
-
论文标题:Extending the Context of Pretrained LLMs by Dropping Their Positional Embeddings -
论文链接:https://www.arxiv.org/pdf/2512.12167
TL;DR
当前的语言模型(LLM)在处理超过预训练长度的序列时面临显著挑战。现有的解决方案如位置插值(PI)或 YaRN 虽然能维持困惑度(PPL),但在需要精确检索的长上下文任务(如 Multi-key Needle-in-a-Haystack)中表现不佳。
本文解读的论文 "Extending the Context of Pretrained LLMs by Dropping Their Positional Embeddings" (DroPE) 提出了一种反直觉的观点:位置编码(PE)主要作为训练期间的归纳偏置(Inductive Bias)加速收敛,但在推理和长文本泛化中并非绝对必要,甚至是有害的。
DroPE 方法的核心流程是:
-
正常预训练:使用 RoPE 进行标准的预训练,利用其归纳偏置加速模型学习。 -
移除 PE:在预训练结束后,物理移除所有位置编码。 -
重新校准(Recalibration):在原始上下文长度下,进行极短的继续预训练(约总步数的 fraction),使模型适应无 PE 的状态。
实验表明,DroPE 使得模型在零样本(Zero-shot)情况下能够泛化到远超训练长度的序列,且在长文本检索任务上显著优于 YaRN 等 scaling 方法,同时保持了短上下文的通用能力。
1. 引言
Transformer 架构的自注意力机制(Self-Attention)本身具有排列不变性(Permutation Invariant)。为了处理序列数据,Vaswani 等人在 2017 年引入了位置编码(Positional Encodings, PEs)。随后,旋转位置编码(Rotary Positional Embeddings, RoPE)因其良好的相对位置特性成为了 Llama、Qwen 等主流大模型的标配。
然而,随着对长上下文需求的增加,PE 成为了双刃剑:
-
训练视角:显式注入位置信息对于打破对称性、加速优化过程至关重要。 -
推理视角:当推理长度超过训练长度()时,PE 引入了未见过的旋转角度或位置索引,导致分布外(OOD)问题,模型性能急剧下降。
为了解决这一问题,社区提出了多种 RoPE Scaling 方法(如 PI, NTK-aware, YaRN, LongRoPE),试图通过调整频率来适应长序列。但本文作者指出,这些方法虽然在困惑度指标上看似有效,但在涉及深层信息检索的下游任务中往往失效。
另一方面,无位置编码(NoPE)Transformer 虽然理论上具备图灵完备性(可以通过因果掩码和深层网络隐式编码位置),但其训练收敛极慢,性能通常不如 RoPE 模型。
论文提出的 DroPE 旨在调和这一矛盾:利用 PE 进行训练,但在获得能力后将其丢弃,从而获得无限制的长度外推能力。
2. 理论剖析
论文通过严谨的理论推导和实证分析,建立了三个核心观察(Observation)。我们将逐一深入探讨。
2.1 观察一:PE 是训练收敛的关键加速器
为了理解为什么 NoPE(No Positional Embedding)架构难以训练,作者从优化(Optimization)的角度进行了分析。
2.1.1 注意力位置偏差(Attention Positional Bias)
定义注意力位置偏差 为注意力权重矩阵 的一种线性泛函,用于量化注意力机制对特定位置模式(如关注对角线、关注前一个 token)的偏好程度:
其中 是满足 的位置权重。如果一个注意力头学会了某种位置模式(例如只关注当前 token),那么 的值会最大化。
2.1.2 NoPE 的“冷启动”问题
作者在文中提出了一个极其重要的理论发现:在 NoPE Transformer 中,位置信息的获取受到梯度的严格限制。
命题 3.2 (Proposition 3.2) 指出,对于 NoPE Transformer,如果输入序列由相同的 token 组成(常数序列 ),则:
-
所有注意力头输出均匀分布 。 -
关于 Query () 和 Key () 投影矩阵的梯度消失:。 -
位置偏差的梯度为零:。
这意味着,在极端的常数序列下,NoPE 模型根本无法通过梯度下降学习到任何位置偏好。虽然真实数据不是常数序列,但在初始阶段,由于 Embedding 初始化方差较小,token 嵌入近似均匀。
定理 3.4 (Theorem 3.4) 进一步推广了这一结论。该定理证明了在 NoPE Transformer 中,嵌入的均匀性(Uniformity)会在网络中传播。
定义第 层隐藏状态的“前缀扩散度”(prefix-spread)为 。如果初始嵌入的扩散度很小(),那么对于所有层 :
解读:这意味着在训练初期,NoPE 模型学习位置偏差(如关注特定相对位置)的梯度被初始化的均匀性所抑制(Bounded by )。这解释了为什么 NoPE 模型训练曲线不仅起步慢,而且全程落后于 RoPE 模型(如图 3 所示)。
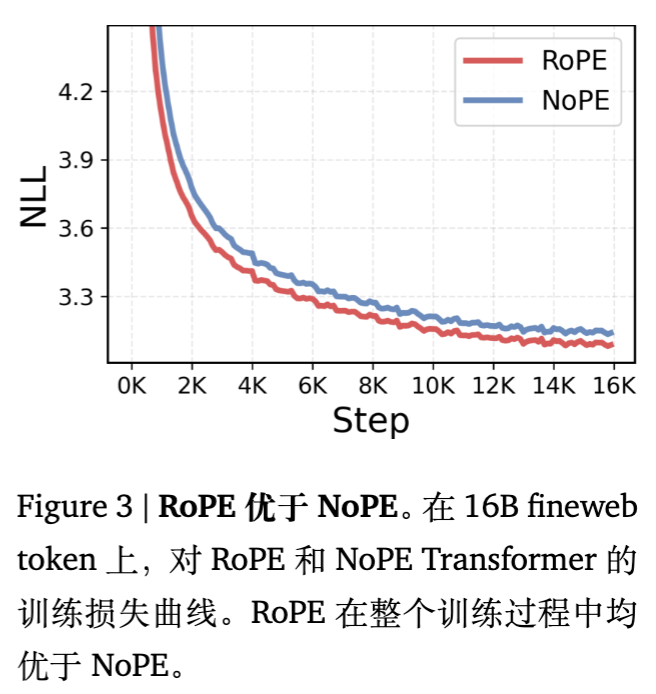
相比之下,命题 3.3 证明了 RoPE 即使在输入为常数序列时,由于旋转操作引入了相对位置差异,其梯度的范数依然大于 0。RoPE 在初始化阶段就打破了对称性,提供了强有力的归纳偏置。
2.2 观察二:RoPE Scaling 破坏了长距离的语义注意力
现有的长上下文扩展方法(如 YaRN)通常通过缩放 RoPE 的频率 来将长序列映射回训练时的相干范围。
RoPE 的核心公式为:
其中 是块对角旋转矩阵,频率 。
当扩展系数为 时,常见方法的频率调整如下:
-
PI (Position Interpolation): 。 -
YaRN: 混合策略,高频部分不缩放(),低频部分按 缩放。
2.2.1 频率与功能的对应关系
Barbero et al. (2024) 的研究表明:
-
高频分量:主要负责编码相对位置信息(如“关注前一个词”)。这些分量对应的波长短,相位变化快。 -
低频分量:主要负责语义内容匹配。这些分量波长极长,在短窗口内相位变化极小,近似于常数,从而允许注意力机制主要关注 Query 和 Key 的内容相似度(点积)。
2.2.2 压缩低频的代价
观察 2 (Observation 2) 指出:为了防止长序列下的相位超出分布(OOD),RoPE Scaling 方法必须压缩低频分量(即乘以 )。
这种压缩导致了一个致命的副作用:在长距离下,低频分量的相位偏移被改变了。
具体来说,对于原本依赖低频分量进行语义匹配的 Attention Head(语义头),其注意力分数不仅仅取决于内容 ,还受到旋转项的影响。当距离 很大时,即使是低频 ,其相位 也会变得显著。
YaRN 等方法通过将频率除以 ,试图将相位拉回 范围内。但这改变了语义头在长距离下的行为模式。
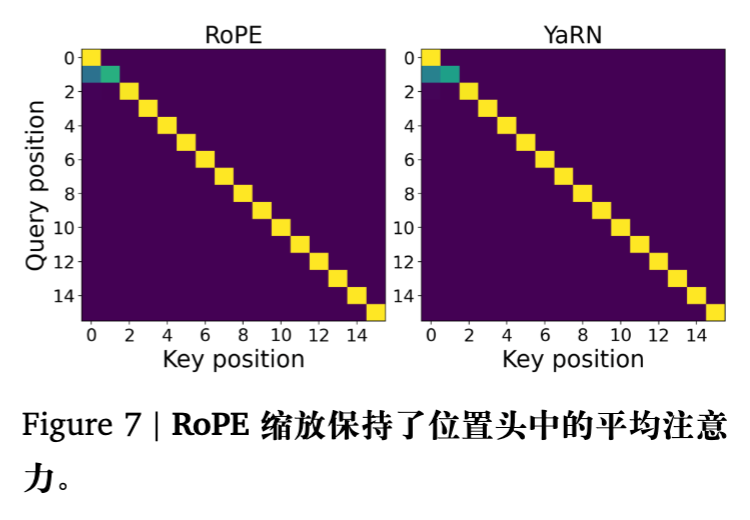
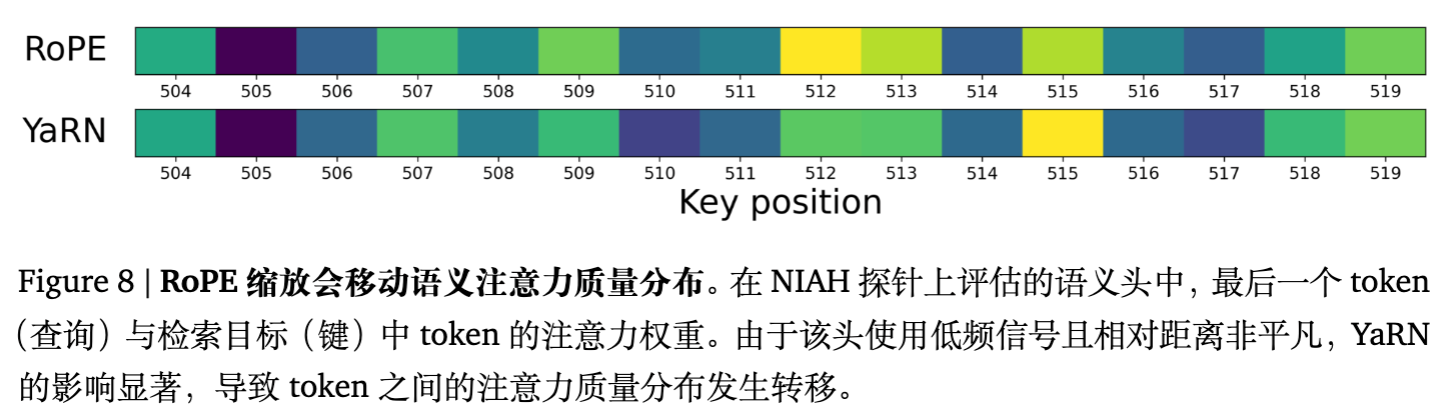
实验(图 8)展示了在 Needle-in-a-Haystack (NIAH) 任务中,YaRN 导致语义头错误地将注意力从“针”(Needle)上移开。这就是为什么 Scaling 方法虽然能维持 PPL(PPL 主要由局部注意力决定),但在需要精确检索长距离信息的任务中表现糟糕的原因。
2.3 观察三:PE 可以被“用完即弃”
结合上述两点:
-
PE 在训练初期是必需的(加速收敛)。 -
PE 在长序列推理时是阻碍(导致 OOD 或 Scaling 副作用)。
逻辑推论便是:在训练完成后移除 PE。
作者假设,经过大规模预训练后,Transformer 已经学会了利用因果掩码(Causal Mask)和深层网络结构来隐式处理位置信息。
3. DroPE 方法详解
DroPE (Dropping Positional Embeddings) 的实施非常简洁,可以无缝集成到现有的预训练流程中。
3.1 算法流程
-
RoPE Pretraining:
使用标准的 RoPE Transformer 在大规模语料上进行预训练。这一步确保模型能够快速学习基本的语言能力和注意力模式。 -
Drop RoPE:
加载预训练好的 Checkpoint,将模型定义中的位置编码部分完全移除。此时模型变为一个 NoPE Transformer。注意,此时模型的参数( 等)是基于 RoPE 训练得到的。 -
Recalibration (Short Continue Pretraining):
在原始上下文长度()下,使用少量数据对 NoPE 模型进行继续训练。-
数据量:只需原训练数据的一小部分(例如 2% - 5%)。 -
学习率:可以使用相对较高的学习率(配合 QKNorm 稳定训练)。 -
目的:让模型参数适应“无位置编码”的环境,学会利用隐式位置信息。
-
-
Zero-shot Context Extension:
推理时,直接将模型应用于任意长度的序列 。由于没有 PE,模型不存在位置索引越界或旋转角度 OOD 的问题。
3.2 关键技术细节:QKNorm
在 Recalibration 阶段,作者发现直接移除 RoPE 可能导致训练初期梯度不稳定(Spike)。为了缓解这一问题,作者引入了 QKNorm (Query-Key Normalization):
在计算 Attention Score 之前对 Q 和 K 进行 LayerNorm 或 RMSNorm。实验表明(见附录 D.3),QKNorm 允许使用更大的学习率(如 级别),从而极大地加速了 Recalibration 的过程。
4. 实验评估
作者在多种规模(0.5B 到 7B)、多种设置(从头训练和基于现有模型)下验证了 DroPE 的有效性。
4.1 从头训练对比 (Training from Scratch)
-
设置:0.5B 参数模型,16B Tokens 训练数据(FineWeb),上下文长度 1024。 -
对比对象: -
RoPE Transformer -
NoPE Transformer -
DroPE(在 14B Token 时移除 PE,继续训练 2B Token)
-
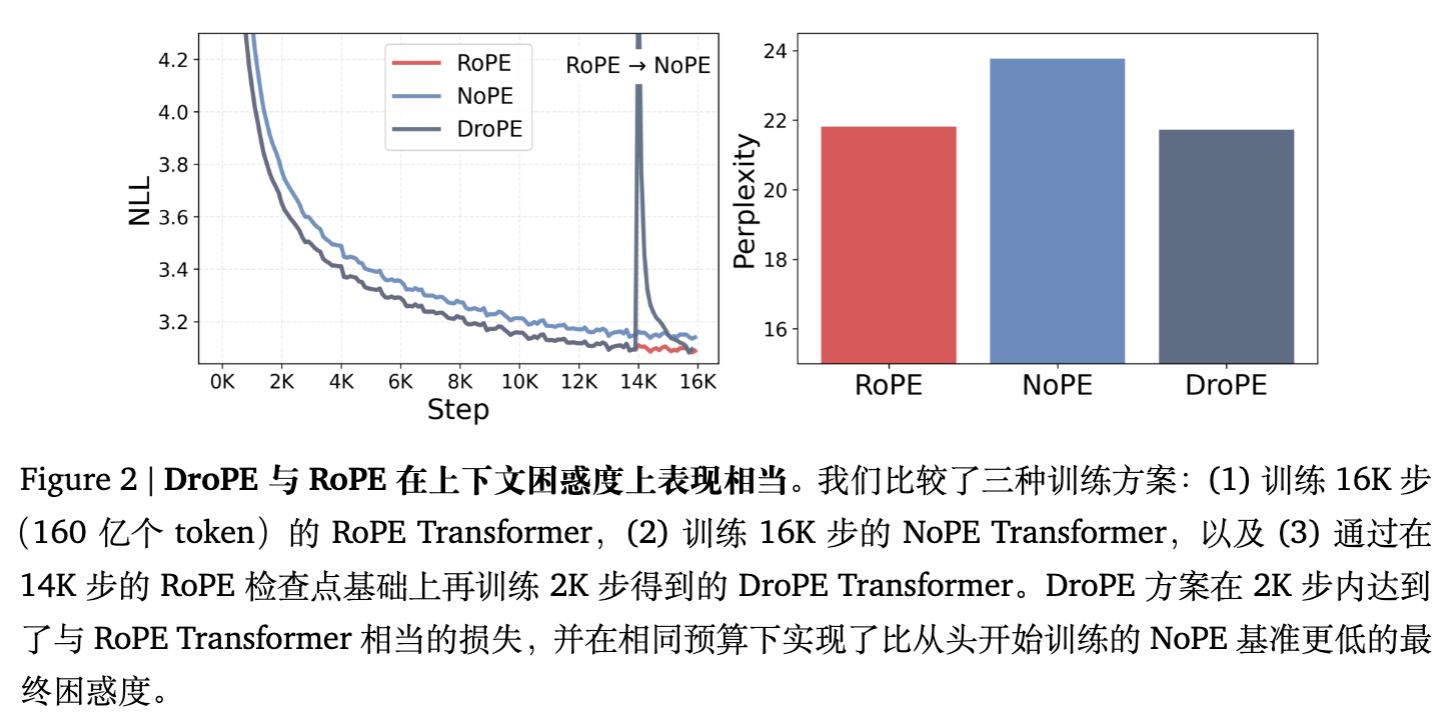
结果:
-
NoPE 的收敛速度明显慢于 RoPE。 -
DroPE 在移除 PE 后,Loss 经历了短暂的震荡,随后迅速下降,最终与 RoPE 模型的 Loss 持平,且显著优于从头训练的 NoPE 模型。 -
这证实了利用 RoPE 进行“热身”是至关重要的。
4.2 长文本检索能力
这是本文最核心的实验结果。作者使用了 RULER Benchmark 中的高难度任务,包括 Multi-Query、Multi-Key 和 Multi-Value NIAH,测试长度为训练长度的 2 倍。
-
Baselines: RoPE (Base), PI, NTK-RoPE, YaRN, ALiBi, NoPE-from-scratch.
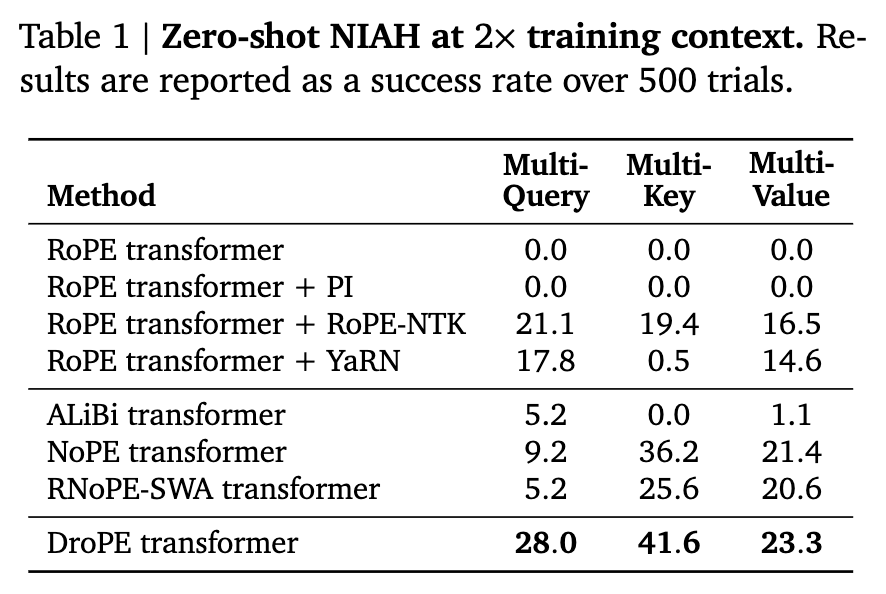
核心发现:
-
RoPE Base 和 PI 在所有任务上全军覆没(0.0%)。 -
YaRN 在简单的 Multi-Query 上有一定表现(17.8%),但在 Multi-Key(0.5%)和 Multi-Value(14.6%)上表现极差。这印证了前文关于 Scaling 破坏语义注意力的理论。 -
DroPE 在所有任务上均取得了最佳性能(28.0% / 41.6% / 23.3%),显著超越了专门设计的长上下文架构(如 ALiBi)和 Scaling 方法。
4.3 现有模型改造 (SmolLM & Llama-2)
为了证明方法的通用性,作者将 DroPE 应用于已经训练好的 SmolLM-360M (600B tokens) 和 SmolLM-1.7B / Llama-2-7B。
-
Recalibration 成本:仅使用了预训练数据量的约 0.5% - 5%。 -
短上下文能力:在 ARC、HellaSwag、MMLU 等标准 benchmark 上,DroPE 模型的性能不仅没有下降,反而略有提升(可能是因为继续训练带来的增益)。
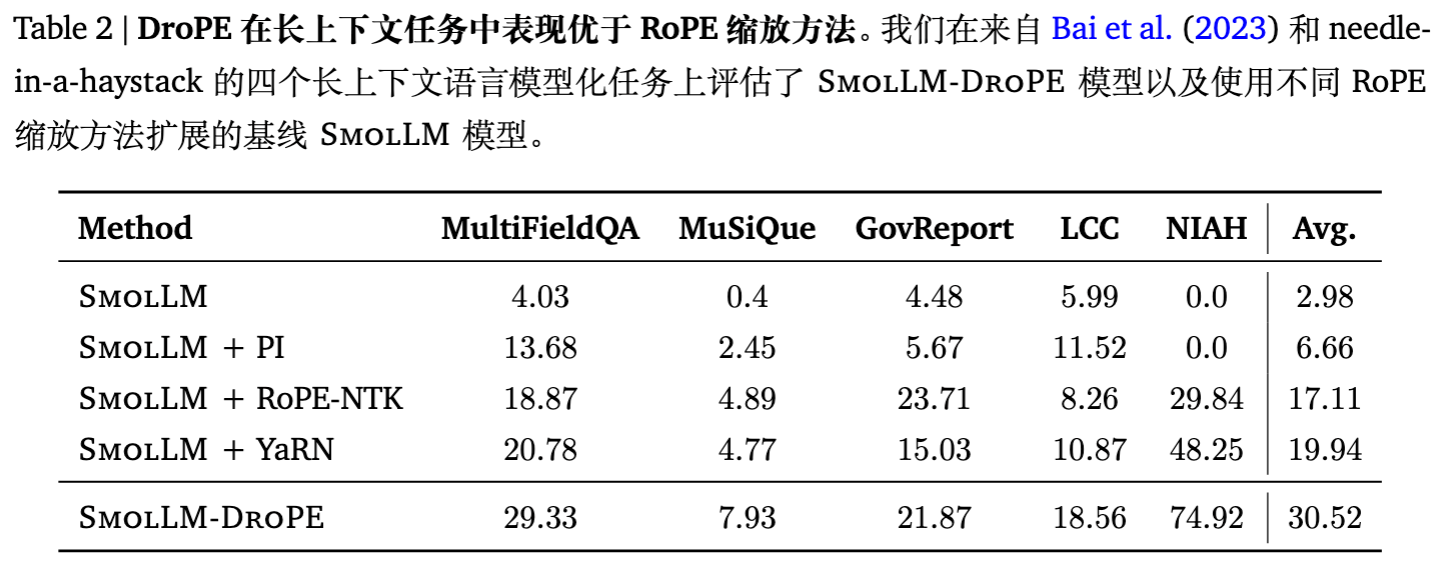
在 MultiFieldQA、MuSiQue、GovReport 等长文本问答和摘要任务中,DroPE 的平均得分(30.52)远超原始模型(2.98)和 YaRN 扩展模型(19.94)。
尤其是在 Llama-2-7B 上,仅需 20B tokens 的 recalibration(相对于 2T 的预训练数据,占比 1%),DroPE 就展现出了强大的长文本泛化能力。
5. 深度讨论与消融实验
5.1 什么时候移除 PE 最好?
作者对比了在训练的不同阶段(0%, 50%, 87.5%, 100%)移除 PE 的效果。
结果显示:越晚移除越好。
如果在 0% 移除,就是难训练的 NoPE。
如果在 14B/16B 处移除,最终的 Validation Perplexity 最低。这再次强调了 PE 作为“训练脚手架”的作用——用得越久,基础打得越牢,拆除后影响越小。
5.2 为什么 RoPE Scaling 会失效?——再探频率域
为了更直观地解释 YaRN 等方法的失败,论文对比了 YaRN 和简单的“截断上下文”(Cropped Context)策略。
令人惊讶的是,YaRN 的零样本表现与直接丢弃超出窗口的信息非常相似。
这是因为当扩展倍数 增大时,为了维持位置编码的分布一致性,低频部分被极度压缩。这种压缩使得原本用于区分长距离语义关系的注意力机制失效,模型实际上退化为只关注局部信息(由高频、未被严重破坏的位置头主导)。
而 DroPE 彻底移除了 PE,迫使模型利用 hidden states 中的语义信息和因果结构来确定关联。虽然这听起来很难,但经过 recalibration,模型学会了不再依赖显式的 ,而是依赖 和 本身的交互以及中间层积累的上下文信息。
5.3 扩展到无限长度?
虽然 DroPE 支持 Zero-shot 扩展,但这并不意味着它可以处理无限长度。限制因素转变为:
-
KV Cache 显存:物理限制。 -
注意力稀释(Attention Dilution):随着序列变长,Softmax 的分母变大,原本尖锐的注意力分布可能会变得过于平滑。 -
因果位置信息的衰减:NoPE 依赖因果掩码隐式传递位置感,这种信号在极深层或极长距离下可能会衰减。
但在实际测试的 8k-32k 范围内(相对于 1k-2k 的训练长度),DroPE 表现出了极佳的鲁棒性。
6. 结论与展望
DroPE 这篇论文对大模型架构设计提出了一个根本性的质问:位置编码真的是 Transformer 的本质组件吗?
论文的结论是:PE 是优化的梯子,而不是表示的基石。
一些实践启示:
-
训练 Pipeline 的新范式:未来的大模型预训练可能分为两个阶段: -
Phase 1: 带强 PE(如 RoPE)的高效学习阶段。 -
Phase 2: 去 PE(DroPE)的泛化适应阶段。
-
-
低成本长窗口适配:对于开源社区,利用少量数据对 Llama-3、Qwen-2 等模型进行 DroPE 处理,可能是一种比微调 LongLoRA 或使用 YaRN 更有效的长窗口扩展手段。
附录:核心数学证明导读
为了满足深度阅读的需求,这里简要梳理 Theorem 3.4 的证明逻辑,解释 NoPE 为何难以训练。
目标:证明 NoPE Transformer 中,如果初始 Embedding 接近均匀,那么深层的注意力偏差 的梯度也是有界的(很小)。
定义:
-
前缀扩散度 ,衡量当前 token 向量与历史平均向量的差异。 -
如果所有 token 都一样,。
证明步骤:
-
初始化:Embedding 。当方差很小时, 很小,即 。 -
注意力层传播:
注意力 logits 差值为 。
由柯西-施瓦茨不等式,logits 的波动被 Key 的扩散度 所界定。 -
Softmax 的平滑性:
Lemma B.4 证明了 。
这意味着 logits 的微小波动只能导致 attention weights 的微小波动。
因此,如果输入是均匀的,注意力权重 接近 (均匀分布)。 -
层间递归:
如果注意力是均匀的,那么输出 接近于 的平均值。
这导致下一层的输入依然保持较低的扩散度 。
论文证明了扩散度的增长是受到 Lipschitz 常数控制的,对于有限层数 ,扩散度始终被 约束。 -
梯度界:
注意力偏差 的梯度取决于注意力权重的非均匀性。
既然注意力权重接近均匀,那么 接近 0,其对参数的梯度 也被 所界定(Theorem 3.4 结论)。
结论:NoPE 在初始化附近存在一个“平原”,梯度极小,导致难以逃离均匀注意力的陷阱。而 RoPE 通过强制旋转,人为制造了巨大的 ,使得梯度能够迅速指引模型关注特定的相对位置。
更多细节请阅读原文。
往期文章:


