最近的大语言模型(LLM)发展得很快,但是,这些个模型有个问题:就是它们太依赖大量人工标注的高质量数据了。
要训练一个顶尖的LLM,需要投入很多人力、财力和时间去标注海量数据,这不仅成本高,而且模型的能力似乎也永远超不过人类给它的数据范围。我们怎么才能让AI自己学习、自己进化,去探索人类还不知道的领域呢?
2025年8月7日,腾讯AI西雅图实验室在arXiv上发表了一篇论文,叫 《R-Zero: Self-Evolving Reasoning LLM from Zero Data》。这篇论文提出了一个叫 R-Zero 的全自动框架,这个框架不依赖任何现有的任务和人类标注,能自己生成训练数据,让模型不断进化。

-
论文标题:R-Zero: Self-Evolving Reasoning LLM from Zero Data -
论文链接:https://www.arxiv.org/pdf/2508.05004
第一章:当前大语言模型的“阿喀琉斯之踵”——数据依赖
在深入R-Zero的世界之前,我们必须首先理解它试图解决的问题是多么的艰巨和重要。当前主流的LLM训练范式,无论是预训练、监督微调(SFT)还是基于人类反馈的强化学习(RLHF),其核心都离不开“数据”二字。
1.1 人类标注数据的“三重困境”
-
成本高昂与规模化难题:高质量的标注数据是“奢侈品”。例如,在数学推理、代码生成或专业问答等领域,寻找能够提供准确标注的专家本身就极其困难,其成本更是天文数字。这导致我们很难构建一个足够庞大且多样化的数据集来覆盖所有需要的知识和技能。
-
质量与一致性瓶颈:人非圣贤,孰能无过。即便是专家,在进行标注时也可能出现错误、偏见或不一致。这些“噪声”会直接影响模型的学习效果,甚至误导模型的价值对齐。
-
超越人类的“天花板效应”:这是最根本的限制。如果我们希望AI解决那些连人类专家都束手无策的问题(如攻克癌症、设计新材料),那么我们从何获取“正确答案”来指导模型呢?依赖人类监督的模式,本质上是将模型的认知上限锁定在了人类的现有水平。
1.2 摆脱依赖的早期探索与局限
为了打破数据依赖的枷锁,研究者们进行了一系列有益的尝试。
-
无标签强化学习(Label-Free RL):这类方法尝试直接从模型自身的输出中提取奖励信号,例如利用模型输出的置信度、序列的熵或不同推理路径间的一致性。这在一定程度上减少了对显式标签的需求。然而,它们仍然需要一个预先存在的、固定的“问题集”或任务语料库。它们解决了“如何评价答案”的问题,却没有解决“问题从哪里来”的根源性问题。
-
自我挑战(Self-Challenging):这类方法让模型自己生成任务来训练自己,这与R-Zero的思想更为接近。然而,现有的大多数自我挑战方法严重依赖于“外部验证器”。例如,在代码生成领域,模型可以生成代码问题,然后通过一个真实的编译器或单元测试来验证答案的正确性。但在更广泛的、缺乏这种“上帝视角”验证工具的开放域推理(如复杂的数学证明、哲学思辨)中,如何保证自生成问题的质量和答案的正确性,就成了一个巨大的挑战。
正是在这样的背景下,R-Zero横空出世,它旨在同时解决“问题生成”和“答案验证”两大难题,构建一个完全封闭、自给自足的进化循环,而无需任何外部任务语料或验证 oracle。
第二章:R-Zero横空出世——全新的自进化框架
R-Zero的核心思想,可以用一句话来概括:通过两个扮演不同角色的模型进行“对抗性”的协同进化,实现从零开始的自我完善。
这个框架的设计精妙之处在于,它模拟了人类社会中“教”与“学”的动态过程。想象一个顶尖的教师和一个聪明的学生:
-
教师(挑战者,Challenger)的目标是出一些稍稍超出学生当前能力边界的题目。太简单,学生学不到新东西;太难,学生会完全无法下手,同样没有学习效果。 -
学生(解题者,Solver)的目标是尽力去解决老师提出的这些有挑战性的问题,从而提升自己的能力。 -
随着学生能力的提升,老师也必须出更难的题目来继续挑战他。
这个“教学相长”的过程,使得师生二人的能力螺旋式上升。R-Zero正是将这一动态过程编码成了一套算法框架。
2.1 挑战者与解题者的协同进化(Co-evolution)
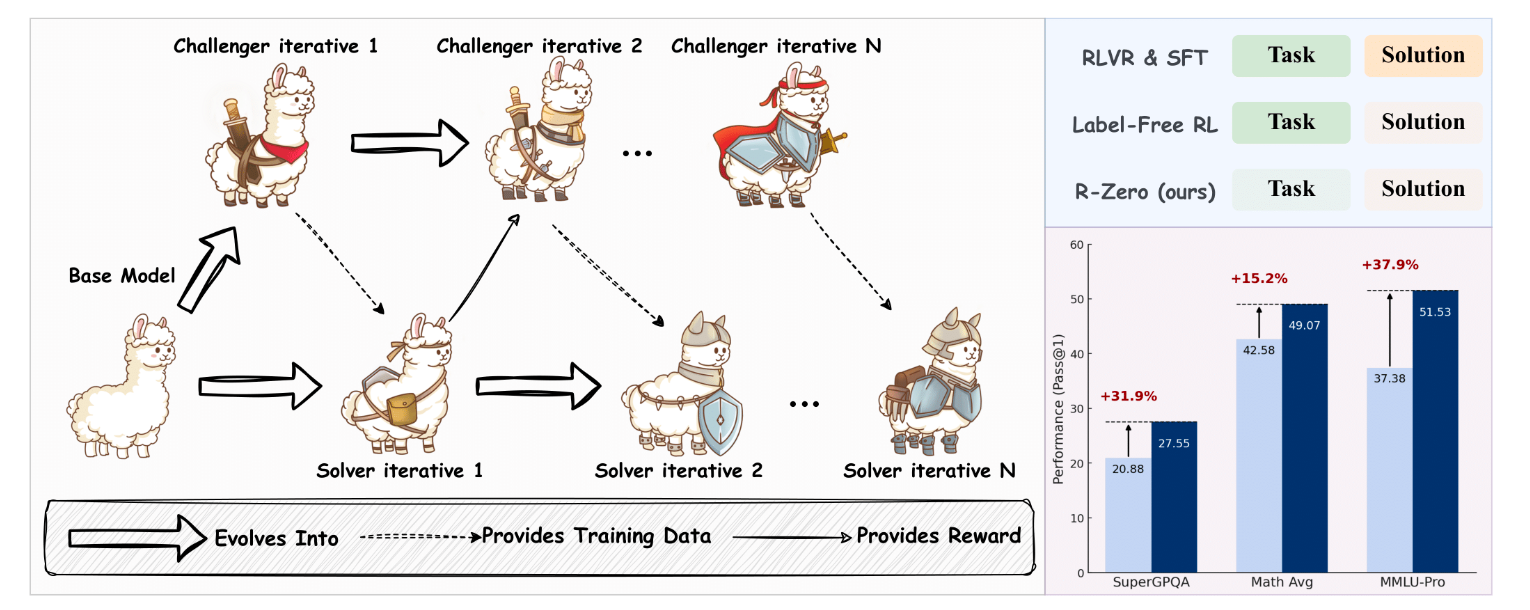
如图1左图所示,R-Zero的流程如下:
-
初始化:从一个基础的LLM(Base Model)开始,克隆出两个功能上独立的模型:挑战者 () 和 解题者 ()。在初始状态,它们的水平是完全一样的。
-
迭代循环(Iterative Loop):整个框架以迭代的方式进行。在第N次迭代中:
-
挑战者出题:挑战者 的任务是生成一批新的、对当前解题者 来说具有挑战性的问题。 -
解题者解题:当前的解题者 会尝试回答这些新问题,并给出自己的答案。 -
奖励与进化: -
挑战者进化:系统会根据解题者 在这批问题上的表现(比如回答的正确率)来给挑战者 一个“奖励”。如果出的题“恰到好处”(即解题者表现出最大的不确定性),挑战者就会获得高奖励,并据此更新自己,以便在下一轮出更高质量的题。 -
解题者进化:系统会从挑战者出的题中,筛选出一批质量最高的“好题”,并利用解题者自己生成的“伪标签”(pseudo-label,通常通过多次采样后多数投票产生)作为答案,构成新的训练数据。然后,解题者 会在这个新的、更有挑战性的数据集上进行训练和微调,从而进化成一个更强大的解题者 。
-
-
-
持续迭代:进入第N+1次迭代,更强大的解题者 将面对来自更强大挑战者 的、更困难的问题。如此循环往复,两个模型的能力共同提升。
这个过程是完全自动化和自包含的。它不需要外部提供任何问题或答案,仅仅从一个基础模型出发,就能源源不断地创造出越来越难的“课程”和越来越强的“学生”。
图1右图直观地展示了这一框架带来的巨大性能提升,我们将在第五章详细分析这些结果。
第三章:核心机制探秘(一):“挑战者”的炼成——如何生成“好”问题?
挑战者的成功与否,是整个R-Zero框架的关键。它必须能够精准地定位到解题者当前能力的“前沿阵地”(frontier of capabilities),并在此处生成问题。为了实现这一目标,R-Zero为挑战者设计了一套精密的奖励机制,并使用一种名为群体相对策略优化(Group Relative Policy Optimization, GRPO)的强化学习算法进行训练。
3.1 强化学习算法:GRPO
在介绍奖励函数之前,我们先简单了解一下GRPO。它是一种无需学习独立价值函数的强化学习微调算法,其核心思想是:一个响应的好坏是相对的。
对于同一个问题(prompt),我们让模型生成G个不同的回答(responses)。GRPO不去评估每个回答的绝对分数,而是计算它在“同伴”中的相对优势。具体来说,它会计算每个回答的奖励,然后对这G个奖励进行z-score归一化,得到一个优势值(Advantage) :
这个优势值表示回答相对于这批回答的平均水平有多好。然后,GRPO使用一个类似PPO的裁剪代理目标(clipped surrogate objective)来更新策略,鼓励模型生成具有正优势值的回答,同时通过KL散度惩罚来防止模型偏离原始策略太远,保证了训练的稳定性。
3.2 挑战者的“灵魂”:复合奖励函数
挑战者的目标是生成“好”问题。那么,什么样的问题才是“好”问题?R-Zero认为,一个好问题应该具备两个特质:1. 有挑战性;2. 有新颖性。为此,它设计了一个复合奖励函数,由三部分构成:不确定性奖励、重复度惩罚和格式检查惩罚。
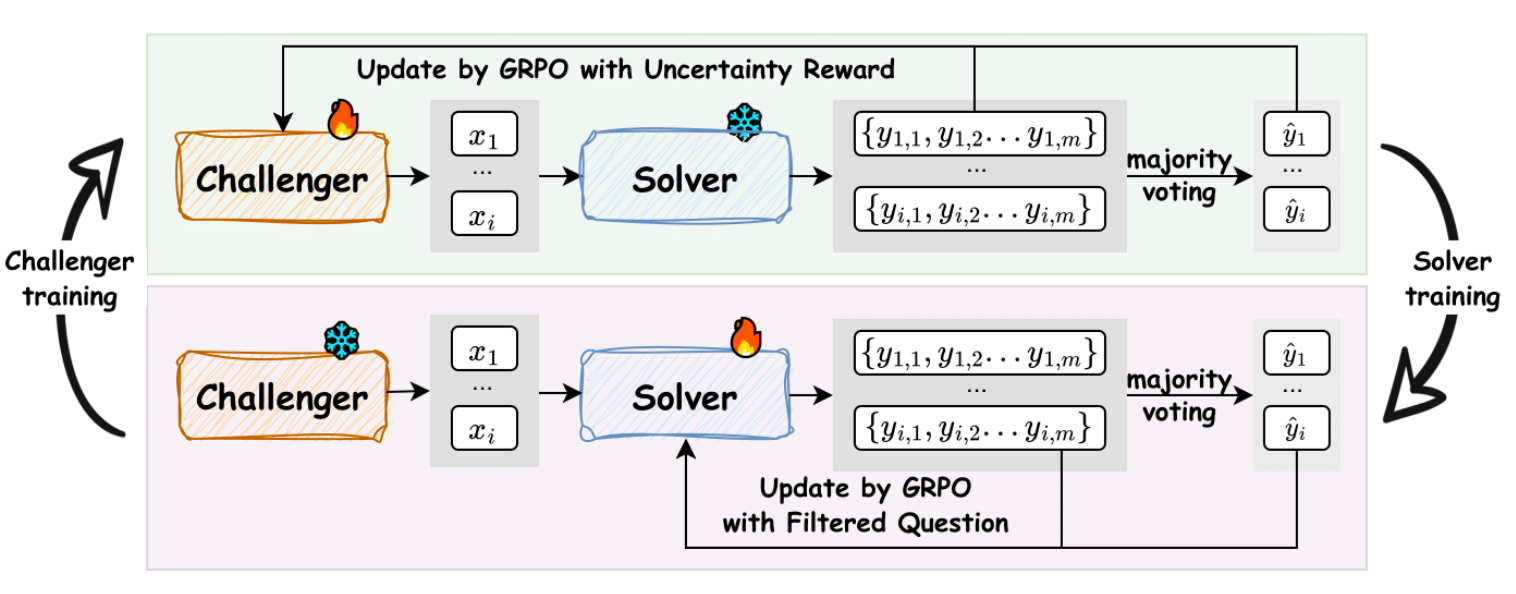
3.2.1 不确定性奖励 (Uncertainty Reward)
这是奖励函数中最核心、也最巧妙的部分。如何量化一个问题对解题者的“挑战性”?R-Zero认为,当解题者对一个问题的回答最不确定时,这个问题就最具挑战性,也最具学习价值。
具体操作如下:
-
对于挑战者生成的一个问题 ,我们用当前(冻结的)解题者 对其进行 次独立采样,得到 个不同的答案 。
-
通过多数投票(majority vote),我们找到最频繁出现的答案,并将其作为这个问题的“伪标签” 。
-
计算解题者 在这个问题上的经验准确率 ,即 个答案中有多少比例与伪标签 相同。
-
最终,不确定性奖励被定义为:
让我们来仔细分析这个公式。它是一个以 为中心、开口向下的V形函数。
-
当解题者的经验准确率 恰好等于 50% 时,,奖励达到最大值 1。这意味着解题者完全“懵了”,它生成的答案中一半是A,一半是B,表现出最大的不确定性。这正是学习效率最高的“甜点区”。 -
当解题者的准确率接近 100%(问题太简单)或 0%(问题太难或存在歧义导致无法形成一致的答案)时, 接近0.5,奖励接近最小值 0。
这一定义有着深刻的理论支撑。论文在3.5节中提到,学习者的学习潜力可以通过其当前策略 与最优策略 之间的KL散度 来量化。而这个KL散度存在一个下界,该下界与奖励的方差成正比。对于我们这里的二元奖励(答对/答错),奖励的方差为 ,其中 是成功率。这个函数在 时取得最大值。因此,通过激励挑战者生成让解题者成功率为50%的问题,R-Zero在理论上保证了每一轮迭代都为解题者提供了最高效的学习课程。
3.2.2 重复度惩罚 (Repetition Penalty)
如果挑战者只盯着一个知识点出题,哪怕难度再合适,解题者也容易“过拟合”。为了鼓励挑战者生成多样化、新颖的问题,R-Zero引入了重复度惩罚。
其实现方式是:
-
在一个训练批次(batch)内,计算所有生成问题两两之间的语义相似度。这里,R-Zero选择使用计算速度更快的 BLEU 分数来近似语义相似度,定义距离 。
-
使用这个距离矩阵,通过层次聚类(agglomerative clustering)将相似的问题分组到不同的簇(cluster) 中。
-
对于一个问题 ,其重复度惩罚与其所在簇的大小成正比:
其中 是问题 所在簇的大小,B是批次大小, 是一个缩放因子(实验中设为1)。一个簇里的问题越多,说明这类问题重复度越高,惩罚就越大。
3.2.3 复合奖励与策略更新
最后,对于一个通过了基本格式检查(例如,问题被正确地包含在<question>标签内)的问题,其最终的复合奖励为:
这意味着,只有当一个问题的不确定性奖励足够高,能够抵消其重复度惩罚时,它才能获得正奖励。
有了这个精密的复合奖励信号 ,R-Zero就可以利用前述的GRPO算法,计算出每个问题的相对优势值 ,并更新挑战者 的策略,使其在下一轮能够生成更具挑战性和多样性的问题。
第四章:核心机制探秘(二):“解题者”的进化——在挑战中成长
当挑战者成功地提供了高质量的“原材料”后,接下来的任务就是如何利用这些原材料来“锤炼”解题者。这个过程包括两个步骤:构建数据集和进行训练。
图2清晰地展示了这个过程。
4.1 解题者数据集构建 (Solver Dataset Construction)
挑战者一次性可能会生成成千上万个候选问题,但并非所有问题都适合用来训练解题者。R-Zero在此处设置了一个关键的过滤步骤,其目的有两个:1. 实施课程学习;2. 进行质量控制。
过滤规则如下:
对于每个由挑战者生成的问题 ,我们已经通过多数投票得到了伪标签 和经验准确率 。只有当这个经验准确率 落在一个特定的“信息带”(informative band)内时,这个问题-答案对 才会被加入到最终的训练集 中。
这个“信息带”被定义为:。
在论文的实验中,作者设定 (即为每个问题生成10个答案),。这意味着,只有当10个答案中,与多数票伪标签相同的答案数量在 3到7个之间(即 )时,这个问题才会被保留。
这个过滤步骤的巧妙之处在于:
-
课程学习:它直接剔除了那些对当前解题者来说“太简单”()或“太难”()的问题,确保了解题者永远在自己的“最近发展区”内学习。 -
质量控制:经验准确率 极低(例如低于0.3)往往意味着一个深层次的问题:这个问题本身可能定义不清、有歧义,或者解题者的多次输出之间毫无共识,导致选出的伪标签非常不可靠。过滤掉这些低一致性的问题,实际上也过滤掉了大量低质量、有噪声的数据,从而提高了训练数据的纯净度。
4.2 解题者训练 (Solver Training)
经过筛选,我们得到了一个高质量的、充满挑战的训练集 。接下来,解题者 将在这个数据集上进行微调。
训练过程同样采用了GRPO算法,但奖励信号的设计比挑战者要简单直接得多。对于训练集 中的一个问题 (其伪标签为 ),我们让解题者 生成一批答案。对于其中任意一个答案 ,其奖励 是一个二元的可验证奖励(verifiable reward):
这个奖励信号非常清晰:只要生成的答案和我们之前通过多数票选出的“标准答案”完全一致,就给予最高奖励。
有了这个奖励,后续流程就和挑战者训练一样了:使用GRPO计算相对优势值,并更新解题者 的策略。这个过程增强了解题者在它之前感到困惑的难题上给出正确(即,与多数票一致)答案的能力。
通过“挑战者生成 -> 解题者过滤 -> 解题者训练”这一系列的迭代,R-Zero构建了一个闭环的、自我驱动的进化系统,两个模型的性能在没有外部干预的情况下稳步提升。
第五章:惊人的实证效果——R-Zero的能力边界探索
理论的优雅最终需要实验来验证。R-Zero的作者们在一系列模型和基准测试上进行了详尽的实验,结果令人印象深刻。
5.1 实验设置
-
基础模型:实验涵盖了两种不同的模型架构和多种尺寸,以验证框架的通用性。 -
Qwen3系列:Qwen3-4B-Base 和 Qwen3-8B-Base。 -
OctoThinker系列:OctoThinker-3B 和 OctoThinker-8B(基于Llama-3.1)。选择这个系列是因为其原始论文报告称直接对其进行RL训练效果不佳,更能凸显R-Zero的有效性。
-
-
评估基准:评估分为两大类。 -
数学推理:这是R-Zero主要训练的领域,因为它答案的对错客观、易于验证。涵盖了AMC, Minerva, MATH-500, GSM8K, Olympiad-Bench等7个极具挑战性的数学基准。 -
通用领域推理:为了测试模型通过数学训练获得的能力是否可以泛化到其他领域,作者们在MMLU-Pro, SuperGPQA, BBEH等顶级通用推理基准上进行了评估。
-
5.2 数学推理能力:显著且持续的提升
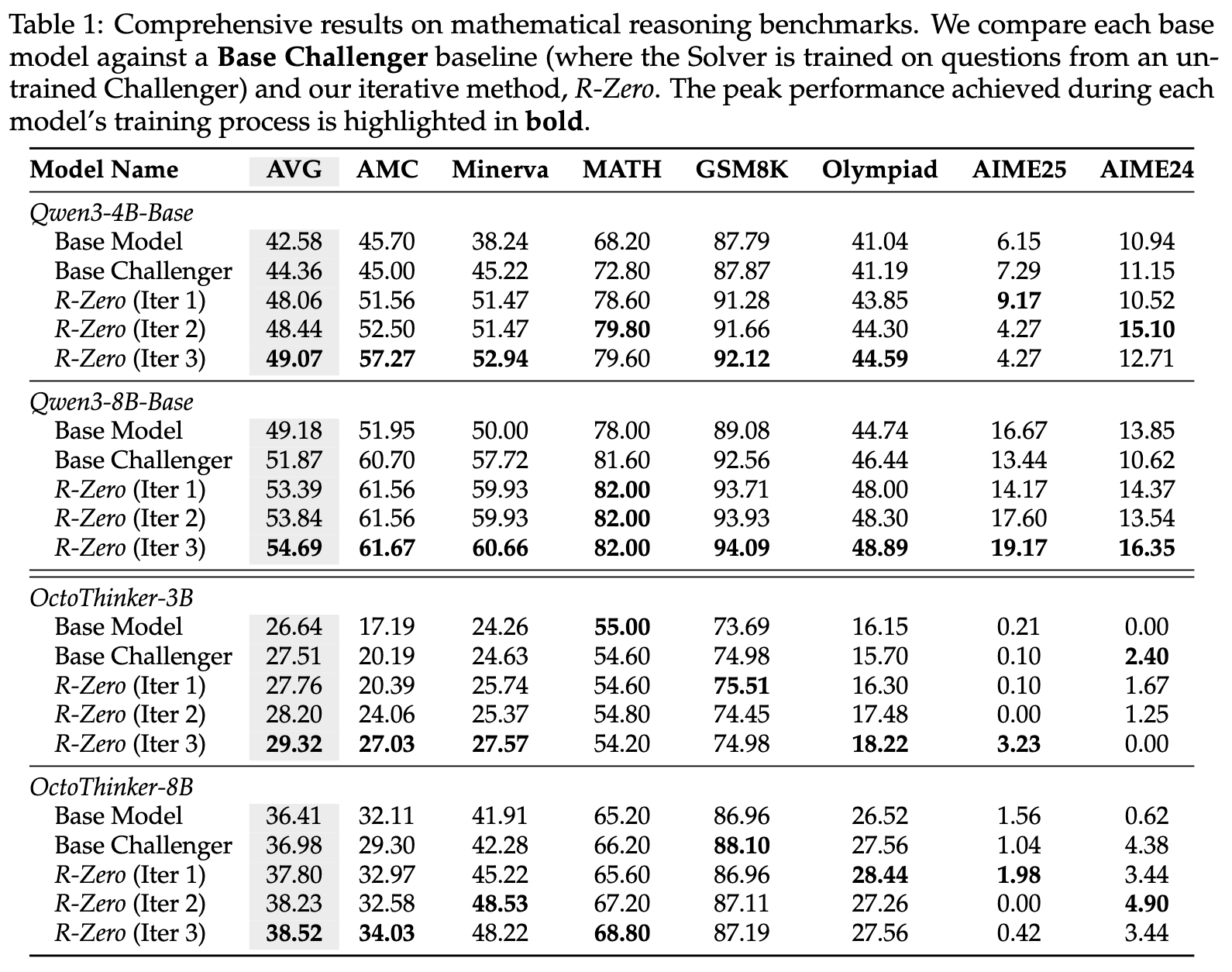
表1详细展示了各个模型在经过R-Zero训练前后的性能变化。我们可以从中观察到几个关键点:
-
效果显著:R-Zero带来了巨大的性能提升。以Qwen3-4B-Base为例,其在7个数学基准上的平均分(AVG)从42.58分(基础模型)提升到了49.07分(经过3轮R-Zero迭代),净增+6.49分。对于更大的Qwen3-8B-Base模型,平均分也从49.18提升到54.69,净增+5.51分。这在竞争激烈的LLM性能榜单上是极为可观的进步。
-
持续迭代,持续进步:性能的提升是渐进的。从
Iter 1到Iter 2再到Iter 3,大部分模型的性能都在稳步攀升。例如,OctoThinker-3B的平均分从26.64(Base)-> 27.76(Iter 1)-> 28.20(Iter 2)-> 29.32(Iter 3),展示了一个清晰的、单调递增的成长轨迹。这有力地证明了R-Zero的协同进化机制是有效的,解题者确实在难度不断增加的课程中持续学习和进步。 -
RL训练的挑战者至关重要:表格中有一个名为“Base Challenger”的基准,它代表只使用一个未经训练的、固定的挑战者来出题进行训练。可以看到,R-Zero的第一轮迭代(R-Zero (Iter 1))就显著优于这个“Base Challenger”。例如,在Qwen3-4B-Base上,“Base Challenger”只将分数提升到44.36,而“R-Zero (Iter 1)”则达到了48.06。这之间的差距(+3.7分)充分说明了通过强化学习动态地、有目的地生成课程是多么重要。一个聪明的、会动态调整难度的老师,远胜于一个只会随机出题的老师。
5.3 通用推理能力的泛化:意外的惊喜
最令人振奋的发现之一是,在数学领域进行专注训练所获得的能力,可以有效地迁移到通用的推理任务中。
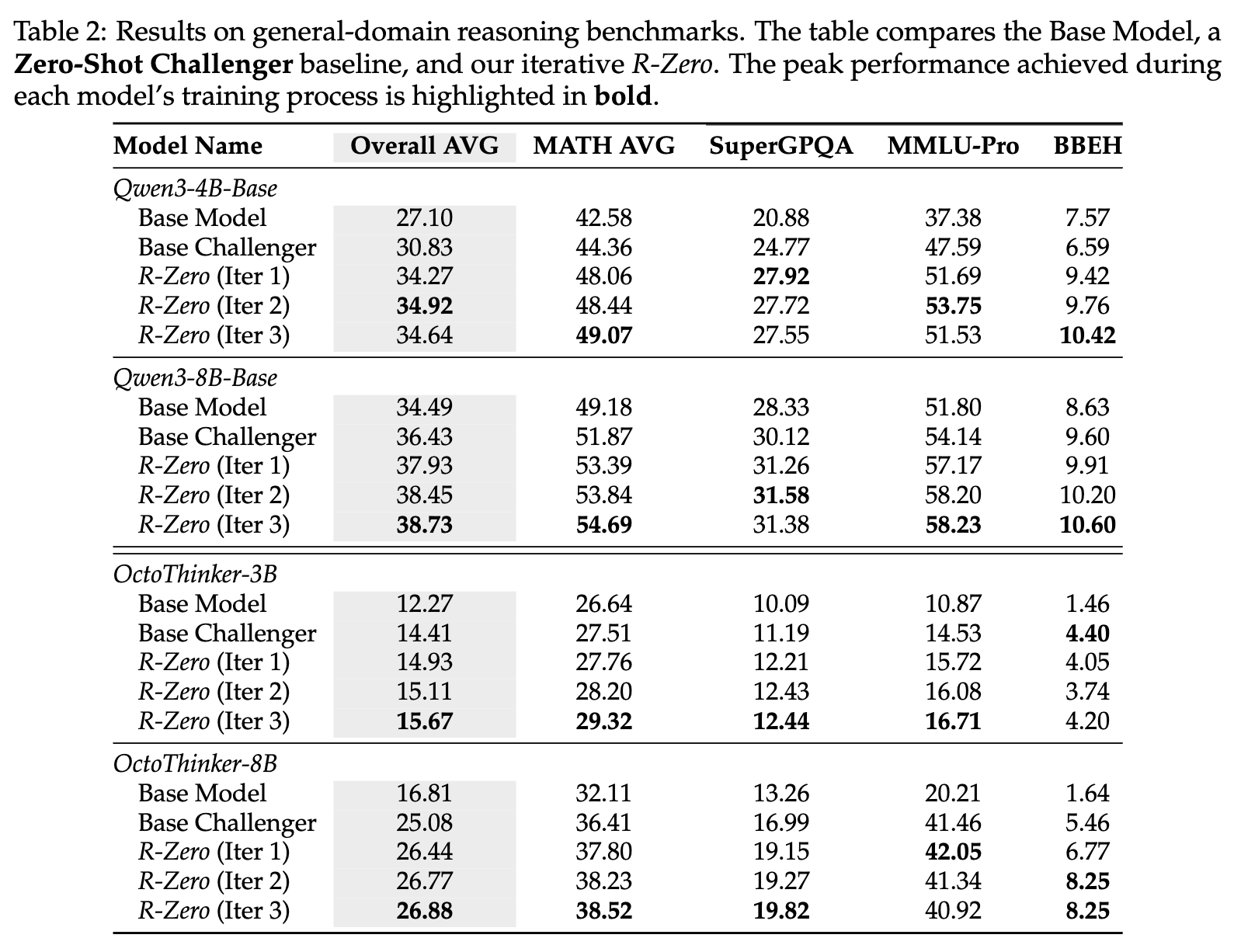
表2展示了这一惊人的泛化效果。
-
以Qwen3-8B-Base为例,经过三轮数学领域的R-Zero训练后,它在通用推理基准上的平均分(Overall AVG)从34.49分提升到了38.73分,净增+4.24分。 -
OctoThinker-3B的提升甚至更明显,从12.27分提升到15.67分,净增+3.4分。
这一发现意义重大。它表明R-Zero并非仅仅是让模型“背会”了更多的数学题,而是实实在在地提升了其底层的、通用的逻辑推理、问题分解和复杂指令遵循能力。数学,作为逻辑和推理的集大成者,成为了一个绝佳的“训练场”,在这里磨练出的“内功”,可以应用于更广阔的世界。这也回答了一个长期存在的问题:针对特定能力的训练(如数学)是否能带来通用能力的提高?R-Zero给出了一个响亮的肯定回答。
第六章:深度剖析——R-Zero为何如此有效?
为了更深入地理解R-Zero成功的秘诀,并探究其内部工作机制和潜在的局限性,作者进行了一系列精辟的分析。
6.1 消融研究:每个组件都不可或缺
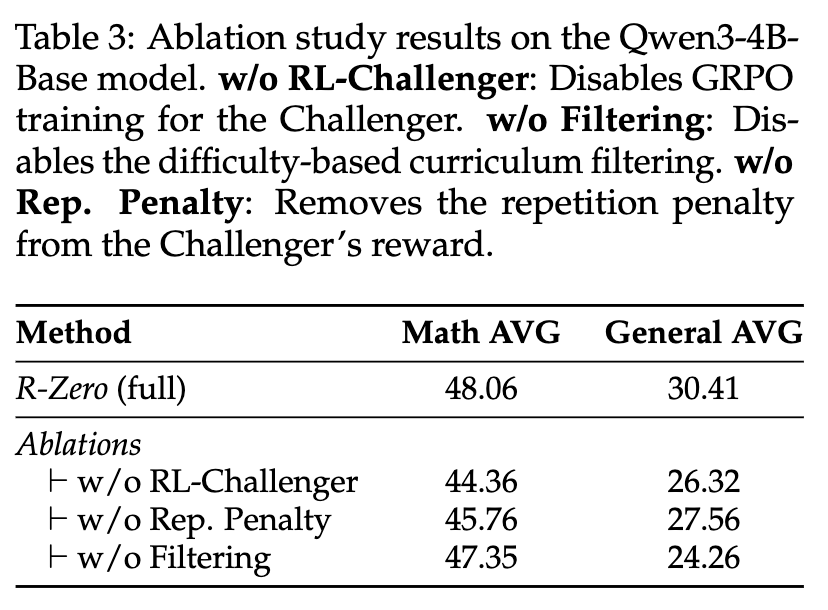
消融研究(Ablation Study)是验证一个复杂系统设计合理性的标准方法,通过逐一“拿掉”某个组件来观察其对整体性能的影响。表3清晰地展示了R-Zero三大核心组件的重要性。
-
移除挑战者的RL训练 (w/o RL-Challenger):这是影响最大的部分。当挑战者不再通过RL进行智能课程生成,而退化为随机出题时,数学平均分下降了3.7分,通用平均分更是暴跌4.1分。这再次印证了“智能教师”的核心价值。 -
移除重复度惩罚 (w/o Rep. Penalty):性能同样出现显著下滑。这说明,如果不对生成问题的多样性加以约束,挑战者很容易陷入“舒适区”,反复生成同质化的问题,从而阻碍解题者的全面发展。 -
移除任务过滤 (w/o Filtering):性能也出现了明显下降,尤其是在通用领域。这说明,我们之前讨论的任务过滤步骤(保留30%-70%正确率的问题)起到了关键的“课程筛选”和“质量控制”作用。如果没有这个过滤器,解题者会被迫学习大量“脏数据”(噪声、歧义问题)和效率低下的数据(太简单或太难),从而损害其学习的鲁棒性。
6.2 问题难度与数据质量的演变:一把双刃剑
R-Zero的协同进化是一个动态过程。那么,在这个过程中,问题的难度和数据的质量是如何变化的呢?作者进行了一项有趣的分析,其结果总结在表4中。
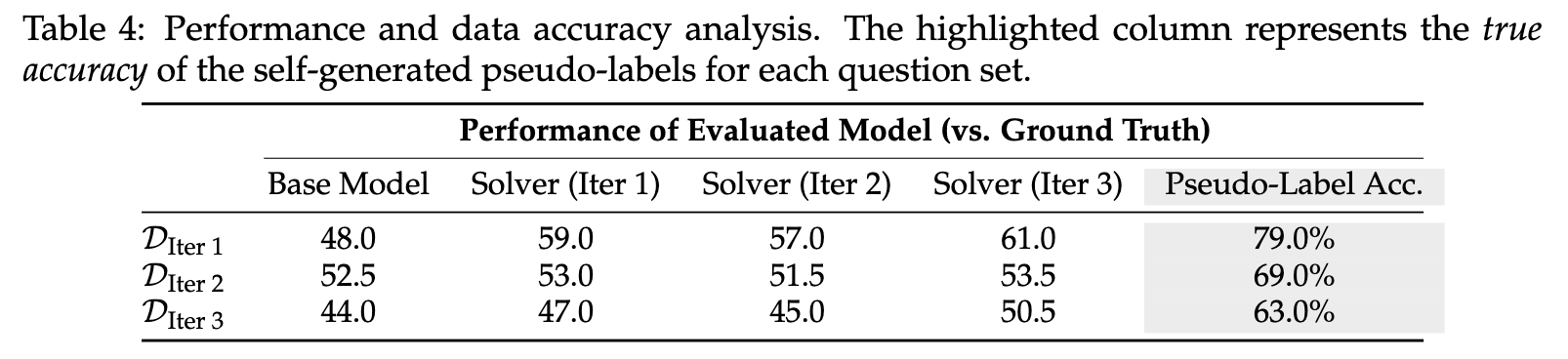
为了进行客观评估,作者引入了一个“上帝视角”的外部裁判——GPT-4o,用它来给出问题的“标准答案”。
分析揭示了一个复杂而深刻的动态:
-
挑战者确实在生成越来越难的问题:这是一个巨大的成功。我们可以通过一个固定的模型在不同迭代轮次的问题集上的表现来看出这一点。例如,第一轮训练出的
Solver (Iter 1)在第一轮的问题集(DIter 1)上能拿到59.0%的正确率,但在第三轮的问题集(DIter 3)上,它的正确率就掉到了47.0%。这表明第三轮的问题确实比第一轮的更难。 -
伪标签的准确率在系统性下降:这是R-Zero面临的核心挑战,也是这把“双刃剑”的另一面。分析显示(表格中
Pseudo-Label Acc.列),第一轮生成的训练数据中,由多数投票产生的伪标签的真实准确率(与GPT-4o答案相比)高达 79.0%。然而,随着问题越来越难,解题者的能力开始跟不上,其多数投票结果的可靠性也随之下降。到了第三轮,伪标签的准确率已经降至 63.0%。
这意味着,随着系统向更高难度的区域探索,它自我生成的数据的“信噪比”也在降低。这种数据质量的衰减,是未来R-Zero框架需要解决的关键瓶颈,它可能会限制模型最终能达到的性能上限。
-
内部奖励机制始终有效:尽管伪标签的绝对准确率在下降,但R-Zero内部的奖励机制依然按照设计在精确工作。观察表格的对角线, Solver (Iter 2)在DIter 2上的表现是51.5%,Solver (Iter 3)在DIter 3上的表现是50.5%。这表明,挑战者始终成功地将问题难度校准在了让同代解题者感到最不确定的50%成功率附近。
6.3 与监督学习的协同作用:1+1 > 2
R-Zero是一个完全无监督的框架,那么当有标注数据可用时,它是否就变得多余了呢?答案是否定的。R-Zero不仅不与监督学习冲突,反而能成为其强大的“性能放大器”。
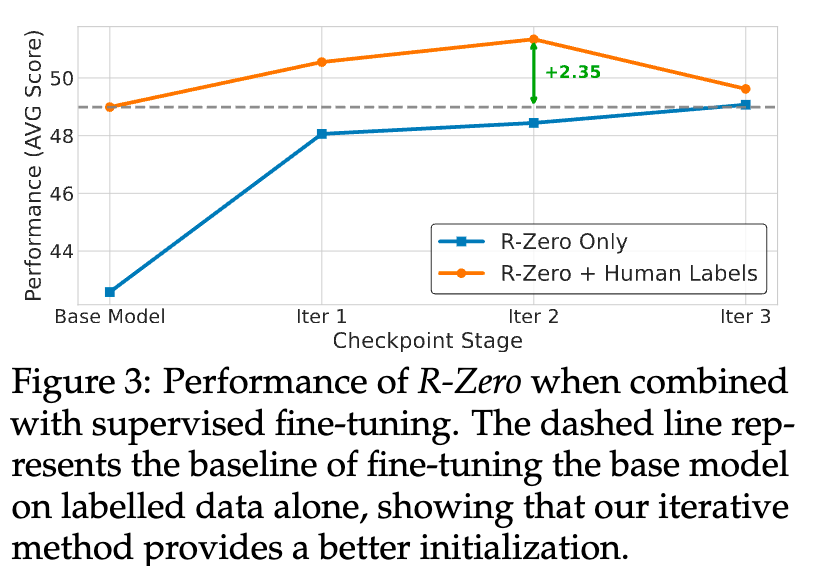
图3展示了这一协同效应。
-
蓝色虚线代表传统的监督微调(SFT)路径:直接在有标签的数据集上微调基础模型。 -
橙色实线代表“R-Zero + SFT”路径:先用R-Zero进行几轮无监督的自我进化,然后在每个迭代节点上,再用相同的有标签数据集进行微调。
结果一目了然。在任何一个迭代节点上,经过R-Zero“预热”的模型,其在SFT后的性能都远高于直接进行SFT的基线。最终,R-Zero + SFT 的组合比单纯的SFT基线高出了整整2.35分。
这说明,R-Zero的自我进化过程,为模型提供了一个远优于原始状态的“初始化”。它帮助模型内化了更深层次的推理结构和解决问题的能力,使得模型在后续接触到有标签数据时,能够更高效地学习和吸收知识,最终达到仅靠SFT无法企及的高度。
点评
这篇论文最大的亮点和贡献,在于提出了一个真正意义上“从零数据”(from Zero Data)的、完全自主的 LLM 自我进化范式。
-
摆脱“双重依赖”:在此之前,所谓的“自学”或“自洽性”方法,虽然摆脱了对“人工标签”(answers)的依赖,但仍然需要一个预先存在的、大规模的“问题集”(tasks)。R-Zero 更进一步,连“问题集”都由模型自己生成。它成功地将学习过程封闭在一个完全内生的循环中,这是对现有范式的一次重大突破。
-
“课程自生成”的理念:R-Zero 的核心思想,即让一个系统自主地创造出适合自己学习的课程(curriculum),是一个非常深刻且强大的概念。它从根本上解决了 AI 发展的“数据瓶颈”问题,为实现超越人类知识边界的智能提供了一条极具想象力的路径。
可以说,R-Zero 在理念上是具有开创性的。它将“自对弈”(self-play)的思想从 AlphaGo 的棋类游戏,成功地、巧妙地迁移到了更开放、更复杂的语言推理领域。
对“客观真理”的强依赖,这是该框架最核心的、也是最大的适用性限制。整个奖励机制(不确定性)和伪标签生成(多数投票)都建立在一个前提上:问题存在一个或少数几个可收敛的、客观正确的答案。
适用领域略窄:这使得 R-Zero 在数学、编程等逻辑性强的领域表现出色,但几乎无法直接应用于绝大多数现实世界任务,例如:
-
主观创造类:写一首感人的诗、写一篇风格独特的短篇小说。 -
开放式总结与分析:总结一份复杂的财报、为一项政策提供利弊分析。 -
策略与规划类:为公司制定下一季度的市场策略。
在这些任务中,“最好的答案”是开放的、主观的、依赖于上下文和价值判断的,无法通过“多数投票”来决定。
往期文章: