将强化学习有效应用于 LLM 并非易事。为了加速推理和训练,现有的主流方法通常依赖于大规模并行化,但这引入了严峻的技术挑战和高昂的经济成本。例如,基于同步策略更新的分布式训练框架(如字节的 verl)虽然高效,但对节点间的低延迟通信、模型和硬件的同质性有苛刻要求。维持一个庞大的、同步的 GPU 集群不仅成本高昂,而且系统脆弱,容易出现通信瓶颈。这些因素共同构成了当前 RL 后训练规模化的核心障碍。
为了应对这些挑战,来自 Gensyn AI 团队的研究者们在 arXiv 上发布了一篇题为 "Sharing is Caring: Efficient LM Post-Training with Collective RL Experience Sharing" 的论文,提出了一种名为 Swarm sAmpling Policy Optimization (SAPO) 的新型算法。SAPO 设计了一个完全去中心化、异步的 RL 后训练框架,旨在绕开传统分布式 RL 的常见瓶颈,为语言模型的协同训练提供了一条全新的、更具可扩展性和经济性的路径。
SAPO 算法详解:构建一个“蜂群”智能体
SAPO 的核心思想源于对自然界中群体智能的观察:单个智能体(如蜜蜂、蚂蚁)的能力有限,但通过简单的信息交换和协作,整个群体能够完成复杂的任务。研究者将这一理念迁移到分布式计算中,构建了一个由异构计算节点组成的“蜂群”(Swarm)。
1. 去中心化的“蜂群”网络 (The Decentralized "Swarm" Network)
在 SAPO 的框架中,“蜂群”是一个由 个节点组成的去中心化网络。与传统分布式系统不同,SAPO 对这些节点没有严格要求:
-
异构性(Heterogeneity):节点可以在不同的硬件上运行(例如,从数据中心的 A100 到个人笔记本电脑的消费级 GPU),拥有不同的网络延迟和计算能力。 -
自主性(Autonomy):每个节点独立管理自己的策略模型 。这意味着节点间无需进行模型权重或梯度的同步,从根本上消除了同步带来的通信开销和等待瓶颈。 -
异步性(Asynchrony):节点的训练和通信是异步进行的,一个节点的延迟或掉线不会阻塞整个网络的运行。
在形式上,每个节点 拥有一个任务(或问题)集 ,其中每个问题 都有一个基准答案(ground-truth solution)。因此,节点 的数据集可以表示为:
论文强调了一个关键要求:任务必须是可验证的(verifiable)。这意味着给定一个模型生成的答案,可以通过一个高效的算法程序来判断其正确性。这一特性对于在 RL 框架中提供可靠的奖励信号至关重要。例如,在数学问题中,可以通过计算结果是否与标准答案一致来验证;在代码生成任务中,可以通过单元测试来验证。
当节点 接收到一个问题 时,它的策略模型 会生成 个不同的答案 。这一组答案构成了它对问题 的一次 "rollout" ,记作 。
2. 集体经验共享机制:轻量级的知识传播
SAPO 的创新之处在于其经验共享机制。不同于传递模型权重这种“重”数据,SAPO 的节点间仅共享解码后的 rollout,也就是纯文本形式的经验数据。
具体流程如下:
-
生成与广播:在每个训练轮次,每个节点 从其任务集 中抽取一批问题 。对于 中的每个问题 ,节点生成 rollout 。随后,节点选择这批 rollout 的一个子集 ,并将对应的经验数据包 广播到蜂群网络中。这个数据包包含了问题 、基准答案 、生成的 rollout 以及用于验证任务的元数据 。
-
采样与训练集构建:每个节点 在准备更新其模型时,会构建一个专属的训练集 。该训练集由两部分组成:
-
本地经验(Self-rollouts):从自己本轮生成的所有 rollout 中,采样 个数据点。 -
外部经验(External rollouts):从蜂群中其他节点 共享的 rollout 池中,采样 个数据点。
训练集 的构成可以形式化为:
-
这种机制的巧妙之处在于:
-
模型无关性:由于共享的是纯文本 rollout,接收方节点可以像处理自己生成的经验一样处理外部经验。它可以使用自己的模型对外部 rollout 进行重新编码(re-encode),并计算 token 级别的价值(如优势函数值),而无需关心生成该 rollout 的原始模型架构。这使得不同架构、不同规模的模型得以在同一个蜂群中协作。 -
通信效率:文本数据的传输成本远低于模型参数或梯度。这使得 SAPO 能够轻松扩展到数千甚至更多节点的规模,而不会被通信带宽所限制。 -
自主采样策略:每个节点拥有完全的控制权来决定如何从外部经验池中采样。这为节点过滤低质量经验、或根据自身模型的短板来针对性地学习提供了可能。例如,在论文的实验中,节点会首先丢弃那些优势值为零(即所有答案都错误)的外部 rollout,然后从剩余的“有价值”经验中进行均匀采样。
3. "Aha Moment" 的传播
这个框架最引人入胜的一点是它促进了“顿悟时刻”(Aha moments)在网络中的快速传播。假设某个节点通过不断的试错,偶然发现了一个解决某类难题的新方法(一个高回报的 rollout)。通过经验共享,这个“顿悟”会被迅速传播给网络中的其他节点。其他节点在自己的训练中使用了这个高质量的经验后,它们的模型能力也得到了提升,进而可能产生新的、更高质量的 rollout,形成一个正向的、自我强化的学习循环。这正是 SAPO 所谓“通过引导学习过程(bootstrapping the learning process)”的含义。
4. 算法伪代码解析

论文中的算法伪代码(Algorithm 1)清晰地描述了 SAPO 的完整流程。我们可以将其分解为以下几个关键步骤:
-
输入:对于每个节点 ,需要定义其数据集 、元数据 、初始策略模型 、奖励模型 、策略更新算法(如 PPO),以及每轮采样的本地经验数量 和外部经验数量 。 -
外层循环(按轮次):算法按训练轮次 迭代。 -
内层循环(按节点):在每个轮次中,所有节点并行、异步地执行以下操作。 -
采样问题:从 中采样一批问题 。 -
生成 Rollouts:对 中的每个问题 ,使用当前策略 生成 rollout 。 -
共享 Rollouts:选择 的一个子集 ,并将相应的经验数据包 通信给网络中的其他节点。 -
组装训练集:通过 SampleSelf从本地经验中采样 个样本,并通过SampleExternal从其他节点共享的经验池中采样 个样本,共同组成训练集 。 -
策略更新:使用指定的策略梯度算法(PolicyGradient),根据奖励模型 在训练集 上计算的奖励,来更新策略模型 。
-
-
输出:经过多轮迭代后,输出更新后的策略参数。
值得注意的是,当外部样本数 设为 0 时,SAPO 算法就退化为标准的、各自为战的 RL 微调。这为设置一个清晰的实验基线(baseline)提供了便利。
实验
为了验证 SAPO 的有效性,研究团队进行了一系列精心设计的实验,包括在严格控制环境下的对比实验和在真实、复杂网络环境中的大规模演示。
1. 受控实验 (Controlled Experiments)
-
实验平台:实验构建了一个包含 8 个智能体(agent)的蜂群。每个智能体都运行一个 Qwen2.5 0.5B 参数的模型。实验环境使用 PyTorch 实现,并通过 Docker 容器进行部署和编排,利用 PyTorch 的分布式数据并行(DDP)和 NCCL 进行 GPU 间的通信。 -
数据集:实验采用了 ReasoningGYM 数据集。这是一个程序化生成的数据集,能够按需创建代数、逻辑、图推理等多个领域的推理问题。其特点是每个问题都配有程序化的验证器,可以提供可靠、即时的奖励信号,这对于 RL 训练至关重要。研究者从中挑选了 9 个不同类型的任务,以确保模型在多样化的推理挑战上得到评估。 -
策略更新与奖励模型:策略更新算法采用了 GRPO (Group Relative Policy Optimization) 。研究者发现,在实验中去掉 KL 散度惩罚项可以提升训练效率。奖励模型直接使用 ReasoningGYM 提供的验证器:如果模型生成的答案能被验证器解析为正确答案,则奖励为 1,否则为 0。一个有趣的发现是,团队最初设计了格式化奖励来引导模型输出正确的答案格式,但后来发现通过经验共享,关于正确格式的“知识”能很快在蜂群中传播,使得显式的格式化奖励变得多余。 -
实验配置:为了隔离“共享”这一变量的效果,实验固定了每个智能体每轮训练的总样本数为 8 个任务的 rollout。通过调整本地经验和外部经验的比例,设计了四种配置: -
Baseline (8 local / 0 external) :无共享,即标准 RL 微调。 -
SAPO (6 local / 2 external) :少量共享。 -
SAPO (4 local / 4 external) :平衡共享。 -
SAPO (2 local / 6 external) :大量共享。
-
结果分析
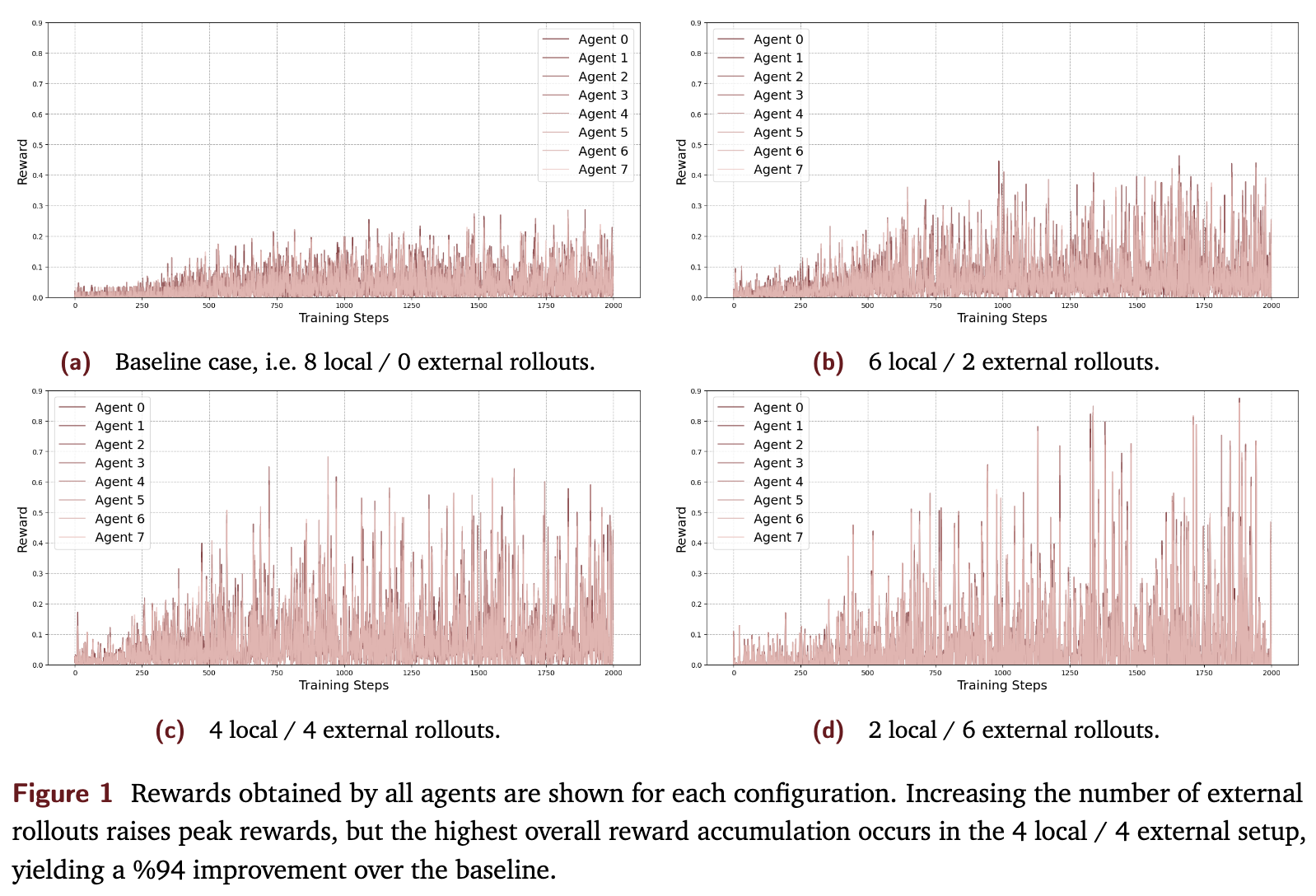
图1展示了四种配置下,8 个智能体在 2000 个训练步骤中的奖励变化轨迹。从中可以直观地看到:
-
所有引入了经验共享的 SAPO 配置,其峰值奖励都明显高于不共享的基线配置。 -
4 local / 4 external 的平衡共享配置不仅达到了最高的峰值奖励,其整体奖励累积也最高,相比基线提升了 94% (1093.31 vs 561.79)。这一结果有力地证明了经验共享的巨大优势。
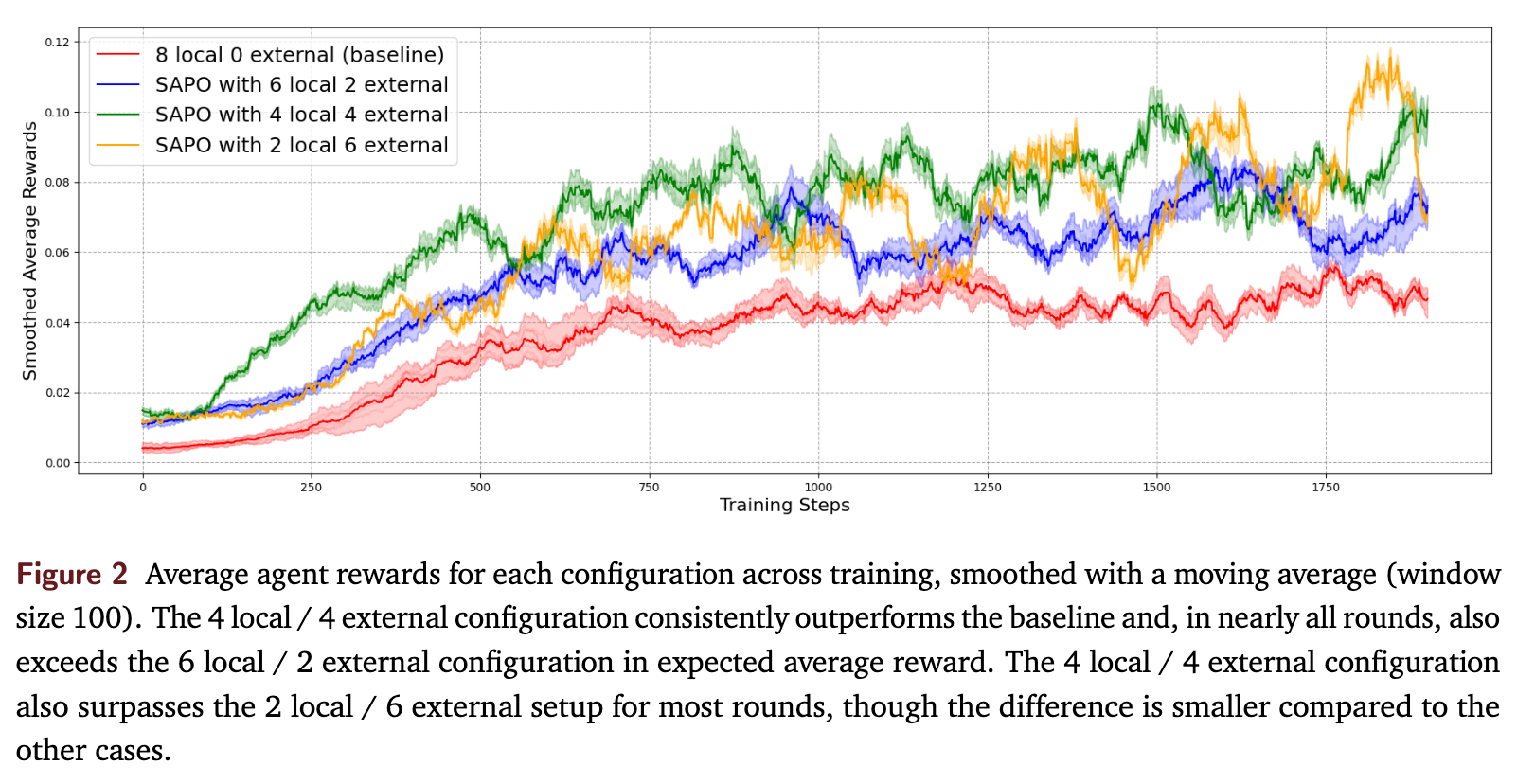
为了更清晰地观察训练动态,研究者对每个配置的智能体奖励进行了平均,并使用 100 个样本的窗口进行了移动平均平滑,结果如图2所示。
-
平衡共享的优越性:蓝色的曲线(4/4 配置)在几乎所有训练阶段都稳定地高于基线(红色曲线)和 6/2 配置(橙色曲线),展现出持续的学习优势。 -
过度依赖外部经验的风险:与 2/6 配置(绿色曲线)相比,4/4 配置在大多数时候也表现更优。这揭示了一个重要现象:过度依赖外部经验可能会损害性能。当节点自身探索不足(本地经验过少),而过多地依赖外部输入时,训练过程会变得不稳定。 -
训练的振荡现象:随着外部 rollout 比例的增加,奖励曲线的振荡幅度也随之增大。2/6 配置表现出剧烈的振荡。论文将其归因于两种网络效应: -
当表现好的智能体过度依赖外部经验时,它们的学习进程可能会被表现差的智能体产生的低质量 rollout 所拖累。 -
当整个蜂群贡献的优质经验过少,而节点又大量从中采样时,共享池的整体质量会下降,导致学习效果时好时坏,形成“学习-遗忘”的循环。
-
这些受控实验清晰地表明,SAPO 能够在不增加总训练样本量的情况下,通过优化经验的来源构成,大幅提升模型的学习效率和最终性能。同时,它也揭示了在实践中需要审慎地平衡本地探索与外部利用。
2. 大规模开源演示 (Large-Scale Open-Source Demo)
为了在更真实、更复杂的环境中评估 SAPO,Gensyn 团队进行了一项大规模的开源演示。他们邀请了数千名社区成员在各自的、配置迥异的硬件上运行 SAPO 算法。
-
环境设置:这是一个高度异构和动态的网络,参与者的硬件、模型配置各不相同,节点随时可能加入或离开。 -
评估方式:团队设立了一个“裁判”(judge)节点。参与者节点可以向裁判请求评估。裁判会从 ReasoningGYM 任务中随机抽取一个问题发给节点,节点生成答案后返回给裁判,裁判使用验证器对答案进行评分。 -
对比分析:通过分析与唯一对等身份(peer identifier)关联的评估结果,研究者得以比较在蜂群中协同训练的模型与隔离训练(isolated baseline)的模型之间的性能差异。
结果分析
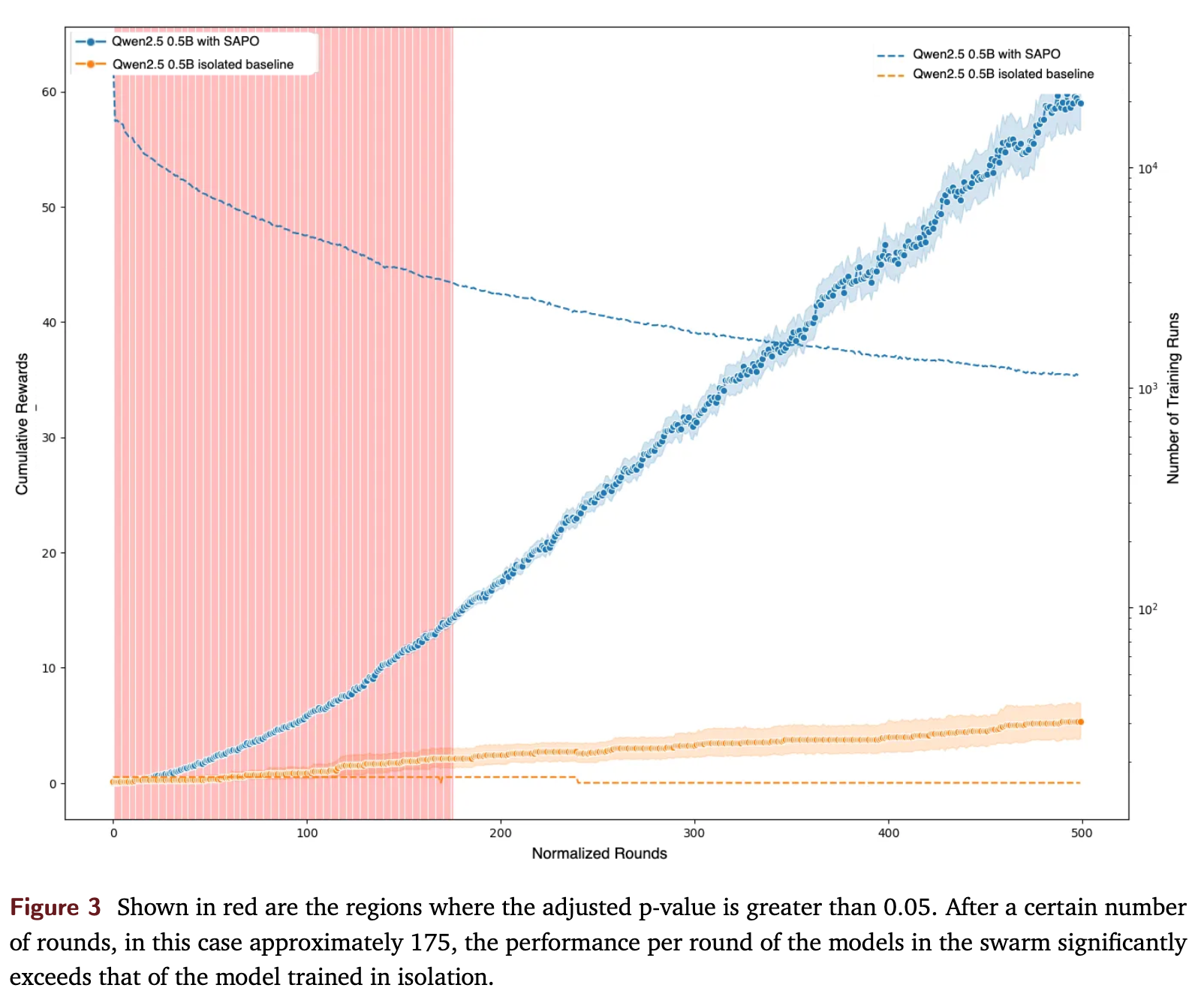
图3的结果显示:
-
对于 Qwen2.5 0.5B 模型,参与蜂群训练(蓝色曲线)的累积性能随着时间的推移,持续优于隔离训练的基线模型(橙色曲线)。 -
经过统计检验,大约在 175 个“标准化轮次”之后,蜂群训练的模型的单轮性能开始显著超越隔离训练的模型。这里的“标准化轮次”是为了处理节点参与度不一的问题而设计的度量。
这项大规模演示在接近真实世界的条件下,再次验证了 SAPO 的有效性。此外,实验还得出了一个耐人寻味的观察:对于能力更强的模型(论文中以 Qwen3 0.6B 为例),在蜂群中训练和隔离训练的性能差异不大。这表明 SAPO 的优势可能对那些处于中等能力(mid-capacity)的模型最为显著。这类模型既有足够的能力去“吸收”和理解多样化的外部经验,又能通过自身的探索为蜂群贡献有价值的“顿悟”。
研究者推测,在这次演示中,由于节点仅使用简单的均匀随机采样来选择外部 rollout,没有进行有效过滤,导致大量无用的(零奖励)经验被频繁交换,这可能限制了高性能模型的进一步提升。如果采用更智能的采样策略,或许能让更强的模型也从蜂群协作中获益。
往期文章:


