
-
论文标题:Motif-2-12.7B-Reasoning: A Practitioner’s Guide to RL Training Recipes -
论文链接:https://arxiv.org/pdf/2512.11463
TL;DR
今天解读一篇 Motif Technologies 近日发布的论文《Motif-2-12.7B-Reasoning: A Practitioner’s Guide to RL Training Recipes》。该工作介绍了一个 12.7B 参数的推理模型,旨在通过系统、数据和算法的全方位优化,在复杂推理和长上下文理解方面缩小开放权重模型与私有前沿模型之间的差距。
论文的核心贡献在于公开了一套可复现的训练配方,主要包括:
-
系统层:支持 64K 上下文的高效混合并行架构与 Liger Kernel 内存优化。 -
SFT 层:基于课程学习(Curriculum Learning)和分布对齐(Distribution Alignment)的两阶段微调策略,强调了合成数据推理模式与学生模型能力的匹配性。 -
RL 层:基于 GRPO 的强化学习微调(RLFT)流水线,通过难度感知的数据过滤和混合策略轨迹复用(Mixed-Policy Trajectory Reuse)解决训练稳定性问题。
1. 引言
随着大语言模型(LLM)的发展,尽管通用指令遵循能力取得了显著进展,但鲁棒的复杂推理和长上下文理解仍然是主要挑战。测试时扩展(Test-time scaling)——即通过更长的思维链(CoT)、多步推演或多样本推理来分配更多的推理计算量——已被证明能显著提升模型在数学、代码及 Agent 决策任务上的表现。
然而,训练具备这种推理能力的模型目前主要由少数闭源机构掌握。关于如何扩展强化学习微调(RLFT)、在长视野(Long Horizon)任务中稳定训练以及处理长上下文负载的实用配方,社区中鲜有详细文档。实践者常发现,简单地将 RLFT 应用于 SFT 模型往往会导致模型坍塌或在推理基准上性能退化。
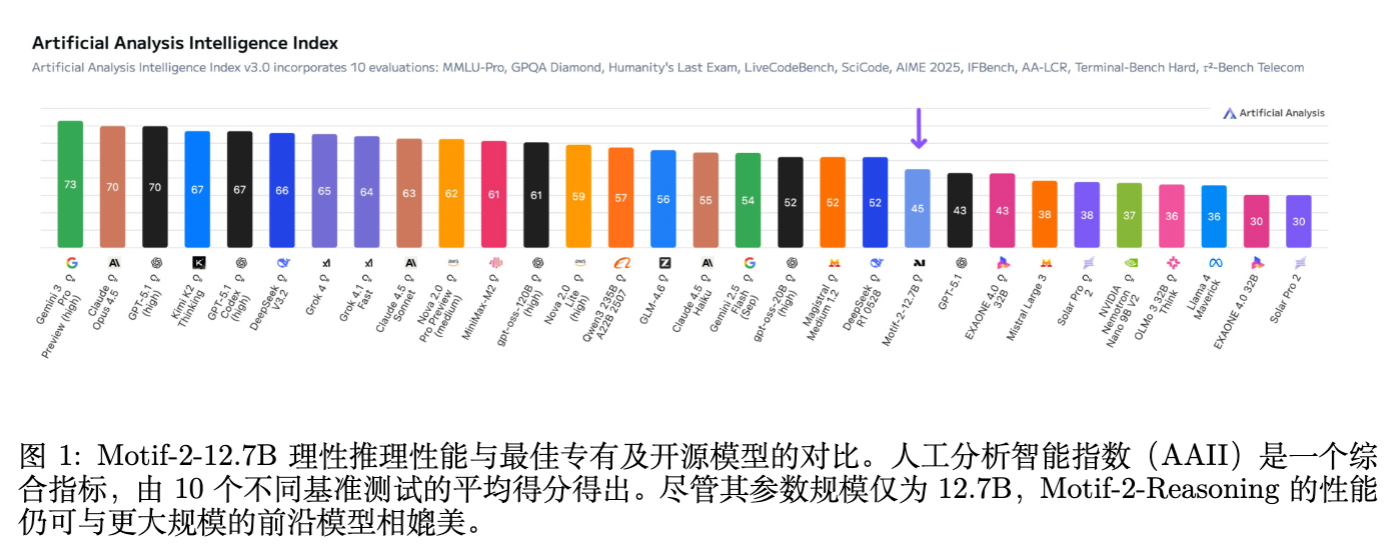
Motif-2-12.7B-Reasoning 的提出旨在解决上述问题。该模型基于 Motif-2-12.7B-Instruct,通过分布对齐的 SFT 和工程化的 RLFT 流水线训练而成。尽管参数量仅为 12.7B,其实验结果显示在多项推理基准上与 30B-40B 参数量的模型相当。本文将详细拆解其训练过程中的关键技术决策、失败教训及最终方案。
2. 系统优化
为了支持长上下文推理训练,Motif 团队构建了针对 64K token 长度的训练基础设施。这一长度对于容纳详细的思维链和多步推理至关重要,但也带来了巨大的显存压力。
2.1 长上下文推理 SFT 的混合并行策略
SFT 阶段将上下文扩展至 64K,这需要超出预训练阶段的并行策略。论文采用了一种节点内与节点间相结合的混合并行方案:
-
节点内 (Intra-node) :采用 DeepSpeed-Ulysses 序列并行(Sequence Parallelism, SP)结合数据并行(Data Parallelism, DP-shard)。DeepSpeed-Ulysses 通过对 Query、Key、Value 进行切分并在 Attention 计算前进行 All-to-All 通信,实现了高效的序列级并行。 -
节点间 (Inter-node) :采用数据并行参数复制(DP-replicate)。
具体到网络层级的处理:
-
Attention 层:使用张量并行(Tensor Parallelism, TP)处理。 -
前馈网络 (FFN) :在序列并行(SP)下运行。由于使用 SP 的 FFN 可以在 SP 组内进行权重分片(Weight Sharding),系统构建了一个合并的 Mesh(网格),将节点内的 DP-shard Mesh 与 SP Mesh 结合来分片 FFN 参数。
由于基础模型使用的 Parallel Muon 优化器设计上支持任意梯度的参数放置配置,因此在混合并行化过程中无需对优化器进行额外修改。
2.2 细粒度激活重计算
在长上下文训练中,激活值(Activations)占用了大量显存。传统的激活重计算(Activation Checkpointing/Recomputation)通常以 Transformer 块(Block)为粒度,即重新计算整个 Decoder Block。
为了在 H100 GPU 上支持 64K 长度训练,论文采取了更精细的策略:
-
分析:不再统一重计算每个模块,而是分析每个 Decoder Block 内各层的激活占用与重计算成本。 -
策略:手动调整了选择性重计算策略(Selective Recomputation Policy)。该策略旨在最小化峰值显存使用,同时避免不必要的计算开销。
2.3 针对 RL 的 Liger Kernel 内存优化
强化学习(RL)训练阶段对显存的需求显著高于 SFT,原因在于需要同时在显存中保留策略模型(Policy Model)、参考模型(Reference Model)以及可能的价值网络状态。尽管 vLLM 等推理引擎支持 Sleep Mode,但这并不能完全消除显存占用。
通过分析 RL 训练的内存使用模式,研究人员发现峰值消耗发生在损失函数前向传播之后、反向传播开始之时。此时,前向计算产生的所有 Checkpoint 激活值仍驻留于内存中。特别地,Logit 激活值的形状为 (context_length, vocabulary_size),远大于形状为 (context_length, hidden_size) 的常规激活值。LM Head 和 Loss 计算贡献了显著的内存占用。
解决方案:采用 Liger Kernel 的损失函数实现。
Liger Kernel 通过沿上下文长度维度划分激活值,在每个分片(Shard)上独立计算 LM Head 的线性层、损失和梯度。这种方法有效避免了在显存中实例化完整的巨大 Logit 张量,从而大幅降低了显存压力。
3. Reasoning SFT
论文提出了一个专注于推理的监督微调阶段,旨在增强多步推理能力、强化长上下文一致性,并将模型与复杂的指令遵循能力对齐。早期实验表明,推理能力对数据集的构成、推理深度以及推理模式的匹配度高度敏感。
SFT 过程被设计为两个核心维度:(1)基于课程(Curriculum)的长上下文适应;(2)分布对齐(Distribution-aligned)的合成推理数据生成。
3.1 失败的教训
在确定最终配方前,研究团队总结了两条关键的失败教训。
教训 1:各阶段静态数据集分布是次优的
在整个 SFT 过程中保持静态、均匀的数据分布会导致模型过早收敛,阻碍推理能力的扩展,甚至引发灾难性遗忘。
-
结论:必须采用动态的数据分布策略。
教训 2:分布失配问题 (The Distribution Mismatch Problem)
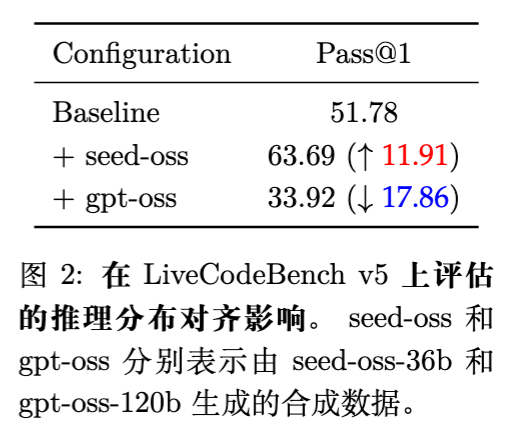
合成数据的质量不仅仅取决于“正确性”,推理分布的“对齐”至关重要。论文通过实验对比了使用不同强度的教师模型生成数据对学生模型的影响:
-
基线 (Baseline) :LiveCodeBench v5 Pass@1 为 51.78。 -
Seed-OSS (36B) :使用 36B 模型生成数据进行微调,Pass@1 提升至 63.69。 -
GPT-OSS (120B) :使用 120B 模型生成数据进行微调,Pass@1 跌至 33.92。
-
分析:GPT-OSS (120B) 导致的性能退化源于“复杂性失配”。教师模型的推理轨迹可能展示了学生模型(12.7B)难以内化的粒度和结构复杂性。这种差异造成了分布失配,即强加的推理模式与模型的内在学习过程冲突,而非增强它。 -
结论:合成监督信号应当来自与目标模型容量相兼容的源头。
3.2 SFT 训练配方
基于上述教训,论文确立了包含数据生成流水线和课程学习计划的 SFT 配方。
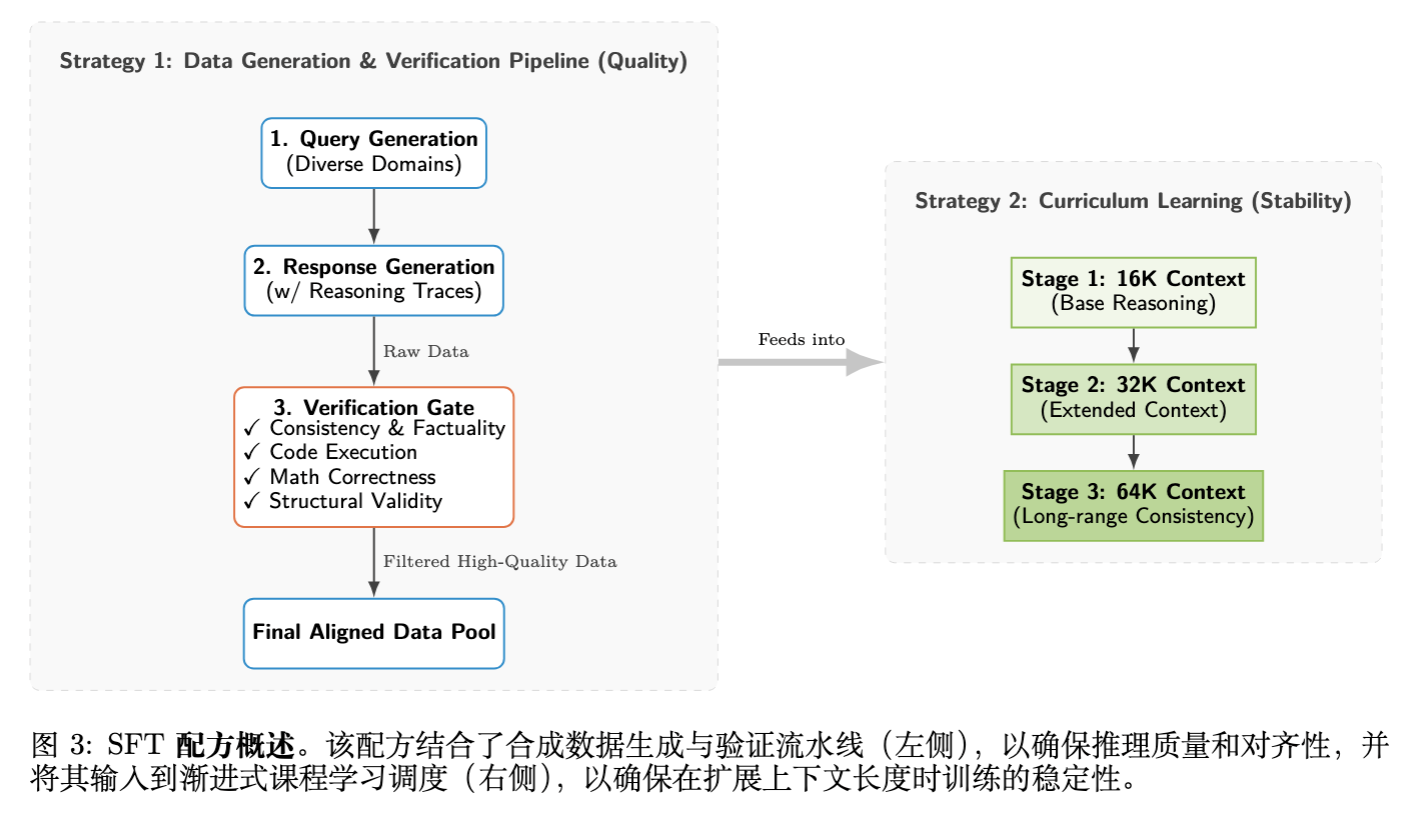
策略 1:合成数据生成(注入推理信号)
为了注入强推理信号,团队构建了包含“查询生成 响应生成 验证”的多阶段流水线。
验证门控 (Verification Gate) 是保持高数据保真度的关键,包含自动化检查:
-
一致性与事实性:验证语义对齐。 -
代码执行:运行基于执行的测试以确保功能正确性。 -
数学正确性:验证最终答案准确性。 -
结构有效性:确保推理轨迹保持逻辑连贯的结构。
策略 2:课程学习(渐进式上下文扩展)
为了避免突兀地暴露于极长序列导致的不稳定,SFT 被划分为两个战略阶段:
阶段 1:推理基础 (Reasoning Foundation)
-
目标:建立代码、数学、STEM 和工具使用领域的综合能力。 -
上下文:16K-32K token。 -
数据构建: -
源自 Nemotron、OpenReasoning、Mixture-of-Thoughts 等。 -
严格过滤:例如在处理 rstar-coder数据集时,基于实证观察,仅选择通过次数在中间范围()的问题,剔除琐碎(trivial)和无法解决(unsolvable)的样本。仅保留验证通过且执行成功的轨迹。
-
-
作用:作为稳定器,确立通用推理能力。
阶段 2:深度推理专业化 (Deep Reasoning Specialization)
-
目标:针对复杂的推断缺口(Inferential Gaps)。 -
上下文:扩展至 64K token。 -
数据构建:注入高粒度的合成数据,包括 CoT 密集型数据和基于失败驱动的修正集(Failure-driven correction sets)。重要的是,重新生成这些样本的推理轨迹,以强制结构上与目标模型的推理分布对齐。 -
作用:使模型能够在长序列上维持连贯推理。
4. Reasoning RL
论文详细介绍了一个鲁棒的强化学习微调(RLFT)流水线。这是将 SFT 模型推向高性能的关键步骤。
4.1 背景:GRPO 与 GSPO
采用 Group Relative Policy Optimization (GRPO) 算法。GRPO 是一种无需 Critic 网络(Critic-free)的 PPO 变体,专为推理任务设计。
-
优势:不依赖独立的价值函数,通过从一组采样输出的统计数据直接估计基线(Baseline),减少了计算开销。 -
目标函数:
其中 是组内标准化后的优势(Advantage)。 -
GSPO:论文指出实际使用了 Group Sequence Policy Optimization (GSPO) 的形式,采用了序列级的 Importance Ratio 公式。
4.2 RL 训练的失败教训
教训 1:代理模型(Proxy Models)上的超参微调无效
试图在较小的预训练检查点(代理模型)上优化 RL 配方,然后迁移到全量 SFT 模型是不可行的。
-
观察:在代理模型上获得 18% 性能提升的配方,应用到 SFT 模型上导致停滞或退化。 -
原因:SFT 后最优策略更新动力学发生了显著偏移,必须直接在目标模型上微调。
教训 2:奖励整形对不可解析轨迹的影响
当模型输出无法被解析(Format Errors)时,简单的惩罚(如长度惩罚)会导致非零优势(Non-zero Advantage)。
-
后果:引入噪声,策略可能被激励去优化辅助约束而非推理逻辑。 -
方案:必须严格 Mask 掉不可解析的实例,使其不贡献梯度。
教训 3:难度对齐以防止梯度消失
RLFT 对训练数据相对于模型能力的难度分布高度敏感。
-
机制:根据公式 (1),优势 源于组内相对表现。如果问题太简单(全对)或太难(全错),组内奖励方差坍塌,导致 。 -
后果:梯度消失,采样计算被浪费。 -
结论:必须构建良构数据集,使模型在组内部分成功、部分失败。
教训 4:混合策略训练解决计算瓶颈
RLFT 的瓶颈在于生成(Rollout),而非更新。On-policy 训练方差大且昂贵。
4.3 RL 训练配方
为了解决上述问题,论文提出了一套包含数据过滤和训练策略的完整方案。
数据过滤流水线:LLM-as-a-data-filtering
为了解决梯度消失问题,论文构建了基于模型自身能力的数据过滤机制。
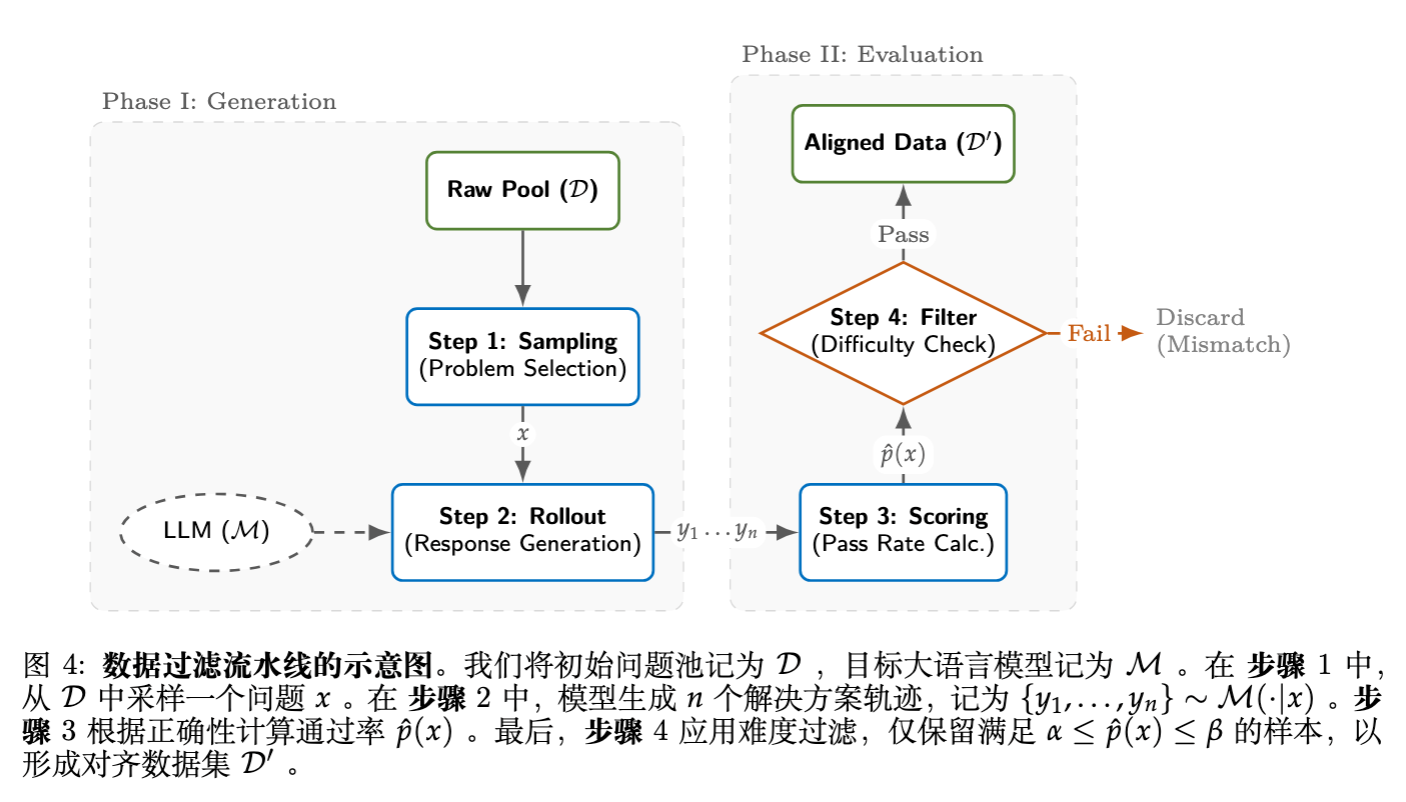
假设初始问题池为 ,目标模型为 。
-
采样:对每个问题 ,生成 个解答轨迹 。 -
评分:计算经验通过率(Empirical Pass Rate):
-
过滤:严格保留通过率在目标区间 内的问题:
这种方法确保了数据集难度与模型当前能力完美对齐。具体设置如下:
-
数学推理:源自 GURU-92K。先用 Qwen-30B 分数初步过滤,再应用上述流水线选择难度带 的实例。针对组合数学占比过高(50%)的问题,进行了分层采样以平衡数论、代数、几何的分布。 -
代码生成:类似数学,源自 GURU-92K,通过率过滤。 -
指令遵循:合成数据集。为了挑战模型,设置了更严格的上限 ,仅保留通过率在 的困难样本。
训练策略优化
扩大裁剪范围 (Expanding Clipping Range)
为了加速收敛,使用了比标准设置更宽松的裁剪范围 。这允许策略在出现高优势信号时更显著地偏离参考模型,在训练效率和防止坍塌之间取得平衡。
鼓励长上下文推理
观察发现,长上下文推理能力对有效 RL 微调至关重要。
-
决策:完全移除了奖励公式中的长度惩罚(Length Penalty)。 -
设施:配置服务基础设施以最大化 vLLM 的生成长度。
基于混合策略的轨迹复用 (Efficiency via Mixed-Policy Trajectory Reuse)
为了缓解 Rollout 的计算瓶颈,论文提出在多次梯度更新步骤中复用同一批轨迹。
具体流程:
在外部迭代 ,从当前策略采样一批轨迹 。
随后,在固定批次上执行 步梯度更新:
其中 ,下一次迭代参数 。
-
理论视角:过程始于 On-policy 采样。随着 逐渐偏离行为策略 (而轨迹 保持不变),训练逐渐过渡到 Off-policy 区域。 -
参数 :作为控制混合 On/Off-policy 动态的旋钮。相比标准的迭代 GRPO,这种策略在最大化效率的同时提供了更稳定的优化。
通过多任务 RL 缓解任务退化
单领域 RL 训练常导致其他领域性能退化(例如,只优化指令遵循会损害数学能力)。
-
方案:采用多任务 RLFT 框架,在同一循环中联合训练所有目标领域(数学、代码、IFBench)。每个 Mini-batch 混合这三类任务,使用特定任务奖励更新共享策略。这起到了正则化作用,防止灾难性遗忘。
更多细节请阅读原论文。
往期文章:


