25
2025/09

北大 & 字节 Seed 提出 DACE:难度感知下的确定性引导探索
我们能否在不引入昂贵的过程监督(process supervision)的前提下,为模型提供更细粒度的学习信号?是否存在一种源自模型内部的、能够反映其推理状态
...
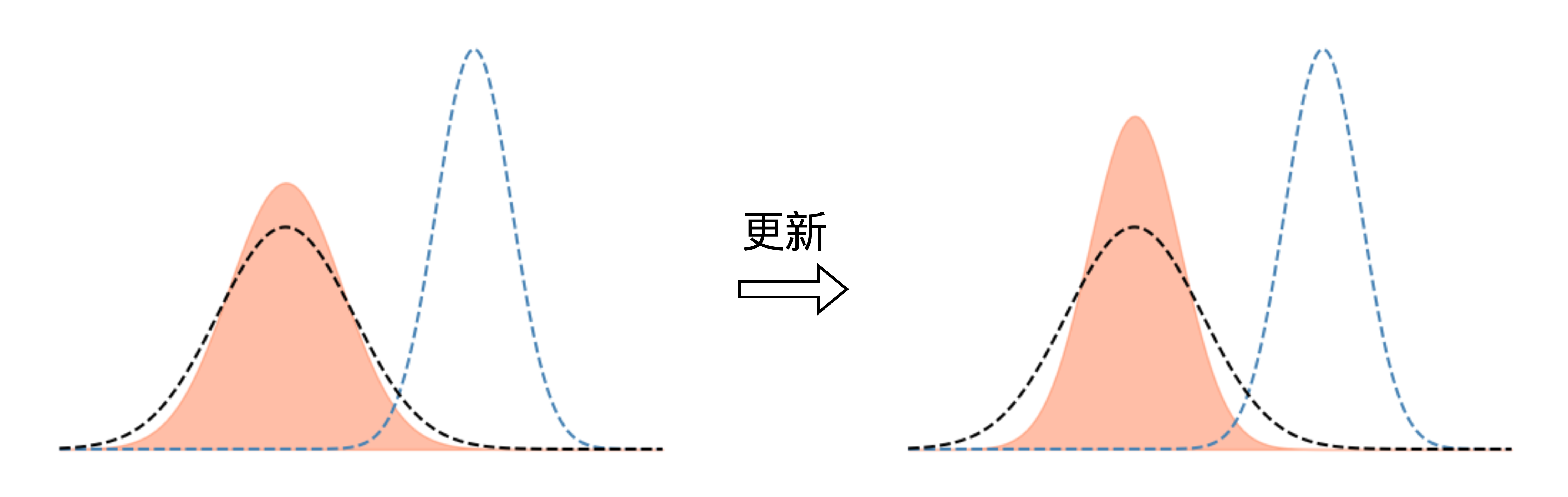
从“方差坍塌”到“探索失效”:深入剖析强化学习在大型语言模型中的核心挑战
前言:当LLM遇见强化学习,是火花还是陷阱?
近年来,大型语言模型(LLM)与强化学习(RL)的结合,特别是以人类反馈强化学习(RLHF)为代表的技术,已成为
...