
-
论文标题:Stabilizing Reinforcement Learning with LLMs: Formulation and Practices -
论文链接:https://arxiv.org/pdf/2512.01374
TL;DR
这是一篇由阿里 Qwen 团队发表的关于大语言模型(LLM)强化学习(RL)稳定性的研究论文。文章通过理论推导提出,在 LLM 强化学习中,常用的 Token 级优化目标(如 PPO、REINFORCE)实际上是期望序列级奖励的一阶近似。该近似成立的前提是最小化“训练-推理差异(Training-Inference Discrepancy)”和“策略滞后性(Policy Staleness)”。基于这一理论,论文解释了 Importance Sampling (IS) 修正、Clipping 以及 Mixture-of-Experts (MoE) 模型中的 Routing Replay 等技术为何能稳定训练。通过在 30B 参数量的 MoE 模型上进行数十万 GPU 小时的实验,论文给出了一套在 On-policy 和 Off-policy 设置下稳定训练 RL 的最佳实践(MiniRL)。
1. 引言
随着大语言模型(LLM)的发展,强化学习(RL)已成为提升模型解决复杂问题能力(如数学推理)的关键技术范式。然而,在扩展 RL 规模时,训练的稳定性是一个核心挑战。
LLM 的 RL 训练存在一个根本性的不匹配(Mismatch):
-
奖励(Reward)是序列级的:通常是对整个生成的回复(Response)给出一个标量分数(例如数学题做对了吗)。 -
优化(Optimization)是 Token 级的:主流算法(如 REINFORCE、PPO、GRPO)通常在 Token 级别进行梯度更新。
这种不匹配引发了对其数学严谨性和训练稳定性的担忧。特别是在 Mixture-of-Experts (MoE) 模型中,动态的专家路由(Expert Routing)机制会使得 Token 级的 Importance Sampling (IS) 权重失效,进一步加剧了不稳定性。
虽然已有研究提出直接优化序列级目标,或通过 Value Model 进行 Token 级分配,但前者通常难以优化,后者难以获得可靠的 Value Model。本文旨在回答:用 Token 级目标优化序列级奖励是否合理?在什么条件下合理?
2. 理论框架:作为一阶近似的 Token 级目标
论文首先建立了一套新的数学表述,论证了 Token 级目标实际上是序列级目标的一阶近似。
2.1 符号定义
-
:模型参数。 -
:目标策略(待优化)。 -
:Rollout 策略(用于采样回复)。注意,这里区分了 (训练引擎中的策略)和 (推理引擎中的策略)。 -
:输入 Prompt,:回复,:序列级标量奖励。
2.2 序列级目标的困境
我们的最终目标是最大化期望序列级奖励:
由于样本通常是在推理引擎(如 vLLM, SGLang)中生成的,而优化发生在训练引擎(如 Megatron, FSDP)中,我们需要引入 Importance Sampling (IS):
其中 是序列级的 IS 权重。该目标的梯度为:
由于序列概率 的数值范围巨大且方差极高,直接优化公式 (2) 在数值上通常是不可行的。
2.3 Token 级目标作为一阶近似
为了解决上述问题,我们通常使用如下的 Token 级代理目标(Surrogate Objective):
注意,这里使用了 Token 级的 IS 权重。这实际上就是带有 IS 权重的 REINFORCE 算法。
论文指出的核心洞见是:公式 (3) 是公式 (1) 的一阶近似。
计算公式 (3) 的梯度:
对比公式 (2) 和 (4),可以发现当 时,。这意味着,只要 足够接近 ,优化 Token 级目标就能有效提升序列级奖励。
2.4 近似成立的条件
为了保证上述一阶近似有效,我们需要 和 接近。我们可以将 Token 级的 IS 权重分解为两部分:
其中 表示在训练引擎中计算的 Rollout 策略。
这个分解揭示了导致近似失效的两个来源:
-
训练-推理差异 (Training-Inference Discrepancy) :由于底层基础设施(如计算 Kernel 不同、推理端为了吞吐量关闭了 batch-invariant kernels、FP8 推理 vs BF16 训练)导致的数值误差。 -
策略滞后性 (Policy Staleness) :Rollout 策略与当前待优化策略之间的差异。这通常由 Off-policy 更新(大 Batch 拆分为 Mini-batch 多次更新)引起。
结论:要稳定 RL 训练,必须同时最小化这两个差异。
3. MoE 模型的特殊挑战与 Routing Replay
对于 Mixture-of-Experts (MoE) 模型,上述条件变得更加苛刻。专家路由机制(Expert Routing)使得前向传播仅激活一小部分参数。
将路由引入公式 (5),Token 级 IS 权重变为:
其中 表示被路由选中的专家。
MoE 的挑战在于:
-
路由不一致:即使输入相同,训练和推理引擎的数值微小差异可能导致选中的专家完全不同(),极大放大了训练-推理差异。 -
专家漂移:策略更新不仅改变参数 ,还改变路由选择 ,加剧策略滞后性。
Routing Replay
为了解决这个问题,论文引入了 Routing Replay 技术:在策略优化期间固定专家路由,使其像 Dense 模型一样被优化。具体有两种实现:
-
Vanilla Routing Replay (R2) :
-
在梯度更新时,重放训练引擎中 Rollout 策略选中的专家 。 -
作用:主要减少策略滞后性(固定了专家变化)。 -
代价:引入了偏差(Bias),因为第一步更新后的目标策略 本应选择新专家,却被强制使用旧专家。
-
-
Rollout Routing Replay (R3) :
-
在训练引擎重放推理引擎中选中的专家 。 -
作用:主要减少训练-推理差异(强制训练端和推理端路径一致),同时也减少策略滞后性。
-
权衡:R2 和 R3 虽然通过减少差异恢复了一阶近似的有效性,但也通过锁定专家引入了优化偏差(Bias)。
4. 实验设计与 MiniRL
为了验证理论并寻找最佳实践,论文设计了一个“极简”的基线算法 MiniRL,并在 30B MoE 模型上进行了大规模实验。
4.1 MiniRL 算法
MiniRL 是对 REINFORCE 的最小化修改,旨在保留一阶近似的有效性:
-
Advantage Group Normalization:降低方差。 -
Clipping:参考 PPO,防止策略更新过大(控制策略滞后性)。 -
Token-level IS Correction:显式包含 项(修正训练-推理差异)。
公式如下:
其中 是 Clipping 掩码。
4.2 实验设置
-
任务:数学推理(HMMT25, AIME25, AIME24)。 -
奖励:二值奖励(0 或 1)。 -
模型:Qwen3-30B-A3B-Base 微调后的 Cold-start 模型。 -
环境:FP8 推理,BF16 训练(这构成了一个强压力测试,训练-推理差异很大)。 -
计算量:数十万 GPU 小时。 -
监控指标: -
Benchmark Score(准确率)。 -
Training Reward。 -
Entropy(策略熵,监控坍塌)。 -
Training-Inference KL Divergence:监控 和 的距离,这是衡量稳定性的关键指标。
-
5. 实验结果分析
5.1 On-policy 训练 (Global BS = Mini BS)
在 On-policy 设置下(即 ,每次生成后立即更新一次),实验对比了 MiniRL 及其变体。
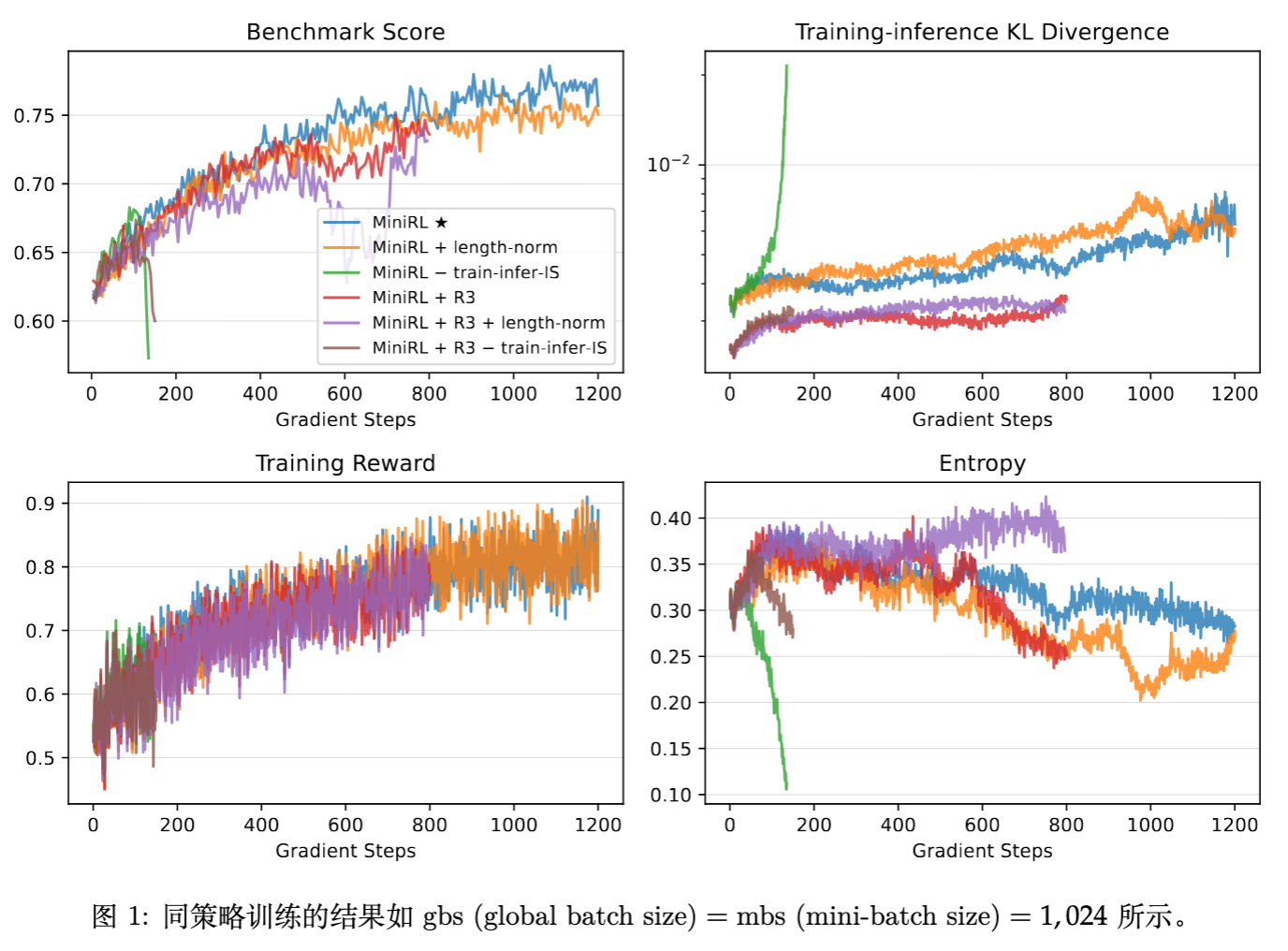
主要发现:
-
MiniRL (带 IS 修正) :表现最好,训练最稳定。 -
去除 IS 修正 :导致训练迅速坍塌(Collapse),Entropy 骤降。这证实了 IS 权重对于修正训练-推理差异(特别是在 FP8 vs BF16 场景下)是必须的。 -
增加长度归一化 (Length Normalization) :虽然稳定,但性能次优。 -
理论解释:长度归一化破坏了公式 (3) 作为公式 (1) 一阶近似的数学性质,导致优化目标有偏。
-
-
R3 的影响:在 On-policy 下,R3 并没有带来性能提升,甚至结合长度归一化后会导致性能下降。这表明在 On-policy 且差异已被 IS 修正的情况下,R3 引入的 Bias 可能超过了其带来的收益。
5.2 Off-policy 训练 (Global BS > Mini BS)
为了加速收敛,通常将大 Batch 切分为多个 Mini-batch 更新(引入了 Off-policy)。论文测试了三种 Off-policiness 程度(在 mini-batch size 固定为 1,024 个响应的情况下,全局批量大小分别调整为 2,048、
4,096 和 8,192,分别对应 N = 2 、4 和 8)。
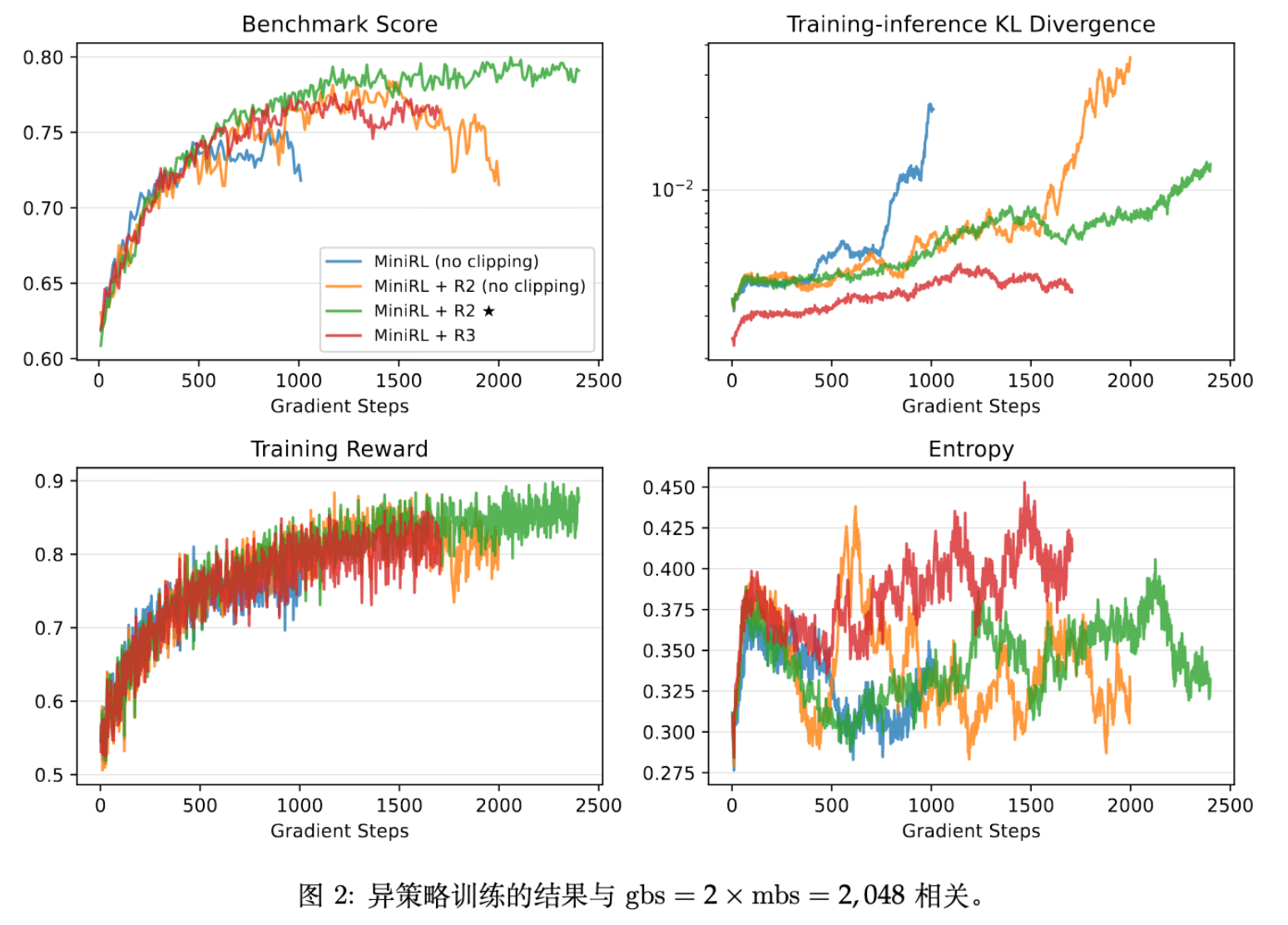
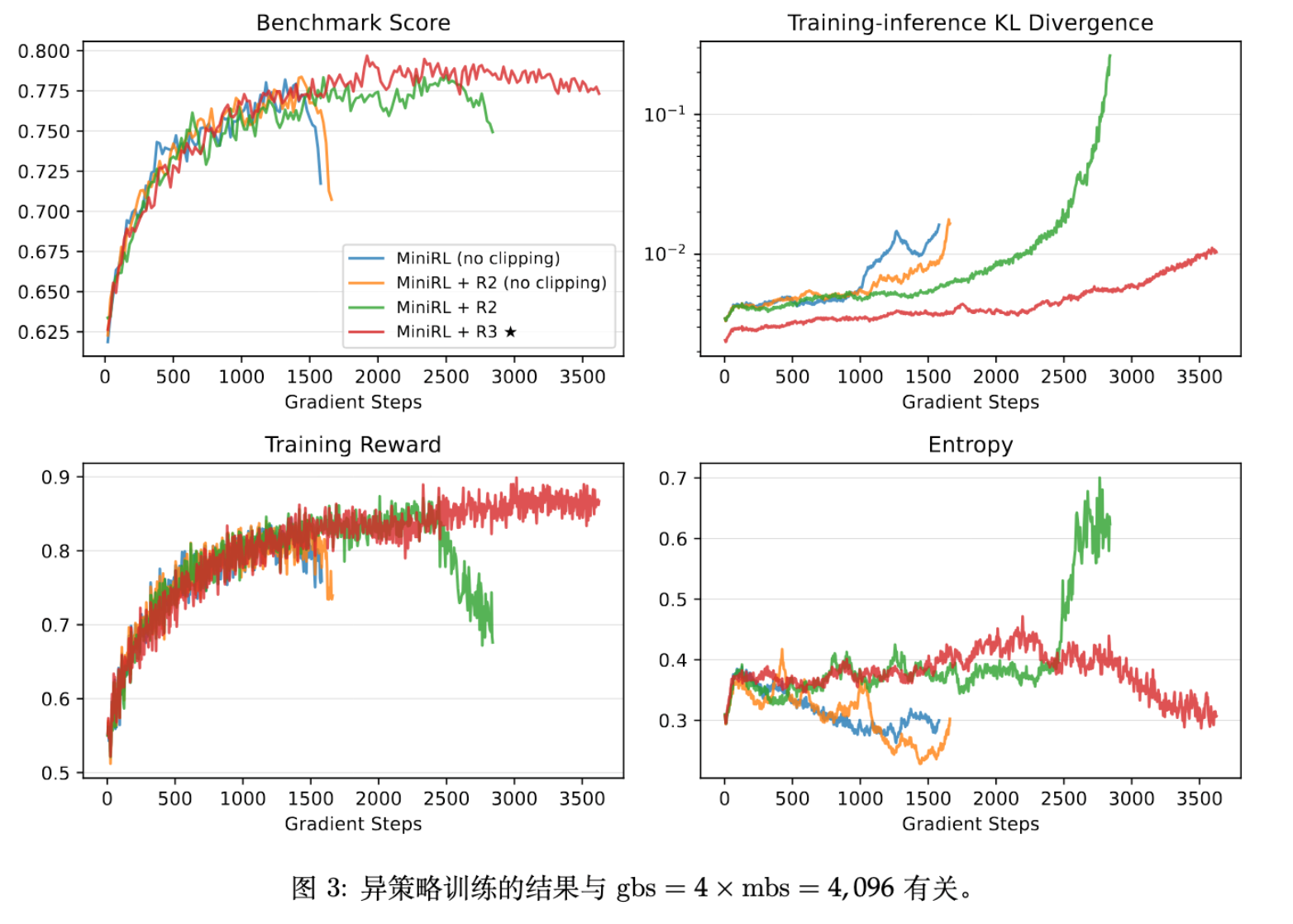
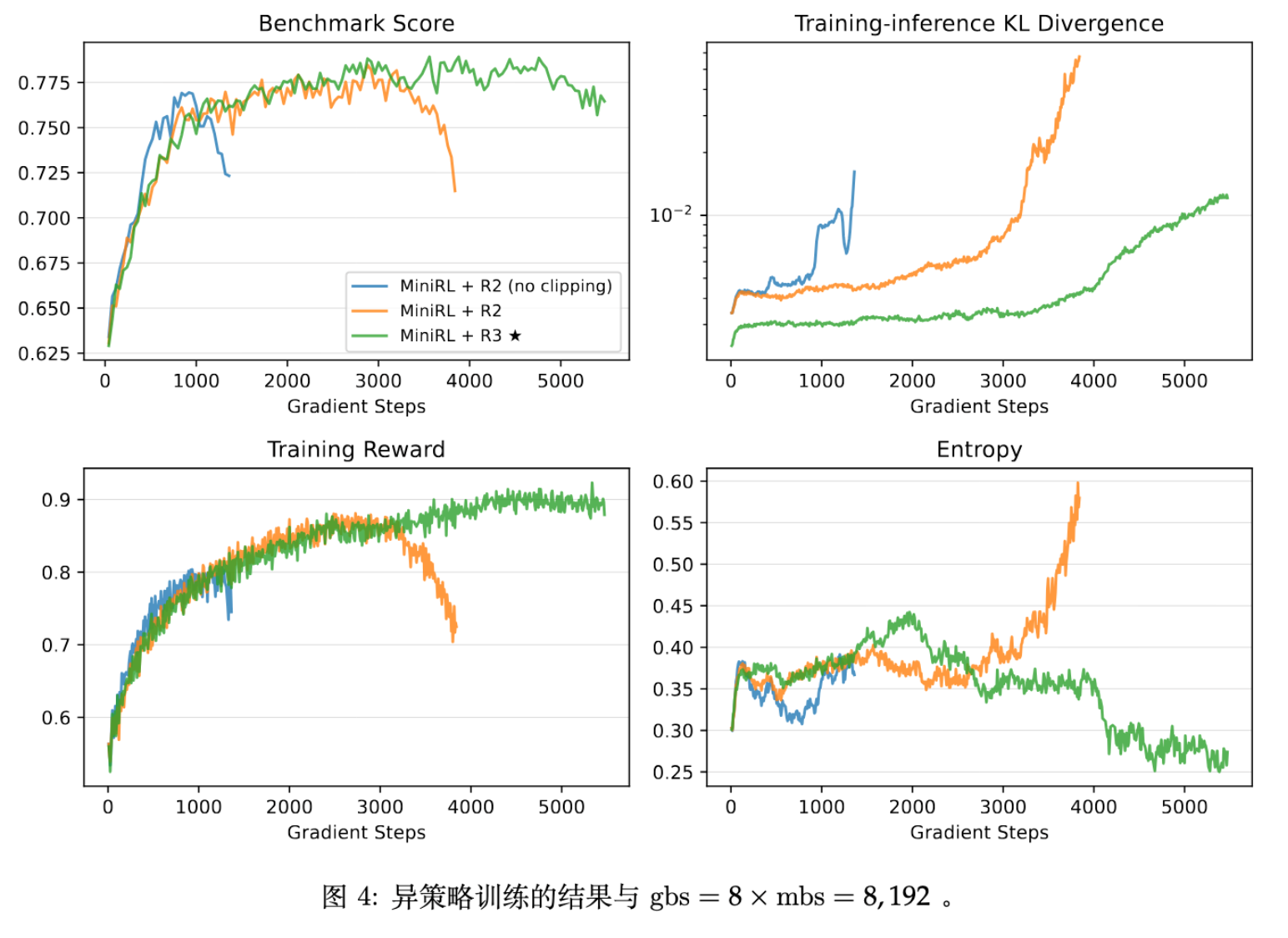
主要发现:
-
Clipping 和 Routing Replay 是必须的:一旦引入 Off-policy,不加这两个技术会导致训练迅速崩溃。这也验证了理论部分关于“策略滞后性”和“MoE 路由漂移”会破坏近似的推断。 -
小 Off-policiness ():R2 优于 R3。 -
解释:此时策略滞后性较小,R2 引入的 Bias 较小且足以控制 MoE 的不稳定性。R3 强制对齐推理专家的约束可能过强(Bias 更大)。
-
-
大 Off-policiness ():R3 优于 R2。 -
解释:随着更新步数增加,策略滞后性变大,R2 在后续 Mini-batch 中无法有效控制训练-推理差异。R3 通过严格复用推理端专家,虽然 Bias 大,但更好地保持了近似的有效性(Valid First-order Approximation),防止了模型发散。
-
5.3 冷启动初始化的影响
论文还研究了不同的冷启动模型(通过蒸馏 Qwen3-Max, DeepSeek-R1, GPT-4o 等得到)对最终 RL 性能的影响。
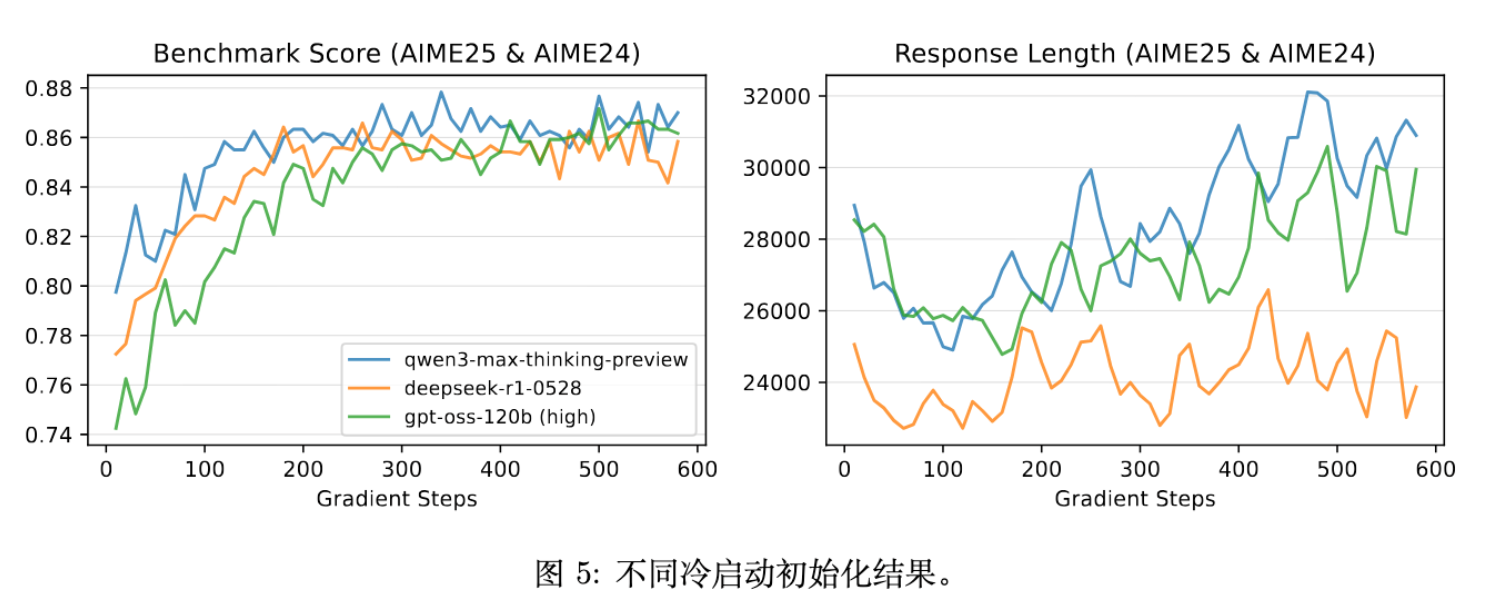
结论:只要 RL 训练过程是稳定的(使用 MiniRL + R2/R3),不同初始化的模型最终都能收敛到相当的性能水平。
-
启示:这表明研究重心应更多放在 RL 算法本身的稳定性及 Scaling 上,而不是过分纠结于冷启动数据的具体细节。当 RL 训练足够长时,初始化的差异会消失。
6. 与其他算法的对比 (GRPO & CISPO)
论文在附录中详细对比了 MiniRL 与 GRPO (DeepSeekMath) 和 CISPO。
-
GRPO:
-
目标函数使用了长度归一化(平均 Token 奖励)。 -
没有考虑训练-推理差异的 IS 修正。 -
评价:长度归一化使得目标有偏,可能导致次优性能;缺乏 IS 修正可能在训练-推理差异大时导致不稳定。
-
-
CISPO:
-
同样使用了长度归一化。 -
没有对特定 Token 进行 Clipping(只 Clip 了比率)。 -
评价:实验显示,不 Clip 梯度会导致训练不稳定(§ 4.4 结果支持)。
-
MiniRL 的优势在于其严格遵循“序列级奖励的一阶近似”这一理论推导,去除了长度归一化,并显式处理了差异项。
7. 总结与最佳实践建议
这篇论文通过严谨的数学推导和大规模实验,为 LLM 的 RL 训练提供了以下核心见解:
-
理论基础:Token 级优化是序列级奖励的一阶近似。这一近似的有效性取决于训练-推理差异和策略滞后性的最小化。 -
稳定性配方: -
IS Correction:必须项。用于修正训练(BF16)与推理(FP8/不同 Kernel)之间的数值差异。 -
Clipping:必须项。用于限制策略更新幅度,防止策略滞后性过大。 -
无长度归一化:不要使用长度归一化,它会使目标有偏。
-
-
MoE 特有配方: -
On-policy / 小 Off-policy:推荐 MiniRL + R2 (Vanilla Routing Replay) 。此时 Bias 较小,R2 足以稳定训练。 -
大 Off-policy:推荐 MiniRL + R3 (Rollout Routing Replay) 。此时稳定性压倒一切,R3 能更强力地消除差异。
-
更多细节请阅读原技术报告。
往期文章:


