带可验证奖励的强化学习(RLVR)能有效解决复杂任务,但在实际训练过程中面临着两大瓶颈:
-
高计算成本:为了让模型充分探索推理空间,RLVR训练过程中需要生成非常长的文本序列(即“rollout”),这要求巨大的上下文窗口(context length)。例如,训练一个4B规模的模型,上下文长度从40K逐步增加到52K,可能需要大约8000个H800 GPU小时。如此高昂的成本限制了该技术的广泛应用和研究迭代。 -
多阶段训练的性能瓶颈:一种常见的折衷方案是采用多阶段训练,即从一个较短的上下文长度开始,然后逐步增加。然而,研究表明,如果初始阶段的上下文过短,可能会导致模型性能发生不可逆的退化,最终无法达到理想的效果,也未能显著降低总体计算成本。
这两个瓶颈共同构成了一个关键的研究空白:我们能否找到一种更高效的训练策略,既能降低训练长思维链模型的成本,又能避免性能损失,甚至进一步提升模型的推理能力上限?
来自腾讯混元的论文《TFPI: Thinking-Free Policy Initialization Makes Distilled Reasoning Models More Effective and Efficient Reasoners》提供了一个新颖的视角。他们提出的无思考策略初始化(Thinking-Free Policy Initialization, TFPI) 方法,从根本上改变了模型学习推理的方式。它不再是单纯地通过模仿或试错来“正向”构建推理过程,而是引入了一个巧妙的“先忘后学”阶段:在正式进行长思维链强化学习之前,先让模型在“忘记”中间思考过程的模式下进行训练。这种看似反直觉的操作,却带来了训练效率和最终性能的双重提升。

-
论文标题:TFPI: Thinking-Free Policy Initialization Makes Distilled Reasoning Models More Effective and Efficient Reasoners -
论文链接:https://arxiv.org/pdf/2509.26226v1
1. 背景
在深入了解TFPI之前,我们首先需要理解当前训练推理模型的主流路径及其面临的挑战。
1.1 思维链蒸馏(CoT Distillation)
训练强大的推理模型,一个常见的起点是通过监督微调(Supervised Fine-Tuning, SFT)进行思维链蒸馏。这个过程通常是:
-
教师模型生成:使用一个非常强大的闭源模型(如GPT-4o)或开源的顶尖推理模型,为大量的训练问题生成带有详细推理过程(CoT)的解答。 -
学生模型学习:用这些高质量的“问题-推理过程-答案”数据对,来微调一个规模较小的开源模型(即学生模型)。
通过这个过程,学生模型可以学习到教师模型的推理模式和知识,从而具备初步的“慢思考”能力。这类经过SFT蒸馏的模型,是后续强化学习的一个理想起点,相比于从原始的预训练模型开始,能够更快地收敛并达到更好的效果。
1.2 RLVR 过长的Rollout与计算瓶颈
尽管SFT蒸馏为模型打下了良好基础,但直接对其应用RLVR会遇到一个严重问题:这些蒸馏后的模型在生成答案(即rollout阶段)时,往往会产生极其冗长的响应。这背后有两个原因:
-
模仿行为:模型在SFT阶段学习了教师模型的详尽推理风格,导致其倾向于生成长篇大论。 -
探索天性:RL训练鼓励模型进行探索,这也可能导致生成路径的进一步延长。
过长的响应直接导致了前文提到的计算瓶颈。在RLVR的每一步训练中,模型都需要完整地生成一次或多次响应,然后计算奖励并更新参数。如果响应长度达到数万个token,不仅对GPU显存提出了极高的要求,也使得整个训练过程异常缓慢和昂贵。
因此,研究的核心矛盾点在于:我们希望模型能进行长思维链的“慢思考”,但又不希望在训练的每个阶段都承受这种“慢”带来的高昂计算代价。
2. 元实验
面对上述困境,论文作者提出了一个大胆的设想:在推理过程中,中间的思考内容真的不可或缺吗?如果我们在特定阶段显式地忽略这些思考内容,会发生什么?
2.1 “ThinkingFree” 操作:从模板入手
TFPI方法的核心在于一个名为“ThinkingFree”的简单操作。让我们通过对比两种不同的输入模板来理解它。
模板1:标准的“思考模式”(Thinking Mode)
<|im_start|>system
Please reason step by step, and put your final answer within \\boxed{}.<|im_end|>
<|im_start|>user
{question (x)}<|im_end|>
<|im_start|>assistant
在这种模式下,模型被期望首先生成一步步的推理过程,最后给出答案。
模板2:“无思考模式”(Thinking-Free Mode)
<|im_start|>system
Please reason step by step, and put your final answer within \\boxed{}.<|im_end|>
<|im_start|>user
{question (x)}<|im_end|>
<|im_start|>assistant
<think>
</think>
在“无思考模式”下,输入模板中直接加入了一对空的<think>和</think>标签。这个操作明确地指示模型跳过中间的详细思考过程,直接生成最终的答案。模型仍然需要进行内部的“思考”来得出答案,但其输出的文本中将不包含这部分内容。
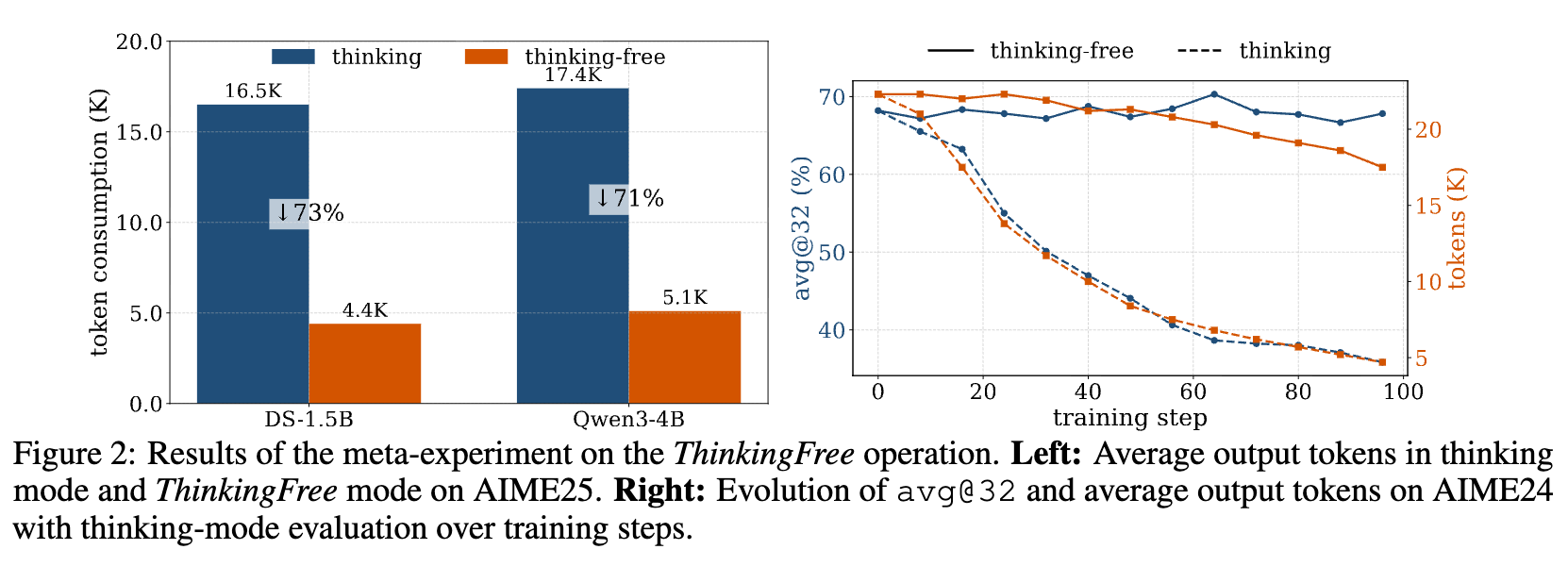
这个简单的修改带来了显而易见的好处:在推理时,token的消耗量大幅降低。实验表明(如下图左半部分所示),对于DeepSeek-Distilled-Qwen-1.5B和Qwen3-4B这两个模型,在AIME25测试集上应用ThinkingFree操作,输出的token数量减少了超过70%。
2.2 无思考训练有益于慢思考
推理时节省token是意料之中的,但真正令人惊讶的是接下来这个发现。研究者们提出了一个更大胆的问题:我们能否在RLVR训练的rollout阶段,对所有输入都应用ThinkingFree操作?这样做是否会损害模型原有的“慢思考”能力?
直觉上,在一个需要长思维链的任务上,却用短输出进行训练,似乎会破坏模型好不容易学来的推理结构,导致性能下降。然而,实验结果完全相反(上图右半部分所示):
-
在ThinkingFree模式下进行RL训练,即使用非常短的上下文长度(例如4K),当模型在标准的“思考模式”下进行评估时,其准确率不仅没有下降,反而略有提升(约2%)。 -
同时,模型在思考模式下的平均输出token数量也减少了约20%,变得更加简洁高效。 -
作为对比,如果直接在标准RLVR中使用同样短的4K上下文长度进行训练,模型的 avg@32准确率会暴跌超过40%。
这个发现是TFPI方法的基石。它表明,通过强制模型在不显式写出思考过程的情况下解决问题,反而能够以一种更高效、更鲁棒的方式,来强化其内在的推理能力。 这种训练方式不仅计算成本低廉,还能对最终的慢思考性能产生积极影响。
3. TFPI
基于上述发现,研究者正式定义了TFPI,并将其定位为一个介于SFT蒸馏和标准长上下文RLVR之间的、高效的初始化阶段。其目标是:降低rollout成本,提升推理能力上限,并加速最终的RL收敛。
3.1 TFPI的定义与目标函数
TFPI本质上是一种特殊配置的RLVR。标准的RLVR目标函数可以表示为 ,其中 是原始的带有思考提示的查询。
而在TFPI阶段,目标函数被修改为:
,其中 。
这意味着,在rollout阶段,模型生成的 个响应都是基于“无思考”版本的输入 产生的:。
相应的,RL算法(如PPO, GRPO, DAPO)中的重要性比率(importance ratio)和优势函数(advantage)也需要进行适配,以 作为条件进行计算。
值得注意的是,奖励函数 仍然基于原始问题 和完整答案 来计算,因为ThinkingFree操作不改变问题的正确答案。
3.2 完整的三阶段训练流程
一个典型的、采用TFPI的先进推理模型训练流程如下:
-
阶段一:SFT思维链蒸馏
-
目标:从教师模型那里学习基础的推理能力和模式。 -
产出:一个经过SFT蒸馏的“长思维链模型”(SFT-distilled LRM)。
-
-
阶段二:TFPI (Thinking-Free Policy Initialization)
-
目标:在低计算成本下,快速提升模型的内在推理能力,并为其后续进行长上下文RL训练做好准备。 -
过程:使用“ThinkingFree”输入进行RLVR训练。这个阶段通常也采用多阶段策略,但上下文长度非常短且增长平缓,例如从2K到4K再到8K(对于1.5B/7B模型)或从4K到8K再到16K(对于4B模型)。由于上下文短,这个阶段的计算成本远低于标准RLVR。
-
-
阶段三:标准长上下文RLVR (可选但推荐)
-
目标:在TFPI初始化的基础上,进一步释放模型在长思维链生成上的潜力,冲击性能上限。 -
过程:使用标准的“思考模式”输入和较长的上下文窗口(例如32K或48K)进行RLVR训练。
-
通过TFPI这个中间阶段,模型在进入计算昂贵的长上下文RLVR之前,已经具备了更强的推理核心和更高效的rollout行为,从而使得最后一个阶段的训练更稳定、收敛更快。
4. 实验
为了全面评估TFPI的效果,研究者们在多个模型尺寸(1.5B, 4B, 7B)和一系列权威的推理基准测试上进行了详尽的实验。
-
模型: DeepSeek-Distill-Qwen-1.5B (DS-1.5B), Qwen3-4B, DeepSeek-Distill-Qwen-7B (DS-7B) -
训练数据: Polaris-53K (一个高质量的数学推理数据集) -
评估基准: -
数学推理: AIME24/25, BeyondAIME -
多任务推理: GPQA-Diamond -
代码生成: LiveCodeBench -
指令遵循: IFEval
-
实验主要围绕以下几个核心问题展开,并得出了一系列有力的结论。
4.1 结论一:TFPI能以更低成本、更大幅度地增强模型的慢思考能力
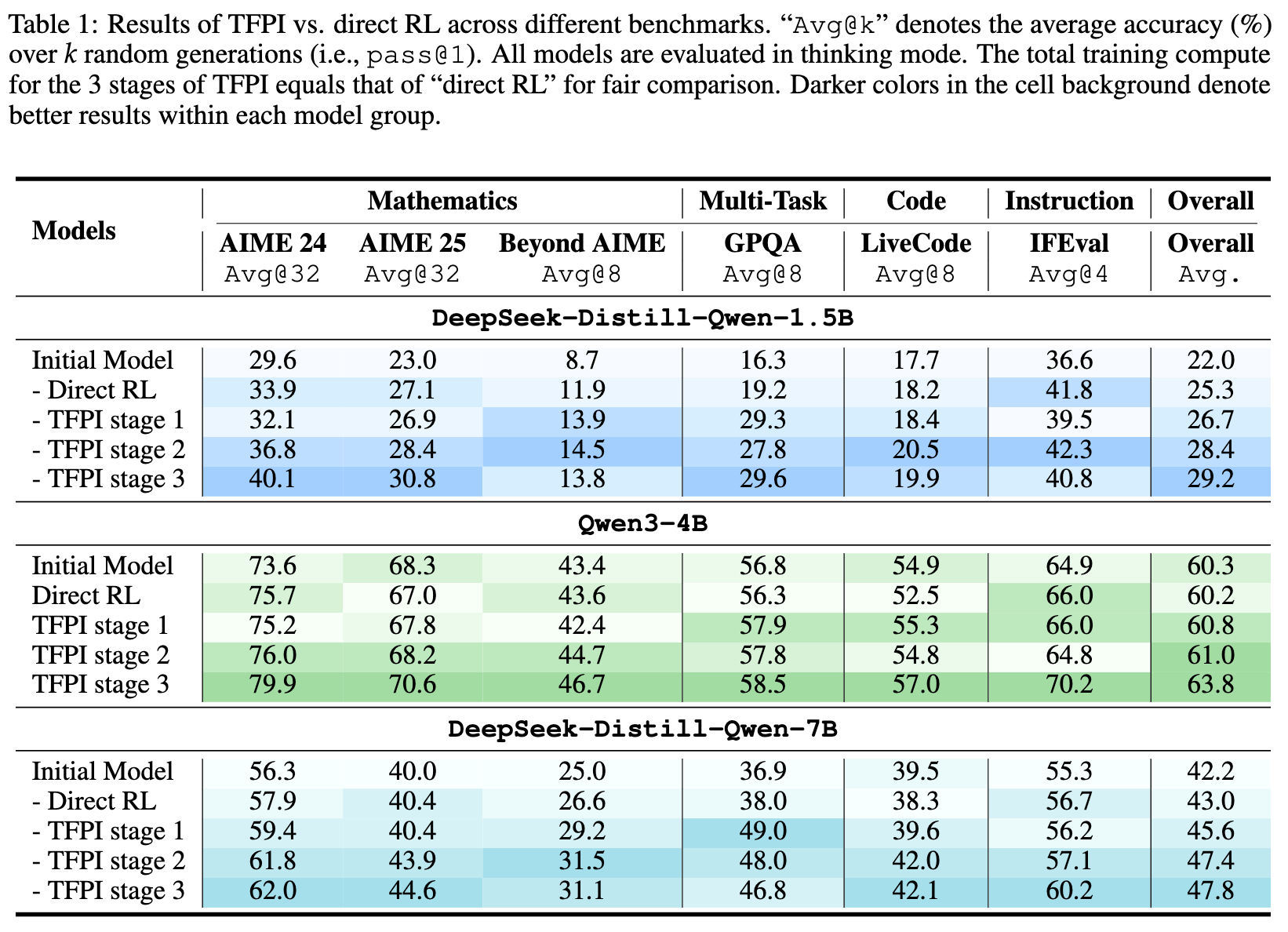
在相同的训练计算预算下,TFPI与直接进行长上下文RL(“Direct RL”)进行了对比。结果如表1所示。
从表格中可以清晰地看到:
-
TFPI在小上下文下依然有效:以DS-1.5B模型为例,仅经过TFPI第一阶段(2K上下文)的训练,模型的整体平均准确率就从22.0%提升到了26.7%(+4.7%),超过了使用16K长上下文进行相同计算量训练的“Direct RL”(25.3%)。这证明了TFPI在低成本设置下训练的有效性。 -
TFPI收敛更快,性能更强:在总计算成本相同的前提下,经过完整三阶段TFPI训练的模型,在几乎所有评测项目上都显著优于“Direct RL”。例如,Qwen3-4B模型的总体准确率从60.2%提升到63.8%(+3.6%),DS-7B模型更是从43.0%大幅提升到47.8%(+4.8%)。这表明TFPI是一条比传统长上下文RL更高效的收敛路径。 -
TFPI具备跨领域泛化能力:尽管TFPI的训练数据仅包含数学问题(Polaris-53K),但它在代码生成(LiveCodeBench)和指令遵循(IFEval)等域外任务上也表现出了性能提升。例如,在DS-1.5B上,GPQA准确率从16.3%提升至29.6%,IFEval从36.6%提升至40.8%。这说明TFPI学到的可能是一种更底层的、可迁移的推理能力,而不仅仅是针对特定领域的知识。
4.2 结论二:TFPI为后续RLVR训练提供了更好的起点,抬高了性能天花板
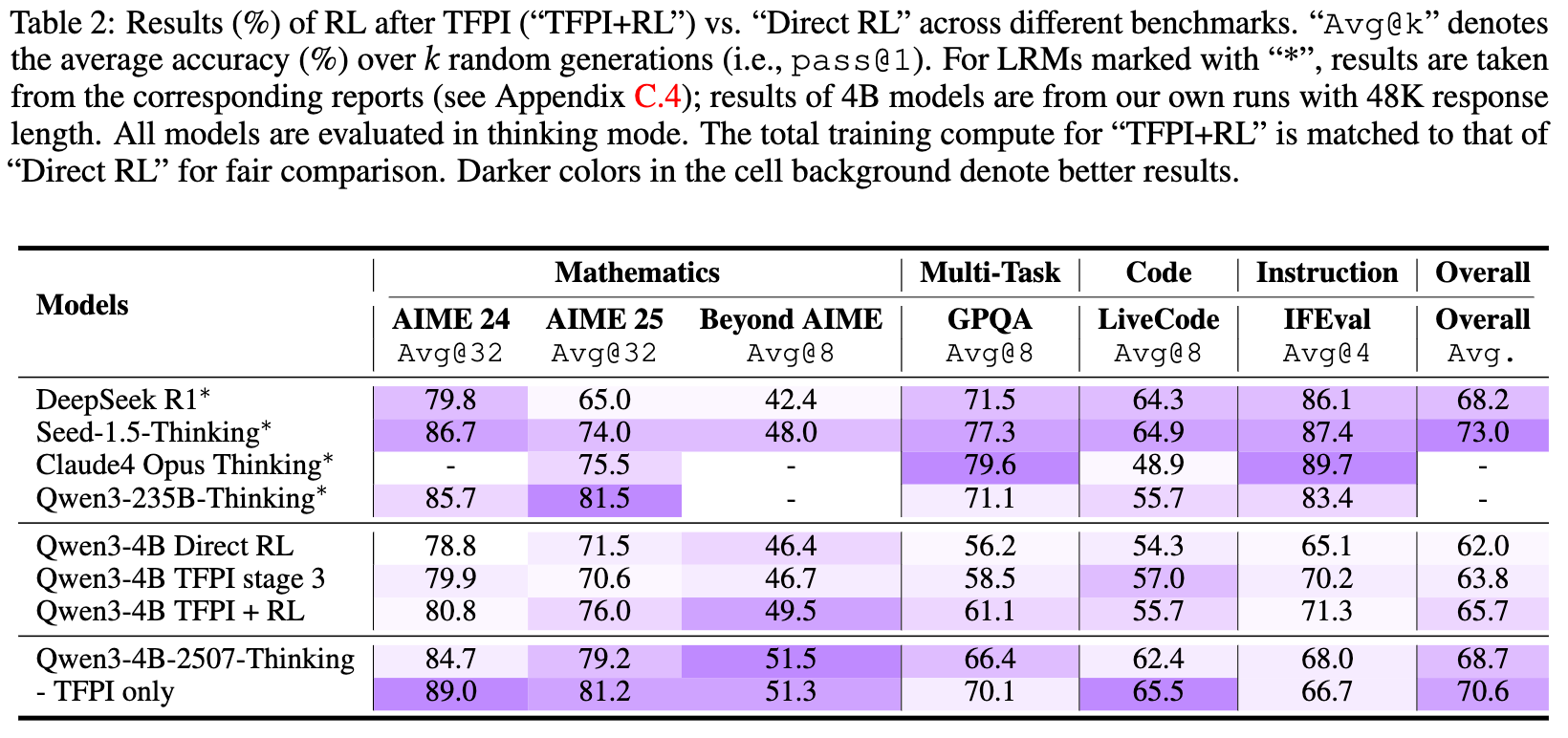
TFPI不仅可以作为一个独立的训练阶段,更重要的价值在于它为后续的标准RLVR奠定了坚实的基础。研究者们对比了“TFPI + RL”与同样计算成本的“Direct RL”的性能。
结果显示:
-
“TFPI + RL”的组合显著优于“Direct RL”。在Qwen3-4B模型上,经过TFPI初始化后再进行RL训练,总体准确率达到了65.7%,而直接进行RL训练的准确率仅为62.0%。这证明了TFPI能够将模型引导到一个更好的参数空间区域,从而使得后续的RL能够达到更高的性能上限。 -
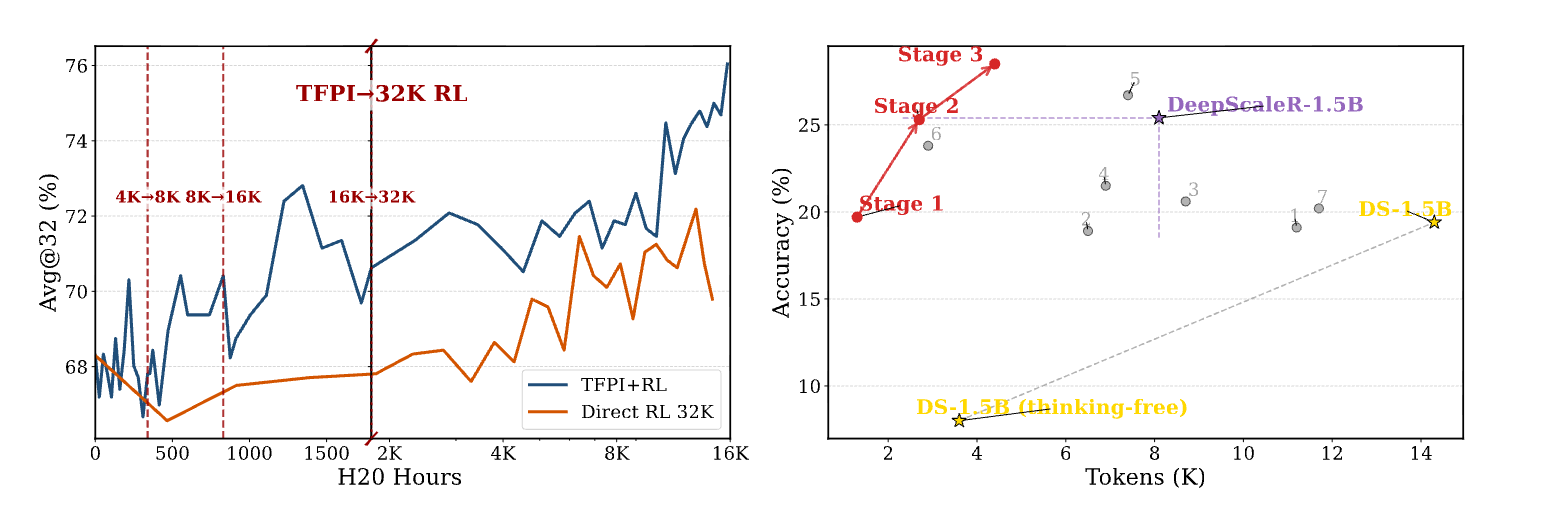
TFPI的效率优势:从训练效率上看(见图1左),完成TFPI的三个阶段所需的计算量,不到标准32K上下文RL训练的20%。这意味着可以用少量的计算资源完成TFPI,然后将主要资源投入到后续的RL冲刺阶段,从而实现更高的性价比。 -
仅用TFPI也能达到SOTA水平:一个值得关注的结果是,仅使用TFPI训练的4B模型(Qwen3-4B-2507),在不经过后续长上下文RL的情况下,就在AIME24上达到了89.0%的准确率,在LiveCodeBench上达到了65.5%。这个性能已经超过了许多更大规模、经过更复杂训练流程的模型,证明了TFPI本身就是一个强大且高效的训练方法。
4.3 结论三:TFPI自然地提升了模型的Token效率,且无需复杂的奖励设计
除了提升准确率,TFPI在另一个关键维度——推理效率上,也表现出色。研究者将TFPI模型在“Thinking-Free”推理模式下的表现,与其他主流的、旨在提升推理效率的RL方法进行了比较。
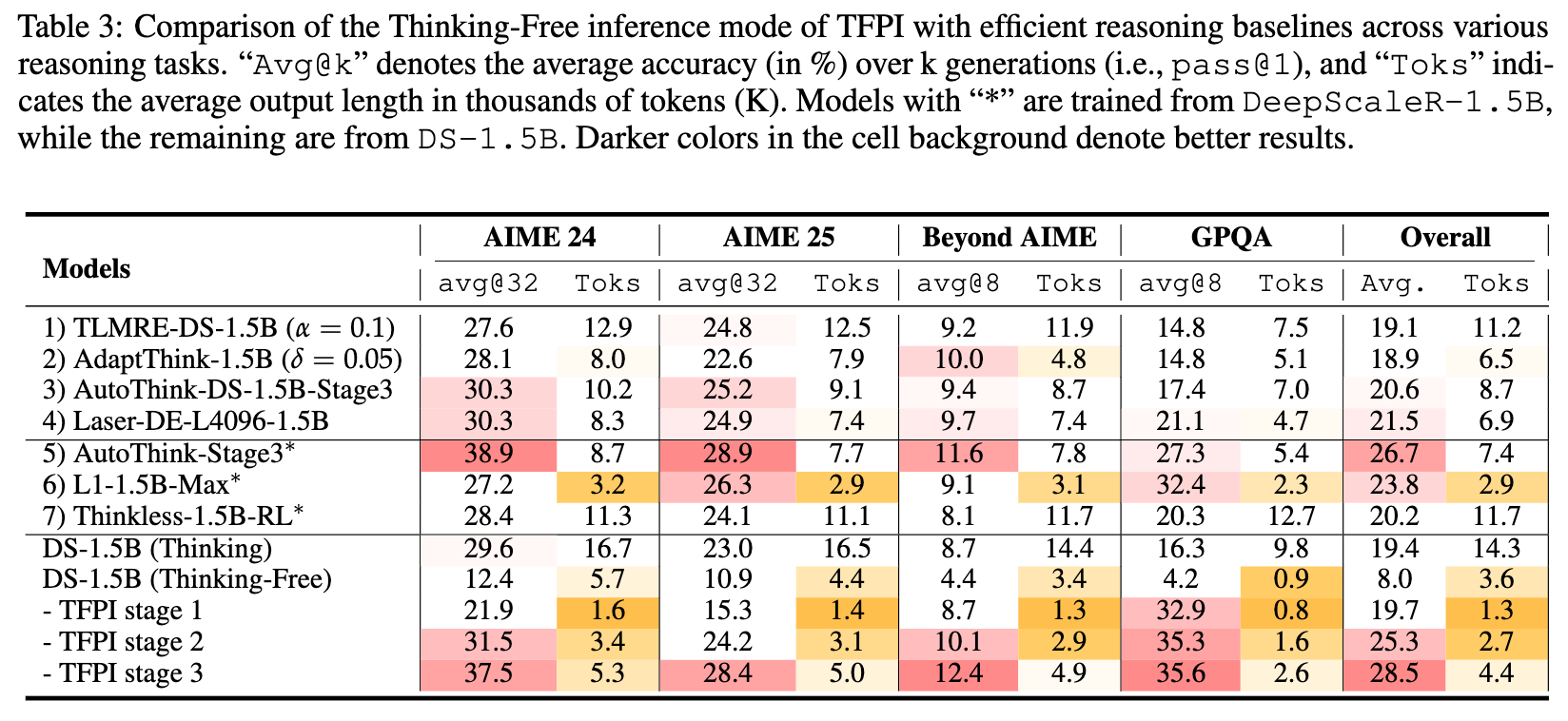
分析上表可以发现:
-
TFPI在准确率和token效率上实现了同步提升。以DS-1.5B为例,经过TFPI Stage 3训练后,模型在AIME24上的准确率从初始的29.6%提升到37.5%,而平均输出长度仅为5.3K tokens,远低于初始的16.7K tokens。 -
TFPI达到了性能-效率的帕累托最优。与其他方法(如TLMRE, AdaptThink, AutoThink等)相比,TFPI Stage 2和Stage 3的模型在保持有竞争力的、甚至更低的token消耗的同时,取得了更高的整体准确率。如上图右侧的帕累托前沿图所示,TFPI的各个阶段始终位于左上方的最优区域。
这一结果的核心意义在于,许多现有方法为了实现token效率,往往需要设计复杂的、与长度相关的奖励函数(reward shaping)或引入额外的训练机制。而TFPI提供了一种更简洁的范式:通过一个高效的初始化阶段训练出一个强大的慢思考模型,然后仅通过切换到Thinking-Free推理模式,就能自然地获得一个token高效的版本,无需任何额外的奖励工程。
5. 实验分析
TFPI的成功看似反直觉,其背后深层的原因是什么?论文从行为和参数两个层面给出了分析。
5.1 行为层面
推理,尤其是慢思考,一个关键的组成部分是“验证”(verification)。模型在推导过程中会进行自我检查和修正。研究者分析了模型在训练过程中“验证步骤”所占的比例。
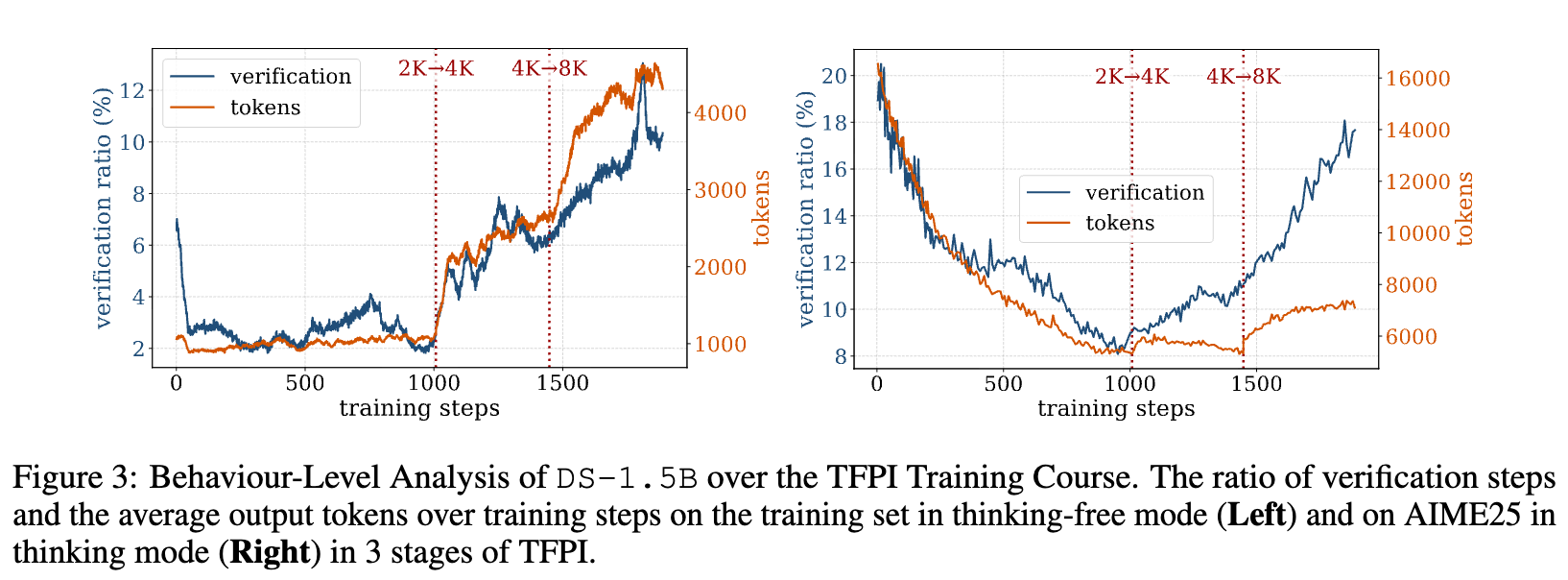
上图展示了在Thinking-Free模式(左)和Thinking模式(右)下,验证步骤比例和输出token数的变化。可以观察到:
-
验证行为模式高度一致:无论在哪种模式下,验证比例都呈现出相似的趋势:在Stage 1急剧下降(类似信息压缩),在Stage 2和Stage 3稳步增长。 -
从无思考到有思考的泛化:在Thinking-Free模式下学到的验证能力,能够成功地泛化到Thinking模式的推理过程中。这意味着,即使模型没有被要求写出中间步骤,它依然在内部学习并强化了如何进行验证和修正的核心推理技能。这种内在能力的提升,是TFPI能够增强慢思考性能的关键。
5.2 参数层面
从模型参数更新的角度看,TFPI的轨迹也揭示了其有效性的秘密。研究者使用主成分分析(PCA)将模型在训练过程中的参数检查点(checkpoints)进行可视化。
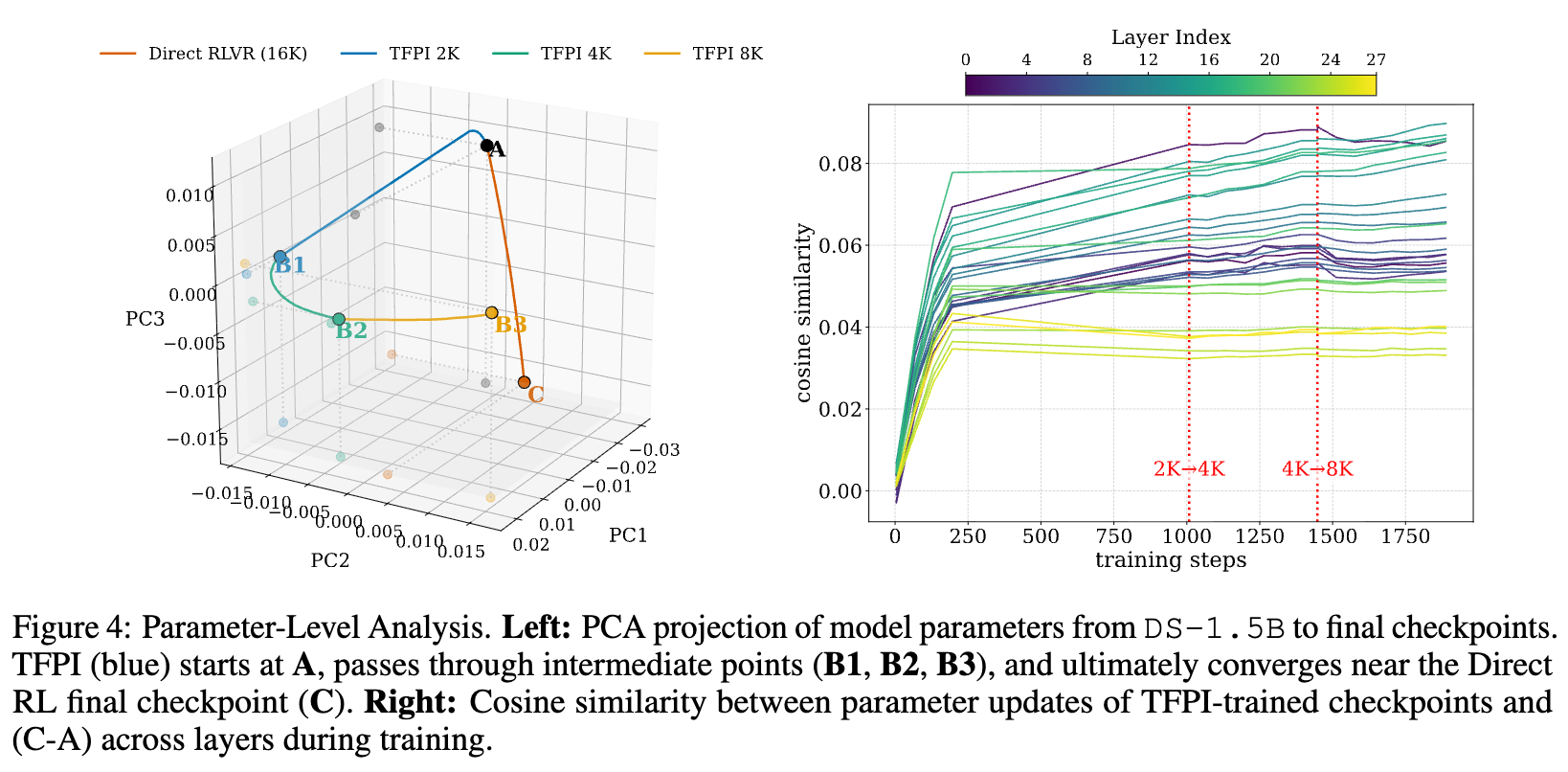
-
更广阔的参数空间探索(左图):图中显示,TFPI的训练轨迹(蓝色,从A点经过B1, B2, B3)与“Direct RL”的轨迹(红色)截然不同。TFPI首先向一个完全不同的方向探索,覆盖了更广泛、更多样的参数区域,最终才收敛到“Direct RL”终点(C点)附近的区域。这种更广泛的探索,可能帮助模型跳出局部最优,找到一个泛化能力更强的解。 -
更新方向的逐步对齐(右图):通过计算TFPI每一步参数更新与“Direct RL”最终更新方向的余弦相似度,研究者发现,随着训练的进行,TFPI的更新方向与标准长思维链RL的更新方向越来越一致。这说明,尽管TFPI的训练形式不同,但它在本质上是在引导模型朝向一个与理想的慢思考模型相似的参数目标演进。
5.3 推理模式与Rollout速度:保留核心,加速训练
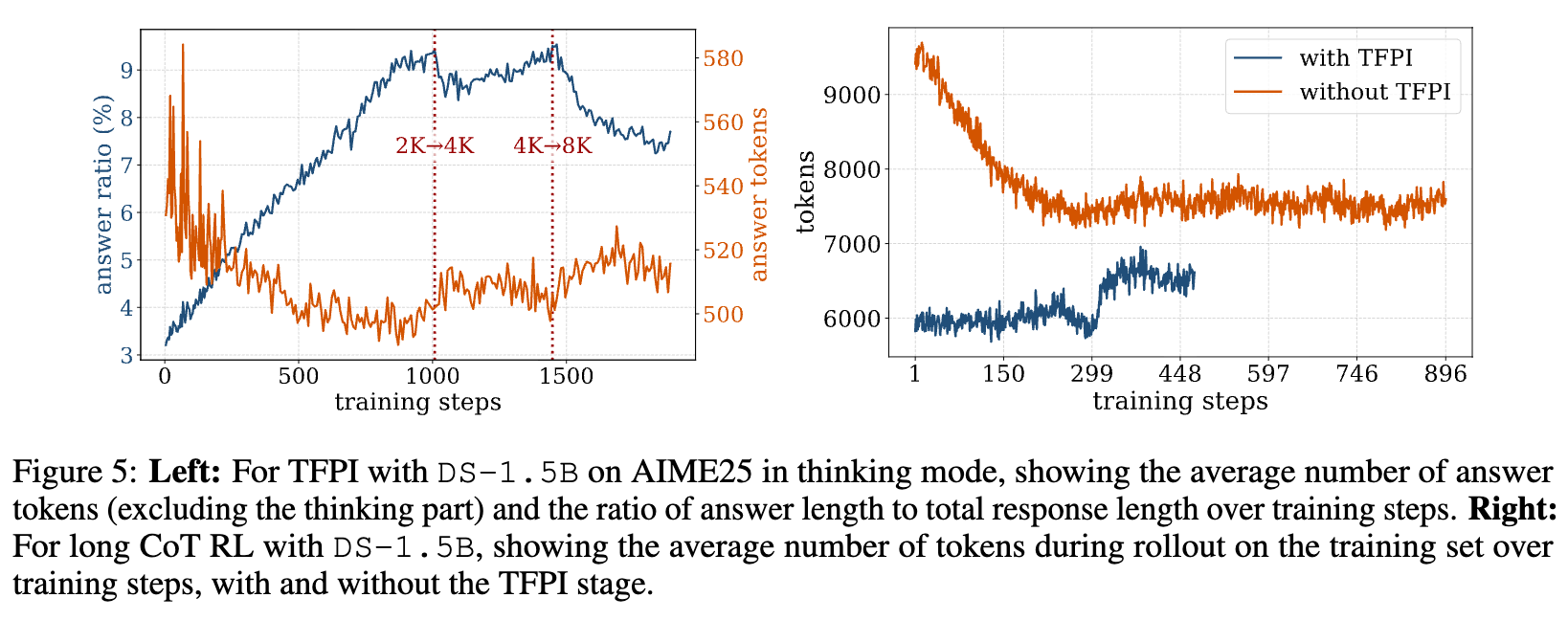
TFPI还带来了两个实际的工程优势:
-
保留核心推理模式:标准的RL训练有时会使模型的思维链部分(thinking part)变得越来越长,而最终答案部分(answer part)却很短,形成一种“过度思考”的模式。TFPI则不同,它在训练中由于没有显式的思考部分,反而强化了模型在答案部分进行简洁推理的能力。如下图左侧所示,经过TFPI训练后,在思考模式下评估,答案部分的长度
|y_ans|保持稳定,而其占总长度的比例|y_ans| / |y|则在上升。这说明TFPI保留了慢思考的核心推理模式,而没有使其退化为冗长的“慢-慢思考”。 -
加速后续RL的Rollout速度:TFPI的另一个直接好处是,它产生的模型在进行rollout时,生成的token数量更少。如下图右侧所示,直接从SFT模型开始RL(橙线),rollout的平均长度从超过9K tokens开始。而从TFPI初始化后的模型开始RL(蓝线),rollout的起始长度仅为6K tokens,并且在整个训练过程中都保持在更低的水平。这意味着,后续的长上下文RL阶段,每一步的训练都更快,从而在整体上节约了大量的计算时间。
6. 总结
TFPI的核心贡献可以总结为:
-
提出并验证了“无思考”训练的有效性:首次证明了在RLVR中显式忽略思考过程的训练,不仅不会损害,反而能增强模型在标准“慢思考”模式下的性能。 -
提供了一个高效的初始化新范式:TFPI可以作为一个中间步骤,插入到SFT和标准RLVR之间,它能加速RL收敛、提升性能上限,并为后续训练提供更高效的rollout,显著降低了训练高性能推理模型的门槛。 -
开辟了构建token高效模型的新路径:TFPI训练出的模型,只需简单切换到Thinking-Free推理模式,就能在不牺牲过多性能的前提下,大幅降低token消耗,实现了性能与效率的平衡,且无需复杂的奖励工程。
往期文章:


