
-
论文标题:Exploring Reasoning Reward Model for Agents -
论文链接:https://arxiv.org/pdf/2601.22154v1
TL;DR
今天解读一篇来自 CUHK 与美团联合发布的论文《Exploring Reasoning Reward Model for Agents》。该研究针对现有 Agentic RL(代理强化学习)中普遍存在的稀疏奖励和二元反馈问题,提出了一种新型的代理推理奖励模型(Agent-RRM)。Agent-RRM 不仅输出标量分数,还提供显式的推理轨迹(Reasoning Trace)和文本批评(Textual Critique)。基于此,作者提出了 Reagent 训练框架,特别是 Reagent-U 策略,将基于规则的奖励、基于模型的标量奖励以及文本批评引导的自我修正机制整合到一个统一的强化学习循环中。在 GAIA、WebWalkerQA 等 12 个基准测试中,该方法取得了显著的性能提升,例如在 GAIA 上达到 43.7% 的准确率。
1. 背景
1.1 Agentic RL 的现状与瓶颈
强化学习(RL)在提升大语言模型(LLM)的推理能力方面已取得显著成效,特别是结合可验证奖励(RLVR)的方法(如 DeepSeek-R1 等工作)。受此启发,研究界开始将这一范式扩展到智能体(Agents)领域,使其能够处理动态环境交互和外部知识检索。
然而,现有的 Agentic RL 方法面临一个核心瓶颈:依赖稀疏的、基于结果的奖励(Outcome-based Reward)。
-
稀疏性:在涉及多步工具调用的长视程任务中,中间步骤的质量难以通过最终结果的成败来衡量。 -
二元性:仅凭“正确/错误”的二元反馈,无法区分“完全错误的尝试”与“仅在最后一步失败的高质量推理”。这种粗粒度的监督信号掩盖了中间成功步骤的价值,导致训练效率低下。
1.2 现有奖励模型的局限性
为了提供更细粒度的反馈,研究者尝试引入奖励模型(Reward Models, RMs)。但现有的 RMs 存在两类主要问题:
-
步骤级奖励(Step-level Rewards):虽然提供了细粒度反馈,但标注成本高昂,且容易遭受 Reward Hacking(奖励黑客攻击)。 -
成对偏好模型(Pair-wise Preferences):这类模型通常只输出优劣排名,缺乏对具体错误的诊断能力,也无法提供可操作的改进建议(Actionable Guidance)。此外,它们通常是隐式的数值反馈,缺乏自然语言形式的批评。
1.3 本文的核心切入点
针对上述问题,论文提出了 Agent-RRM,旨在为智能体轨迹提供“推理感知”的反馈。与传统的仅输出标量分数的 RM 不同,Agent-RRM 模拟了人类专家的评估过程,通过显式的推理来论证其评分依据。这种多维度的反馈信号被进一步用于构建 Reagent 训练体系,探索如何有效地利用这些异构信号(文本批评 + 标量分数)来优化智能体策略。
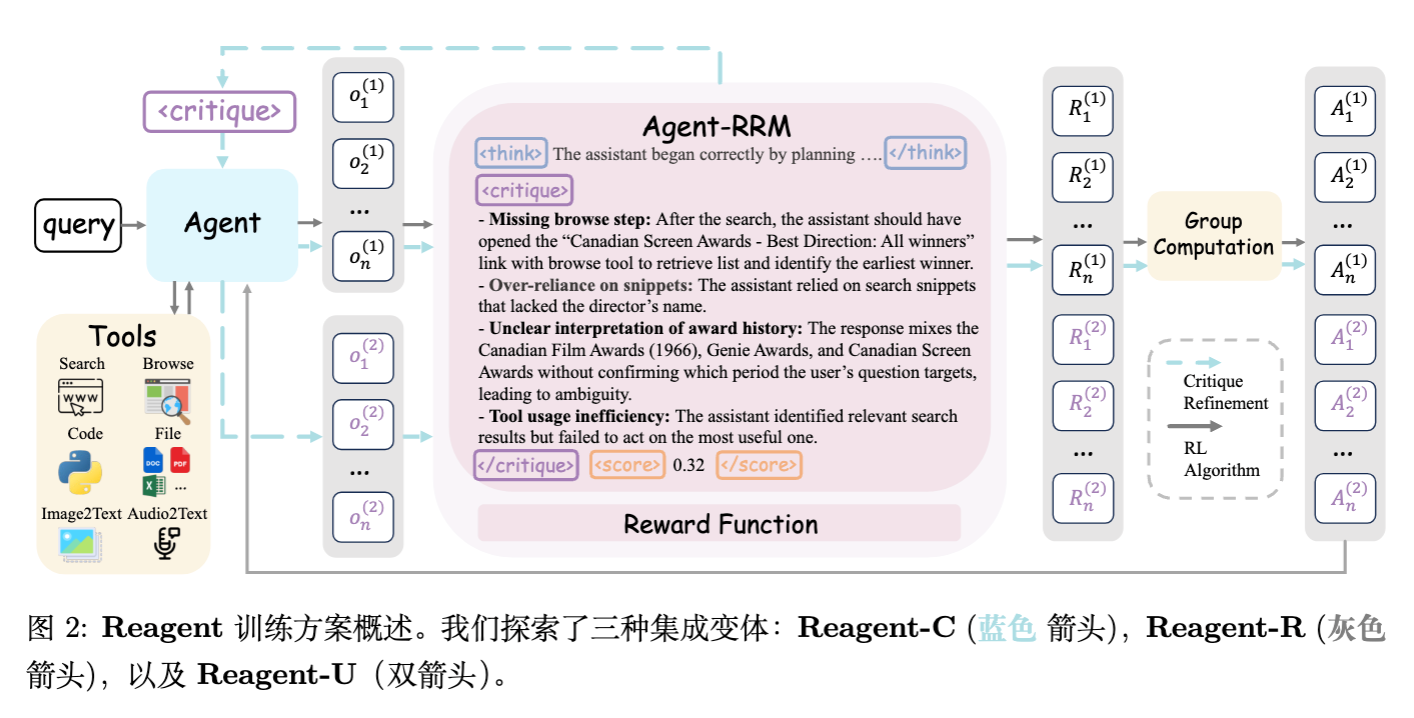
2. Agent-RRM 模型构建
Agent-RRM 是本文的基础组件,它作为一个多面评估器(Multi-faceted Evaluator),被设计用于生成结构化的反馈。
2.1 Agent-RRM 的输出结构
对于每一个智能体生成的轨迹,Agent-RRM 生成包含三个部分的分解判断:
-
<think>(内部推理轨迹):-
分析轨迹的逻辑一致性。 -
评估工具使用的合理性(是否必要、参数是否正确、是否过度依赖)。 -
这一部分为后续的评分和批评提供逻辑支撑,类似于 Chain-of-Thought(CoT),增加了模型判断的透明度。
-
-
<critique>(针对性批评):-
提供具体的、可操作的自然语言反馈。 -
指出具体的逻辑谬误或执行错误(例如:“未验证假设”、“遗漏关键浏览步骤”)。 -
关键约束:批评必须针对过程,严禁泄露正确答案(Ground Truth)。
-
-
<score>(整体质量评分):-
输出一个 区间的标量值。 -
用于量化过程表现,作为强化学习中的稠密奖励信号。
-
2.2 Agent-RRM 的训练数据构建
为了训练 Agent-RRM,作者构建了专门的数据集,涵盖了广泛的逻辑错误模式和响应风格。
-
数据来源:基于 Reagent-RL-709K 数据集(详见第 5 节),从多个模型(Qwen3, Qwen2.5, DeepSeek-V3 等)采样推理轨迹。使用多模型采样的目的是最大化错误模式的覆盖率。 -
标注过程:使用 GPT-OSS-120B 模型对轨迹进行标注,生成上述的三部分结构化判断(think, critique, score)。 -
数据集规模: -
Reagent-RRM-SFT-28K:2.8万条高质量轨迹,用于监督微调(SFT)。 -
Reagent-RRM-RL-90K:9万条实例,用于后续的强化学习优化。
-
2.3 Agent-RRM 的两阶段训练
为了确保 Agent-RRM 的评估能力和校准度,作者采用了两阶段训练流程:
-
监督微调(SFT):
-
在 Reagent-RRM-SFT-28K 上进行训练。 -
目标是让模型掌握结构化的输出格式,并具备基础的评估能力。
-
-
GRPO 强化学习:
-
在 Reagent-RRM-RL-90K 上应用组相对策略优化(GRPO)。 -
目的:进一步细化模型的评估理由,并确保标量奖励的校准(Calibration)。这一步对于让 RM 生成高保真、自洽的反馈至关重要,使其在没有标准答案的开放式任务中也能有效工作。
-
3. Reagent 智能体训练框架
在拥有了强力的 Agent-RRM 后,论文探讨了三种将其反馈集成到智能体策略 中的范式。
3.1 基础设置:智能体工具与 SFT
-
基座模型:Qwen3-8B。 -
工具集:配备了 6 种专用工具,包括 Search(搜索)、Web Browse(网页浏览)、Code Interpreter(代码执行)、File Reader(文件读取)、Image Descriptor(图像描述)、Audio Converter(音频转文本)。 -
Cold Start:首先在 Reagent-SFT-55.6K 数据集上进行 SFT,得到基础策略 。这一步确保智能体具备基本的推理和工具调用能力。
3.2 策略一:文本增强修正(Reagent-C)
Reagent-C (Text-augmented Refinement) 侧重于利用 <critique> 进行推理时(Inference-time)的修正,本身不涉及参数更新(或者说是一个不需要训练的基线策略变体,但在 Reagent-U 中作为训练的一部分)。
-
流程: -
智能体生成初始响应 。 -
Agent-RRM 分析 并生成批评 。 -
智能体基于原始问题和批评,生成修正后的响应 。
-
-
特点:策略 保持冻结,主要评估智能体的上下文修正能力(In-context Refinement)。
3.3 策略二:奖励增强引导(Reagent-R)
Reagent-R (Reward-augmented Guidance) 侧重于利用 <score> 解决奖励稀疏问题。
-
奖励函数设计:
其中, 是基于最终答案正确性的规则奖励(通常为 0 或 1), 是 Agent-RRM 给出的标量分数, 是平衡系数。 -
优势:通过引入基于模型的稠密奖励,智能体即使在答案错误时也能因逻辑正确的部分获得正反馈,反之亦然。这有助于智能体区分“有价值的失败”和“无意义的胡言乱语”。
3.4 策略三:统一反馈集成(Reagent-U)
Reagent-U (Unified Feedback Integration) 是本文的核心贡献,它将上述两种模态(文本批评和标量奖励)融合到一个统一的 RL 优化循环中。
3.4.1 两阶段采样机制
对于每个查询 ,智能体执行两阶段采样:
-
初始尝试:。 -
批评引导的修正:Agent-RRM 对 生成批评 ,智能体据此生成 。
3.4.2 统一奖励池与优势计算
作者将两个阶段产生的所有轨迹汇入一个统一的池子:
对池中所有样本计算组合奖励 (公式同 Reagent-R)。关键点在于,优势(Advantage)是在这个统一池中归一化的:
设计意图:通过跨阶段归一化,如果 (修正后)的质量显著高于 ,它将获得更高的优势值。这隐式地鼓励了智能体不仅要优化初始生成的质量,还要学习如何利用批评进行有效的自我修正。
3.4.3 优化目标
Reagent-U 的 GRPO 目标函数如下:
其中,KL 散度 是相对于各自的上下文计算的。
注意:在推理阶段(测试时),Reagent-U 作为一个标准的智能体运行,不需要 Agent-RRM 的介入,也不需要执行两步修正。这意味着 Reagent-U 成功地将批评带来的改进能力“内化”(Internalize)到了模型参数中。
4. 实验
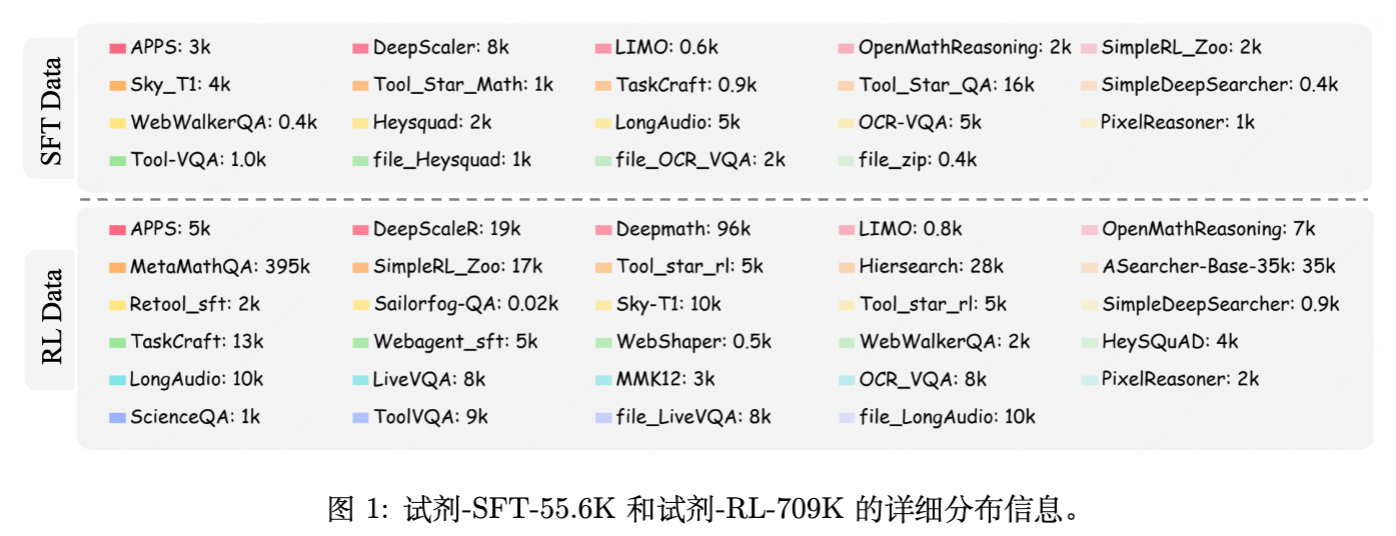
4.1 数据集构建
高质量的数据是 Agentic RL 成功的基石。作者构建了以下数据集:
-
Reagent-RL-709K:
-
规模:70.9万个问答对。 -
来源:整合了多种公开数据集,经过严格过滤。 -
过滤流水线: -
剔除答案有歧义的样本(Ambiguous Ground Truths)。 -
跨源去重(Cross-source Deduplication)。 -
难度感知采样(Difficulty-aware Sampling),保留中高难度样本,减少简单样本。
-
-
-
Reagent-SFT-55.6K:
-
用途:冷启动 SFT。 -
构建方法:从 RL 数据集中随机选取 100k 数据,使用 DeepSeek-V3 采集包含 6 种工具调用的解题轨迹。仅保留最终答案正确的轨迹,最终筛选出 5.56万条。 -
数据分布: -
DeepMath(数学推导):移除多解不一致的样本。 -
DeepScaleR:移除解答与 GT 不一致的样本。 -
SimpleRL-Zoo:降采样简单题。 -
MMK12/PixelReasoner/LiveVQA:多模态理解任务。 -
ToolVQA:筛选适配当前工具集的样本。 -
AFM-WebAgent/LongAudio:复杂的代理交互与长音频处理。
-
-
4.2 实验基准
评估涵盖了 12 个多样化的基准测试,分为三类:
-
数学推理:AIME24, AIME25, GSM8K, MATH500。 -
知识密集型推理:HotpotQA, 2Wiki, Bamboogle, MuSiQue。 -
通用代理与搜索推理:GAIA, WebWalkerQA, Humanity's Last Exam (HLE), xbench。
其中,GAIA 和 WebWalkerQA 是最具挑战性的代理任务,涉及多步规划和工具使用。
4.3 训练超参数
-
硬件:8 张 NVIDIA A800-80G GPU。 -
Batch Size:32 (SFT & RL)。 -
Learning Rate:SFT 为 ,RL 为 。 -
GRPO 参数:(Reagent-R/U 中的模型奖励权重)。 -
Rollout Samples:。
5. 实验结果与分析
5.1 综合性能表现
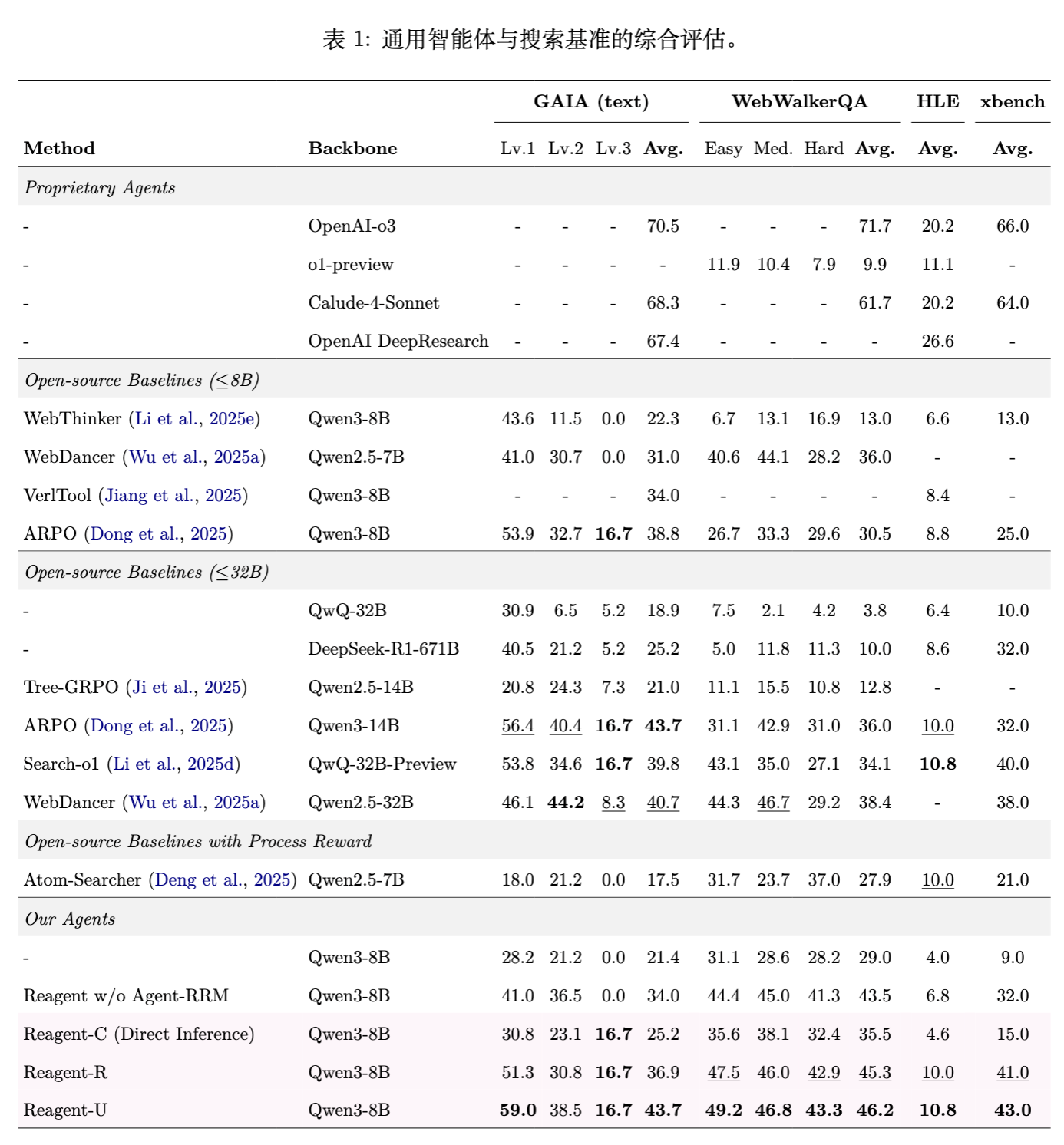
实验结果表明,Reagent-U 在绝大多数基准上都取得了最优性能。
-
GAIA (text) :Reagent-U 达到 43.7% 的平均准确率,显著优于 Qwen3-8B 基线(21.4%)和 WebThinker(22.3%),甚至超过了参数量更大的 ARPO (Qwen3-14B)。 -
WebWalkerQA:达到 46.2% ,优于 WebDancer (36.0%)。 -
HLE (Humanity's Last Exam) :这是一个极高难度的基准,Reagent-U 取得了 10.8% 的成绩,与 Search-o1 (10.8%) 持平,优于大多数开源基线。
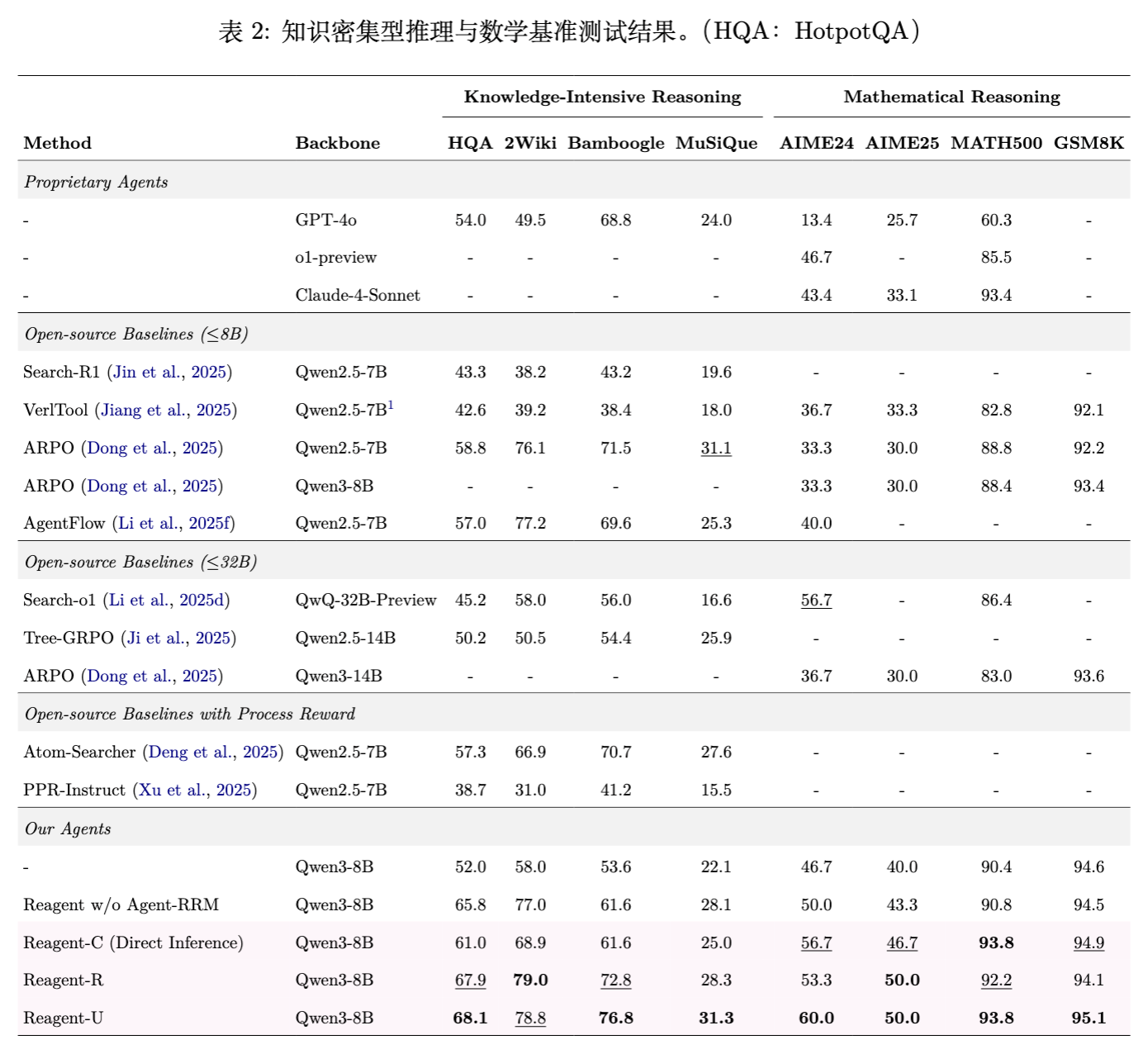
在数学和知识密集型任务上,Reagent-U 同样表现出色,例如在 GSM8K 上达到 95.1%,在 HotpotQA 上达到 68.1%。
5.2 核心消融研究
作者对比了 Reagent-C、Reagent-R 和 Reagent-U 的表现,得出以下关键结论:
-
Reagent-C (文本批评) 的有效性:
-
仅通过推理时的上下文修正(无参数更新),Reagent-C 就在所有基准上提升了性能。 -
例如在 GAIA 上从 21.4% 提升至 25.2%。这证明了 Agent-RRM 生成的批评具有具体的指导意义,能帮助智能体纠正逻辑谬误。
-
-
Reagent-R (模型奖励) 的必要性:
-
Reagent-R 相比 Reagent-C 有了大幅提升(GAIA 36.9%)。 -
这表明将评价信号整合到模型参数中(通过 RL)比仅在上下文中提供指导更有效。模型奖励缓解了稀疏奖励问题,为探索提供了更平滑的梯度。
-
-
Reagent-U (统一集成) 的优越性:
-
Reagent-U 结合了前两者的优势,实现了性能的进一步飞跃(GAIA 43.7%)。 -
分析:通过在训练中引入“生成-批评-修正”的循环,并统一计算优势,智能体学会了更稳健的推理模式。虽然推理时不再使用批评,但这种训练机制迫使模型内部化了自我反思和修正的能力。
-
5.3 跨模态与复杂工具使用分析
为了验证模型是否仅仅过拟合了文本搜索任务,作者在 GAIA Full Set(包含多模态任务)上进行了测试。
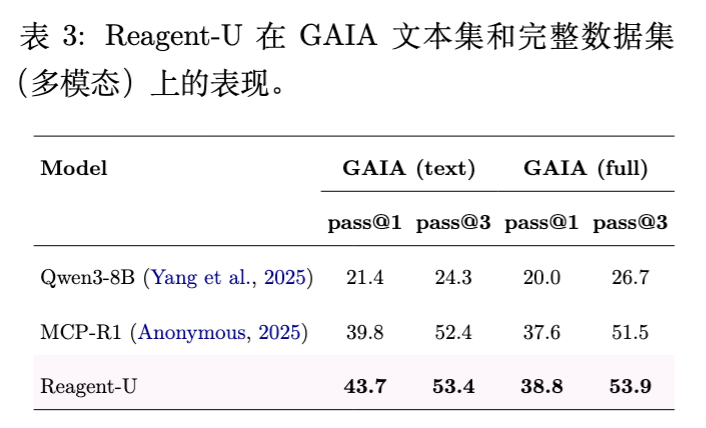
结果显示,Reagent-U 在 GAIA (full) 上依然保持了相对于基线的显著优势(38.8% vs Qwen3-8B 的 20.0%)。这说明 Agent-RRM 提供的通用推理反馈能够泛化到涉及图像理解、代码执行等复杂工具调用的任务中。
5.4 参数 的敏感性分析
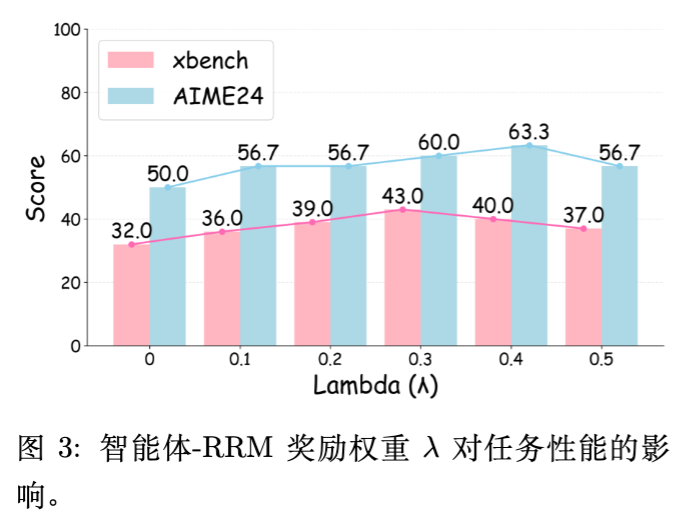
作者探究了模型奖励权重 对性能的影响。
-
当 从 0 增加到 0.3 时,性能稳步提升。 -
在 区间内性能达到平台期。 -
过大的 (如 0.5)导致性能轻微下降。 -
结论:适度的推理反馈提供了必要的监督信号,但如果权重过高,可能会导致模型过度关注中间步骤的“讨好”奖励模型,而牺牲了最终任务的完成度。因此,平衡规则奖励(结果)和模型奖励(过程)至关重要。
6. 案例研究
为了直观展示 Agent-RRM 的作用,论文提供了两个详细的案例(Case Study)。
案例 1:GAIA 搜索任务
问题:根据 Phys.org 的一篇文章找到某次灾难的爆炸当量,然后在不列颠百科全书(Britannica)中找到具有相同当量的美国核试验名称。
-
第一次尝试: -
智能体通过搜索发现 Tunguska 事件当量为 3-5 百万吨。 -
错误:智能体没有使用 Browse 工具打开 Britannica 页面进行验证,而是直接假设当量为 5 百万吨,并以此搜索美国核试验,最终错误地选择了 "Cannikin"。
-
-
Agent-RRM 的批评: -
"Missing essential tool call"(缺少关键工具调用):指出从未打开 Britannica 页面。 -
"Unverified assumptions"(未验证的假设):指出直接推断 5 百万吨是不严谨的。 -
"Ambiguous test selection"(模糊的选择):指出在多个候选中随意选择了 Cannikin。
-
-
第二次尝试: -
智能体接受批评,使用了 browse工具访问 Britannica。 -
确认当量高达 15 百万吨(而非之前的 5 百万吨)。 -
根据 15 百万吨的线索,正确找到了 "Castle Bravo" 核试验。
-
案例 2:GSM8K 数学任务
问题:计算每位油漆工的工作小时数。
-
第一次尝试: -
智能体编写了 Python 代码计算结果。 -
错误:代码中缺少 print语句,导致工具返回无输出。智能体虽然在<think>中算出了正确答案,但在工具调用上是无效的。
-
-
Agent-RRM 的批评: -
指出 Python 调用未包含 print,导致无输出,浪费了一次调用机会。
-
-
第二次尝试: -
智能体修正了思考过程,甚至直接通过逻辑推导给出了完整步骤,避开了不必要的工具错误,或者正确修正了代码(案例中展示了更清晰的思维链)。
-
这两个案例清晰地证明了 Agent-RRM 生成的批评具有高度的诊断性(Diagnostic)和纠错性(Corrective)。
7. 深入讨论与技术洞察
7.1 为什么 Reagent-U 优于 Reagent-R?
虽然 Reagent-R 已经引入了稠密奖励,但 Reagent-U 的优势在于数据效率和策略鲁棒性。
-
样本利用率:Reagent-U 利用了 (原始)和 (修正)两种轨迹。 通常质量更高,为策略优化提供了正向的引导样本;而 如果质量差,在归一化优势计算中会作为负样本被抑制。 -
隐式思维链优化:通过奖励机制鼓励模型生成类似于 的轨迹,实际上是在训练模型模仿“经过深思熟虑和自我修正后”的行为模式。
7.2 文本批评与标量奖励的互补性
-
标量奖励提供了全局的优化方向(梯度),适合大规模 RL 训练,解决“往哪里走”的问题。 -
文本批评提供了局部的、结构化的错误信息,解决了“具体哪里错了”的问题。 -
将两者结合,实际上是在模拟人类学习的过程:既有考试分数的压力(Scalar),又有老师具体的评语指导(Critique)。
7.3 局限性与未来方向
论文坦诚地讨论了局限性:
-
模型规模:目前实验主要基于 8B 模型。更大参数的模型(如 70B+)在处理长视程任务时可能表现出不同的缩放行为(Scaling Laws)。 -
工具集的局限:目前的工具集虽然涵盖了多模态,但相对标准化。面向开放世界(如 OS 操作、科学实验)的工具交互可能需要更复杂的 RM。 -
计算开销:训练 RM 和在 RL 中生成批评都需要额外的推理计算量。
更多细节请阅读原文。
往期文章:


