07
2026/02
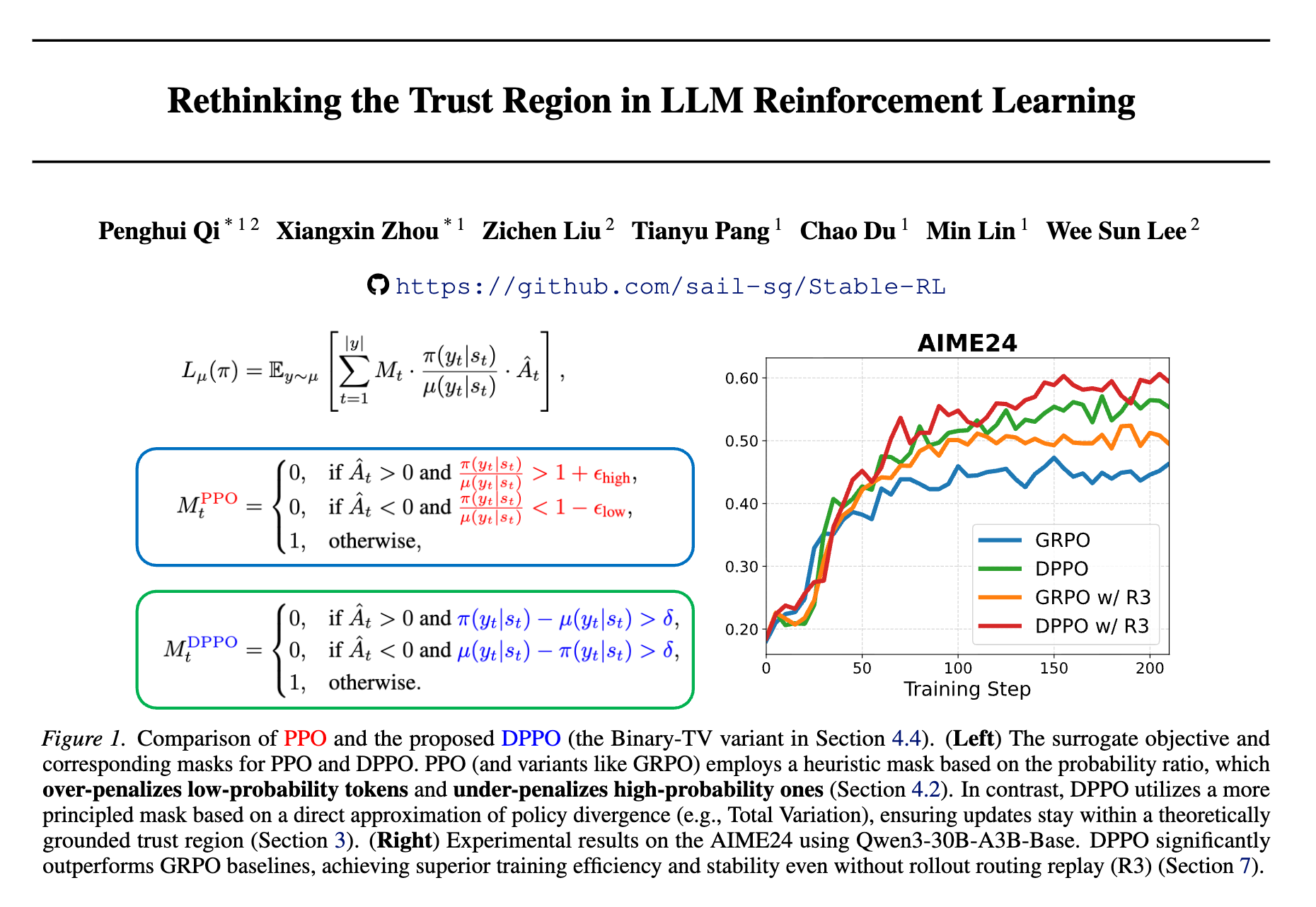
Sea AI Lab 提出 DPPO:重新审视 PPO 算法中的信任域
论文标题:Rethinking the Trust Region in LLM Reinforcement Learning
论文链接:https:
...