
-
论文标题:On the Superimposed Noise Accumulation Problem in Sequential Knowledge Editing of Large Language Models -
论文链接:https://arxiv.org/pdf/2505.07899
TL;DR
大型语言模型(LLM)在顺序知识编辑(Sequential Knowledge Editing)场景下面临的性能衰退问题,本论文作者发现随着编辑次数的增加,模型输出会逐渐偏离目标,这种现象被定义为“叠加噪声累积问题”(Superimposed Noise Accumulation Problem)。理论分析表明,该噪声源于无关知识的错误激活以及新旧编辑参数之间的冲突。
为了解决这一问题,作者提出了一种名为 DeltaEdit 的新方法。该方法将更新参数分解为“影响向量”(Influence Vector)和“激活向量”(Activation Vector),并通过动态正交约束策略(Dynamic Orthogonal Constraint Strategy)来优化影响向量,从而在保持编辑效率的同时减少参数间的冲突。
实验结果显示,在 Llama3-8B 模型上进行 3000 次顺序编辑后,DeltaEdit 在编辑性能上相比最强基线(AlphaEdit)提升了 16.8%,并显著缓解了模型崩溃现象,更好地保留了模型的通用能力。
1. 引言
随着大型语言模型(LLM)在各个领域的广泛应用,如何保持模型知识的时效性和准确性成为了一个关键问题。虽然预训练赋予了模型海量的知识,但世界是动态变化的,模型内部的知识可能会过时或出现错误。传统的微调(Fine-tuning)方法虽然可行,但计算成本高昂,且容易导致灾难性遗忘(Catastrophic Forgetting)。
知识编辑(Knowledge Editing)作为一种高效的替代方案,旨在通过定位并修改模型中的特定参数,精确更新知识而不影响其他无关知识。现有的主流方法,如 ROME 和 MEMIT,采用“定位-编辑”(Locate-then-Edit)范式,在单次编辑任务中表现出色。
然而,实际应用往往要求模型能够连续处理一系列的知识更新,即顺序知识编辑(Sequential Knowledge Editing)。研究表明,简单地将单次编辑方法扩展到顺序场景会导致严重的性能下降。随着编辑次数的增加,模型的编辑成功率降低,甚至出现模型崩溃。
论文针对这一现象进行了全面的理论和实验调查。作者发现,现有的顺序编辑研究主要关注优化“激活向量”以减少错误激活,却往往忽视了“影响向量”之间的重叠与冲突。本文提出 DeltaEdit,通过数学上的正交投影技术,显式地控制叠加噪声的累积。
2. 预备知识与问题定义
在深入探讨 DeltaEdit 之前,我们需要对自回归语言模型及知识编辑的数学形式进行回顾。
2.1 自回归语言模型结构
现代自回归语言模型(如 GPT、Llama 系列)主要由堆叠的 Transformer 层组成。第 层的隐藏状态 计算如下:
其中, 是注意力机制的输出, 是前馈神经网络(FFN)的输出。已有研究表明,FFN 的参数矩阵 和 存储了大量的事实性知识。因此,大多数知识编辑方法都选择修改 FFN 的权重来更新知识。
2.2 顺序知识编辑
知识通常以三元组 的形式表示,分别代表主体、关系和客体。知识编辑的目标是将原有的知识 替换为新知识 。我们将这一操作记为 。
在长度为 的顺序编辑任务中,给定编辑序列 ,每一次编辑 都在上一次编辑 的基础上进行。
主流的“定位-编辑”方法(如 MEMIT, AlphaEdit)首先定位模型参数 ,然后计算更新量 :
对于整个编辑序列,参数更新序列为 ,最终的参数为 。
2.3 更新参数的封闭解
大多数编辑方法通过求解正规方程(Normal Equation)来获取 。以 MEMIT 为例,其优化目标是:
其中 是待编辑主体的表示, 是需要保持不变的无关知识的表示, 是目标编辑表示。该优化问题的解形式为:
AlphaEdit 则引入了零空间投影,其解形式为:
这里 是无关输入表示 的零空间。
3. 叠加噪声累积问题
本文的核心贡献之一是识别并形式化了“叠加噪声累积”问题。
3.1 影响向量与激活向量的分解
为了便于分析,作者将更新参数 分解为两个向量的外积:
其中:
-
(影响向量, Influence Vector) :对应于前文公式中的 部分。它是一个专门训练的向量,旨在修改模型的输出方向。 -
(激活向量, Activation Vector) :对应于前文公式中的后半部分(如 )。它决定了 在何种程度上被激活。
对于输入表示 ,更新量对输出的贡献为 。这里点积 决定了激活强度。
3.2 叠加噪声的定义
在顺序编辑任务中,假设我们完成了 次编辑。当我们针对第 次编辑的主体输入 进行推理时,模型的实际输出会偏离预期的 。这种偏离可以表示为:
理想情况下,不同的编辑操作应当是独立的,互不干扰。即对于操作 ,应该只有 被激活,其他 应当保持静默。但在实际中,不同编辑之间存在干扰。作者定义第 次编辑受到的叠加噪声(Superimposed Noise) 为:
这个指标定量地描述了由于多重编辑干扰而产生的额外偏差。
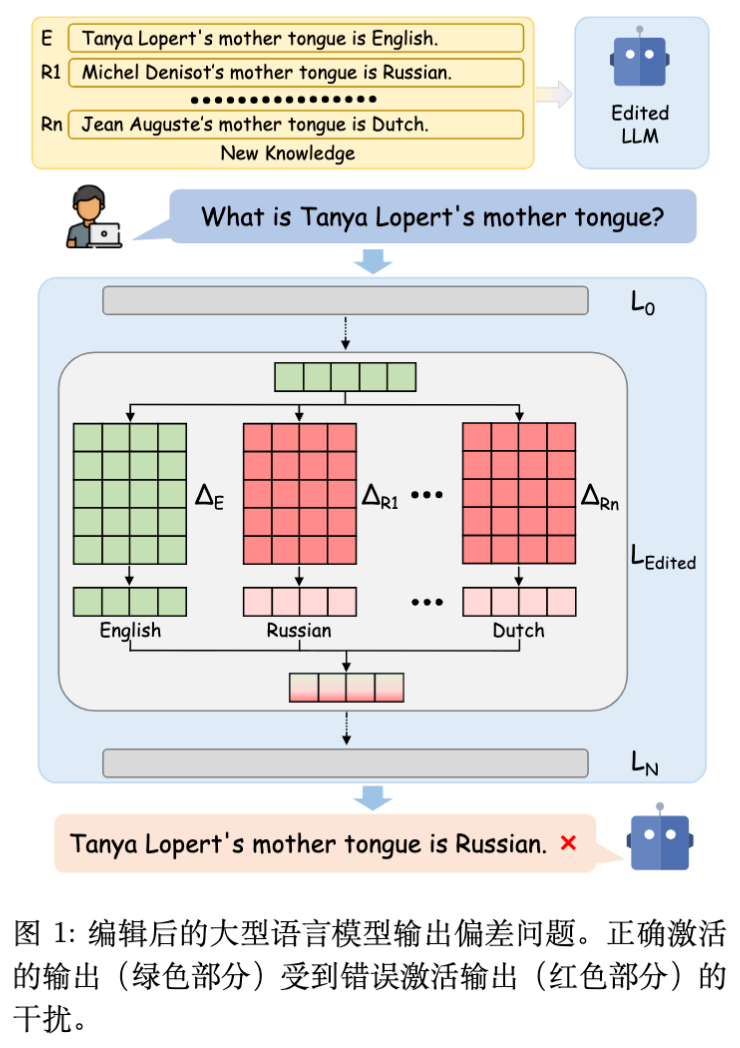
如图 1 所示,随着编辑数量增加,用户的查询不仅激活了正确知识,还激活了大量无关知识(红色部分)。这种无关知识的叠加使得正确输出被掩盖。
3.3 噪声的成因分析
根据 ,可以将 展开为:
通过分析上式,作者发现噪声的大小主要由两项决定:
-
(错误激活) :表示第 个输入在多大程度上错误地激活了第 次编辑的参数。 -
(影响向量重叠) :表示不同编辑的影响向量之间的方向一致性。
现有的局限性:
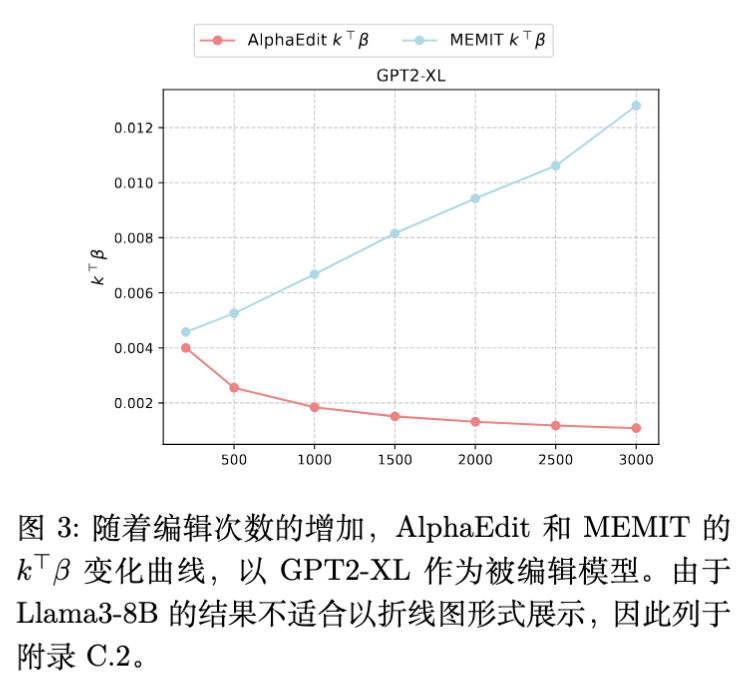
现有的方法如 AlphaEdit 试图通过优化 (例如利用零空间投影)来减小 。实验显示(图 3),AlphaEdit 确实比 MEMIT 获得了更小的 值。然而,随着编辑数量的增加,AlphaEdit 的性能依然会显著下降。
这表明,仅仅降低错误激活()是不够的,必须同时考虑减少影响向量之间的冲突()。如果 和 接近正交,那么即便存在一定的错误激活,其产生的噪声也会因为向量点积接近零而被抑制。
4. DeltaEdit 方法
基于上述分析,作者提出了 DeltaEdit。该方法的核心思想是在训练当前的编辑参数时,引入基于历史编辑信息的动态正交约束,显式地优化影响向量 ,使其与历史编辑产生的空间保持正交。
4.1 噪声公式的重写
对于编辑序列 ,执行第 次编辑时的噪声可以重写为:
第一项是历史编辑对当前输入的累积干扰,是常数;第二项是当前编辑与历史编辑的交互项。DeltaEdit 旨在通过约束 来最小化第二项中的 。
4.2 正交约束策略
为了抑制噪声增长,DeltaEdit 利用历史编辑的累积参数 。
动态阈值判定:
并非每次编辑都需要强加正交约束。作者引入了一个动态阈值 。仅当 时,才启动正交空间投影优化。这避免了在噪声尚不严重时过度限制优化空间,从而保护模型的泛化能力。
正交空间优化:
为了使 与历史所有的 () 正交,DeltaEdit 计算历史参数的零空间。为了避免存储所有历史向量的高昂开销,作者直接对 的列空间进行操作。
-
构造列空间矩阵:。 -
对 进行奇异值分解 (SVD):。 -
筛选特征向量:选取 中非零特征值对应的特征向量构成 。 -
注意:为了防止训练空间过度收缩,如果非零特征值数量超过了 维度的 3/4,则丢弃最小的特征值,直到保留的数量为 3/4。
-
-
计算投影矩阵 :
-
在训练 的过程中,每一步更新后都将其投影到零空间:
通过这种方式, 被强制限制在与历史编辑方向正交的子空间内,从而使得 。
4.3 动态阈值设计
由于 随着编辑次数增加而自然增长,固定阈值是不合适的。DeltaEdit 采用了滑动平均策略来更新阈值。
定义均值 和方差 的更新规则( 为滑动系数):
动态阈值 定义为:
其中 是控制约束强度的超参数。当当前输入的历史噪声干扰超过均值加 倍标准差时,触发正交约束。
4.4 算法流程
DeltaEdit 的整体执行流程如下(简化版):
-
初始化 , 。
-
对于每一个编辑 :
a. 获取输入表示 。
b. 判断是否满足启动条件: 且 。
c. 若满足,对 进行 SVD,计算零空间投影矩阵 ;否则 。
d. 更新统计量 和 (仅在非异常值范围内更新)。
e. 优化求解 :在梯度下降过程中应用 。
f. 计算 (使用类似于 AlphaEdit 的公式)。
g. 更新模型参数 。
h. 累加历史参数 。
5. 实验设置
为了全面评估 DeltaEdit 的有效性,作者在两个主流 LLM 上进行了广泛的实验。
5.1 实验环境
-
模型: -
GPT2-XL (1.5B 参数):代表较小规模的模型。 -
Llama3-8B:代表当前主流的开源大模型。
-
-
数据集: -
ZsRE (Question Answering):用于评估问答形式的知识编辑。 -
CounterFact:更具挑战性的数据集,包含反事实陈述,区分事实与反事实。
-
-
硬件:GPT2-XL 在 RTX 4090 (24GB) 上运行,Llama3-8B 在 A100 (40GB) 上运行。
5.2 评估指标
实验采用了三个核心指标,并区分了“top” (最高概率 token) 和“larger” (目标 token 概率上升) 两种计算方式:
-
Efficacy (有效性) :编辑后模型能否输出目标知识。 -
: 目标 是否具有最高概率。
-
-
Generalization (泛化性) :模型对语义等价的改写提示(Rephrased Prompts)能否输出正确知识。 -
Specificity (特异性/局部性) :模型对无关输入的预测是否保持不变。这是衡量模型是否发生“遗忘”或“副作用”的关键。
5.3 基线方法
作者选取了多种具有代表性的基线方法进行对比:
-
Fine-Tuning (FT) :传统的微调。 -
ROME:单次编辑的经典方法。 -
MEMIT:ROME 的多层批量扩展,是当前的强基线。 -
PRUNE:通过控制条件数来支持顺序编辑。 -
RECT:通过稀疏化更新参数来减少副作用。 -
AlphaEdit:最新的基于零空间投影的方法,是 DeltaEdit 的主要对比对象。
6. 实验结果与分析
6.1 主要性能对比
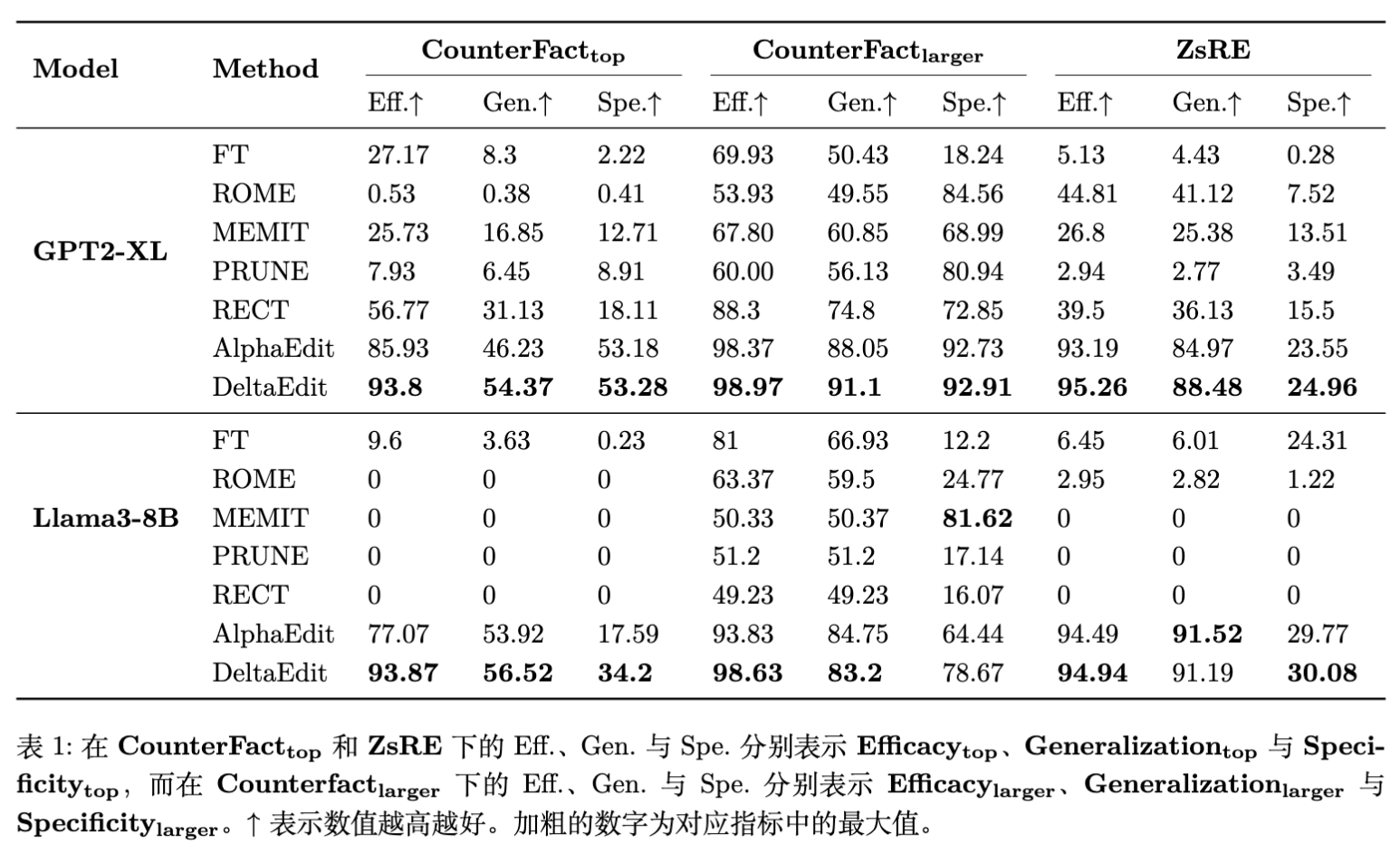
在 CounterFact 和 ZsRE 数据集上进行 3000 次顺序编辑后的结果显示,DeltaEdit 在绝大多数指标上都超越了基线方法。
关键发现:
-
Llama3-8B 上的显著提升:在 CounterFact 数据集上,DeltaEdit 相比 AlphaEdit 在 上提升了 16.8% ,在 上提升了 16.61% 。这说明在更大、更复杂的模型中,噪声控制对于维持长期编辑性能至关重要。 -
GPT2-XL 的结果:在较小的模型上,AlphaEdit 本身表现已经很好,DeltaEdit 依然取得了更优的结果,但提升幅度相对较小。这可能与小模型的参数空间较小,更容易饱和有关。 -
稳定性:MEMIT 在 Llama3-8B 上表现极差(Efficacy 为 0),这是因为 MEMIT 产生的噪声随着编辑次数迅速累积导致模型崩溃。而 DeltaEdit 展现了极强的稳定性。
6.2 噪声抑制效果
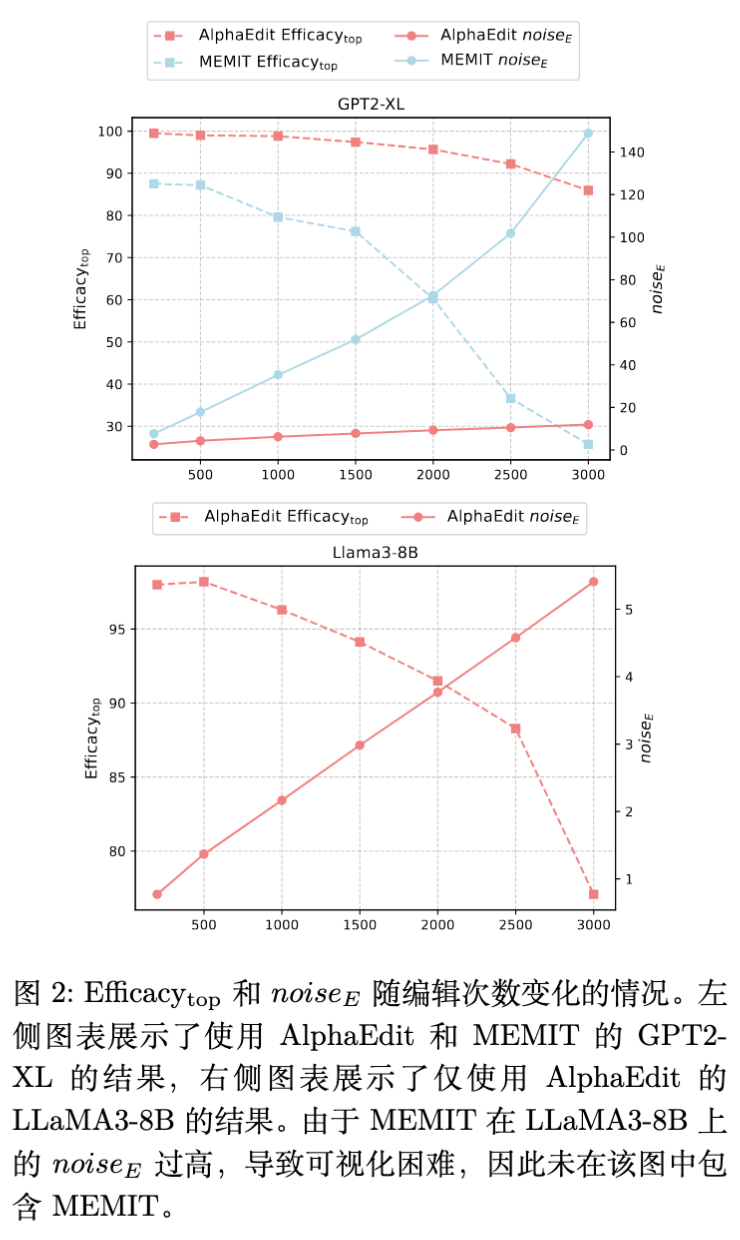
作者绘制了 (平均叠加噪声)随编辑次数变化的曲线。
-
性能衰退与噪声的关系:随着 的增加,模型的 Efficacy 呈现明显的下降趋势。且这种下降是非线性的,一旦噪声超过阈值,性能会急剧恶化。 -
DeltaEdit 的优势:相比 AlphaEdit,DeltaEdit 产生的 增长极其缓慢。在 Llama3-8B 上,3000 次编辑后,DeltaEdit 能够保持高 Efficacy,而 AlphaEdit 则出现了大幅下滑。
6.3 影响向量与激活向量的进一步分析
为了验证 DeltaEdit 是否真正减少了参数间的冲突,作者分析了 的值。有趣的是,DeltaEdit 的 并没有比 AlphaEdit 进一步降低(在某些情况下甚至略高)。
这反过来印证了本文的核心假设:在 (错误激活)难以完全消除的情况下,通过正交约束降低 (影响向量重叠)是解决噪声问题的关键。 DeltaEdit 并不是通过让 更稀疏来起作用,而是通过让 互不干扰来容忍 的非完美性。
7. 消融实验与深入探讨
7.1 隐藏层表示分析 (t-SNE)
为了探究编辑对模型内部表示的影响,作者提取了 Llama3-8B 在编辑前后的隐藏层表示,并使用 t-SNE 进行可视化。
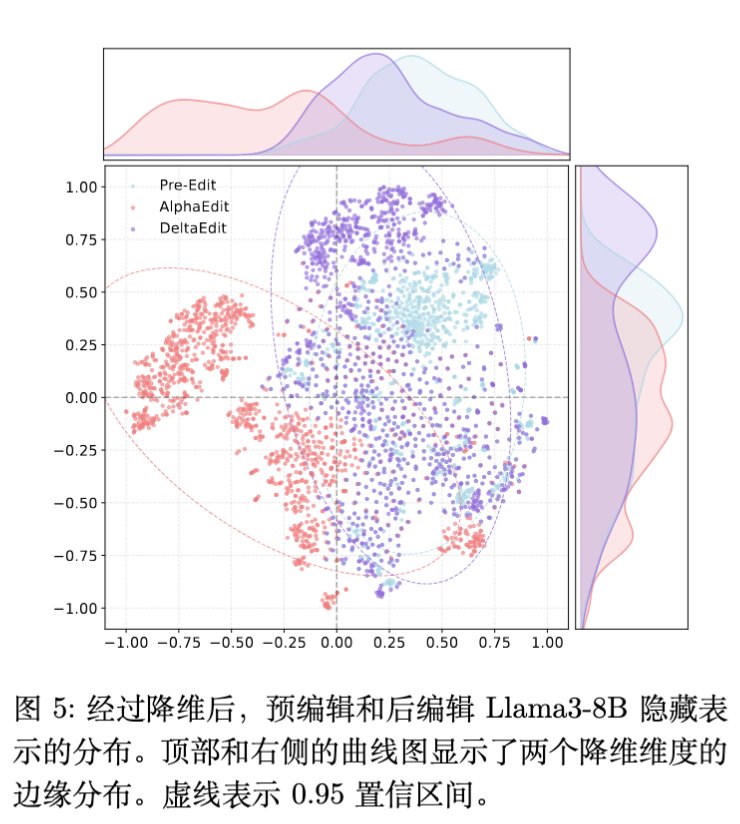
-
分布偏移:AlphaEdit 编辑后的模型表示分布发生了显著的偏移(Shift),这意味着模型的原始语义空间被扭曲了。 -
保持分布:DeltaEdit 编辑后的表示分布与原始模型(Pre-edited)高度重合。这解释了为什么 DeltaEdit 在保持 Specificity(特异性)方面表现优异——它极大地保留了模型的原始流形结构。
7.2 超参数 的影响
超参数 控制正交约束的强度。
-
较小:约束启动频繁,可能会限制新知识的学习能力,导致 Generalization 下降。 -
较大:约束启动少,退化为类似 AlphaEdit 的行为,噪声累积增加,Specificity 下降。 -
实验表明,在 (Llama3) 和 (GPT2) 附近可以达到最佳的平衡。有趣的是,GPT2 需要更强的约束,而 Llama3 需要相对宽松的约束,这可能与 Llama3 本身参数空间更大、容纳冲突能力更强有关。
7.3 通用能力评估
除了编辑任务本身,作者还在 GLUE 基准测试(CoLA, MMLU, MRPC, NLI, RTE, SST)上评估了模型。
-
结果:DeltaEdit 在各项任务上的 F1 分数与原始模型差异极小,优于 AlphaEdit。 -
意义:这证明了 DeltaEdit 并非通过牺牲模型的通用推理能力来换取编辑成功率,它真正做到了“外科手术式”的精准修改。
7.4 案例研究
作者展示了具体的生成案例(Case Study)。例如,将 Danielle Darrieux 的母语修改为英语。
-
MEMIT:输出重复的乱码,标志着模型崩溃。 -
AlphaEdit:虽然语句通顺,但内容与编辑目标无关(产生幻觉)。 -
DeltaEdit:不仅生成流畅,而且逻辑上与新知识一致(例如推断出生地在英语国家)。
8. 讨论与结论
8.1 现有方法的盲点
这篇论文敏锐地指出了现有顺序编辑研究的一个盲点:过度关注激活端()的稀疏性,而忽视了影响端()的方向性。 事实上,在大规模连续编辑中,完全避免输入表示的重叠几乎是不可能的( 很难为 0)。DeltaEdit 提供了一种正交化的思路,使得即便存在激活重叠,参数更新之间也能互不干扰。
8.2 局限性与未来方向
虽然 DeltaEdit 表现优异,但其计算 SVD 和投影矩阵带来了一定的计算开销。尽管作者通过仅分解 的列空间来优化效率,但随着编辑次数 趋于无穷大,维护历史信息的成本仍需关注。
未来的研究方向可能包括:
-
无梯度的正交编辑:是否可以通过闭式解直接计算出正交的 ,而无需在优化循环中进行投影? -
更高效的历史压缩:如何更紧凑地存储历史编辑信息,避免随着 增长的内存压力? -
跨层协同:本文主要关注单层的编辑,多层联合正交约束可能会带来进一步的提升。
8.3 总结
DeltaEdit 通过引入“叠加噪声”这一概念,为理解 LLM 顺序编辑中的灾难性遗忘和模型崩溃提供了新的视角。其提出的动态正交约束策略,在数学上优雅且在实验中有效。对于致力于让大模型具备持续学习和实时更新能力的研究员来说,这篇论文提供了极具价值的理论参考和工程实践范例。
更多细节请阅读原论文。
往期文章:


