
-
论文标题:DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models -
论文链接:https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2/resolve/master/assets/paper.pdf
TL;DR
时隔两个月,DeepSeek 今天正式发布了 DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。针对开源模型在复杂任务中与闭源模型(如 Gemini-3.0-Pro, GPT-5)存在的差距,新模型在架构效率、后训练(Post-Training)计算规模以及 Agent 数据合成三个方面进行了改进。
核心技术要点如下:
-
架构层面:引入了 DeepSeek Sparse Attention (DSA) 。通过“闪电索引器”(Lightning Indexer)和细粒度 Token 选择机制,将长上下文下的注意力计算复杂度降低,同时保持了模型性能。 -
后训练层面:构建了可扩展的强化学习(RL)框架。后训练阶段的计算预算超过了预训练成本的 10%。为保证训练稳定性,提出了无偏 KL 估计(Unbiased KL Estimate)、Off-Policy 序列掩码(Sequence Masking)等改进策略。 -
Agent 层面:开发了大规模 Agent 任务合成流水线。通过生成超过 1800 个不同环境和 85,000 个复杂 Prompt,结合“在工具使用中思考”(Thinking in Tool-Use)的策略,提升了模型在复杂交互环境中的泛化能力。
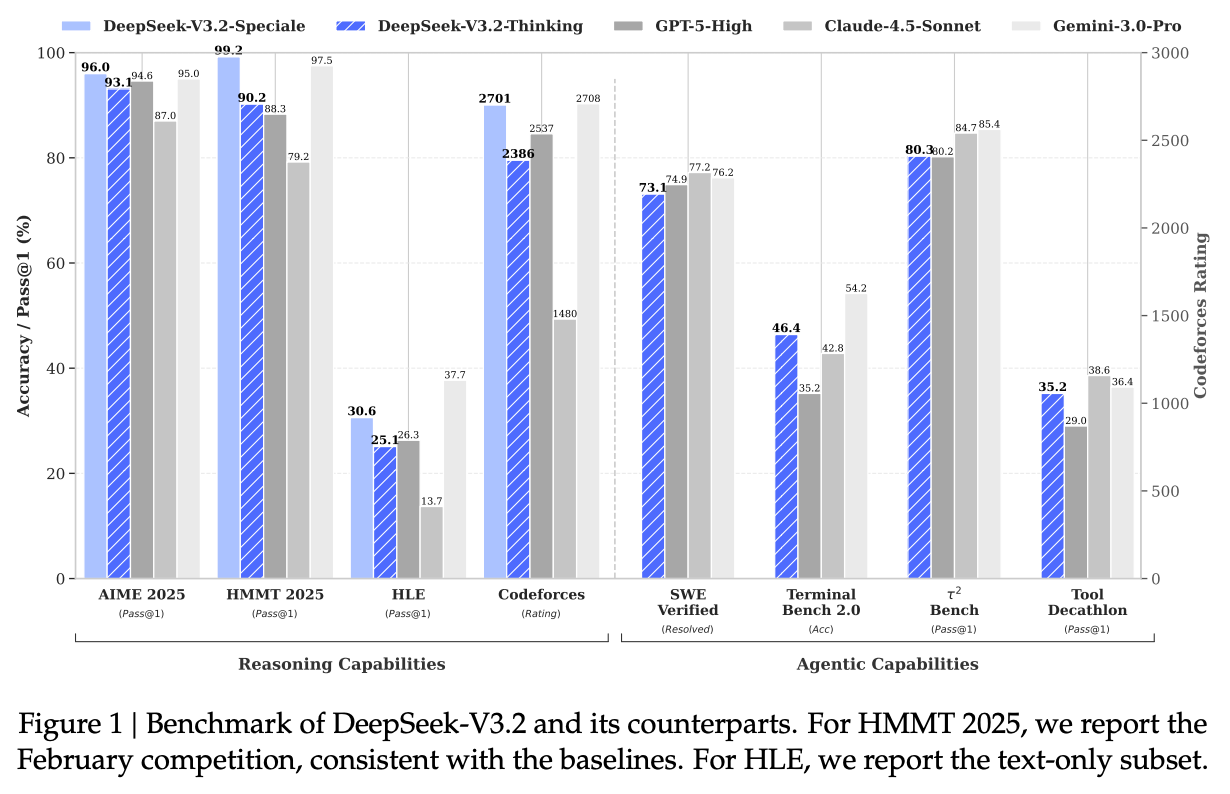
实验结果表明,DeepSeek-V3.2 在主流推理榜单上与 GPT-5 表现相当。其高计算版本 DeepSeek-V3.2-Speciale 在 2025 IOI 和 IMO 中均取得了金牌水平的成绩。
1. 引言
随着推理模型(Reasoning Models)的发布,大语言模型(LLM)的能力在可验证领域取得了显著提升。然而,开源模型与闭源专有模型之间的性能差距并未如预期般缩小,反而呈现扩大的趋势。DeepSeek 团队通过分析认为,限制开源模型在复杂任务上表现的主要因素有三点:
-
架构效率瓶颈:传统的注意力机制(Vanilla Attention)在处理长序列时效率低下,阻碍了可扩展的部署和有效的后训练。 -
后训练资源分配不足:开源模型通常缺乏在后训练阶段的算力投入,限制了其在困难任务上的性能上限。 -
Agent 能力滞后:在工具使用、泛化和指令遵循方面,开源模型与闭源模型存在显著差距。
为了解决上述问题,DeepSeek-V3.2 提出了一整套解决方案,涵盖了从底层注意力机制的设计到高层 Agent 数据合成的全流程。
2. DeepSeek-V3.2 模型架构
DeepSeek-V3.2 的基础架构沿用了 DeepSeek-V3 系列的设计,但在注意力机制上进行了重大调整,引入了 DeepSeek Sparse Attention (DSA)。
2.1 DeepSeek Sparse Attention (DSA) 原理
DSA 的设计目标是在保持长上下文性能的前提下,大幅降低计算复杂度。DSA 主要由两个核心组件构成:闪电索引器(Lightning Indexer)和细粒度 Token 选择机制(Fine-grained Token Selection Mechanism)。
2.1.1 闪电索引器 (The Lightning Indexer)
闪电索引器的作用是快速计算查询 Token(Query)与前序 Token 之间的相关性分数,从而确定哪些 Token 值得被“关注”。
给定查询 Token 和前序 Token ,索引分数 的计算公式如下:
其中:
-
表示索引头的数量。 -
和 均由查询 Token 导出。 -
由前序 Token 导出。 -
采用 ReLU 作为激活函数,旨在提高吞吐量。
由于索引头的数量较少,且可以使用 FP8 精度实现,该模块的计算效率较高。
2.1.2 细粒度 Token 选择机制
基于索引器计算出的分数 ,模型执行 Top-k 选择。对于每个查询 Token ,机制仅检索索引分数最高的前 个 Key-Value 对 。
最终的注意力输出 计算如下:
这种机制将注意力机制的核心计算复杂度从 降低到了 ,其中 。
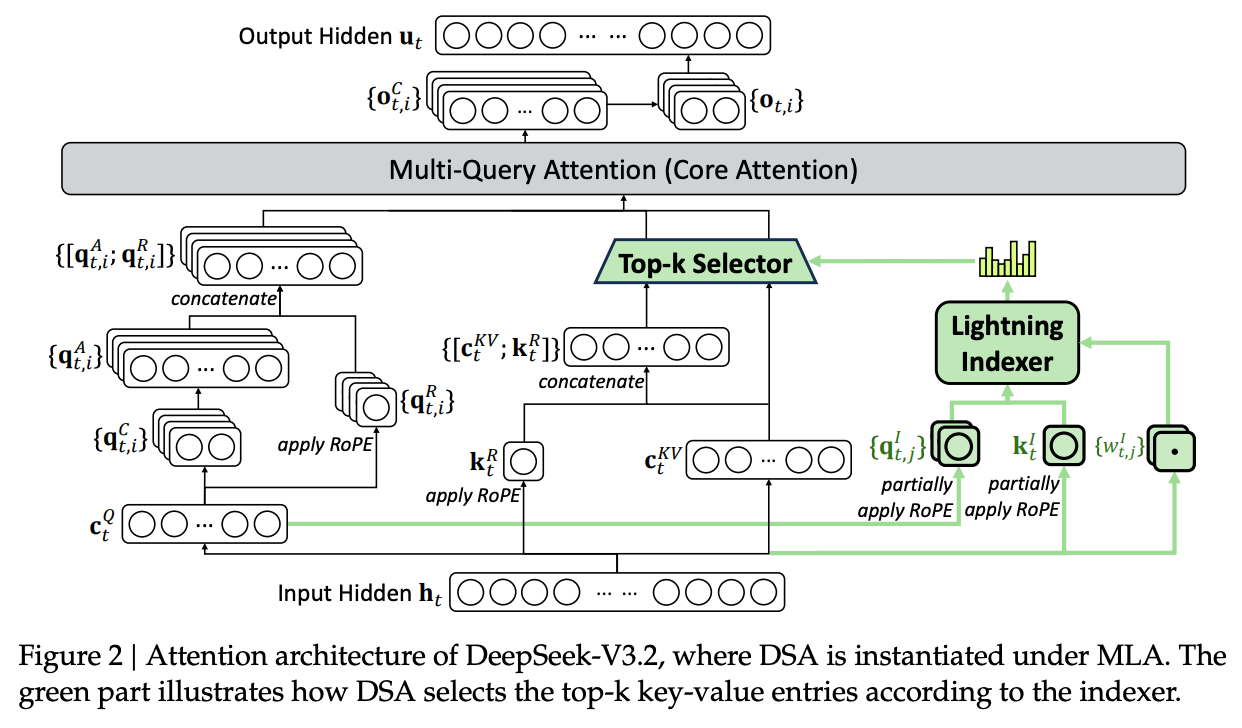
2.2 DSA 在 MLA 中的实例化
为了能够从 DeepSeek-V3.1-Terminus 检查点进行持续训练,DeepSeek-V3.2 将 DSA 实例化在多头潜在注意力(MLA, Multi-Head Latent Attention)架构之下。
出于计算效率的考量,DeepSeek-V3.2 基于 MLA 的 MQA (Multi-Query Attention) 模式实现了 DSA。在这种模式下,每个潜在向量(MLA 的 Key-Value 条目)在查询 Token 的所有查询头之间共享。
2.3 持续预训练策略
从 DeepSeek-V3.1-Terminus(上下文长度扩展至 128K)开始,训练分为两个阶段,旨在将模型适配到稀疏注意力模式。
2.3.1 密集预热阶段 (Dense Warm-up Stage)
此阶段的目标是初始化闪电索引器。
-
配置:保持密集注意力(Dense Attention),冻结除闪电索引器外的所有模型参数。 -
目标:使索引器的输出拟合主注意力分数的分布。 -
过程:对于第 个查询 Token,首先聚合所有注意力头的主注意力分数,沿序列维度进行 L1 归一化,得到目标分布 。 -
损失函数:采用 KL 散度损失:
该阶段仅训练 1000 步,消耗约 2.1B Tokens。
2.3.2 稀疏训练阶段
此阶段引入细粒度 Token 选择机制,并优化所有模型参数以适应 DSA 的稀疏模式。
-
配置:同时训练主模型和索引器。 -
索引器优化:输入从计算图中分离(detach),仅通过 进行优化。此时仅考虑被选中的 Token 集合 :
-
主模型优化:仅根据语言建模损失(Language Modeling Loss)进行优化。 -
参数:每个查询 Token 选择 2048 个 KV Tokens。训练 15000 步,共计 943.7B Tokens。
3. 后训练
DeepSeek-V3.2 的后训练策略延续了 DeepSeek-V3.2-Exp 的路线,包含专家蒸馏(Specialist Distillation)和混合强化学习训练(Mixed RL Training)。该框架的一个显著特点是大幅增加了后训练阶段的计算预算,并针对大规模 RL 训练的稳定性进行了算法层面的改进。
3.1 Scaling GRPO
DeepSeek-V3.2 采用组相对策略优化(GRPO, Group Relative Policy Optimization)作为 RL 训练算法。GRPO 的基本目标函数如下:
其中 是重要性采样比率, 是优势函数。
为了支持大规模 RL 计算并保持训练稳定,论文提出了以下关键改进策略:
3.1.1 无偏 KL 估计
在计算当前策略 和旧策略 之间的 KL 散度时,传统的 K3 估计器(Schulman, 2020)存在偏差。当采样 Token 在当前策略下的概率远低于参考策略时(即 ),K3 估计器的梯度会分配过大且无界的权重,导致梯度更新充满噪声,破坏训练动态。
DeepSeek 修正了 K3 估计器,利用重要性采样比率获得无偏 KL 估计:
这一调整消除了系统性估计误差,促进了收敛的稳定性。
3.1.2 Off-Policy 序列掩码
为了提高数据生成效率,通常会生成大批量的 Rollout 数据,然后切分为多个 Mini-batch 进行多次梯度更新。这引入了 Off-policy 行为。此外,推理框架和训练框架的实现细节差异也会加剧策略偏离。
为了解决此问题,引入了二进制掩码 ,用于屏蔽那些引入显著策略偏离的负优势序列:
其中 是控制策略偏离阈值的超参数。这意味着模型主要从自身的错误中学习,而屏蔽那些高度 Off-policy 的负样本,因为这些样本可能会误导优化过程。
3.1.3 路由一致性
对于混合专家(MoE)模型,推理和训练框架之间的微小差异可能导致同一输入在不同框架下激活不同的专家。这种不一致会导致参数子空间的剧烈偏移,破坏优化稳定性。
Keep Routing 策略要求在训练期间强制使用与推理采样时相同的专家路由路径,确保优化的参数与采样时使用的参数一致。
3.1.4 采样掩码一致性
在 RL 训练中通常使用 Top-p 或 Top-k 采样来保证生成质量。但这会导致 和 的动作空间不匹配(因为截断了低概率 Token),违反重要性采样的原则。
Keep Sampling Mask 策略在训练期间将 采样时使用的截断掩码应用到 上,确保两者的动作子空间一致。
3.2 专家模型蒸馏
DeepSeek-V3.2 首先针对特定领域(数学、编程、逻辑推理、Agent 任务等)训练专门的专家模型。每个专家模型都经过大规模 RL 计算。然后,利用这些专家模型生成领域特定的数据,用于蒸馏到最终的通用检查点中。实验表明,这种方法可以有效消除通用模型与领域专家之间的性能差距。
4. Agent
DeepSeek-V3.2 在 Agent 领域的改进主要集中在如何将强大的推理能力(Thinking)融入到工具调用(Tool-use)场景中,并通过大规模合成数据进行训练。
4.1 工具使用中的思维
DeepSeek-R1 证明了思维过程(Chain-of-Thought)能显著提升解题能力。DeepSeek-V3.2 旨在将这种能力扩展到 Agent 场景。
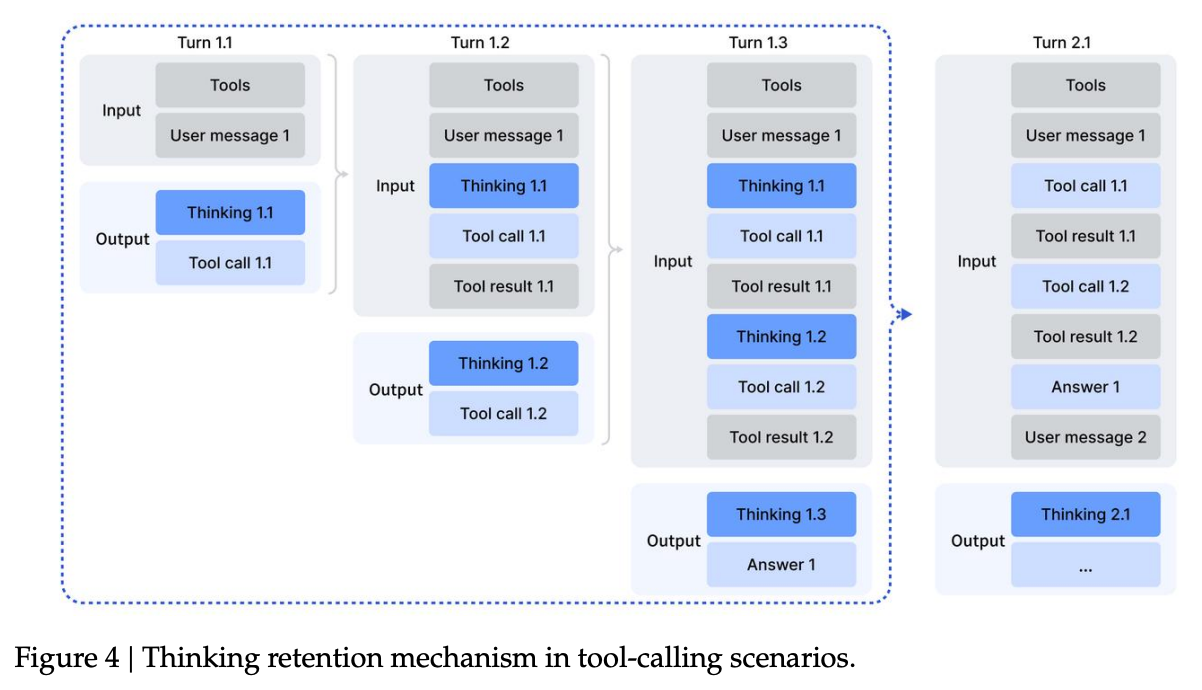
4.1.1 上下文管理策略
直接在多轮对话中保留所有的思维内容会导致 Token 消耗过大。DeepSeek-V3.2 采用了一种针对工具调用场景的上下文管理机制:
-
思维保留:如果后续消息仅与工具相关(例如工具输出),则保留思维内容。 -
思维丢弃:仅当新的用户消息引入时,才丢弃历史思维内容。 -
工具历史保留:无论思维内容是否被丢弃,工具调用的历史及其结果始终保留在上下文中。
4.1.2 冷启动
为了整合推理数据(非 Agent)和非推理 Agent 数据,DeepSeek-V3.2 采用了精心设计的 Prompt 工程进行冷启动。通过系统提示词(System Prompt),明确要求模型在给出最终答案或调用工具之前进行推理,并使用 <think></think> 标签包裹推理过程。
4.2 大规模 Agent 任务合成
为了增强模型的鲁棒性,DeepSeek-V3.2 构建了一个包含真实环境和合成环境的大规模 Agent 训练集。
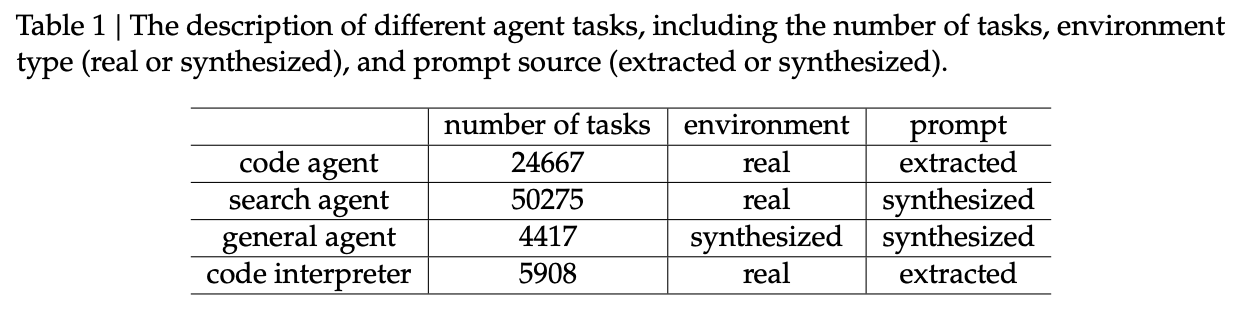
4.2.1 Search Agent
采用基于 DeepSeek-V3.2 的多 Agent 流水线生成数据:
-
实体采样:从大规模 Web 语料库中采样长尾实体。 -
问题构建:Agent 利用搜索工具探索实体,整合信息生成问答对(QA Pair)。 -
答案生成:多个不同配置的 Agent 生成候选回复。 -
验证:验证 Agent 利用搜索能力进行多轮验证,仅保留 Ground-truth 正确且所有候选皆被验证为错误的样本。
4.2.2 Code Agent
基于 GitHub 的 Issue-PR 对构建大规模可执行环境:
-
挖掘与过滤:利用启发式规则和 LLM 判断过滤出高质量的 Issue-PR 对。 -
环境构建:自动化 Agent 处理依赖安装和测试执行。 -
验证标准:通过应用 Gold Patch 后的测试通过情况(F2P > 0, P2F = 0)来确认环境构建成功。
最终构建了数万个涵盖 Python, Java, C++ 等多种语言的可复现环境。
4.2.3 General Agent
利用自动化环境合成 Agent 生成了 1827 个任务导向的环境。流程如下:
-
数据准备:利用 Bash 和搜索工具获取数据存入沙盒数据库。 -
工具合成:合成特定任务的工具函数。 -
任务生成与验证:生成任务、解决方案函数和验证函数。解决方案仅能通过工具接口解题。验证函数用于校验解决方案的正确性。如果验证失败,Agent 会迭代修改方案或验证逻辑。
5. 实验结果与分析
DeepSeek-V3.2 在多个基准测试中进行了评估,涵盖英语、代码、数学、代码 Agent、搜索 Agent 和工具使用等领域。
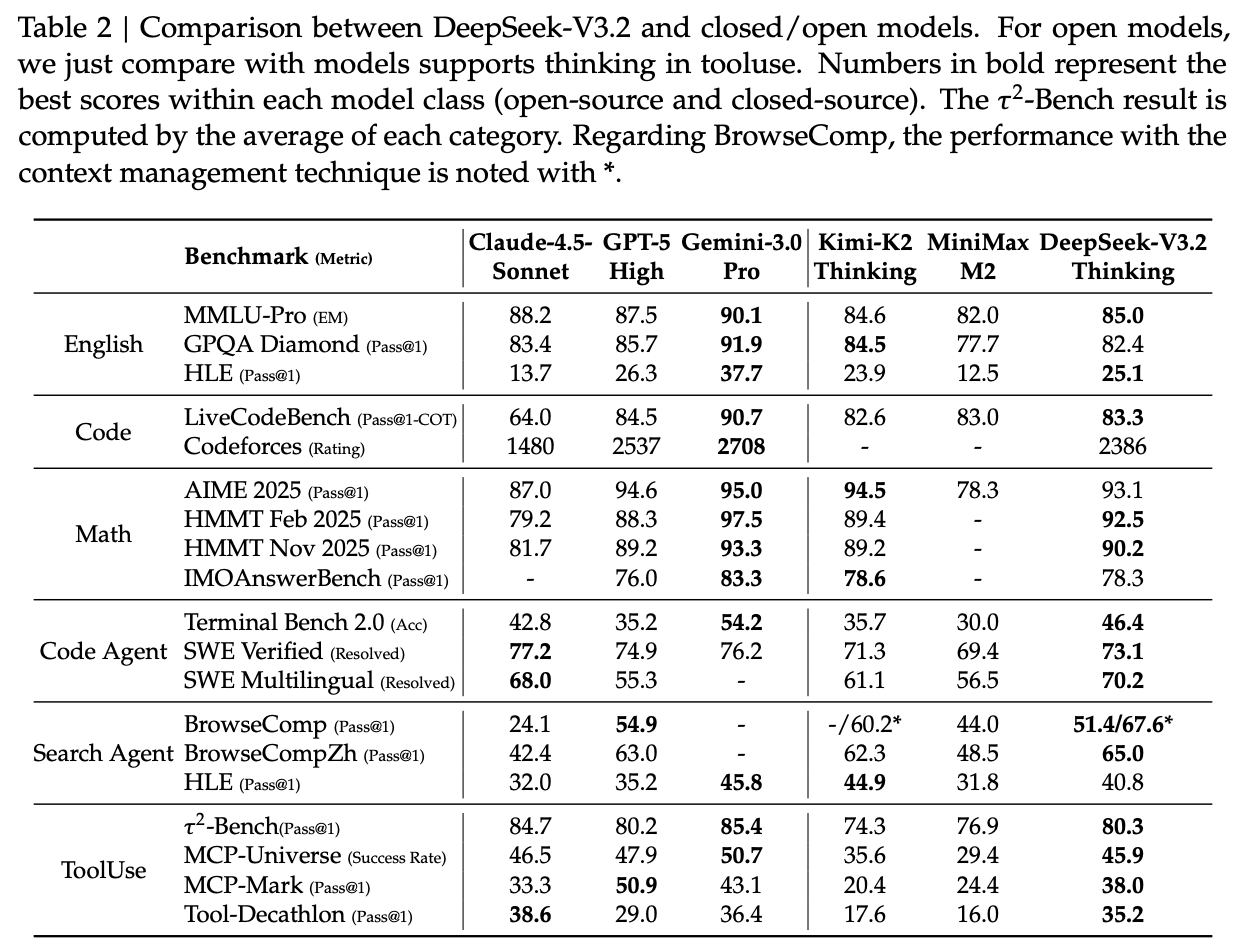
5.1 主要结果分析
-
推理能力:DeepSeek-V3.2 在 MMLU-Pro (85.0%), GPQA Diamond (82.4%), MATH 等基准上表现强劲,与 GPT-5 (High) 相当,但在部分任务上略逊于 Gemini-3.0-Pro。 -
代码能力:在 LiveCodeBench 和 Codeforces 上表现优异,接近 Gemini-3.0-Pro。 -
Agent 能力:在 SWE-bench Verified (73.1%) 和 BrowseComp (51.4/67.6*) 上,DeepSeek-V3.2 大幅缩小了与前沿闭源模型的差距。特别是对于搜索任务,上下文管理策略显著提升了性能。 -
成本效益:DeepSeek-V3.2 在实现与竞品相当性能的同时,得益于 DSA 和高效的后训练策略,具有更高的成本效益。
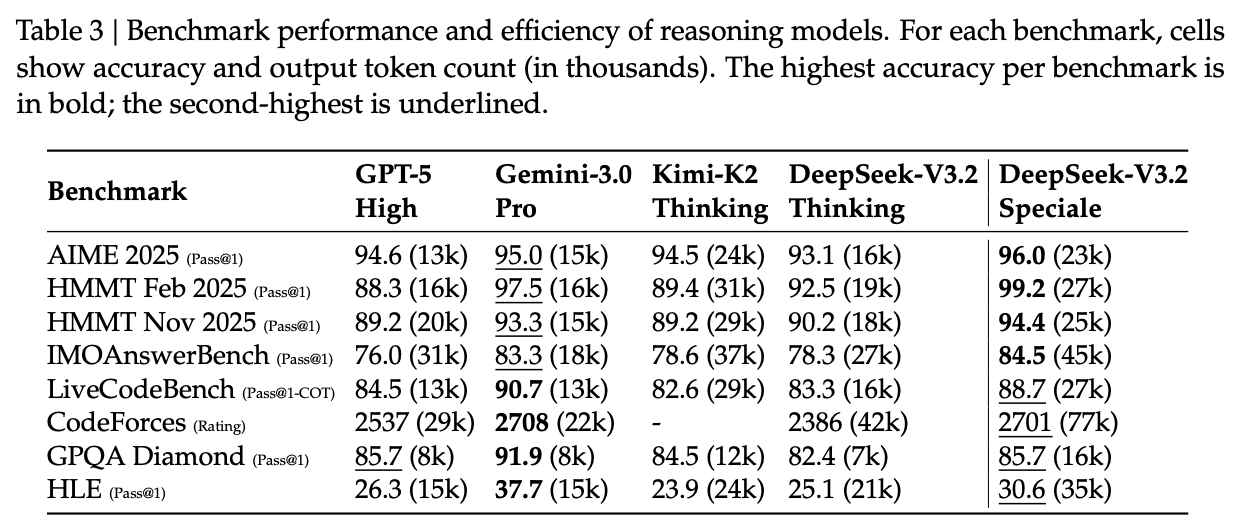
5.2 DeepSeek-V3.2-Speciale
这是一个放宽长度限制、专注于推理的高计算版本。
-
竞赛表现:在 IOI 2025 中获得金牌(第 10 名),在 ICPC WF 2025 中排名第 2。在 IMO 2025 和 CMO 2025 中均达到金牌水平。 -
性能对比:Speciale 版本在 AIME 2025 (96.0%) 和 HMMT 等数学基准上超越了 GPT-5 和 Gemini-3.0-Pro。
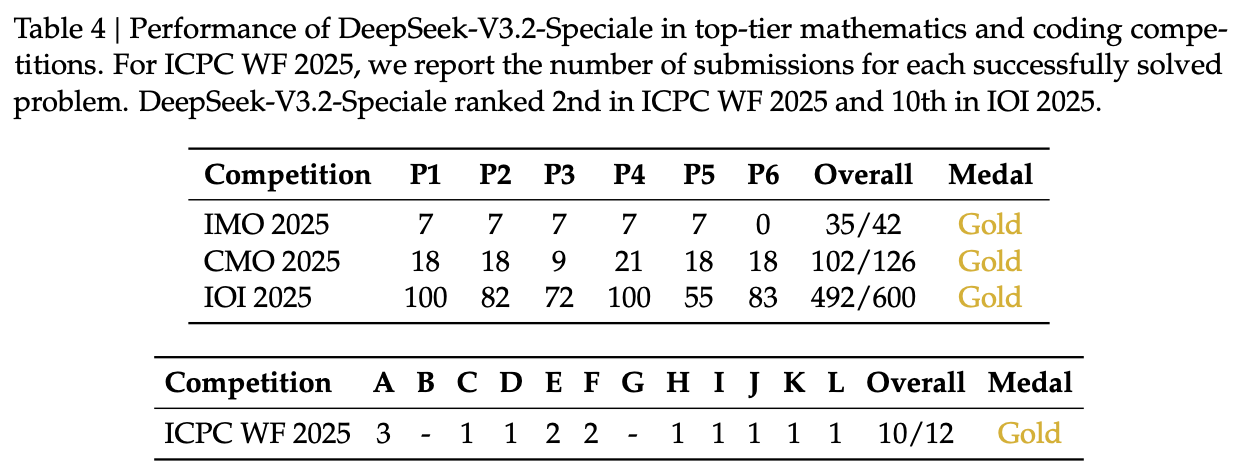
5.3 推理成本分析
得益于 DSA,DeepSeek-V3.2 在长上下文场景下的推理成本显著降低。虽然闪电索引器的引入带来了额外的 计算,但其系数极小且可利用低精度计算,结合稀疏注意力 的特性,总体上实现了端到端的加速。
6. 消融研究
6.1 合成 Agent 任务的有效性
研究通过消融实验探讨了两个问题:合成任务是否足够难?合成任务是否具备泛化性?
-
难度:DeepSeek-V3.2-Exp 在通用合成任务上的准确率仅为 12%,说明任务极具挑战性。 -
泛化性:仅在合成 Agent 任务上进行 RL 训练(非 Thinking 模式),模型在 Tau2Bench, MCP-Mark 等未见过的真实环境基准上取得了显著提升。这证明了大规模合成数据不仅能提升模型在特定任务上的表现,还能有效泛化到下游任务。
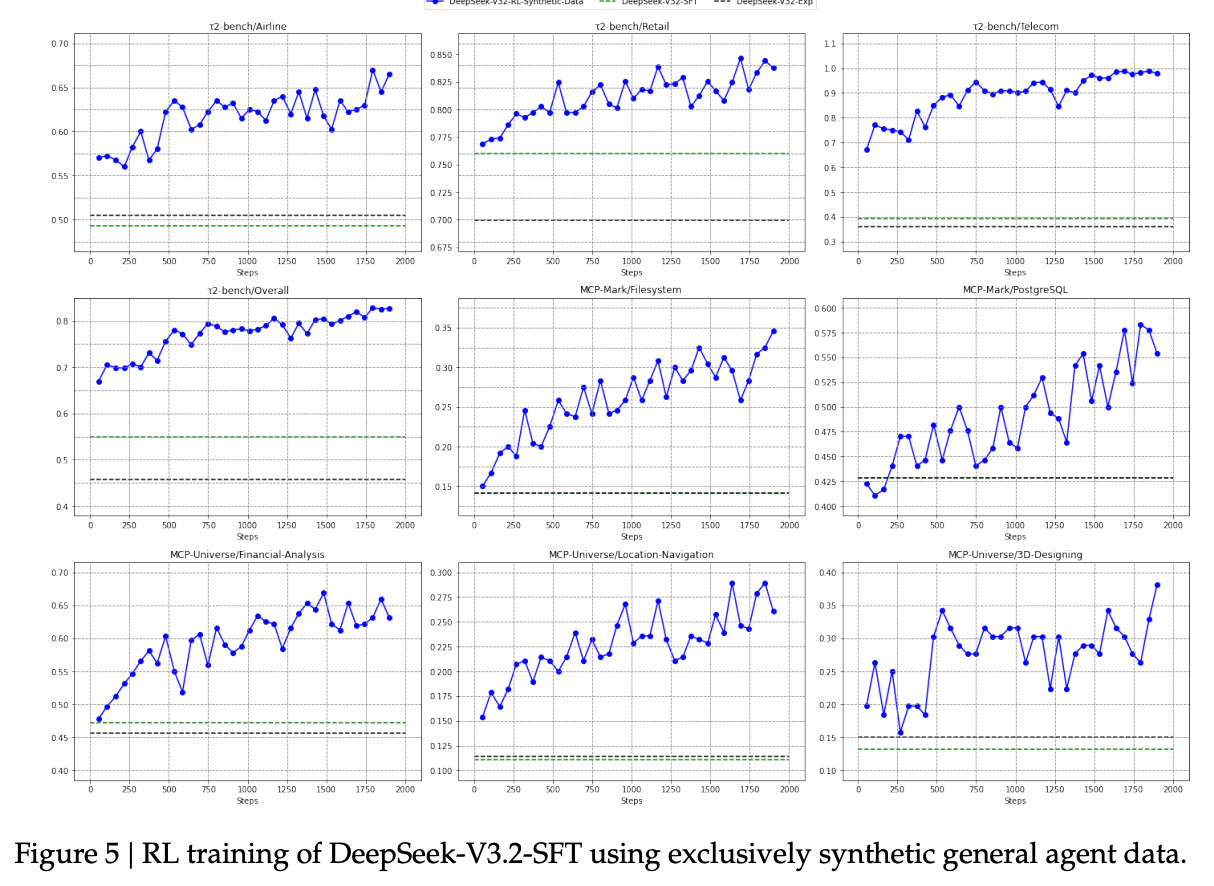
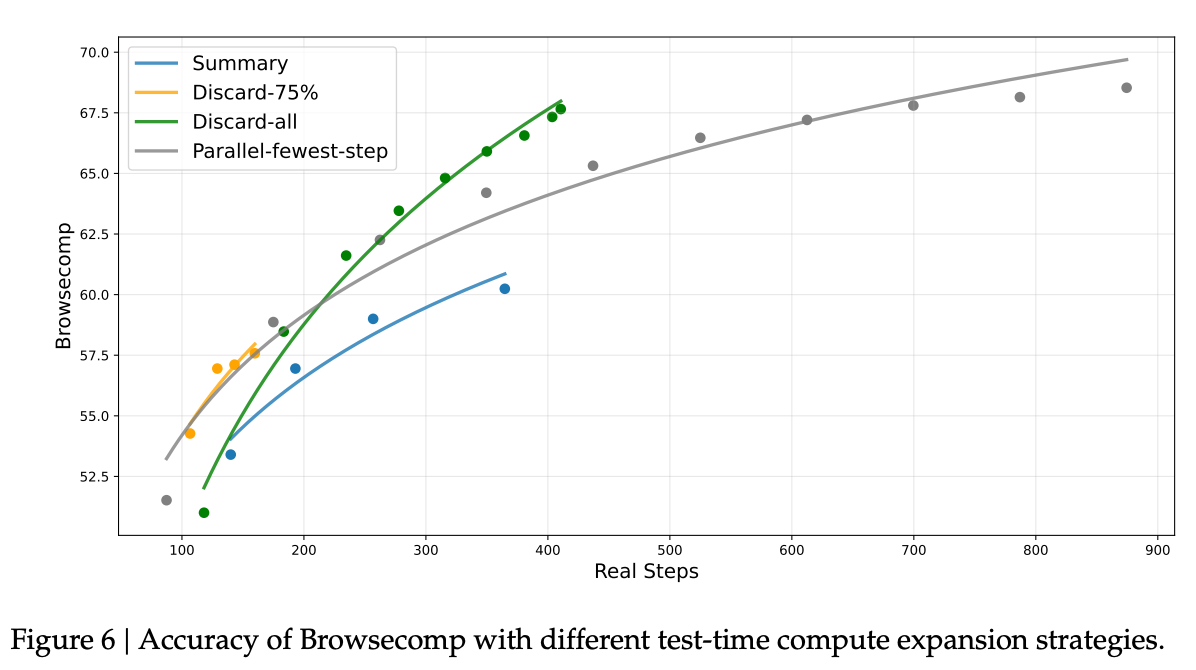
6.2 搜索 Agent 的上下文管理
针对长上下文(128K)在 Agent 任务中仍显不足的问题(特别是在冗长的搜索与推理过程中),论文提出了几种测试时(Test-time)的上下文管理策略:
-
Summary:总结溢出的轨迹并重启。 -
Discard-75% :丢弃轨迹中前 75% 的工具调用历史。 -
Discard-all:丢弃所有之前的工具调用历史。
实验结果显示,Discard-all 策略在效率和可扩展性之间取得了最佳平衡,使 BrowseComp 的分数从 53.4 提升至 67.6。这表明简单的上下文丢弃策略在特定场景下非常有效,允许模型在有限的上下文窗口内进行更多的尝试。
7. 结论与局限性
DeepSeek-V3.2 成功地缩小了开源模型与最前沿闭源模型之间的差距。通过引入 DSA,解决了长上下文下的计算效率问题;通过扩展 RL 计算预算和改进算法稳定性,释放了模型的推理潜力;通过大规模 Agent 任务合成,增强了模型在复杂环境中的实用性。特别是 Speciale 版本在国际顶级竞赛中的金牌表现,标志着开源 LLM 的一个里程碑。
然而,论文也坦诚地指出了局限性:
-
世界知识的广度:由于预训练 FLOPs 总量较少,DeepSeek-V3.2 在世界知识的覆盖面上仍落后于 Gemini-3.0-Pro 等顶级模型。未来的工作将通过扩大预训练规模来解决。 -
Token 效率:DeepSeek-V3.2 通常需要生成更长的轨迹(更多的 Token)才能达到与 Gemini-3.0-Pro 相当的输出质量。这增加了推理延迟和成本。未来的研究将致力于优化推理链的“智能密度”(Intelligence Density)。 -
复杂任务的上限:在某些极端复杂的任务上,仍略逊于最强闭源模型。这激励团队进一步完善基础模型和后训练配方。
往期文章:


