-
论文标题:SELF-DISTILLATION ENABLES CONTINUAL LEARNING -
论文链接:https://arxiv.org/pdf/2601.19897
TL;DR
本文提出了一种名为 SDFT (Self-Distillation Fine-Tuning) 的方法,旨在解决基础模型(Foundation Models)在持续学习(Continual Learning)过程中面临的灾难性遗忘问题。SDFT 利用模型自身的上下文学习(In-Context Learning, ICL)能力,构建了一个以“演示(Demonstration)”为条件的教师模型,并通过在线(On-Policy)蒸馏的方式指导学生模型(即原模型本身)。理论上,SDFT 可以被视为一种无需显式奖励函数的逆强化学习(Inverse RL)。实验结果表明,在技能学习和新知识获取任务中,SDFT 在提升新任务性能的同时,显著减少了对旧任务的遗忘,其表现优于监督微调(SFT)及其他离线蒸馏方法。
1. 引言
基础模型在语言、视觉和机器人等领域展现了广泛的能力。然而,现有的 AI 系统在部署后通常保持静态。虽然可以通过检索增强生成(RAG)或提示工程(Prompting)在推理阶段调整模型行为,但模型参数并未更新,因此无法内化新技能或知识。
为了实现真正的智能,模型需要具备持续学习(Continual Learning)的能力:即在不断获取新技能和知识的同时,不降低(或仅轻微降低)已有的通用能力。
1.1 SFT 的局限性
目前,从专家演示中学习的主流范式是监督微调(Supervised Fine-Tuning, SFT)。SFT 将演示数据视为静态的监督信号,其本质是离线策略(Off-Policy)学习。
SFT 面临的核心问题在于训练数据分布与模型推理时的诱导分布(Induced Distribution)不匹配。
-
训练时:模型学习的是专家轨迹上的行为 。 -
推理时:模型一旦产生微小的误差,状态分布就会偏离专家轨迹,进入未见过状态(Out-of-Distribution states)。由于缺乏纠正反馈,误差会迅速累积,导致所谓的“复合误差(Compounding Errors)”。
此外,在持续学习的场景下,SFT 倾向于过度拟合当前任务的数据分布,导致模型参数大幅偏离预训练状态,从而引发灾难性遗忘(Catastrophic Forgetting)——即模型在学习任务 B 后,在任务 A 上的性能急剧下降。
1.2 在线学习(On-Policy Learning)的优势与挑战
与之相对,在线学习(On-Policy Learning)通过让模型在自身生成的轨迹上进行训练,能够有效缓解分布偏移问题。研究表明,基于策略梯度的强化学习(RL)在保持通用能力和泛化性方面优于 SFT。
然而,传统的在线 RL 依赖于显式的奖励函数(Reward Function)。在许多现实场景(如开放域问答、复杂推理)中,定义一个高质量的奖励函数极其困难,或者不可用。
1.3 SDFT 的切入点
本文提出的 SDFT 试图结合两者的优势:
-
利用演示数据(如同 SFT,无需显式奖励)。 -
保持在线学习(如同 RL,缓解分布偏移和遗忘)。
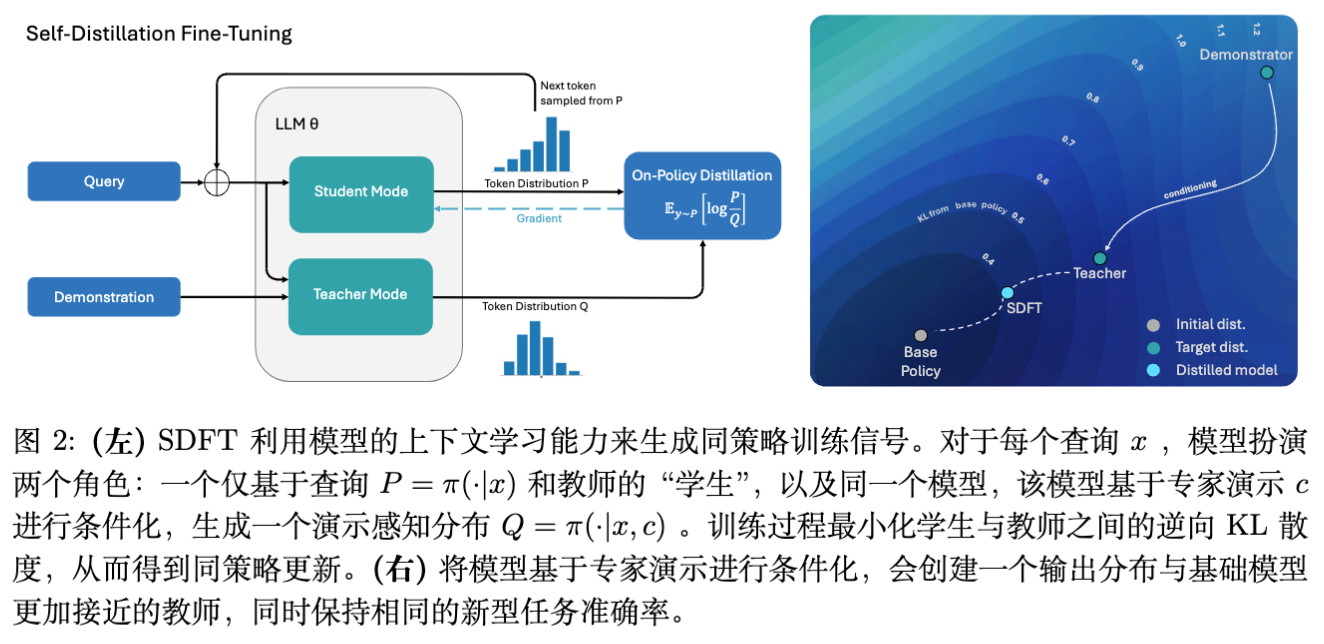
其核心直觉是利用大模型强大的上下文学习(ICL)能力。给定一个任务 和专家演示 ,模型 的表现通常优于仅给定任务 的表现。我们可以将前者视为“教师”,后者视为“学生”,通过在线蒸馏使得学生逼近教师的行为。
2. 理论框架
虽然 SDFT 在形式上表现为学生-教师蒸馏,但作者通过推导证明,该过程在数学上等价于最大化一个隐式奖励函数的逆强化学习(Inverse RL, IRL)过程。
2.1 信任区域更新与最优策略
考虑标准的信任区域(Trust-Region)正则化 RL 问题。在第 步,我们希望找到策略 ,使其在最大化奖励的同时,不偏离当前策略 :
其中 是奖励函数, 是正则化系数。该优化问题的闭式解(Closed-form solution)为著名的倾斜分布(Tilted Distribution):
2.2 隐式奖励推导
通过重排上述公式,我们可以将奖励函数表示为最优策略与当前策略之间差异的函数:
在标准的 IRL 设定中,最优策略 是未知的。然而,SDFT 引入了一个关键假设:上下文学习假设(In-Context Assumption)。
假设:给定专家演示 ,条件化后的模型 可以近似该任务的最优策略。即:
这一假设的合理性基于两点:
-
最优性:条件化后的模型通常能生成高质量的响应。 -
最小偏离:由于教师模型与学生模型共享参数(仅上下文不同),其输出分布在 KL 意义上接近基础模型,符合信任区域的要求。
将此假设代入奖励公式,得到 SDFT 优化的隐式奖励:
2.3 目标函数等价性
基于上述隐式奖励,如果我们使用策略梯度方法更新当前策略 ,其梯度为:
另一方面,如果我们考虑在线蒸馏,最小化学生 和教师 之间的逆向 KL 散度(Reverse KL):
可以发现,最小化逆向 KL 的梯度与最大化上述隐式奖励的策略梯度在期望上是等价的。这确立了 SDFT 的理论基础:它是一个利用 ICL 构造隐式奖励模型的在线强化学习算法。
3. Self-Distillation Fine-Tuning
SDFT 的实施并不依赖外部复杂的奖励模型或更大的教师模型,而是完全基于自身。
3.1 核心流程
对于每一个查询(Query):
-
构建教师(Teacher Construction):
从演示数据集 中检索或采样一个相关的演示 。构建教师提示词,通常包含<Question>,<Demonstration>,<Thinking Process>等结构。
教师分布定义为 。 -
学生采样(Student Rollout):
学生模型仅接收查询 。
学生分布定义为 。
从学生分布中采样生成一条完整的响应轨迹 。这是一个关键的 On-Policy 步骤。 -
计算梯度与更新:
计算轨迹 上教师和学生的似然比。
最小化逆向 KL 散度 。
3.2 梯度估计器
由于目标是最小化 ,且采样来自 ,我们需要处理采样操作的不可导性。SDFT 采用了基于 Token 的分析梯度估计器(Analytic per-token estimator)。
利用模型的自回归特性,KL 散度可以分解为 Token 级别的求和。对于第 步,给定历史 ,SDFT 计算:
这比单纯的 REINFORCE 估计器方差更小,因为我们在每一步都利用了词表 上的完整分布信息,而不是仅利用采样到的单一 Token。
3.3 EMA 的必要性
在训练过程中,教师模型 的参数如何设定是一个关键的设计选择。
-
选项 A:冻结的基础模型。这会导致性能上限受限,因为教师无法随着学生的进步而改进。 -
选项 B:实时学生副本()。这会导致训练极不稳定,正反馈循环可能放大噪声。 -
选项 C(SDFT 采用):指数移动平均(EMA)。
教师参数 更新规则为:。
EMA 能够平滑高方差的更新,同时确保教师随着学生的能力提升而逐步“进化”,提供更准确的指导。
4. 实验设置
作者在两种具有代表性的持续学习场景下评估了 SDFT:技能学习(Skill Learning)和新知识获取(Knowledge Acquisition)。
4.1 技能学习
目标是在不降低通用能力的前提下,让模型掌握特定的新技能。
-
数据集: -
Science Q&A: 科学推理(SciKnowEval Chemistry L-3)。 -
Tool Use: 工具调用(ToolAlpaca)。 -
Medical: 临床推理(HuatuoGPT-o1)。
-
-
基础模型: Qwen2.5-7B-Instruct。
4.2 新知识获取
目标是将预训练数据中不存在的新事实注入模型。
-
数据集: 构建了一个关于 2025 年自然灾害 的维基百科文章语料库(模型知识截止日期之后)。 -
评估: 生成相关问答对进行测试。 -
严格准确率 (Strict Accuracy): 所有细节均正确。 -
宽容准确率 (Lenient Accuracy): 包含正确信息且无错误陈述。 -
分布外 (OOD) 准确率: 测试间接依赖新知识的问题(而非直接记忆的问题)。
-
4.3 基线对比
-
SFT: 标准监督微调。 -
Re-invoke: SFT 后使用通用提示词进行额外蒸馏以恢复能力。 -
CPT (Continual Pre-Training): 直接在文本语料上进行 Next Token Prediction 训练。 -
DFT: 数据过滤/加权技术。 -
RAG (Oracle): 带有完美检索器的 RAG(作为上限参考)。
5. 实验结果分析
5.1 在线学习带来的泛化性提升
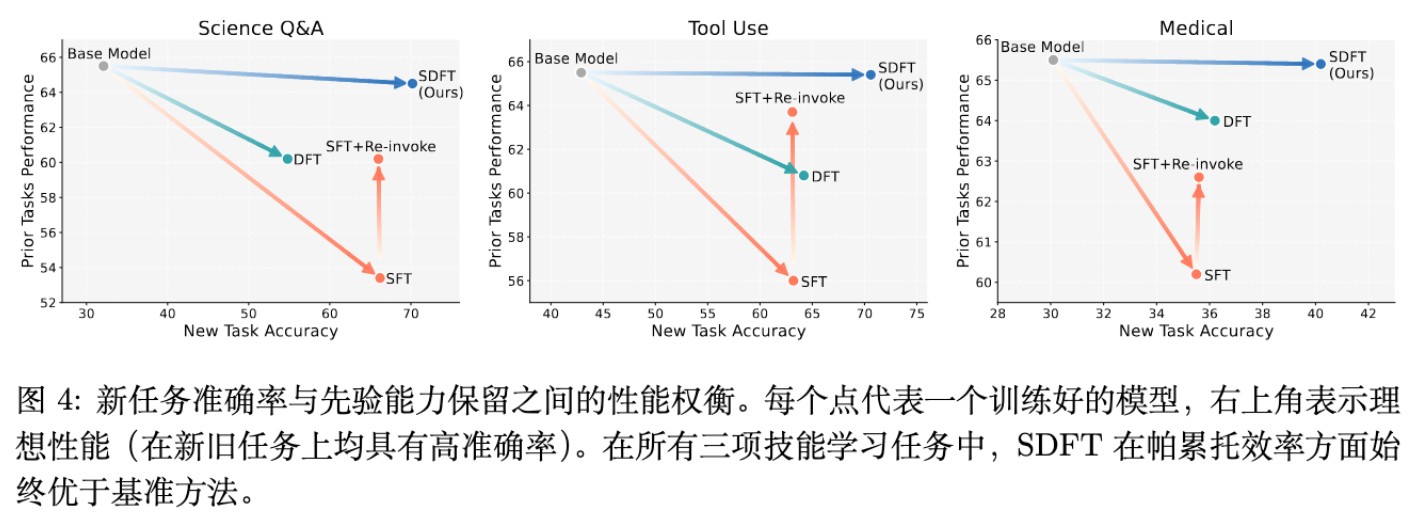
SDFT 在所有任务上的新任务准确率均优于 SFT。
-
分布内(In-Distribution)性能:
在技能学习任务中,SDFT 实现了更高的最终准确率。 -
分布外(Out-of-Distribution)泛化:
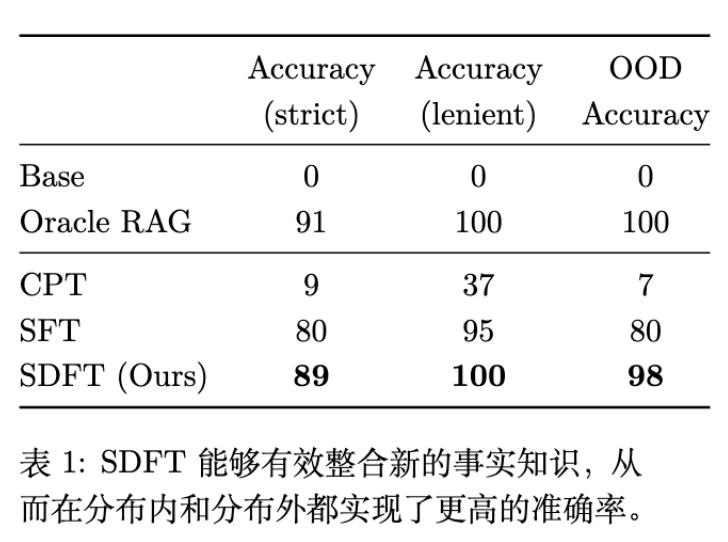
在新知识获取任务中(表 1),SFT 虽然能回答直接相关的问题(Strict 80%),但在 OOD 问题上表现不佳(80%)。相比之下,SDFT 在 OOD 问题上达到了 98% 的准确率,接近 Oracle RAG (100%)。这表明 SDFT 不是在死记硬背答案,而是真正将知识集成到了模型的内部表示中。
5.2 缓解灾难性遗忘
持续学习的核心挑战在于“不遗忘”。实验测量了模型在 HellaSwag, MMLU, GSM8K 等通用基准上的性能变化。
-
单任务微调:SFT 导致通用能力显著下降。例如在 Science Q&A 上,SFT 导致 MMLU 分数下降,而 SDFT 保持甚至略微提升了通用能力。 -
多任务顺序学习:这是最具挑战性的设置。模型按顺序学习任务 A -> B -> C。 -
SFT 现象:呈现“振荡”模式。学习 B 时,A 的性能迅速下降;学习 C 时,A 和 B 的性能均受损。 -
SDFT 现象:表现出稳定的累积学习曲线。在学习后续任务时,先前任务的性能保持稳定,甚至受益于模型的整体微调。
-
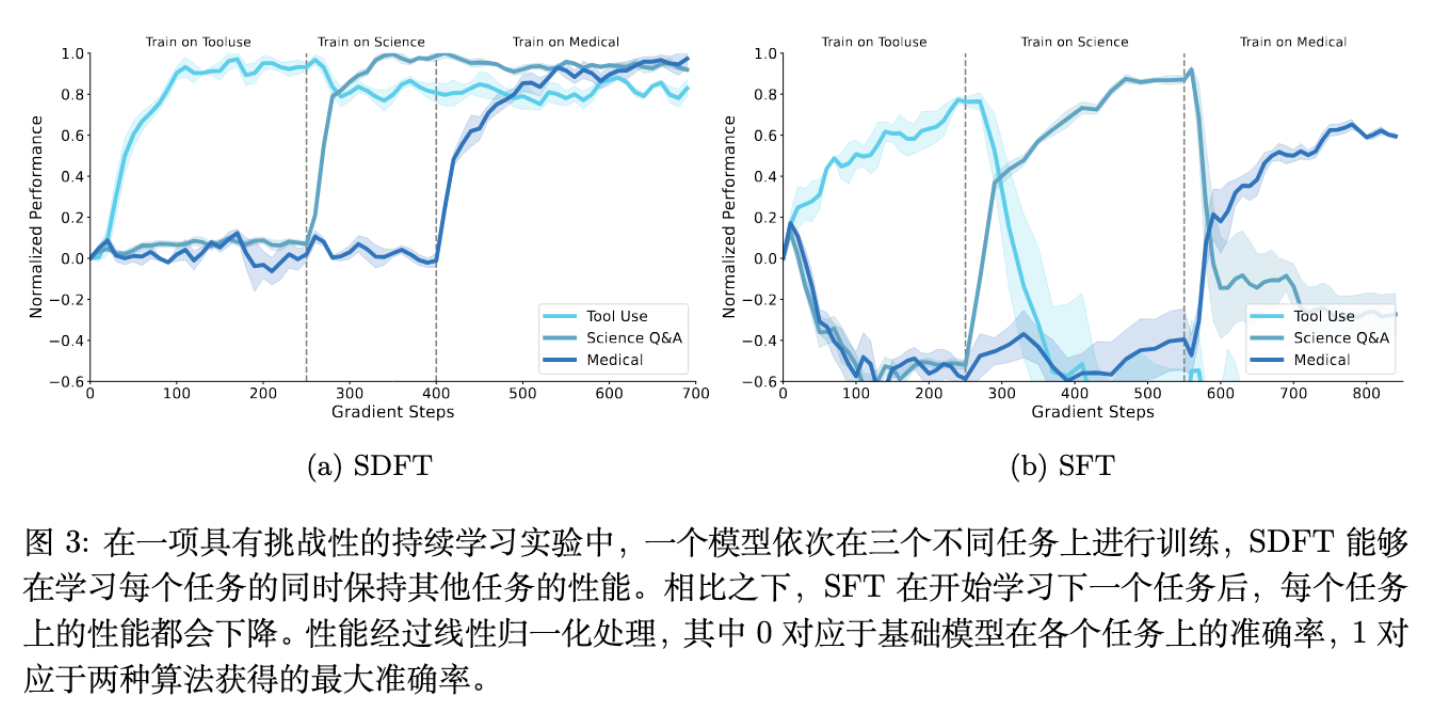
5.3 为什么 SFT 会导致遗忘?
作者通过分析指出,SFT 仅在专家轨迹上训练,导致模型在推理时一旦偏离专家路径,就会进入未定义区域。为了降低 Loss,SFT 强迫模型过度拟合特定路径,这破坏了预训练模型原本鲁棒的参数结构。
SDFT 通过 On-Policy 采样,让模型探索状态空间,并由 Teacher 在这些状态上提供软标签(Soft Labels)。由于 Teacher 基于原模型,其输出分布在整个词表上保留了原模型的大部分知识结构(High Entropy),而不仅仅是 One-hot 的正确答案。这起到了强大的正则化作用。
5.4 推理能力的保留与迁移
一个有趣的实验是关于无思维链(CoT)数据的推理学习。
使用 Olmo-3-7B-Think 模型在医学数据上微调。该数据仅包含最终答案,没有推理过程。
-
SFT 结果:模型为了匹配短答案,丢失了原本的 CoT 能力,生成的 Token 数从 4612 降至 3273,准确率从 31.2% 降至 23.5%。 -
SDFT 结果:尽管演示数据只有答案,但 Teacher(通过 ICL)会在内部生成推理过程(或至少保留推理倾向)。通过蒸馏 Teacher,学生保留了长 CoT 行为(4180 tokens),准确率提升至 43.7%。
结论:SDFT 可以在没有显式推理监督的情况下,利用模型自身的潜能适应新任务,同时避免“推理坍缩”。
6. 消融研究与深入分析
6.1 模型规模的影响
SDFT 依赖于模型的 ICL 能力。ICL 能力通常随模型规模缩放。
实验对比了 Qwen2.5 的 3B, 7B, 14B 版本。
-
3B 模型:ICL 能力较弱,Teacher 信号质量差,SDFT 收益甚微,甚至不如 SFT。 -
7B/14B 模型:随着规模增加,SDFT 相对 SFT 的优势单调递增。这表明 SDFT 是一个不仅 Scale-Friendly,而且 Scale-Demanding 的算法。
6.2 教师上下文的重要性
Teacher 的提示词中包含哪些信息至关重要。以知识获取任务为例:
-
仅包含文本 (Context Only): 准确率 37%。离线蒸馏通常采用此法,效果较差。 -
仅包含答案 (Answer Only): 准确率 75%。 -
文本 + 答案 (Context + Answer): 准确率 89%。
这证明了完整的演示上下文对于构造高质量的 Teacher 分布是必须的。
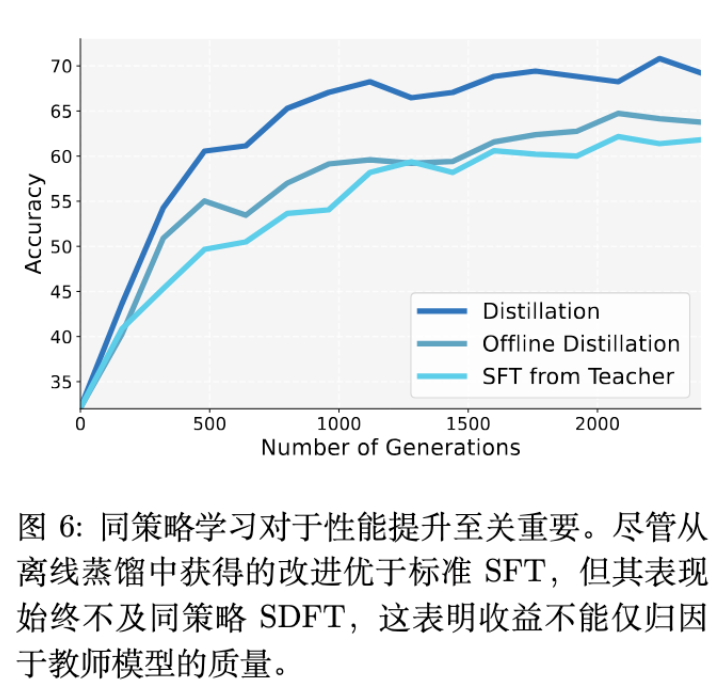
6.3 离线蒸馏 vs 在线蒸馏
为了证明 On-Policy 的必要性,作者比较了 SDFT 与两种变体:
-
Teacher SFT:用 Teacher 生成静态数据,离线微调学生。 -
Offline Distillation:在固定数据集上计算 KL 散度。
结果显示,虽然利用 Teacher 的离线方法优于标准 SFT,但仍显著弱于 On-Policy 的 SDFT。这证实了让学生在自己生成的轨迹上学习(纠正自己的错误)是性能提升的关键来源。
7. 讨论与局限性
7.1 与 On-Policy RL (如 PPO, GRPO) 的关系
SDFT 不是要替代 RL,而是解决 无奖励函数 场景的问题。
-
RL 需要 Reward Model,通过探索优化回报。 -
SDFT 利用 Demonstrations + ICL,通过模拟“更聪明的自己”来优化。
两者可以结合:SDFT 可以作为 RL 的冷启动(Warm-up),提供一个高质量的初始策略,然后接续 RLHF 进一步提升。
7.2 计算开销
SDFT 需要在训练过程中进行采样(Rollout)。
-
成本:相比 SFT,SDFT 的 FLOPs 约为 2.5 倍,wall-clock 约为 4 倍。 -
权衡:考虑到许多持续学习方法(如 Re-invoke)需要多阶段训练,SDFT 在达到同等性能(且不遗忘)的前提下,总成本可能是具有竞争力的。
7.3 潜在的 Artifacts
由于 Teacher 是基于演示的,它可能会生成类似“根据以上文本...”的元语言。SDFT 的学生虽然没有看到演示,但可能会通过蒸馏学会这些口癖。作者采用了一种简单的启发式方法:在计算 Loss 时 Mask 掉前几个 Token,有效缓解了此问题。
7.4 对基础模型的要求
如消融实验所示,SDFT 在小模型(弱 ICL 能力)上无效。它要求基础模型已经具备一定的能力,能够通过 Prompt 被“激发”。对于完全陌生的领域(模型无法通过 ICL 理解),SDFT 可能不如直接的参数更新有效。
8. 结论
Self-Distillation Fine-Tuning (SDFT) 为大模型的持续学习提供了一条切实可行的路径。通过将监督学习问题转化为在线自蒸馏问题,SDFT 成功地在无需显式奖励函数的情况下,利用了在线学习的优势。
核心启示:基础模型本身蕴含的潜在能力(通过 ICL 展现)可以作为其自身进化的最佳监督信号。
更多细节请阅读原文。
往期文章: