
-
论文标题:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning -
论文链接:https://arxiv.org/pdf/2501.12948v2
TL;DR
近期,DeepSeek-R1 的技术报告在 v1 版本(22页)的基础上进行了大幅扩充,形成了 v2 版本(86页)。v1 版本主要作为模型发布的简介,概述了 DeepSeek-R1-Zero 和 DeepSeek-R1 的核心理念及基础评估结果。v2 版本则补充了完整的技术实现细节,使其具备了复现指南的性质。
核心改动包括:
-
RL 算法细节披露:详细介绍了组相对策略优化(Group Relative Policy Optimization, GRPO)算法的数学原理,并对比了其与 PPO 的差异,解释了为何摒弃 Critic 模型。 -
训练流程全解:从 DeepSeek-R1-Zero 的纯 RL 探索,到 DeepSeek-R1 的“冷启动数据 -> 第一阶段 RL -> 拒绝采样与 SFT -> 第二阶段 RL”的完整流水线。 -
失败路径总结:新增了关于过程奖励模型(PRM)和蒙特卡洛树搜索(MCTS)的失败尝试分析(Negative Results)。 -
超参数与基础设施:附录中公开了各阶段详细的超参数(学习率、Batch Size、KL 系数等)及基于 vLLM 的 RL 训练架构。 -
安全性与评估:大幅增加了安全性测试报告、中间检查点(Checkpoint)的性能评估及 Chatbot Arena 的人类偏好评测。
1. 引言
DeepSeek-R1 系列模型旨在通过强化学习(RL)提升大语言模型的推理能力。v1 版本确立了“通过大规模 RL 激励推理能力涌现”的核心论点,并展示了令人瞩目的结果。然而,对于研究社区而言,v1 缺乏具体的实施细节。v2 版本填补了这一空白,不仅详细描述了如何从零开始训练 DeepSeek-R1-Zero,还阐述了如何通过多阶段训练解决语言混合和可读性差的问题,最终得到 DeepSeek-R1。
2. GRPO 的深度解析
在 v1 版本中,DeepSeek 团队仅提及使用了 GRPO 算法。在 v2 版本中,作者在正文及附录 A.3 中详细阐述了 GRPO 的数学原理,并提供了与 PPO 的对比实验。
2.1 PPO 与 GRPO 的架构差异
传统的 PPO(Proximal Policy Optimization)算法在训练大语言模型时,通常依赖于 Actor-Critic 架构。这意味着除了策略模型(Policy Model)外,还需要维护一个参数量相当的价值模型(Value Model/Critic),用于估计状态价值 以计算优势函数(Advantage)。
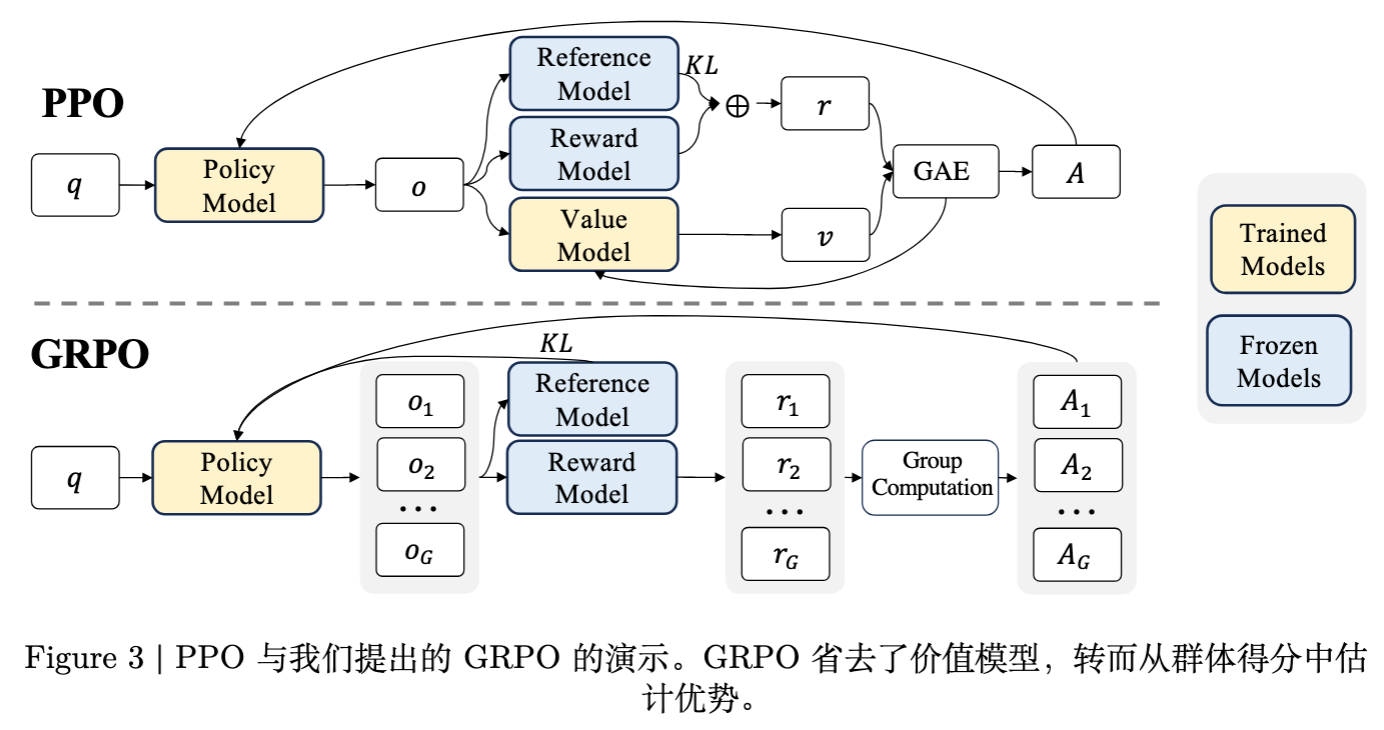
v2 报告指出,GRPO 摒弃了 Critic 模型。这一设计决策主要基于两点考量:
-
计算资源:Critic 模型通常与 Actor 模型大小一致,在大规模模型(如 671B MoE)训练中,额外的 Critic 模型会带来巨大的显存和计算开销。 -
基线估计(Baseline Estimation):GRPO 通过从同一问题 采样一组输出 ,利用组内输出的奖励均值作为基线,从而替代了价值模型的预测。
2.2 GRPO 的数学形式化
在 v2 中,GRPO 的目标函数被形式化定义。对于每个问题 ,模型 采样一组输出 。优化目标如下:
其中,优势函数 基于组内标准化的奖励计算:
这里, 是第 个输出的奖励。
关键改动点分析:
-
KL 散度处理:与 PPO 通常将 KL 散度作为奖励项的一部分不同,GRPO 将 KL 散度 直接加入损失函数中。v2 附录指出,PPO 的每 token KL 惩罚可能会在长链条推理(Long CoT)中不当地抑制模型输出长度,阻碍推理能力的探索。GRPO 的处理方式更利于模型在长序列生成中保持探索性。 -
Reference Model 更新:为了平衡探索广度与训练稳定性,v2 披露了具体策略:每 400 步将 Reference Model 更新为最新的 Policy Model。
2.3 GRPO 与 PPO 的性能对比
v2 附录 A.3 展示了在 DeepSeek-Coder-V2-Lite(16B MoE)模型上进行的 MATH 任务对比实验。
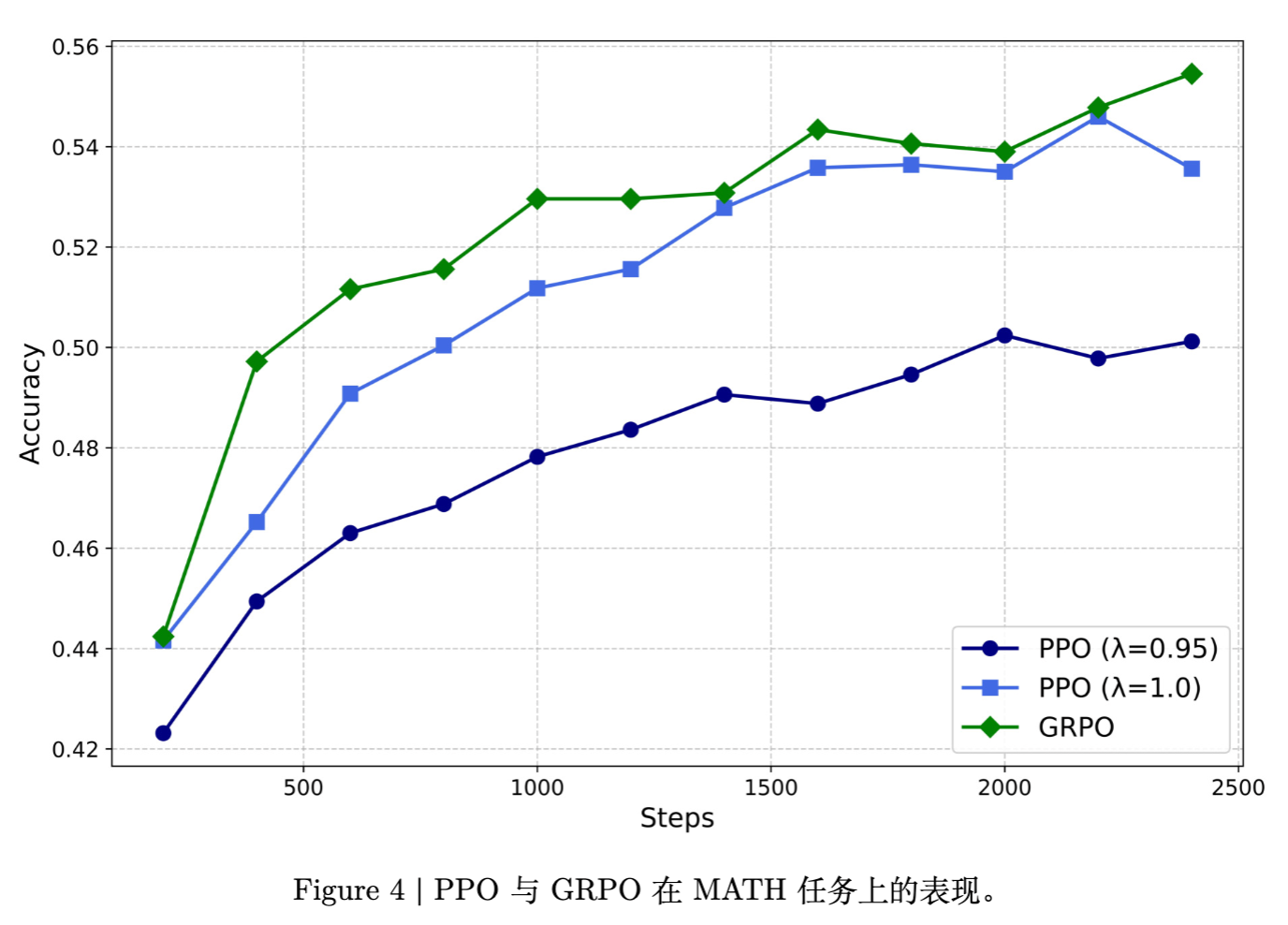
实验结果表明:
-
参数敏感性:PPO 对 GAE(Generalized Advantage Estimation)的参数 高度敏感。默认参数 下 PPO 表现显著劣于 GRPO;即使精细调节至 ,PPO 的性能也仅接近 GRPO。 -
训练效率:GRPO 省略了 Value Model,减少了内存占用和通信开销,使得在大规模模型上进行 RL 训练成为可能。
3. 训练流水线
v1 版本主要描述了 R1-Zero 和 R1 的概念。v2 版本则通过 Figure 2 和相关章节,详细拆解了 DeepSeek-R1 的完整训练流水线,特别是引入了中间检查点(DeepSeek-R1 Dev1, Dev2, Dev3)的概念,揭示了性能提升的来源。
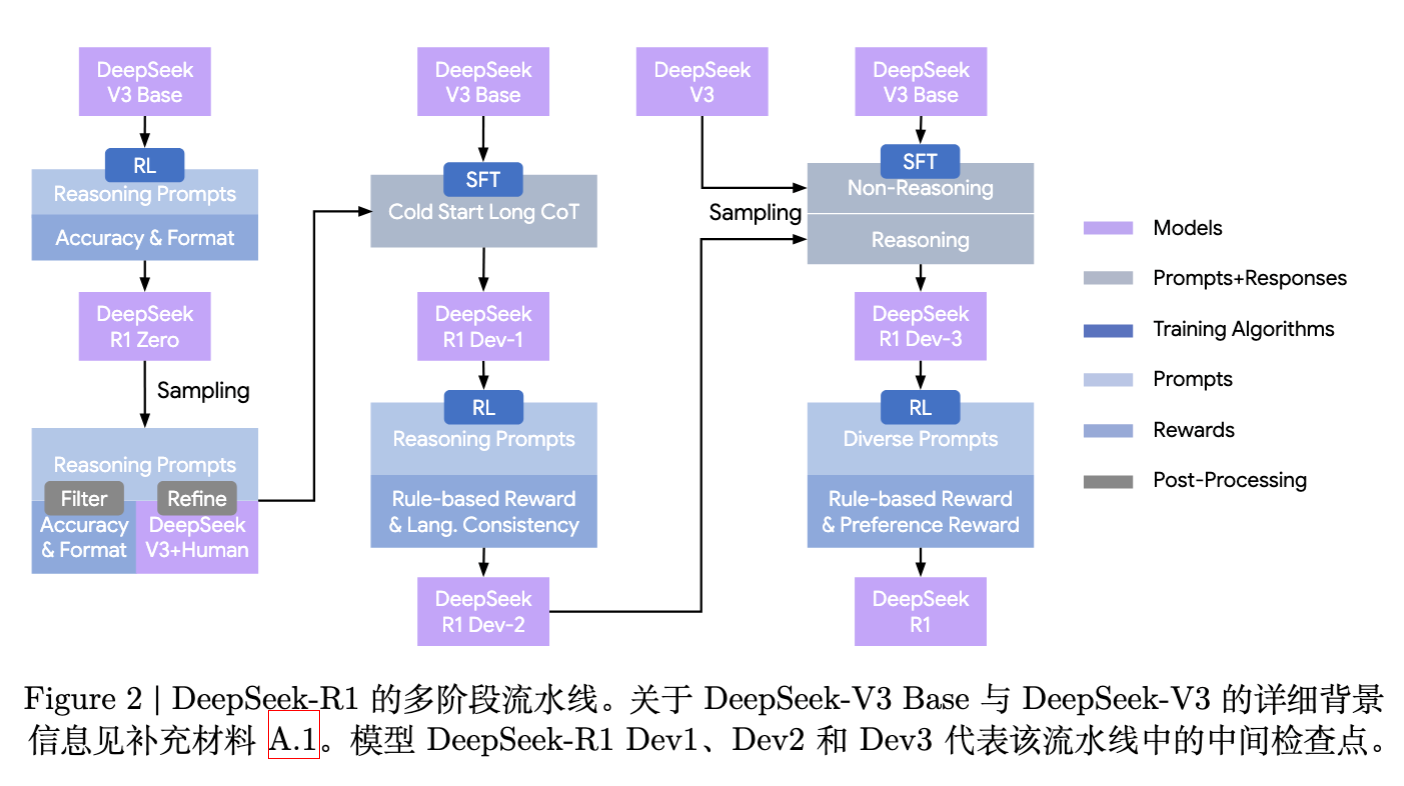
3.1 阶段一:DeepSeek-R1-Zero(纯 RL)
此阶段直接在 DeepSeek-V3-Base 上应用 GRPO,不使用任何 SFT 数据。
-
奖励设计:v2 明确了奖励仅包含 Accuracy Reward(答案准确性)和 Format Reward(格式合规性,即 <think>标签的使用)。明确指出不使用神经奖励模型(Neural Reward Model)以防止 Reward Hacking。 -
自进化现象:v2 详细记录了模型在训练过程中“顿悟(Aha Moment)”的时刻,即模型学会了通过重新评估(Re-evaluation)来分配更多的思考时间。附录 C.2 提供了具体的案例分析。
3.2 阶段二:冷启动(Cold Start)
R1-Zero 虽然推理能力强,但存在语言混合和可读性差的问题。v2 引入了“冷启动”数据的构建细节(附录 B.3.2):
-
数据来源:利用少量的长 CoT 数据对 Base 模型进行微调。这些数据通过让模型生成长 CoT、人工注释、以及多轮迭代清洗获得。 -
格式规范:定义了清晰的输出格式 |special_token|<reasoning_process>|special_token|<summary>,强制模型在思考后生成总结。 -
目的:为模型注入人类偏好的可读性格式,作为后续 RL 的起点。这一阶段产出的模型被称为 DeepSeek-R1 Dev1。
3.3 阶段三:推理导向的强化学习(Reasoning-oriented RL)
在冷启动模型的基础上,再次进行大规模 RL 训练。
-
语言一致性奖励(Language Consistency Reward):v2 首次披露了具体的计算公式。为了解决 R1-Zero 的语言混合问题,引入了如下奖励:
虽然消融实验(附录 B.6)显示该奖励会导致推理性能轻微下降,但显著提升了可读性。这一阶段的模型为 DeepSeek-R1 Dev2。
3.4 阶段四:拒绝采样与 SFT(Rejection Sampling & SFT)
当上一阶段 RL 收敛后,利用该 checkpoint 生成大量数据进行 SFT。
-
数据构成: -
推理数据(600k):对 RL 后的模型进行拒绝采样,保留正确且格式优良的样本。v2 指出,此处使用了生成式奖励模型(DeepSeek-V3 作为 Judge)来筛选部分数据,并过滤掉语言混合的样本。 -
非推理数据(200k):包含写作、问答、自我认知等通用任务,复用了 DeepSeek-V3 的 SFT 数据部分。
-
-
目的:将推理能力内化,同时恢复模型的通用能力。此阶段产出的模型为 DeepSeek-R1 Dev3。
3.5 阶段五:全场景强化学习(RL for all scenarios)
最后的 RL 阶段旨在对齐人类偏好(Helpfulness 和 Harmlessness)。
-
奖励组合:
其中通用奖励结合了基于模型的偏好奖励(Helpful RM 和 Safety RM)。 -
训练策略:v2 提到,为了避免 Reward Hacking,通用任务的偏好奖励仅在训练的最后 400 步加入,且使用了较低的 KL 惩罚系数。
4. 数据工程与奖励建模细节
v2 版本在附录中公开了大量关于数据和奖励的具体实现,这对于复现至关重要。
4.1 数据配方(Data Recipe)
附录 B.3 详细列出了 RL 训练数据的分布:
-
Math (26k): 包含代数、微积分等,通过确定性规则验证答案。 -
Code (17k): 来源于 LeetCode、Codeforces 等,通过编译器和测试用例验证。 -
STEM (22k): 物理、化学、生物等多选题目。 -
Logic (15k): 逻辑推理题。 -
General (66k): 用于最后的对齐阶段,包含有用性和安全性数据。
4.2 奖励模型(Reward Model)
v2 详细描述了通用任务奖励模型的训练:
-
Helpful RM:基于 DeepSeek-V3 管道,使用 pairwise 数据训练。 -
Safety RM:使用 point-wise 损失训练,区分安全与不安全响应。 -
公式:
4.3 提示词工程(Prompt Engineering)
v2 附录 B.2 和 J 章节展示了大量的 Prompt 模板,包括:
-
RL 训练模板:要求模型在 <think>标签内输出思维过程。 -
奖励模型评测模板:基于 LLM-as-a-Judge 的评测 Prompt。 -
数据清洗模板:用于将 R1-Zero 的输出转换为可读格式的 Prompt。
5. 基础设施与训练成本
v2 附录 B.1 和 B.4 提供了关于训练基础设施和成本的硬核数据。
5.1 训练架构
DeepSeek 采用了一个解耦的 RL 训练框架:
-
Rollout Worker:仅负责推理,使用 vLLM 加速生成,部署在多节点上。 -
Training Worker:负责参数更新,使用 DeepSeek-V3 的 DualPipe 策略进行管线并行。 -
Replay Buffer:用于存储生成的样本。
这种架构允许 Rollout 和 Training 独立扩缩容,解决了长 CoT 生成速度慢导致的 GPU 利用率低的问题。
5.2 训练成本
v2 公开了具体的训练消耗(估算值):
-
DeepSeek-R1-Zero:约 101k H800 GPU hours。 -
DeepSeek-R1:SFT 数据生成约 5k GPU hours,RL 训练约 41k GPU hours。 -
总成本:训练 DeepSeek-R1 的总算力消耗显著低于预训练阶段,证实了后训练(Post-training)的高效性。
6. 蒸馏(Distillation)与小模型策略
v1 简单提及了蒸馏效果,v2 则在 2.4 节和附录 F 进行了深入探讨。
6.1 蒸馏优于纯 RL
实验对比了两种小模型提升策略:
-
RL from Scratch:直接在 Qwen-32B-Base 上运行大规模 RL(类似 R1-Zero 的流程)。 -
Distillation:使用 DeepSeek-R1 生成的 800k 数据对 Qwen-32B 进行 SFT。
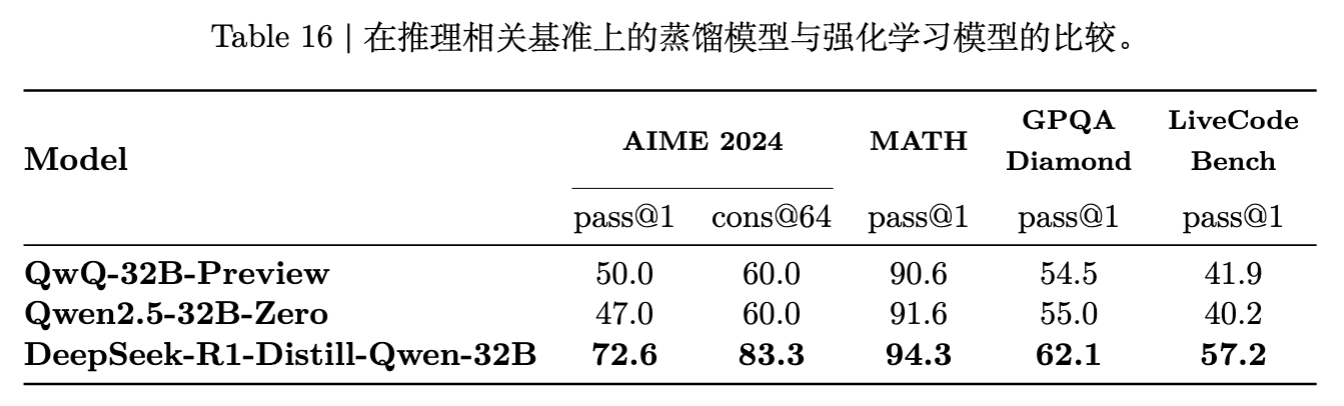
结果显示,蒸馏模型(DeepSeek-R1-Distill-Qwen-32B)在 AIME 2024 和 MATH-500 上的表现显著优于纯 RL 训练的模型。这表明,对于小模型而言,由大模型发现的推理模式(Reasoning Patterns)比其自我探索更易于学习。
6.2 开源模型列表
v2 确认开源了基于 Qwen2.5 和 Llama3 系列的多个蒸馏版本,涵盖 1.5B 到 70B 的参数规模。这些模型仅经过 SFT,未进行后续 RL,但性能依然超越了许多同类模型。
7. 负面结果(Negative Results)与失败尝试
这是 v2 版本中最具诚意的内容之一(附录 G.2)。研究团队分享了他们在研发过程中遇到的失败路径,为社区规避风险提供了参考。
7.1 过程奖励模型(Process Reward Model, PRM)
PRM 被认为是提升推理能力的重要方向,但 DeepSeek 团队并未在 R1 中采用,原因如下:
-
定义困难:难以明确定义推理步骤的粒度。 -
标注成本:大规模的人工标注难以扩展,而自动化标注的准确率不足。 -
Reward Hacking:基于模型的 PRM 极易导致 Reward Hacking,模型会利用奖励模型的漏洞刷分,而非真正提升推理质量。
7.2 蒙特卡洛树搜索(MCTS)
虽然 AlphaGo 证明了 MCTS 的有效性,但在 LLM 推理中,DeepSeek 团队遇到了以下挑战:
-
搜索空间过大:与围棋不同,文本生成的搜索空间呈指数级增长,难以通过 MCTS 有效覆盖。 -
价值模型训练难:训练一个能精确评估中间状态价值的 Value Model 极其困难,导致搜索引导失效。
8. 安全性评估(Safety Evaluation)
v2 新增了长达数页的安全性评估章节(附录 D.3),展示了 DeepSeek-R1 在安全性方面的表现。
-
越狱攻击(Jailbreak):测试表明,DeepSeek-R1 在面对越狱攻击时表现出较高的拒绝率,但也存在一定的防御薄弱点。v2 讨论了长 CoT 可能带来的安全隐患(如在 <think>中泄露有害信息,但在最终回答中隐藏)。 -
多语言安全性:评估了模型在不同语言环境下的安全性表现。 -
主要结论:虽然 R1 的推理能力强大,但在未经过专门的安全 RL 之前,其输出可能包含风险内容。最终发布的 R1 版本经过了安全对齐,平衡了有用性与无害性。
9. 详细评估分析
v2 扩展了实验部分,提供了更细粒度的分析。
9.1 中间检查点性能
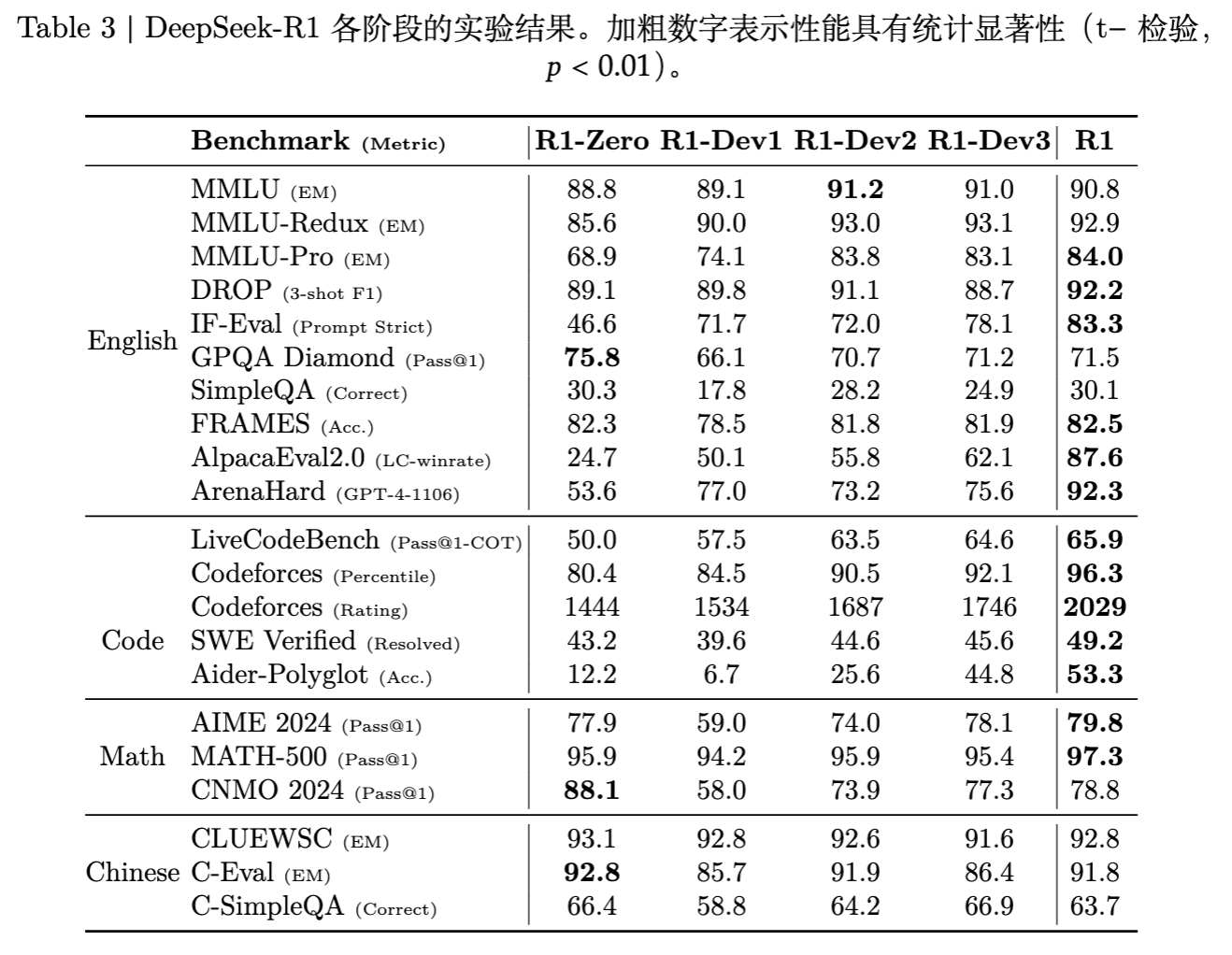
数据展示了从 R1-Zero 到 R1-Dev1, Dev2, Dev3 再到最终 R1 的性能演变。
-
Dev1 vs R1-Zero:由于引入了通用冷启动数据,Dev1 在推理任务上略有下降,但可读性提升。 -
Dev2 vs Dev1:经过推理导向的 RL,数学和代码能力大幅回升。 -
R1 vs Dev3:最后的对齐阶段在保持推理能力的同时,显著提升了 AlpacaEval 和 ArenaHard 的分数。
9.2 测试时计算扩展(Test-time Compute Scaling)
附录 E.4 分析了 CoT 长度与问题难度的关系。
-
自适应长度:模型学会了根据问题难度自适应地调整思考时间。对于简单问题(如 1+1),CoT 很短;对于复杂竞赛题,CoT 可达数千 token。 -
多数投票(Majority Voting):通过对长 CoT 输出进行采样投票,R1 的性能可以进一步提升,证明了模型生成的推理路径具有多样性。
更多细节请阅读原文。
往期文章:


