
-
论文标题:Scaling Laws for Code: Every Programming Language Matters -
论文链接:https://arxiv.org/pdf/2512.13472
TL;DR
今天解读一篇来自北航 & 九坤的一篇论文《Scaling Laws for Code: Every Programming Language Matters》。该研究针对代码大模型(Code LLMs)预训练中的核心问题——不同编程语言(PLs)的 Scaling 特性差异及多语言混合策略——进行了系统性的实证研究。
主要结论包括:
-
语言特异性 Scaling Laws:不同编程语言不仅不可互换,其 Scaling 行为差异显著。解释型语言(如 Python)相比编译型语言(如 Rust)具有更高的 Scaling 指数,即对模型参数量和数据量更敏感,且具有更高的不可约 Loss(内在复杂度)。 -
内在复杂度排序:通过不可约 Loss () 测定,编程语言的内在预测难度排序为:C < Java ≈ Rust < Go < TypeScript < JavaScript < Python。语法越严格,可预测性越高。
-
协同效应矩阵:多语言混合训练通常优于单语言训练。Java 表现出极强的“通用供体”特性,能提升大多数其他语言的表现;而 Python 作为辅助语言时往往带来负迁移。语法结构相似的语言对(如 Java-C#,JS-TS)表现出显著的协同效应。 -
平行语料的价值:利用平行语料(代码翻译对)进行拼接训练,能显著提升跨语言 Scaling 效率,且即使在零样本(Zero-Shot)场景下也能通过隐式桥接提升未见语言对的翻译能力。 -
比例依赖的 Scaling Law:论文提出了包含语言比例参数的通用 Scaling Law 公式,并据此推导出了在固定算力预算下的最优数据配比策略——增加高收益语言(Python)和高协同组合的权重,减少快速饱和语言(Rust)的权重。
1. 引言
大语言模型(LLM)的发展在很大程度上归功于 Scaling Laws(缩放定律)的指导。从 Kaplan et al. (2020) 到 Hoffmann et al. (2022) 的 Chinchilla 研究,我们已经建立了一套基于幂律分布的理论框架,用于描述模型性能(Loss)与计算量(Compute)、数据量(Data)和参数量(Parameters)之间的关系。
然而,现有的 Scaling Laws 研究主要集中在自然语言领域或将“代码”视为一个同质的整体。在实际的代码大模型预训练(如 Codex, StarCoder, Llama-Code, DeepSeek-Coder)中,训练数据往往是由几十种甚至上百种编程语言混合而成的。
这就引出了一系列长期悬而未决的问题:
-
异质性问题:Python 和 C++ 在语法结构、抽象层级和语义逻辑上天差地别,它们遵循相同的 Scaling 曲线吗? -
数据配比问题:在有限的算力预算(Compute Budget)下,应该如何分配不同编程语言的 Token 比例?是均匀分布,还是依据某种指标加权? -
相互作用问题:学习 Java 会促进 Python 的能力吗?还是会产生干扰(Negative Transfer)?
2. 基础理论框架与实验设定
2.1 Chinchilla Scaling Law 的数学形式回顾
在进入代码特定领域前,我们需要回顾 Chinchilla Scaling Law 的标准形式。对于一个参数量为 ,训练 Token 数为 的模型,其验证集 Loss 可以表示为:
其中:
-
和 是常数。 -
是参数量的 Scaling 指数,反映模型性能随参数增加而提升的速率。 -
是数据量的 Scaling 指数,反映模型性能随数据增加而提升的速率。 -
是不可约 Loss(Irreducible Loss),代表了数据的固有熵或贝叶斯误差下界,即拥有无限算力和数据时模型能达到的理论最优值。
2.2 实验环境配置
为了控制变量,研究团队采用了一套严格标准化的实验设置:
-
模型架构:采用类 LLaMA-2 架构,包含 SwiGLU 激活函数、RoPE 旋转位置编码、MHA 多头注意力机制和 RMSNorm。 -
模型规模:覆盖 10 个量级,从 0.1B 到 3.1B(部分实验扩展至 14B)。 -
数据规模:Token 预算覆盖 6 个档位,从 2B 到 64B,最大实验涉及 1T Token。 -
目标语言:选取了 7 种代表性编程语言,涵盖不同范式: -
Python:动态类型,解释型,广泛使用。 -
Java:静态类型,虚拟机运行,面向对象。 -
JavaScript (JS) :动态类型,Web 核心。 -
TypeScript (TS) :JS 的超集,静态类型。 -
C# :强类型,企业级应用。 -
Go:静态类型,编译型,简洁并发。 -
Rust:静态类型,编译型,内存安全,语法严格。
-
实验总规模为:10 (模型尺寸) × 6 (数据预算) × 7 (语言) = 420 个基础 Scaling 实验。
3. 单编程语言的 Scaling 特性分析
首先,研究者针对每种语言单独训练并拟合了 Scaling Law 曲线。结果表明,不同编程语言的训练动力学存在本质差异。
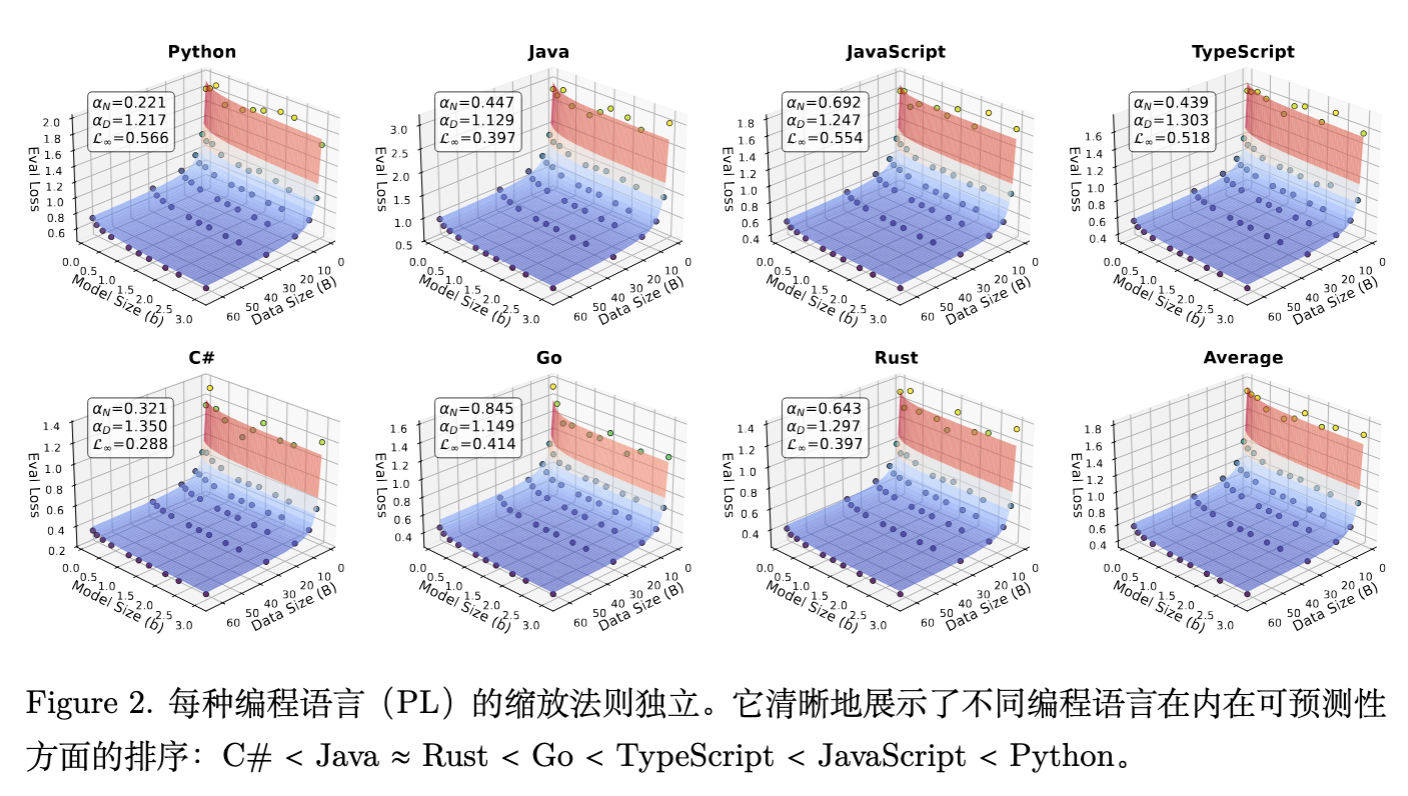
该图展示了不同语言在模型大小和数据大小时 Loss 下降的曲面。结果显示出清晰的内在可预测性排序:C
< Java ≈ Rust < Go < TypeScript < JavaScript < Python。
3.1 Scaling 指数 () 的差异
拟合结果揭示了一个显著的规律:解释型语言比编译型语言具有更大的 Scaling 指数。
-
Python:拥有最高的 和 。这意味着 Python 模型非常“吃”资源——随着模型变大和数据变多,其性能提升的幅度远超其他语言。这也暗示了 Python 模型在小规模时可能表现不佳,但具有极高的上限。 -
Rust:表现出较小的 Scaling 指数。由于 Rust 拥有严格的类型系统、所有权机制和显式的语法结构,模型在较小的参数和数据量下就能较好地掌握其规律,随后进入边际效应递减区。
物理含义:
Scaling 指数越大,意味着该任务的“信息密度”或“模式复杂性”越高,需要更多的容量来压缩信息。Python 灵活多变的语法和动态特性使其更难以被简单规则覆盖,因此需要更大的模型和更多的数据来捕捉长尾分布。
3.2 不可约 Loss () 与语言复杂度
反映了语言本身的熵。如果我们将编程语言视为一种信息编码方式, 越低,说明该语言越规整、歧义越少。
论文得出的复杂度(难度)排序为:
此排序的解释如下:
-
C (最低 Loss)
:受益于极其严格的类型系统、统一的命名规范(如 Microsoft 风格)和高度标准化的生态系统。代码的一致性极高,模型极易预测下一个 Token。 -
Java & Rust:同样强制执行严格的句法和语义约束(如 Rust 的生命周期标注),限制了表达的多样性,降低了预测难度。 -
Go:设计极简,强制的代码格式化(gofmt),但其表达力受限于极简主义设计,处于中间位置。 -
TypeScript:作为 JS 的超集,引入了类型约束,比纯 JS 更可预测,但保留了部分灵活性。 -
JavaScript:动态类型,范式灵活(函数式、OOP 混用),且历史上缺乏统一标准,导致语料库中存在大量风格迥异的代码。 -
Python (最高 Loss) :动态类型,极具表现力。Python 之所以 Loss 最高,是因为它允许用多种截然不同的方式实现同一功能(尽管 Python 之禅提倡一种方式,但现实语料并非如此),且包含大量省略、语法糖和动态属性,这显著增加了预测的不确定性。
结论:在训练 Code LLM 时,不能期望所有语言达到相同的 Loss 水平。Python 的高 Loss 是其语言特性决定的,而非模型训练不足。
4. 双语混合:协同效应与干扰
在实际预训练中,我们几乎总是混合数据。第二个核心问题是:混合两种语言(Language A + Language B)训练,相比于只训练 Language A(数据量翻倍),效果是更好还是更差?
4.1 协同增益(Synergy Gain)定义
为了量化这种效应,论文定义了协同增益 :
-
:基线。在总 Budget 为 128B 的情况下,使用 64B 重复两遍(或总共 128B )训练得到的 验证集 Loss。 -
:实验组。使用 64B 和 64B 混合训练得到的 验证集 Loss。 -
:表示正向协同,混合 比单纯增加 数据更有效。 -
:表示负向干扰。
4.2 协同矩阵分析
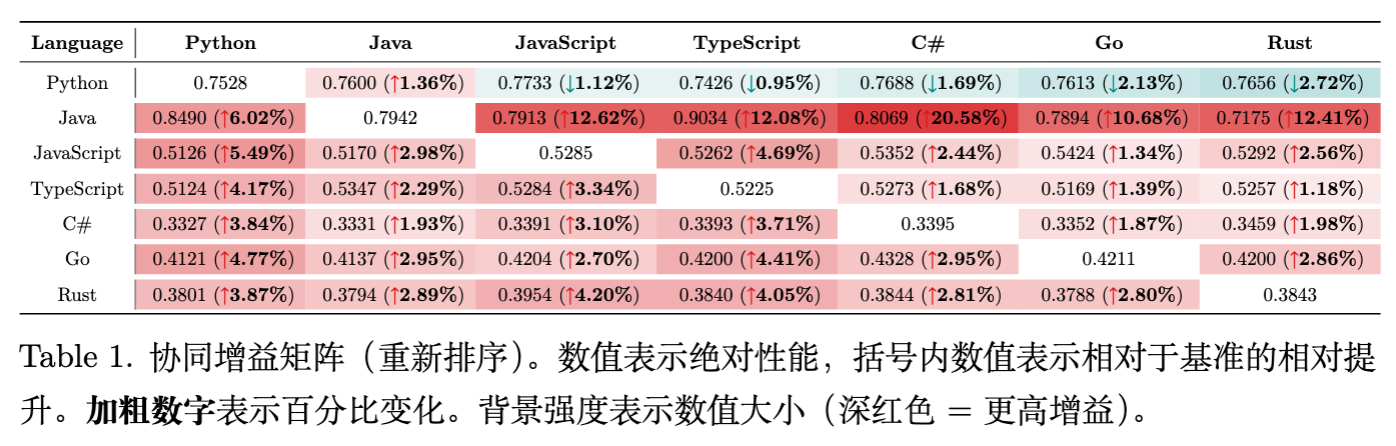
基于 28 个模型的实验结果(7种语言两两组合),论文揭示了几个关键现象:
-
多语言训练普遍有益:在 7 种语言中,有 6 种语言在与大多数辅助语言混合时表现出正向协同。这打破了“单语言专精模型最好”的迷思。 -
Java 的“全能供体”效应: -
Java 与所有其他语言混合时,都能给对方带来显著提升。 -
特别是 Java + C# 组合,C 的加入让 Java 的 Loss 相比基线降低了 20.58%。这可能是因为两者都是强类型、面向对象、语法高度相似(C-family)的语言,共享了大量的设计模式和标准库逻辑。
-
-
Python 的“孤岛”效应: -
当 Python 作为目标语言时,混合其他语言(JS, TS, C#, Go, Rust)大多带来微小的负增益或忽略不计的微小正增益。 -
解释:Python 的缩进风格(Indentation-based)与 C-family 的大括号风格(Brace-based)截然不同。这种语法上的正交性使得底层统计规律难以迁移,甚至可能产生噪声干扰。
-
-
语法相似性主导迁移: -
JS - TS:互为强协同对。 -
Java - C# :互为强协同对。 -
这表明,在数据配比时,将语法相似的语言聚类(Cluster)在一起是有效的策略。
-
5. 跨语言 Scaling Laws:平行语料的威力
除了非配对的混合训练,论文还深入探讨了使用平行语料(Parallel Corpus,即实现相同功能的代码对)对模型 Scaling 行为的影响。这是针对代码翻译任务(Code Translation)的研究。
5.1 数据构建与策略
-
数据:构建了以 Python 为中心(Pivot)的平行语料库,即 Python <-> {Java, JS, TS, C#, Go, Rust}。注意,非 Python 语言之间(如 Java <-> Go)没有直接的平行数据。 -
三种训练策略: -
隐式(Implicit/Shuffled):随机打乱所有单语言数据,没有明确的对齐信号。 -
监督(Supervised/Pairing):将平行代码对拼接在一起训练(Document-level pairing),例如 Python Code <EOS> Java Translation。 -
零样本(Zero-Shot):测试模型在未见过的非 Python 语言对(如 Java -> Go)上的翻译能力。
-
5.2 翻译任务的 Scaling 公式
对于监督训练(Python <-> Others),Scaling Law 遵循以下形式:
关键发现:
-
平行拼接策略的 Scaling 指数 () 显著高于随机打乱策略 ()。 -
这意味着显式的文档级对齐(Document-level alignment)使得模型能够极高效率地利用参数容量来学习跨语言映射。随着模型变大,监督策略的优势呈指数级扩大。
5.3 零样本跨语言能力的涌现
最令人兴奋的发现出现在零样本场景(如 Java -> Go),尽管模型从未见过 Java 和 Go 的成对数据:
-
监督策略(拼接 Python 对)显著提升了非 Python 对的翻译能力。 -
其 Scaling Law 形式为:
-
解释:模型通过 Python 作为隐式的“桥梁”或“锚点”。通过学习 Java <-> Python 和 Python <-> Go,模型在潜空间(Latent Space)中对齐了 Java 和 Go 的表示。这种“组合式泛化”(Compositional Generalization)能力随着模型规模扩大而显著增强。
5.4 拼接策略对比
论文还对比了两种拼接方式:
-
直接拼接 (Direct Concatenation) : Source Code + Target Code -
基于提示的拼接 (Prompt-based Concatenation) : Source Code + "Translate to X" + Target Code
结果表明,基于提示的拼接略优,但这两种显式拼接方法都远优于随机打乱基线。这指导我们在构建预训练数据时,应尽可能识别平行代码并显式构造拼接样本。
6. 多语言预训练指南:比例依赖 Scaling Law
本论文的终极目标是指导实际生产。基于上述发现,作者提出了一个整合了语言比例参数的 Proportion-dependent Multilingual Scaling Law。
6.1 理论推导
传统 Scaling Law 假设数据是同质的。作者将其扩展为包含语言比例向量 的形式:
其中:
-
加权参数:Scaling 指数 和 以及不可约 Loss 不再是常数,而是各语言参数的加权平均(权重基于比例 )。
-
有效数据量 :这是最核心的创新。实际有效数据量不仅仅是物理 Token 数,还包含了来自其他语言的迁移贡献。 -
是从表 1 协同矩阵中推导出的迁移系数。 -
该公式数学化地表达了:如果你混合了具有高协同效应的语言对(如 Java 和 C#),你的“有效数据量”会膨胀,从而降低 Loss。
-
6.2 最优数据分配策略 (Optimized Allocation)
基于上述公式,作者构建了一个优化问题:在给定总计算预算( 和 固定)的前提下,寻找最优比例向量 ,使得整体 Loss 最小。
通过求解该优化问题,论文展示了相比于均匀分布(Uniform Allocation)的优化方案:
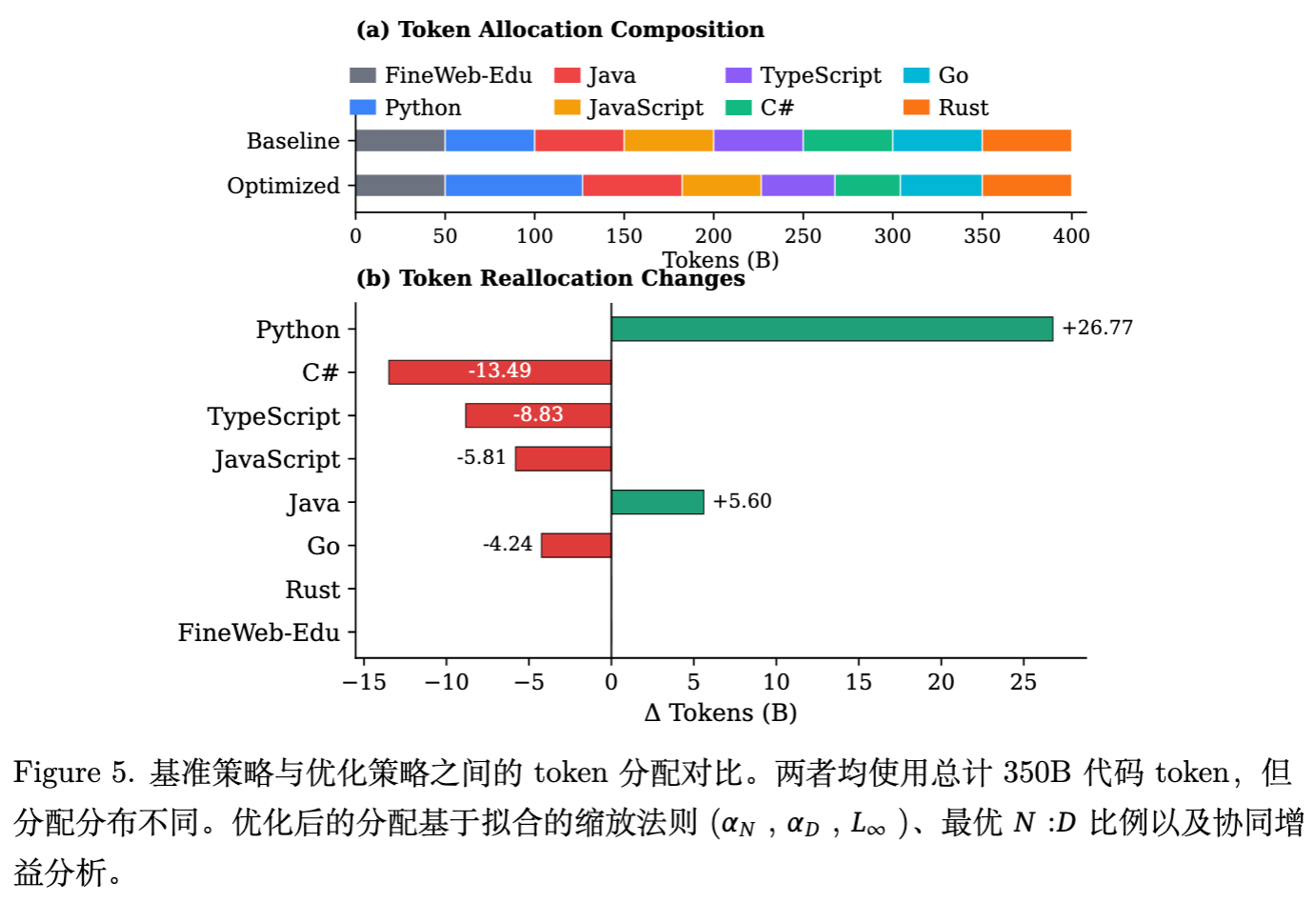
虽然两者总代码 Token 数均为 350B,但分布截然不同。优化分配是基于拟合的 Scaling Laws、最优 N:D 比率以及协同增益分析推导得出的。
调整方向:
-
大幅增加 Python:由于 Python 具有高 (数据饥渴)和高复杂性,优化算法建议显著增加 Python 的配比(图中增加了 26.77B Token)。 -
平衡强协同对:对于 JavaScript 和 TypeScript,算法倾向于保持相对平衡的比例,以利用互补效应。 -
削减快速饱和语言:Rust 和 Go 的 较低,且易于早期收敛。算法建议减少它们的配比(Rust 减少 4.24B,Go 减少 5.81B)。这一策略类似于“边际效用均等化”——将宝贵的 Token 预算从低收益区(已饱和的 Rust)转移到高收益区(未饱和的 Python)。 -
利用 Java 的供体特性:适度增加 Java,因为它能辅助 C 等其他语言。
6.3 实测验证
为了验证这一理论推导的有效性,作者训练了两个 1.5B 的模型,分别使用均匀分布和优化分布的数据。
-
测试基准:MultiPL-E(代码生成)和自建的代码翻译测试集。 -
结果: -
平均性能提升:优化模型在所有语言的平均 Pass@1 和 BLEU 分数上均优于基线。 -
Python 大幅提升:符合预期。 -
低资源语言未受损:最令人惊讶的是,尽管 Rust 的训练数据被削减了,其性能并没有显著下降(甚至保持持平)。这验证了 Scaling Law 的预测——Rust 在该数据规模下已经进入饱和区,多余的数据是浪费。
-
这一结果有力地证明了:盲目堆砌数据是不够的,基于 Scaling Law 的科学配比可以在不增加算力成本的前提下免费提升模型性能。
7. 结论与工程启示
7.1 核心结论总结
这篇文章是代码大模型领域的一项基础性工作。它并没有提出某种新的 Attention 变体,而是通过扎实的实证研究,量化了我们长期以来的经验直觉:
-
语言不平等:Python 最难学,但也最具潜力;Rust 最好学,但上限受限。 -
混合有技巧:不要指望 Python 能帮助 C++,但一定要把 Java 和 C#,JS 和 TS 放在一起练。 -
平行最有效:如果有平行语料,一定要拼接训练,这对多语言对齐至关重要。 -
配比需计算:不要拍脑袋决定数据比例,应根据语言的 Scaling 属性和协同系数进行优化求解。
7.2 工程建议
-
数据采集优先级:
-
投入最大资源清洗和扩充 Python 数据,因为它的 Scaling 还没到头。 -
对于 Rust/Go 等强类型编译语言,如果资源有限,可以适当放宽数据量要求,因为它们收敛得快。
-
-
数据混合策略:
-
在构建 Batch 时,或者在数据洗牌(Shuffling)阶段,考虑聚类采样。尽量让 JS 和 TS 出现在相近的上下文中,或者确保训练集中包含足够的 Java-C 混合模式。
-
警惕 Python 对其他语言的潜在干扰,在微调阶段(Fine-tuning)如果专注于特定语言(如 C++),可能需要降低 Python 的比例。
-
-
利用平行数据:
-
不仅要收集单语言代码库,更要挖掘 GitHub 上的多语言实现(如 LeetCode 题解、算法库的多语言版本)。 -
采用 Source <SEP> Target的拼接格式进行预训练,这能极大地促进 Zero-Shot 翻译能力。
-
-
动态配比调整:
-
随着模型规模()的增大,应重新计算最优数据配比。小模型可能需要更多易学的语言来打底,而大模型需要更多高复杂度的语言(Python)来填满其容量。
-
更多细节请阅读原论文。
往期文章:


