
-
论文标题:JudgeRLVR: Judge First, Generate Second for Efficient Reasoning -
论文链接:https://arxiv.org/pdf/2601.08468
TL;DR
-
核心问题:现有的验证奖励强化学习(RLVR)倾向于诱导模型生成冗长、充满试错和回溯的思维链(CoT),导致推理效率低下且信息密度不足。虽然启发式长度惩罚能缓解此问题,但往往损害准确率。 -
解决方案:提出 JudgeRLVR,一种“先判断、后生成”的两阶段训练范式。第一阶段训练模型区分正确与错误的解题过程(判别能力);第二阶段用判别模型初始化策略模型,进行标准的 RLVR 微调(生成能力)。 -
主要结论:在 Qwen3-30B-A3B 模型上的实验表明,JudgeRLVR 在域内数学任务上平均准确率提升 3.7 个百分点,同时平均生成长度减少 42% ;在域外任务上展现出更强的泛化能力。该方法促使模型将外部的“试错”内化为内部的“判别”,从而生成更直接、高效的推理路径。
1. 背景
在大型语言模型(LLM)的推理能力演进中,基于验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR) 已成为提升模型解决复杂数学和代码问题能力的标准范式(如 DeepSeek-R1 等工作)。RLVR 通过稀疏但客观的监督信号(即最终答案是否正确)来激励模型探索监督微调(SFT)数据之外的解题策略。
然而,RLVR 引入了一个显著的副作用:思维链的“无序扩张”。
1.1 结果导向优化的盲区
由于 RLVR 主要优化最终答案的正确性,模型往往倾向于采取“生成式搜索”的策略:即通过枚举大量可能的尝试分支、不断修正中间步骤、进行显式的自我校正来“撞”对答案。这种行为模式导致了两个主要问题:
-
推理冗余与效率低下:生成的 Chain-of-Thought (CoT) 轨迹极长,充斥着大量的回溯(backtracking)和自我否定。例如,“让我再试一次”、“这里好像不对,通过...来验证”等。虽然这保证了正确率,但大幅增加了推理时的计算开销(Token 消耗)。 -
低信息密度:长输出并不等同于高质量推理。现有的研究(如 Kimi k1.5, DAPO 等)尝试引入长度惩罚(Length Penalty)来抑制 Token 数,但这往往造成了一种不可调和的权衡(Trade-off):缩短长度通常会导致关键推理步骤被截断,从而降低准确率。
1.2 认知科学的启示
论文作者从认知科学(Chi et al., 1981)中汲取了灵感:专家与新手的区别不在于是否进行搜索,而在于搜索发生的位置。
-
新手:倾向于进行外部化的试错,将所有尝试路径写在纸上(或生成在 Context 中)。 -
专家:具备“早期判别与剪枝”的能力,在思维展开之前就能识别并剪除低价值的路径,从而只输出高价值的推理过程。
基于此,作者提出假设:判别能力(Discriminative Capability)是高效生成的前提。 只有当模型学会了区分什么是“好的推理”和“坏的推理”,它才能在生成阶段内化这种指导信号,从而在不依赖显式长度惩罚的情况下,自发地修剪搜索空间。
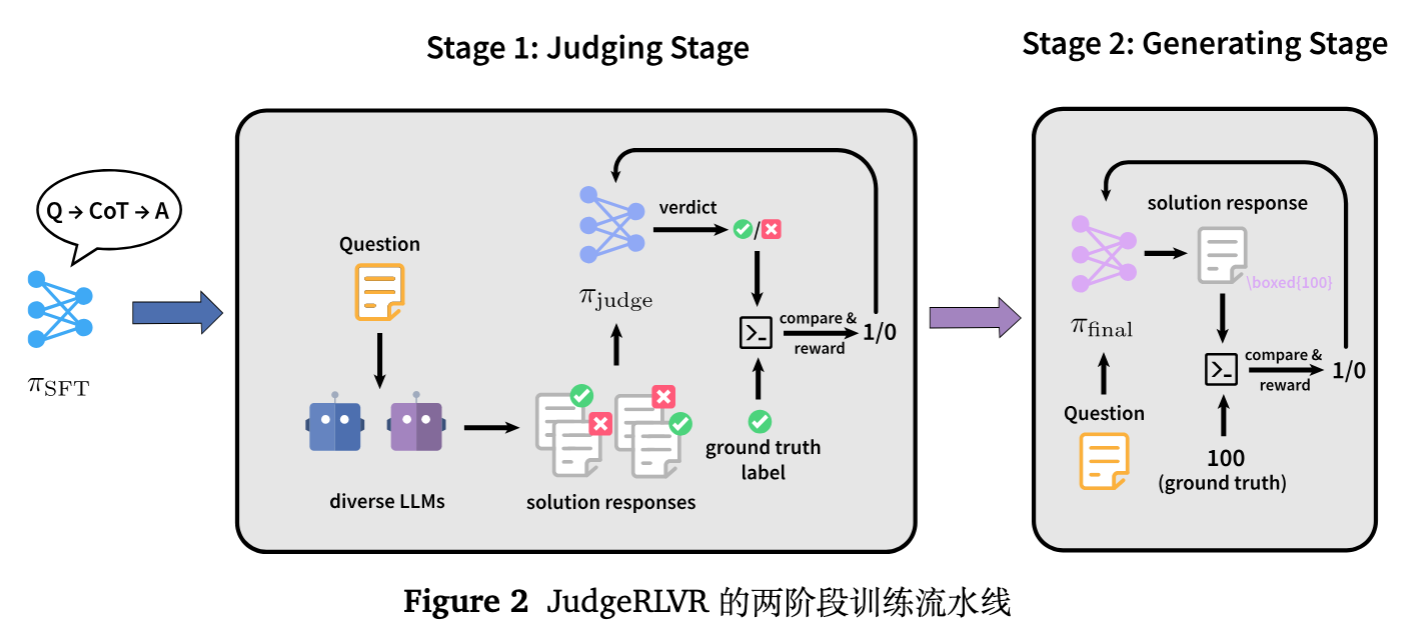
2. JudgeRLVR 二阶段范式
JudgeRLVR 将推理策略的训练拆解为两个顺序执行的阶段:判别阶段(Judging Stage) 和 生成阶段(Generating Stage)。
2.1 符号定义
-
问题域 ,标准答案 。 -
解题响应(Solution Response),为一个包含逻辑过程并以最终答案结尾的 Token 序列。 -
通过确定性解析器提取预测答案 。 -
正确性标签 ,当且仅当 时为 1。
2.2 第一阶段:判别阶段 (Judging Stage)
此阶段的目标是训练模型作为一个“裁判”(Judge),使其具备识别错误路径的能力。
数据构建:难负样本挖掘
为了训练一个高质量的判别器,数据的构造至关重要。作者采用了以下策略:
-
Rollout 生成:对于每个问题 ,使用多个模型(如 MiMo-7B RL 和目标模型 Qwen3-30B-A3B-SFT)生成一组候选响应 。 -
难负样本挖掘(Hard Negative Mining):优先选择那些通过率非 0 且非 1 的“中等难度”问题。这类问题产生的错误答案通常是“差一点就对”的,比纯粹的随机错误更具判别训练价值。 -
类别平衡:对正样本()和负样本()进行下采样平衡,防止模型学习到类别先验偏见。
训练目标
模型接收问题 和候选响应 ,输出两部分内容:
-
评论(Critique/Commentary) :包含对推理过程的分析。 -
判决 Token :0 代表不正确,1 代表正确。
奖励函数 定义为判决 是否匹配真实标签 :
此时的策略网络 学习条件概率:
这一步的关键在于,模型不仅要学会“做题”,更要学会“看题”和“挑错”。这种训练方式迫使模型建立起对推理逻辑严密性的内在评价标准。
2.3 第二阶段:生成阶段 (Generating Stage)
此阶段回归到标准的 Vanilla RLVR 设置,但关键在于初始化。
-
初始化:策略模型 使用第一阶段训练好的判别模型权重进行初始化。 -
训练流程:给定问题 ,模型生成思维链和答案 :
-
奖励信号:仅使用稀疏的二值最终答案正确性奖励:
机制假设
作者假设这种两阶段训练通过两种机制提升推理质量:
-
风格迁移(Style Transfer):判别阶段的训练改变了模型的语言风格,使其更倾向于客观、审慎的表达。 -
减少回溯(Reduced Backtracking):模型在生成阶段激活了内化的判别模式,将原本需要显式写出的“验证-纠错”过程在隐空间(Internal Hidden States)中完成,表现为文本中回溯性词汇的减少。
3. 实验设置
为了验证该范式的有效性,作者在数学推理和通用能力基准上进行了广泛的测试。
3.1 模型与算法
-
基础模型:Qwen3-30B-A3B (MoE架构),经过基础 SFT 获得指令遵循能力。 -
训练算法:DAPO (Yu et al., 2025),属于 GRPO (Group Relative Policy Optimization) 家族的策略梯度方法。 -
训练超参: -
Rollout size 。 -
动态采样(过滤掉全对或全错的样本)。 -
学习率 。 -
最大 Token 数 65536(支持长思维链)。
-
3.2 评估基准
-
域内(In-Domain)数学:AIME24, AIME25, MATH500, HMMT_feb_2025, BeyondAIME。 -
域外(Out-of-Domain)泛化: -
GPQA Diamond (科学推理) -
IFEval (指令遵循) -
LiveCodeBenchv6 (代码) -
MMLU-Redux (通用知识) -
ZebraLogic (逻辑推理)
-
3.3 对比基线
-
Base SFT:未经 RL 训练的基座模型。 -
Vanilla RLVR:仅使用最终答案奖励进行单阶段训练(共 250 步)。 -
JudgeRLVR:先判别(145 步)后生成(105 步),总步数与 Vanilla RLVR 保持一致,确保公平比较。
4. 主要实验结果分析
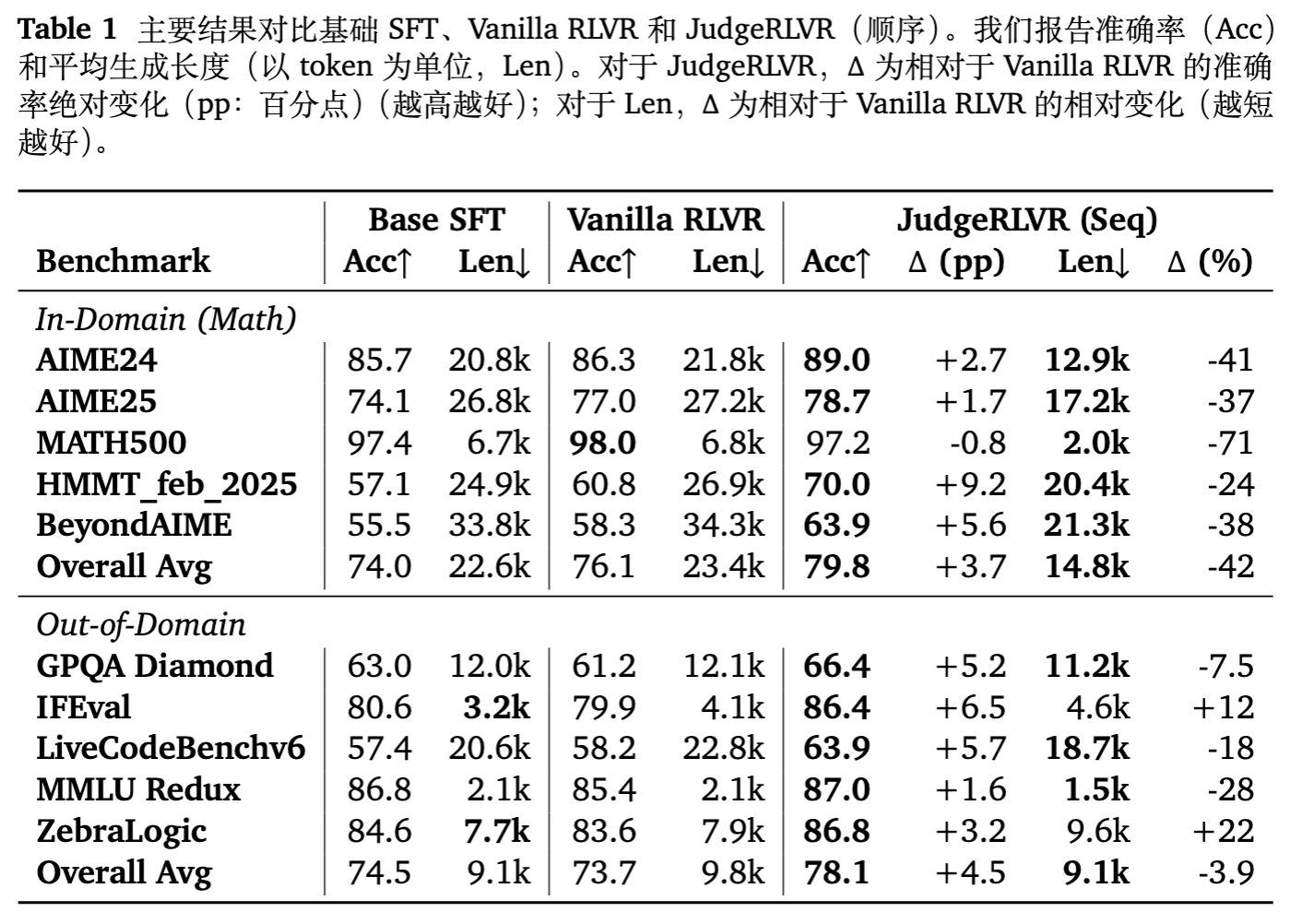
4.1 域内数学:质量与效率的双重飞跃
在 AIME 和 HMMT 等高难度数学基准上,JudgeRLVR 展现了显著的优势:
-
准确率提升:相比 Vanilla RLVR,JudgeRLVR 在所有数学榜单上均取得正向收益。例如,在 HMMT_feb_2025 上提升了 +9.2 个百分点,在 AIME24 上提升了 +2.7 个百分点。 -
长度大幅缩减:这是最显著的成果。在 AIME24 上,平均生成长度从 21.8k 降至 12.9k( -41% );在 MATH500 上更是减少了 71% 。 -
结论:这直接验证了“判别先验”能够有效修剪无效搜索分支。相比之下,Vanilla RLVR 依靠“堆砌长度”来换取微弱的准确率提升,其推理过程充斥着冗余。
4.2 域外泛化:能力迁移
在非数学领域的任务中,JudgeRLVR 同样表现出色:
-
GPQA Diamond:准确率提升 +5.2,长度减少 7.5% 。说明科学推理同样受益于更严谨的判别能力。 -
代码任务 (LiveCodeBench) :准确率提升 +5.7,长度减少 18% 。代码生成往往需要精密的逻辑规划,判别训练显然有助于此。 -
指令遵循 (IFEval) :准确率提升 +6.5,但有趣的是,长度增加了 12% 。这表明对于需要严格格式和约束的任务,模型学会了通过更详细的检查(而非盲目试错)来确保合规性。
总体而言,JudgeRLVR 在域外任务上平均提升了 +4.5 个百分点,证明了该范式习得的是一种通用的“高质量思考模式”,而非仅仅拟合了数学题。
5. 消融实验与机制分析
为了探究收益的来源,作者设计了两组重要的消融实验。
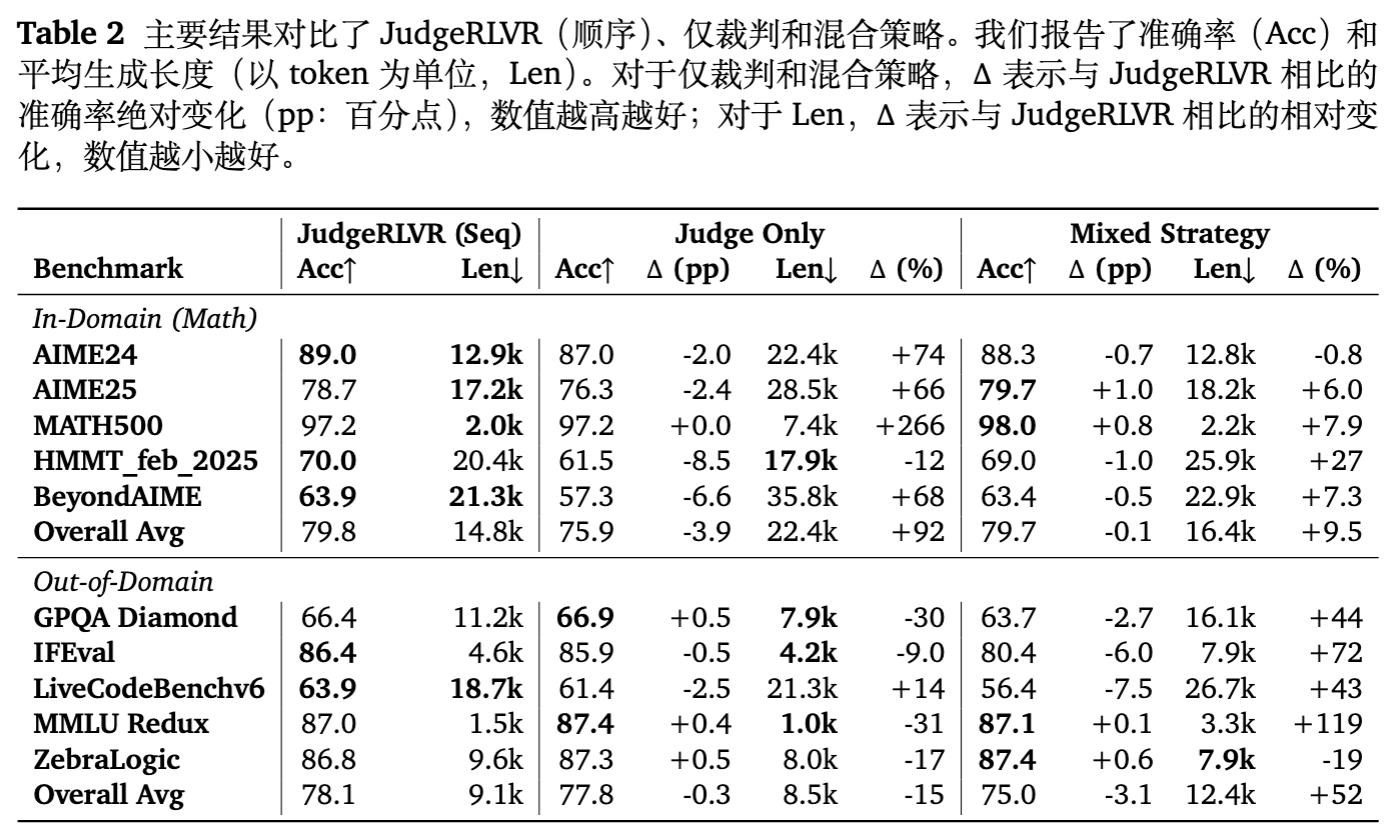
5.1 为什么不能只做判别?
如果仅进行第一阶段的判别训练(Judge Only),模型表现如何?
-
结果:相比 JudgeRLVR,Judge Only 在所有数学任务上准确率均有下降,且生成长度显著增加(例如 AIME24 上长度增加了 74%)。 -
分析:这说明判别训练本身并不会自动转化为简洁的生成策略。相反,一个纯粹的“评论家”模型可能变得过于谨慎和絮叨,倾向于在输出中反复纠结于检查过程。生成阶段(RLVR)是必不可少的,它负责将这种对错误的敏感性转化为高效的路径选择策略。
5.2 为什么必须是两阶段?
如果将判别任务和生成任务混合在一起并行训练(Mixed Strategy),效果如何?
-
结果:表现不稳定。虽然在某些任务上接近 JudgeRLVR,但在 IFEval 和代码任务上大幅退步,且生成长度普遍较长。 -
分析:混合训练导致模型在同一阶段需要优化两个不同的目标(判别 vs 生成),这种干扰阻碍了清晰内部决策过程的形成。顺序执行的策略(先学判别,再学生成)更符合“先学走,再学跑”的学习曲线。
6. 模型到底学到了什么?
作者通过定性和定量分析,揭示了 JudgeRLVR 改变模型思维模式的证据。
6.1 风格迁移 (Perplexity Analysis)
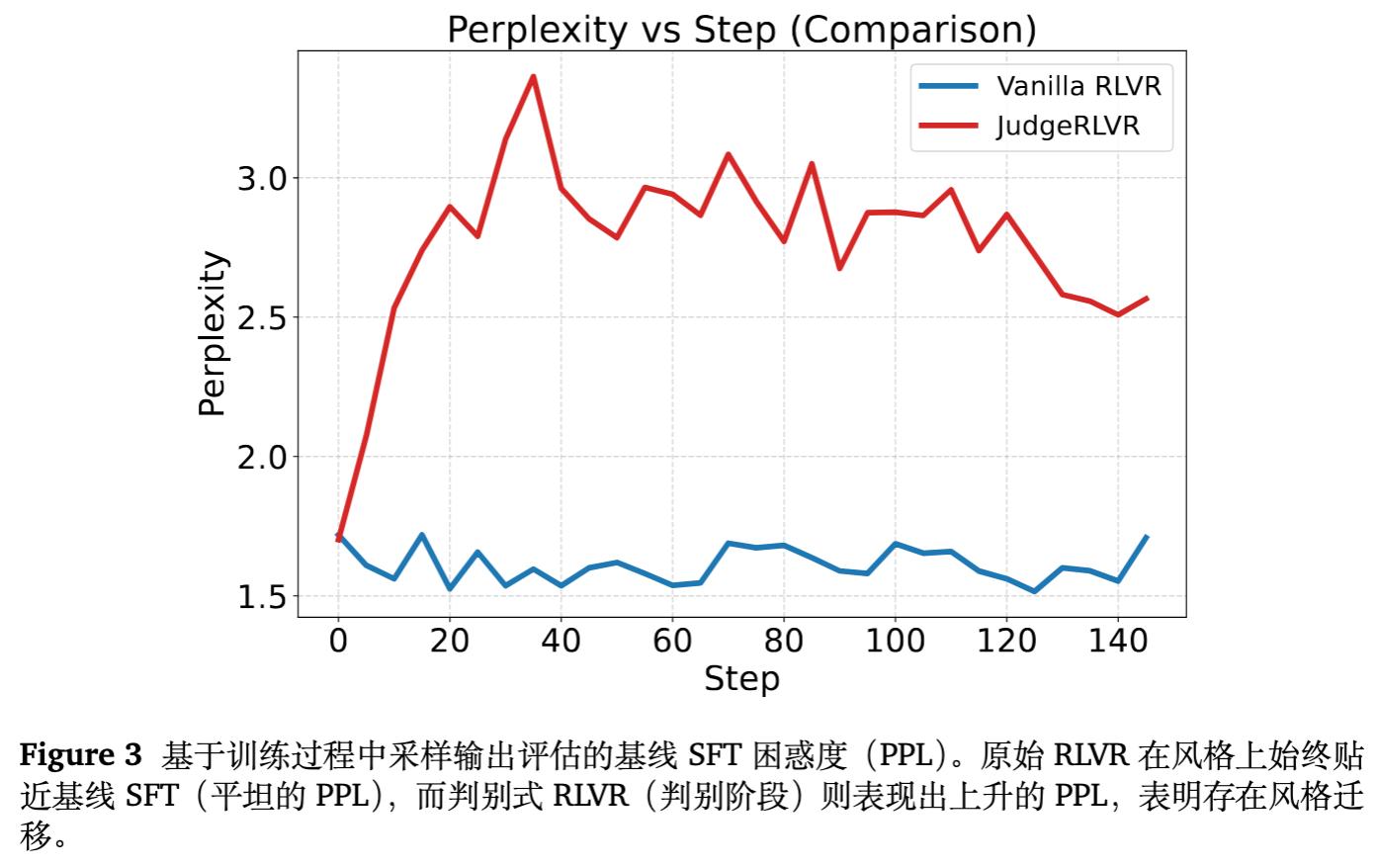
-
作者使用 Base SFT 模型作为探针,计算训练过程中模型输出的困惑度(PPL)。 -
Vanilla RLVR:PPL 保持平坦,说明其输出风格与 Base SFT 差异不大。 -
JudgeRLVR (第一阶段) :PPL 显著上升。这表明判别训练剧烈改变了模型的语言分布,引入了一种不同于原始 SFT 的“裁判风格”。这种风格偏置(Inductive Bias)为第二阶段的高效生成奠定了基础。
6.2 显式回溯的减少 (Reduced Backtracking)
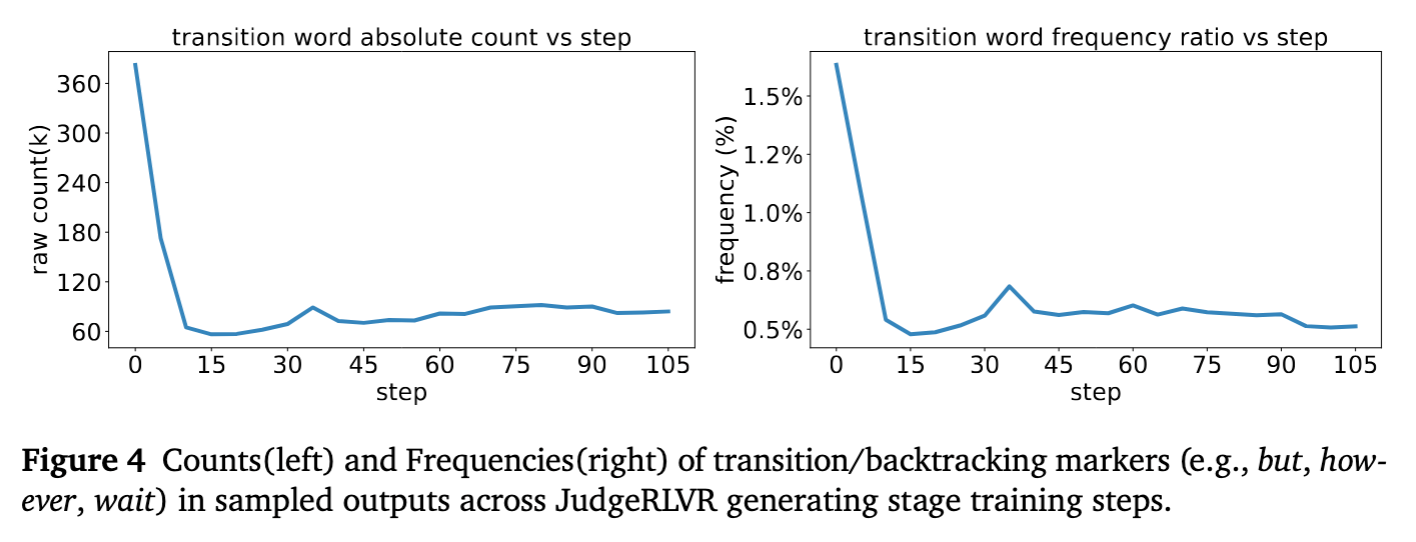
-
作者统计了转折词(如 but, however, wait, actually 等)在生成文本中的频率。 -
结果:在 JudgeRLVR 的生成阶段训练中,这些词汇的绝对数量和相对频率均呈大幅下降趋势。 -
解读:这提供了强有力的语言学证据,证明模型不再依赖显式的“写出错误再修正”(Explicit Self-Correction),而是学会了在思维链展开之前进行隐式的预判和剪枝。
7. 案例研究:思维链的质变
论文通过一个具体的坐标转换问题(直角坐标转极坐标),直观展示了两种范式的区别。
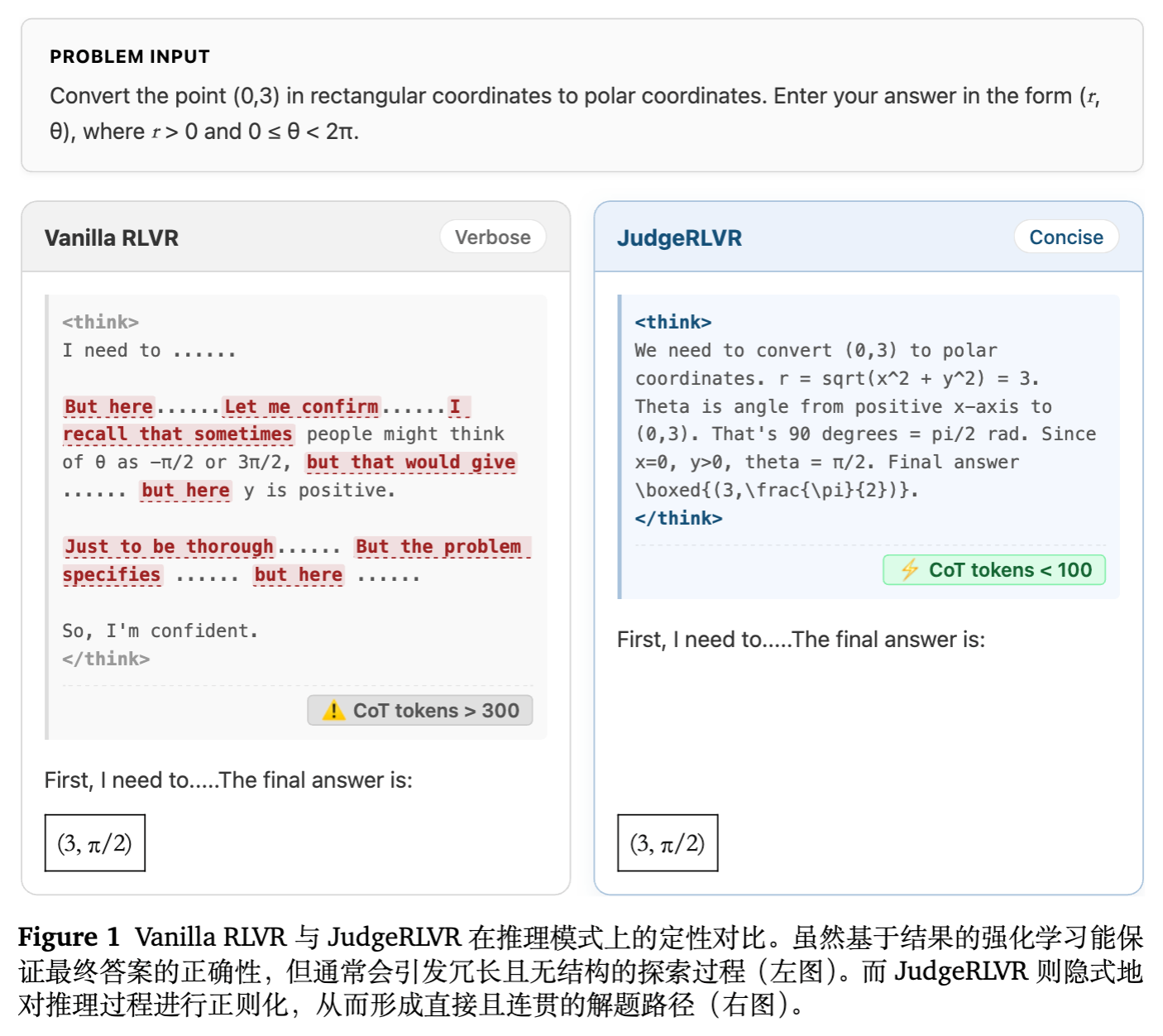
-
Vanilla RLVR 的思维链: -
充满了犹豫和重复验证:“Let me confirm...”, "Just to be thorough...", "But here...". -
甚至出现对非常基础事实的反复确认,显得信心不足。 -
耗费了大量 Token 描述心理活动,而非解题逻辑。
-
-
JudgeRLVR 的思维链: -
开门见山,直接列出公式 。 -
计算过程线性推进,无冗余分支。 -
在得出 后直接输出答案,没有多余的自我怀疑。 -
结果:逻辑清晰,长度仅为 Vanilla 的三分之一,且答案正确。
-
8. 深度讨论与展望
8.1 效率与质量的 Trade-off 新解
长期以来,RLVR 领域存在一种误区,认为更长的 CoT 必然带来更好的性能(Test-time Compute Scaling)。JudgeRLVR 挑战了这一观点,指出当前的许多长 CoT 实际上是低效的“伪推理”。通过提升 Token 的信息密度,我们可以在更短的长度下实现更高的准确率。这对降低 LLM 推理成本具有重大意义。
8.2 与 Process Reward Model (PRM) 的关系
JudgeRLVR 的第一阶段可以看作是一种隐式的 PRM 训练,但它不需要昂贵的逐步标注数据。它通过构建全序列的判别任务(区分 Good/Bad Response),让模型自己习得对过程质量的感知。这为在缺乏细粒度标注的场景下提升推理能力提供了一条新路径。
8.3 局限性
虽然 JudgeRLVR 在数学和逻辑任务上表现优异,但在需要极高创造性或发散性思维的任务上(如创意写作),过早的“剪枝”是否会抑制多样性?这一点仍需进一步探索。
更多细节请阅读原文。
往期文章:


