GRPO 或其变体等在线策略算法,遵循着一个严格的“生成-更新-丢弃”循环:模型根据当前策略生成一批经验数据(即解题轨迹),使用这批数据进行一次或几次梯度更新,然后便将这批数据完全丢弃。这种做法虽然保证了训练的稳定性(因为用于计算梯度的数据始终来自于当前策略),但其代价是巨大的计算资源浪费和样本效率低下。
这一瓶颈引出了一系列关键的研究问题:我们能否打破在线策略的限制,让模型从过去的所有经验中持续学习?如果可以,那么是否所有的经验都具有同等的学习价值?如何高效地识别、管理并重放那些最高价值的经验,以最大化学习效率、提升模型性能并增强训练稳定性?
来自上海人工智能实验室、澳门大学、南京大学和香港中文大学的研究者们在他们的最新论文《ExGRPO: LEARNING TO REASON FROM EXPERIENCE》中,对这些问题进行了系统性的探索,并提出了一个名为 ExGRPO (Experiential Group Relative Policy Optimization) 的新框架。该框架的核心思想是,建立经验回放缓冲区,通过特定策略识别并整合值得优先学习的中等难度问题与低熵解题路径,在不减少新知识探索的前提下,提升对已有经验的利用效率。

-
论文标题:ExGRPO: LEARNING TO REASON FROM EXPERIENCE -
论文链接:https://arxiv.org/pdf/2510.02245
1. 什么样的推理经验是“有价值的”?
ExGRPO 的设计并非凭空而来,而是基于一系列精心设计的初步研究(preliminary study)。研究者们的核心问题是:为了实现高效的经验回放,我们必须首先回答,什么样的经验最值得回放?
他们将“经验的价值”分解为两个维度进行考察:问题的价值和轨迹的价值。
1.1 问题的价值
直觉上,太简单的问题(模型总能答对)和太难的问题(模型总也答不对)可能都不是好的训练材料。为了验证这一点,研究者们设计了一个实验:
-
实验设置:使用 Qwen2.5-Math 7B 模型,在训练过程中,根据模型对每个问题的实时 rollout 正确率(online correctness rate),将问题动态地分为三类: -
简单 (Easy) :正确率 -
中等 (Medium) :正确率 -
困难 (Hard) :正确率
-
-
分组训练:他们训练了四个模型,其中三个模型分别只使用简单、中等、困难这三类问题进行训练,第四个模型作为基线,使用全部数据进行训练。
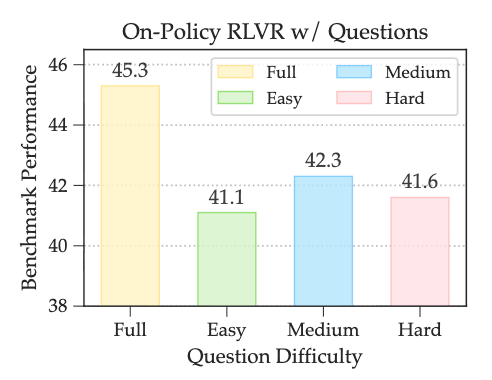
实验结果如上图所示。可以清晰地看到:
-
绝对性能最高的是使用全部数据训练的模型 (Full),其分数(45.3)显著高于任何一个单独的子集。 -
在只使用单一难度子集进行训练的三个模型中,使用“中等”(Medium) 难度问题训练的模型取得了最好的性能(42.3)。它的表现优于只使用“简单”(Easy) 或“困难”(Hard) 问题的模型。
这个结果提供了一个关键的洞察:相较于简单或困难问题,中等难度的问题为模型提供了最有效的学习信号。简单问题无法提供新的信息,而困难问题所带来的学习信号可能充满噪声,甚至对模型产生误导。
1.2 轨迹的价值
仅仅选对问题还不够。对于同一个问题,模型可能生成多条最终答案正确但推理过程质量各异的轨迹。那么,是否存在一个可以在线计算的、廉价的代理指标来衡量推理过程的质量呢?
研究者们将目光投向了熵 (Entropy) 。对于一条轨迹 ,其平均动作熵定义为:
熵衡量了模型在生成每个 token 时的不确定性。低熵意味着模型在生成这条轨迹时“胸有成竹”,每一步的选择都非常确定;高熵则意味着模型“犹豫不决”,输出的 token 具有很高的随机性。
为了验证熵与推理质量的关系,他们引入了一个外部的、更强大的 LLM(Qwen3-32B)作为“CoT 裁判”,来判断轨迹的推理过程是否逻辑正确。
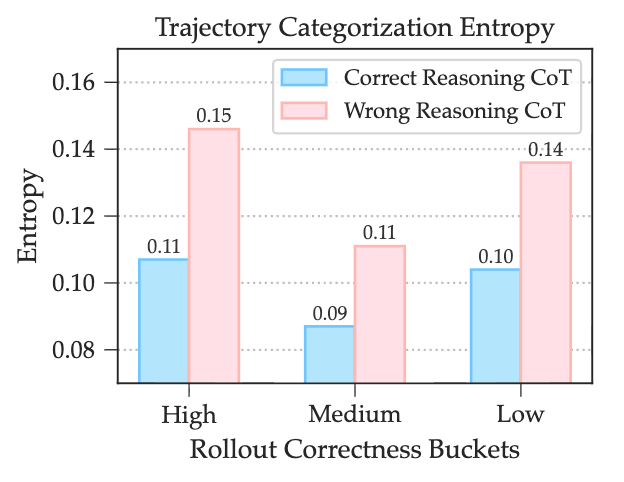
如上图所示,实验结果表明:
-
逻辑正确的推理轨迹普遍比逻辑错误的轨迹表现出更低的熵。这说明,低熵确实可以作为高质量 CoT 的一个有效代理指标。当模型遵循一条清晰的逻辑路径时,其内部状态会更加确定,从而导致 token 生成的熵值降低。
研究者们进一步分析了不同难度问题下,正确轨迹的熵分布。
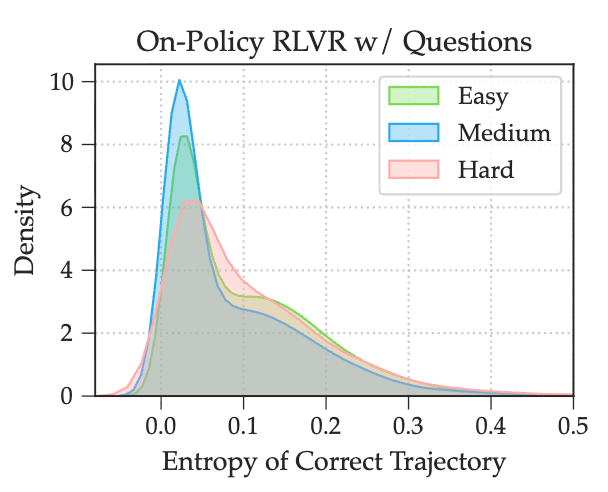
结果显示,“中等”难度问题所对应的正确轨迹,其熵值更集中地分布在较低的区间。这进一步解释了为什么中等难度问题是学习的“甜蜜点”:它们不仅提供了有效的学习信号,而且其成功的解法往往质量更高(熵更低)。
1.3 雪球效应
这些发现共同指向了一个重要风险:雪球效应 (snowball effect) 。如果在经验回放中不加区分地重放所有成功的经验,那么那些高熵的、“碰巧成功”的轨迹就会被模型反复学习。这会污染模型的训练过程,让模型学会错误的、或冗余的推理模式(例如,在解决数学问题时生成不必要的代码块),导致系统性的推理错误,就像一个滚雪球,越滚越大。
总结一下,这份初步研究得出了两个核心的设计准则:
-
问题选择:优先选择中等难度的问题。 -
轨迹选择:对于选定的问题,优先选择熵最低的成功轨迹。
2. ExGRPO
基于上述洞察,ExGRPO 框架被设计为一个包含两个核心阶段的系统:经验管理和经验化策略优化。
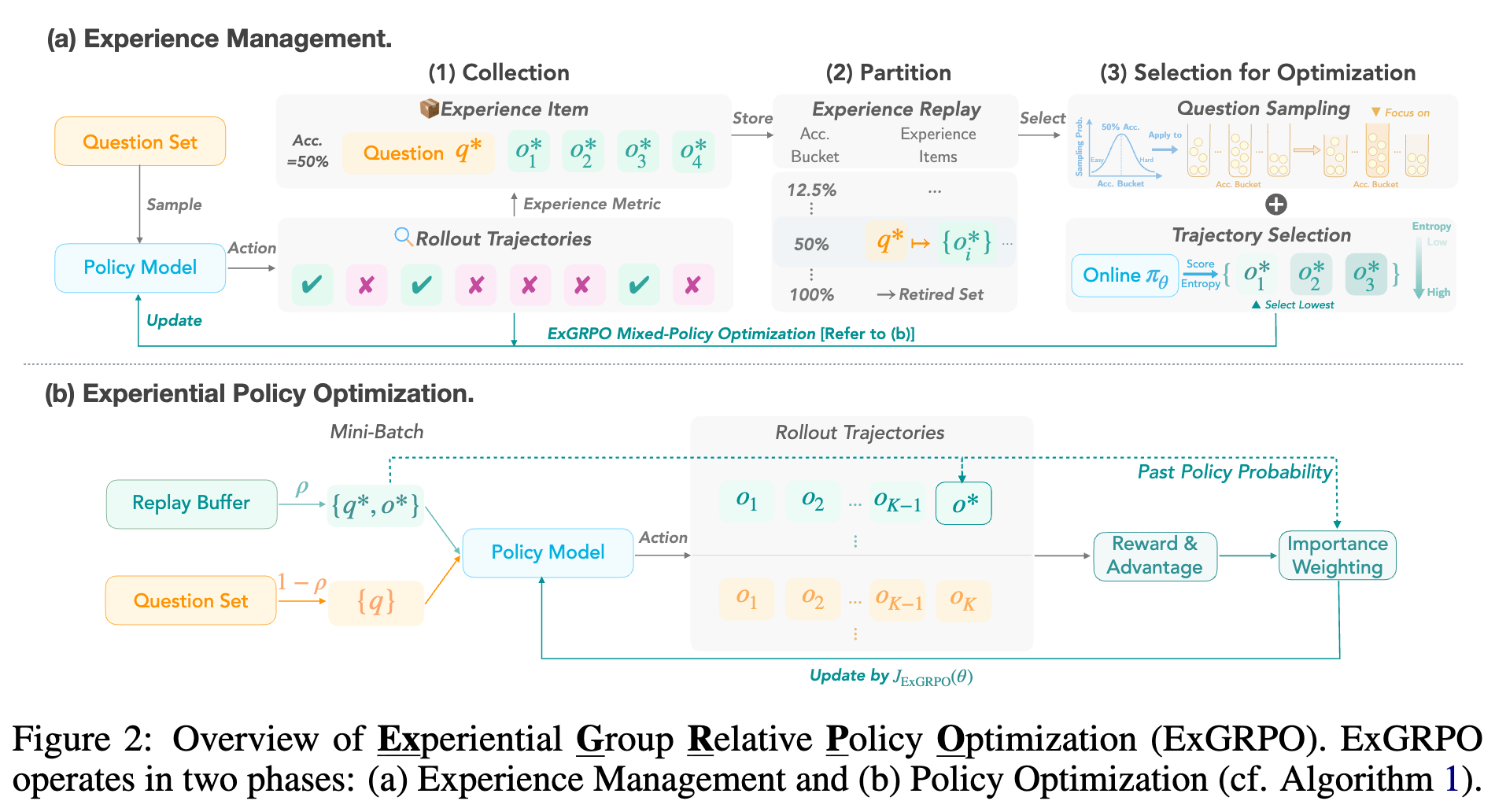
2.1 经验管理 (Experience Management)
第一步:经验收集 (Experience Collection)
-
在每次训练迭代中,当模型为一批问题生成 条轨迹后,奖励模型会验证它们。 -
所有成功的轨迹(奖励为 1)都会被存入一个经验回放缓冲区 。 -
是一个键值对结构: {问题 q* -> 成功的轨迹集合 {o*}}。 -
与此同时,每个问题 最新的 rollout 正确率 Acc(q*)也会被记录下来,作为其动态难度的衡量指标。
第二步:经验划分 (Experience Partition)
-
缓冲区 并非一个无组织的“大杂烩”。它会根据每个问题最新的正确率 Acc(q*)被逻辑地划分为多个桶 (buckets) 。例如,所有正确率在 25% 到 35% 之间的问题都属于同一个桶。 -
为了防止模型在已经完全掌握的问题上过度拟合,ExGRPO 引入了一个引退集 (Retired Set) 。一旦一个问题的正确率在 rollout 中达到 100%(即 条轨迹全部成功),它就会被移入引退集,不再参与后续的经验回放采样。这确保了优化的焦点始终在那些尚未完全解决的问题上。
第三步:经验选择 (Experience Selection)
这是经验管理的核心,它精确地执行了前述的两个设计准则。
-
问题采样 (Question Sampling) :ExGRPO 不会均匀地从缓冲区中采样问题。相反,每个桶被采样的概率正比于一个以均值为 0.5 的高斯分布:
这种采样策略使得正确率在 50% 左右的中等难度问题被采样的概率最大,而那些非常简单或非常困难的问题被选中的概率则较低。
-
轨迹选择 (Trajectory Selection) :当一个问题 被选中后,ExGRPO 并不会随机从其对应的多条成功轨迹中挑选一条。而是,它会计算当前策略 下,所有这些候选轨迹的熵,并选择那条熵最低的轨迹:
这一步确保了模型学习的是最“自信”、最可能是逻辑正确的推理路径。
经过这三步,ExGRPO 就从庞大的历史经验中筛选出了一个高质量的、用于离线策略(off-policy)更新的小批量数据。
2.2 经验化策略优化 (Experiential Policy Optimization)
获得高质量的经验数据后,接下来的问题是如何将它们与在线策略的探索过程结合起来,形成一个统一的优化目标。
ExGRPO 的核心是一个混合策略(mixed-policy)优化目标。在每个 mini-batch 中,数据由两部分构成:
-
在线策略样本 :从训练集中采样的新问题,用于模型的持续探索。 -
经验化样本 :通过上述“经验管理”流水线筛选出的高质量历史经验。
一个超参数 控制了经验化样本在整个 batch 中所占的比例。 时,ExGRPO 退化为纯粹的在线策略 GRPO。
其统一的目标函数 可以分解为两部分:
-
在线策略部分:这部分与标准的 GRPO 完全相同,用于探索新问题,保证模型能力的持续拓展。 -
离线策略部分:这部分是 ExGRPO 的核心创新。对于每个从经验缓冲区中采样出的样本 ,为了计算其优势,ExGRPO 构建了一个混合优势估计组 (mixed advantage estimation group) 。这个组由一条来自过去的回放轨迹 和 条由当前策略 新鲜生成的轨迹组成。
由于回放轨迹 是由过去的某个策略 生成的,与当前策略 存在分布差异,因此必须使用重要性采样 (importance sampling) 进行修正。其权重为:
最终,完整的优化目标(简化形式)如下:
2.3 保证学习稳定的关键机制
直接在低熵的回放轨迹上进行优化可能会抑制模型的探索性。为了平衡好利用(exploitation)和探索(exploration),ExGRPO 引入了两个关键的稳定机制:
-
熵保持的 Policy Shaping ( Policy Shaping for Entropy Preservation) :
传统的 PPO 或 GRPO 使用硬截断(hard clipping)来限制重要性权重 ,这可能导致梯度信息的损失。受先前研究LUFFY的启发,ExGRPO 采用了一种平滑的、非线性的 Policy Shaping 函数 来替代硬截断,尤其针对回放的经验:其中 是一个小的正常数(例如 0.1)。这个函数有很好的特性:
-
当 很小时, ,可以放大来自新颖经验的信号。 -
当 很大时, ,可以抑制那些概率过高的经验,防止模型过度自信,从而保留了一定的探索性。
这种“软”更新方式比硬截断更平滑,有助于稳定学习。
-
-
延迟启动机制 (Delayed Start Mechanism) :
在训练的最初阶段,模型的能力很弱,其生成的成功轨迹很可能是“侥幸成功”,质量不高。如果过早地启动经验回放,可能会向缓冲区中填充大量此类低质量经验。因此,ExGRPO 采用延迟启动策略:只有当训练批次的Pass@1(单次尝试成功率)超过一个预设的阈值(例如 35%)时,经验管理和回放机制才会被激活。这确保了进入缓冲区的经验具有一定的初始质量。
3. 理论分析
除了框架设计和实验验证,论文的附录部分还提供了对 ExGRPO 的理论分析,这对于理解其有效性至关重要。
3.1 经验化梯度的无偏性
一个核心问题是:在使用了混合优势估计组后,通过重要性采样修正的回放样本所贡献的梯度,是否仍然是对真实策略梯度的一个无偏估计?
定理 1 (无偏性) :在策略支持重叠的假设下(即当前策略能生成过去策略生成过的任何轨迹),对于任意可测函数 (例如策略梯度项),经过重要性权重 校正后的期望,等于完全在当前策略下采样的期望。即:
证明概要:
该证明的核心在于条件期望的分解。在给定混合组中其他 个成员的条件下,对 的期望可以写作:
这个推导说明,即使优势函数 的计算依赖于整个混合组(即 是 的函数),重要性采样校正后的梯度仍然是无偏的。这为 ExGRPO 的混合策略优化提供了坚实的理论基础。
3.2 方差分解与界定
离线策略学习通常会引入额外的方差。论文分析了经验化部分贡献的梯度 的方差。
命题 2 (方差上界) :在有界二阶矩和有界重要性权重的假设下,经验化梯度的方差满足:
其中, 是单个轨迹的梯度贡献, 是重要性权重的上界()。
这个方差界定揭示了几个关键点:
-
方差由 主导。特别是重要性权重的平方 。 -
控制方差的关键在于控制重要性权重的上界 。如果回放的经验来自与当前策略差异很大的旧策略, 就会很大,导致方差爆炸。 -
ExGRPO 的设计有助于控制 。通过选择低熵轨迹,模型被鼓励从其“典型集合”(typical set)中采样,这些轨迹与当前策略的偏差通常较小,从而天然地降低了重要性权重的值,收紧了方差界。这从理论上解释了为什么低熵选择是一个好的启发式策略。
4. 实验
论文进行了一系列详尽的实验,以验证 ExGRPO 的有效性、鲁棒性和泛化能力。
4.1 主要结果
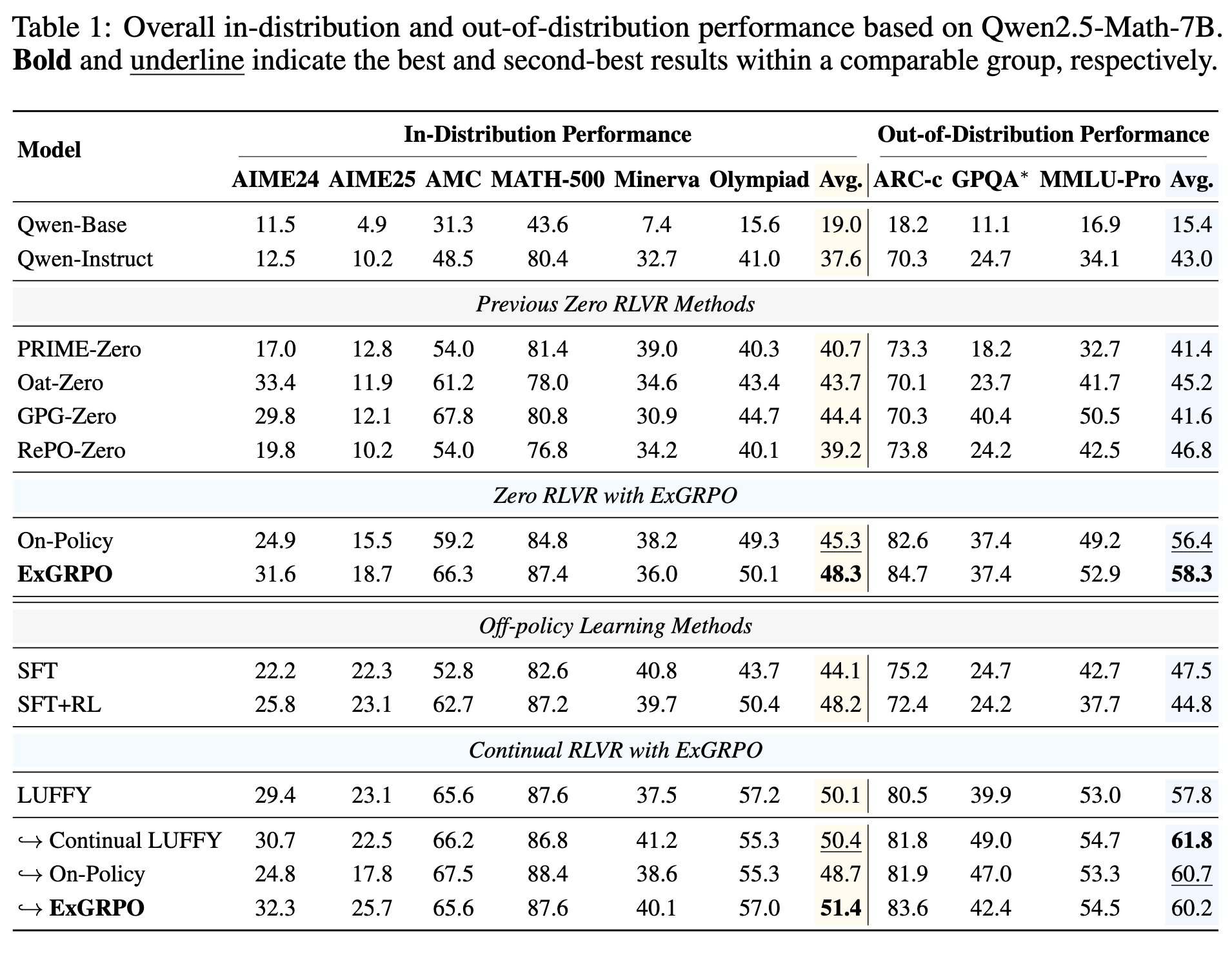
上表展示了在 Qwen2.5-Math-7B 模型上,ExGRPO 与多种 RLVR 方法的比较。
-
性能提升:与强大的在线策略基线(On-Policy)相比,ExGRPO 在分布内(in-distribution)的数学推理基准上平均提升了 3.0 个点,在分布外(out-of-distribution)的泛化推理基准上平均提升了 1.9 个点。尤其在像 AIME 这样的挑战性数据集上,提升更为显著。 -
超越其他方法:ExGRPO 的性能也优于包括 SFT、SFT+RL 以及其他几种零样本 RLVR 方法。
4.2 鲁棒性
为了证明 ExGRPO 不是特定于某个模型,研究者们在多种模型上进行了实验,包括不同尺寸(1.5B, 7B, 8B)和不同家族(Qwen, Llama)的模型。
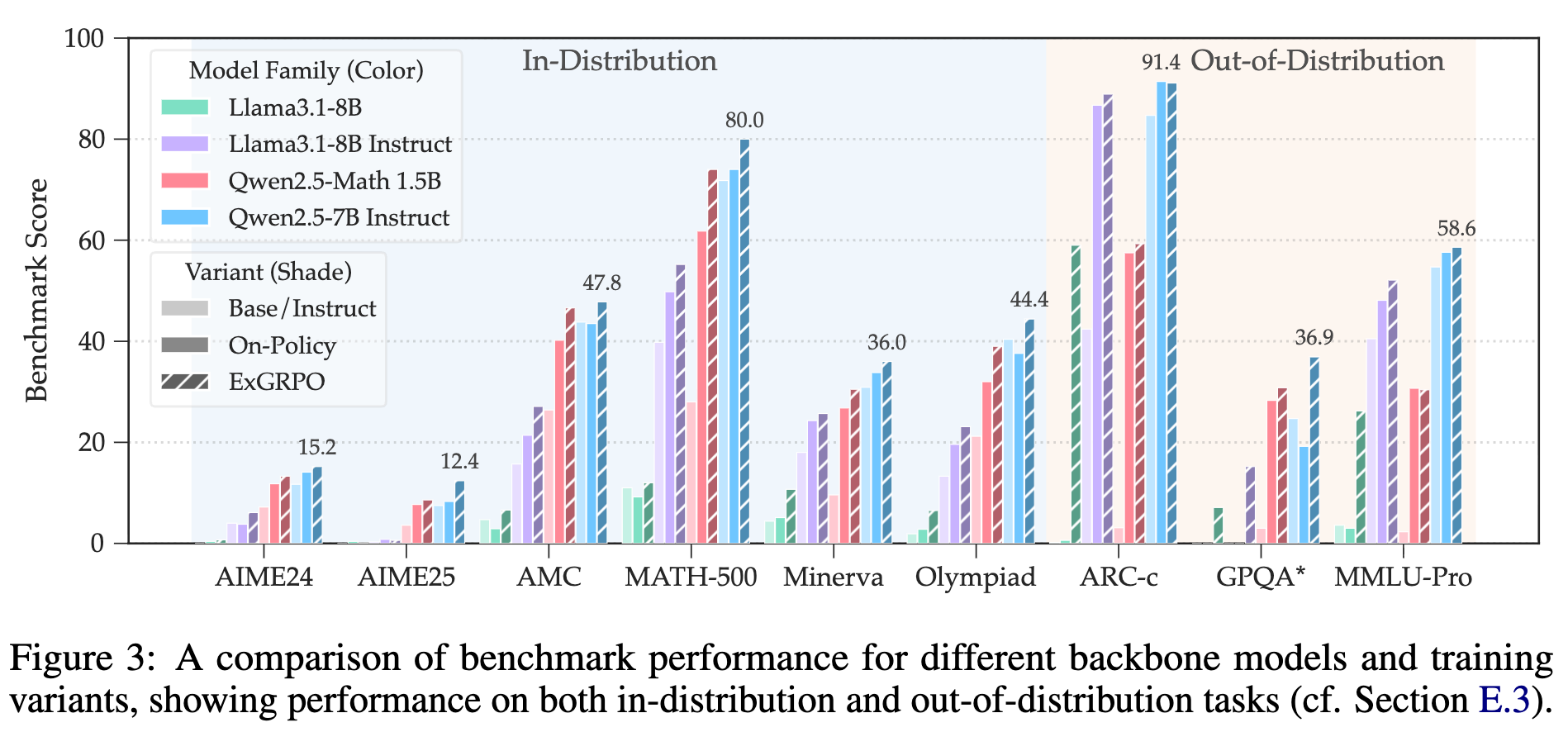
结果表明,ExGRPO 的优势是普遍的。无论是在基础模型还是在指令微调模型上,ExGRPO 都能带来一致的性能提升。
4.3 稳定性
ExGRPO 最引人注目的结果之一,是其在弱模型上表现出的训练稳定性。以 Llama-3.1 8B 基础模型为例,由于其初始推理能力较弱,在面对复杂的数学推理任务时,标准的在线策略 RLVR 训练很快就会崩溃。
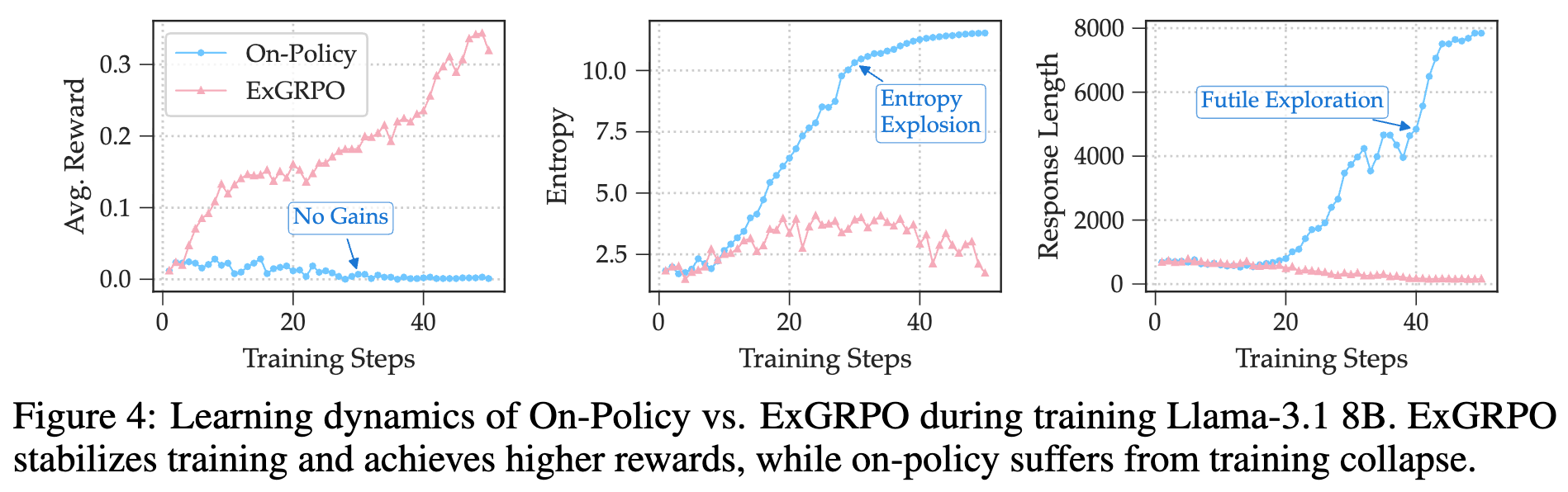
如上图的学习动态曲线所示:
-
在线策略(蓝色):模型的平均奖励在训练初期就停滞不前,无法获得有效的学习信号。随后,模型的探索信号崩溃,最终在困难的训练数据上遭遇熵爆炸(橙色曲线,熵急剧上升),这标志着训练的彻底失败。 -
ExGRPO(红色):与之形成鲜明对比,ExGRPO 允许模型在训练早期利用那些“侥幸成功”的低熵经验。通过反复回放这些宝贵的成功案例,模型得以接收到持续且有意义的奖励信号,从而被引导到一个与其当前能力相匹配的探索轨迹上。这不仅稳定了学习过程,防止了过早崩溃,还最终实现了奖励的稳步提升。
这个实验有力地证明了,经验回放,特别是有原则的经验回放,对于在能力有限的模型上进行 RLVR 训练至关重要。
4.4 消融实验
为了探究 ExGRPO 成功的根源,论文进行了一系列消融实验,移除了框架中的关键组件,以观察其性能影响。
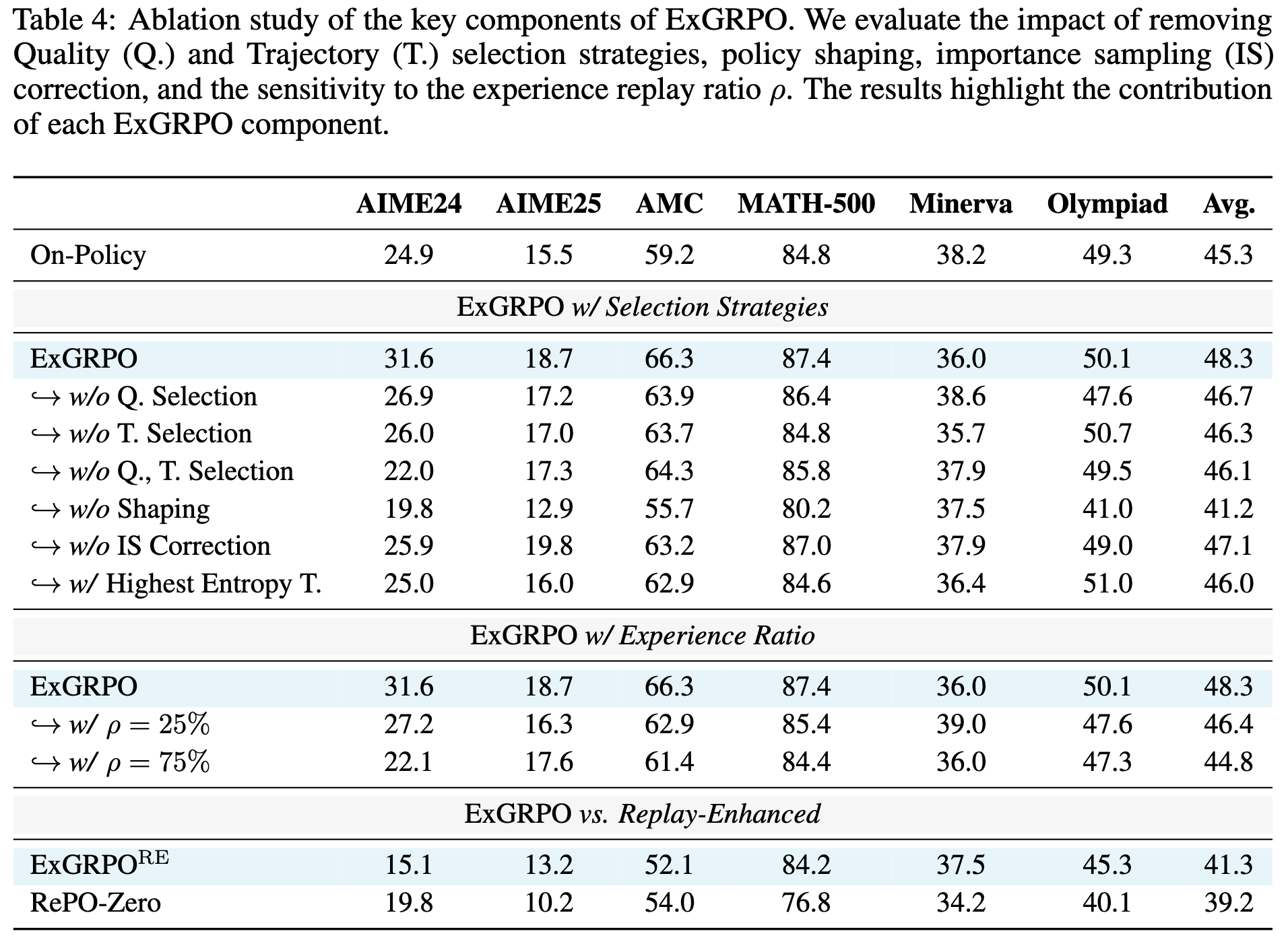
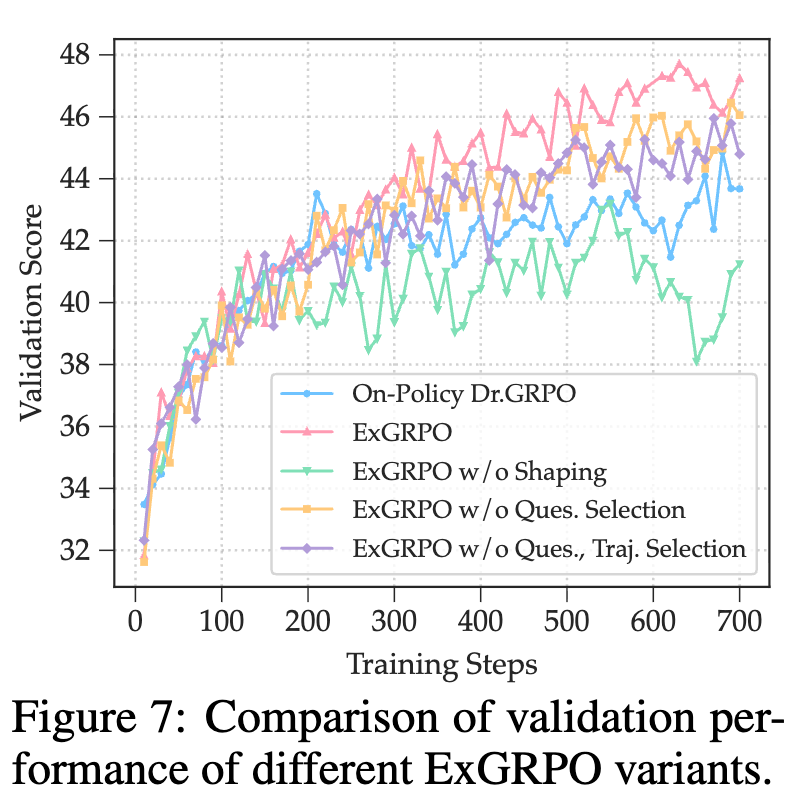
-
移除选择策略:如果移除问题选择(即随机采样问题)或轨迹选择(即随机采样轨迹),性能都会出现下降。这证实了基于难度和熵的选择策略是有效的。 -
调整经验比例 :将 从 50% 调整为 25% 或 75% 都会导致性能下降。 时,经验利用不足; 时,过度依赖历史经验,探索不足,导致“经验固化”。这表明在探索和利用之间取得平衡是关键。 -
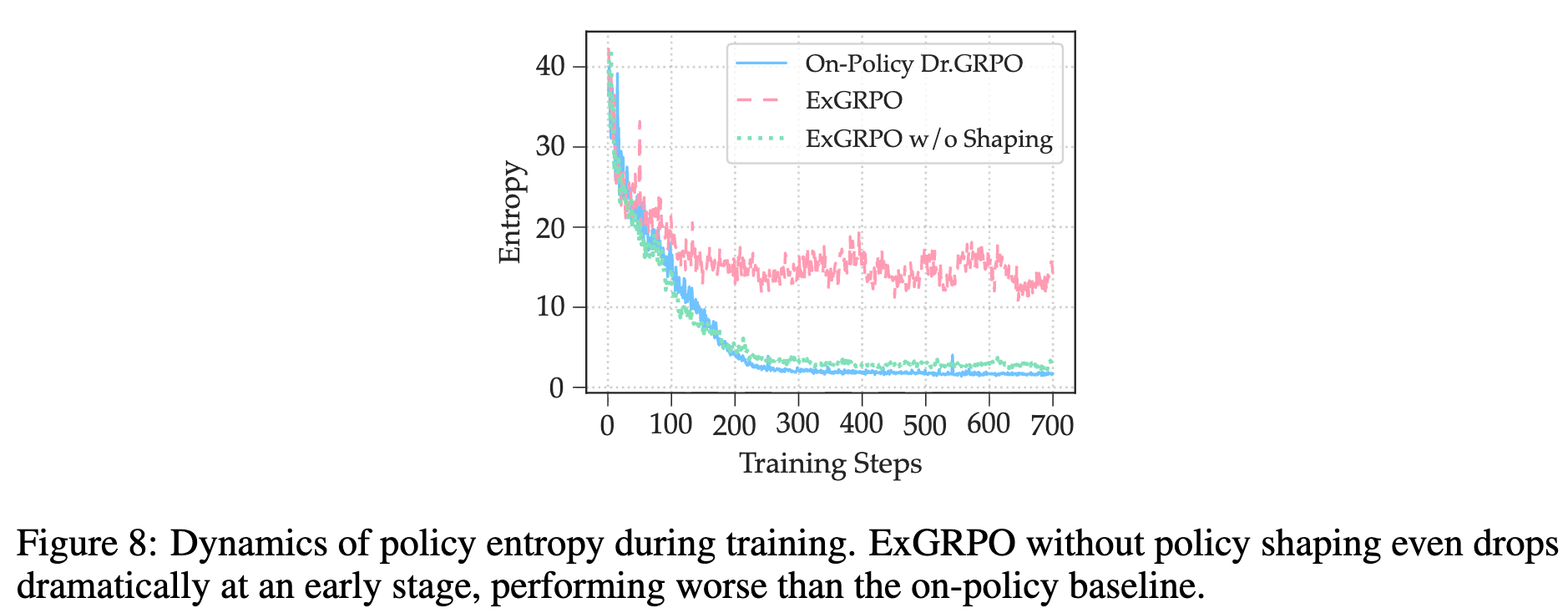
移除 Policy Shaping :移除 Policy Shaping 函数会导致性能大幅下降。如下图的熵动态所示,没有 Policy Shaping 的模型(绿色曲线)虽然熵在早期下降,但很快就无法维持探索,性能远差于基线。
4.5 数据效率分析
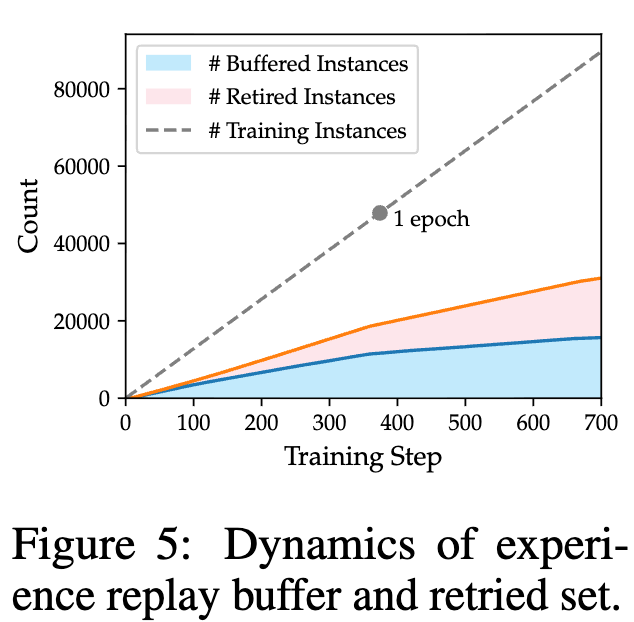
上图展示了训练过程中回放缓冲区和引退集大小的动态变化。可以看到,随着训练的进行,越来越多的问题被模型掌握并进入引退集,这使得训练可以自动地将重心转移到更难的问题上。
一个值得注意的细节是,当经验比例 时,ExGRPO 在每个训练步骤中接触到的“新鲜”在线策略数据,只有纯在线策略基线的一半。然而,即便如此,它依然取得了更好的性能。这充分说明了 ExGRPO 显著提升了数据利用效率,通过深度挖掘历史经验的价值,弥补了探索广度的不足。
往期文章:


