-
论文标题:SHORT-CONTEXT DOMINANCE: HOW MUCH LOCAL CONTEXT NATURAL LANGUAGE ACTUALLY NEEDS? -
论文链接:https://arxiv.org/pdf/2512.08082v1
TL;DR
虽然现代大语言模型(LLM)支持长达数千甚至百万级别的上下文窗口,但不列颠哥伦比亚大学(UBC)与 Google DeepMind 的一项最新研究提出并验证了“短上下文主导假设”(Short-Context Dominance Hypothesis)。研究发现,对于绝大多数自然语言序列(即使来自长文档),仅需最后 32-96 个 token 的局部前缀即可准确且自信地预测下一个 token。基于此发现,作者提出了一种名为 TaBoo (Targeted Boosting) 的解码算法。该算法利用“长短上下文分布偏移”(LSDS)来检测真正需要长上下文的序列,并针对性地增强那些对长距离依赖敏感的 token 的概率。实验表明,该方法在 NarrativeQA、HotpotQA 等数据集上显著优于传统的核采样(Nucleus Sampling)和上下文感知解码(CAD)。
1. 引言
人类在续写文本时,究竟依赖多少前文信息?是主要关注最近的词汇和局部连贯性,还是时刻保持对宏大叙事的全局视角?在人类身上研究这一问题颇具难度,但大语言模型(LLM)为我们提供了一个可操作的实验模拟对象。
当前基于 Transformer 的 LLM 能够处理极其庞大的上下文窗口(从 8k 到 1M+ token)。然而,模型具备处理长上下文的能力,并不意味着其在推理时时刻都在利用这些信息。既往研究表明,模型往往存在“最近偏差”(Recency Bias)或“位置偏差”(Positional Bias)。
本文的核心贡献在于系统性地量化了模型在推理时对局部上下文的依赖程度。作者提出了短上下文主导假设:对于自然语言的大多数序列,准确预测下一个有效 token 所需的信息包含在一个极短的局部前缀中。
为了验证这一假设,论文定义了 最小上下文长度 (Minimal Context Length, MCL) 和 分布感知 MCL (DaMCL) ,并基于此开发了长上下文检测器和改进的解码策略。
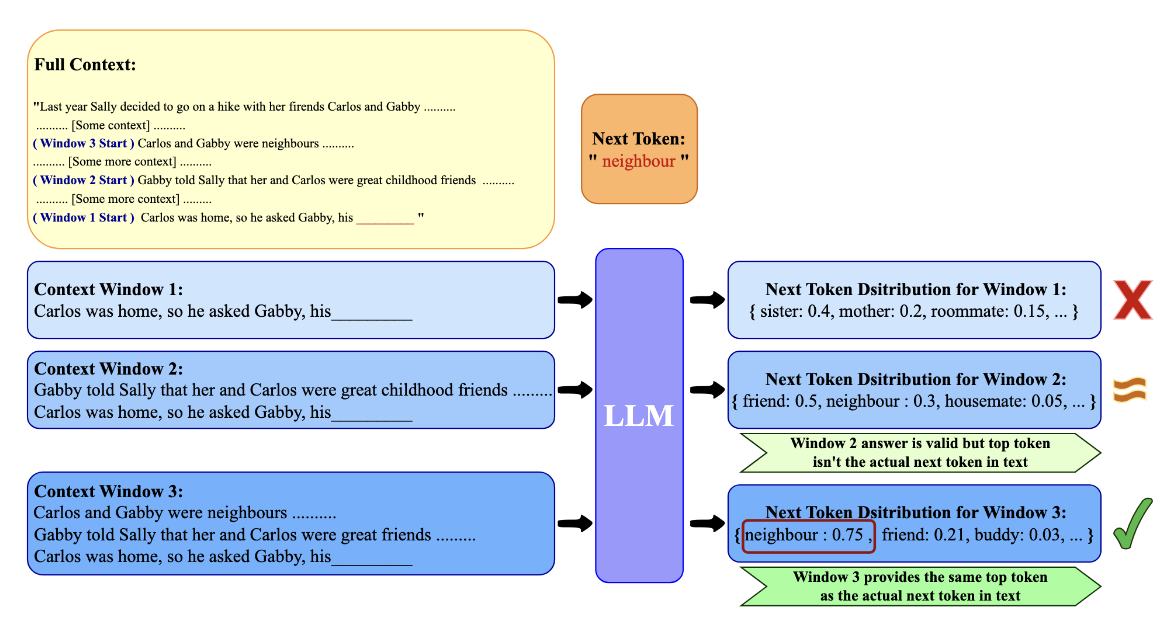
2. 最小上下文长度 (MCL):量化局部依赖
为了回答“预测下一个 token 至少需要多少上下文”这一问题,研究者将 LLM 视为一个统计预言机(Statistical Oracle)。
2.1 定义与方法
研究者关注那些模型能够正确且自信地预测出 ground-truth token 的序列。对于给定的序列 和其在语料库中的下一个 token ,最小上下文长度 (MCL) 定义为最短后缀 的长度 ,使得模型在该前缀下的输出既正确又自信。
形式化定义如下:
其中:
-
表示序列 的最后 个 token。 -
返回模型输出概率最高的 token。 -
表示置信度,定义为排名第一和排名第二的 token 之间的概率差。 -
是置信度阈值,实验中设置为 0.2。
2.2 实验设置
-
数据集: -
短文档:Reddit Writing Prompts, CNN/DailyMail, WikiText-103。 -
长文档:GovReport (政府报告), QMSum (会议记录), BookSum (书籍章节)。
-
-
模型:LLaMA-3-8B, Mistral-7B-Instruct-v0.2, Qwen2-7B。 -
序列选择:针对长文档,采样长度 的文档;针对短文档,采样长度 的文档。为了消除模型能力的干扰,仅筛选那些在全上下文输入下模型能正确且自信预测的样本。
2.3 结果:幂律衰减与局部性
实验结果呈现出惊人的一致性。MCL 的分布呈现极度的偏斜(Skewed Distribution)。
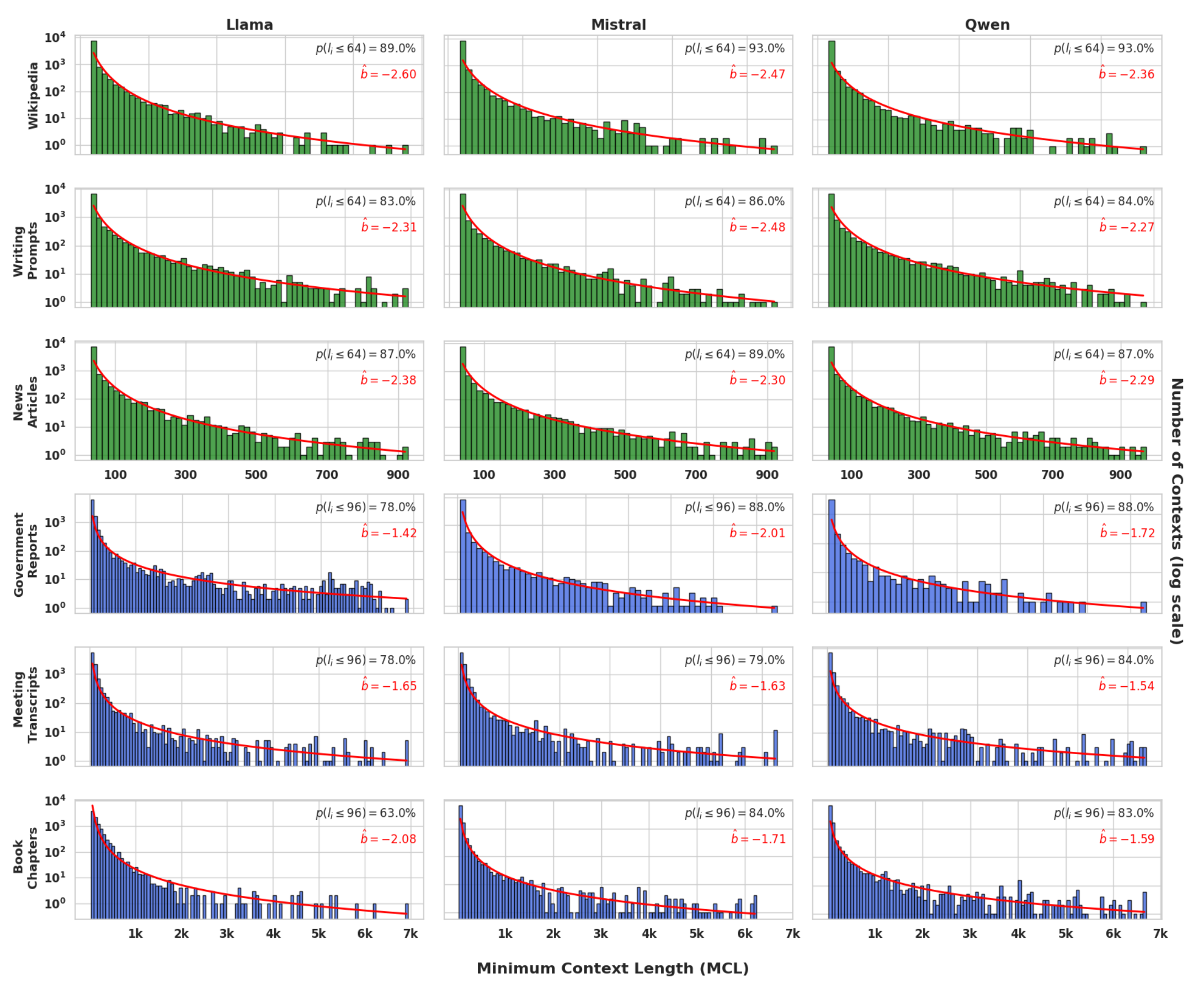
主要发现包括:
-
极短的依赖范围:对于 75%–80% 的序列,模型仅需最后 32 到 96 个 token 即可自信且正确地预测下一个 token。 -
幂律特征:MCL 的分布符合幂律衰减 。对于短文档,;对于长文档,。这种强衰减表明,即使在长文档任务中,绝大多数预测也仅依赖局部信息。
这一发现揭示了自然语言的一个内在属性:局部性原理。这也解释了为什么基于 n-gram 的模型(如最近的 Infini-gram)能在一定程度上取得成功。
3. 分布感知 MCL (DaMCL):超越贪婪解码
MCL 的定义依赖于贪婪解码(Greedy Decoding)和对 ground-truth token 的精确匹配。然而,自然语言往往存在多个合理的续写,且现代生成任务常采用采样策略(如 Nucleus Sampling)。单纯依赖 Top-1 匹配可能低估了模型对上下文的理解(例如,模型预测了同义词)。
为了解决这一局限,作者提出了 分布感知最小上下文长度 (DaMCL) 。
3.1 定义
DaMCL 旨在寻找最短的前缀长度 ,使得在该前缀下的输出分布 与全上下文下的输出分布 足够接近。
形式化定义:
其中:
-
是解码策略(如 Nucleus Sampling, Top-k)。 -
是分布相似度度量,本文主要采用 Jensen-Shannon 距离 (JSD) 。 -
是相似度阈值。
JSD 的定义为:
其中 。选择 JSD 是因为它对称且有界,且满足三角不等式。
3.2 发现与讨论
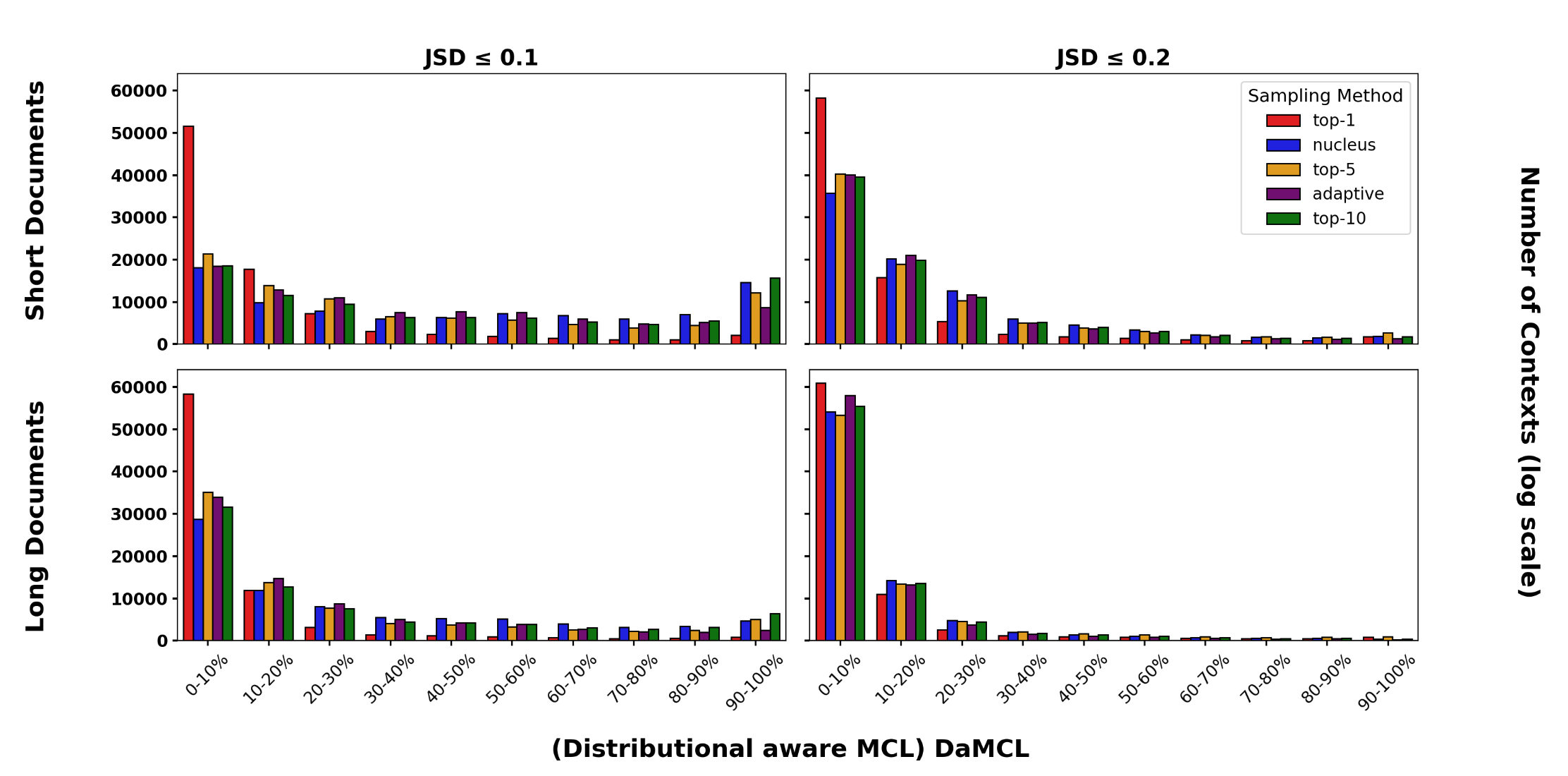
-
短上下文依然主导:在较宽松的阈值()下,DaMCL 的分布与 MCL 相似,依然呈现长尾衰减,证明了大部分情况下短前缀足以恢复全上下文的分布形态。 -
严格阈值下的双峰结构:当阈值非常严格()时,分布呈现出“U型”结构。一部分序列依然仅需极短上下文,但另一部分序列则需要几乎完整的上下文才能使分布收敛。这表明存在两类截然不同的序列:短上下文序列和长上下文序列。
4. 长上下文序列检测
基于 DaMCL 的发现,作者提出了一种无需 ground-truth 即可在推理时检测长上下文需求的方法。
4.1 长短分布偏移 (LSDS)
作者定义了 长短分布偏移 (Long-Short Distribution Shift, LSDS) 指标,用于量化给定序列对长距离信息的依赖程度。
这里,作者固定短前缀长度为 32(基于 MCL 的发现,32 是一个关键的局部窗口),并计算该短前缀下的分布与全上下文分布之间的 JSD 距离。
4.2 验证与阈值选择
为了验证 LSDS 的有效性,作者设计了“大海捞针”(Needle-in-a-Haystack)式的受控实验:
-
短上下文查询:答案位于最后 32 个 token 内。 -
长上下文查询:答案位于文档更早的位置,必须依赖长距离信息。
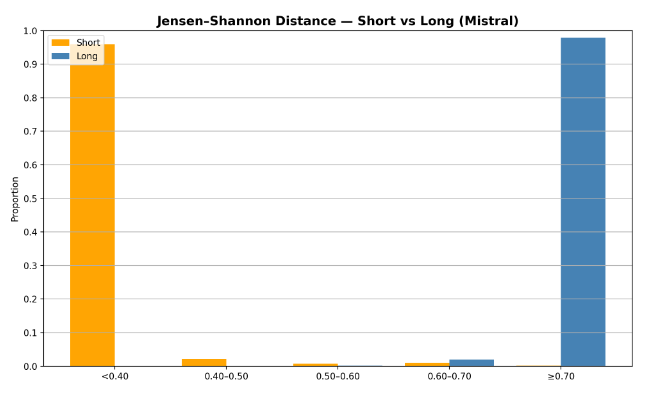
实验结果显示出清晰的二分法:
-
短上下文查询集中在低 LSDS 值区域 ()。 -
长上下文查询集中在高 LSDS 值区域 ()。
基于此,可以设定一个阈值 (例如 0.6),构建一个简单的二分类器:
-
若 ,则判定为长上下文序列。 -
若 ,则判定为短上下文序列。
4.3 自然文本上的评估
在自然文本(如 GovReport 和 Reddit Writing Prompts)上,作者使用 MCL Oracle(基于真实 token 是否需要长上下文)作为标签,评估 LSDS 的分类性能。
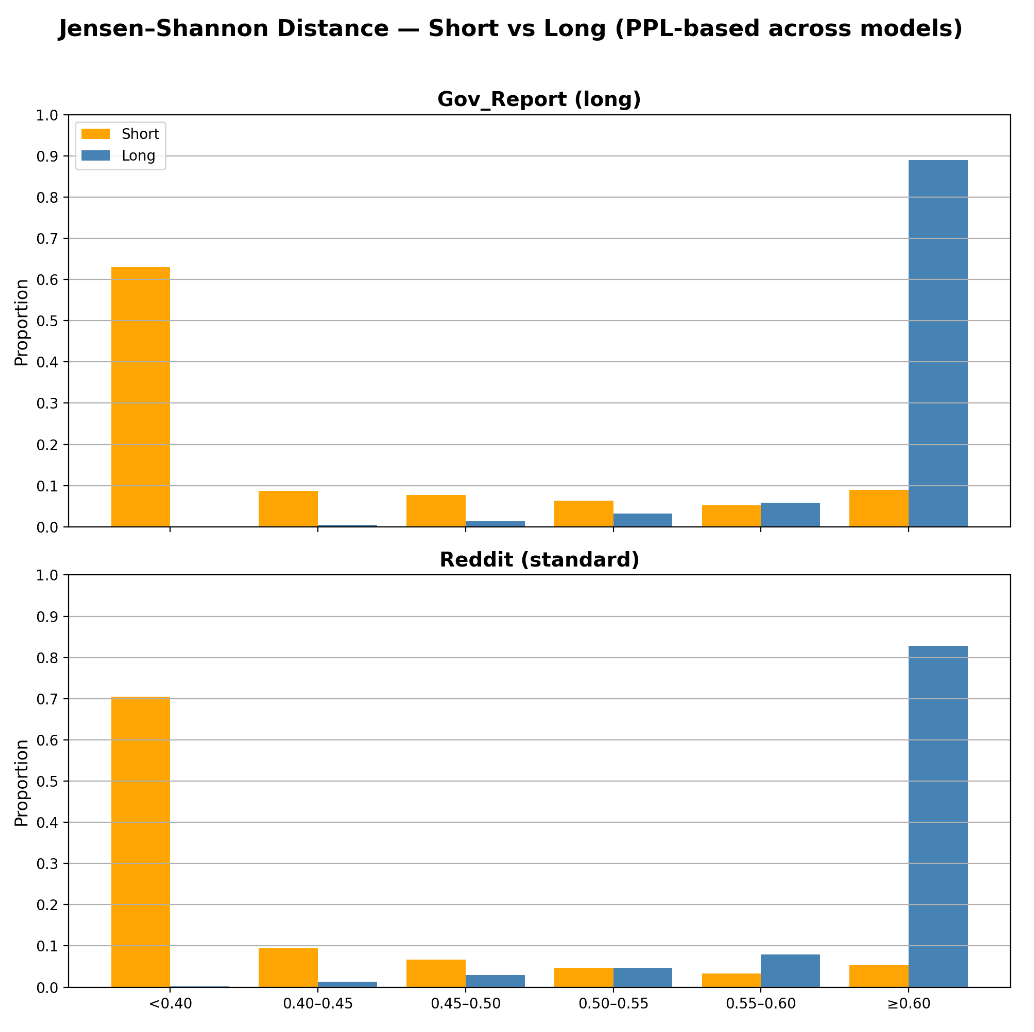
结果表明,LSDS 与 Oracle 标签具有极高的一致性(80%-90% 的 Oracle 标记的长上下文序列具有高 LSDS 值)。这证明了利用模型自身的分布变化作为长上下文依赖的代理是可靠的。
5. TaBoo:针对性增强长上下文 Token
既然大多数序列只需要短上下文,那么模型在训练过程中可能会产生偏见,倾向于生成仅符合局部连贯性的“填充词”或常见搭配,从而掩盖了真正需要长距离依赖的 token。
作者提出了 TaBoo (Targeted Boosting) 算法,旨在推理阶段纠正这种偏差。
5.1 识别长上下文相关的 Token
仅仅检测出“当前序列需要长上下文”是不够的,我们还需要知道词表中的哪些 token 是由长上下文信息支持的。
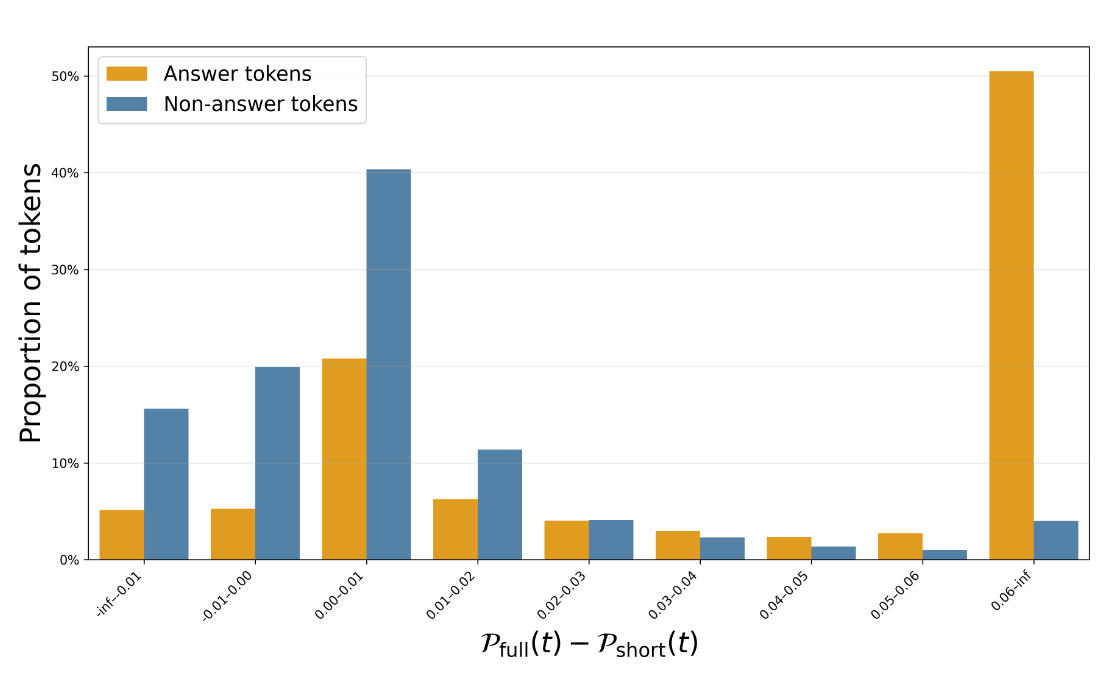
作者定义了 长短概率偏移 (Long-Short Probability Shift, LSPS) :
其直觉在于:如果一个 token 确实依赖于长距离信息,那么当模型从短上下文切换到全上下文时,该 token 的概率应该显著增加。
在 NarrativeQA 上的验证表明,答案 Token(通常是人名、地点等实体)表现出显著更高的 LSPS 值,而非答案 Token(常用词)的 LSPS 值通常较小甚至为负。
5.2 TaBoo 算法流程
TaBoo 是一种干预式的解码算法,具体步骤如下(详见论文算法 1):
-
检测 (Detect) :
计算当前步骤的 。如果 (即短上下文主导),则直接使用标准的核采样解码,不做干预。 -
识别 (Identify) :
如果 ,则计算词表中候选 token 的 。构建长上下文相关 token 集合 。 -
增强 (Boost) :
对于集合 中的每一个 token ,将其概率乘以增强因子 :最后对修改后的分布进行重归一化,并进行采样。
5.3 与 Context-Aware Decoding (CAD) 的区别
CAD (Duh et al., 2024) 也是通过对比有无上下文的 logits 来增强互信息,但 TaBoo 有显著不同:
-
选择性干预:TaBoo 仅在检测到 LSDS 高时才触发,而 CAD 对所有步骤都进行调整。这避免了在不需要长上下文时引入噪声。 -
针对性增强:TaBoo 仅增强 LSPS 高的特定 token,而 CAD 对整个分布进行调整。 -
基于概率而非 Logits:TaBoo 直接操作概率差,物理意义更直观(概率增益),而 CAD 操作 Logits 差(即概率比率),容易在低概率区域产生数值不稳定。
6. 实验结果与分析
作者在 NarrativeQA, HotpotQA, MultiFieldQA-en 等数据集上评估了 TaBoo,并与 Vanilla Nucleus Sampling 和 CAD 进行了对比。
6.1 主要结果
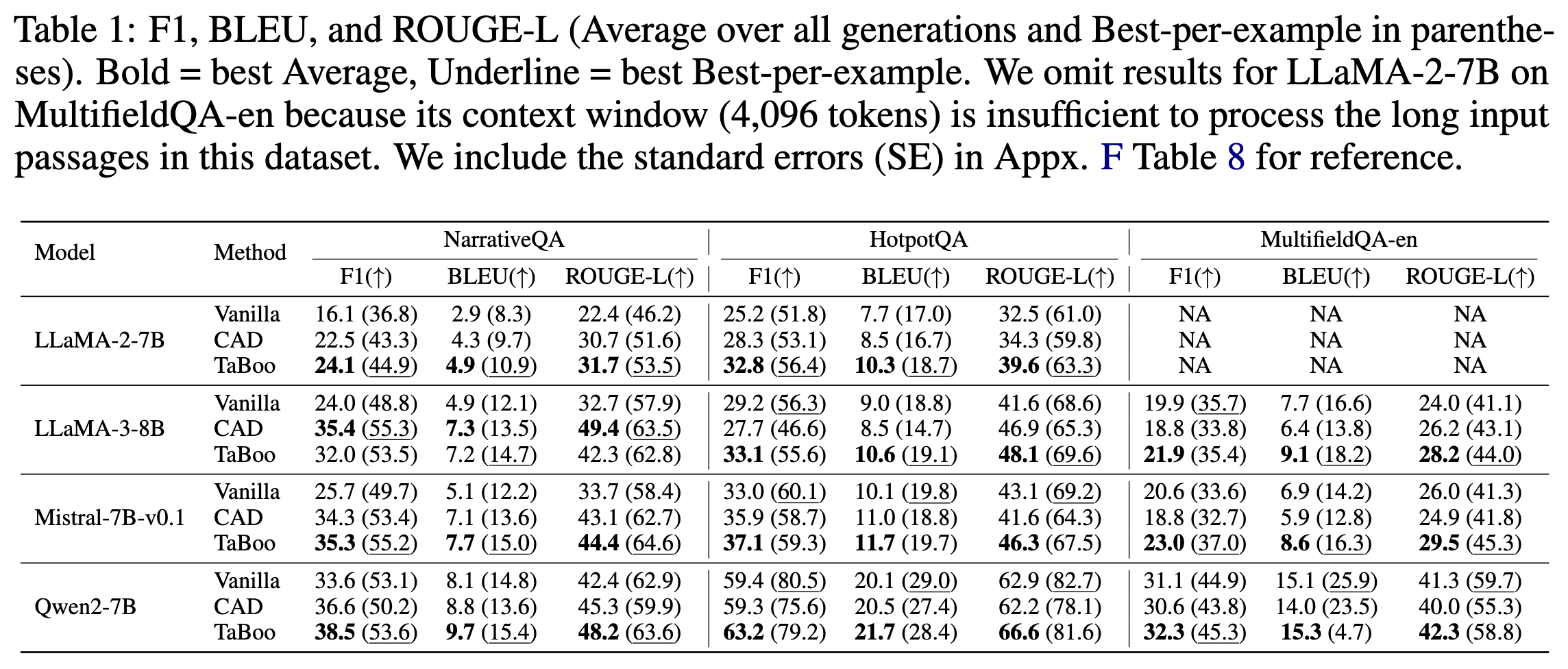
-
性能提升:在 12 个模型-数据集组合中,TaBoo 在 11 个组合上取得了最优的 F1 分数。 -
对比 CAD:TaBoo 普遍优于 CAD,特别是在 NarrativeQA 上提升显著。这得益于 TaBoo 避免了对短上下文主导位置的错误干预。 -
模型泛化性:无论是较小的 LLaMA-2-7B 还是较强的 Qwen2-7B,TaBoo 均能带来提升。
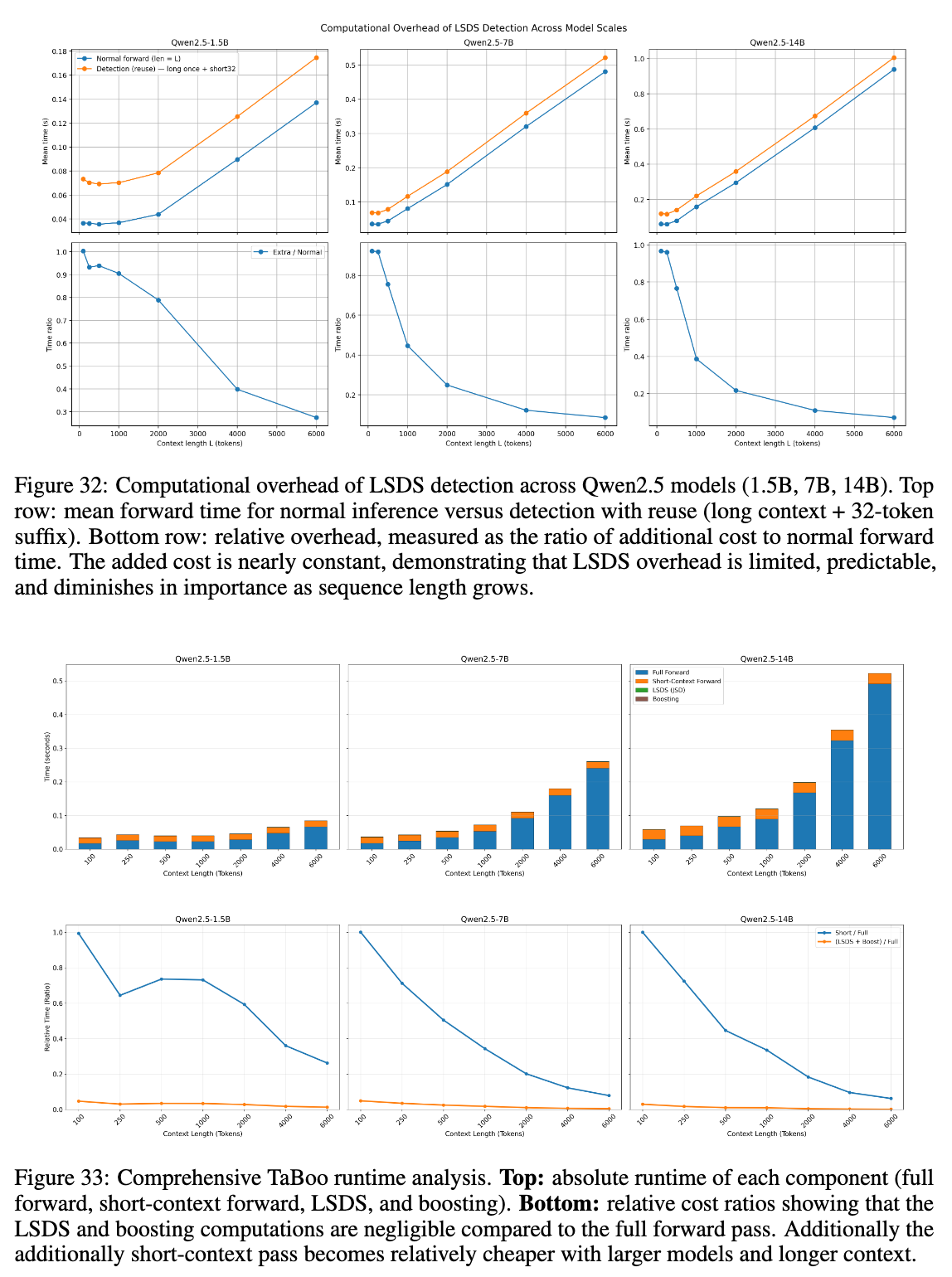
6.2 计算开销
读者可能会担心计算两次前向传播(一次全上下文,一次短上下文)会带来巨大的开销。但分析显示:
-
KV Cache 复用:全上下文的前向传播是必须的。短上下文前向传播仅涉及最后 32 个 token,计算量极小。 -
实际延迟:在 Qwen2-7B 上,额外的计算仅增加了 35-67ms 的延迟。对于长文档生成(如 6000 token 上下文),这部分开销仅占总时间的 6%-8%,几乎可以忽略不计。
7. 深入分析与讨论
论文的附录部分提供了大量详实的消融实验和补充分析,这对于理解该方法的鲁棒性至关重要。
7.1 语言与领域的普适性
短上下文主导现象是否仅存在于英语?
-
多语言测试:作者在 Wikipedia 的多种语言翻译版本(中、法、德、俄、阿、韩、泰)上进行了 MCL 测试。结果表明,所有语言都呈现出相似的幂律衰减和短上下文依赖特性。 -
专业领域测试:在生物医学 (PubMed)、数学 (OpenWebMath) 和代码 (Python) 数据集上,虽然具体数值略有波动,但整体趋势依然稳固。代码数据略微表现出更长的上下文依赖(这是合理的,因为代码涉及类定义引用等),但依然符合假设。
7.2 分词 (Tokenization) 的影响
是否是因为 Subword Tokenization 导致了“假性”的短依赖(例如预测单词后缀不需要长文)?
-
作者将 token 分为三类:完整单词、单词首个 subword、单词非首个 subword。 -
实验发现,三类 token 的 MCL 分布几乎没有差异。这说明短上下文主导是自然语言的语义属性,而非分词器的人工产物。
7.3 词性 (POS) 分析
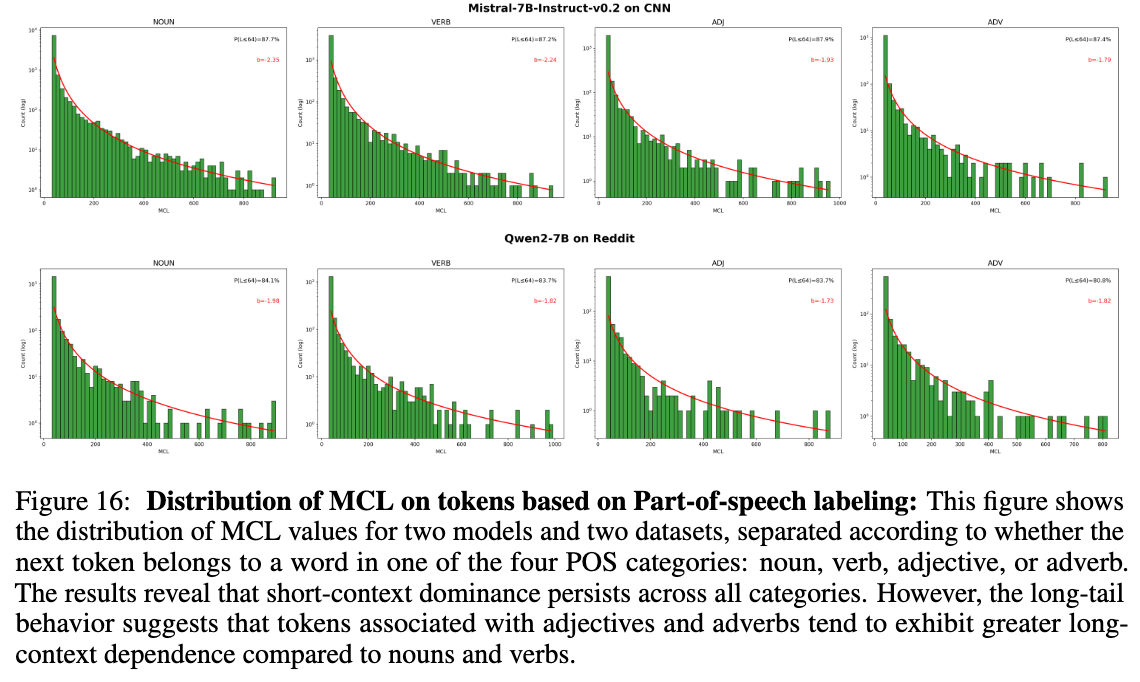
-
名词 (Noun) 和动词 (Verb) 的短上下文依赖性依然很强。 -
形容词 (Adjective) 和副词 (Adverb) 表现出稍长一点的上下文依赖,可能与描述性修饰需要回溯前文对象有关。
7.4 为什么不使用 Logits 差值?
在 TaBoo 的设计选择中,作者比较了 LSPS(概率差)和 LSPR(概率比/Logits 差)。
-
实验表明,使用概率比(Logits 差)在低概率区域极其敏感。例如,概率从 变到 会产生巨大的 Logits 变化,但该 token 可能依然是无关紧要的干扰项。 -
概率差(LSPS)能够自然地过滤掉低概率 token 的噪声,更加稳健。
8. 总结与展望
这篇论文通过严格的实证研究,揭示了一个或许反直觉但极其重要的事实:尽管我们向 LLM 喂入了海量的上下文,但在生成的每一个步骤中,模型真正“用到”的信息往往只集中在最后几十个 token。
这一发现具有多重意义:
-
评估层面:现有的 Perplexity 指标可能在长文档评估中存在误导,因为它主要反映了短距离预测能力。 -
效率层面:既然大部分时间只需要短上下文,那么可以通过动态稀疏注意力或混合加载策略来大幅降低推理成本。 -
生成质量:TaBoo 算法证明了,通过显式地对抗“短上下文偏见”,我们可以诱导模型更好地利用长距离信息,从而减少幻觉,提升 QA 准确率。
这项工作为长上下文 LLM 的研究提供了一个清晰的理论视角和实用的工具箱。对于致力于提升 RAG 系统或长文本生成来说,理解并利用这种“短上下文主导”特性,将是优化系统性能的关键切入点。
往期文章: