
-
论文标题:OPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in Every Iteration -
论文链接:https://arxiv.org/pdf/2602.05400
TL;DR
今天解读一篇来自上交、千问等团队的一篇文章《OPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in Every Iteration》。该研究针对大语言模型(LLM)预训练中的数据选择问题,提出了一种名为 OPUS (Optimizer-induced Projected Utility Selection) 的动态数据选择框架。
核心观点:现有的静态数据筛选方法忽略了训练动态,而现有的动态选择方法通常基于原始梯度(Raw Gradient)计算数据效用,隐含假设了 SGD 优化器,这与现代 LLM 训练普遍使用的 AdamW 或 Muon 等自适应优化器存在“几何失配”。
主要贡献:
-
优化器感知效用(Optimizer-Aware Utility):定义了在优化器诱导的更新空间中的数据效用,而非原始梯度空间。OPUS 将候选数据的有效更新投影到由分布内 Proxy(代理)数据确定的目标方向上。 -
Bench-Proxy 构建:提出了一种基于检索的 Proxy 构建方法,从预训练语料库中检索与目标 Benchmark 相似的样本,构建稳定的、分布内的目标方向。 -
高效性与可扩展性:结合 Ghost Clipping 技术和 CountSketch 降维,避免了全梯度的物化(Materialization),将额外计算开销降低至 4.7%。 -
多样性采样:使用 Boltzmann 采样替代贪婪 Top- 选择,并引入冗余惩罚项,防止数据同质化。
实验结果:在 GPT-2 Large/XL (30B tokens) 和 Qwen3-8B (Continued Pre-training) 上,OPUS 在计算量匹配的前提下,性能优于 Random 选择及工业界主流的静态(如 DSIR, QuRating)和动态(如 GREATS)基线方法。
1. 引言
随着大语言模型(LLM)参数规模的不断增长,Scaling Laws 指出模型性能与计算量及数据量高度相关。然而,高质量公共文本数据正面临枯竭的风险(即 "Data Wall" 现象,Villalobos et al., 2022)。在此背景下,预训练的研究重心正从单纯追求“更多的 Token”转向挖掘“更好的 Token”。
数据选择(Data Selection)的核心问题在于:在特定的优化步骤 ,哪些 Token 应该被用于更新模型参数?
传统的处理方式通常将数据选择视为预处理步骤(Pre-processing),即在训练开始前对语料库进行一次性的过滤或重加权(例如 FineWeb-Edu 分类器、DSIR 等)。这种静态方法(Static Selection) 具有可扩展性强的优势,但其局限性在于无法感知模型的训练状态——模型在训练初期和末期对数据的需求可能是截然不同的。
相对地,动态方法(Dynamic Selection) 试图在训练过程中根据模型当前状态实时选择数据。然而,现有的动态方法(如基于 Loss 的筛选或基于梯度投影的方法)存在一个根本性的理论缺陷:它们通常在原始梯度空间(Raw Gradient Space) 度量数据的重要性,这隐含地假设了优化器遵循随机梯度下降(SGD)的更新规则。
现实情况是,现代 LLM 训练几乎全部依赖于自适应优化器(如 AdamW)或在大 batch size 下表现优异的 Muon 优化器。这些优化器会对梯度进行预处理(Preconditioning),从而显著改变参数的更新方向。如图 1 所示,忽略优化器几何特性的数据选择会导致“未满足的优化轨迹”。
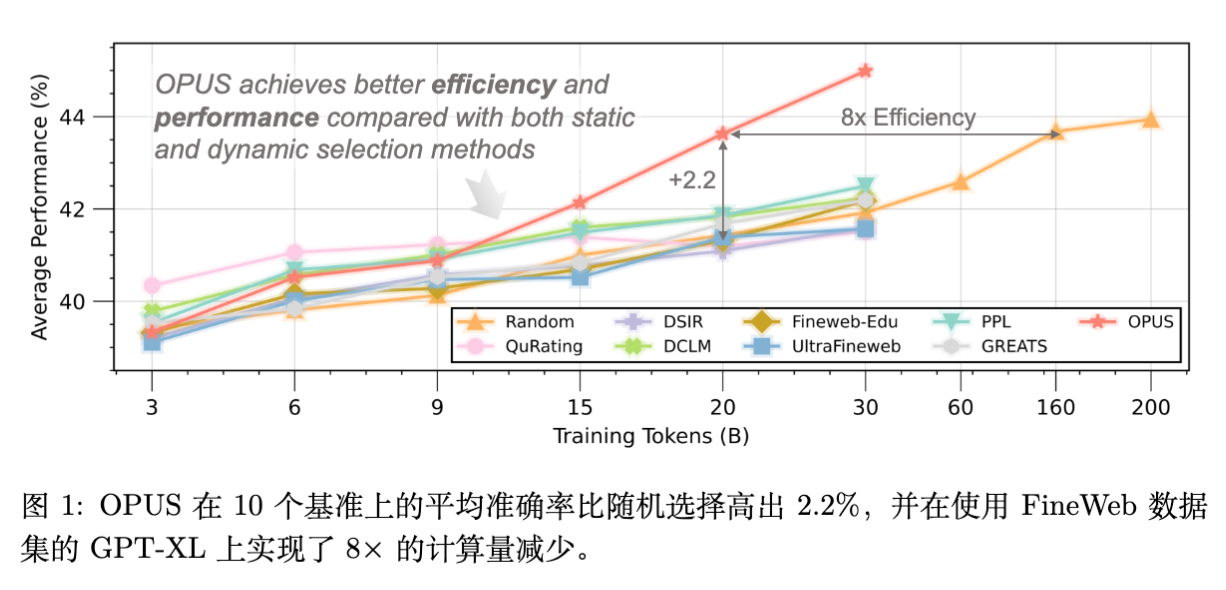
本文提出的 OPUS 框架正是为了解决这一几何失配(Geometry Mismatch) 问题,旨在将数据选择与其在特定优化器下的实际参数更新效果对齐。
2. 优化器诱导的几何失配
为了理解 OPUS 的动机,我们需要形式化地描述 LLM 的参数更新过程。
2.1 预训练更新公式
考虑参数为 的自回归语言模型。在步骤 ,给定一个候选数据 Batch ,优化器根据损失函数 的梯度更新参数。
对于 SGD,参数更新方向与负梯度方向一致:
其中 是学习率。在这种情况下,数据的价值可以通过其梯度与目标方向的内积来衡量。
然而,对于现代优化器,更新方向经过了变换矩阵(或算子) 的预处理:
这里的 封装了优化器的状态(如动量、二阶矩估计等)。
-
AdamW: 近似为一个对角矩阵,其元素与历史梯度的均方根(RMS)成反比。这实际上是对参数空间进行了各维度的独立缩放。 -
Muon:这是一种针对矩阵参数(2D Tensor)设计的优化器,利用 Newton-Schulz 迭代进行正交化。其 是一个非线性的、混合了各维度信息的稠密算子。
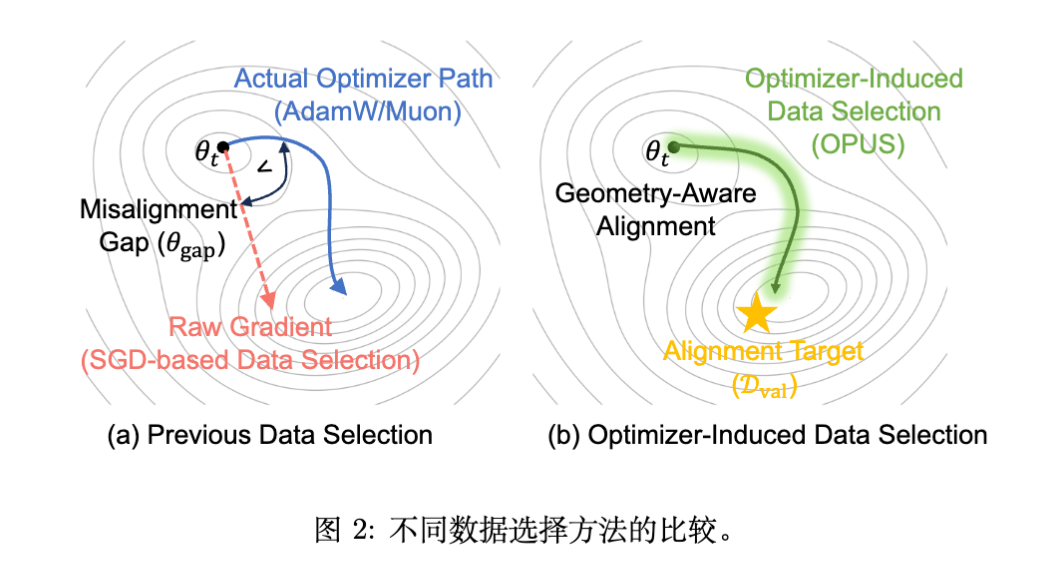
2.2 失配的后果
如果我们在原始梯度空间计算数据分数(例如,计算 ),而在参数更新时应用了 ,那么高分样本产生的实际更新方向可能并不指向验证集损失下降的方向。
这种差异在 Muon 这种非对角预处理优化器中尤为严重,因为 Muon 会混合梯度的坐标,使得原始梯度空间中的方向信息与最终更新方向大相径庭。OPUS 的核心洞察在于:一个 Batch 的价值仅取决于它在优化器特定的几何结构下,能否推动参数向改善目标分布性能的方向移动。
3. OPUS 方法论详解
OPUS 框架包含三个关键组件:
-
目标(Objective):基于优化器诱导更新的效用函数。 -
估计器(Estimator):利用 Ghost Clipping 和 CountSketch 的高效计算方法。 -
选择规则(Selection Rule):带有冗余惩罚的 Boltzmann 采样。
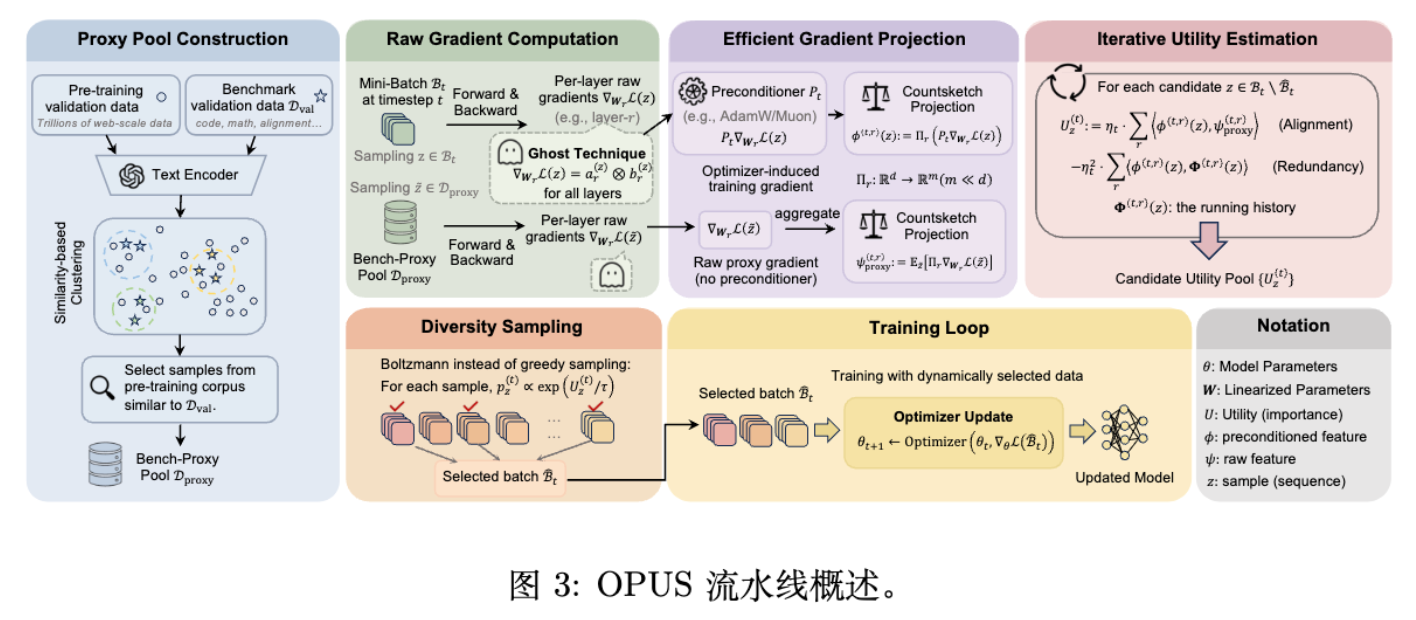
3.1 优化器诱导的效用目标 (Optimizer-Induced Utility)
OPUS 定义候选子集 的效用为执行一步优化后,在验证集 上的损失降低量:
为了评估单个样本 的边际效用(Marginal Utility),即在当前已选集合 的基础上加入 带来的增益,论文利用一阶泰勒展开推导出了近似公式。
令 为样本 在优化器作用下的有效更新方向。则样本 的边际效用可以近似为:
其中:
-
第一项是对齐项(Alignment):衡量样本更新方向与验证集梯度 的一致性。 -
第二项是冗余惩罚(Redundancy Penalty):衡量样本与已选集合中其他样本的相互作用。
由于直接计算 Hessian 矩阵 在 LLM 规模下不可行,OPUS 采用了各向同性近似 。于是评分规则简化为:
其中 是当前已选集合的累积有效更新方向。
3.2 优化器预处理器 的线性化
为了在在线选择中应用上述公式,必须明确写出 的形式。论文针对 AdamW 和 Muon 进行了详细推导。
3.2.1 AdamW 的预处理器
AdamW 维护一阶矩 和二阶矩 。在步骤 ,我们冻结 RMS 几何结构(即认为 在选择当前步数据时是常数)。
AdamW 的有效更新可以近似为:
其中预处理器为对角矩阵:
这表明 AdamW 的 本质上是按坐标重缩放。
3.2.2 Muon 的预处理器
Muon 是一种针对矩阵参数 的优化器,它使用 Newton-Schulz 迭代来近似正交化更新。其更新规则涉及非线性操作 NewtonSchulz(M_t)。
为了进行在线评分,OPUS 冻结了优化器状态,并将 Newton-Schulz 算子线性化为左乘矩阵 。
这里 是一个稠密矩阵,这意味着 Muon 会混合梯度的不同维度。这是一个关键区别:在 Muon 下,样本的效用不仅取决于其梯度方向,还取决于它如何通过 进行变换。
3.3 Bench-Proxy:构建稳定的目标方向
效用函数中的关键是目标方向 (即 )。
-
直接使用随机的 Validation Batch 方差太大。 -
直接使用 Benchmark 原始数据分布差异(Distribution Shift)太大,且梯度噪声高。
OPUS 提出了 Bench-Proxy 策略:
-
使用预训练语料库构建索引。 -
使用冻结的文本编码器(如 Arctic-Embed-L v2)计算 Benchmark 验证集与预训练语料库中样本的相似度。 -
检索与 Benchmark 最相似的 个预训练文档,组成分布内代理池(In-distribution Proxy Pool, )。
在训练的每一步 ,从 中采样一个小 Batch 来估计 。这种方法既保证了目标方向与下游任务的相关性,又确保了代理数据位于预训练数据的流形上,使梯度估计更加可靠。
3.4 可扩展性:Ghost Norm 与 CountSketch
在 LLM 预训练中,直接计算每个样本的梯度 并存储是显存不可承受的。OPUS 结合了 Ghost Clipping (Goodfellow, 2015; Li et al., 2021) 和 CountSketch (Cormode & Muthukrishnan, 2005) 来解决这一问题。
3.4.1 Ghost Technique
对于线性层,样本 的梯度是输入激活 和输出梯度 的外积:
Ghost 技术允许我们在不显式构造 维梯度矩阵的情况下,直接计算梯度的模或内积。
3.4.2 CountSketch 投影
为了进一步降低计算点积的维度,OPUS 使用 CountSketch 将高维梯度投影到低维空间 (实验中 )。
对于线性层 ,预处理后的 Sketch 特征 计算如下:
-
对于 AdamW:由于 是对角的,投影可以保持坐标的可分离结构,计算复杂度仅为 。 -
对于 Muon:由于 是稠密的,理论上需要 。但在具体实现中,通过近似或利用 Muon 结构的特性,依然可以实现高效计算。
最终的效用分数是在 Sketch 空间中计算内积求和得到的,这极大地降低了计算量和内存占用。
3.5 Boltzmann 采样 vs. 贪婪选择
大多数现有的动态数据选择方法(如 GREATS)使用确定性的 Top- 选择。这在数据流非平稳或代理信号有噪声时容易导致过拟合,并且容易选择出高度相似的重复数据(尽管有冗余惩罚项,但硬截断仍可能导致模式坍塌)。
OPUS 采用 Boltzmann 采样(Soft Sampling):
其中 是温度参数。
-
高效用样本有更高概率被选中,但不是绝对。 -
低效用样本仍有非零概率,保持了训练数据的多样性。 -
配合迭代式的选择过程(每次选一个,更新 ,再选下一个),实现了“多样性感知”的动态构建。
4. 算法实现细节
OPUS 的伪代码(Algorithm 1)描述了其在每个训练迭代中的工作流:
-
Batch 采样:从数据流中读取候选 Buffer (例如 个样本)。 -
构建预处理器:从优化器状态中提取 。 -
Proxy 特征生成:采样 Proxy Batch,利用 Ghost+CountSketch 计算其在优化器空间中的投影 。 -
候选特征生成:对 中的每个样本 ,计算其投影 。 -
软采样循环: -
初始化已选集合 。 -
循环 次( 为选择比例)。 -
计算剩余候选者的边际效用 (包含对齐项和当前的冗余惩罚)。 -
根据 进行 Boltzmann 采样,选择一个索引 加入 。 -
更新历史累积方向 。
-
-
更新模型:使用选出的 执行标准的优化器更新。
资源开销分析:
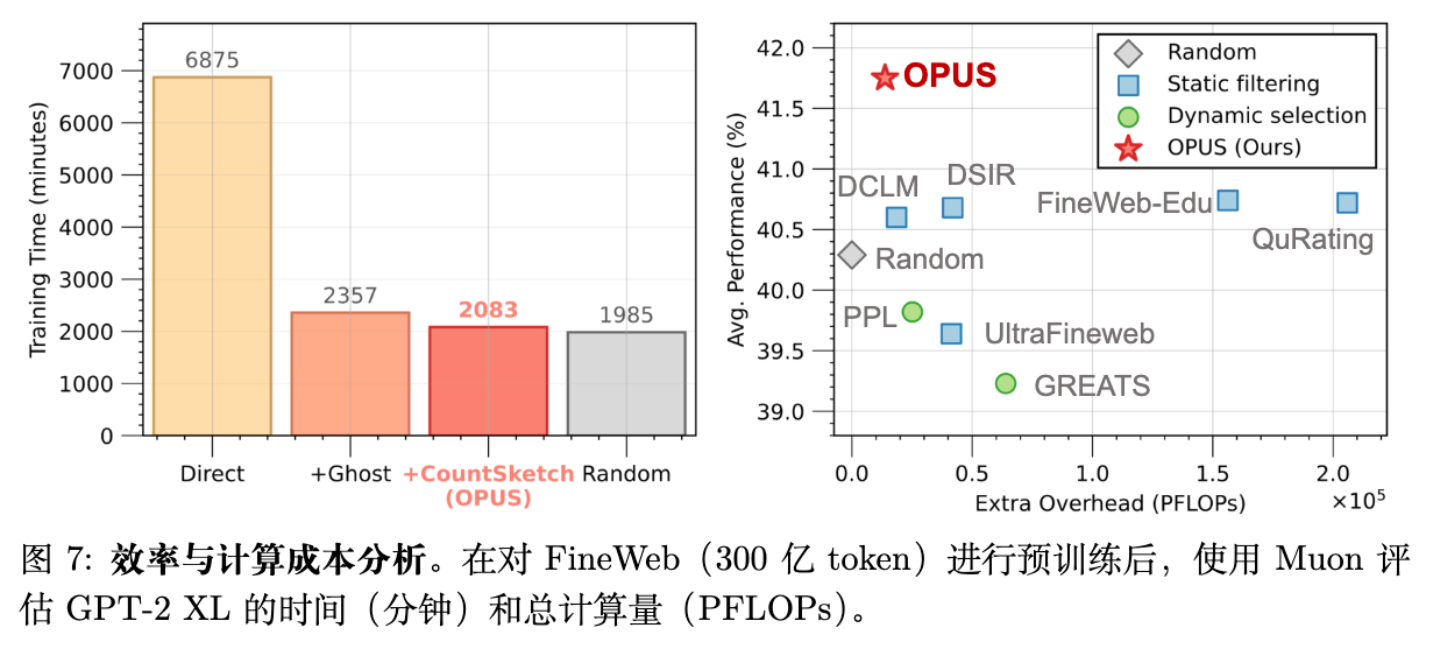
论文指出,通过上述优化,OPUS 带来的额外计算开销仅为 4.7% 。这在“每步迭代都做选择”的方法中是非常高效的。相比之下,一些需要计算完整 Influence Function 或重型静态评分的方法开销要大得多。
5. 实验设置
为了验证 OPUS 的有效性,作者在不同规模的模型和数据集上进行了广泛实验。
-
模型:GPT-2 Large (774M), GPT-2 XL (1.5B), Qwen3-8B-Base (用于持续预训练)。 -
训练预算:固定为 30B tokens(与计算量匹配的比较)。 -
数据集: -
FineWeb:大规模网络语料。 -
FineWeb-Edu:经过高质量筛选的教育类语料。 -
SciencePedia:用于持续预训练的科学领域数据集。
-
-
基线方法: -
静态:Random, QuRating, DSIR, DCLM-FastText, FineWeb-Edu Classifier, UltraFineweb。 -
动态:High-PPL (Loss-based), GREATS (Gradient-based, SGD assumption).
-
-
优化器:对比了 AdamW 和 Muon+AdamW 混合设置。
6. 实验
6.1 从头预训练 (Pre-training from Scratch)
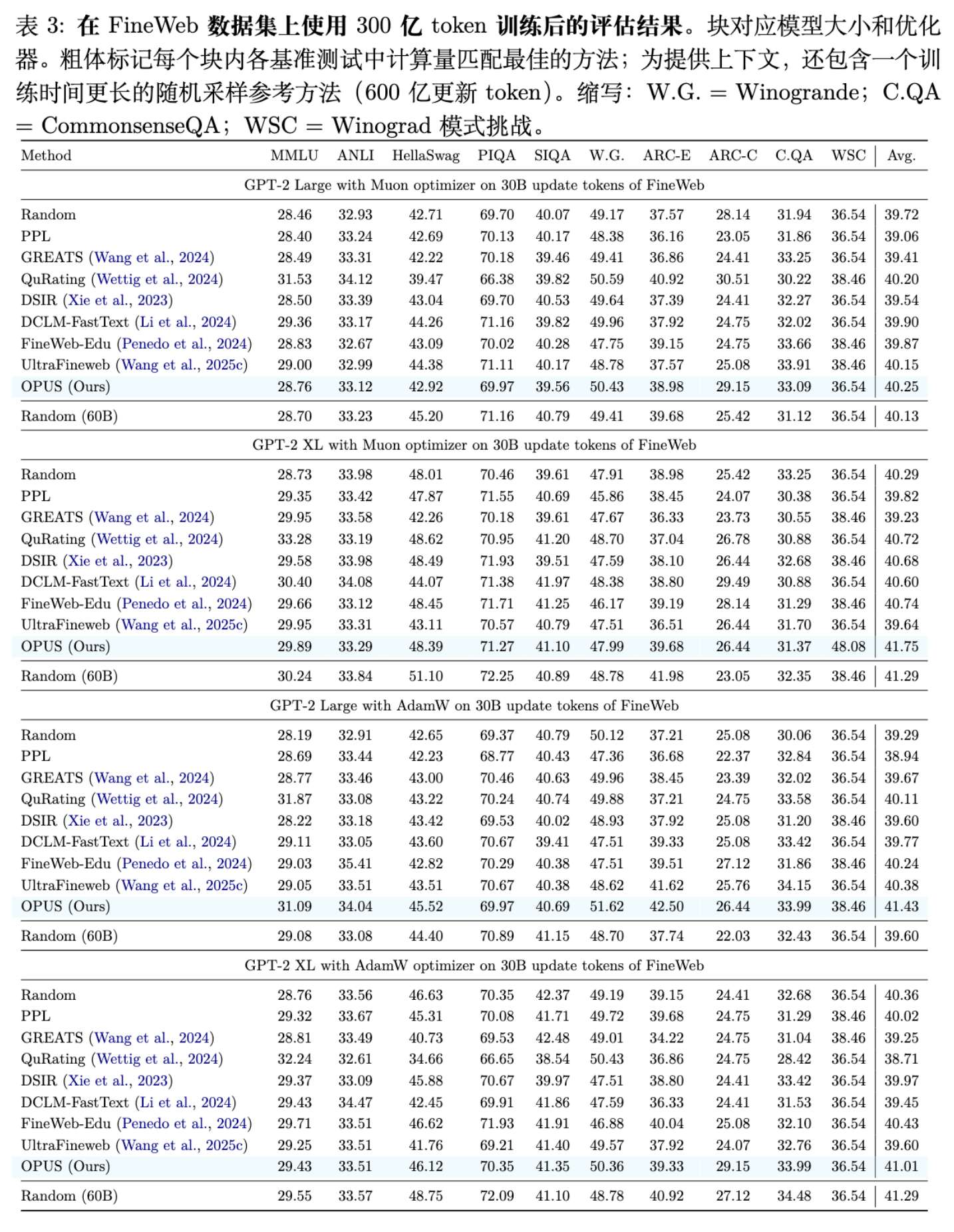
关键发现 1:全面超越基线
在 FineWeb 数据集上,OPUS 在 GPT-2 Large 和 XL 模型上均取得了最高的平均准确率(Avg.)。
-
在 GPT-2 XL (Muon) 设置下,OPUS 达到 41.75 的平均分,显著优于 Random (40.29) 和静态筛选最强者 UltraFineweb (39.64)。 -
值得注意的是,OPUS (30B tokens) 的性能甚至超过了训练更久(60B tokens)的 Random 基线。这意味着 OPUS 实现了超过 2 倍的数据效率提升。
关键发现 2:优化器感知的重要性
实验结果明确支持了“几何匹配”的假设。
-
GREATS 方法假设 SGD 几何,在 Muon 优化器下的表现(39.23)甚至不如 Random(40.29)或仅略好。这说明在复杂的优化器几何下,基于原始梯度的选择可能会产生误导信号。 -
OPUS 显式建模了 Muon 的预处理矩阵,从而能够准确识别对当前优化轨迹有益的样本。
6.2 在高质量语料上的鲁棒性 (FineWeb-Edu)
为了测试极限性能,作者设计了一个更严苛的实验:
-
OPUS 只能从 FineWeb-Edu 的中等质量子集(Score 3)中进行选择。 -
基线方法 则在高质量子集(Score 4+5)上训练。
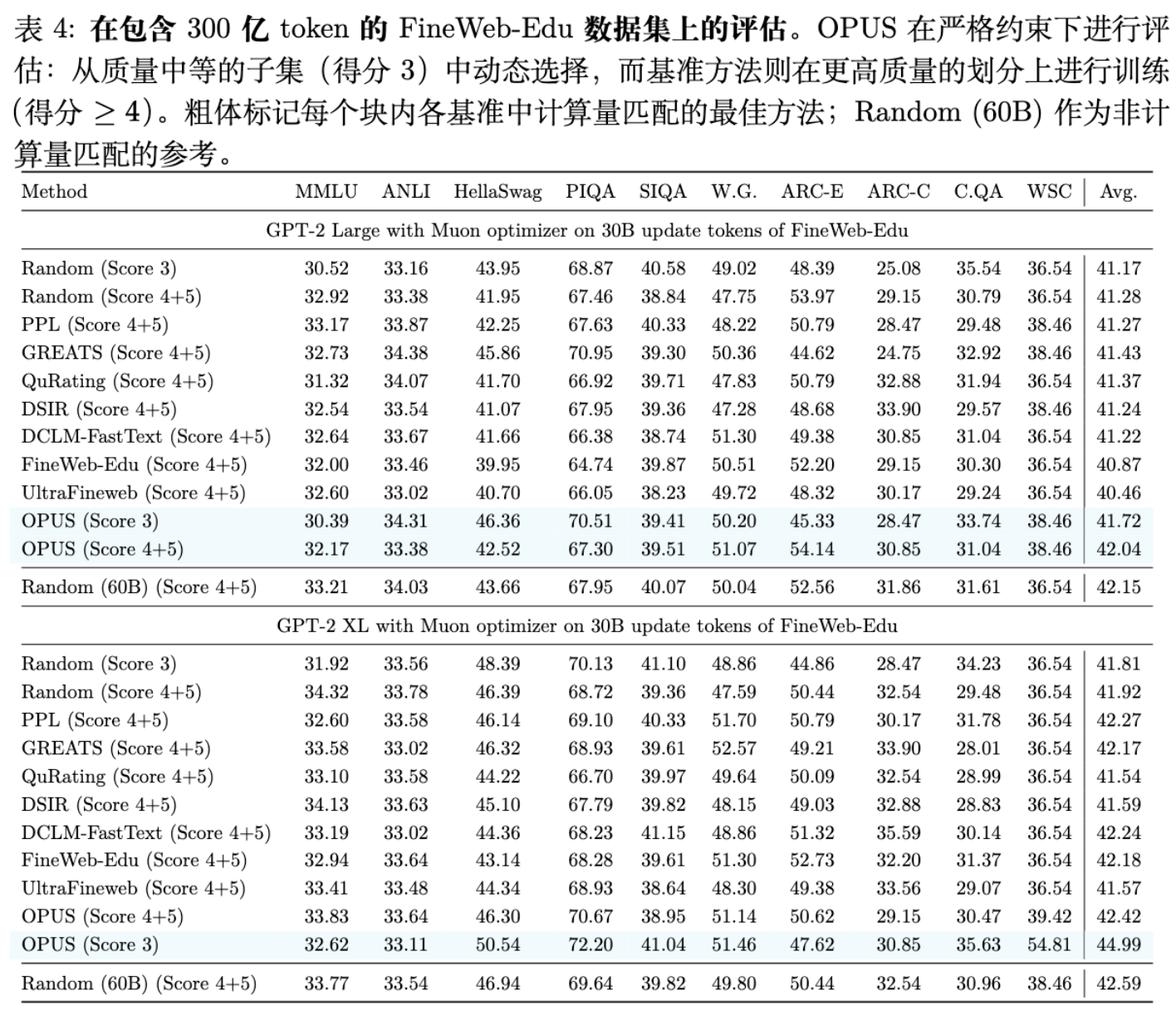
结果解读:
尽管 OPUS 只能访问质量较低的原始数据池,其性能(Avg 44.99)依然击败了在高质量数据上训练的 Random (41.92) 和其他静态方法。这表明:“什么对模型当前最有用”比单纯的“文本静态质量”更重要。 即使是静态评分较低的数据,如果正好填补了模型当前的知识空缺或梯度方向,其训练价值也可能极高。
6.3 持续预训练 (Continued Pre-training, CPT)
在 Qwen3-8B-Base 模型上,作者使用 SciencePedia 数据集进行了持续预训练,评估其在 OlympicArena 和 SciAssess 等科学基准上的性能。
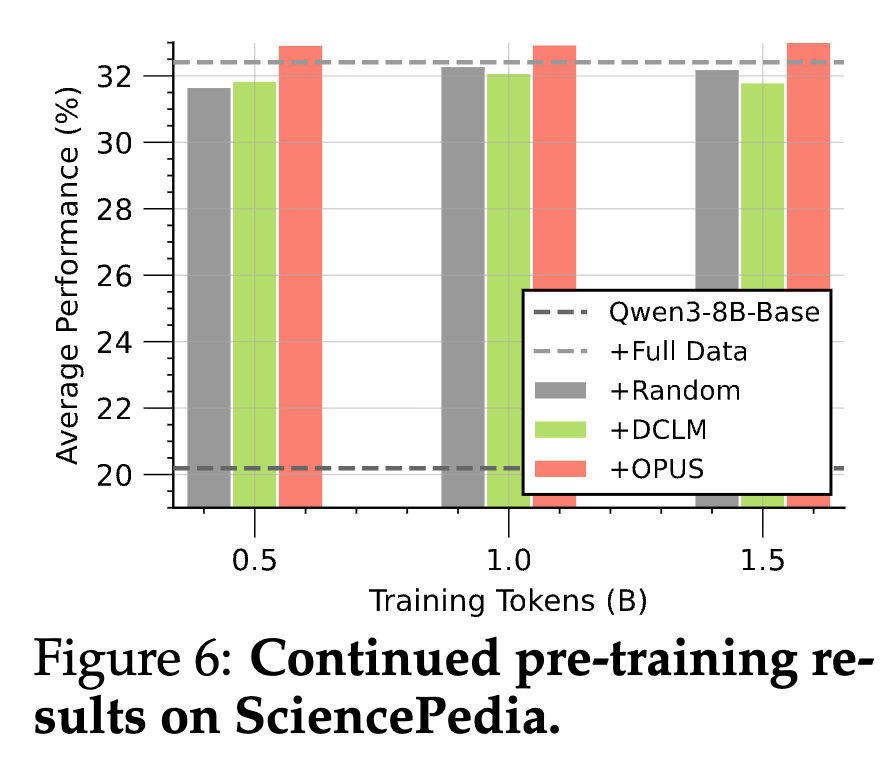
结果解读:
-
OPUS 展现了极高的数据效率:仅用 0.5B tokens 的训练效果就超过了 Random Baseline 训练 3B tokens 的效果(6倍增益)。 -
在特定领域(如物理、化学),OPUS 能够精准筛选出包含核心知识的样本,而过滤掉噪声或低通过率的内容。这对于垂直领域大模型的训练具有极高的工业价值。
6.4 消融实验
作者对 Buffer 大小、采样温度 和投影维度 进行了消融研究。
-
采样策略:表 7 显示,Greedy(贪婪)策略优于 Random 但弱于 OPUS(Soft Sampling)。这证明了保留一定的随机性对防止过拟合和维持多样性至关重要。 -
Proxy 构建:使用 Bench-Proxy(检索构建)比使用 Standard Proxy(随机验证集)性能更好(41.75 vs 41.03),证明了分布内代理的有效性。
7. 定性分析:OPUS 到底选了什么?
为了直观理解 OPUS 的选择逻辑,论文在附录中展示了具体的样本案例。
-
OPUS 的选择:倾向于选择内容多样、且与 Proxy 方向一致的样本。它不仅仅关注“教科书式”的高质量文本,也会选择一些看似普通但能提供特定梯度信息的 Web 文本。 -
与 High-PPL 的对比:基于 Loss (High-PPL) 的方法倾向于选择高困惑度的样本,这些样本往往是含有大量噪声、乱码或极其生僻的文本。这类数据虽然 Loss 大,但对模型泛化能力的贡献通常是负面的。 -
与静态分类器的对比:静态分类器(如 FineWeb-Edu)往往偏好格式工整、教育属性强的文本。而 OPUS 能够在训练后期动态调整,可能会在模型已经掌握基础语法后,转而关注更复杂的语义推理文本,即使这些文本的静态评分可能不高。
8. 相关工作对比
为了凸显 OPUS 的位置,我们需要将其置于现有的研究版图中:
-
静态筛选 (Static Filtering) :
-
代表作:FineWeb-Edu classifier, DSIR, QuRating. -
特点:一次性处理,低训练开销。 -
OPUS 对比:OPUS 是动态的,能适应模型变化。实验证明 OPUS 即使在较差的数据池中也能通过动态选择胜过静态筛选。
-
-
基于 Loss 的动态选择:
-
代表作:Online Batch Selection, Rho-Loss. -
特点:优先选 Loss 大的(Hard Mining)或 Loss 适中的。 -
OPUS 对比:Loss 只是标量,丢失了方向信息。高 Loss 可能是噪声。OPUS 基于梯度投影,关注的是对验证集性能的改善方向,而非单纯的训练集 Loss 大小。
-
-
基于梯度的动态选择:
-
代表作:GREATS, Grad-Match. -
特点:利用梯度相似度。 -
OPUS 对比:这是 OPUS 最直接的竞争对手。GREATS 隐含假设 SGD。OPUS 证明了在 AdamW/Muon 下,必须考虑 。这是理论上的修正,实验结果也证实了其必要性。
-
-
Influence Functions (IF):
-
特点:理论上最严谨,但涉及 Hessian 逆矩阵,计算极其昂贵。 -
OPUS 对比:OPUS 可以看作是 IF 的一种高效近似。它利用优化器自身的预处理矩阵 来近似逆 Hessian 效应,并通过 Ghost+Sketch 技术解决了计算瓶颈。
-
9. 局限性与讨论
尽管 OPUS 表现优异,论文也并没有回避潜在的挑战:
-
Proxy 的依赖性:OPUS 的性能高度依赖于 的质量。如果 Proxy 无法代表目标任务,选择可能会发生偏离(Misalignment)。虽然 Bench-Proxy 缓解了这个问题,但如何构建一个完美的通用 Proxy 仍然是一个开放问题。 -
计算开销:虽然 4.7% 的开销相对于全量梯度计算已经很低,但在千卡、万卡级别的超大规模训练中,任何额外的同步和计算都需要仔细的工程优化。 -
超参敏感性:Buffer 大小和温度 需要调节。虽然论文给出了推荐值,但在不同架构和数据分布下可能需要重新搜索。
10. 结论与展望
OPUS 论文通过引入优化器感知(Optimizer-Awareness) 的概念,将 LLM 预训练数据选择的研究推向了一个更严谨、更符合实际训练动力学的新高度。
它不仅在理论上指出了现有方法在非 SGD 优化器下的几何缺陷,更在工程上给出了一套可扩展的解决方案(Ghost + CountSketch)。对于大模型研究员而言,OPUS 提供了一个重要的启示:数据质量不是绝对的,而是相对于模型状态和优化器几何的动态属性。
未来的研究方向可能包括:
-
将 OPUS 扩展到多模态预训练。 -
研究在 Data Mixture(多源数据混合)权重调整中的应用。 -
探索更高效的 Proxy 构建方法,甚至通过模型生成合成数据作为 Proxy。
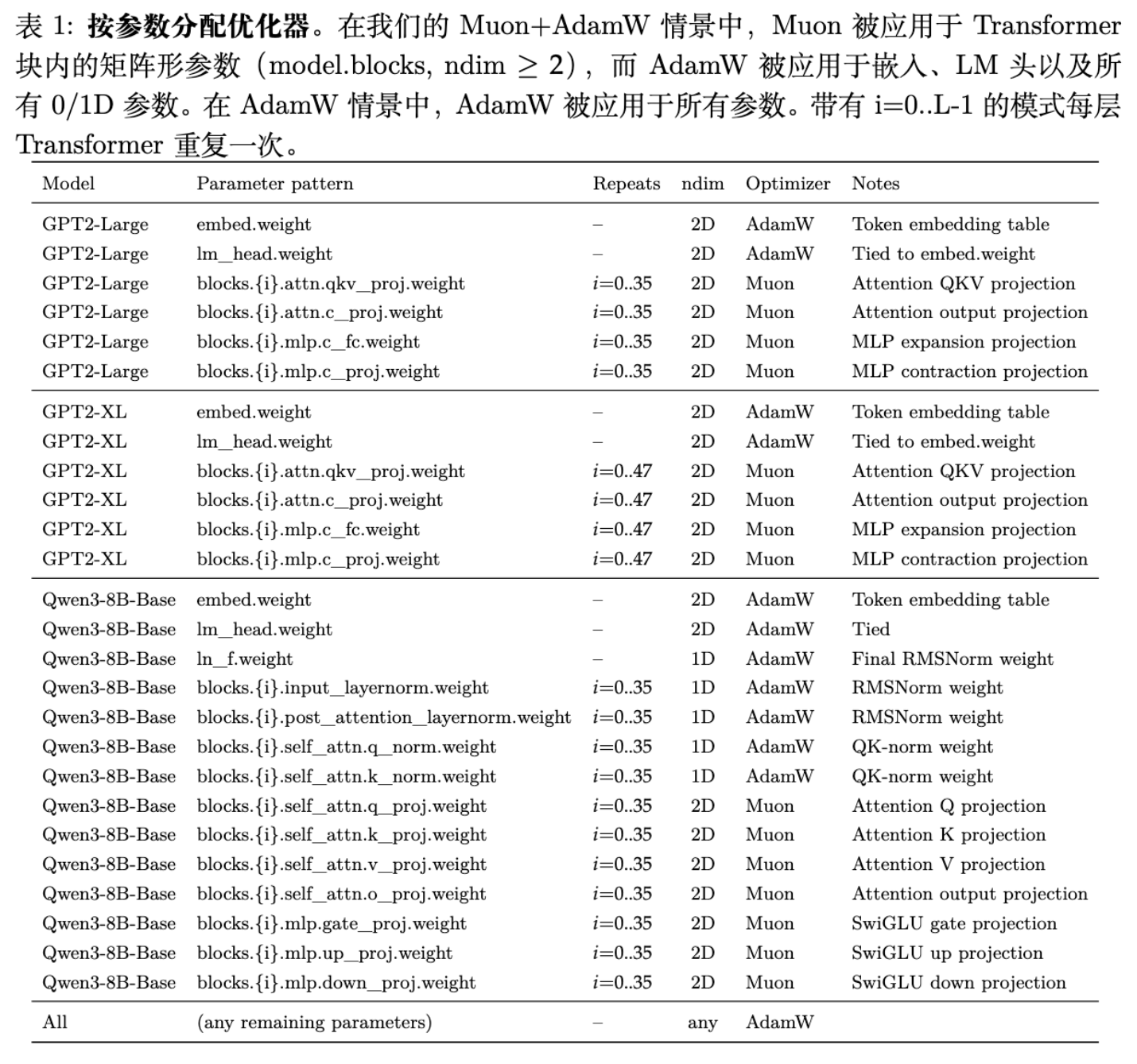
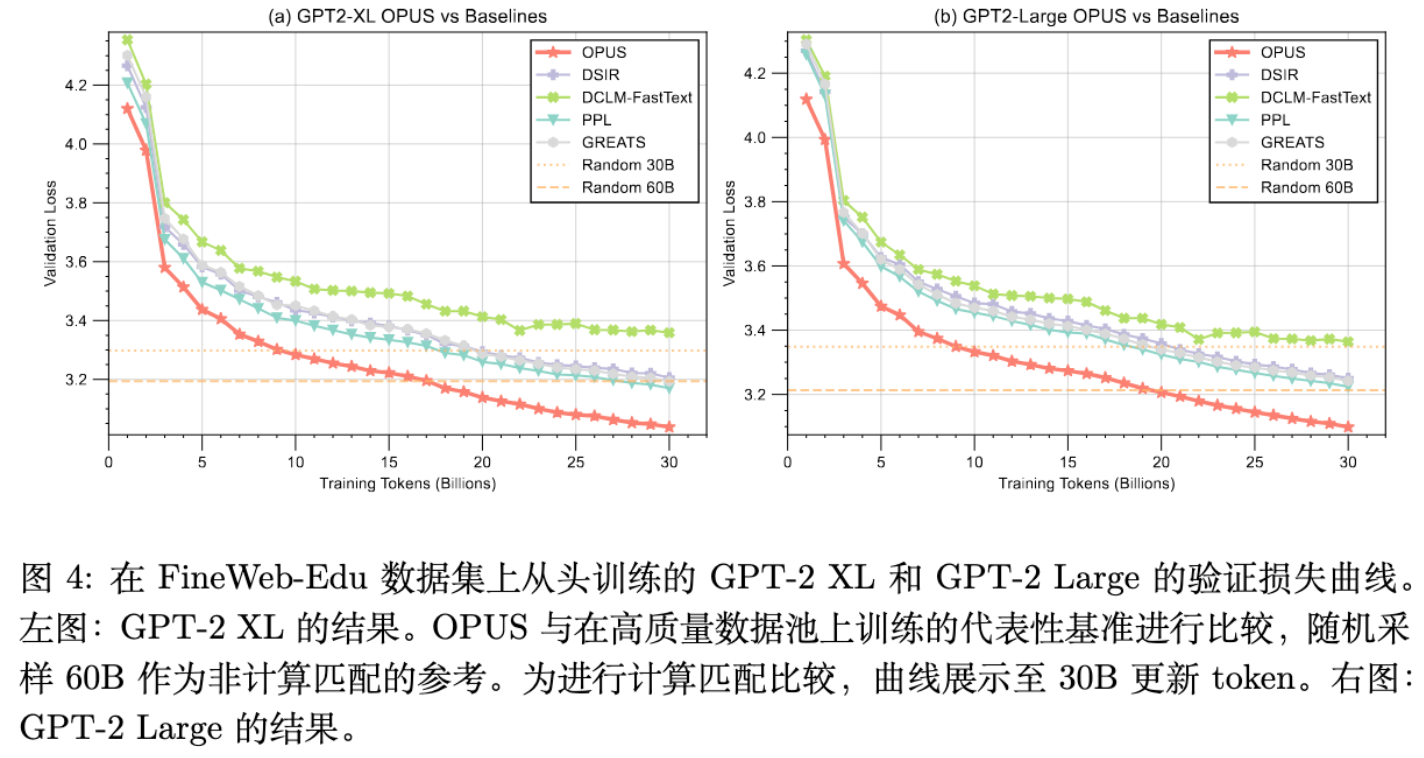
更多细节请阅读原文。
往期文章:


