-
论文标题:On the Entropy Dynamics in Reinforcement Fine-Tuning of Large Language Models -
论文链接:https://arxiv.org/pdf/2602.03392
TL;DR
今天解读一篇来自通义实验室的一篇文章 《On the Entropy Dynamics in Reinforcement Fine-Tuning of Large Language Models》。
该研究针对强化微调(Reinforcement Fine-Tuning, RFT)过程中普遍存在的熵坍塌(Entropy Collapse)现象,建立了一套理论分析框架。作者推导了单个Logit更新对策略熵的一阶影响,提出了“熵判别器分数”(Entropy Discriminator Score, )这一核心概念。
理论表明,熵的变化方向由更新方向(奖励/惩罚)与 的符号共同决定。基于此,论文解释了为何奖励高置信度“安全”回复会导致探索能力丧失,并统一了现有多种熵控制方法的理论解释。最终,作者提出了两种基于 的梯度截断算法( 和 ),在不引入额外超参调试的情况下,有效缓解了熵坍塌,显著提升了模型在数学推理任务中的探索能力(Pass@K)。
1. 引言
随着 DeepSeek-R1 等工作的涌现,强化微调(RFT)已成为提升大语言模型(LLM)推理能力的关键范式。不同于监督微调(SFT),RFT 将微调过程转化为策略优化问题,通过奖励信号激励模型生成高质量回复。GRPO 作为其中的代表性算法,因其高效性和稳定性被广泛采用。
然而,RFT 面临着经典的“探索-利用”(Exploration-Exploitation)权衡难题。在实践中,研究人员经常观察到熵坍塌(Entropy Collapse)现象:随着训练进行,策略的输出分布迅速尖锐化,模型倾向于生成重复的、高置信度的“安全”回复,导致多样性丧失,最终陷入局部最优。
尽管近期出现了一些监测和调整熵的启发式方法(如熵正则化、概率加权更新等),但学界对于 RFT 过程中熵动力学(Entropy Dynamics)的内在机理缺乏原则性的理解。
-
为什么奖励高分回复往往会导致熵迅速下降? -
单个 Token 的更新如何具体影响整体策略的熵? -
如何从理论层面设计更有效的熵控制机制?
2. 理论框架:从微观视角剖析熵动力学
论文的核心贡献在于建立了一个描述 Token 级别熵变化的理论模型。作者采用自底向上的分析路径:首先量化单个 Logit 更新引起的熵变,然后扩展到 GRPO 的优化步。
2.1 基础定义
考虑词表大小为 的策略 ,在时间步 的输出 Logits 为 。概率分布 由 Softmax 函数给出:
该分布的香农熵定义为:
2.2 单个 Logit 扰动对分布的影响
为了理解动力学,首先需要分析最基本的原子操作:对第 个 Token 的 Logit 进行扰动。
设扰动为 ,其中 是标准基向量, 代表优化步长及方向( 表示奖励/增加 Logit, 表示惩罚)。
引理 3.1 (概率的一阶变化):
给定 Logit 扰动 ,概率分布 的一阶变化为:
这个引理直观地说明了 Softmax 的性质:增加某个 Token 的 Logit 会增加其概率,并按比例从其他所有 Token 处“抽取”概率质量。
2.3 熵判别器分数 与熵的一阶变化
基于引理 3.1,论文推导出了核心定理,量化了熵的变化 。在此之前,定义熵判别器(Entropy Discriminator):
对于词表中任意 Token ,定义其判别器分数为:
对于被选中的目标 Token ,简记为 。
定理 3.2 (熵的一阶变化):
在扰动 下,熵的一阶变化为:
深度解析 的物理含义:
公式 揭示了熵变化的决定性因素。熵增还是熵减,取决于更新方向 和判别器 的符号。
的符号由 决定:
-
当且仅当 :即该 Token 是相对高概率的(高于“平均”概率 )。 -
当且仅当 :即该 Token 是相对低概率的。
推论:
-
奖励高概率 Token (): 此时 ,导致 。这是导致 RFT 中熵坍塌的主要原因——模型倾向于利用已知的高概率路径,奖励这些路径会进一步降低熵。 -
奖励低概率 Token (): 此时 ,导致 。这是“探索”的过程,奖励模型未曾确信的路径会增加熵。 -
惩罚高概率 Token (): 此时 ,导致 。这迫使模型放弃当前的固守,寻找新解。
2.4 扩展至 GRPO 优化步
在实际的 GRPO 训练中,目标函数涉及优势函数 和重要性采样比率 。对于单个 Token 的更新:
其中有效步长 ( 为学习率)。
定理 3.3 (GRPO 下的熵变化):
这里出现了一个关键的变化:在完整的梯度更新下(考虑了 Logit 更新对所有 的影响),熵的变化不再仅取决于 的绝对值,而是取决于 相对于其期望 的偏差。
这一公式不仅更加精确,还揭示了动态基线的存在。系统会根据当前的策略分布状态(由 体现)来衡量特定 Token 更新对熵的影响。
关键推论 (Corollary 3.4 & 3.5):
在 On-policy 采样下,熵变化因子的期望为零:
这意味着,如果优势 与 Token 的选择无关(即随机奖励),从统计期望上看,GRPO 更新不会导致熵的系统性漂移。
然而,熵为何还是坍塌了?
结合附录 C 的分析,批量(Batch)级别的熵变化期望可以表示为:
熵坍塌的根本原因在于 优势 与 之间存在正相关性。
-
模型倾向于对高概率("Safe")的回复给出正确答案,从而获得正优势 。 -
高概率 Token 往往具有较高的 (即 )。 -
因此,协方差项 为正,导致整体 为负。
这一理论解释了 RFT 训练中“成功导致保守,保守导致坍塌”的循环。
3. 现有熵控制方法的统一视角
3.1 梯度截断 (Clipping Mechanisms)
如 PPO 或 GRPO 中的 -clip,或 DAPO 中的 Clip-higher。
-
机制: 限制重要性采样比率 的范围。 -
理论解释: 截断主要发生在 偏离 1 的时候。对于正样本(),如果 过大(意味着当前策略比采样策略更确信该 Token),通常对应 较高的情况。此时 往往较大,本应导致大幅熵减。截断机制限制了这部分更新,从而缓解了熵减。
3.2 熵正则化 (Entropy Regularization)
如 Wang et al. (2025) 提出的仅更新高熵 Token。
-
机制: 仅对 高的 Token 进行梯度更新。 -
理论解释: 高熵位置通常意味着模型不确定。根据定理 3.3,在这些位置更新正样本会减少熵,更新负样本会增加熵。通过筛选高熵 Token,实际上是在控制 的分布范围,防止极端的 Logit 更新。
3.3 概率加权更新 (Probability Weighted Updating)
如 He et al. (2025) 对低概率正样本赋予更高权重。
-
机制: 放大低 Token 的更新权重。 -
理论解释: 低概率 Token 对应 。对于正样本(),根据 ,此时 (熵增)。放大这些样本的权重,就是直接放大熵增的更新分量,从而强力对抗熵坍塌。
4. 基于熵判别器的截断 ( & )
既然 (及其相对于期望的偏差)是熵变化的精确指示器,作者提出直接利用这一指标来过滤掉那些导致熵剧烈波动的“离群”更新,特别是导致熵恶性下降的更新。
作者设计了两种截断策略,核心思想是:如果某个 Token 的熵判别器分数过于极端,就将其梯度置零(Mask)。
4.1 : Batch-Normalized Entropy-Discriminator Clipping
这是一种计算高效的方法,利用 Batch 内的统计数据进行归一化。
算法流程:
-
对于 Batch 中的所有 Token,计算其判别器分数 。 -
计算 Batch 内的均值 和标准差 。 -
生成梯度掩码 :
-
仅保留 的 Token 的梯度。
特点:
-
计算量极小(仅标量运算)。 -
不需要额外的模型前向传播。 -
通过 控制对“熵减主力军”(高 Token)的抑制。
4.2 : Vocabulary-Normalized Entropy-Discriminator Clipping
这是一种理论上更严谨的方法,直接利用定理 3.3 中的词表期望项。
算法流程:
-
计算词表中心化的分数 。 -
注: 需要利用全词表 Logits 计算,通常在计算熵时已顺带得到。
-
-
计算该中心化分数在 Batch 内的标准差 (注:根据推论 3.5,其均值期望为 0)。 -
生成梯度掩码:
特点:
-
更贴合定理 3.3 的物理意义。 -
能够更精准地定位那些相对于当前分布“异常”的更新。
5. 实验
实验主要在 Qwen2.5-7B-Instruct 和 Qwen2.5-14B-Instruct 上进行,基准数据集为 DAPO-Math-17k(包含数学推理任务)。评估指标侧重于 AIME24/25 和 DAPO500 测试集上的 Pass@K(衡量探索能力/多样性)和 Avg@K(衡量平均准确率/利用能力)。
5.1 熵动力学的实证观察
论文首先验证了 对熵变方向的预测能力。
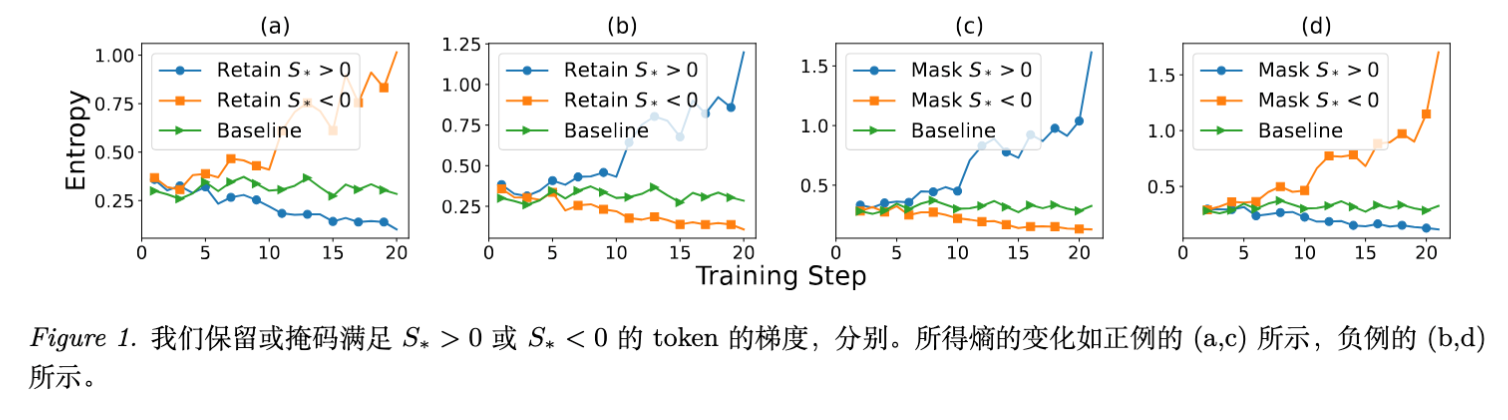
结果显示:
-
仅保留 的正样本更新,熵迅速下降。 -
仅保留 的正样本更新,熵显著上升。
这与理论预测完全一致,证明 是控制熵的有效“旋钮”。
5.2 截断方法的效果
对比 Vanilla GRPO、 和 。
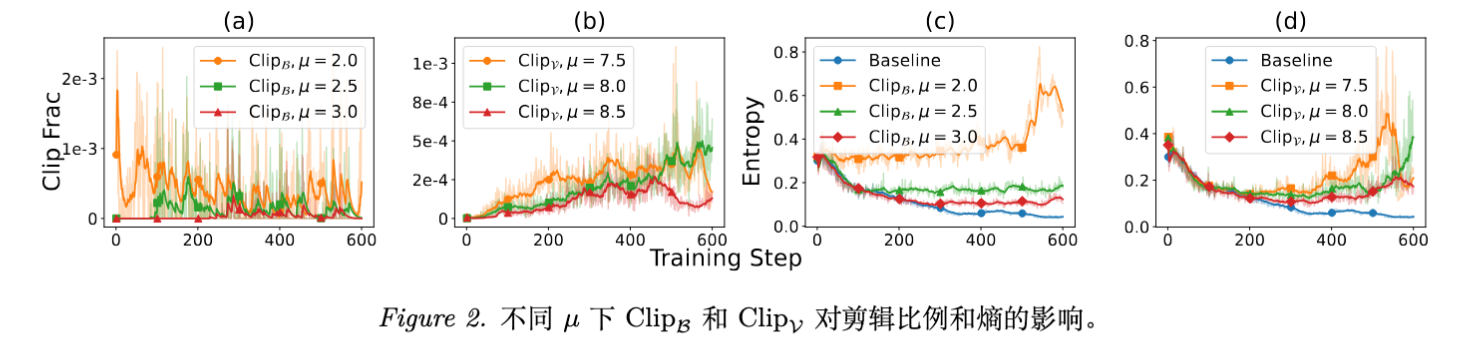
-
熵的稳定性: Vanilla GRPO 的熵在训练早期迅速下降并维持在极低水平。而 Clip 方法通过调节 ,成功将熵维持在较高且稳定的水平。 -
性能提升:
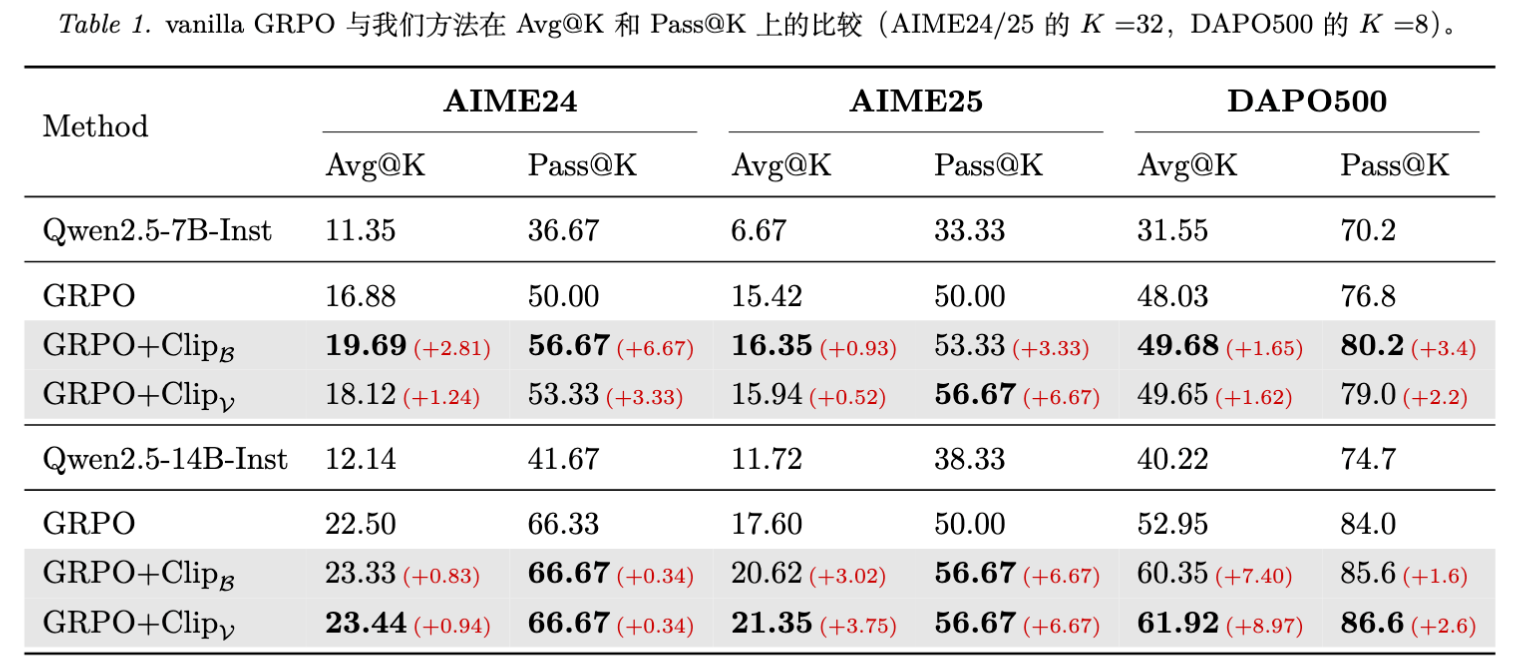
实验数据表明(以 Qwen2.5-7B 在 AIME24 为例):
-
Pass@K 显著提升: GRPO 为 50.00, 达到 56.67 (+6.67), 达到 53.33。这直接证明了模型探索到了更多样化的解题路径。 -
Avg@K 同步提升: 并没有因为保留了多样性而牺牲准确率,反而因为探索能力的增强促进了更好的利用。
5.3 探索与利用的深入分析
论文通过分析问题通过率的分布,进一步揭示了性能提升的来源。
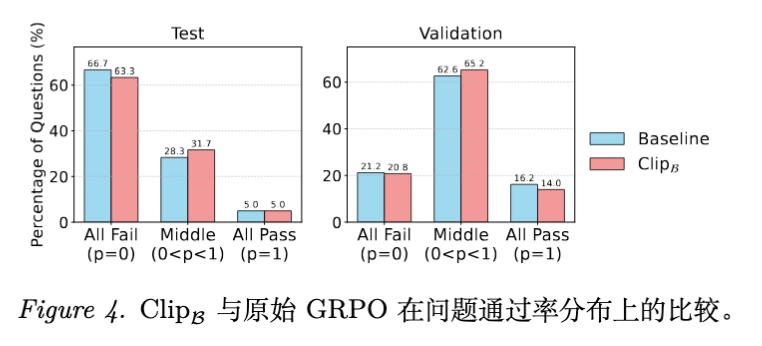
-
Vanilla GRPO: 分布呈“两极化”。大量问题要么全对(通过率1.0,过度利用),要么全错(通过率0.0,缺乏探索)。 -
Clip 方法: 中间段通过率的问题比例显著增加。这意味着模型并没有简单地记忆简单题,而是通过保持探索性,尝试解决那些原本无法解决的困难问题。
5.4 泛化性验证
-
PPO 算法: 附录实验表明,该方法同样适用于 PPO,证明了理论的普适性。 -
不同模型: 在 DeepSeek-Distill-Llama-8B 和 InternLM3-8B 上同样取得了性能提升,特别是在 InternLM 上,Clip 方法成功拯救了原本训练崩溃(Training Collapse)的情况。
更多细节请阅读原文。
往期文章: