对于大型语言模型(LLMs)而言,生成与输入源或已知事实不符的内容,即“幻觉”(Hallucination),是阻碍其在关键应用中落地部署的核心障碍之一。早期研究多将幻觉检测任务建模为一个二元分类问题:判断一段文本整体上是否包含幻觉。然而,这种粗粒度的判断在许多真实场景中是不够的。例如,在生成式问答或报告摘要等任务中,用户不仅需要知道模型是否犯了错,更需要精确定位到具体是哪些句子、短语甚至词汇出现了事实性错误。这便引出了一个更具挑战性也更具实用价值的任务:幻觉范围检测(Hallucination Span Detection)。
幻觉范围检测要求模型不仅做出判断,还要“指认”幻觉内容在文本中的具体起止位置。这不再是一个简单的分类任务,而是一个复杂的多步决策过程。模型需要逐一审视生成内容中的每一个信息点,将其与源文档进行比对,并做出精准的边界判断。这个过程天然地与“推理”(Reasoning)能力紧密相连——模型需要像一个事实核查员一样,通过一系列中间步骤,系统性地分析、比对、验证,最终得出结论。
这一观察自然地引出了一个核心问题:显式的、可学习的推理过程能否帮助模型更好地完成幻觉范围检测任务?如果可以,我们应该如何设计一个有效的学习框架来训练这种推理能力?
来自苹果的论文《Learning to Reason for Hallucination Span Detection》中,对上述问题进行了系统性的探索。他们提出了一种名为 RL4HS (Reinforcement Learning for Hallucination Span Detection) 的新框架,该框架创新性地运用强化学习,并设计了与任务目标高度一致的范围级别(span-level)奖励函数,直接激励模型学习用于幻觉定位的推理链条。研究表明,通过这种方式学习到的推理能力,显著优于传统的监督微调(Supervised Fine-Tuning, SFT)方法和依赖通用推理能力的预训练模型。此外,论文还深入剖析了强化学习在此任务中遇到的“奖励不平衡”(Reward Imbalance)问题,并提出了类别感知策略优化(Class-Aware Policy Optimization, CAPO)算法予以解决。

1. 背景
在深入技术细节之前,我们首先需要理解为什么幻觉范围检测本质上是一个推理任务。传统的二元幻觉检测,通常依赖于模型对文本的整体语义理解。例如,一个模型可能会学习到某些语言模式或语义特征与幻觉高度相关,从而做出“是”或“否”的判断。然而,这种全局性的判断忽略了局部信息的精确对齐。
幻觉范围检测则要求更高的粒度。给定一段源上下文 和模型生成的文本 ,任务目标是识别出所有在 中但不受 支持的文本片段 。每一个这样的片段 都由其在 中的起始和结束位置定义。为了完成这个任务,模型必须执行一系列精细的操作:
-
事实拆解:将生成文本 分解为一系列独立的事实性断言(factual claims)。 -
信息溯源:对于每一个断言,在源上下文 中寻找支持性证据。 -
对齐验证:精确判断断言与证据之间是否存在逻辑一致性。如果存在偏差、夸大或完全捏造,则判定为幻觉。 -
边界界定:准确地标出幻觉断言在原始文本 中的起始和结束字符位置。
这个流程与人类进行事实核查的过程高度相似,每一步都依赖于逻辑推理。因此,让模型学会生成中间的思考步骤,即“思维链”(Chain-of-Thought, CoT),似乎是提升其性能的有效途径。
研究者们首先通过一个初步实验验证了这一假设。他们选取了 Qwen2.5-7B 和 Qwen3-8B 等模型,在 RAGTruth 数据集上比较了使用 CoT 和不使用 CoT 两种提示(prompting)方式进行幻觉范围检测的性能。实验中,他们让模型对同一个输入进行 次采样,并从 个输出中选出最优结果。
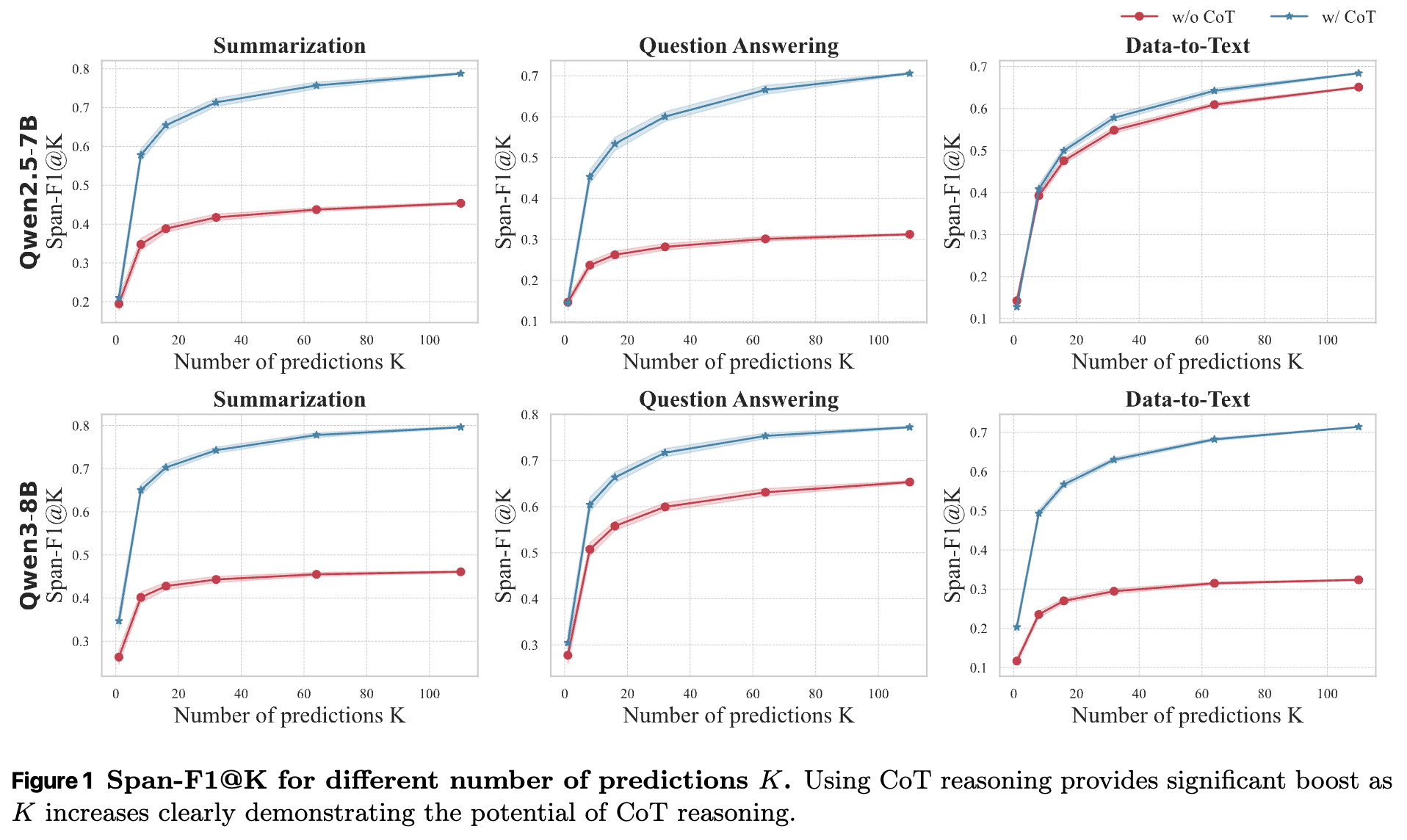
实验结果如上图所示。当采样次数 时,CoT 推理带来的提升有限,甚至没有提升。但是,随着 的增加,使用 CoT 的模型性能(以 Span-F1@K 指标衡量)显著超越了不使用 CoT 的模型。这揭示了一个重要现象:尽管单次 CoT 推理的路径可能不完美,但通过多次采样,模型有能力生成至少一个正确的推理过程和答案。这为利用强化学习来放大和提炼这种内在的推理潜力提供了明确的动机。既然模型“知道”什么是好的推理,那么我们就可以设计一个学习机制,引导它更稳定地生成那个最优的推理路径。
2. RL4HS
受到上述发现的启发,研究者们提出了 RL4HS 框架,其核心思想是利用强化学习,通过一个精心设计的奖励函数,直接优化模型的推理过程,使其更擅长定位幻觉范围。
2.1 算法选择:组相对策略优化 (GRPO)
在具体的 RL 算法上,研究者们选择了组相对策略优化(Group Relative Policy Optimization, GRPO)。与更常见的近端策略优化(Proximal Policy Optimization, PPO)相比,GRPO 在处理语言生成任务时具有一些独特的优势。
PPO 算法通常需要训练一个独立的价值网络(Value Network)来估计当前状态的预期回报。这个价值网络的训练本身可能不稳定,且需要大量样本。GRPO 则巧妙地绕开了价值网络。它的核心思想是:对于同一个输入,让模型生成一组(group)多个候选输出,然后在组内进行相对比较。
具体来说,GRPO 的优势函数 定义如下:
其中, 表示一个完整的生成轨迹(即推理过程和最终答案), 是该轨迹获得的奖励。 是 所在的那一组生成结果的集合。 和 分别是组内所有轨迹奖励的均值和标准差。
这个公式的直观解释是:一个轨迹的好坏,不是由其绝对奖励值决定的,而是由它在当前这一组候选者中的相对排名决定的。如果一个轨迹的奖励高于组内平均水平,它的优势函数就是正的,策略网络就会朝着增加其生成概率的方向更新。反之亦然。
通过这种组内归一化的方式,GRPO 将奖励信号从绝对数值转换为了相对排序信号,这使得学习过程更加稳定,尤其适合那些奖励函数本身尺度不固定或难以精确定义的任务。
2.2 奖励设计:可验证的 Span-F1 奖励
RL 框架的灵魂在于奖励函数的设计。奖励函数必须准确地反映任务的最终目标。对于幻觉范围检测,最终的评估指标是 Span-F1,它综合了预测的精确率(Precision)和召回率(Recall)。
研究者们将 Span-F1 直接用作奖励函数。给定模型预测的幻觉范围集合 和真实的幻觉范围集合 ,奖励 定义为:
其中,Span-F1 的计算方式如下:
令 为所有预测范围覆盖的字符索引集合, 为所有真实范围覆盖的字符索引集合。
这个奖励函数的设计非常直观:
-
当文本中没有幻觉,且模型也正确地预测没有幻觉时(即预测的范围列表为空),给予满分奖励 1。 -
在其他所有情况下,奖励值就是预测范围和真实范围之间的 F1 得分。
这种设计确保了 RL 的优化目标与任务的最终评估指标完全对齐。
3. 奖励不平衡与“hacking”行为
在应用上述 GRPO 和 Span-F1 奖励的框架后,研究者们发现了一个微妙但严重的问题:模型在训练过程中倾向于变得“保守”,即过度预测“无幻觉”。这种行为被称为“奖励黑客”(Reward Hacking),指的是模型找到了一个最大化奖励的“捷径”,但这个捷径并没有真正解决任务的核心挑战。
3.1 问题的根源:奖励函数的不对称性
问题出在任务和奖励函数的内在不对称性上。
-
对于“无幻觉”的样本:模型的任务相对简单。它只需要输出一个空的幻觉列表,就可以轻松获得高奖励(在真实情况也无幻觉时,奖励为 1)。 -
对于“有幻觉”的样本:模型的任务要困难得多。它必须精确地定位幻觉的起始和结束位置。哪怕只错一个字符,F1 分数也可能会大幅下降。
这种难易度的差异,导致在 GRPO 的组内比较中,预测“无幻觉”的轨迹(只要猜对)往往能获得比那些尝试定位幻觉但不够完美的轨迹更高的相对优势。
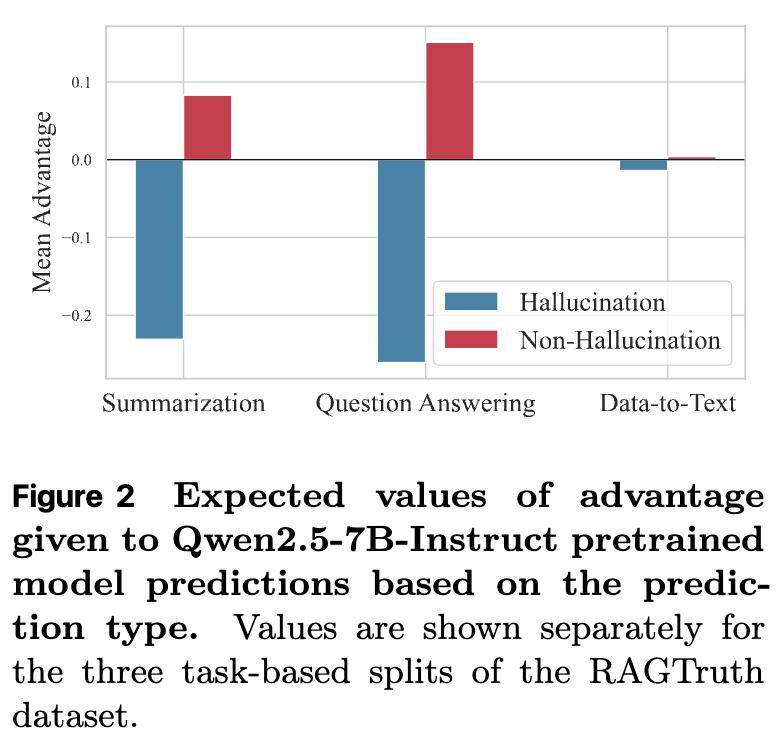
上图清晰地展示了这个问题。该图统计了在训练初期,模型不同类型的预测(预测有幻觉 vs. 预测无幻觉)所获得的平均优势值。可以看到,无论是在摘要、问答还是数据到文本生成任务中,“无幻觉”预测获得的平均优势值都显著高于“有幻觉”预测。这意味着,GRPO 的学习信号在系统性地鼓励模型做出更保守的预测。
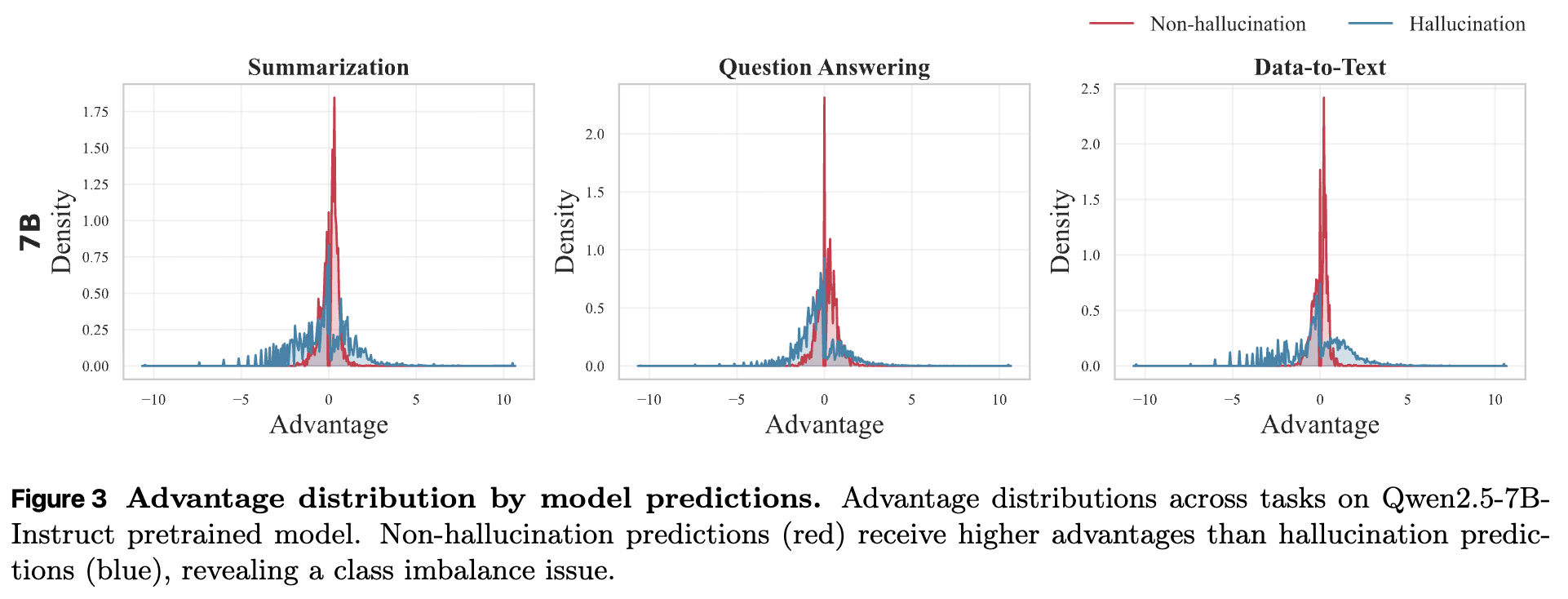
上图进一步展示了两种预测类型下优势值的完整分布。红色曲线(无幻觉预测)的分布重心明显偏右(正优势值),而蓝色曲线(有幻觉预测)的分布则更偏向左侧(负优势值)。这导致策略更新会抑制模型去识别幻觉,造成最终模型虽然精确率(Precision)很高(因为它只在非常有把握时才预测幻觉),但召回率(Recall)很低(漏掉了大量真实存在的幻觉)。
3.2 类别感知策略优化 (CAPO)
为了解决奖励不平衡问题,研究者们对 GRPO 进行了改进,提出了类别感知策略优化(Class-Aware Policy Optimization, CAPO)。
一个看似直接的解决方法是降低“无幻觉”样本的奖励值,例如,当 时,奖励值从 1 降为一个较小的数。然而,由于 GRPO 的优势函数计算中包含了标准化步骤(减去均值,除以标准差),这种对奖励的直接缩放会被“抵消”掉,无法从根本上改变组内的相对排序。
CAPO 的做法更为精巧。它不是修改奖励本身,而是在计算优势函数之后,对属于特定类别的样本的优势值进行缩放。具体来说,对于那些属于“无幻觉”类别的样本,其计算出的优势函数 会被乘以一个缩放因子 (其中 ):
通过引入这个缩放因子(实验中取 ),CAPO 人为地“拉低”了无幻觉预测所能获得的优势值,使得有幻觉预测和无幻觉预测的优势贡献更加均衡。这可以有效缓解模型“偷懒”的倾向,鼓励它更积极地去发现和定位幻觉,从而在保持高精确率的同时,提升召回率。
4. 实验
研究者们在一系列详尽的实验中验证了 RL4HS 框架和 CAPO 算法的有效性。实验基于 RAGTruth 基准数据集,该数据集包含了摘要、问答和数据到文本三种任务场景下带有精细幻觉范围标注的数据。
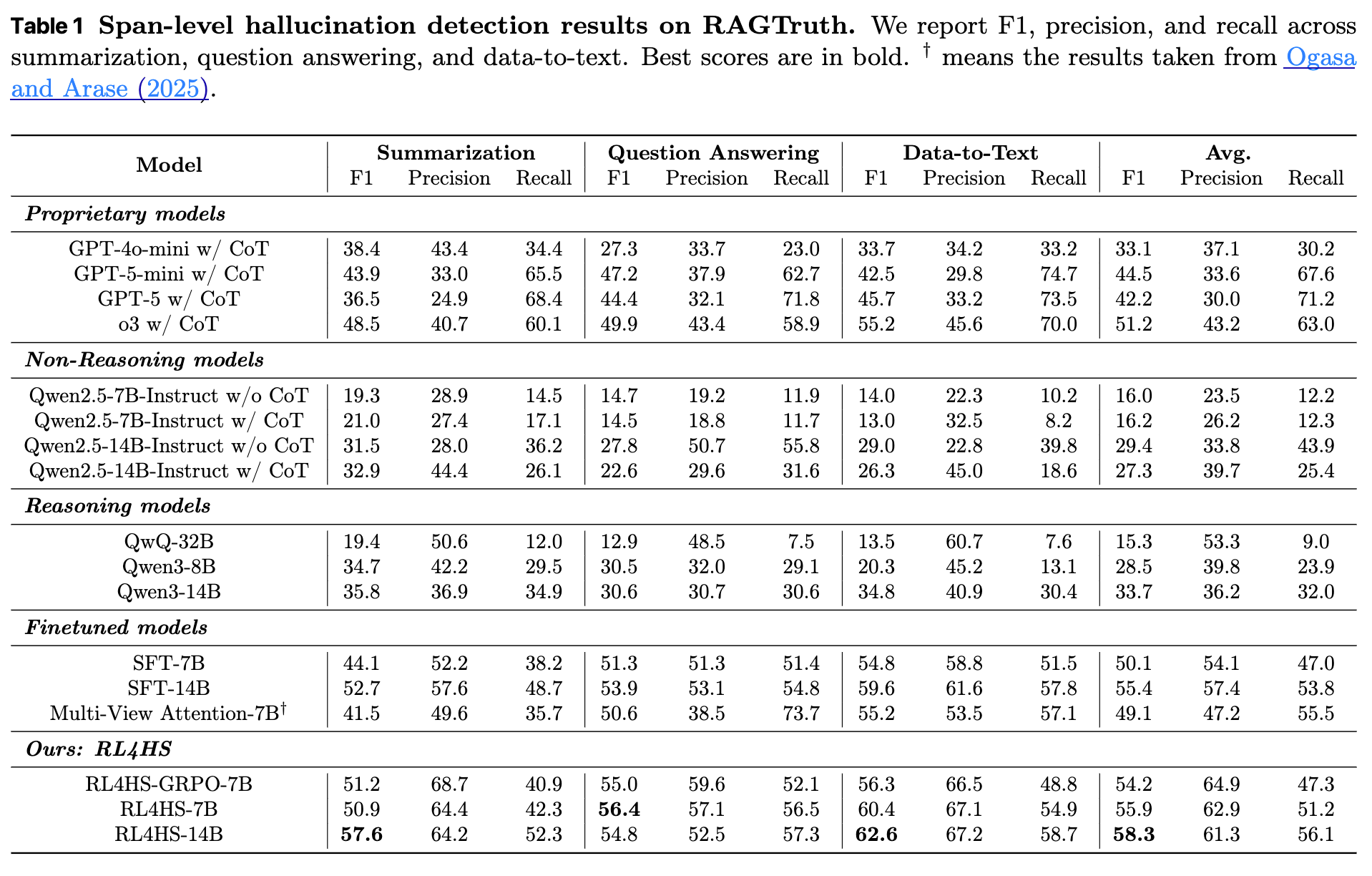
4.1 Q1:RL4HS 的整体有效性如何?
上表展示了主要实验结果。可以观察到:
-
预训练模型表现不佳:无论是直接使用(w/o CoT)还是通过 CoT 提示(w/ CoT),像 Qwen2.5-7B/14B 这样的预训练指令微调模型,在没有经过任务专属训练的情况下,F1 值普遍低于 30,说明仅靠提示工程不足以解决复杂的范围定位问题。 -
通用推理模型能力有限:像 QwQ-32B 和 Qwen3-8B/14B 这类为通用推理任务设计的模型,虽然表现优于基础指令微调模型,但其 F1 值依然落后于经过专门微调的方法。这表明,通用的推理能力无法直接、高效地迁移到幻觉范围检测这个特定领域。 -
监督微调(SFT)是强基线:SFT 在 7B 和 14B 尺度上都取得了不错的性能(F1 分别为 50.1 和 55.4),证明了使用带标注数据进行微调的必要性。 -
RL4HS 表现最优:无论是 7B 还是 14B 尺度,RL4HS 的性能都全面超越了所有基线模型,包括强大的专有模型(如 GPT-5 和 O3)。RL4HS-14B 在三个任务上的平均 F1 达到了 58.3,这充分证明了通过强化学习和范围级别奖励来学习推理过程的优越性。
4.2 Q2:CAPO 是否缓解了奖励黑客问题并平衡了P-R?
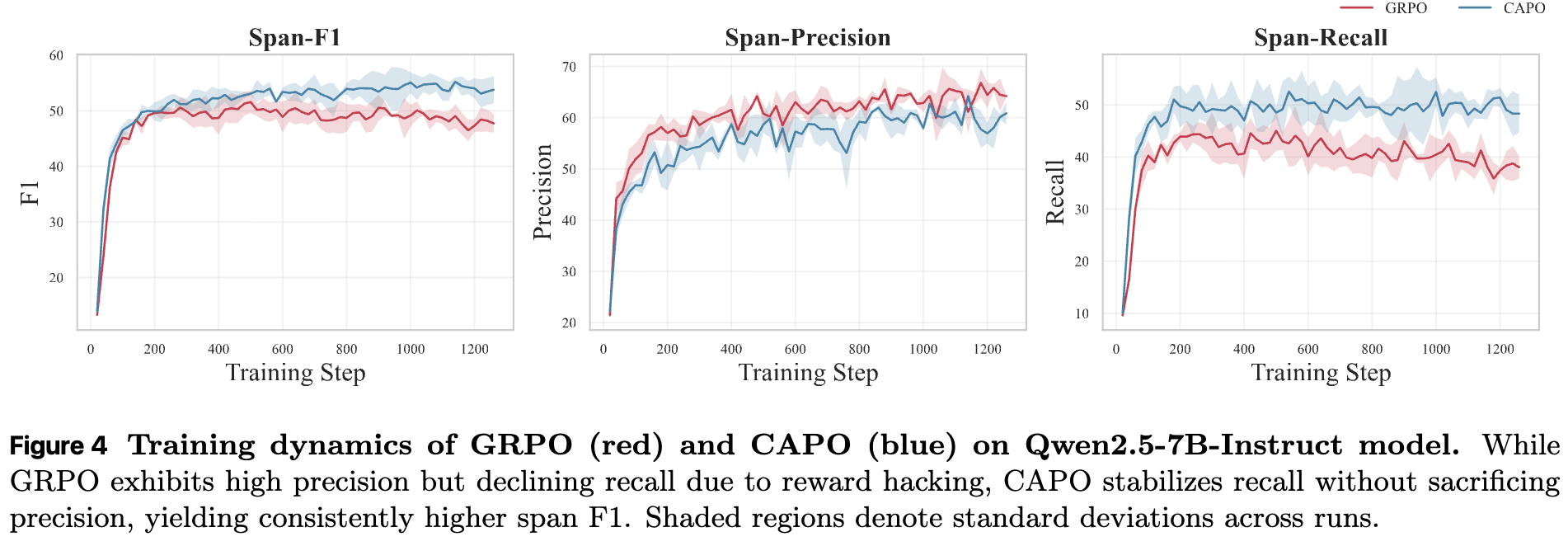
上图对比了原始 GRPO 和改进后的 CAPO 在训练过程中的动态变化。
-
GRPO 偏向高精确率、低召回率:红色曲线代表的 GRPO,在训练过程中精确率(Precision)保持在较高水平,但召回率(Recall)却持续下降。这正是“奖励黑客”行为的体现:模型为了规避犯错,越来越不愿意做出“有幻觉”的判断。 -
CAPO 平衡了精确率和召回率:蓝色曲线代表的 CAPO,通过对优势值进行重新加权,成功地稳住了召回率,使其不再下降,同时保持了具有竞争力的精确率。最终,CAPO 在整个训练过程中都获得了比 GRPO 更高的 F1 分数。
这组对比实验有力地证明了 CAPO 的有效性,它确实解决了 GRPO 在该任务上的内在偏见,实现了更好的精确率-召回率权衡。
4.3 Q3:领域内推理对于幻觉检测是否必要?
为了回答这个问题,研究者们进行了一项“留一法”(leave-one-out)的跨任务泛化实验。他们每次在一个任务上训练 RL4HS 模型(例如,只在问答和数据到文本上训练),然后在被排除的那个任务上(例如,在摘要任务上)进行测试。
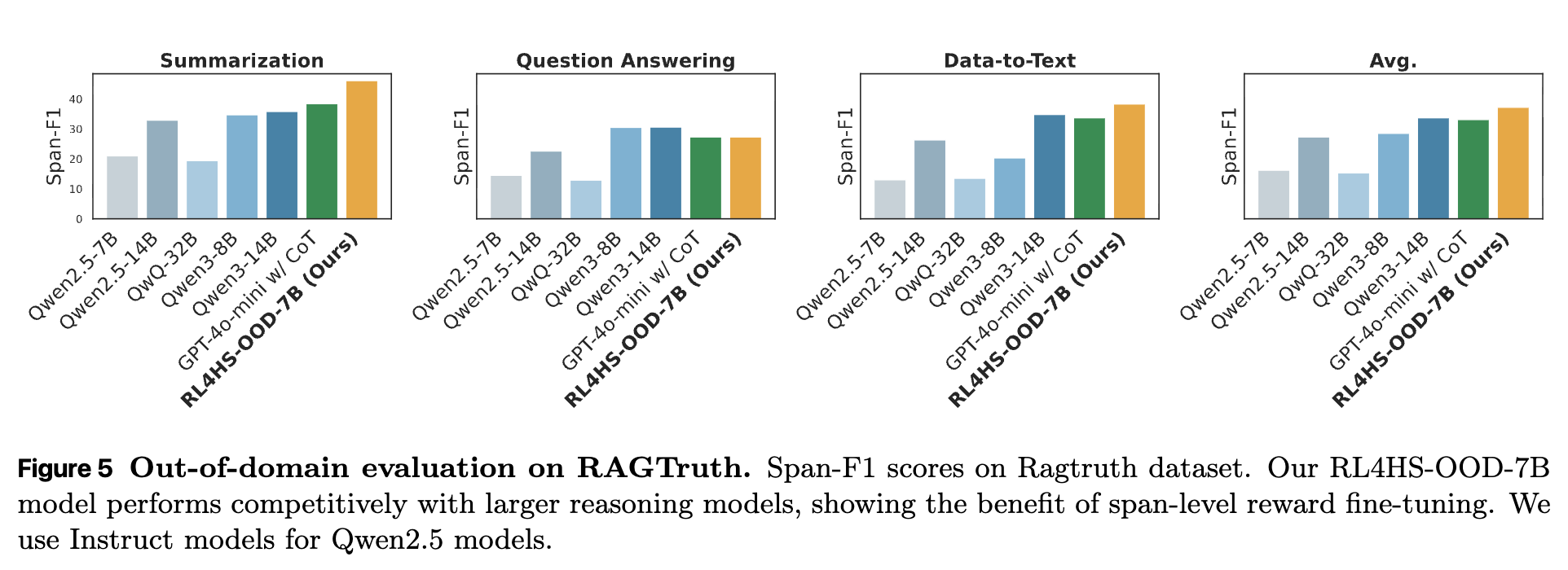
实验结果表明,尽管 RL4HS-OOD-7B(OOD 指 Out-of-Domain)的性能相比在全量数据上训练的模型有所下降,但它仍然显著优于那些通用的预训练推理模型(如 QwQ 和 Qwen3)。这说明,即便是在未见过的任务上,通过 RL4HS 在相似任务上学习到的“事实核查式”推理能力也具有一定的泛化性。更重要的是,它强调了为幻觉检测任务学习一种“领域内”的、专门的推理模式是至关重要的,通用的数学或代码推理能力并不能直接胜任这项工作。
4.4 Q5:RL4HS 究竟学到了什么样的推理?
为了更直观地理解 RL4HS 学到的能力,研究者们提供了一个案例研究。

在这个案例中,一篇机器生成的关于餐厅的文章提到该餐厅提供“餐饮服务(catering services)”。
-
预训练模型的推理:训练前的模型按部就班地检查了文章中的多个信息点,如餐厅类别、位置、提供的户外座位和Wi-Fi等,并认为它们与源数据(一份包含餐厅信息的JSON文件)一致。然而,它忽略了最关键的一点:源数据中根本没有提及“餐饮服务”。因此,它最终错误地判断文章没有幻觉。 -
RL4HS 模型的推理:经过 RL4HS 训练后的模型,其推理过程展现出一种更具批判性和结构化的核查逻辑。它的第一步就精准地抓住了“餐饮服务”这个关键断言,并直接指出这与源数据不一致,怀疑是错误信息。后续步骤虽然也检查了其他信息点,但其核心判断已经建立在对这个关键不一致的识别上。最终,它正确地将“catering services”标记为幻卷。
这个案例生动地说明,RL4HS 不仅仅是学会了生成更长的、看起来像推理的文本。它学会了一种系统性的、类似启发式规则的一致性检查流程。这种学习到的行为是功能性的、有意义的,并且与人类事实核查员的思维方式高度对齐,证明了通过范围级别奖励学习到的推理是真实、可靠且语义扎实的。
往期文章:


