大型语言模型 (LLM) 凭借其强大的思维链 (Chain-of-Thought) 推理能力,在解决复杂问题上取得了显著的进展。然而,如何有效控制其在推理过程中产生的计算成本,成为模型在实际部署中面临的一大挑战。近期,一些专有系统(如 OpenAI 的 gpt-oss 系列)通过引入离散的操作模式,为用户提供了直观的推理控制方式,但开源社区在实现类似功能方面进展有限。
为了弥合这一差距,来自字节跳动 Seed 团队与复旦大学、上海交通大学、清华大学智能产业研究院的研究人员共同提出了一种名为 ThinkDial 的端到端开源框架。该框架首次成功地以“开源”的形式,实现了类 gpt-oss 的可控推理机制。ThinkDial 允许模型在三种不同的推理模式间无缝切换,分别是:
-
高模式 (High mode) :提供完整的推理能力,追求最高的准确性。 -
中模式 (Medium mode) :在性能下降小于10%的前提下,将推理过程产生的 token 数量减少50%。 -
低模式 (Low mode) :在性能下降小于15%的前提下,将 token 数量减少75%。

-
论文标题:ThinkDial: An Open Recipe for Controlling Reasoning Effort in Large Language Models -
论文链接:https://arxiv.org/pdf/2508.18773
这一成果使得开发者可以根据不同的应用场景和计算预算,灵活地平衡模型的性能与效率。
1. 背景
LLM 在进行复杂推理时,通常会生成冗长的思维链,其中包含了大量的中间步骤。这种“过度思考” (overthinking) 虽然有助于模型得出正确答案,但也带来了几个问题:
-
高计算成本:更长的推理链意味着需要更多的计算资源和时间,直接增加了部署和使用的成本。 -
潜在的质量下降:冗长的推理步骤可能引入错误传播,影响最终答案的准确性。 -
可解释性降低:过长的推理过程使得用户难以理解模型的决策逻辑。
在实际应用中,用户对性能和成本的需求是动态变化的。例如,在处理关键的科学计算或医疗诊断任务时,用户可能希望模型进行最详尽的思考以确保准确性;而在进行快速问答或内容摘要时,则更看重响应速度和成本效益。
目前,学术界和工业界已经探索了多种控制推理成本的方法:
-
思维链压缩 (CoT Compression) :通过构建更短的推理路径来减少 token 生成。这包括在监督微调 (SFT) 阶段筛选简短而正确的推理样本,或在强化学习 (RL) 阶段奖励更简洁的回答。然而,这些方法通常只关注压缩,而缺乏让用户动态控制压缩程度的能力。 -
显式指定 token 预算:用户可以直接设定模型生成 token 数量的上限。这种方法的挑战在于,为不同难度的任务设定一个合适的预算值是非常困难的。 -
自适应思维链 (Adaptive CoT) :模型可以根据问题的复杂性自主决定是否需要进行深入思考。但这类方法通常只提供“思考”与“不思考”的二元切换,无法实现更细粒度的控制。 -
三模式系统 (Three-Mode Systems) :以 OpenAI 的 gpt-oss 系列为代表,提供“高”、“中”、“低”三种离散的推理模式。这种方式为用户提供了直观且无需关心具体 token 数量的控制选项,但其实现方法一直没有公开。
ThinkDial 的目标正是为开源社区提供一套完整的、可复现的三模式可控推理解决方案,从而推动先进推理能力的普及。
2. ThinkDial 的核心方法:端到端的预算模式控制
ThinkDial 的核心在于一个贯穿模型训练全流程的端到端框架。它将预算控制的理念从训练的初始阶段就融入其中,而非在模型训练完成后再进行“改造”。整个框架包含两个关键阶段:预算模式监督微调 (Budget-Mode Supervised Fine-tuning) 和 两阶段预算感知强化学习 (Two-Phase Budget-Aware Reinforcement Learning) 。
2.1 预算模式监督微调 (Budget-Mode Supervised Fine-tuning, BM-SFT)
传统的可控推理方法通常将重点放在强化学习阶段。但 ThinkDial 认为,监督微调 (SFT) 阶段是构建可控推理能力的基础。其原因有二:
-
模型必须在初始阶段就学会将不同的模式指令(例如,“请使用高模式回答”)与相应的推理行为(例如,生成详细或简略的推理步骤)关联起来。 -
必须为每种模式建立稳定、清晰的输出分布,以防止在后续的强化学习阶段,不同模式的训练目标互相干扰。
为了实现这一目标,研究人员构建了一套专门的 预算模式 SFT 数据集。其构建过程如下:
-
起始数据:从高质量、完整的思维链推理数据作为“高模式”的样本。 -
数据衍生:通过对“高模式”样本的推理部分进行有针对性的截断,生成“中模式”和“低模式”的样本。截断比例分别设为大约 50% () 和 75% ()。 -
平滑过渡:在截断后的推理内容末尾,添加模式特定的连接性文本(例如,在中模式下加入“我应该平衡推理深度和效率,现在我将停止思考并给出一个经过深思熟虑的回答。”),以确保逻辑流畅。 -
答案重新生成:为每个被截断的样本重新生成正确的答案部分,确保模型学会在推理不完整的情况下也能给出正确结果。 -
数据平衡:最终的数据集在三种模式之间保持平衡,以确保模型对每种模式都有充分的学习。
SFT 阶段的训练目标是最小化所有模式下的负对数似然损失,其公式如下:
其中, 是训练样本总数, 是第 个样本输出序列中的第 个 token, 是模式指示符, 是输入问题, 是由参数 控制的模型策略。
通过 BM-SFT,模型初步掌握了根据不同模式指令生成不同长度推理链的能力,为后续的精细化调优奠定了基础。
2.2 两阶段预算感知强化学习 (Two-Phase Budget-Aware Reinforcement Learning, BA-RL)
在模型具备了基本的模式区分能力后,ThinkDial 采用一个精心设计的两阶段强化学习策略来进一步优化其性能,确保在引入压缩能力的同时,不会损害模型原有的峰值推理水平。
2.2.1 DAPO 框架
ThinkDial 的强化学习方法建立在 DAPO (Decouple Clip and Dynamic sAmpling Policy Optimization) 框架之上。DAPO 通过对每个输入问题 采样一组输出 ,并根据这些输出来优化模型策略。其优化目标如下:
其中, 是重要性采样率, 是优势函数的估计值。
2.2.2 第一阶段:预热 RL 训练 (Warm-up RL Training)
在引入任何压缩目标之前,第一阶段的目标是让模型达到其性能天花板。在这一阶段,模型仅在高模式下进行训练,优化目标完全聚焦于提升任务的准确性,不施加任何关于响应长度的限制。
这个预热阶段至关重要,因为它确保了模型在学习压缩推理链之前,已经处于一个最优的性能状态。后续的压缩训练将在这个高性能基线上进行,从而避免了在学习控制能力时导致模型基础性能的下降。
2.2.3 第二阶段:带预算感知的奖励塑造 (RL with Budget-Aware Reward Shaping)
第二阶段的核心是引入预算感知的奖励函数,引导模型学习在不同模式下生成不同长度的响应。研究团队设计了一个复合奖励函数,它综合考虑了任务完成度、响应长度和推理泄漏三个方面。
对于在模式 下的输出 ,其总奖励 定义为:
-
任务奖励 () :通过精确匹配标准答案来评估任务是否正确完成,。
-
模式特定的长度奖励 () :这是实现可控推理的关键。它对不同模式施加不同的长度惩罚。
其中, 是输出的总长度, 和 是当前采样批次中的最小和最大长度。这个归一化的长度惩罚 将响应长度映射到一个标准化的 区间。
更重要的是,长度奖励的权重 是模式特定的。在高模式下,,不施加长度惩罚;在中模式和低模式下,逐步增加权重,例如 和 ,从而鼓励模型生成更短的响应。 -
泄漏惩罚 () :在训练中,研究人员发现了一个被称为“ Reasoning Length Hacking ”的现象。模型为了达成压缩目标(即缩短
<think>标签内的 token 数量),会倾向于将本应在思考环节完成的推理步骤,“泄漏”到最终的答案部分(即</think>标签之后的内容)。这种行为只是将推理成本从一个部分转移到了另一个部分,并没有真正实现推理压缩。
为了解决这个问题,研究人员引入了泄漏惩罚。如果在答案部分检测到诸如 "Wait", "Let me think", "Actually" 等典型的推理过程转换词,模型就会受到惩罚。这个二元奖励机制有效地抑制了推理泄漏,确保模型进行的是真正的推理过程压缩。
通过这个精细设计的两阶段 RL 训练和复合奖励函数,ThinkDial 成功地在保持高性能的同时,赋予了模型在不同模式间切换、生成不同长度推理的能力。
3. 实验与结果分析
为了验证 ThinkDial 框架的有效性,研究人员在一系列数学推理基准测试上进行了全面的实验。
-
实验设置
-
基础模型:Qwen-2.5-Instruct-32B。 -
数据集:实验覆盖了不同难度级别的数学推理任务,包括 AIME 2025 (难), AIME 2024 (中), 和 GSM8K (易)。此外,还使用 GPQA 数据集来评估模型在非数学领域的泛化能力。 -
基线模型:为了进行对比,实验设置了多个基线,包括: -
性能峰值检查点 (Peak-Performance Checkpoint) :只经过预热 RL 训练的模型,代表了模型的性能上限。 -
无 BM-SFT (w/o Budget-Mode SFT) :跳过预算模式微调,直接进行带长度奖励的 RL 训练。 -
仅 BM-SFT (Only Budget-Mode SFT) :只进行预算模式微调,不进行 RL 优化。 -
无预热 (w/o Warm-up) :跳过预热 RL 阶段,直接进行带长度奖励的压缩训练。 -
峰值截断 (Peak Truncation) :一种简单的基线方法,直接在性能峰值模型的输出上进行机械截断。 -
专有模型:OpenAI 的 gpt-oss-120b 和 o3-mini,作为业界先进水平的参考。
-
-
-
评估指标
研究人员定义了一个复合指标 准确率-成本权衡分数 (Accuracy-Cost Trade-off, ACT Score) 来量化可控推理的整体效果。对于模式 ,其 ACT 分数计算如下:其中, 是准确率保留率, 是压缩率。权重 反映了不同模式的侧重点:在高模式下,,完全关注性能;在中低模式下,,同等关注性能和效率。
3.1 总体性能分析
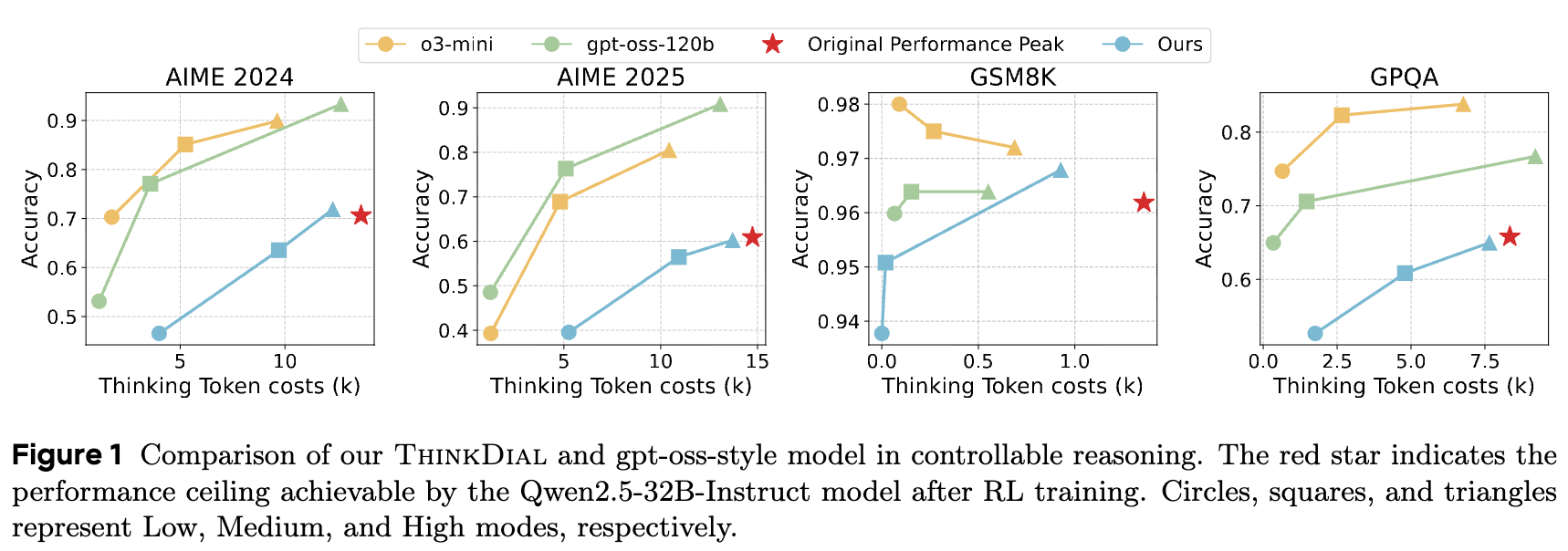
实验结果表明,ThinkDial 在所有基准测试中都取得了出色的 ACT 分数。
-
精确的权衡控制:模型在高模式下的性能与性能峰值基线持平甚至略有超出,打消了“为实现可控性会牺牲峰值性能”的担忧。同时,在中、低模式下,模型实现了明确的阶梯式性能/效率权衡,token 数量显著减少,同时性能下降被控制在预设阈值内。 -
智能的资源分配:模型表现出对问题难度的适应性。在面对更具挑战性的 AIME 系列问题时,模型会分配更多的推理 token;而在处理相对简单的 GSM8K 问题时,则会更有效地进行压缩。这表明模型学会了根据任务需求智能地分配计算资源,而非机械地执行压缩。 -
成功复现 gpt-oss 风格:性能可视化图表显示,ThinkDial 的准确率-token 成本曲线与 gpt-oss-120b 和 o3-mini 的曲线高度吻合,证明了该开放框架成功复现了专有系统的可控推理模式。 -
强大的泛化能力:尽管主要在数学数据上进行训练,ThinkDial 在 GPQA 这种跨领域的数据集上也表现出有效的可控性,证明了其学习到的控制机制具有良好的泛化能力。
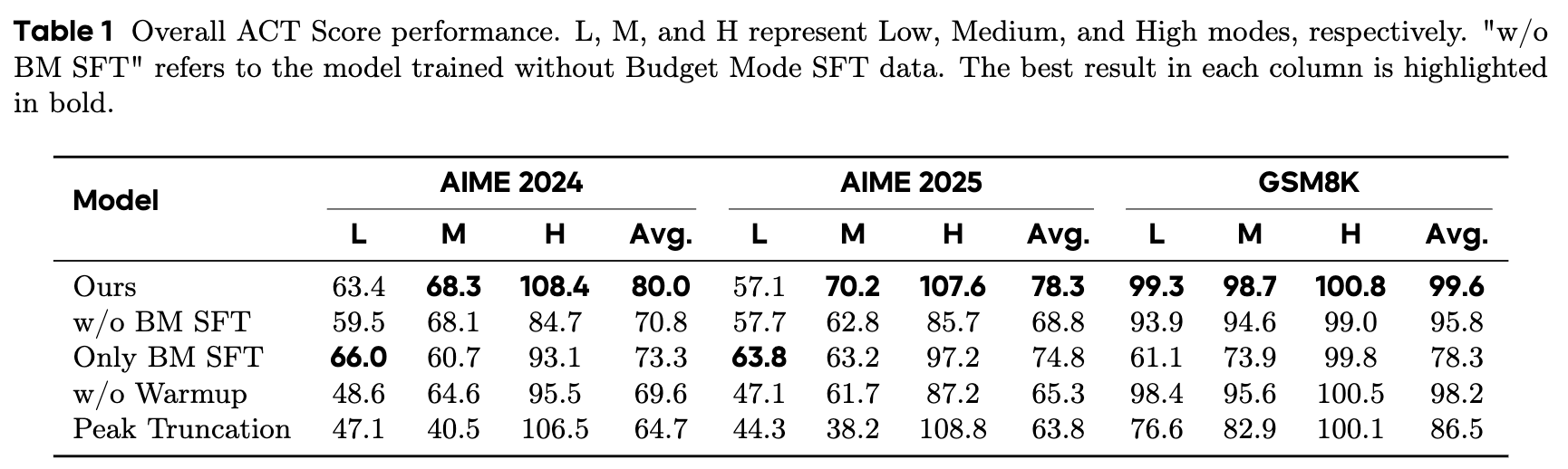
3.2 消融实验分析
通过一系列的消融实验,研究人员验证了框架中每个组件的必要性。
-
BM-SFT 的重要性
对比实验显示,如果没有经过 BM-SFT 的预先训练,直接进行带长度奖励的 RL 训练会导致灾难性的后果。三种模式的训练目标会互相严重干扰,导致高模式的性能大幅崩溃,远低于其应有的性能峰值。 这证明了 BM-SFT 为后续 RL 训练提供了必要的语义基础和模式区分能力,是整个框架不可或缺的一环。
-
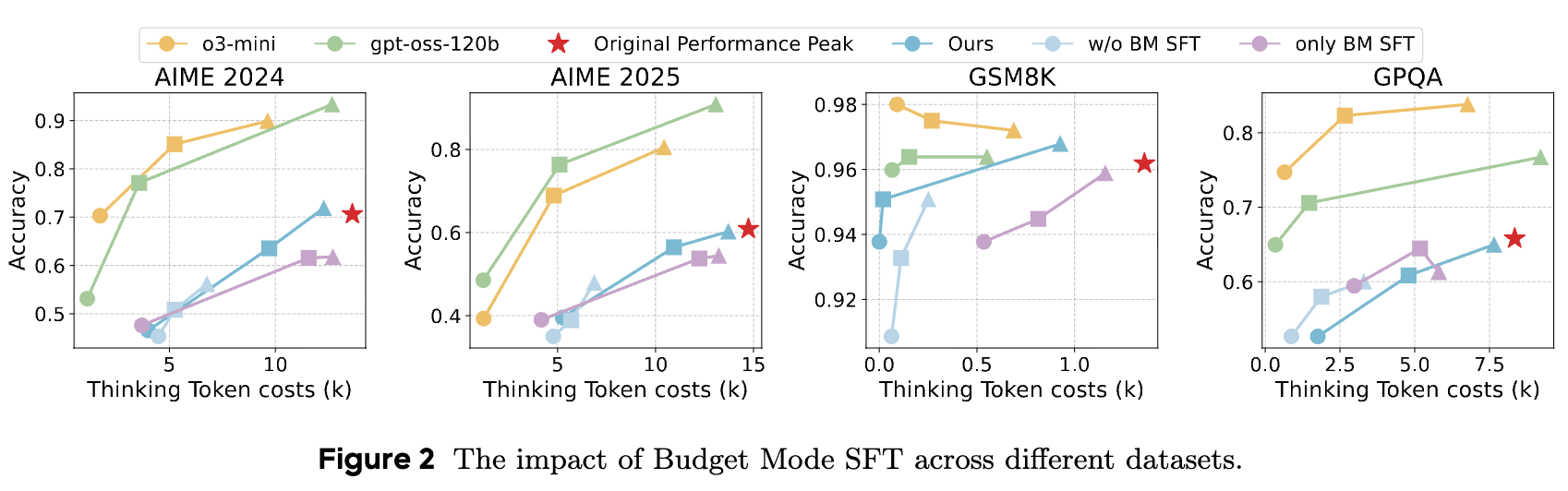
两阶段 RL 训练策略的重要性
实验表明,如果没有第一阶段的预热训练,模型在学习压缩的同时很难维持在高模式和中模式下的性能。预热阶段确保了压缩能力是建立在坚实的性能基础之上,而非以牺牲模型的核心能力为代价。
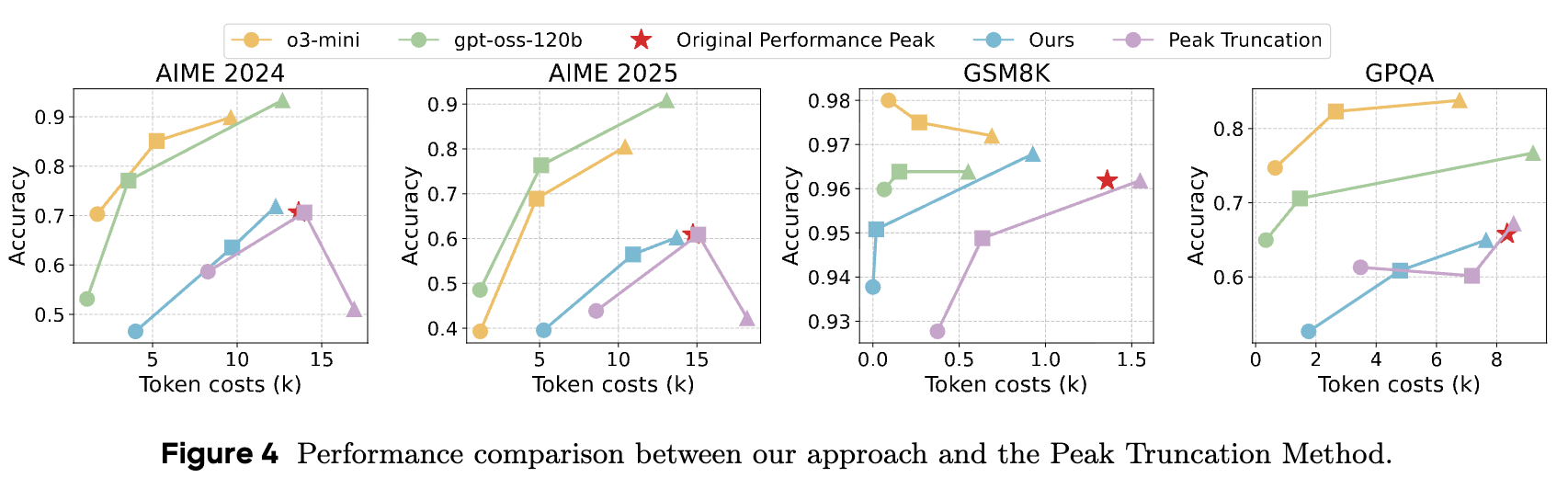
与简单的“峰值截断”方法相比,ThinkDial 的优势更为明显。机械地截断推理链会导致性能的急剧下降,无法形成平滑的性能-效率权衡曲线。这凸显了通过端到端训练学习到的压缩策略的复杂性和有效性。
-
解决推理长度hacking的重要性
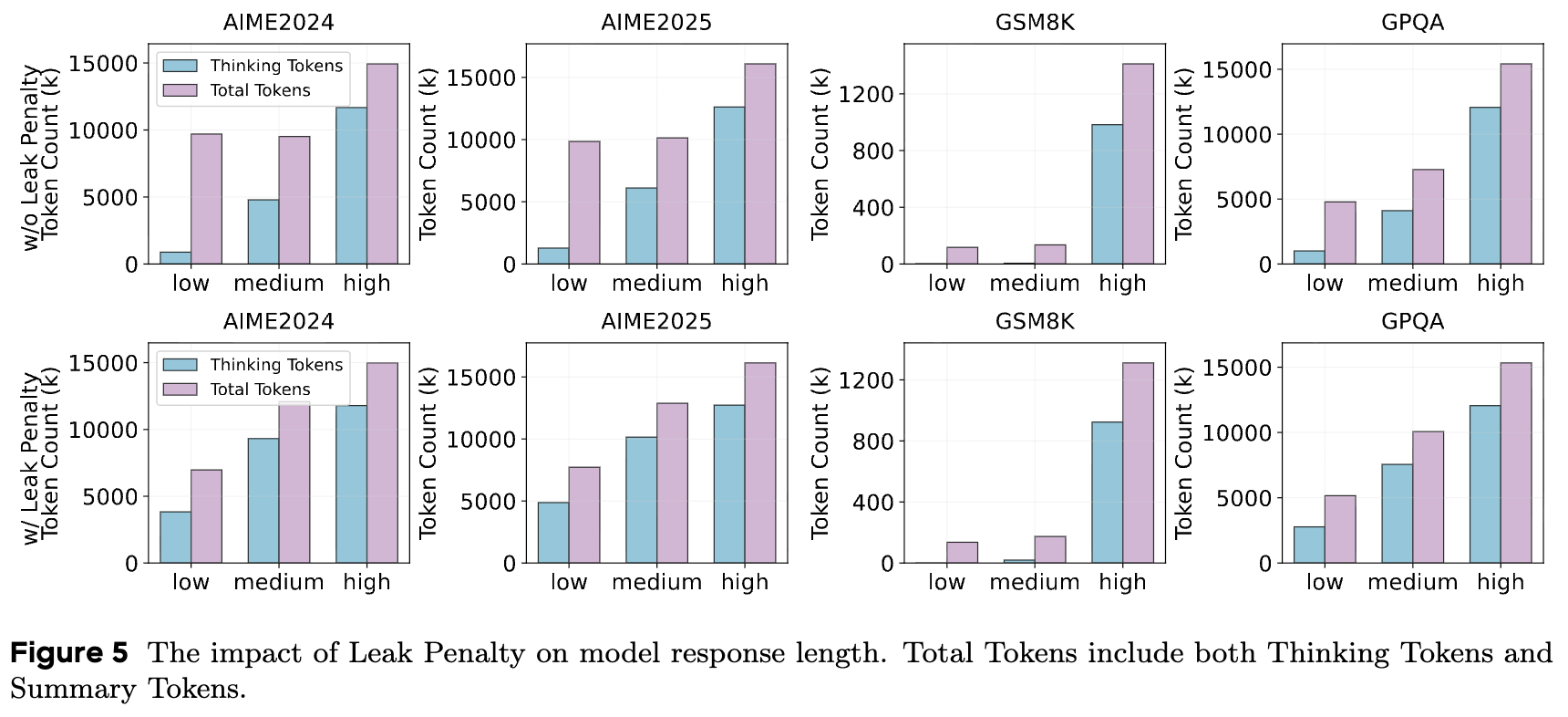
通过对比有无“泄漏惩罚”的模型,可以清晰地看到该机制的关键作用。在没有惩罚的情况下,尽管思考部分的 token 减少了,但答案部分的 token 却大幅增加,导致总 token 消耗不降反升,完全违背了压缩的初衷。引入泄漏惩罚后,模型能够同时压缩思考和答案部分的长度,实现真正的、全局的 token 数量缩减。
4. 点评
ThinkDial 的研究贡献是多方面的:
-
它提供了首个完整的、开源的端到端框架,用于实现类 gpt-oss 的三模式可控推理。 -
通过将预算控制从 SFT 阶段贯穿至 RL 阶段,并结合自适应奖励塑造,该框架为实现复杂的可控行为提供了有效途径。 -
研究揭示并解决了“推理长度hacking”这一模型在压缩训练中的投机行为,为后续相关研究提供了宝贵的经验。
也存在一些可以改进的地方:
当前BM-SFT阶段主要通过对完整推理链进行按比例截断来生成中、低模式的数据。这种方法虽然有效,但可能比较“生硬”,有时会切断一个重要的逻辑步骤,导致上下文不完整。
可以考虑基于语义的推理链压缩,使用一个强大的“teacher model”来对完整的推理链进行摘要和重写,而不是简单截断;或者是迭代式剪枝,逐步删除推理链中对最终答案影响最小的句子或步骤,剔除冗余信息。


