让每一项优秀工作,被更多人看见:点击进入投稿通道
论文追踪 APP 推荐:DailyPapers

-
论文标题:How to Fine-Tune a Reasoning Model? A Teacher–Student Cooperation Framework to Synthesize Student-Consistent SFT Data -
论文链接:https://arxiv.org/pdf/2604.14164
TL;DR
今天解读一篇来自上海人工智能实验室、大连理工大学和南京大学的论文《How to Fine-Tune a Reasoning Model? A Teacher-Student Cooperation Framework to Synthesize Student-Consistent SFT Data》。在大型语言模型的研究中,使用强模型(Teacher)生成合成数据来微调弱模型(Student)是一种标准的监督微调(SFT)范式。然而,研究人员发现,当这种范式应用于较新的推理模型(如 Qwen3-8B)时,不仅无法提升推理能力,反而会导致严重的性能下降。
作者通过实验与分析揭示,这种现象的主要原因在于教师生成数据与学生模型固有数据分布之间存在风格分歧(Stylistic Divergence)。由于开源推理模型通常在未公开的专有数据集上进行了大量后训练,引入分布不匹配的新合成数据会引发隐蔽的分布冲突,进而导致灾难性遗忘。
为解决这一问题,本文提出了一种名为 TESSY(Teacher-Student Cooperation Data Synthesis) 的数据合成框架。该框架将输出序列解耦为能力令牌(Capability Tokens)与风格令牌(Style Tokens),并让教师模型与学生模型交替生成这两类内容。通过这种"生成-回滚"的机制,TESSY 合成的数据既继承了教师模型的高逻辑准确性,又在文本风格和连贯性上保持了与学生模型原始分布的一致。实验表明,在 GPT-OSS-120B 作为教师、Qwen3-8B 作为学生的设定下,纯教师数据导致 LiveCodeBench-Pro 和 OJBench 性能分别下降 3.25% 和 10.02%,而使用 TESSY 合成的数据则在这两个基准上分别提升了 11.25% 和 6.68%。
1. 引言
近年来,具备显式思考过程的推理模型在代码生成、数学问题求解等密集推理任务上取得了突破。在此背景下,利用参数量大、推理能力强的大型模型生成 SFT 训练数据,进而微调较小规模的模型,已成为提升小模型任务表现的常规手段。然而,以往的蒸馏和微调工作大多在基础模型(Base)或指令微调模型(Instruct)上进行,鲜少针对已经具备深度推理能力的模型开展研究。
作者在初步实验中观察到一个反直觉的现象:当使用编码能力强大的 GPT-OSS-120B 作为教师模型,生成解决编程竞赛题目的数据去微调 Qwen3-8B 时,Qwen3-8B 的代码生成能力不仅没有增强,反而出现了最高 10.02% 的性能衰退。
通过深入调查,作者排除了教师响应质量不足、提示词过于简单以及基准数据泄露等因素,最终将问题的根源锁定在训练数据是否符合模型策略(On-policy)上。推理模型在预训练和后训练阶段已经形成了特定的内部知识表示和输出风格(例如语气词、推理步骤间的过渡话语)。由于各家机构的训练配方不公开,直接注入异构教师模型生成的数据,会迫使学生模型去适应一种不熟悉的分布。这种分布差异虽然在字面上表现为"风格不同",但实质上干扰了模型对核心推理逻辑的学习,引发了灾难性遗忘。
基于此,本文的研究动机明确为:如何合成既能保留教师模型强大推理能力,又能与学生模型数据分布保持一致的 SFT 数据。

2. 研究目标与问题定义
在 SFT 阶段,核心目标是使模型的输出分布与训练数据的分布相对齐。
为了在数学上严格定义这一过程,作者引入了以下符号:
设 表示在给定输入 和历史令牌 的条件下,第 个令牌的数据真实分布。
设 表示学生模型 的预测分布。
为简化符号表达,下文省略对 和 的显式条件依赖。SFT 的标准训练目标即最小化两者之间的 KL 散度:
其中 表示总令牌数。通常,为了获得高质量的 ,我们会借助更强大的教师模型 来合成数据。
进一步,作者提出将输出序列中的令牌划分为两个不相交的集合:
-
能力令牌集合 :与任务求解直接相关的令牌,如代码片段、数学公式、逻辑推导的实质内容。 -
风格令牌集合 :与任务求解本身无关的令牌,如表示语气、连接或话语标记的词汇(例如"Wait"、"Okay, let's see"、"But")。
基于此划分,训练目标可以分解为能力损失和风格损失两部分:
在传统的微调场景(如微调基础模型)中,学习风格损失 通常是无害的,且相对容易拟合。但对于推理模型而言,教师和学生模型经历了不同的、广泛的预训练和微调,各自具有根深蒂固的风格模式。如果强行优化异构的 ,会导致模型参数发生不必要的剧烈更新,进而干扰对 的学习。
为避免这种负面影响,作者提出了合成数据的理想构造方式:能力令牌应采样自教师模型以保证正确性,而风格令牌应遵循学生模型自身的分布。形式化表达如下:
3. TESSY 框架:交替生成与回滚机制
为了实现上述公式中定义的令牌解耦与重组,作者提出了 Teacher-Student Cooperation Data Synthesis (TESSY) 框架。其核心思想是让教师模型和学生模型在生成同一条响应时交替接管生成权。
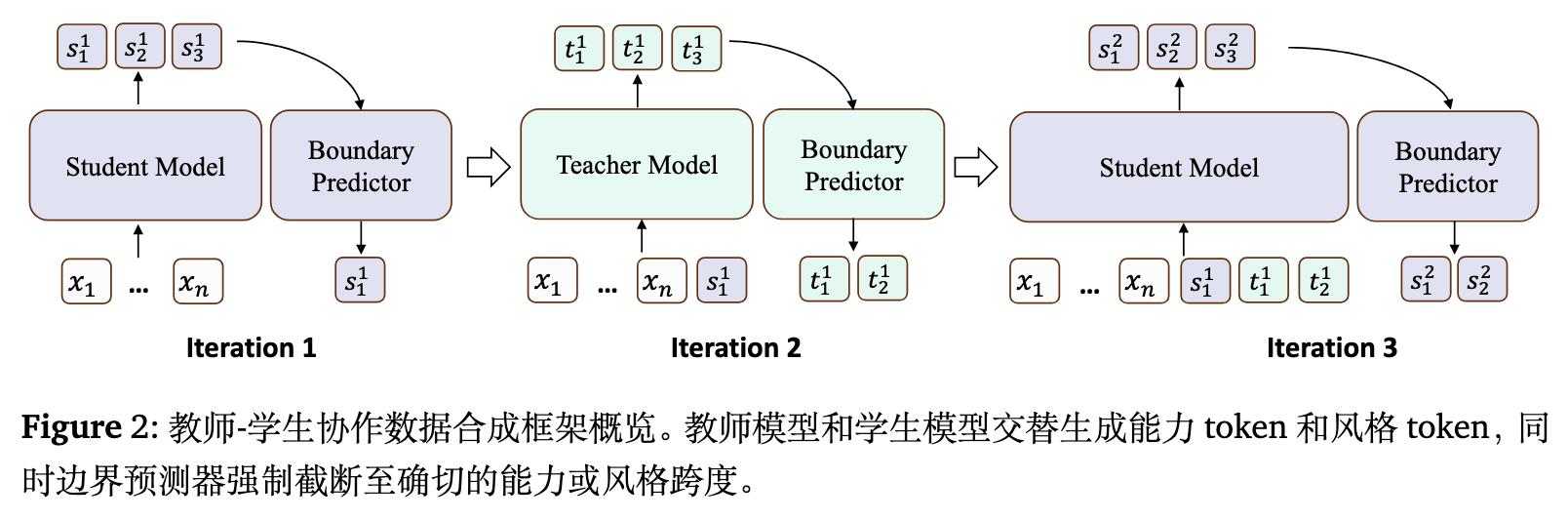
3.1 交替生成 (Alternating Generation)
在人类解决复杂问题的过程中,推理步骤(能力)通常由过渡性或连接性的陈述(风格)连接起来。相应地,模型生成的推理轨迹中,能力令牌和风格令牌往往交替出现。
对于合成样本 ,TESSY 通过交替调用教师和学生模型来生成能力片段和风格片段:
其中 和 分别表示由学生和教师生成的包含多个令牌的片段。由于大模型的输出通常以风格化的短语(如"Okay, let's see")开头,TESSY 默认由学生模型开始生成第一个片段 。
每个片段的生成都依赖于之前所有已生成的片段作为上下文:
3.2 生成回滚 (Generation Rollback)
上述交替生成面临一个核心挑战:边界确定问题。模型在单次前向传播中如何准确知道何时停止生成风格并切换到能力,或者何时停止能力生成切换回风格?
为解决此问题,TESSY 采用了一种"先生成,后回滚"(Generate-then-rollback)的策略:
在每一步中,当前主导模型首先固定生成 个令牌。随后,将这 个令牌输入到一个独立训练的边界预测器(Boundary Predictor)中,寻找正确的边界位置,并丢弃越界的部分。
设 和 分别为学生和教师模型初步生成的长度为 的原始片段。应用边界预测器进行单步截断的公式如下:
此处 和 分别表示用于教师模型(预测能力令牌边界)和学生模型(预测风格令牌边界)的边界预测器。
3.3 边界预测器的实现与训练
边界预测器被实现为令牌级别的序列标注模型。在每一个令牌位置,添加一个二分类头,用于预测该令牌属于风格令牌还是能力令牌。
-
对于能力令牌边界预测器(服务于教师),边界定义为序列中第一个被预测为"风格令牌"的位置。截断时保留该位置之前的所有纯能力令牌。 -
对于风格令牌边界预测器(服务于学生),边界定义为序列中第一个被预测为"能力令牌"的位置。截断时保留该位置之前的所有纯风格令牌。
为了训练这两个预测器,作者采样了 10 万段由教师和学生模型生成的思考内容,并使用教师模型基于预先设计的 Prompt 自动标注其中的所有风格片段。Prompt 要求抽取表达犹豫、语气、过渡或连接的词句(如"well", "to begin with"),排除实际推理、代码、公式或解题步骤。为保证 TESSY 框架的运行效率,边界预测器选择了参数量极小的 Qwen3-0.6B-Base 模型进行训练。
3.4 最终答案的生成
在长思维链模型中,输出通常明确分为内部推理(Thinking)和最终答案(Final Answer)两部分。由于最终答案的逻辑相对简单,且同样带有强烈的学生模型特有格式要求,一旦完成思考过程的交替生成,TESSY 会退出交替循环,将生成最终答案的任务全权交还给学生模型。
def TESSY_synthesize(x, M_S, M_T, B_T, B_S, k):
"""
TESSY (Teacher-Student Cooperation Data Synthesis) 算法核心逻辑
参数说明:
x: 用户的输入提示词 (prompt)
M_S: 学生模型 (Student Model)
M_T: 教师模型 (Teacher Model)
B_T: 能力边界预测器 (Capability boundary predictor)
B_S: 风格边界预测器 (Style boundary predictor)
k: 单步迭代允许的最大生成令牌数 (Maximum token number)
返回:
y: 师生协作生成的合成序列 (Synthetic sequence)
"""
y = [] # 初始化合成序列,存储历史生成的令牌
# 按照人类对话习惯,开头由风格定调,因此初始生成模型设为学生模型
M_current = M_S
B_current = B_S
# 只要模型尚未输出结束思考过程的标识符(如 </think>),就持续交替生成
while not check_reaching_final_answer(y):
# 1. 生成定长片段: 当前模型以前文 y 为条件,盲目生成 k 个令牌
z_hat_tokens = M_current.generate(prompt=x, context=y, max_tokens=k)
# 2. 预测边界: 使用对应的预测器对生成的 k 个令牌进行逐词分类
boundary_index = B_current.predict_boundary(z_hat_tokens)
# 3. 截断片段: 丢弃越界的令牌,保留符合当前角色定位的纯净跨度
z_tokens = z_hat_tokens[:boundary_index]
# 将合法截断后的令牌序列追加到总体合成序列中
y.extend(z_tokens)
# 4. 判断是否需要切换生成角色
# 如果截断后长度小于原始生成长度,说明在这 k 个令牌中触碰到了文本风格的边界
if len(z_tokens) < len(z_hat_tokens):
# 执行角色互换
if M_current == M_S:
M_current = M_T
B_current = B_T
else:
M_current = M_S
B_current = B_S
# 退出循环说明思考过程已经完成,此时必须规避教师模型的最终答案格式差异
# 统一切换回学生模型,基于前文生成最终答案内容
a_tokens = M_S.generate_final_answer(prompt=x, context=y)
# 将最终答案追加,完成整条数据的合成
y.extend(a_tokens)
return y
4. 实验设置
4.1 数据集与评测基准
训练数据来源于 OpenThoughts 和 NVIDIA Nemotron 的开源数据集,通过设定规则筛选出与编程竞赛相关的题目,共计 8 万道题(包含 3.7 万道去重题目)。所有对比实验均在这同一批问题上合成响应并进行训练。
核心评估任务为代码生成,包含内域测试集 LiveCodeBench-V5、LiveCodeBench-V6、LiveCodeBench-Pro 以及 OJBench。
为测试泛化能力,还引入了数学与科学任务作为外域测试集,包括 AIME2024、AIME2025、OlympiadBench 以及 GPQA-Diamond。所有评测均取多次独立运行的 pass@1 平均值。
4.2 模型与对比方法
主要实验使用 GPT-OSS-120B 作为教师模型,Qwen3-8B 作为被微调的学生模型。
作为对比,作者设置了三类 SFT 数据构建基线:
-
学生主导: -
Self-Distillation (自我蒸馏):教师生成参考答案,学生根据参考答案生成思考和最终解答。 -
Reject-Sampling (拒绝采样):学生生成 5 个候选答案,由教师打分挑选出最好的一个作为训练数据。
-
-
师生合作: -
Teacher-Answer:学生负责生成思考部分,教师负责生成最终答案。 -
Teacher-Think:教师负责生成思考部分,学生负责生成最终答案。
-
-
教师主导: -
Teacher-Only:全部数据由教师端到端生成。 -
Teacher-Mix:混合教师和学生单独生成的数据(比例为 1:1)。
-
所有模型在合成数据上统一使用 XTuner 框架训练至多 9 个 epoch,批次大小设定为 128,学习率为 5e-5。
5. 主实验结果分析
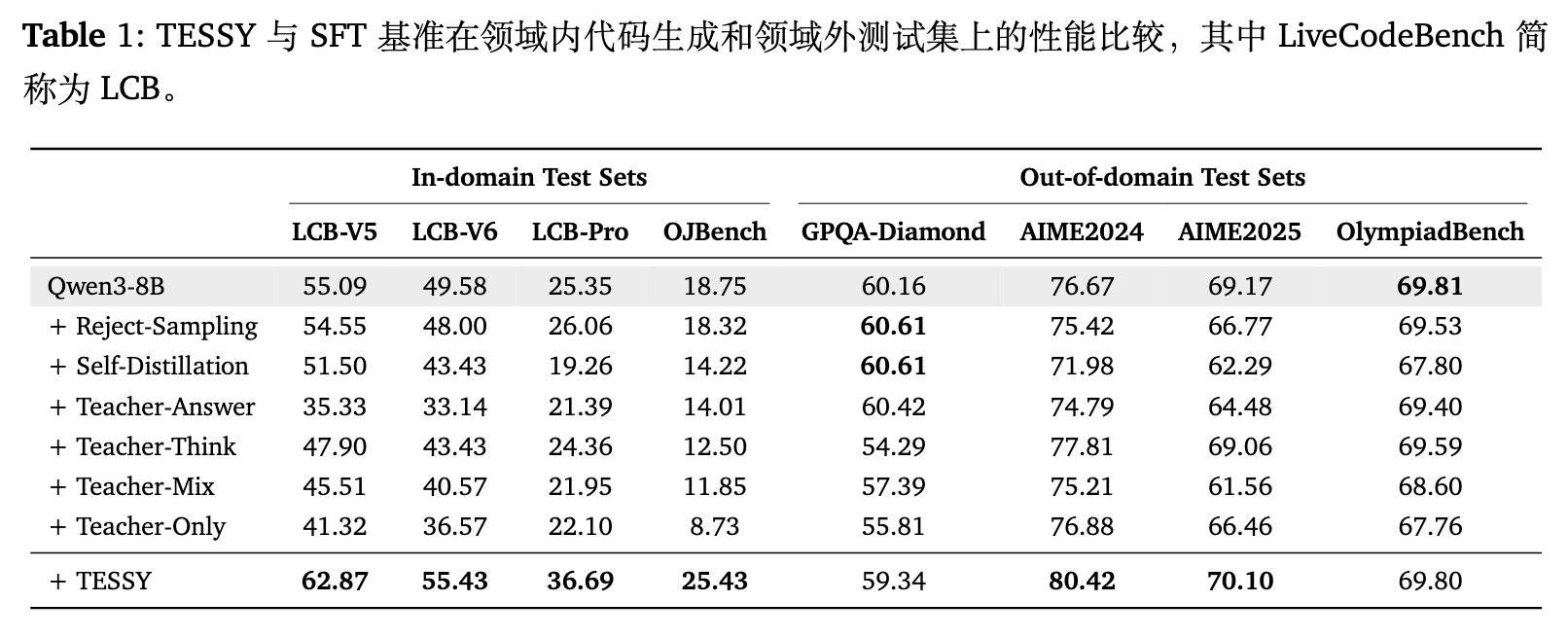
观察代码生成任务的内域测试结果,一个明显的趋势是:在传统 SFT 范式下,教师模型在数据生成中的参与度越高,学生模型的性能下降幅度就越大。
使用纯教师生成数据的 Teacher-Only 方法,在经过 8 万条数据、9 个 epoch 的充分训练后,在 OJBench 上的成绩下降了 10.02%(从 18.75% 降至 8.73%),在 LiveCodeBench-Pro 上下降了 3.25%。Teacher-Mix 虽然稀释了教师数据,但依然导致性能下降。被广泛认为能缓解分布不匹配的自我蒸馏(Self-Distillation),在这些基准测试中同样引发了实质性的退化。纯靠学生主导的 Reject-Sampling 能够保持模型稳定性,但仅在 LCB-Pro 上带来了 0.71% 的微小增益,未能有效利用教师模型的上限能力。
相较之下,TESSY 在所有四个代码测试集上均实现了一致且明显的提升。它使得 Qwen3-8B 在三个 LiveCodeBench 数据集上分别提升了 7.78%、5.85% 和 11.34%,在 OJBench 上提升了 6.68%(达到 25.43%)。
在外域测试集上,TESSY 同样展现出良好的泛化性。在 AIME2024 和 AIME2025 上,TESSY 微调后的模型成绩分别提升了 3.75% 和 0.93%,同时在 GPQA-Diamond 和 OlympiadBench 上保持了相近的水平。反观其他依赖教师数据的基线方法,在各个外域任务上均造成了不同程度的负面影响(例如 Teacher-Only 在 GPQA-Diamond 上下降了 4.35%)。
6. 深入分析与消融实验
6.1 不同模型设定的泛化验证
为了验证 TESSY 并非仅对特定模型组合有效,作者进行了一系列替换实验。
更换学生模型:将学生模型替换为参数量更大的 MoE 模型 Qwen3-30B-A3B。虽然更大的模型容量使其能够在 Teacher-Only 的数据上获得轻微增益,但 TESSY 的优势依然存在。在 LCB-Pro 和 OJBench 上,TESSY 在 Teacher-Only 的基础上进一步提升了 5.52% 和 8.41%。
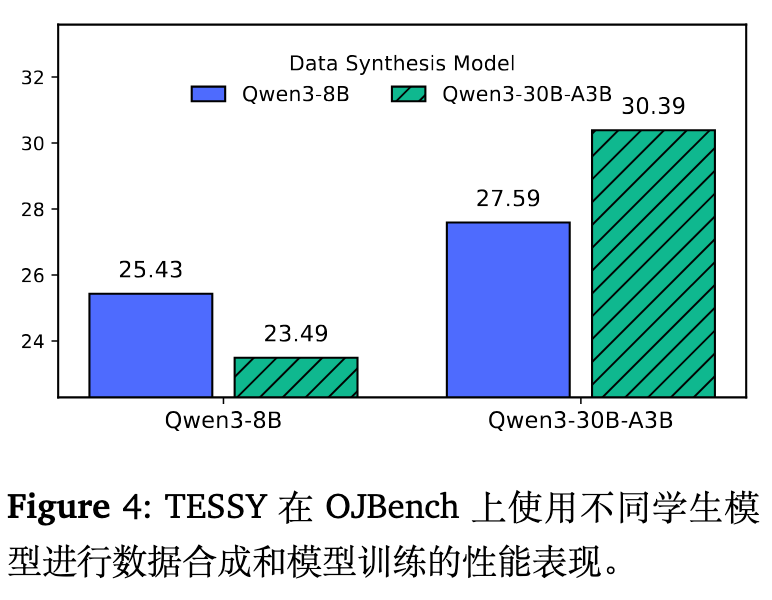
作者还进行了交叉训练测试,以强调数据分布对齐的重要性。在使用 Qwen3-8B 合成的数据去训练能力更强的 Qwen3-30B-A3B 时,OJBench 上的成绩比使用同分布数据下降了 2.8%。反过来,用 Qwen3-30B-A3B 的数据训练 Qwen3-8B 也导致了 1.94% 的性能折损。即使是同系列的先进模型,不同规模带来的分布微调也足以干扰 SFT 的效果。
更换教师模型:将教师替换为同家族但更大规模的 Qwen3-235B,以及异构的 DeepSeek-R1-0528。
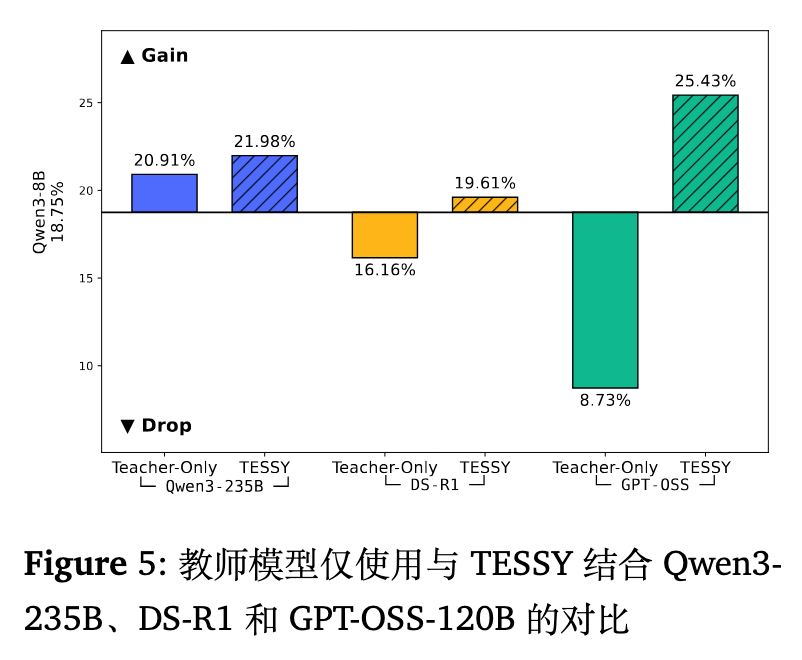
即使用同家族模型作为教师(Qwen3-235B),Teacher-Only 的效果依然不如 TESSY(相差 1.07%)。当面临异构教师模型时,风格分布不匹配的惩罚更加严重:DeepSeek-R1 和 GPT-OSS 作为教师时,Teacher-Only 均导致了掉点,而 TESSY 则分别超越了对应 Teacher-Only 基线 3.45% 和 16.79%。
6.2 数据质量与生成长度分析
TESSY 混合了学生模型生成的令牌(经统计约占总令牌数的 22.4%),这是否会拉低数据的逻辑质量?
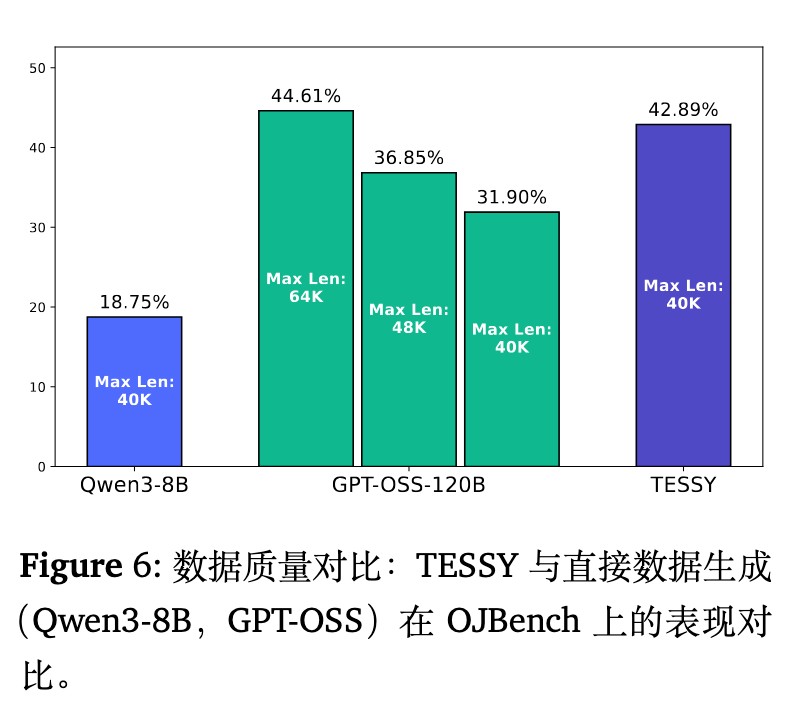
作者直接评测了各方法合成数据本身在 OJBench 上的正确率。在最大生成长度限制为 40K 令牌时,TESSY 合成的数据正确率为 42.89%,比其教师模型 GPT-OSS(31.90%)高出 10.99%。只有当 GPT-OSS 的生成长度限制放宽至 64K 令牌时,其单独生成的正确率才勉强反超 TESSY。
这种现象指向了一个有趣的推论:在交替生成的过程中,学生模型接管时倾向于产生更精简的思维路径,这种风格潜移默化地引导了教师模型更早地终止无效推理。因此,TESSY 不仅没有损害质量,反而能在限制长度的条件下提高答题效率。
6.3 为什么不从基础模型(Base Model)开始训练?
既然对推理模型进行 SFT 容易产生分布冲突和灾难性遗忘,退回一步,直接用合成数据去微调尚未经过深度推理后训练的基础模型(Qwen3-8B-Base),是否更为稳妥?
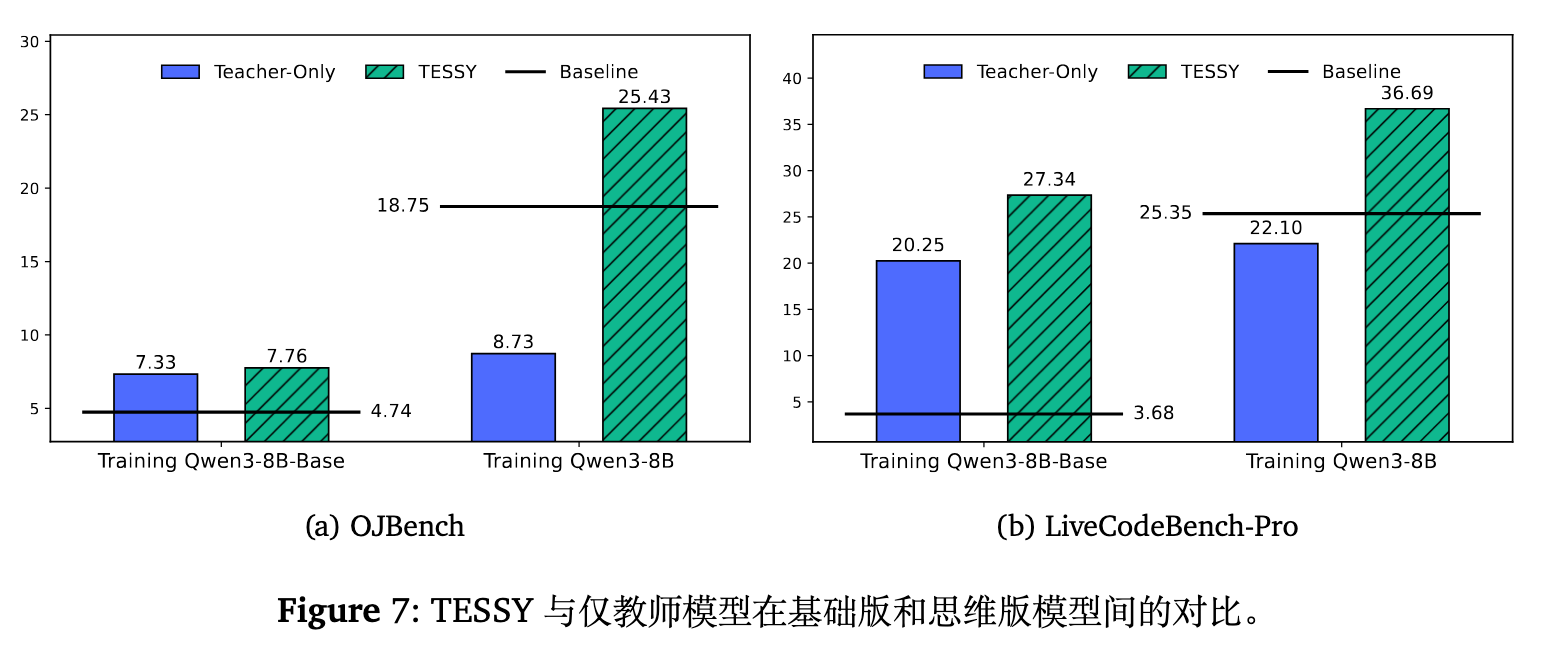
实验显示,针对基础模型,Teacher-Only 和 TESSY 的微调均能提升性能。然而,即使用 TESSY 微调后的基础模型,其表现依然落后于微调前的原始推理模型(Qwen3-8B)达 10.99%。这证明了推理模型在后训练阶段积累的知识和能力下限远高于基础模型,为了规避灾难性遗忘而放弃这些预先习得的能力是得不偿失的。推理模型本身才是进行后续 SFT 的正确起点。
同时值得注意的是,即使在基础模型上,TESSY 依然比 Teacher-Only 高出 0.43%(OJBench)和 7.09%(LCB-Pro)。这意味着即使是基础模型,也具有一定的固有风格偏好,与异构大模型的数据存在冲突。
6.4 数据分布偏移的可视化验证
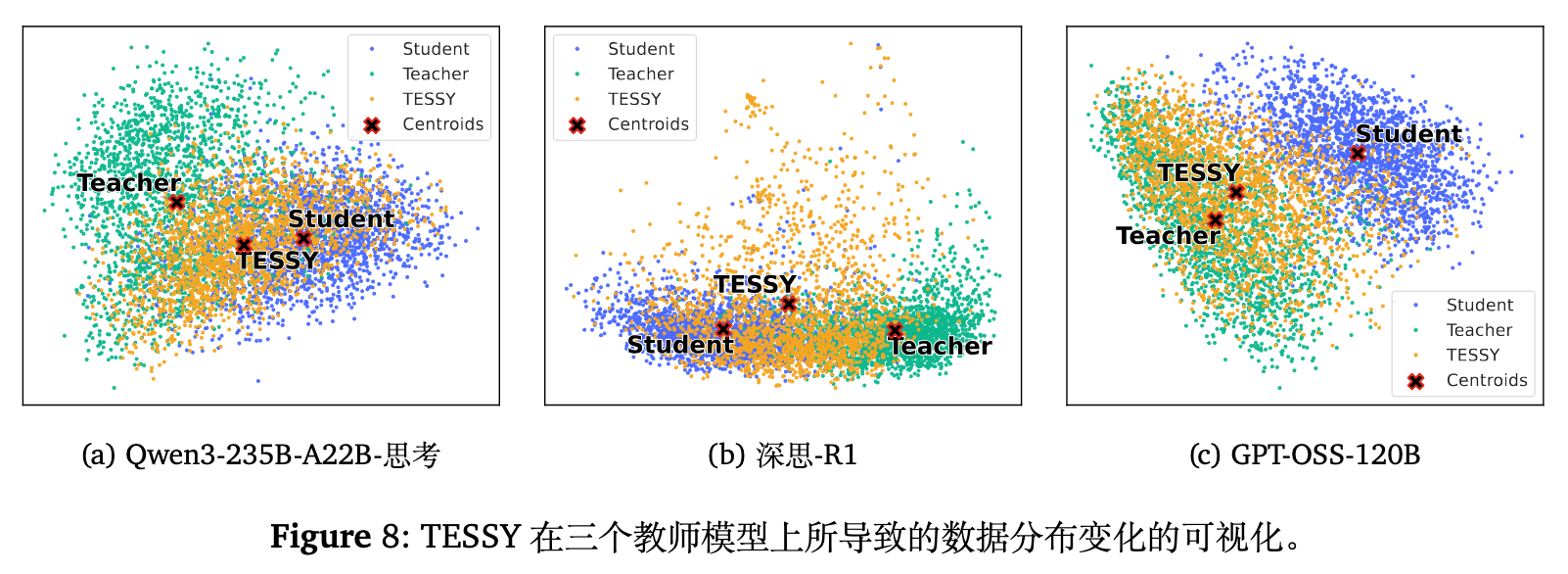
为了直观展示 TESSY 是如何缩小分布鸿沟的,作者抽取了 10,000 个问题的解答,将其转换为基于 TF-IDF 的词袋向量并进行 PCA 降维。图中红叉表示各个分布的质心。
无论使用哪种教师模型(Qwen3-235B、DeepSeek-R1、GPT-OSS),TESSY 生成数据的质心总是位于 Teacher-Only 和纯 Student 数据分布的中间。这种向学生模型原始分布拉回的趋势,在宏观层面上解释了 TESSY 为何能减轻微调过程中的分布冲突。
6.5 其他设计选择的影响
为了更全面地评估,作者还在附录和补充实验中探讨了以下问题:
系统提示词隔离(System Prompt Isolation)
一种常见的工程手段是,在 SFT 时加入特殊的系统提示词,以区隔新注入的数据与原有的训练数据。虽然实验证明加入系统提示词能让 Teacher-Only 在 LCB-Pro 上提升 5.28%,但整体成绩依旧低于未微调的基线模型。提示词隔离治标不治本,无法抵消大规模异构风格数据带来的参数干扰。
LoRA 与全参数微调
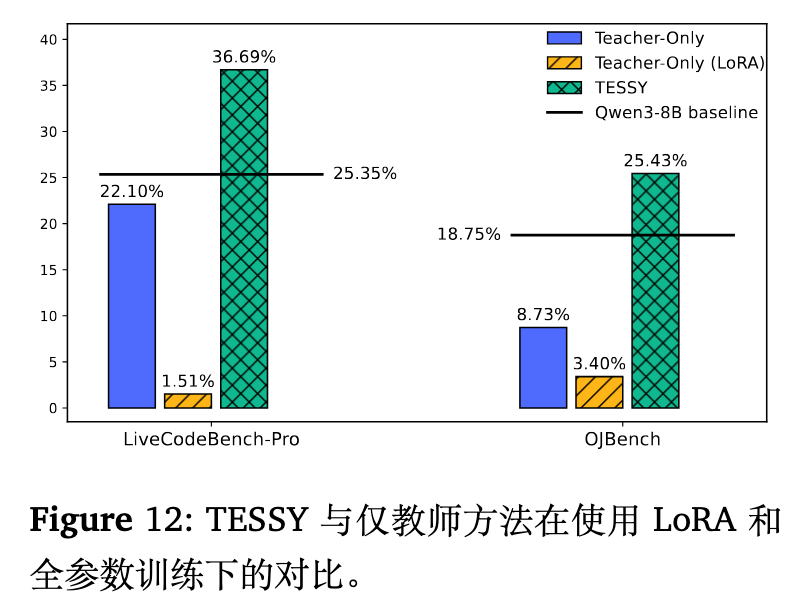
通常认为 LoRA 通过冻结大部分参数可以缓解灾难性遗忘。但在该项研究中,使用 Rank=8 的 LoRA 训练 9 个 epoch 后,无论是在 Teacher-Only 还是 TESSY 设定下,性能衰退都比全参数微调更为严重。原因在于,适应分布差异需要改变较多参数,而 LoRA 有限的参数更新能力不足以完成这一调整,反而让模型陷入混乱。
最终答案由谁生成
如果将 TESSY 的最后一步——生成最终答案——交给逻辑更强的教师模型,会导致 LCB-Pro 和 OJBench 的性能分别下降 12.33% 和 13.58%。这深刻地说明:在 SFT 数据中避免风格冲突(最终答案格式的突变),比追求那一丁点数据质量的提升更为关键。
通过观察具体生成的文本,可以看出 Qwen3 的思考过程更偏向逐步推导和列举约束,而 GPT-OSS 更倾向于抽象的算法分析和引理证明。TESSY 成功地将二者缝合:保留了 GPT 的算法解析部分,并用 Qwen3 偏好的转折词(如 "But since...","So the independent selection works...")进行了平滑过渡。
7. 讨论与总结
在当前大模型朝着深度推理方向演进的浪潮下,如何为已具备较强能力的推理模型注入新知识成为了一个难题。直接应用基础模型时代的知识蒸馏和微调范式遇到了"灾难性遗忘"的瓶颈。
以往的缓解方案多依赖于在线策略优化(如 RLHF)或限制参数更新,而本文提供了一种离线数据合成视角:通过细粒度的边界控制,在单条数据内部实现核心逻辑与外在风格的解耦。这种方法表明,在评估合成数据时,不仅要看其结果的"正确率",更要评估其对于目标优化模型的"分布友好度"。
当然,TESSY 也存在一些工程和应用上的局限性。受限于生成-回滚的交替前向推理机制,TESSY 离线合成数据的速度低于直接端到端生成。此外,当前为了绝对保证数据与学生分布的一致性,本文并未引入复杂的拒绝采样或自我纠错机制以进一步拔高数据质量上限。
总而言之,TESSY 为异构大模型之间的高效知识迁移指明了一条兼顾能力与分布的协作道路,证明了让学生模型参与 SFT 数据构建能够有效抵御风格错配带来的负面影响。
更多细节请阅读原论文。

