
-
论文标题:DeepSeek-OCR 2: Visual Causal Flow -
论文链接:https://github.com/deepseek-ai/DeepSeek-OCR-2
TL;DR
DeepSeek-OCR 2 提出了一种名为 Visual Causal Flow(视觉因果流) 的新颖编码范式,旨在解决传统多模态模型中视觉 Token 扫描顺序(光栅扫描)与人类视觉认知顺序不匹配的问题。核心改进在于引入了 DeepEncoder V2,它使用一个参数量较小的 LLM(Qwen2-0.5B)作为视觉编码器,并通过通过定制化的注意力掩码(Attention Mask),结合了 ViT 式的双向注意力和 LLM 式的因果注意力。模型引入了可学习的 Causal Flow Queries,在编码阶段即对视觉信息进行语义重排序,实现了从 2D 空间结构到 1D 逻辑序列的软对齐。实验表明,该架构在仅使用 256-1120 个视觉 Token 的情况下,在文档理解基准 OmniDocBench v1.5 上取得了优于现有模型的性能,同时显著降低了计算开销。
1. 引言
在当前的大型视觉-语言模型(LVLM)研究中,编码器(Encoder)的设计往往落后于解码器(Decoder/LLM)的演进。主流架构通常遵循 "ViT + Adapter + LLM" 的范式。其中,ViT(Vision Transformer)将图像切分为 Patch,并按照从左到右、从上到下的光栅扫描(Raster-Scan)顺序展平成一维序列。
这种处理方式引入了一个强烈的空间归纳偏置(Inductive Bias):它假设图像的语义逻辑与物理坐标的线性扫描顺序一致。然而,对于自然图像,尤其是包含复杂排版(如多栏文本、表格、公式插入)的文档图像而言,这种假设往往是不成立的。人类的视觉感知系统并非机械地扫描像素,而是基于语义理解进行因果驱动(Causally-driven)的跳跃式关注(Foveal Fixations)。
DeepSeek-OCR 2 的核心动机正是为了打破这种僵化的空间映射。作者认为,视觉 Token 进入 LLM 之前,应当根据图像的内在语义逻辑进行重排序。基于此,论文提出了 DeepEncoder V2,探索了一种利用级联的因果推理结构(Cascaded Causal Reasoning)来实现更符合认知逻辑的 2D 图像理解方法。
2. DeepEncoder V2
DeepSeek-OCR 2 的整体架构主要由 DeepEncoder V2 和 DeepSeek-MoE Decoder 两部分组成。其中,DeepEncoder V2 是本次升级的核心。
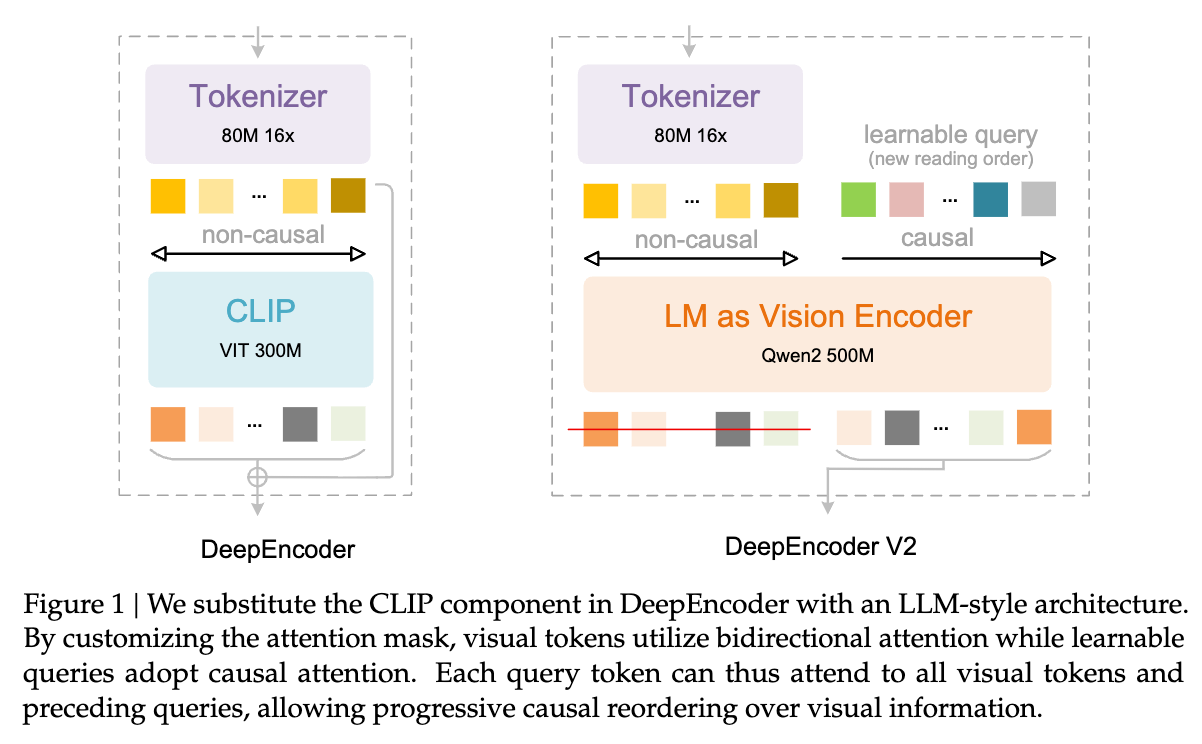
2.1 视觉分词器
DeepEncoder V2 沿用了前代 DeepSeek-OCR 的分词策略,采用了一个参数量约为 80M 的混合架构:SAM-base + 卷积层。
-
基础骨干:Segment Anything Model (SAM-base)。 -
下采样:通过两层卷积层进一步压缩特征。 -
压缩率:实现了相对于原始 Patch 的 压缩。
设计考量:
尽管目前的趋势是直接使用简单的 Patch Embedding 以保留更多细节,但作者保留这种压缩式 Tokenizer 是出于计算效率的考量。通过窗口注意力(Window Attention)机制,SAM-base 在保持较低参数量(~80M,与 LLM 的 Text Embedding 层相当)的同时,大幅降低了后续全局注意力模块的序列长度和显存占用。这种设计将进入编码器主体的 Token 数量控制在一个非常经济的范围内。
2.2 LLM as Vision Encoder:架构的统一化
这是 DeepEncoder V2 最显著的创新点。作者移除了前代中使用的 CLIP 组件,取而代之的是一个LLM 风格的架构(具体实例化为 Qwen2-0.5B)。
这一改动并非简单的模型替换,而是涉及对 Transformer 计算模式的根本性调整。在传统 VLM 中,Encoder 通常是双向注意力(如 BERT/ViT),而 Decoder 是因果注意力(如 GPT)。DeepEncoder V2 试图在一个 Encoder 内部同时融合这两者的特性。
为什么选择 LLM 架构作为视觉编码器?
-
参数效率:Qwen2-0.5B (500M) 与 ViT-L (300M) 参数量级相当,但在大规模语言数据上预训练过的架构可能具有更好的通用序列建模能力。 -
统一模态的潜力:使用标准的 Transformer Decoder Block 作为编码器,为未来统一多模态(Omni-modal)编码打下基础。
2.3 视觉因果流(Visual Causal Flow)与注意力掩码设计
为了实现“视觉 Token 的语义重排序”,DeepEncoder V2 引入了一组可学习的查询向量,称为 Causal Flow Queries。模型在输入序列中将这些 Query 拼接在视觉 Token 之后。
为了让这组 Query 具备重排序能力,作者设计了一种特殊的注意力掩码(Attention Mask)。设 为视觉 Token 序列, 为 Causal Flow Query 序列。
2.3.1 注意力掩码的数学形式
注意力掩码 由两个区域拼接而成:
其中:
-
是视觉 Token 的数量。 -
是 Causal Flow Query 的数量。 -
表示全 1 矩阵(允许注意力)。 -
表示全 0 矩阵(禁止注意力)。 -
是一个 的下三角矩阵(因果掩码)。
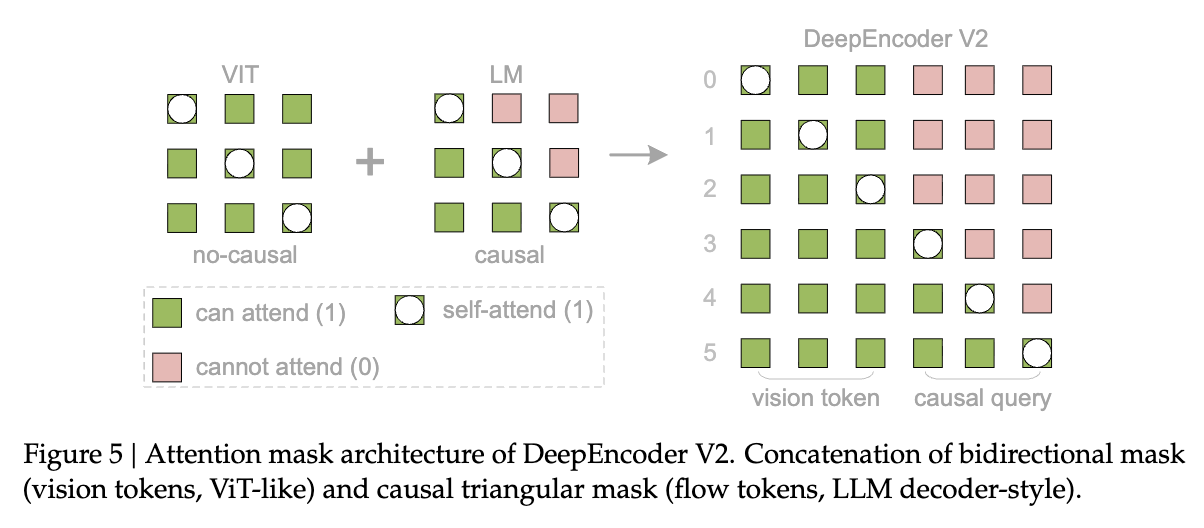
2.3.2 掩码的物理含义
-
左上区域 () - 视觉内部的双向交互:
原始视觉 Token 之间保持全连接的双向注意力(Bidirectional Attention)。这保留了类似 ViT 的全局感受野,使得每个视觉 Patch 都能感知到整图的上下文信息。 -
右上区域 () - 视觉对查询的不可见性:
视觉 Token 无法看到后序的 Query Token。这保证了视觉特征提取的纯粹性,不被特定的查询任务干扰。 -
左下区域 () - 查询对视觉的全局感知:
所有的 Query Token 都可以看到所有的视觉 Token。这是信息提取的关键步骤,类似于 Cross-Attention,但在同一个 Transformer Block 中通过 Mask 实现。 -
右下区域 () - 查询内部的因果交互:
这是核心创新点。 Query Token 之间采用因果注意力(Causal Attention)。即第 个 Query 只能看到第 个及之前的 Query,而不能看到第 个。
2.3.3 机制解读:级联因果推理
这种设计构建了一个两阶段的级联因果推理系统:
-
第一阶段(Encoder 内部):Causal Flow Queries 通过因果注意力机制,逐步从双向的视觉特征中提取信息。由于 Query 是可学习且有序的(Causal),它们可以学习按照语义逻辑(而非空间坐标)来“读取”图像。例如,第一个 Query 可能关注文档标题,第二个关注第一段,第三个关注右侧插图的说明文字。 -
第二阶段(LLM Decoder):经过重排序的 Query 输出(即编码后的视觉表征)被送入 LLM Decoder。由于这些表征已经具备了因果逻辑,LLM 可以更自然地进行自回归生成。
作者在论文中提到,曾尝试使用 mBART 风格的 Encoder-Decoder 交叉注意力架构(即 Query 在 Decoder 中通过 Cross-Attention 访问 Encoder 输出),但导致模型不收敛。作者假设这是因为将视觉 Token 隔离在单独的 Encoder 中导致交互不足。相比之下,DeepEncoder V2 的 Prefix-Concatenation(前缀拼接)模式使得视觉 Token 在所有层中都保持活跃,促进了更深层的信息交换。
2.4 Token 预算与多裁剪策略 (Multi-crop Strategy)
为了处理高分辨率文档,模型采用了多裁剪策略。Token 数量的计算公式如下:
其中:
-
Global View:固定分辨率 ,产生 个 Query Token。 -
Local View:裁剪分辨率 ,每个裁剪产生 个 Query Token。 -
是裁剪数量,范围从 0 到 6。
因此,输入 LLM 的视觉 Token 总数在 256 到 1120 之间。

对比分析:
-
DeepSeek-OCR 2:最大 1120 Token。 -
OmniDocBench 中的其他 SOTA(如 Qwen2.5-VL-72B, InternVL3):通常使用 > 6000 个视觉 Token。
DeepSeek-OCR 2 以极低的 Token 预算实现了 SOTA 性能,这得益于 DeepEncoder V2 高效的信息压缩与重排序能力。它证明了“语义有序的少量 Token”可能比“空间有序的大量 Token”包含更高的有效信息熵。
3. 解码器:DeepSeek-MoE
解码器部分未做重大改动,沿用了 DeepSeek-OCR 的配置。它是一个 3B 参数的 Mixture-of-Experts (MoE) 模型,激活参数量约为 500M。
数学表达为:
其中:
-
是 Vision Tokenizer 输出。 -
是可学习的初始 Query Embedding。 -
是带有掩码 的 Transformer 层(DeepEncoder V2)。 -
是投影操作,只提取后 个 Query Token 的输出(视觉 Token 被丢弃,仅作为上下文)。 -
是 DeepSeek-MoE Decoder。
值得注意的是,只有 Causal Flow Queries 的输出被送入 LLM Decoder。原始的视觉 Token 在 Encoder 结束后即完成了使命。这强制 Encoder 必须将所有关键视觉信息“蒸馏”到 Query 序列中。
4. 训练策略与流程
为了让这个新颖的架构有效收敛,作者采用了三阶段训练管线。
4.1 训练数据
数据主要由 OCR 1.0/2.0 数据和通用视觉数据组成。针对文档布局的多样性,作者优化了采样策略,按 3:1:1 的比例平衡了纯文本、公式和表格页面。
4.2 训练阶段
阶段一:Encoder 预训练 (Encoder Pretraining)
-
目标:让 Vision Tokenizer 和 LLM-style Encoder 获得基础的特征提取和压缩能力。 -
配置:连接一个轻量级 Decoder(202M)。初始化自 SAM-base 和 Qwen2-0.5B。 -
数据:100M 图文对。 -
细节:仅保留 Encoder 参数进入下一阶段。
阶段二:查询增强 (Query Enhancement)
-
目标:强化 Encoder 的 Token 重排序能力,并提升视觉知识的压缩质量。 -
配置:连接 DeepSeek-3B-MoE Decoder。冻结 Vision Tokenizer(SAM 部分),联合优化 LLM-style Encoder 和 Decoder。 -
策略:引入多裁剪策略(Multi-crop),统一分辨率输入。
阶段三:LLM 继续训练 (Continue-training LLM)
-
目标:让 LLM Decoder 更好地适应 Encoder 输出的“重排序”特征,并专门化处理 OCR 任务。 -
配置:冻结 DeepEncoder V2 的所有参数,仅更新 DeepSeek-LLM 参数。 -
效果:此阶段大幅提升了训练吞吐量(因为 Encoder 被冻结,不需要反向传播),同时进一步降低了 Edit Distance。
5. 实验评估
实验主要在 OmniDocBench v1.5 上进行,这是一个包含 1355 张文档图像的综合基准,涵盖杂志、论文、报告等多种布局。
5.1 主要结果
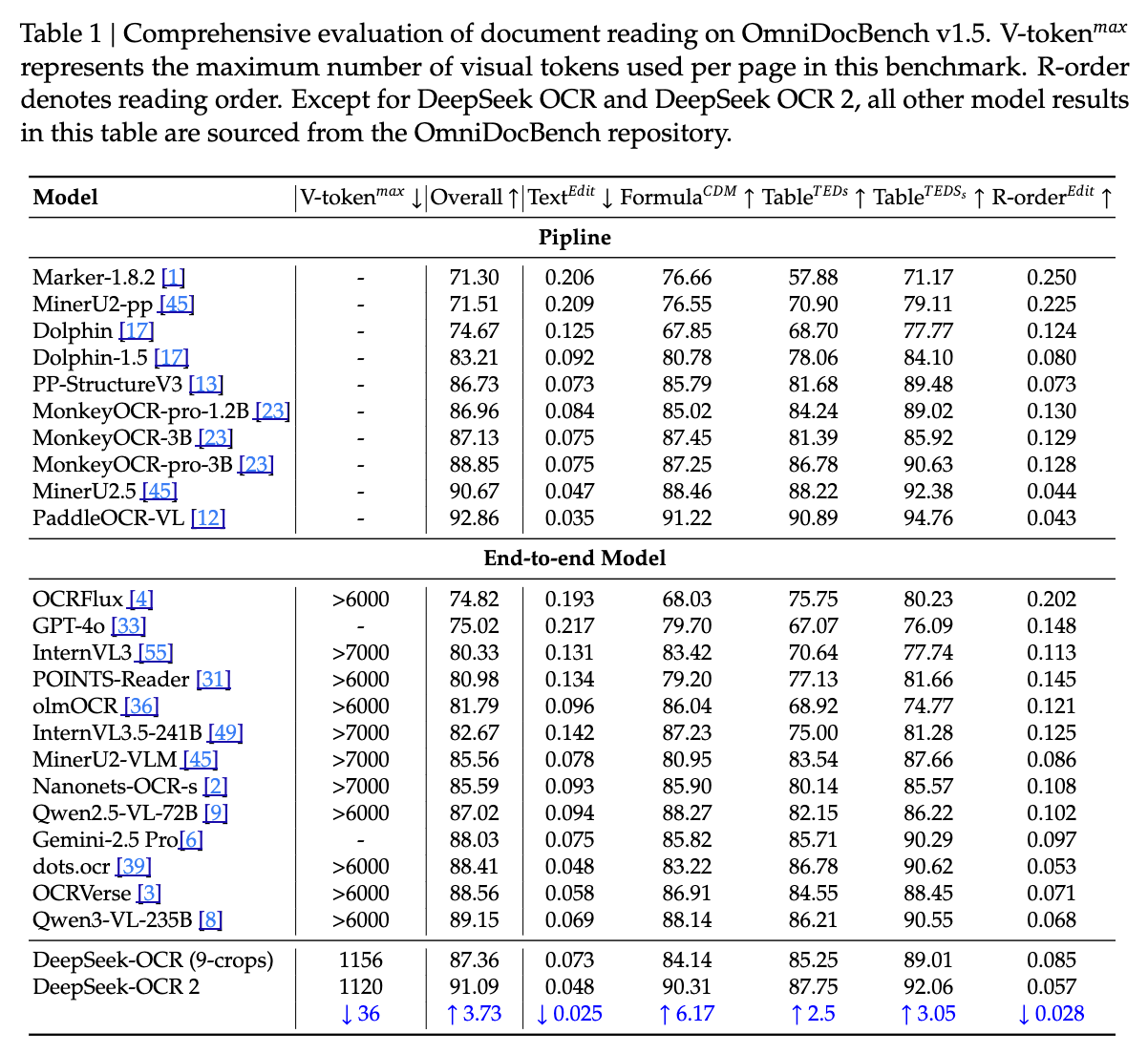
-
总体性能:DeepSeek-OCR 2 达到了 91.09% 的整体得分,相较于 Baseline(DeepSeek-OCR 1)提升了 3.73%。 -
阅读顺序(R-order):这是衡量模型是否理解文档逻辑结构的关键指标。DeepSeek-OCR 2 的编辑距离(Edit Distance)从 0.085 降至 0.057。这直接验证了 Causal Flow Query 在处理语义顺序上的有效性。 -
效率对比: -
DeepSeek-OCR 2 (1120 tokens): 91.09% -
Qwen2.5-VL-72B (>6000 tokens): 87.02% -
InternVL3.5-241B (>7000 tokens): 82.67%
此对比极其强烈地展示了架构优化的力量。在视觉 Token 数量减少 5-6 倍的情况下,性能依然领先。
-
5.2 细分领域分析
在公式(Formula)和表格(Table)识别上,模型均取得了显著提升。这说明因果重排序不仅对文本流有效,对结构化数据的解析同样具有优势。
不足之处:
在“报纸(Newspaper)”类别上,模型的提升有限(ED > 0.13)。作者分析原因为:
-
报纸文本极度密集,1120 个 Token 的上限可能触及了信息瓶颈。 -
训练数据中报纸样本较少(仅 250k)。
这也指出了未来的改进方向:增加 Local Crop 数量或针对性扩充数据。
5.3 实际生产就绪度
对于工业界应用,重复率(Repetition Rate)是一个关键指标(大模型在生成长文本时容易陷入重复循环)。
实验显示,DeepSeek-OCR 2 在 PDF 数据上的重复率从 3.69% 降低到了 2.88% 。这表明经过因果重排序的视觉特征,能让 LLM 生成更加流畅和稳定的文本,减少了由于视觉特征困惑导致的解码循环。
6. 讨论与分析
6.1 2D 理解的本质
传统的 VLM 实际上是将 2D 图像强行降维为 1D 序列,然后交给 1D 的 LLM 处理。这中间丢失了大量的拓扑信息。
DeepSeek-OCR 2 的尝试可以被视为一种 "Soft 2D-to-1D Alignment"(软性 2D 到 1D 对齐)。它没有试图去修改 LLM 的注意力机制来适应 2D(例如 2D-RoPE),而是通过一个可学习的 Encoder 将 2D 信息“翻译”成符合 LLM 偏好的 1D 因果流。
6.2 相关工作的联系
-
DETR:DETR 引入了并行的 Object Queries 用于检测。DeepSeek-OCR 2 的 Causal Queries 可以看作是 DETR Queries 的自回归变体,不仅关注图像,还关注“阅读顺序”。 -
BLIP-2 (Q-Former) :Q-Former 使用 Cross-Attention 压缩视觉特征。DeepSeek-OCR 2 采用了类似的压缩思想,但将其嵌入在一个 Decoder-only 的架构中,并通过 Causal Mask 赋予了时序逻辑。
6.3 局限性
尽管效果显著,但这种“双重因果”架构(Encoder Causal + Decoder Causal)在处理需要多次回看(Re-examination)或多跳推理的任务时可能面临挑战。因为一旦 Encoder 完成了重排序,输出的序列就是固定的。如果 Encoder 使得某些信息在序列中“过早”或“过晚”出现,Decoder 可能无法有效利用。这就对 Encoder 的 Query 学习能力提出了极高的要求。
7. 结论与展望
技术亮点总结:
-
架构创新:成功验证了使用带有定制 Mask 的 LLM 架构作为 Vision Encoder 的可行性。 -
高效推理:通过 Causal Flow Query 实现了极高的视觉 Token 压缩率(Max 1120),大幅降低了长文档处理的成本。 -
认知对齐:通过模拟人类视觉的因果流,解决了文档 OCR 中复杂的布局依赖问题。
未来展望:
Native Multimodality(原生多模态)。这种 Shared Encoder 架构(共享权重、不同模态使用不同 Query)为构建统一的 Omni-modal 模型提供了一条清晰的路径。如果一个 Encoder 可以通过切换 Query 来分别处理图像、音频和文本,那么我们将离真正的通用多模态智能更进一步。
这篇论文最重要的启示在于:不要盲目增加视觉 Token 的数量,而应关注 Token 的语义密度和组织顺序。 在 Transformer 的世界里,顺序即逻辑。
更多细节请阅读原文。
往期文章:


