今天,我们要一起探索一个在人工智能(AI)领域非常重要,特别是驱动像 ChatGPT 这样的大型语言模型(Large Language Models, LLMs)不断进化的核心算法之一:近端策略优化(Proximal Policy Optimization, PPO)。
别担心,虽然这个名字听起来有点“高大上”,但我会用最通俗易懂的语言、最生动的例子,带你一步步揭开它的神秘面纱。读完这篇博客,你不仅会明白 PPO 是什么,还会理解它为什么如此重要。

Part 1: 引言:开启智能之旅
1.1 大模型是什么?
首先,我们来聊聊“大模型”。你可以把它想象成一个拥有海量知识、并且学习能力超强的“虚拟大脑”。这个“大脑”通过阅读互联网上几乎所有的书籍、文章、网站和对话,学会了理解和生成人类的语言。
当你向 ChatGPT 提问时,它并不是在某个数据库里搜索现成的答案,而是利用它学到的庞大知识,像一个真正的“思考者”一样,一个词一个词地组织和生成新的句子来回答你。这就是大模型的魔力所在。
这些模型之所以被称为“大”,是因为它们内部的结构极其复杂,包含了数千亿甚至上万亿个被称为“参数”的旋钮。正是通过调整这些“旋钮”,模型才能学会语言的各种规律和知识。
1.2 为什么大模型需要“优化”?
一个刚“出生”的大模型,虽然知识渊博,但可能还不太“懂事”。它可能会说一些无用、重复甚至不那么友好的话。这就好比一个学富五车的学者,但不一定擅长与人交流。
所以,我们需要对它进行“优化”或“微调”,教会它如何更好地为人类服务。这个过程就像是给这位学者进行“情商”培训,让他学会说有用、真实、且无害的话。
而 PPO 算法,正是在这个“情商”培训过程中,扮演着关键角色的“指导老师”之一。它通过一种叫做强化学习的方法来优化模型。
1.3 欢迎来到强化学习的世界
想象一下你在训练一只宠物狗。当你对它下达“坐下”的指令,它做对了,你就会给它一块零食作为奖励。如果它做错了,你可能就不会给奖励。久而久之,狗狗为了得到更多的零食,就会更频繁地做出“坐下”这个正确的动作。
强化学习(Reinforcement Learning, RL) 的思想与此非常相似。我们让 AI 模型(也就是我们的“学习者”)在一个虚拟的环境中不断尝试,如果它的行为带来了好的结果,我们就给它一个“正奖励”;如果结果不好,就给一个“负奖励”(或者不给奖励)。AI 的目标就是学会一套行为模式,来最大化它能获得的累积奖励。
PPO 算法,就是一种高效指导 AI 如何根据奖励来调整自己行为的强化学习算法。在优化大模型的任务中,这个“奖励”通常来自于人类的反馈。
Part 2: 强化学习基础:在与环境的互动中学习
要理解 PPO,我们必须先掌握强化学习的几个基本概念。它们是构建整个理论大厦的基石。
2.1 核心概念五件套
让我们用一个玩游戏的例子来理解这几个核心概念:
-
智能体 (Agent) :这就是我们的玩家,也就是正在学习的 AI 模型。在我们的故事里,它就是那个需要被优化的大模型。
-
环境 (Environment) :智能体所处的外部世界。对于玩游戏的 AI 来说,环境就是游戏本身。对于大模型来说,环境可以理解为与它对话的用户以及整个对话系统。
-
状态 (State, S) :描述环境在某一时刻的具体情况。在游戏中,状态就是屏幕上显示的画面,比如你的角色位置、敌人的位置、得分等。在与大模型的对话中,状态就是到目前为止的对话历史。
-
动作 (Action, A) :智能体在某个状态下可以做出的行为。在游戏中,动作就是按下“上、下、左、右、攻击”等按键。对于大模型,动作就是生成下一个词或一句话。
-
奖励 (Reward, R) :智能体在执行一个动作后,环境反馈给它的一个信号,用来评价这个动作的好坏。 在游戏中,奖励可以是得分增加(正奖励)或生命值减少(负奖励)。在大模型优化中,奖励来自于人类评估员对模型生成回答的评分。
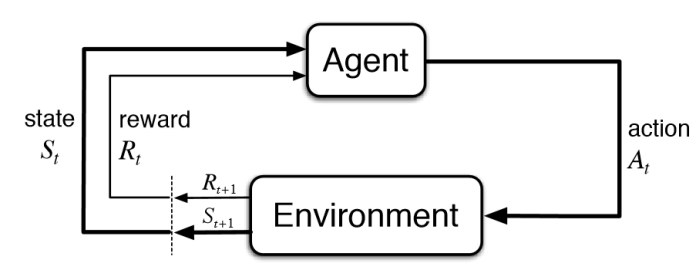
这个过程可以用一张图来表示:
智能体 (Agent) 在某个 状态 (State) 下,选择执行一个 动作 (Action)。环境 (Environment) 接收到这个动作后,会转到一个新的状态,并给智能体一个 奖励 (Reward)。智能体根据这个奖励来调整自己的行为,循环往复。
2.2 目标:最大化累积奖励
智能体的目标不是只看眼前的一步奖励,而是要让长期的、累积的奖励最大化。这就像下棋,有时需要牺牲一个棋子(短期损失)来换取最终的胜利(长期收益)。
我们用 来表示从时间点 开始的未来累积奖励。最简单的计算方式是把未来的所有奖励加起来:
但通常我们会引入一个叫做折扣因子 (Discount Factor) (gamma) 的东西,它的值在 0 和 1 之间。未来的奖励需要乘以这个折扣因子。
这很符合直觉:离现在越近的奖励通常越重要,越远的不确定性越大,价值也就越低。 越接近 0,智能体越“短视”,只关心眼前的奖励;越接近 1,智能体越有“远见”。
2.3 策略 (Policy): 智能体的大脑
那么,智能体是如何根据状态来决定执行哪个动作的呢?答案是策略 (Policy) 。
策略,通常用 (pi) 来表示,它就是一个函数,输入是当前的状态,输出是应该执行的动作。可以把它看作是智能体的“大脑”或“行为准则”。
-
确定性策略 (Deterministic Policy) :在某个状态下,永远只选择一个固定的动作。比如,看到红灯就一定停车。 -
随机性策略 (Stochastic Policy) :在某个状态下,它会给每个可能的动作一个概率。比如,看到黄灯,有 70% 的概率停车,30% 的概率加速通过。我们通常优化的都是随机性策略,用 表示在状态 下选择动作 的概率。
强化学习的目标,本质上就是找到一个最优策略 ,使得智能体遵循这个策略时,能够获得的期望累...
2.4 一个简单的例子:机器人走迷宫
想象一个机器人在一个 4x4 的格子里走迷宫(环境)。
-
状态 (States) :机器人所在的格子位置(共 16 个状态)。 -
动作 (Actions) :上、下、左、右。 -
奖励 (Rewards) :走到终点(右下角)奖励 +1,撞到墙(边界)奖励 -1,走到普通格子奖励 -0.1(为了鼓励它尽快找到终点)。 -
智能体 (Agent) :就是这个机器人。 -
策略 (Policy) :在每个格子里,决定向哪个方向移动的规则。
机器人的目标就是学习一个最优策略,让它能以最快的速度(扣分最少)从起点走到终点(获得+1奖励)。它会在迷宫里不断尝试,撞墙了得到负反馈,它就会知道这个方向不好;离终点近了,它就会逐渐学到走向终点的路径。
Part 3: 策略梯度方法:让策略“更好”的数学魔法
我们已经知道,目标是找到一个好策略。但“好策略”太抽象了,怎么用数学来描述和寻找它呢?这就是策略梯度 (Policy Gradient) 方法要解决的问题。
3.1 从“价值”到“策略”
在策略梯度方法出现之前,很多算法(比如 Q-Learning)的核心思想是去学习一个“价值函数”,这个函数用来评估在某个状态下执行某个动作有多好。然后,智能体总是选择那个价值最高的动作。
这种方法在动作空间很简单(比如只有上下左右四个动作)的情况下很好用。但如果动作是连续的呢?比如控制机器人手臂的角度,可能有无数个选择。或者像大模型生成文本,词汇表里有几万个词,动作空间非常巨大。 在这些情况下,一个个去计算所有动作的价值是不现实的。
策略梯度方法另辟蹊径:我们不学价值函数了,而是直接学习策略本身。
我们把策略参数化,通常是用一个神经网络来表示。这个网络的参数我们记为 (theta)。这样,我们的策略就变成了 。只要我们能找到一组最优的参数 ,就找到了最优策略。
3.2 目标函数 : 如何衡量策略的好坏?
为了优化策略,我们首先需要一个可以衡量的目标。这个目标,我们称之为目标函数 (Objective Function) ,记作 。它衡量了使用参数为 的策略 能获得的期望总回报。
这个公式看起来有点复杂,我们来拆解一下:
-
(tau) 代表一个完整的轨迹 (Trajectory),也就是从开始到结束的一系列状态、动作和奖励的序列:。 -
是这个轨迹的总回报。 -
表示在遵循策略 的情况下,对所有可能轨迹的总回报求期望(平均值)。
简单来说, 就是当前策略的“平均分”。我们的目标就是调整参数 ,让这个“平均分”越高越好。
3.3 梯度上升:最陡峭的“上山”之路
如何让 最大化呢?在数学中,有一个强大的工具叫做梯度 (Gradient) 。一个函数的梯度指向该函数值增长最快的方向。
想象一下你在一个山坡上,想尽快登上山顶。你不需要看地图,只需要每走一步都选择脚下最陡峭的那个上坡方向,就能最快地接近山顶。这个“最陡峭的方向”就是梯度。
这个过程叫做梯度上升 (Gradient Ascent) 。我们的更新规则是:
-
是旧的参数。 -
是更新后的新参数。 -
(alpha) 是学习率 (Learning Rate) ,它控制着我们每一步“走”多远。步子太小,上山太慢;步子太大,可能会“一步跨过山顶”,反而跑到另一边的下坡路去了。 -
就是目标函数 对参数 的梯度。它告诉我们应该朝哪个方向调整 才能让 增长得最快。
3.4 策略梯度定理 (The Policy Gradient Theorem)
现在,关键问题变成了:如何计算这个梯度 呢?
直接对 求导非常困难,因为它依赖于策略和环境的复杂交互。幸运的是,数学家们推导出了一个非常优美的结果,叫做策略梯度定理:
这个公式是策略梯度方法的核心。让我们来理解它的直观含义:
-
:这部分是“方向”。它告诉我们,为了增加在状态 下做出动作 的概率,我们应该如何调整参数 。 -
:这部分是“权重”或“幅度”。它代表了从 时刻开始,我们最终获得了多少回报。
整个公式的含义是:
-
我们用当前的策略 和环境互动,产生很多轨迹。 -
对于轨迹中的每一步 ,我们都计算一个梯度方向 。 -
然后,我们看这一步之后带来了多大的总回报 。 -
如果 是一个很大的正数(意味着这一步之后的决策带来了好结果),我们就在这个梯度方向上前进一大步。也就是说,我们大大增加未来在 状态下选择 的概率。 -
如果 是一个负数(带来了坏结果),我们就在这个梯度方向上“后退”一步(相当于在反方向上前进)。也就是说,我们降低未来在 状态下选择 的概率。
-
-
最后,我们把所有轨迹、所有时间步的这些加权梯度平均起来,就得到了我们最终的更新方向。
这种方法非常直观:好的动作,我们就让它以后出现的概率变高;坏的动作,就让它以后出现的概率变低。
Part 4: PPO 的前身:信赖域策略优化 (TRPO)
基本的策略梯度方法虽然思想简单,但在实践中存在一个大问题:训练不稳定。
4.1 策略梯度方法的问题:一步错,步步错
还记得梯度上升公式里的学习率 吗?它的选择至关重要。
如果 设置得太大,参数 的更新步子就会迈得太大。这意味着策略 可能会发生剧烈的变化。想象一下,一个之前玩得还不错的游戏 AI,突然因为一次更新,开始胡乱操作,导致得分急剧下降。一旦策略变差,它采集到的数据质量也会变差,从而陷入一个“越学越差”的恶性循环,最终可能导致整个训练过程崩溃。
反之,如果 设置得太小,训练速度又会非常慢。如何找到一个恰到好处的 非常困难。
4.2 信赖域 (Trust Region): 谨慎地更新
为了解决这个问题,研究者们提出了信赖域策略优化 (Trust Region Policy Optimization, TRPO) 算法。
TRPO 的核心思想是:我们希望策略能变好,但我们又不希望新策略和旧策略相差太远,因为我们只在旧策略周围的一小块“可信”的区域内,才能保证更新是有效的。
TRPO 的优化目标可以描述为:
最大化 目标函数,同时满足新策略和旧策略之间的“距离”不能超过一个很小的阈值 (delta)。
我们来解释一下这两个公式:
-
上面的目标函数和策略梯度的目标类似,但用了一个叫做优势函数 (Advantage Function) 的东西来代替总回报 。我们稍后会详细讲它,现在你只需要知道, 表示动作 比平均水平要好, 表示比平均水平差。 -
下面的约束条件是 TRPO 的精髓。 叫做 KL 散度 (Kullback-Leibler Divergence) ,它用来衡量两个概率分布之间的差异。这个约束条件强制要求新策略 的分布与旧策略 的分布之间的平均差异不能超过 。
这样一来,TRPO 就把“步子能迈多大”这个问题,从选择一个固定的学习率 ,变成了控制新旧策略的差异程度 。这使得更新过程更加稳定。
4.3 TRPO 的“难”:复杂的计算
TRPO 的思想非常出色,它在很多任务上都取得了比普通策略梯度方法好得多的效果。但它有一个很大的缺点:计算太复杂了。
为了满足那个带 KL 散度的约束条件,TRPO 在每一步更新时都需要求解一个复杂的优化问题,其中涉及到二阶导数(Hessian 矩阵)的计算和共轭梯度法。这些计算量巨大且难以实现,尤其是在神经网络这种参数巨多的模型上。
有没有一种方法,既能拥有 TRPO 的稳定性,又能像普通策略梯度方法一样简单、容易实现呢?
Part 5: 主角登场:近端策略优化 (PPO)
终于,我们的主角 PPO 登场了。PPO (Proximal Policy Optimization) 的目标就是用一种更简单的方法来实现 TRPO 的“信赖域”思想。OpenAI 在 2017 年提出了 PPO,并因为它出色的性能和实现的简单性,迅速成为了强化学习领域的默认算法之一。
PPO 有两种主要形式:PPO-Penalty 和 PPO-Clip。我们主要关注后者,因为它在实际应用中更常见,也更容易理解。
5.1 PPO 的核心思想:简化版的 TRPO
PPO 的目标是:在更新策略时,尽量让新策略不要偏离旧策略太远。它没有像 TRPO 那样使用一个严格的 KL 散度约束,而是直接修改了目标函数,通过一个“裁剪 (Clipping)”的操作来间接实现这个目的。
5.2 PPO 的核心武器 1: 裁剪 (Clipping)
让我们来看看 PPO-Clip 的目标函数:
这个公式是 PPO 的灵魂,我们必须把它掰开揉碎了理解。
5.2.1 概率比率
首先,我们定义一个概率比率 (Probability Ratio) :
-
是新策略下执行动作 的概率。 -
是旧策略下执行动作 的概率(也就是我们上一轮更新前的策略)。
这个比率的含义是:
-
如果 ,说明新策略更倾向于执行动作 。 -
如果 ,说明新策略不太倾向于执行动作 。 -
如果 ,说明新旧策略没变化。
如果没有后面的 min 和 clip,目标函数就是 ,这其实就是 TRPO 的目标函数。PPO 的所有魔法都在 min 和 clip 这两个操作里。
5.2.2 “裁剪”的含义:clip 函数
clip(number, min_value, max_value) 这个函数的作用是把 number 限制在 [min_value, max_value] 这个区间内。
-
如果 number>max_value,则输出max_value。 -
如果 number<min_value,则输出min_value。 -
否则,输出 number本身。
在 PPO 中,我们裁剪的是概率比率 :
这里的 (epsilon) 是一个超参数,通常取一个很小的值,比如 0.2。这意味着,我们把 强行限制在 这个区间内。
5.2.3 剖析 PPO-Clip 目标函数
现在我们可以把整个目标函数 拆成两部分来分析,这两部分由 min 函数连接:
-
第一部分(无裁剪): -
第二部分(有裁剪):
PPO 会取这两部分中的较小值作为最终的目标。为什么要这么做呢?这需要分两种情况讨论,而这两种情况都取决于优势函数 的正负。
情况一: (这是一个好动作)
当优势函数为正时,说明在状态 执行动作 是一个比平均水平更好的选择。我们当然希望提高执行这个动作的概率,也就是增大 ,从而让整个目标函数变大。
-
第一部分: 。随着 的增大,它也随之线性增大,没有上限。 -
第二部分: 。当 增长到超过 时, clip函数会把它“摁”在 。所以这部分的值最大也就是 。
由于 PPO 取的是两者中的最小值,所以当 试图变得太大(超过 )时,整个目标函数的值就被第二部分限制住了,不会无限增长。
这就实现了一个重要的目的:当我们发现一个好动作时,我们鼓励策略去更多地执行它,但我们不希望策略更新得太激进,以至于新策略和旧策略相差太远。通过裁剪,我们给这个“鼓励”设置了一个上限。
情况二: (这是一个坏动作)
当优势函数为负时,说明动作 是一个坏选择。我们希望降低执行这个动作的概率,也就是减小 ,从而让整个目标函数变大(因为一个负数乘以一个更小的正数,结果会更大,更接近0)。
-
第一部分: 。随着 的减小,它也随之增大。 -
第二部分: 。当 减小到低于 时, clip函数会把它“拔高”到 。所以这部分的值最大也就是 。
同样,因为取的是最小值,当 试图变得太小(低于 )时,整个目标函数的值就被第一部分限制住了。
这同样实现了限制更新幅度的目的:当我们发现一个坏动作时,我们鼓励策略去减少执行它,但同样不希望更新太猛烈,导致策略不稳定。
总结一下 clip 的神奇作用:它构建了一个“围栏”,无论是好的动作还是坏的动作,它都限制了由这个动作带来的策略更新幅度,不允许新策略跑得离旧策略太远。这样,PPO 就在没有复杂计算的情况下,巧妙地实现了 TRPO 的核心思想,保证了训练的稳定性。
5.3 PPO 的核心武器 2: 优势函数 (Advantage Function)
前面我们多次提到了优势函数 。现在我们来揭晓它的真面目。
在最原始的策略梯度算法中,我们用的是总回报 来评价动作。但这样做有一个问题:如果一个游戏里,不管怎么玩,所有轨迹的总回报都是正的(比如都在 1000 到 1100 之间),那么根据策略梯度定理,所有执行过的动作都会被或多或少地“鼓励”,这显然不合理。
我们真正想知道的不是一个动作绝对意义上的好坏,而是它相对于当前状态下的平均水平有多好。
这就是优势函数 (Advantage Function) 的定义:
-
:动作价值函数 。表示在状态 下,执行动作 ,然后一直遵循当前策略,能获得的期望总回报。 -
:状态价值函数 。表示在状态 下,遵循当前策略,能获得的期望总回报。它相当于在状态 下所有可能动作的平均价值。
所以,优势函数的含义就是:在状态 下,执行动作 比通常情况(平均水平)要好多少。
-
:动作 优于平均。 -
:动作 劣于平均。
使用优势函数代替总回报 可以大大减小梯度的方差,让训练更稳定。
在实践中,我们通常没有真实的 和 ,需要用神经网络(称为 Critic 网络)来估计它们。这就是所谓的 Actor-Critic 架构,其中 Actor 网络负责输出策略(前面讲的 ),Critic 网络负责评估状态的价值。
5.4 PPO 的完整目标函数
PPO 的最终目标函数通常由三部分组成:
-
:这是我们前面详细讨论过的核心部分,即裁剪后的策略损失。 -
:价值函数损失 (Value Function Loss) 。这是 Critic 网络的损失函数,通常是估计的价值 与真实回报(比如用蒙特卡洛方法计算的 )之间的均方误差。我们希望 Critic 的评估越准越好。 是一个系数。 -
:熵奖励 (Entropy Bonus) 。熵是衡量一个概率分布随机性的指标。策略的熵越大,说明它选择各个动作的概率越平均,探索性就越强。把熵加入目标函数,是为了鼓励智能体进行更多的探索,避免它过早地收敛到一个次优的策略而不再尝试其他可能性。 是一个系数。
通过最大化这个完整的 ,PPO 算法就能同时优化 Actor 和 Critic 网络,实现稳定高效的训练。
5.5 PPO 算法流程
让我们来梳理一下 PPO 的完整工作流程:
-
初始化:初始化 Actor 网络(参数 )和 Critic 网络(参数 )。
-
循环迭代 :在每一轮迭代中,执行以下步骤:
a. 数据收集 (Rollout) :用当前的策略(Actor 网络 )与环境交互,收集一大批数据,包括状态 、动作 、奖励 等。
b. 优势估计 (Advantage Estimation) :对于收集到的每一-步数据,使用 Critic 网络 来计算优势函数 。
c. 优化 (Optimization) :
i. 将收集到的数据分成若干个小批次 (mini-batch)。
ii. 对每个小批次的数据,计算 PPO 的目标函数 。
iii. 使用梯度上升(或梯度下降,取决于目标函数的符号)来更新 Actor 网络的参数 和 Critic 网络的参数 。
iv. 这个优化过程通常会重复好几遍(epochs)。 -
重复:回到步骤 2,用更新后的策略继续收集数据和优化,直到模型收敛。
Part 6: PPO 在大模型中的应用
现在,我们终于可以把所有知识点串联起来,看看 PPO 是如何帮助训练像 ChatGPT 这样的大模型的。这个过程被称为基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF) 。
RLHF 通常分为三个步骤:
第一步:监督微调 (Supervised Fine-Tuning, SFT)
首先,我们找一批高质量的“问题-回答”数据对,这些回答是由人类专家精心编写的。然后,我们用这些数据对预训练好的大模型进行监督学习微调。这一步的目的是让模型先学会模仿人类的回答风格,产生基本有用且符合指令的回答。完成这一步的模型,我们称之为 SFT 模型。
第二步:训练奖励模型 (Reward Model, RM)
接下来,我们需要一个“裁判”来评价模型生成的回答质量。这个“裁判”就是一个奖励模型 (RM) 。
训练奖励模型的过程如下:
-
拿一个问题(Prompt),用 SFT 模型生成多个不同的回答(比如 A, B, C, D)。 -
让人类评估员对这些回答进行排序,比如他们可能认为 B > D > A > C。 -
收集大量的这种排序数据。 -
训练另一个模型(奖励模型),它的输入是一个“问题-回答”对,输出是一个单一的分数(奖励)。训练的目标是让 RM 给出的分数与人类的排序偏好一致。也就是说,RM 应该给回答 B 最高分,给 C 最低分。
第三步:使用 PPO 进行强化学习优化
这是 RLHF 的核心步骤,也是 PPO 发挥作用的地方。
-
智能体 (Agent) :就是我们的 SFT 模型。 -
环境 (Environment) :用户输入一个问题 (Prompt)。 -
动作 (Action) :模型根据 Prompt 生成一个完整的回答。 -
奖励 (Reward) :生成的回答会被输入到第二步训练好的奖励模型 (RM) 中,RM 会给出一个分数作为奖励。这个分数代表了人类对这个回答的偏好程度。 -
策略 (Policy) :模型本身就是策略。 -
优化:我们使用 PPO 算法来更新 SFT 模型的参数。 -
PPO 会根据 RM 给出的奖励来调整模型的策略。如果一个回答获得了高奖励,PPO 就会更新模型参数,让模型未来更倾向于生成类似的回答。 -
如果回答获得低奖励,PPO 就会调整参数,降低生成类似回答的概率。 -
此外,为了防止模型在优化过程中“走火入魔”,产生一些能骗过 RM 但实际上乱七八糟的文本,通常会在 PPO 的目标函数中加入一个惩罚项,这个惩罚项就是当前模型策略与原始 SFT 模型策略的 KL 散度。这确保了优化后的模型不会离它最初学会的“人类风格”太远。
-
通过 PPO 的不断迭代优化,大模型就能学会在保持语言流畅和知识准确的基础上,生成更符合人类价值观、更有用、更安全的回答。
Part 7: 总结
恭喜你!坚持看到了这里,相信你对 PPO 算法已经有了非常清晰的认识。让我们最后回顾一下今天的旅程:
-
我们从大模型和强化学习的基本概念出发,理解了为什么需要对大模型进行优化。 -
我们学习了强化学习的五大核心元素:智能体、环境、状态、动作、奖励,并明确了其目标是最大化累积奖励。 -
我们深入探讨了策略梯度方法,理解了它是如何通过梯度上升直接优化策略本身,以及其核心策略梯度定理的直观含义。 -
我们了解了策略梯度方法的弊端(训练不稳定),以及其改进版 TRPO 如何通过信赖域来解决这个问题,但也引入了计算复杂的难题。 -
我们最终迎来了主角 PPO。我们详细剖析了 PPO 最核心的裁剪 (Clipping) 目标函数,理解了它是如何通过一个简单的 clip操作,巧妙地实现了 TRPO 的稳定更新思想,同时保持了算法的简洁性。 -
最后,我们将所有知识融会贯通,了解了 PPO 在基于人类反馈的强化学习 (RLHF) 流程中扮演的关键角色,揭示了它是如何帮助大模型变得更“智能”和“懂事”的。
为什么 PPO 如此受欢迎?
-
效果好:它在很多复杂的任务中都能取得与 TRPO 相当甚至更好的性能。 -
实现简单:相比 TRPO 复杂的二阶优化,PPO 只使用一阶梯度,代码实现和调试都更加容易。 -
效率高:它的计算效率更高,训练速度更快。 -
稳定性强:在各种超参数下都表现得比较稳定,更容易调参。
PPO 算法的出现,无疑是强化学习发展中的一个重要里程碑。它在理论的完备性和实践的易用性之间找到了一个绝佳的平衡点,为许多复杂 AI 系统的实现提供了强大的技术支持,尤其是在推动大模型对齐人类价值观的进程中,发挥了不可或缺的作用。


