2025年8月8日,智谱 AI (Zhipu AI) 与清华大学联手推出了《GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models》技术报告,不仅详细介绍了一款全新的开源混合专家(MoE)大语言模型——GLM-4.5,更重要的是,它提出并实践了一个雄心勃勃的目标:统一并提升模型在智能体(Agentic)、推理(Reasoning)和编码(Coding)这三大核心能力上的表现。
GLM-4.5 拥有 3550 亿(355B)总参数和 320 亿(32B)激活参数,在性能上取得了惊人的成就。它在全面的 ARC 评测基准上,总分位列所有参评模型的第三名,在智能体任务上更是高居第二名。作为一个开源模型,这一成绩无疑是里程碑式的。
1. 引言:从知识库到通用问题求解器
大型语言模型(LLM)的演进正经历一个深刻的范式转换。它们不再仅仅是存储和检索知识的庞大数字仓库,而是日益成为能够解决复杂问题的“通用问题求解器”(General Problem-Solvers)。这一转变的终极目标,与通用人工智能(AGI)的愿景紧密相连:创造出具备跨领域人类水平认知能力的模型。
为了实现这一宏伟目标,模型必须超越在特定任务上的卓越表现,转而追求在多个核心能力上的统一精通。智谱 AI 和清华大学的研究团队在这篇论文中,明确指出了衡量一个模型是否真正具备“通用性”的三个关键维度,并将其概括为 ARC 框架:
-
智能体能力(Agentic Abilities):模型与外部工具和真实世界环境进行交互的能力。这包括使用 API、浏览网页、执行代码等,是模型将虚拟智能转化为现实生产力的关键。 -
复杂推理能力(Complex Reasoning):在数学、科学等领域解决需要多步骤逻辑推导问题的能力。这是衡量模型“智力”深度的核心指标。 -
高级编码能力(Advanced Coding):处理真实世界软件工程任务的能力,如理解和修复复杂代码库中的问题。这是模型在专业领域应用潜力的直接体现。
尽管此前已有如 OpenAI 的 o1/o3 和 Anthropic 的 Claude Sonnet 4 等先进的闭源模型在某些 ARC 领域展示了突破性性能,但一个能在所有这三个领域都表现出色,并且是开源的强大模型,始终是社区的期待。
GLM-4.5 的诞生,正是为了填补这一空白。它不仅在 ARC 三个维度上均取得了显著的性能提升,超越了现有的众多开源模型,还发布了两个版本:
-
GLM-4.5(355B):主力模型,性能强大。 -
GLM-4.5-Air(106B):一个更紧凑的版本,在 100B 参数规模的模型中也展现出了非凡的竞争力。
论文的核心贡献可以总结为:
-
发布强大的开源 ARC 基础模型:GLM-4.5 在多个关键基准测试中(如 TAU-Bench 70.1%, AIME 24 91.0%, SWE-bench Verified 64.2%)取得了顶尖的成绩。 -
高效的参数设计:与一些拥有更多参数的竞争对手相比,GLM-4.5 以更少的参数实现了相当甚至更强的性能,展现了卓越的参数效率。 -
全面的技术路线分享:论文详细公开了从预训练、中度训练到后训练的完整技术栈,包括数据处理、模型架构和创新的训练方法,为整个社区的研究提供了宝贵的参考。
接下来,我们将深入探索 GLM-4.5 背后的技术细节,看它是如何通过精心设计和系统性训练,实现 ARC 能力的统一和飞跃的。
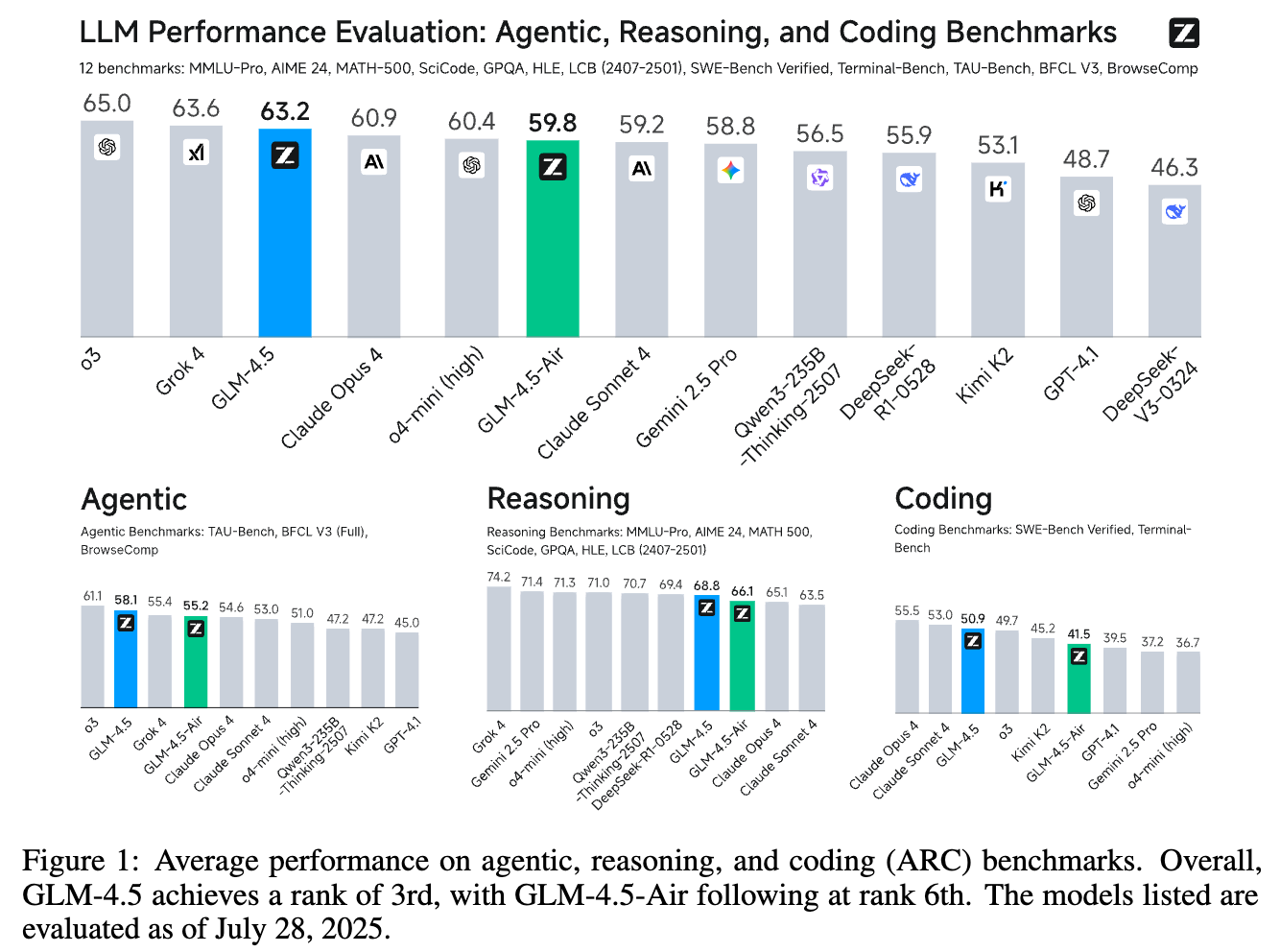
从上图可以看出,GLM-4.5 在包含 12 个基准的综合性能评估中,以 63.6% 的平均分位列第三,仅次于 Grok 4 和 Claude Opus 4。而其轻量版 GLM-4.5-Air 也位列第六。这一成绩充分证明了其强大的综合实力。
2. 登峰之路:GLM-4.5 的训练全景
GLM-4.5 的卓越性能并非偶然,其背后是一套极其复杂和精密的、分为三个主要阶段的训练流程:预训练 (Pre-Training)、中度训练 (Mid-Training)和后训练 (Post-Training)。
2.1 预训练 (Pre-Training):奠定坚实基础
预训练阶段的目标是让模型学习到广泛的世界知识和基本语言能力。GLM-4.5 在这一阶段处理了高达 23T tokens 的海量数据。
2.1.1 模型架构:深度与效率的权衡
GLM-4.5 系列采用了 混合专家(Mixture-of-Experts, MoE)架构。MoE 架构的核心思想是在模型中设置多个“专家”子网络,对于每个输入的 token,通过一个“门控网络”(gating network)来决定激活哪几个专家进行计算。相比于传统的“稠密模型”(dense model)需要激活所有参数,MoE 能够在保持甚至提升模型性能的同时,显著降低训练和推理的计算成本。
论文中特别强调了几个关键的架构设计决策,这些决策是其高性能的重要保障:
-
更深更窄的设计:与 DeepSeek-V3 和 Kimi K2 等模型不同,GLM-4.5 选择了减少模型的宽度(隐藏层维度和专家数量)并增加其高度(层数)。研究团队发现,更深的网络结构表现出更好的推理能力。 -
更多的注意力头:GLM-4.5 使用了比同类模型更多的注意力头(例如,在 5120 的隐藏维度下使用了 96 个头)。一个反直觉的发现是,虽然增加注意力头数量并未显著降低训练损失,但它持续地提升了模型在 MMLU 和 BBH 等推理基准上的性能。 -
先进技术的融合:模型集成了多项先进技术以提升性能和稳定性,包括: -
Grouped-Query Attention(GQA):一种折衷于多头注意力(MHA)和多查询注意力(MQA)之间的技术,有效提升了推理效率。 -
partial RoPE:部分旋转位置编码。 -
QK-Norm:用于稳定注意力 logits 的范围,防止训练中出现不稳定的情况。 -
MTP (Multi-Token Prediction) Layer:在模型的最后一层增加了一个额外的 MoE 层,用于支持推理时的“推测解码”(speculative decoding),进一步加速生成速度。
-
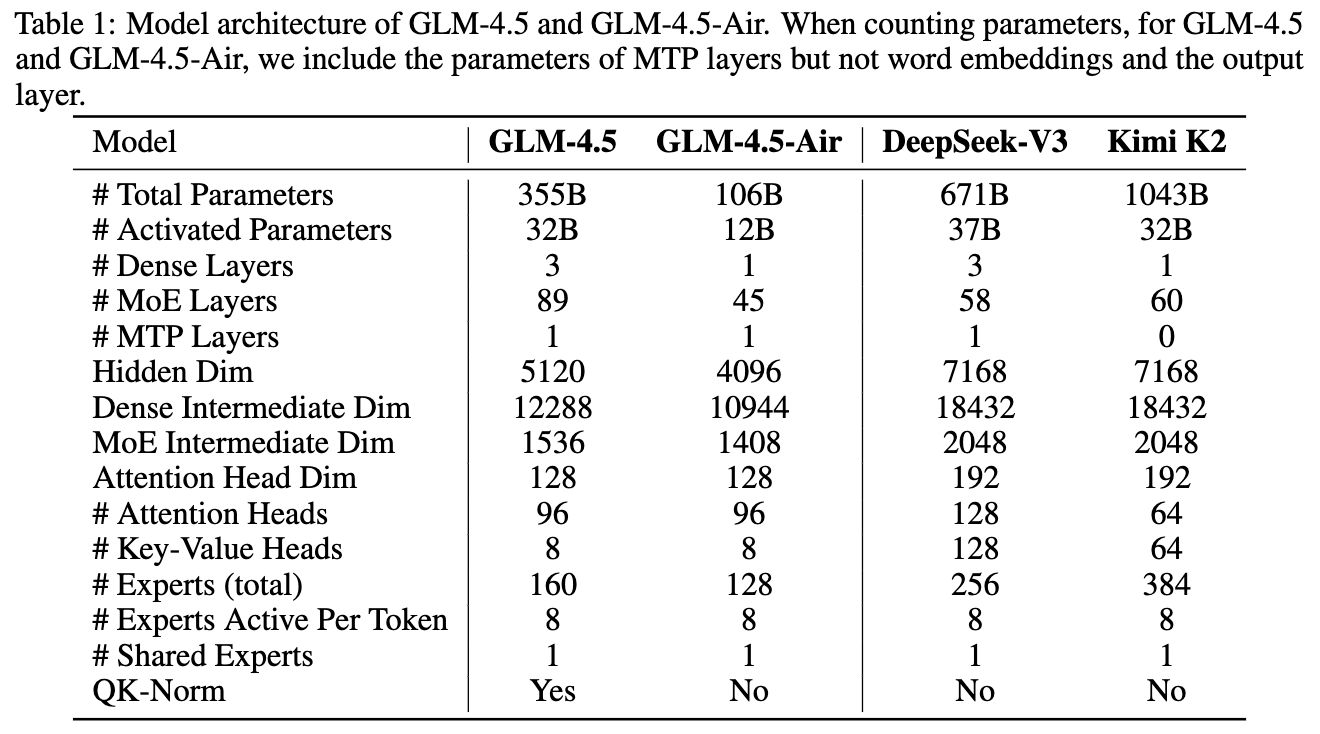
从表格中可以清晰地看到 GLM-4.5 和 GLM-4.5-Air 与其他模型的架构差异。GLM-4.5 在总参数量(355B)远低于 Kimi K2(1043B)和 DeepSeek-V3(671B)的情况下,激活参数量(32B)与它们处于同一水平,体现了其参数高效性。其层数(89层MoE + 3层Dense)也显著多于其他模型,印证了其“更深”的设计理念。
2.1.2 预训练数据:质量与多样性的艺术
数据的质量和多样性是决定模型能力上限的关键。GLM-4.5 的预训练语料库来源广泛,并经过了极其精细的处理。
-
Web 数据:大部分数据来自中英文网页。团队借鉴了 Nemotron-CC 的思想,将抓取的网页根据质量评分分入不同的“桶”中,并对高质量桶中的数据进行上采样(up-sample)。得分最高的桶在预训练中被迭代了超过 3.2 个 epoch,这使得模型能够重点学习高频的推理知识,同时也能覆盖长尾的世界知识。为了处理模板化生成的低质网页,团队还引入了 SemDedup,一种基于文档嵌入的语义去重技术。 -
多语言数据:为了支持更广泛的自然语言,语料库中包含了来自网页抓取和 Fineweb-2 数据集的多语言文档。通过一个质量分类器来判断文档的教育价值,并对高质量的多语言文档进行上采样。 -
代码数据:代码语料库经过了多级处理。首先是基于规则的过滤,然后使用特定语言的质量模型将代码分为高、中、低三个等级,训练时只使用高质量和中等质量的代码。此外,Fill-In-the-Middle (FIM) 训练目标被应用于所有代码数据,以增强代码补全能力。对于网页中的代码相关内容,团队设计了一个两阶段检索流程,先用 FastText 分类器或 HTML 标签识别出潜在内容,再用专用模型进行质量评估和采样。 -
数学与科学数据:为了增强推理能力,团队从网页、书籍和论文中收集了大量数学和科学相关的文档。他们使用一个大模型对这些文档进行打分(基于数理教育内容的比例),然后训练一个小分类器来预测这个分数,并对高分文档进行上采样。
GLM-4.5 的预训练分为两个阶段:第一阶段主要在通用文档上训练,第二阶段则上采样代码以及与编码、数学、科学相关的网页数据,以强化 ARC 核心能力。
2.2 中度训练 (Mid-Training):定向增强 ARC 能力
预训练之后,模型进入了中度训练阶段。与在通用文档上进行传统预训练不同,中度训练使用中等规模的、领域特定的数据集(包括指令数据)来进一步提升模型在关键应用领域(即 ARC)的性能。
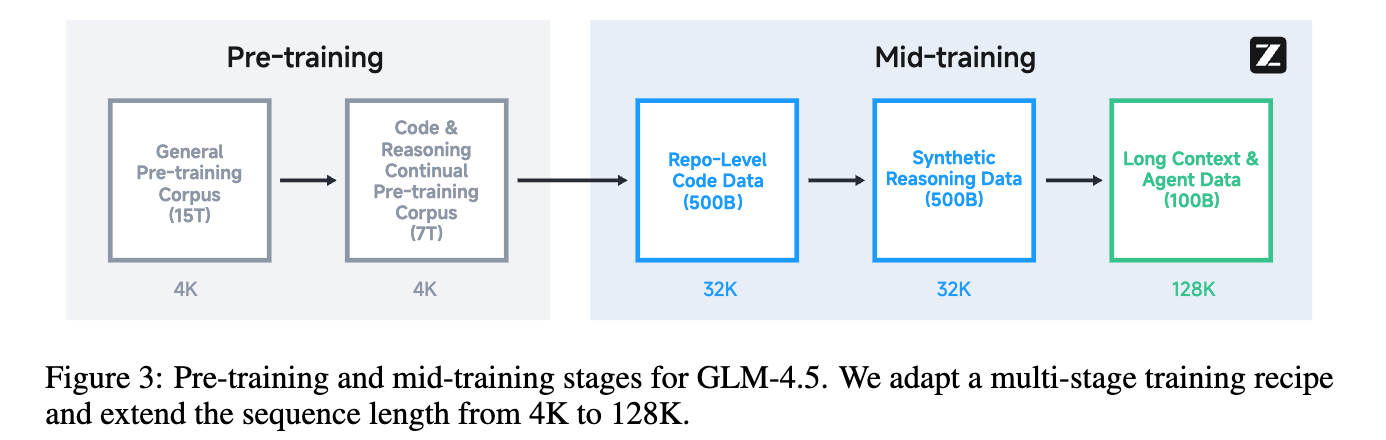
如上图所示,这个阶段是一个承前启后的关键环节,序列长度也从预训练的 4K 逐步扩展到 128K。
-
Repo-level 代码训练:将同一代码仓库中的多个代码文件拼接在一起进行训练,让模型学习跨文件的依赖关系。为了提升模型的软件工程能力,团队还引入了经过模型过滤的 GitHub issues、pull requests (PRs) 和 commits 数据。这个阶段的序列长度从 4K 扩展到 32K,以容纳大型代码库。 -
合成推理数据训练:在这个阶段,团队为模型添加了大量用于数学、科学和编程竞赛的合成推理数据。他们从网页和书籍中收集了大量问题和答案,并使用一个推理能力强的模型来合成详细的推理过程。 -
长上下文与智能体训练:为了进一步提升模型的长上下文处理能力,序列长度从 32K 扩展到 128K,并对预训练语料库中的长文档进行上采样。同时,大规模的合成智能体轨迹(agent trajectories)数据也被加入到训练中,为后续的智能体能力训练打下基础。
2.3 超参数设定
在超参数方面,论文也分享了一些关键选择:
-
优化器:使用了 Muon 优化器,它能加速收敛并允许更大的批量大小。 -
学习率:采用余弦衰减(cosine decay)调度,而非 warmup-stable-decay (WSD)。团队发现 WSD 调度会导致模型在通用基准上表现不佳,可能存在欠拟合问题。 -
批量大小:使用了 batch size warmup 策略,在前 500B tokens 的训练中,批量大小从 16M tokens 逐渐增加到 64M tokens。 -
正则化:权重衰减(weight decay)设为 0.1,不使用 dropout。 -
RoPE 基频调整:在将序列长度扩展到 32K 时,将 RoPE 的基频从 10,000 调整到 1,000,000,以获得更好的长上下文建模能力。
3. 点石成金:后训练与专家模型迭代
如果说预训练和中度训练给了 GLM-4.5 一副强健的骨架,那么后训练(Post-Training)阶段则为其注入了灵魂,使其能够精准、高效、安全地与用户交互。这个阶段的核心是专家模型迭代(Expert Model Iteration)。
整个后训练过程分为两个截然不同的阶段:
-
阶段一:专家训练 (Expert Training):构建在三个特定领域——推理(Reasoning)、智能体(Agent)和通用对话(General chat)——的专家模型。 -
阶段二:统一训练 (Unified Training):使用自蒸馏(self-distillation)技术,将多个专家的能力整合到一个统一的、能够支持深思熟虑的推理和即时响应的综合模型中。
3.1 监督微调 (Supervised Fine-Tuning, SFT)
SFT 是后训练的起点,为模型提供基础的对话、推理和工具使用能力。
-
冷启动 SFT(Cold Start SFT):在专家训练的初期,使用一小部分带有扩展思维链(Chain-of-Thought, CoT)响应的 SFT 数据,让每个专家模型具备必要的基础能力,为后续的强化学习做准备。 -
全局 SFT(Overall SFT):在统一训练阶段,收集了数百万覆盖推理、通用对话、智能体任务和长上下文理解等多个领域的样本。这些样本来自于之前训练好的专家模型的输出。通过从不同专家的输出中进行蒸馏,模型学会了为不同类型的任务应用最有效的长 CoT 推理。
创新的函数调用模板
一个值得特别关注的技术创新是减少函数调用模板中的字符转义。在传统的 JSON 格式中,如果函数参数包含代码片段,大量的字符(如引号、斜杠)需要被转义,这增加了模型的学习负担。
为了解决这个问题,团队提出了一种新颖的、基于 XML 风格特殊标签的函数调用模板。
<|system|>
# Tools
You may call one or more functions to assist with the user query.
You are provided with function signatures within <tools></tools> XML tags:
<tools>
{"name": "get_weather", "description": "Get the weather of a city for a specific date.", "parameters": {"
type": "object", "properties": {"city": {"type": "string", "description": "The city to get weather for,
in Chinese."}, "date": {"type": "string", "description": "The date in YYYY-MM-DD format."}}, "required":
["city"]}}
</tools>
For each function call, output the function name and arguments within the following XML format:
<tool_call>{function-name}
<arg_key>{arg-key-1}</arg_key>
<arg_value>{arg-value-1}</arg_value>
<arg_key>{arg-key-2}</arg_key>
<arg_value>{arg-value-2}</arg_value>
...
</tool_call><|system|>
You are a helpful assistant.<|user|>
Today is June 26, 2024. Could you please check the weather in Beijing and Shanghai for tomorrow<|
assistant|>
<think>The user wants to check the weather of Beijing and Shanghai tomorrow. I need to call the
get_weather function respectively to check Beijing and Shanghai.</think>
I will call the get_weather function to check the weather in Beijing and Shanghai.
<tool_call>get_weather
<arg_key>city</arg_key>
<arg_value>Beijing</arg_value>
<arg_key>date</arg_key>
<arg_value>2024-06-27</arg_value>
</tool_call>
<tool_call>get_weather
<arg_key>city</arg_key>
<arg_value>Shanghai</arg_value>
<arg_key>date</arg_key>
<arg_value>2024-06-27</arg_value>
</tool_call><|observation|>
<tool_response>
{"city": "Beijing", "date": "2024-06-27", "weather": "Sunny", "temperature": "26C"}
</tool_response>
<tool_response>
{"city": "Shanghai", "date": "2024-06-27", "weather": "Overcast", "temperature": "29C"}
</tool_response><|assistant|>
<think>I have obtained the weather query results of get_weather for Beijing and Shanghai respectively and
can reply to users directly.</think>
It will be sunny in Beijing tomorrow with a temperature of 26 degrees Celsius. The weather in Shanghai is
overcast with a temperature of 29 degrees Celsius.<|user|>
这种方法将函数名、参数键和值都封装在 <tag_name>...</tag_name> 这样的标签中,极大地减少了代码片段作为参数时的转义需求,使得绝大多数代码可以原生形式表示。实验证明,这种新模板在不牺牲函数调用执行性能的同时,有效降低了模型的学习难度。
3.2 推理强化学习 (Reasoning RL)
Reasoning RL 专注于提升模型在需要逻辑推导、结构化问题解决和可验证准确性的领域(如数学、代码生成、科学推理)的能力。
-
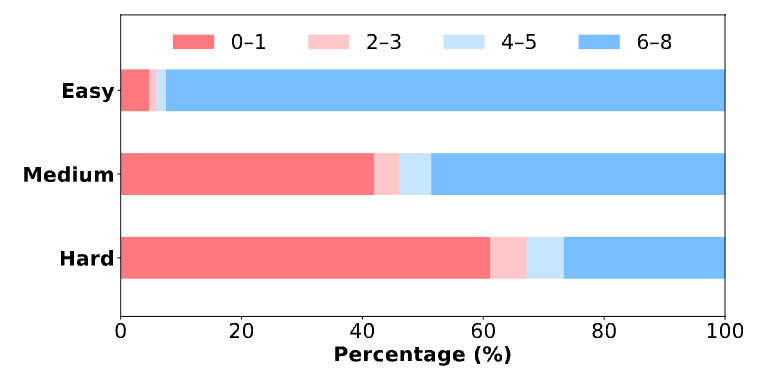
基于难度的课程学习 (Difficulty-based Curriculum Learning):在强化学习过程中,模型的熟练度是动态变化的。如果一直使用静态的训练数据,在后期,简单的任务无法提供有效的学习信号(奖励总是1),而在早期,过难的任务也同样无效(奖励总是0)。为了解决这个问题,团队采用了两阶段的、基于难度的课程学习策略。 -
第一阶段:使用中等难度的数据进行训练。 -
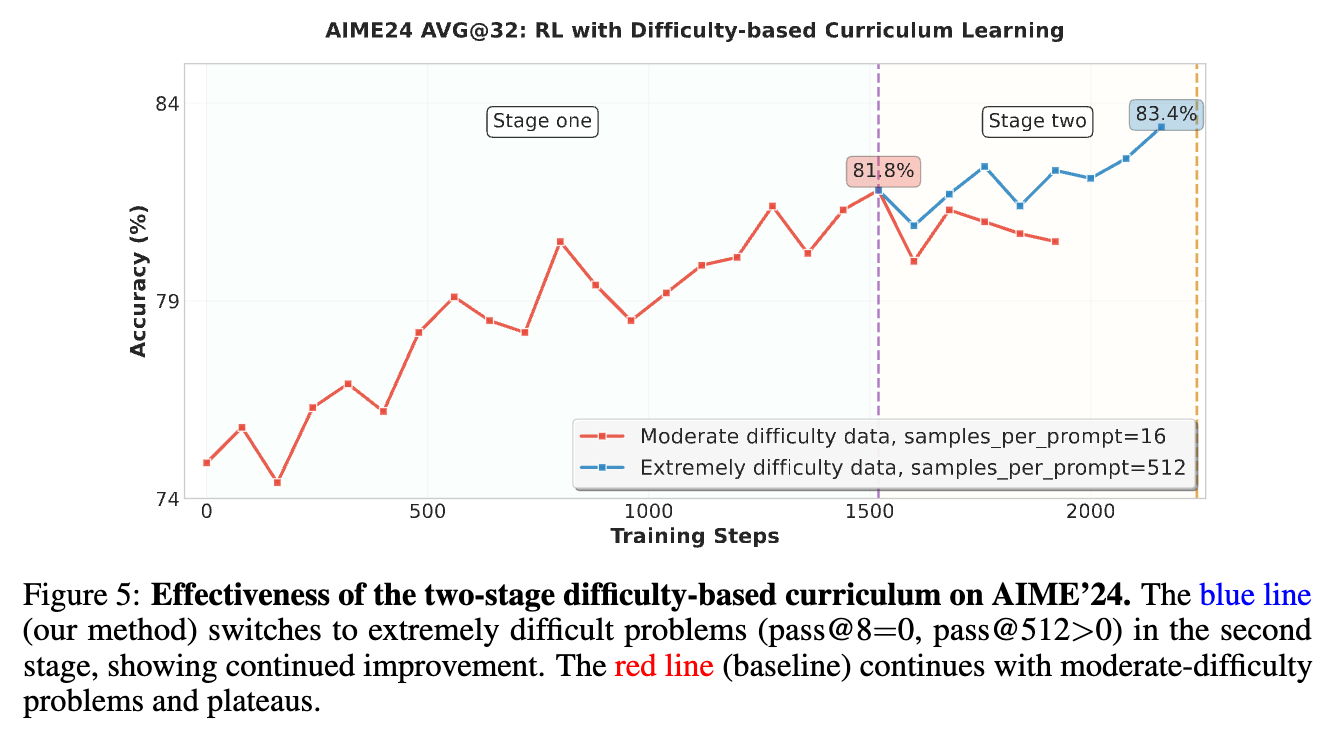
第二阶段:当模型性能达到平台期时,切换到极高难度的数据(例如,pass@8=0,但 pass@512>0 的问题,意味着用少量样本无法解决,但大量采样有可能解决的难题)。从图5中可以看到,切换到极难问题后(蓝线),模型的性能突破了平台期并持续提升,而基线(红线)则停滞不前。
-
-
64K 输出长度的单阶段 RL:与一些研究提出的多阶段、逐步增加最大输出长度的 RL 方法不同,GLM-4.5 的实验表明,直接在目标最大长度(64K)上进行单阶段 RL 更为有效。如果在已经适应了长输出的 SFT 模型上引入较短输出长度的 RL 阶段,可能会导致模型“遗忘”其长上下文能力,造成难以恢复的性能下降。
3.3 智能体强化学习 (Agentic RL)
Agentic RL 的目标是让模型更可靠地遵循指令,尤其是在需要与外部环境(如网络搜索、代码执行)交互的场景中。
-
数据收集与合成:团队为网络搜索和软件工程任务开发了数据合成流水线。对于网页搜索,他们通过知识图谱上的多跳推理和人工循环来创造需要多步推理才能回答的问题。对于软件工程,他们收集了大量的 GitHub PR 和 issues 来构建真实的开发基准。 -
迭代蒸馏 (Iterative Distillation):由于在智能体任务上进行 RL 训练非常耗时,团队采用了一种自蒸馏的方法来迭代提升模型性能。具体流程是: -
在初始的 SFT 模型上进行 RL 训练,提升其智能体能力。 -
当训练达到一定步数或平台期时,使用这个 RL 训练过的模型来生成新的、质量更高的响应数据。 -
用这些新数据替换掉原始的 SFT 数据,创建一个更优越的 SFT 模型。 -
在这个增强版的 SFT 模型上进行下一轮 RL 训练。
这个迭代过程能够高效地推动 RL 训练模型的性能上限。
-
3.4 通用强化学习 (General RL)
通用 RL 旨在全面提升模型的整体性能,修复潜在问题,并强化关键能力。其核心是一个多源反馈系统,协同利用了:
-
基于规则的反馈 -
人类反馈 (RLHF) -
基于模型的反馈 (RLAIF)
这种混合框架提供了更鲁棒的训练信号。
-
指令遵循 RL (Instruction Following RL):为了让模型能更好地理解和满足复杂指令,团队创建了一个包含7个大类和151个细分类别的约束类型分类法。基于此,他们构建了一个专门的、具有挑战性的指令训练集。反馈系统由确定性验证规则、一个训练好的奖励模型和一个批判模型(critique model)组成。
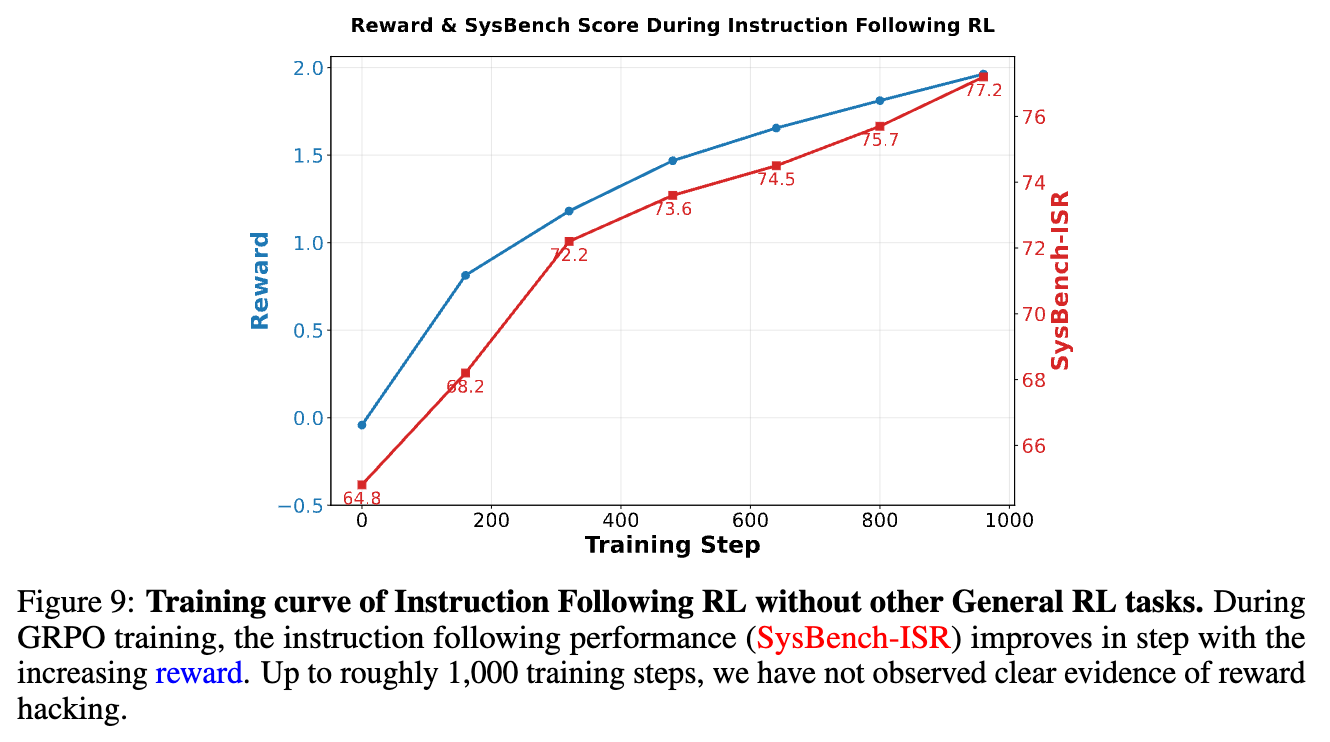
图中显示,随着奖励的增加,模型在 SysBench-ISR 上的性能稳步提升,且没有出现明显的奖励过拟合(reward hacking)现象。
-
函数调用 RL (Function Calling RL):分为两部分: -
基于规则的逐步 RL:对于有明确工具调用流程的任务,模型被训练在每个步骤生成正确的函数调用。奖励函数非常严格:只有当生成的函数调用格式正确且与真实标签完全匹配时,奖励才为1,否则为0。 -
端到端的多轮 RL:为了让模型能处理更复杂的、需要自主探索和规划的动态任务,团队引入了端到端 RL。模型需要生成完整的交互轨迹,并根据最终的任务完成情况获得奖励。
-
3.5 强化学习基础设施:Slime
所有 RL 训练都构建在一个名为 Slime 的自研开源框架之上。该框架经过精心设计和优化,以提高灵活性、效率和可扩展性。其核心设计包括:
-
灵活的混合训练与数据生成架构:支持同步、同地(colocated)和异步、解耦(disaggregated)两种模式。对于通用 RL 任务,同步模式能最大化 GPU 利用率;而对于软件工程这类数据生成过程漫长的智能体任务,异步模式能让智能体环境持续生成数据而不被训练周期阻塞。 -
混合精度推理加速 Rollout:训练时使用 BF16,而在数据生成(Rollout)阶段,通过在线的、逐块的 FP8 量化,使用 FP8 进行推理,极大地提升了数据收集过程的吞吐量。
4. 实证为王:全面的性能评测
“是骡子是马,拉出来遛遛”。GLM-4.5 在一系列广泛而严苛的基准测试中证明了其实力。评测覆盖了从基础模型能力到 ARC 各个方面,再到安全性和实际用户体验的方方面面。
4.1 基础模型评测
在进行任何指令微调之前,团队首先评估了 GLM-4.5-Base 模型的性能,并与其他代表性的开源基础模型进行了比较。
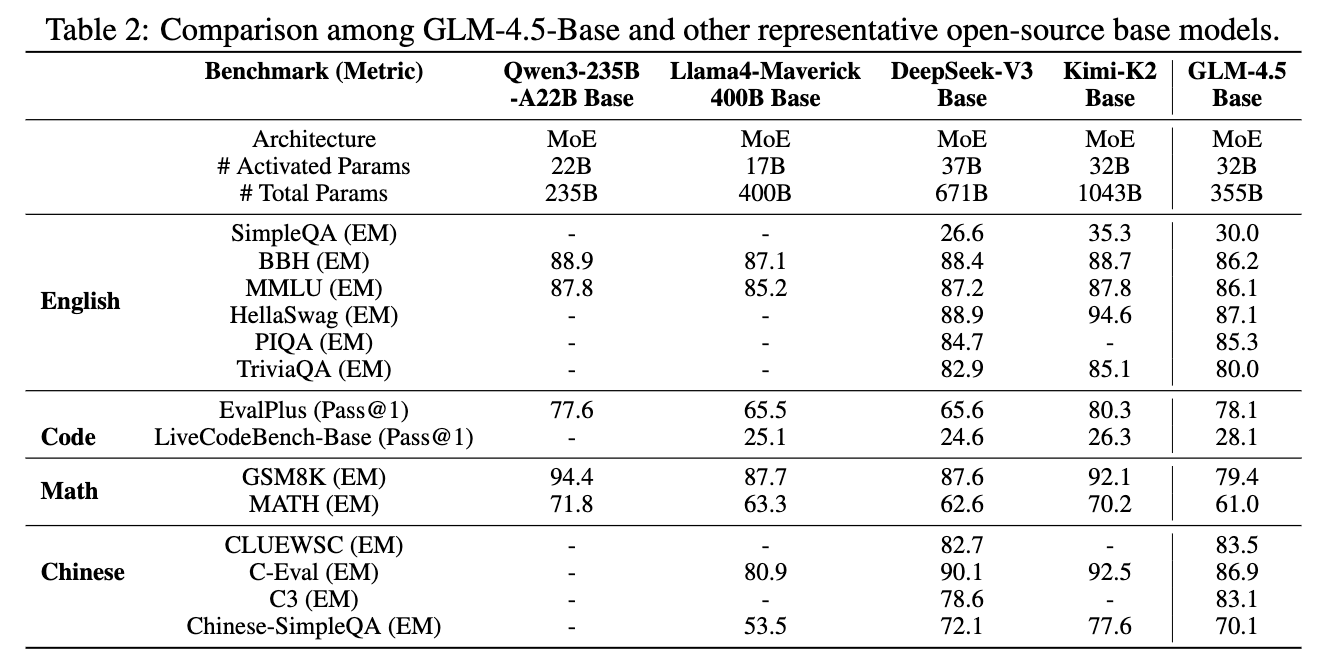
结果显示,GLM-4.5-Base 在英语、代码、数学和中文等所有不同基准上都表现稳定,验证了团队将所有能力统一到一个模型中的想法是成功的。例如,在代码评测 EvalPlus (Pass@1) 上,GLM-4.5-Base 取得了 78.1 的高分,与 Qwen3-235B 的 77.6 相当。在中文 C-Eval 上也取得了 86.9 的好成绩。
4.2 12项 ARC 基准综合评测
后训练完成后,完整的 GLM-4.5 模型在覆盖 ARC 三个维度的 12 个基准上进行了全面评估。这些基准包括 MMLU-Pro, AIME 24, MATH-500, SciCode, GPQA, HLE, LCB, SWE-Bench Verified, Terminal-Bench, TAU-Bench, BFCL V3, BrowseComp。
4.2.1 智能体能力评测
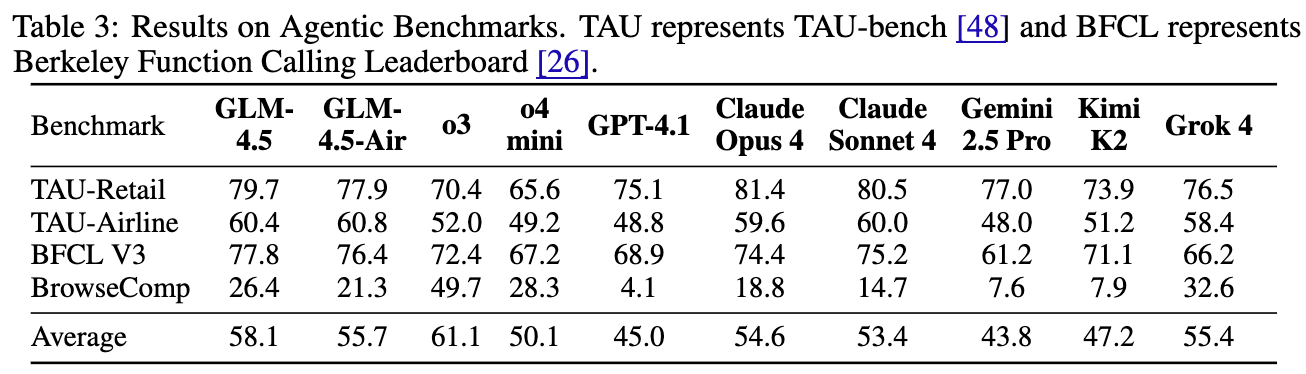
在智能体能力方面,GLM-4.5 的表现极其亮眼。
-
在 TAU-bench(一个评估模型在零售和航空领域与用户交互能力的基准)上,GLM-4.5 的性能超越了 Gemini 2.5 Pro,并与 Claude Sonnet 4 非常接近。 -
在 BFCL V3(伯克利函数调用排行榜)上,GLM-4.5 在所有基线模型中取得了最高的总分。 -
在 BrowseComp(一个衡量网页浏览智能体能力的基准)上,虽然 OpenAI o3 表现一骑绝尘,但 GLM-4.5 的性能接近于第二好的模型(o4-mini),并显著优于 Claude Opus 4。
综合来看,GLM-4.5 的智能体能力在所有参评模型中位居第二,仅次于 OpenAI 的模型,这充分展示了其在与外部世界交互方面的强大实力。
4.2.2 推理能力评测
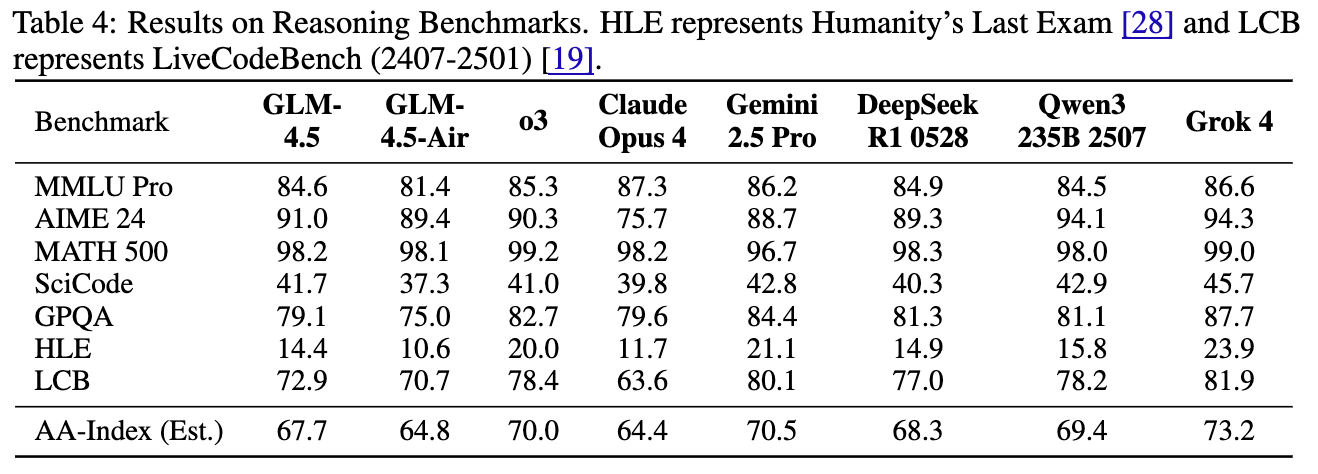
推理能力是衡量模型“智商”的硬指标。
-
在极具挑战性的 AIME 24 数学竞赛基准上,GLM-4.5 取得了 91.0% 的惊人分数,超越了 OpenAI o3 (90.3%)。 -
在 SciCode 基准上,GLM-4.5 同样超越了 o3。 -
根据 Artificial Analysis 提出的智能指数(AA-Index)进行估算,GLM-4.5 的平均推理性能(67.7)优于 Claude Opus 4(64.4),并非常接近 DeepSeek-R1-0528(68.3)。
4.2.3 编码能力评测
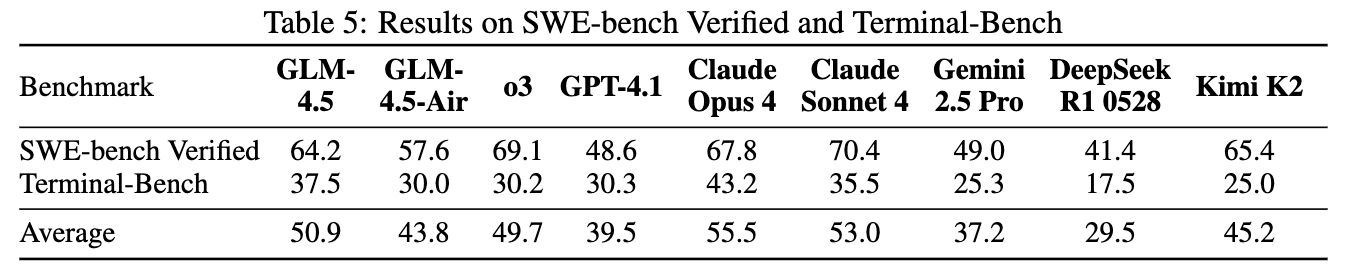
在编码能力方面,GLM-4.5 同样表现出色。
-
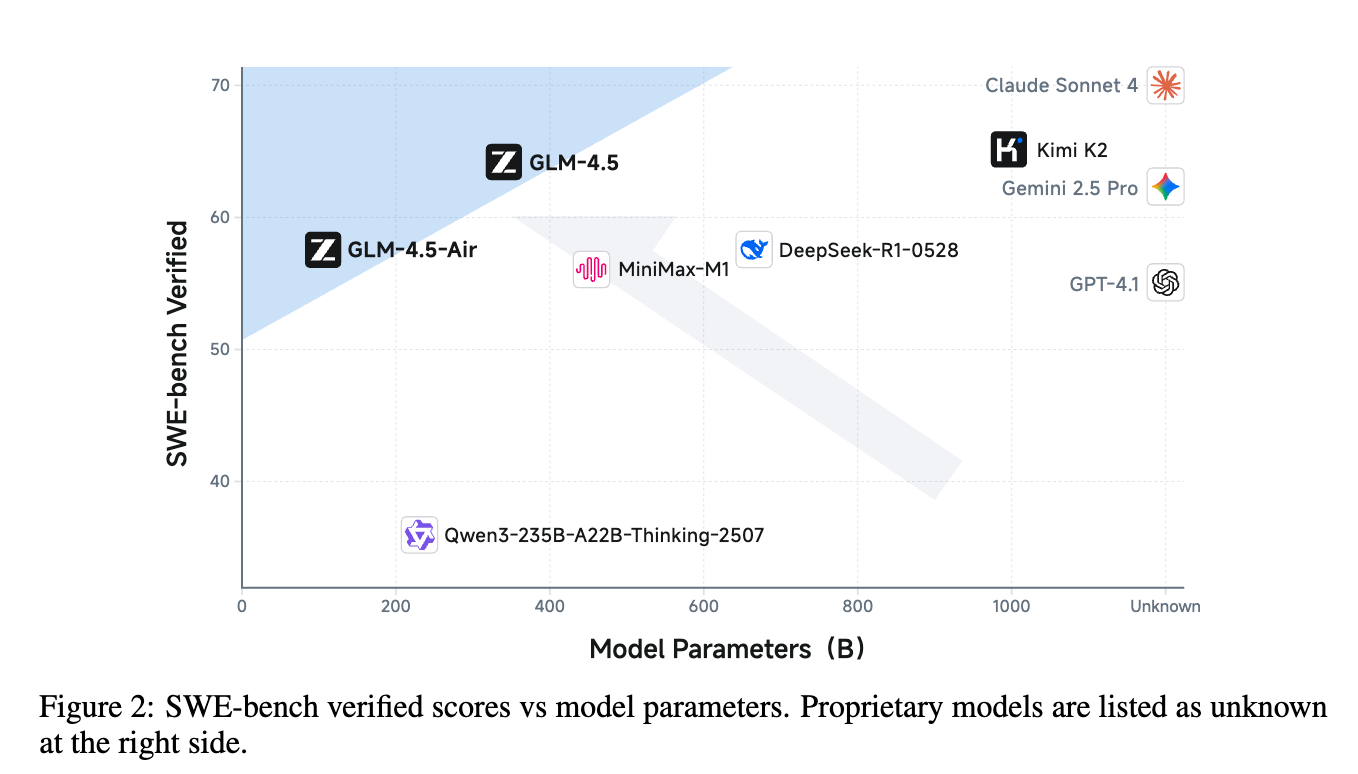
在 SWE-bench Verified(一个衡量模型修复真实 GitHub issue 能力的基准)上,GLM-4.5 (64.2%) 显著优于 GPT-4.1 (48.6%) 和 Gemini-2.5-Pro (49.0%),非常接近 Claude Sonnet 4 (70.4%)。从参数与性能的帕累托前沿图(Figure 2)可以看出,GLM-4.5 和 GLM-4.5-Air 处于非常高效的位置。 -
在 Terminal-Bench(一个衡量模型在终端环境中完成复杂任务能力的基准)上,GLM-4.5 甚至超越了 Claude Sonnet 4。 -
平均来看,GLM-4.5 是 Claude Sonnet 4 在编码任务上最有力的竞争者。
4.3 通用、安全与体验评测
除了硬核的 ARC 能力,模型在通用对话、安全性以及真实场景下的主观体验也至关重要。
-
通用对话能力:
在 MMLU, IFEval, SysBench, MultiChallenge 等一系列通用评测中,GLM-4.5 表现稳健。特别是在反映模型真实知识水平的 SimpleQA 上,GLM-4.5 (355B) 的表现与参数量几乎是其两倍的 DeepSeek V3/R1 (均为 671B) 相当。在指令遵循评测 IFEval 和 SysBench 上,GLM-4.5 超越了 GPT-4.1 和 DeepSeek R1 等多个强劲对手。 -
安全性评测:
在全面的安全基准 SafetyBench 上,GLM-4.5 的总分(89.9)与 Kimi-K2 (90.5) 和 GPT-4.1 (89.7) 等顶级模型不相上下,展现了强大的安全对齐能力。 -
动手体验(人工评测):
为了评估模型在真实、开放式问题上的表现,团队进行了一项全面的人工评测。他们精心构建了一个包含 660 个高质量提示的数据集,覆盖英语、中文和其他多种语言,以及数学、文本处理、主/客观问答、逻辑、代码等多个类别。-
英语评测结果:GLM-4.5 在英语提示上获得了最高的总分,尤其在数学、客观问答和文本生成方面表现突出。 -
中文评测结果:在中文提示上,GLM-4.5 再次领先,在文本生成、逻辑推理和代码指令方面表现出色。 -
其他语言结果:在多语言评测中,GLM-4.5 保持了其领先地位。
-
4.4 智能体编码与前沿能力专项评测
真实世界开发场景下的智能体编码 (CC-Bench)
为了评估 GLM-4.5 在真实软件开发场景中的智能体编码能力,团队构建了一个名为 CC-Bench 的新基准。该基准基于 Claude Code,包含了 52 个精心设计的编程任务。评测由人类专家与模型进行多轮交互来完成。
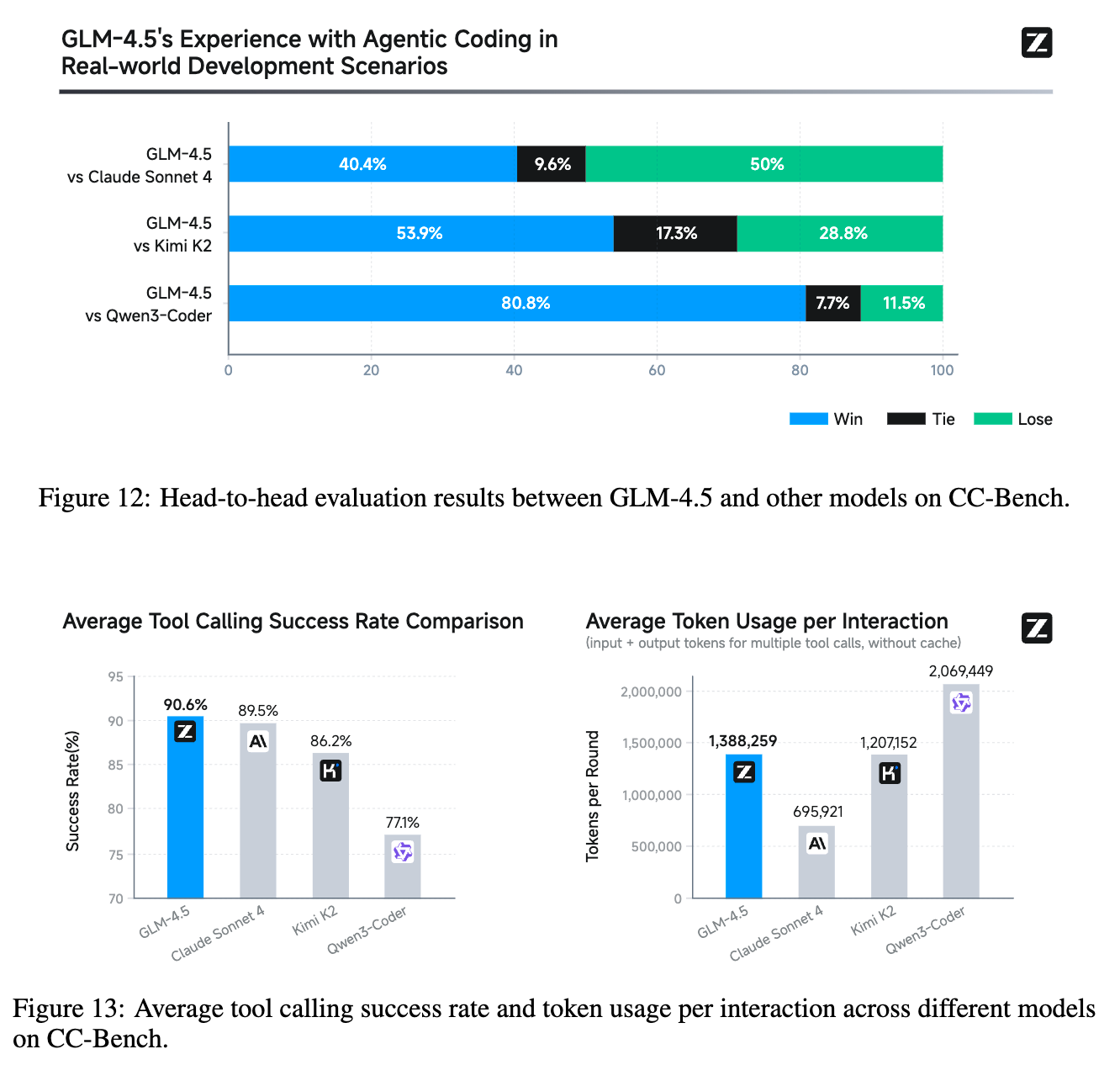
结果令人印象深刻:
-
头对头胜率:GLM-4.5 对 Kimi K2 的胜率为 53.9%,对 Qwen3-Coder 的胜率高达 80.8%。虽然与 Claude Sonnet 4 的对抗中略处下风(40.4% 胜,50.0% 负),但考虑到 Sonnet 4 在编码领域的强大实力,这一结果已极具竞争力。 -
工具调用可靠性:GLM-4.5 在工具调用可靠性方面表现最佳,成功率达到了 90.6%,高于 Claude Sonnet 4 (89.5%)、Kimi-K2 (86.2%) 和 Qwen3-Coder (77.1%)。这表明 GLM-4.5 在任务完成的一致性和智能体执行的鲁棒性方面具有明显优势。
新颖逻辑推理与深度上下文翻译
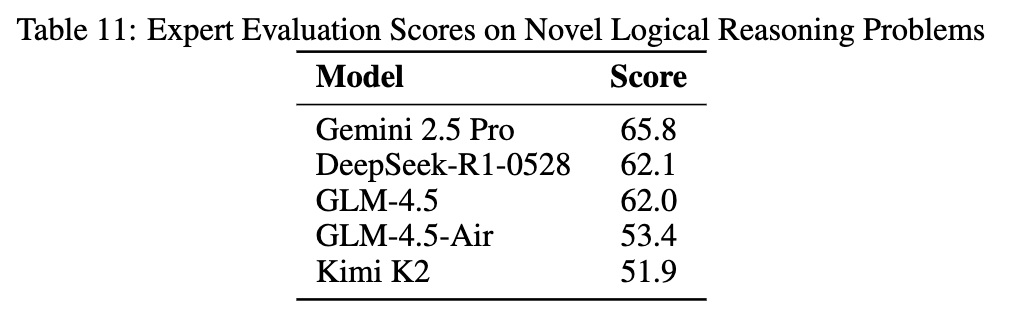
-
新颖逻辑推理:为了测试模型真正的逻辑推理能力,而非“背题”,团队构建了一套全新的、网上不存在的复杂逻辑推理问题。
表11结果显示,GLM-4.5 (62.0) 的表现与 Gemini 2.5 Pro (65.8) 和 DeepSeek-R1-0528 (62.1) 处于同一梯队,展现了强大的原生推理能力。 -
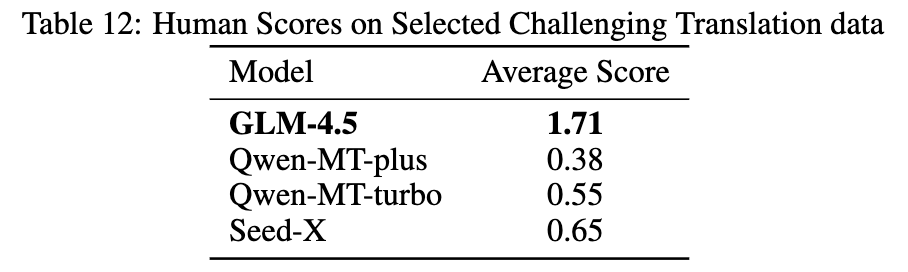
新范式翻译:现代翻译任务远不止字面转换,更需要对网络俚语、文化背景和领域术语的深刻理解。 -
网络俚语:如准确翻译“yyds”为“the eternal god”。 -
领域昵称:如识别摄影圈中的“爱死小白胖”是指代佳能某款镜头。 -
文化符号:如理解中文语境下“咸鱼”表情包可能指代二手交易平台。 -
深度上下文推理:如将“三花公主驾到,速来围观”准确翻译为“The Calico Princess has arrived! Come and see!”,理解“三花”在此处指代一种猫的花色,而非人名。
表12,在一项包含 100 个这类挑战性案例的盲评中,GLM-4.5 (平均分 1.71) 显著优于多个专业的翻译模型(如 Qwen-MT-plus 的 0.38)。
-
往期文章:
-清华&美团首次揭秘MoE:从“Massive Activations”到“Attention Sink”,探寻“超级专家”的机制
-Diffusion:真正的王牌不是“快”,而是“超级数据学习者”