理时的 KV Cache 显存占用。 -
位置编码:采用 RoPE(Rotary Positional Embeddings)。 -
激活函数:使用 SwiGLU。 -
归一化:采用 RMSNorm。 -
长上下文支持:使用 YaRN 方法和基于位置的 Softmax 温度缩放(Position-based softmax temperature scaling)来扩展上下文窗口。 -
Embedding 策略:3B 模型采用了输入输出 Embedding 权重绑定(Tied Embeddings),以减少参数量;而 8B 和 14B 模型则未绑定。这反映了在极小参数规模下,Embedding 参数占比过大,绑定权重是一种有效的参数压缩手段。
2.2 视觉编码器
Ministral 3 全系具备图像理解能力。其视觉部分直接复用了 Mistral Small 3.1 Base 中的 Vision Transformer (ViT),参数量为 410M。该 ViT 的架构与 Pixtral 12B 中的视觉编码器一致。
在实现上,ViT 的权重被冻结(Frozen),模型去除了原始的投影层(Projection Layer),并为每个特定规模的 Ministral 3 模型训练了一个新的投影层,将视觉特征映射到语言模型的特征空间。
3. 预训练方法论:级联蒸馏
Ministral 3 的核心贡献在于其训练配方(Recipe)。研究团队并未独立训练每个尺寸的模型,而是设计了一个迭代式的“剪枝-蒸馏”管道。
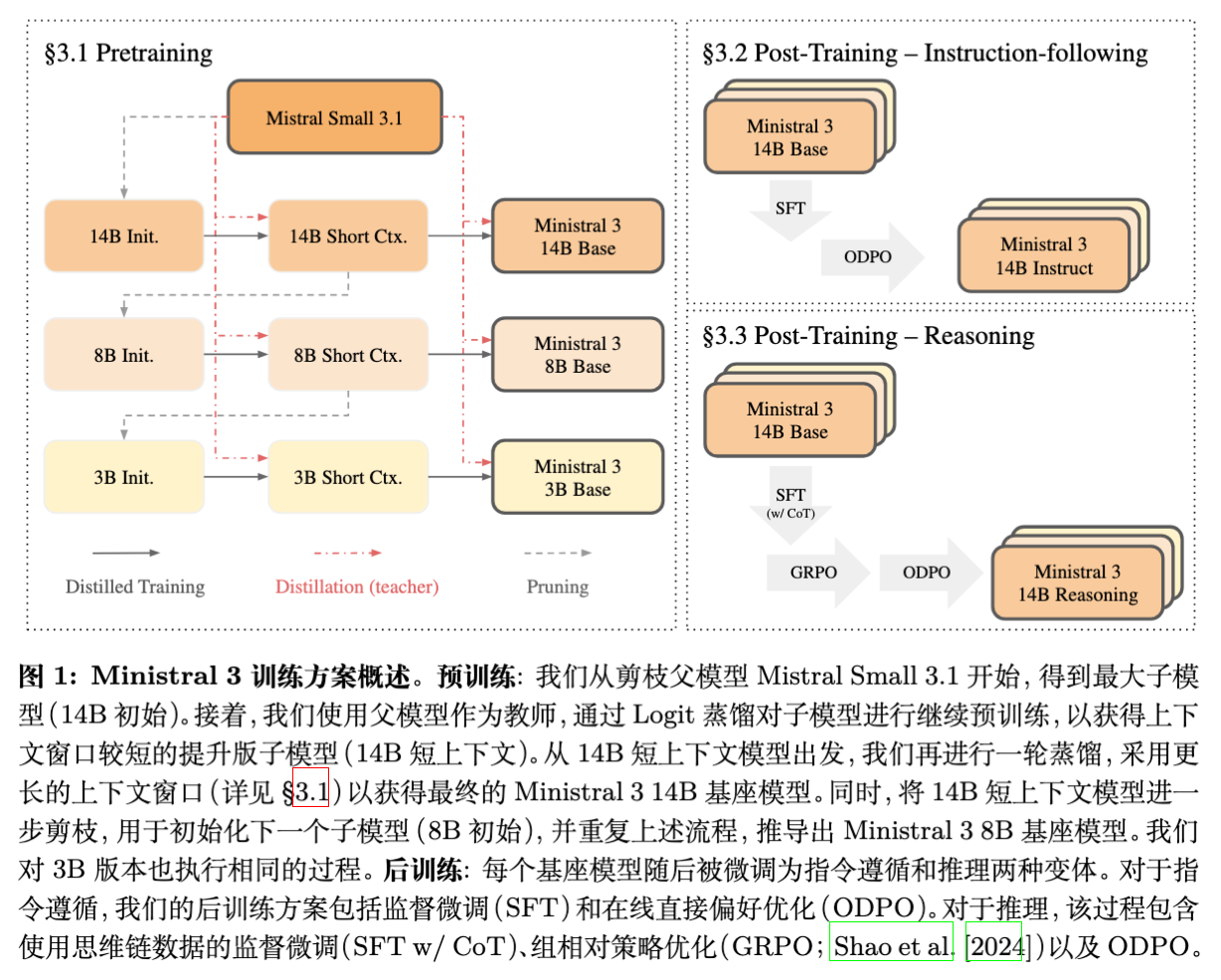
3.1 级联蒸馏算法流程
整个过程可以形式化为算法 1。初始输入为父模型 Mistral Small 3.1 Base (MS3.1)。
-
初始化:令 。 -
循环生成:对于目标尺寸 : -
剪枝(Prune):利用剪枝算法将 的参数缩减至目标尺寸 ,得到 。 -
短上下文蒸馏:在 基础上,使用 作为教师模型,在短上下文数据(16k)上进行蒸馏训练,得到 。 -
长上下文蒸馏:在 基础上,继续使用 作为教师,在长上下文数据上进行蒸馏,得到最终的 Base 模型 。 -
更新父模型:将当前阶段生成的短上下文模型 作为下一阶段的输入(即 ),用于生成更小尺寸的模型。
-
注意,对于 14B 模型,其父模型是 24B 的 MS3.1;对于 8B 模型,其父模型是训练好的 14B 短上下文模型;对于 3B 模型,其父模型是训练好的 8B 短上下文模型。这种链式继承确保了知识的逐级传递。
3.2 剪枝策略
Ministral 3 采用的剪枝方法并非简单的随机丢弃或基于梯度的复杂计算,而是基于激活统计量的结构化剪枝。这种方法类似于 Minitron 和 Wanda 等工作,但在具体指标上有所创新。
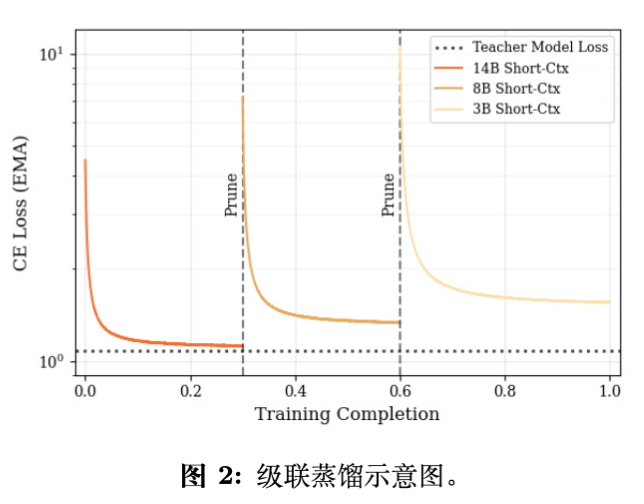
剪枝过程分为三个维度:层(Layers)、隐藏层维度(Hidden Dimension)和前馈网络维度(FFN Dimension)。
3.2.1 层剪枝
不同于某些工作依赖移除层后的困惑度(Perplexity)变化来评估层的重要性,Ministral 3 提出了一种更高效的代理指标:输入输出激活范数比。
对于第 层,其重要性得分 计算如下:
其中 和 分别是该层的输入和输出激活。逻辑在于,如果一层的输出范数相对于输入范数变化较小,说明该层对信号的变换贡献较低,可以被移除。根据得分保留 Top-k 层。
3.2.2 隐藏层维度剪枝
为了缩减隐藏层维度(Hidden Dim),模型对所有层中的 Attention Norm 和 FFN Norm 的输入激活进行拼接,并应用主成分分析(PCA)。
-
收集校准批次(Calibration Batch)的归一化输入。 -
计算 PCA 旋转矩阵 。 -
将该旋转矩阵应用于整个网络,将权重投影到解释方差最大的低维子空间中。 -
这保证了在整个网络中应用一致的旋转变换,保留了信息量最大的特征维度。
3.2.3 前馈网络维度剪枝
对于使用 SwiGLU 激活函数的 MLP,其计算形式为 。需要同时剪枝 的维度。
重要性分数定义为中间激活值的平均绝对值:
根据该分数保留 Top-k 的神经元,并相应地裁剪 的输出行和 的输入列。
3.3 蒸馏目标函数
在蒸馏阶段,学生模型在文本数据和图文交错数据上进行训练。损失函数仅包含前向 KL 散度(Forward KL Divergence),即利用教师模型的 Logits 进行蒸馏。
作者指出,仅使用 KL 散度损失优于混合使用 KL 散度和 Next Token Prediction(NTP)损失的方法。在所有阶段,教师模型始终是初始的 Mistral Small 3.1(24B),即使在训练 3B 模型时也是如此。
4. 指令微调
指令微调(Instruction Tuning)旨在赋予模型遵循指令的能力。该阶段包含监督微调(SFT)和在线直接偏好优化(Online DPO)。
4.1 监督微调 (SFT)
-
量化训练:使用 FP8 量化进行 SFT。 -
教师模型切换:与预训练不同,SFT 阶段的蒸馏教师模型升级为更强的 Mistral Medium 3。这是一个关键的策略转换,意味着在后训练阶段,模型容量差距(Capacity Gap)的影响减弱,更强的教师能带来更好的对齐效果。 -
视觉适配器:视觉编码器保持冻结,仅训练适配器(Adapter)。
4.2 在线直接偏好优化 (Online DPO)
Ministral 3 采用了 Online DPO (ODPO) 变体。
-
采样:对于每个样本,使用当前策略模型(温度 T=0.7)生成两个候选响应。 -
奖励模型:使用一个基于文本的成对奖励模型(Pairwise Reward Model, PWRM)对这两个响应进行排序。该 PWRM 本身是在结构化成对数据上训练的。 -
损失函数修正: -
利用 PWRM 输出的二项概率(Binomial Probability)来替换传统的硬标签(Winner/Loser),实现软标签训练。 -
应用 -rescaling 技术,使 DPO 损失对尺度更加不敏感。 -
启发式过滤:自动将出现无限循环的生成结果标记为“Loser”。
-
5. 推理微调
为了提升模型在数学、代码和复杂逻辑任务上的表现,Ministral 3 引入了专门的推理微调流程。这部分模型被称为 Ministral 3 Reasoning。
5.1 三阶段训练管道
推理模型的训练并非始于 SFT 后的 Instruct 模型,而是直接从 Base 模型的长上下文检查点开始,包含三个阶段:
-
推理 SFT (Reasoning SFT) :
-
数据混合:包含通用的 SFT 数据和带有长思维链(Long CoT)推理轨迹的数据。 -
CoT 数据处理:对推理轨迹进行清洗,移除格式错误、重复或语言切换不当的样本。
-
-
群体相对策略优化 (GRPO) :
-
采用 DeepSeek-AI 提出的 GRPO 算法。 -
阶段一(STEM RL):专注于数学、代码和视觉推理任务。利用编译器或规则检查器作为奖励信号。 -
阶段二(General RL):扩展到通用对话和指令遵循。利用 LLM 作为裁判(Judge)根据预定义的评分标准(Rubrics)对模型生成的输出进行打分,奖励值为满足标准的比例。 -
长上下文生成:在 RL 阶段,最大生成长度从 32k 增加到 80k,以允许模型进行充分的思考。
-
-
最终 ODPO:
-
在 GRPO 之后,再次应用 ODPO 以对齐人类偏好。 -
关键处理:在输入给奖励模型之前,剥离(Strip)掉模型生成的思维链(Thinking Chunks),仅对最终回答进行偏好评分。这确保了奖励模型专注于结果的正确性和可读性,而非思维过程的冗长程度。
-
5.2 3B 模型的特殊处理
对于 3B 规模的模型,直接进行 SFT 导致模型出现严重的重复和冗长输出。解决方案是在 SFT 阶段引入 Logit Distillation,使用 Mistral Small 1.2 作为教师。这成功稳定了模型并减少了废话,为后续的 RL 训练奠定了基础。
6. 实验结果
6.1 预训练性能
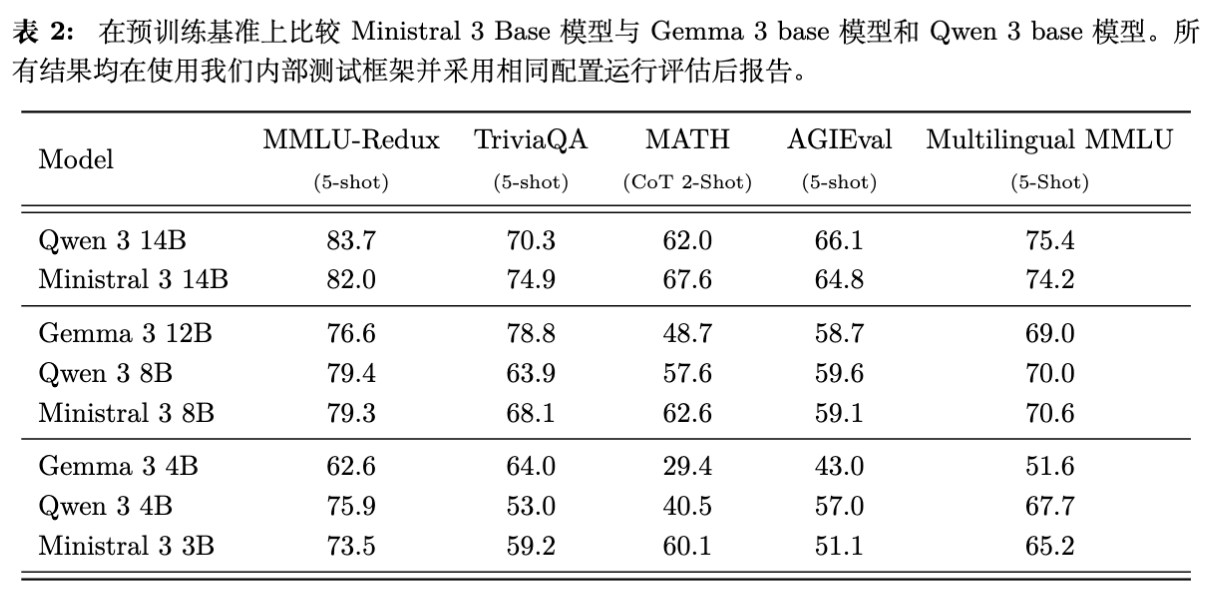
在 14B 尺度上,Ministral 3 在 TriviaQA 和 MATH 基准上优于 Qwen 3 14B,在其他基准上表现相当。相较于 Gemma 3 12B,Ministral 3 14B 展现了显著的优势。
在 8B 和 3B 尺度上,Ministral 3 同样表现出极高的参数效率(Parameter Efficiency)。特别是 Ministral 3 8B 在除 TriviaQA 外的所有测试中均击败了参数量更大的 Gemma 3 12B。
6.2 教师模型的知识保留
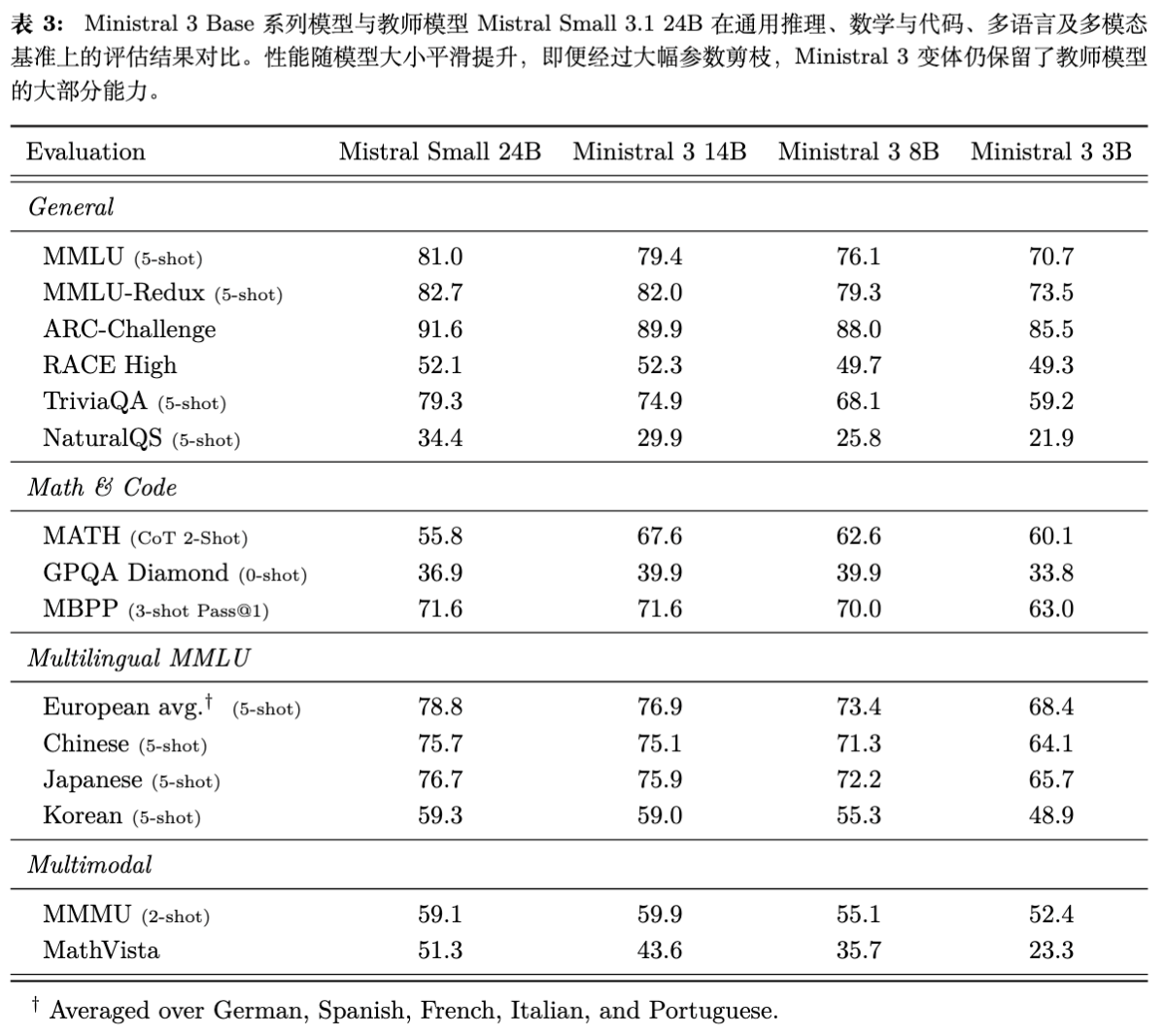
表 3 展示了剪枝后的模型在多大程度上保留了父模型的能力。结果显示,性能随参数量减少平滑下降,但即使是 3B 模型也保留了父模型相当大比例的能力。例如在 MMLU 上,14B 模型仅比 24B 父模型低 1.6 分。
6.3 指令遵循与推理能力
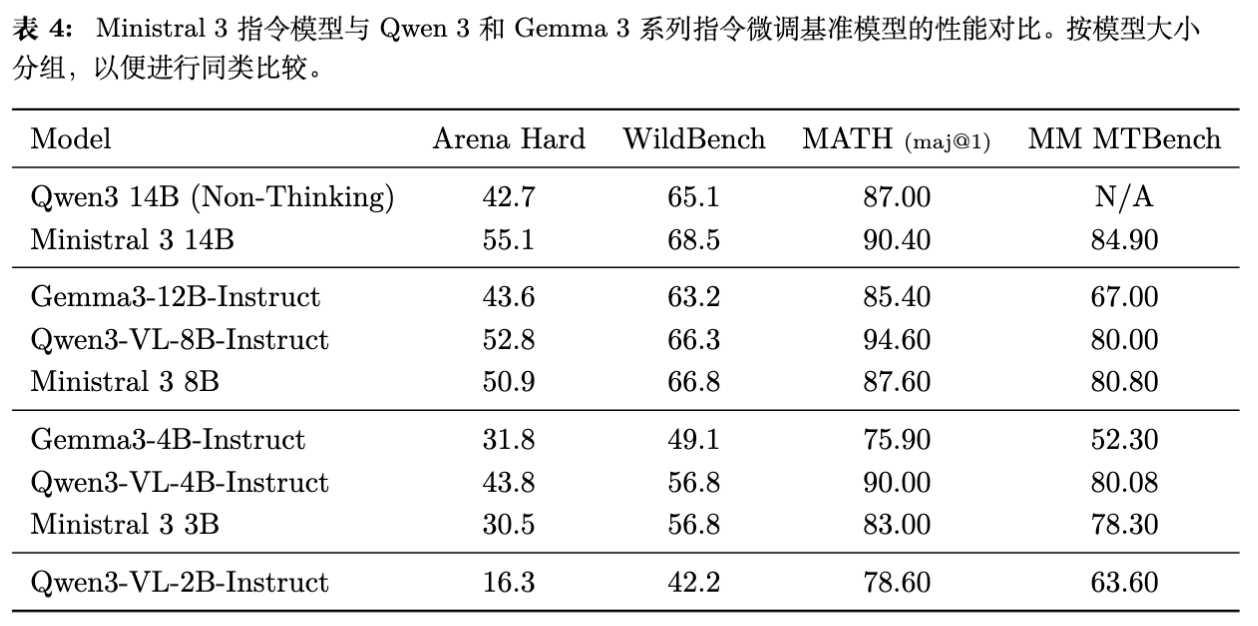
在指令微调后,Ministral 3 在 Arena Hard、WildBench 等对齐基准上表现优异。特别是 Ministral 3 14B 在 MATH (maj@1) 上达到了 90.40% 的准确率,优于同尺寸的 Qwen 3。
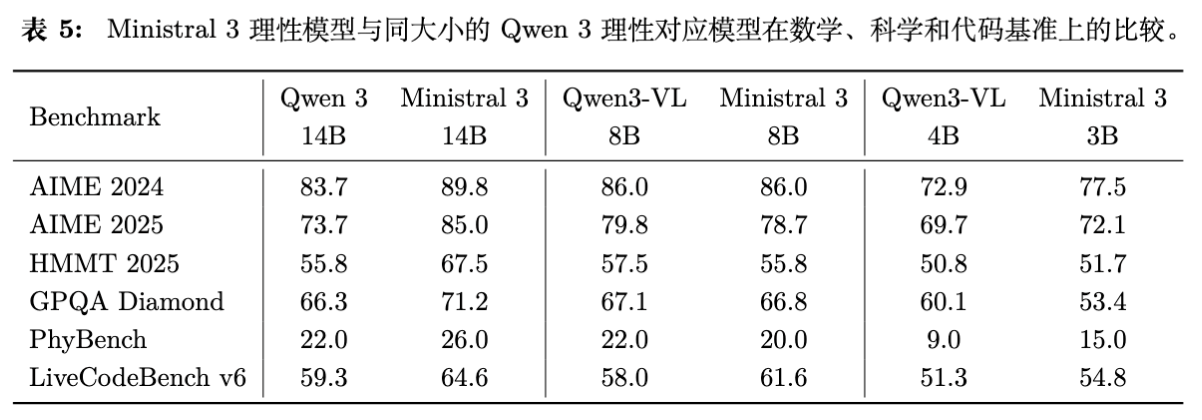
推理版本(Reasoning Models)在数学和代码任务上进一步提升了性能。在 AIME 2024 和 GPQA Diamond 等高难度基准上,Ministral 3 14B Reasoning 均优于 Qwen 3 14B。
7. 讨论与消融研究
7.1 教师模型的选择:越强越好吗?
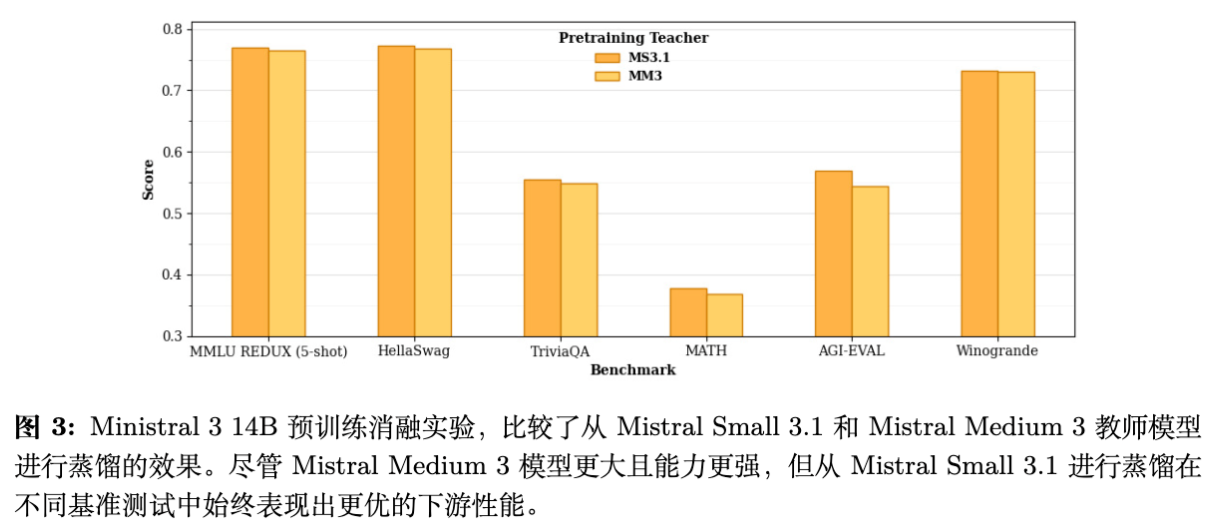
在预训练的蒸馏阶段,直觉上认为教师模型越强,学生模型学得越好。然而,Ministral 的实验(图 3)反驳了这一点。
-
预训练阶段:比较了从 Mistral Small 3.1(24B)蒸馏和从 Mistral Medium 3(更强的大模型)蒸馏的效果。结果显示,使用较弱的 Mistral Small 3.1 作为教师,学生模型的下游任务表现反而更好。 -
解释:这证实了“容量差距”(Capacity Gap)的存在。当教师模型过于复杂,其概率分布包含的细微差别可能超出了小参数学生模型的拟合能力,导致学习效率下降。 -
后训练阶段:有趣的是,在 SFT 和后训练阶段,这种限制不再适用。Ministral 3 在 SFT 阶段切换到 Mistral Medium 3 作为教师,获得了性能提升。这表明模型在具备了基础知识表征后,能更好地从强教师那里学习对齐和复杂指令遵循。
7.2 教师模型的类型:Base 还是 Instruct?
另一个关键问题是:预训练 Base 模型时,应该蒸馏 Teacher 的 Base 版本还是 Instruct 版本?
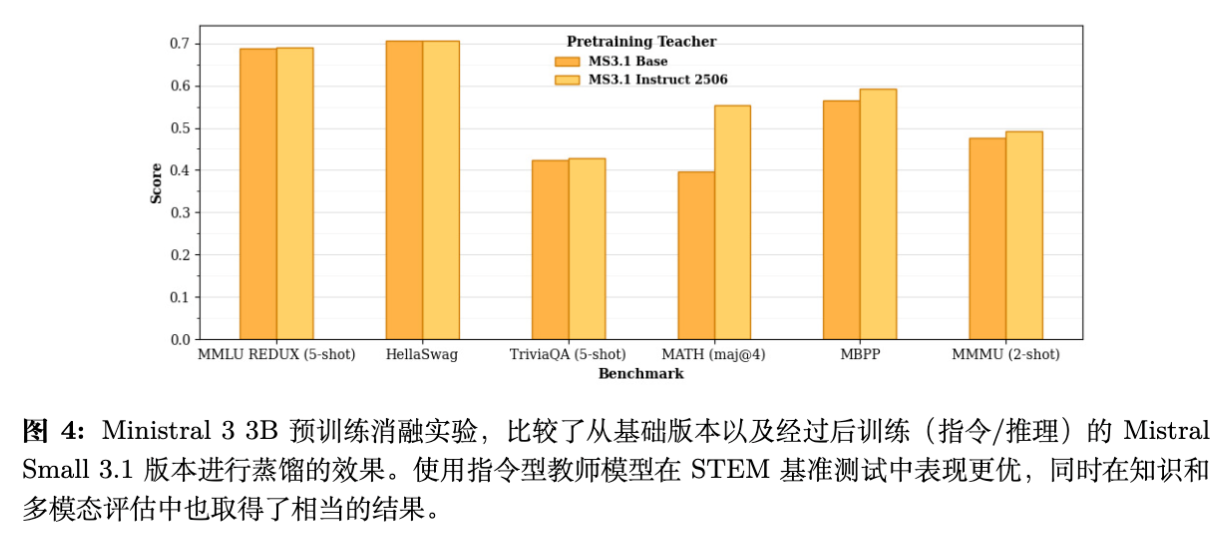
-
实验(图 4)表明:从 Post-trained(Instruct/Reasoning)教师蒸馏,能得到更强的 Base 学生模型。 -
具体影响:这种收益在数学(MATH)和代码能力上尤为显著,而在一般知识(MMLU)上影响较小。这意味着 Instruct 教师模型中的逻辑推理能力可以通过 Logit 蒸馏有效地传递给 Base 学生模型。
7.3 偏好优化教师的优势
进一步的实验比较了从 SFT 教师蒸馏与从“SFT+偏好优化”教师蒸馏的效果。
-
结论:从经过人类偏好优化(Preference Tuned)的教师处蒸馏始终优于仅经过 SFT 的教师。 -
意义:这意味着对齐(Alignment)不仅仅是调整说话方式,它可能在模型内部优化了知识的组织形式,使其更易于被学生模型吸收。即便学生模型随后也会进行自己的偏好优化,这种初始的增益依然存在。
7.4 冗余性与推理行为

在分析 Reasoning 模型时,研究者发现 Ministral 3 的 Instruct 版本与 Qwen 3 表现出不同的“冗余性”(Verbosity)。由于 Ministral 3 的训练流程中,Reasoning RL 是在 SFT 之后、通用 RL 之前进行的(或者说其 Instruct 模型并未像 Qwen 那样混合了大量推理数据进行预训练),其输出长度和行为模式有所不同。
此外,为了诱导 Instruct 模型产生推理能力,研究者尝试在 SFT 数据中加入长 CoT 数据。虽然提升了 STEM 性能,但也导致了副作用:模型在一般对话中也开始过度反思、自言自语(Internal Monologues)和回溯。这被认为是不可取的,因此 Ministral 3 最终将 Reasoning 模型作为一个独立的分支发布,而不是试图让一个模型同时通过 Prompt 兼顾极致推理和通用对话(尽管 Reasoning 模型在 ODPO 阶段剥离了思维链以改善对话体验)。
8. 结论
Ministral 3 证明了在受限计算预算下,通过级联蒸馏(Cascade Distillation)策略,可以高效地生产出一系列高性能的密集小模型。
核心启示:
-
复用父模型资产:通过结构化剪枝继承大模型权重,比从零预训练更高效。 -
蒸馏的细微差别:预训练阶段需警惕容量差距,应选择适配的教师;而后训练阶段则应大胆使用最强教师。 -
推理能力的传递:利用 Instruct 或 Reasoning 版本的教师来预训练 Base 模型,可以显著增强小模型的数学代码基因。
更多细节请阅读原文。
往期文章:


