让每一项优秀工作,被更多人看见:点击进入投稿通道
论文追踪 APP 推荐:DailyPapers

-
论文标题:Why Supervised Fine-Tuning Fails to Learn: A Systematic Study of Incomplete Learning in Large Language Models -
论文链接:https://arxiv.org/pdf/2604.10079
TL;DR
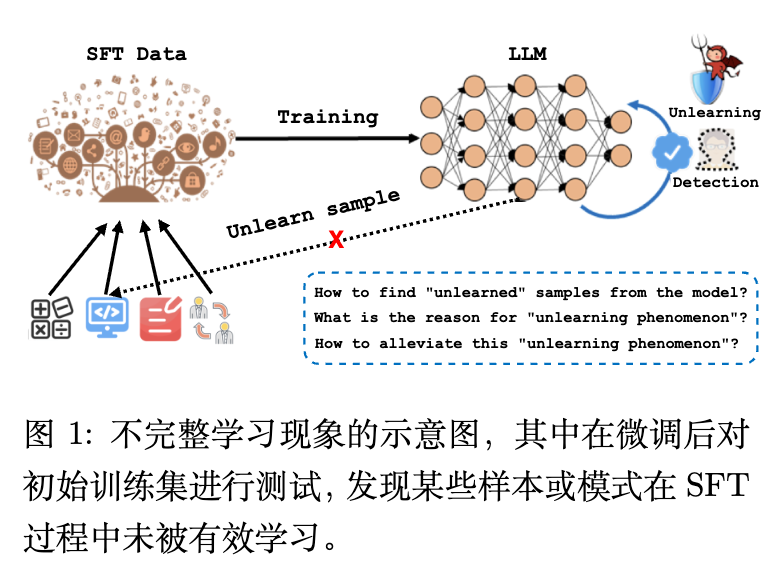
今天解读一篇来自新南威尔士大学(UNSW)、腾讯混元与北京大学等机构合作的论文《Why Supervised Fine-Tuning Fails to Learn: A Systematic Study of Incomplete Learning in Large Language Models》。在大型语言模型(LLM)的对齐与适应阶段,监督微调(SFT)已成为标准范式。然而,研究者在实践中观察到一个普遍存在的失效模式:即使训练损失已经收敛且经过了充分的超参数搜索,模型仍然会持续在 SFT 训练集自身的部分样本上预测错误。这种现象不同于灾难性遗忘,也不同于机器废除学习,被作者定义为不完全学习现象(Incomplete Learning Phenomenon, ILP)。
本文提出了一个系统性的诊断框架,从逐样本的视角考察了模型为何无法内化特定的监督信号。通过广泛的实证分析,作者将 ILP 的成因归结为五个维度:基础模型的先验知识局限、SFT 数据与基础模型的知识冲突、SFT 数据内部的标注冲突、序贯训练引发的左侧遗忘,以及对复杂模式的优化不足。为了探究这些原因,作者引入了基于多次采样和多项选择的后验评估方法,以准确定位未学习的样本。
在关键结论方面,研究表明简单的增加 SFT 训练轮数无法有效解决 ILP,特别是当问题源于基础模型缺乏先决条件知识或存在强烈的错误先验时。针对性地引入继续预训练(CPT)注入外部知识、采用冲突感知的动态分桶策略以及基于精度下降的动态重采样,能够有效提高模型对监督数据的掌握度。实验结果显示,通过这些细粒度的干预,模型不仅在特定领域(如医疗、法律)的准确率获得了实质性提升,也为我们理解并改善大模型的知识习得过程提供了新视角。
1. 引言
监督微调(Supervised Fine-Tuning, SFT)是将预训练大型语言模型(LLMs)适配到下游应用(如问答、对话生成和特定领域推理)的主要手段。利用相对较小但经过精心策划的标注数据集,SFT 使预训练模型能够将自身行为与特定任务目标对齐,同时保留通用的语言能力。
尽管 SFT 被广泛采用,但作者指出了一个容易被忽略的失效模式:在 SFT 阶段,聚合的评估指标(如整体的准确率或困惑度)可能会掩盖模型在特定样本上的持续失败。在实际操作中,即使训练损失已经收敛,模型在面对 SFT 训练集自身的特定样本时,依然无法输出正确的监督响应。这种失败在跨越不同的随机种子和评估设置时表现出稳定性,说明它并非单纯的随机噪声。
作者将这种行为正式命名为不完全学习现象(Incomplete Learning Phenomenon, ILP)。
ILP 与其他常见的微调问题有本质区别:
-
它不同于灾难性遗忘(Catastrophic Forgetting)(McCloskey and Cohen, 1989),后者关注的是模型丧失了先前获得的通用能力。 -
它也不同于机器废除学习(Machine Unlearning)(Cao and Yang, 2015),后者是出于隐私或安全目的的人为故意擦除。
ILP 反映的是模型在 SFT 期间未能获取或内化部分监督信号。理解 ILP 具有实际意义:首先,特定领域的 SFT 数据集(如法律、医学)构建成本高昂,不完全学习直接降低了数据效用;其次,未被学习的样本通常对应于罕见情况、组合模式或知识密集型实例,这些盲区会影响模型的鲁棒性与可靠性。
2. 未学习样本的检测与诊断机制
要研究不完全学习,首要前提是建立一套可靠的测量机制,以在微调结束后识别出哪些监督实例未被有效学习。作者将此视为一个后训练测量问题,而非优化目标。
2.1 样本级一致性评估
由于 SFT 数据集通常由自由形式的文本响应组成,采用传统的文本生成指标难以在不同任务间进行标准化评估。为此,作者将监督响应操作化为多项选择(Multiple-Choice, MC)格式。
对于每个 SFT 实例,原始的监督响应作为正确选项被保留,同时利用大模型构造若干个语义合理但事实上错误的干扰项。微调后的模型需要在这些固定候选集中进行选择。在此设定下,对于包含 个实例的训练集,其准确率定义为:
这里, 表示模型为第 个实例的第 个选项预测的概率, 是正确选项的索引。 是指示函数,当条件成立时取 1,否则取 0。这种转换仅用于检测与分析,不改变原始 SFT 的自由生成训练目标。
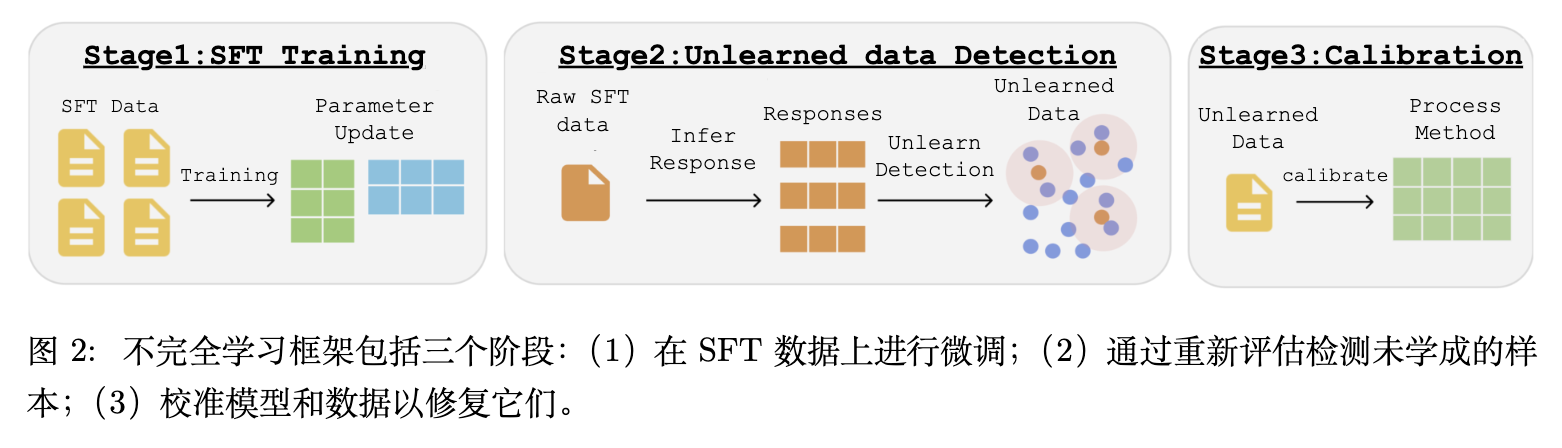
2.2 鲁棒检测与阈值设定
单一的预测具有随机性,因此作者引入了重复采样来降低方差。对于每个实例,执行 次独立推理并计算其 pass@N 胜率(即模型预测正确的次数占比)。同时,采用 Best-of-N (BoN) 标准,在 个采样中选择置信度最高的预测,以此作为模型能力的上限估计。
如果一个实例的 pass@N 胜率低于预设阈值 (在本文实验中,,采用 BoN-5 采样),则认为该实例处于未学习状态。经验验证表明,这样筛选出的实例在不同轮次间保持稳定,排除了随机解码伪影的可能。
实验表明 ILP 是一个普遍现象。在十个基准 SFT 数据集上,平均有 15.3% 2.1% 的监督实例在收敛后仍处于未学习状态。
2.3 诊断前的知识状态探测
为了将未学习样本归因于特定成因,作者在微调之前探测了基础模型(Base Model)的知识状态。对于候选实例 ,首先测试基础模型能否在零样本(zero-shot)设定下答对,定义知识存在性的二元指标:
这里, 表示基础模型, 用于指示基础模型是否具有相关的先验知识储备。
此外,为了衡量微调前后模型预测分布的变化,作者计算了基础模型与微调后模型分布间的 Jensen-Shannon 散度(JS Divergence):
其中, 是两个概率分布的平均值, 为 KL 散度。JS 散度能够反映基础模型是否对监督信号持有强烈的冲突先验,或者在微调期间经历了不充分、不稳定的更新。
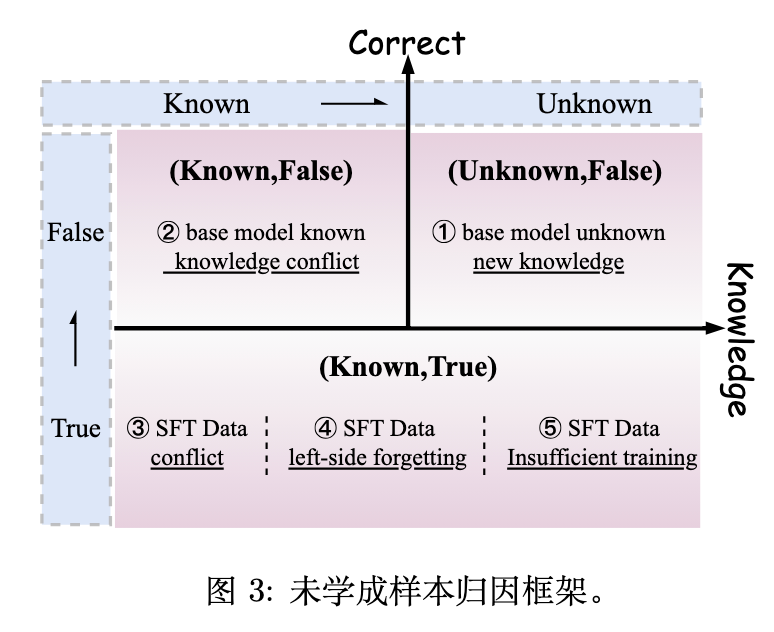
结合上述指标,作者将未学习样本归纳为五个核心类别。

3. 不完全学习的五大成因与干预策略
针对上述诊断体系,作者逐一分析了导致 ILP 的五种模式,并针对性地引入了验证策略。需要指出的是,这些策略被用作验证因果关系的控制干预手段,以证明特定成因的有效性。
3.1 基础模型知识局限(Base Model Knowledge Limitations)
当基础模型缺乏吸收监督信号所需的先决条件概念时,就会发生学习失败。利用 OpenIE 工具,作者将样本转换为实体-谓词-客体(subject-predicate-object)三元组候选集 。
盲区知识集合被定义为即使经过多次尝试仍无法回答的知识:
此处, 反映了模型在 10 次采样中恢复知识 的频率。这一过滤条件排除了由推理噪声导致的错误,保留了系统性的知识缺口。
干预策略:定位盲区后,作者通过外部知识源(如 WikiData、Google Search)为未知实体检索相关文档,构建知识增强语料库 。随后,将其与通用域语料 混合进行继续预训练(Continued Pre-Training, CPT):
比例设定(0.8:0.2)旨在显式平衡知识注入与分布稳定性,避免破坏通用语言理解能力。如果在 CPT 之后重新执行 SFT 能使这些样本被掌握,即证明知识局限是该类 ILP 的直接原因。
3.2 SFT 与基础模型间的知识冲突(Conflicts Between SFT and Base Model)
在某些情况下,基础模型不仅缺乏相关知识,甚至持有一套与 SFT 监督信号相左的、根深蒂固的错误信念。这些冲突导致模型在微调期间表现出高度的抗拒性。
为了量化这一点,作者计算了基础模型对不正确答案的置信度。当模型强烈偏好错误答案时,将其标记为高置信度错误:
其中 为预设的置信度阈值, 是模型预测结果为 的概率, 为 SFT 提供的真实标签。
干预策略:对于这一类冲突,单纯增加微调轮数往往无济于事。作者沿用了上述的 CPT 流程,用维基百科和特定领域语料库提供的权威正确信息,重新对齐模型的内部知识表示,削弱其对 SFT 更新的抗拒性。
3.3 SFT 数据内部冲突(Knowledge Conflicts Within SFT Data)
如果 SFT 数据集本身存在噪声或标注不一致,例如语义相似的输入关联了相互矛盾的标签,模型将接收到不一致的梯度信号。作者通过计算样本对之间的语义相似度 来检测这一现象。如果相似度大于阈值 ,则这对样本被视为潜在冲突。
干预策略:引入外部评估器(如 GPT-4 或 DeepSeek)判断正确性。如果两个样本均被判断为正确(即存在一词多义、多视角合理性等情况),简单的删除会损失信息。作者采用动态分桶(Dynamic Bucketing)机制:将冲突样本分配到不同的训练桶中,确保它们不会在同一个 mini-batch 中共现。桶的分配每隔 个训练步重新评估一次。通过隔离矛盾样本,模型能更有效地吸收高质量信息。
3.4 左侧遗忘(Left-Side Forgetting)
在多任务或混合域数据集上按顺序执行 SFT 时,模型倾向于系统性地偏好最近看到的数据。早期批次中学到的监督知识会被逐渐掩盖,造成左侧遗忘。
干预策略:实施全局混洗(Global Shuffling),并配合动态重采样(Dynamic Resampling)。算法每隔 步监控每个数据子集的验证准确率变化 。如果某个子集的精度下降超过阈值 (即发生了遗忘),则从该子集中提取样本重新加入当前的训练批次中。
3.5 优化不足(Insufficient Training)
由于 SFT 数据集中存在长尾或结构复杂的模式,固定轮次(Epoch)的训练无法为其提供充足的梯度更新,导致残留误差。
干预策略:采用受早停法(Early Stopping)启发的渐进式轮次增加(Progressive Epoch Increment)策略。设定基础轮次 ,只要验证集性能持续提升就增加轮次,直到触发停止条件:
这里, 为第 轮的验证集损失, 是一个容忍裕度,用于防止因噪声导致的过早终止。
4. 实验验证与结果分析
作者在 Qwen(7B/14B)、LLaMA2(7B/13B)以及最近开源的 OLMo2-7B 等基座模型上进行了广泛的验证。
4.1 基础模型知识增强实验
针对缺乏先验知识造成的 ILP,应用 CPT 策略能够显著改善特定领域 SFT 数据集的最终表现。
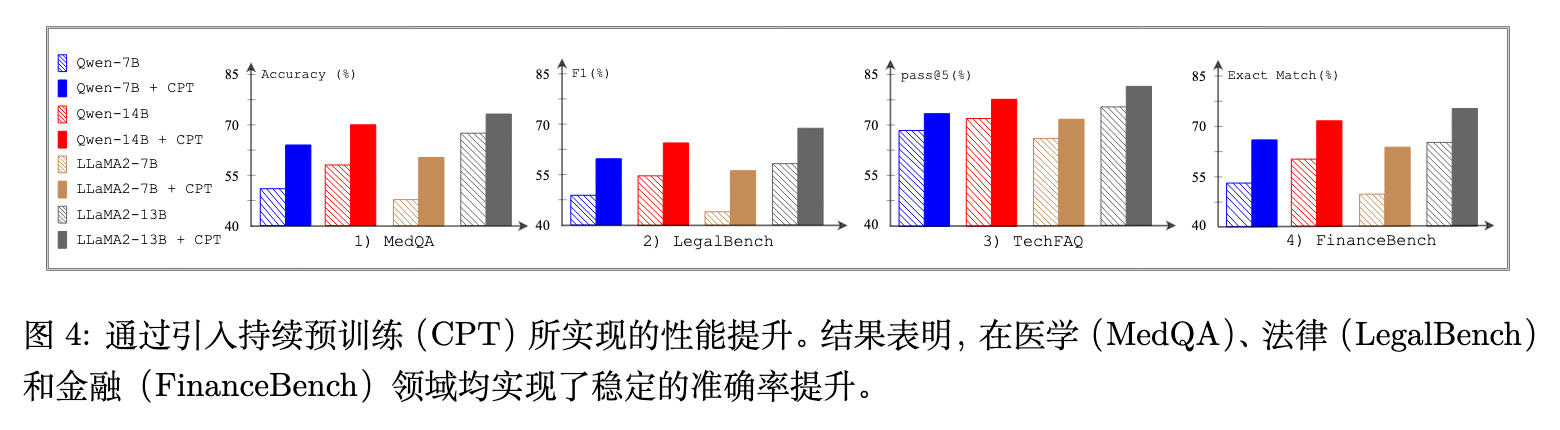
如图 4 所示,在医疗(MedQA)、法律(LegalBench)和金融(FinanceBench)基准上,CPT 带来了 9.4% 到 14.1% 不等的准确率提升。例如,在 MedQA 上实现了 +12.5% 的涨幅。
一个关键对照发现是:简单地将 SFT 的训练轮次从 2 轮增加到 10 轮,只带来了极边缘的性能改善(涨幅约 1.2%)。这证实了缺失的基础事实知识不能通过延长指令微调的时间来无中生有,必须在预训练阶段(或 CPT 阶段)进行注入。
4.2 知识冲突校准效果
对于因 SFT 监督信号与模型内部先验矛盾而导致的未学习现象,CPT 校准策略同样有效。
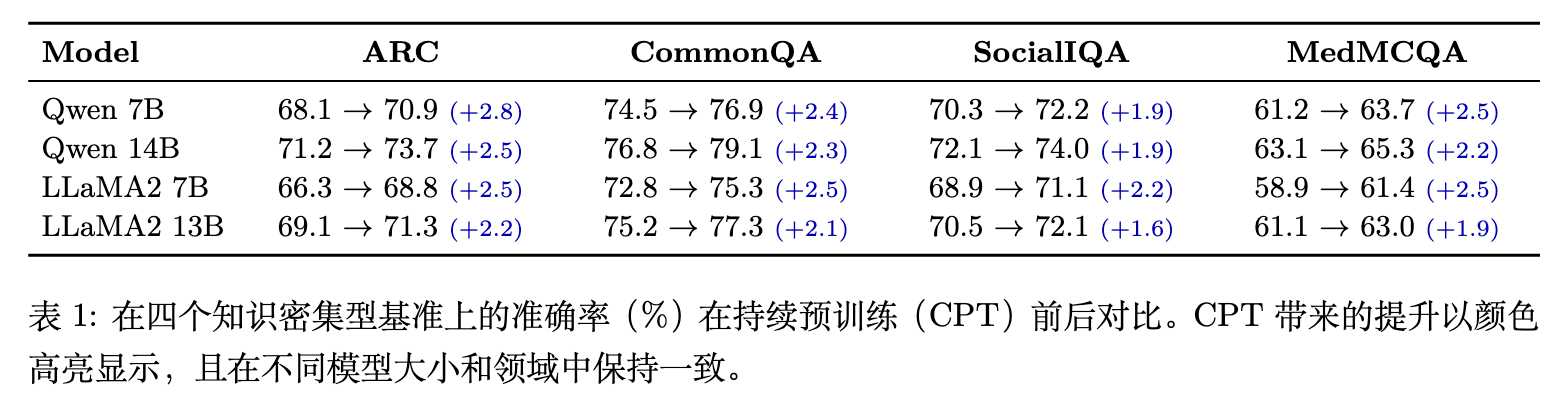
从表 1 可以看出,在 ARC、CommonQA 等依赖常识和科学事实的数据集上,经过 CPT 减少内部冲突后,各尺寸模型的准确率均获得提升(如 Qwen-7B 在 ARC 上提升了 2.8%,Qwen-14B 提升了 2.5%)。这种改进对应于高置信度冲突样本的实质性减少,说明模型修正了原有的顽固偏见。
4.3 应对数据冲突、左侧遗忘与优化不足
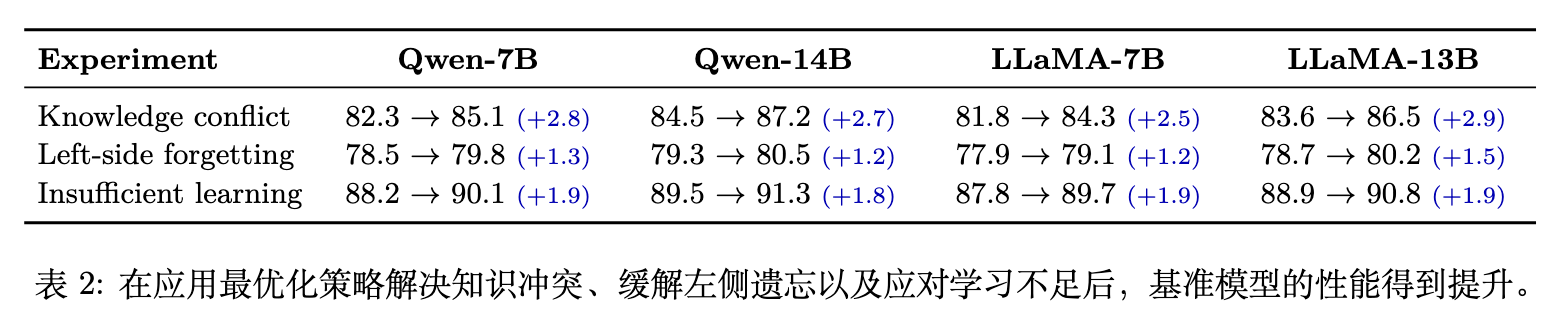
针对另外三种原因,应用所提出的对应策略(动态分桶、重采样、渐进训练)也表现出了稳定的改进。
-
数据内部冲突:动态分桶策略不仅在 Qwen-7B 上带来了 +2.8% 的精度提升,在消融实验中(附录 Table 8)也证明了其优于"直接删除冲突数据"的粗暴做法。保留信息并从批次层面隔离,是一种更温和且有效的干扰消减方案。 -
左侧遗忘:全局混洗结合动态重采样使模型准确率稳步增长(Qwen-14B 提升 1.2%)。更重要的是,在文本摘要任务(CNN/DailyMail)中,针对最容易遭受左侧遗忘的"前 10% 数据片段",模型的 ROUGE-L 得分从 0.41 提高到了 0.53(提升 29%),有效保留了早期能力。 -
优化不足:渐进式早停策略在防止过拟合的前提下,帮助模型多摄取了复杂数据的梯度,总体性能提升约 1.8% 左右。
4.4 OLMo2-7B 的深度剖析:知识注入与泛化能力的权衡
为了进一步剖析模型内部机制,作者分析了 OLMo2 的预训练语料库(Dolma)与其 SFT 数据之间的关系。
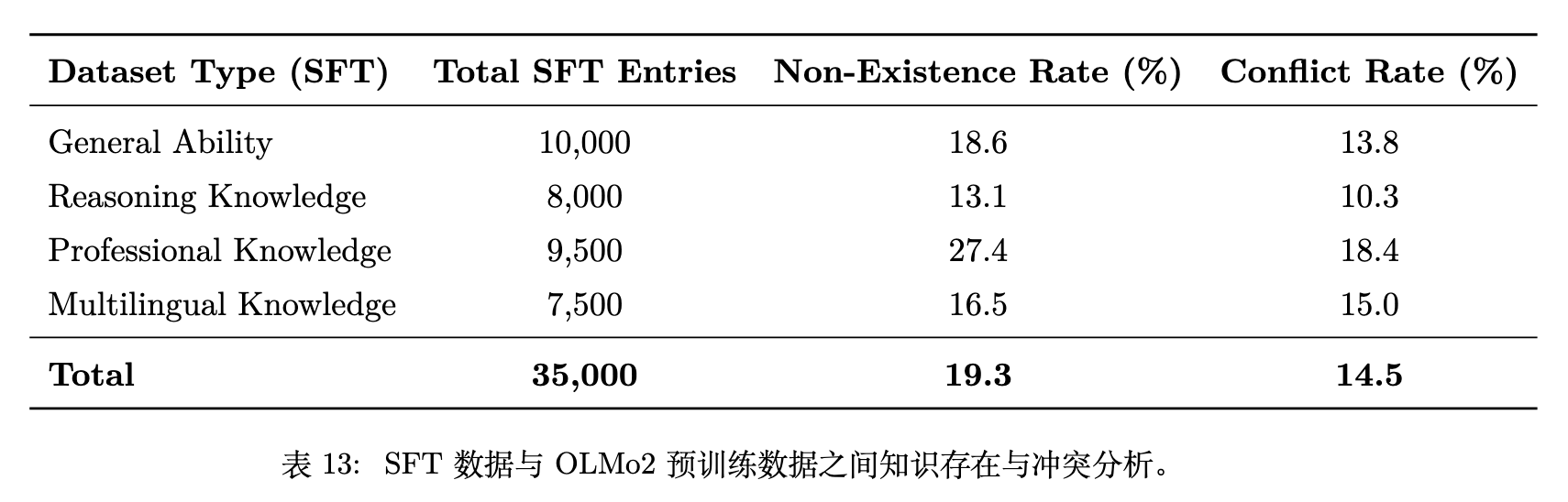
表 13 显示,在专业知识(Professional Knowledge)类 SFT 数据中,有高达 27.4% 的知识在预训练语料中是不存在的(Non-Existence Rate),同时存在 18.4% 的直接冲突(Conflict Rate)。这一客观统计直接证明了 SFT 阶段让模型学习全新知识面临着多大的先天阻碍。
然而,当向 OLMo2-7B 应用 CPT 策略后,作者观察到了一个值得探讨的现象。
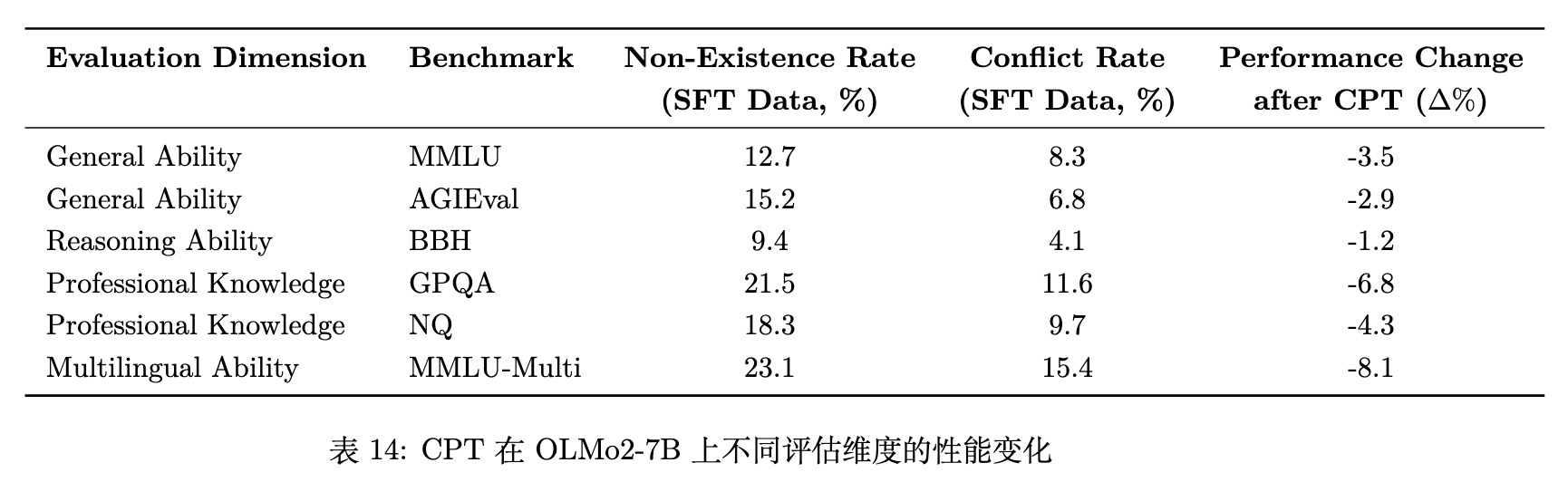
如表 14 所示,在注入专门知识后,虽然针对性冲突得以解决,但模型在广泛的泛化基准(General Ability, MMLU 等)上出现了指标下降(如 MMLU-Multi 下降了 8.1%)。
这揭示了通过 CPT 注入局部专门知识时的一个内在权衡:模型在尝试整合大量新颖信息或协调与固有偏见相矛盾的信息时,其内部表征经历了显著的认知重构。这种认知调整可能会暂时破坏依赖于旧有表征稳定性的通用能力。这一发现提示,在处理 ILP 问题时,细粒度的知识矫正往往需要配合后续更精细的对齐手段,以重新协调模型的通用能力。
5. 讨论与相关工作
本文的研究视角跨越了 SFT 领域现有的几条主线:
-
与SFT 数据质量优化(如过滤、增强或指令调优)不同,本文并未试图丢弃"坏数据",而是去理解为什么看似合理的数据在优化过程中会被阻断。 -
与灾难性遗忘(Catastrophic Forgetting)研究的侧重点不同,遗忘研究的是 任务覆盖了 任务,而本文的不完全学习表明模型连当前正在训练的 任务内部的某些区域都无法完全覆盖。 -
此外,针对模型因自身固有观念(Pre-trained bias)而拒绝服从人类指令的现象,本文从概率和冲突检测的角度给出了量化标准,这为 AI 对齐过程中的信念冲突研究提供了实证基础。
6. 总结与局限性
总结而言,本文首次系统化地解构了大模型在监督微调过程中的不完全学习现象(ILP)。研究表明:
-
模型的学习失败不仅是优化器或学习率的问题,更是知识鸿沟和数据间结构性冲突的产物。 -
通过"基于一致性的后验测量"检测未学习样本,并对其进行分类诊断是可行的。 -
增加训练 Epoch 无法弥补先决知识的缺失;必须在预训练分布层面(CPT)进行干预,或采用动态的批次/重采样级调度策略。
论文也坦诚地讨论了现有方法的局限性:
首先,冲突检测的复杂性高度依赖于高质量标注和可靠的外部工具/模型来进行验证,如果评价模型产生幻觉,可能导致次优的分桶或过滤。
其次,依赖预训练数据质量。CPT 方法假设补充语料能够弥合知识差距,但如果检索到的补充语料本身有偏或含有噪声,这些误差会随着进一步微调被放大。
最后是计算开销。在高参数量级(如十亿、百亿参数)的大模型中,额外的 CPT 阶段和动态重采样操作不可避免地增加了整体训练耗时与硬件要求。
通过从"性能导向"的聚合指标评估,转向"学习导向"的细粒度样本诊断,这项研究为我们构建更可靠、更具解释性的大语言模型适应策略奠定了基础。
更多细节请阅读原论文。

