
-
论文标题:LIGHTREASONER: CAN SMALL LANGUAGE MODELS TEACH LARGE LANGUAGE MODELS REASONING? -
论文链接:https://arxiv.org/pdf/2510.07962
TL;DR
今天分享一篇论文:《LIGHTREASONER: CAN SMALL LANGUAGE MODELS TEACH LARGE LANGUAGE MODELS REASONING?》。这篇论文是探讨如何利用较弱的小模型(Amateur)来辅助较强的大模型(Expert)提升数学推理能力的论文。该研究的核心发现是:大模型的推理能力并非通过全量 token 的均匀训练提升,而是取决于少数关键决策点(Critical Decision Points)。
该论文提出了一种两阶段框架:
-
采样阶段:利用 Expert 和 Amateur 在同一上下文下的预测分布计算 KL 散度,筛选出 Expert 显著优于 Amateur 的“关键步骤”。 -
微调阶段:构建对比监督信号(Contrastive Supervision),在不依赖 Ground Truth(真实标签)的情况下,通过最大化 Expert 与 Amateur 的行为差异来强化 Expert 的推理模式。
实验表明,在 GSM8K 上训练后,该方法在 MATH 等多个基准测试上取得了优于传统 SFT(监督微调)的效果,且在采样数量减少 80%、微调 Token 减少 99% 的情况下,总时间成本降低了 90%。
1. 引言
1.1 传统 SFT 的资源瓶颈
当前提升大语言模型(LLM)推理能力的主流范式是监督微调(Supervised Fine-Tuning, SFT)。为了获得高质量的推理数据,研究者通常采用“拒绝采样”(Rejection Sampling)策略:让模型对同一问题生成多个推理路径,利用 Ground Truth 过滤出正确路径,再将这些路径作为训练数据。
这种方法存在两个显著的资源与效率问题:
-
采样成本高:需要生成大量完整的推理轨迹(Chain-of-Thought, CoT),并进行结果验证。 -
训练效率低:SFT 通常采用标准的交叉熵损失函数(Cross-Entropy Loss),对推理路径上的每一个 token 进行等权重的优化。
然而,从认知科学和信息论的角度来看,推理过程中并非每一步都同等重要。通过简单的连接词(如 "so", "therefore"),往往包含的信息熵较低;而决定解题思路的关键转折点(Bottlenecks),才是区分“专家”与“新手”的核心所在。
1.2 LightReasoner 的切入点
LightReasoner 提出的核心假设是:模型推理能力的提升应当聚焦于那些“高价值”的决策时刻,而非均匀地覆盖整个序列。
为了自动识别这些时刻,作者引入了一个反直觉的视角:利用一个能力较弱的“业余模型”(Amateur)作为参照系。当 Expert 模型对下一步的预测非常有信心,而 Amateur 模型表现出困惑或预测错误时,该时刻往往对应着推理链条中的关键步骤。
基于此,LightReasoner 试图解决以下问题:
-
如何在没有人工标注和外部验证器的情况下,自动识别关键推理步骤? -
如何将 Expert 与 Amateur 的行为差异转化为有效的监督信号?
2. 从行为差异到监督信号
本章节将深入剖析 LightReasoner 的数学原理,包括关键步骤的筛选机制、对比分数的构建以及其与策略梯度(Policy Gradient)的联系。
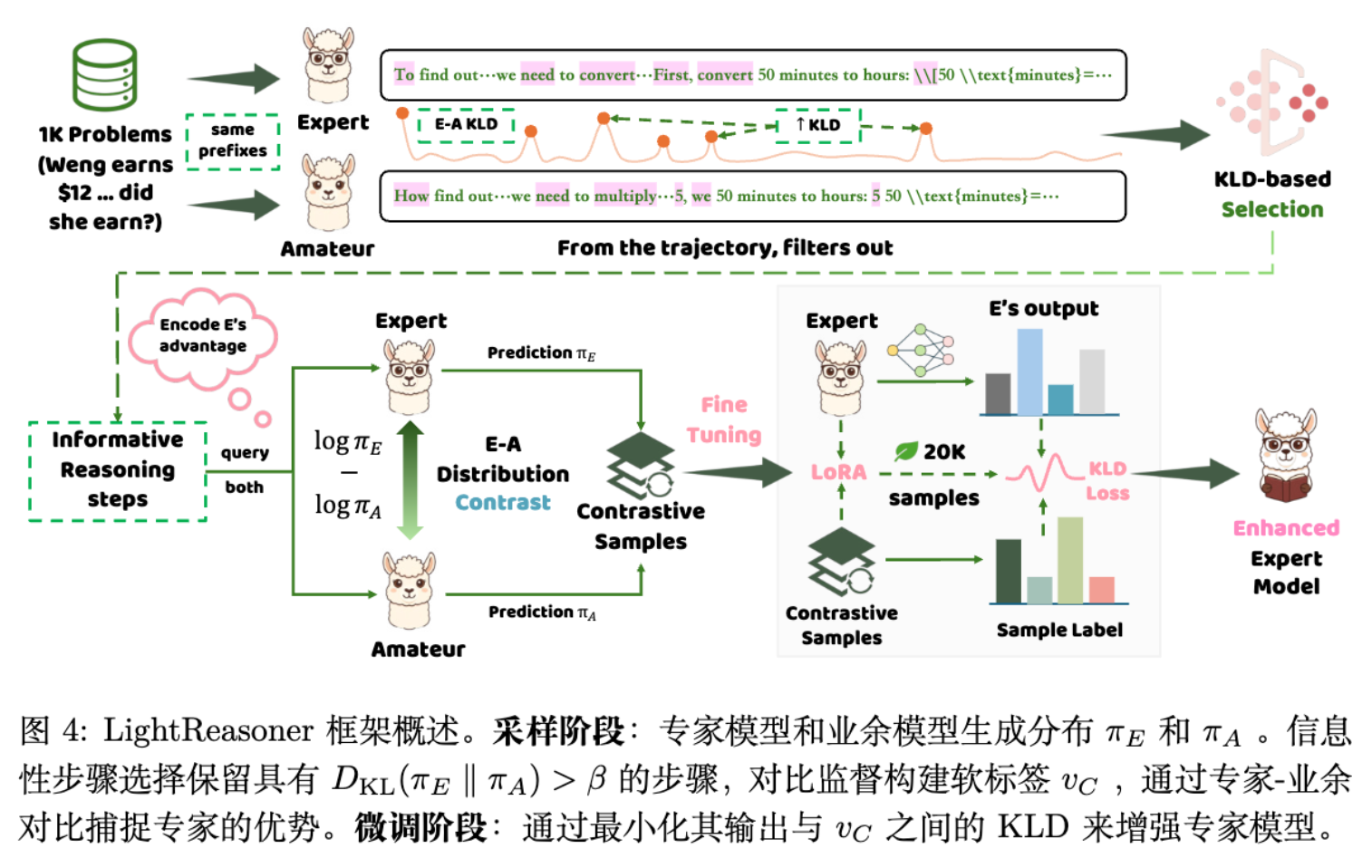
2.1 KL 散度
对于给定的输入 和词表 ,模型自回归地生成序列 。在任意时间步 ,Expert 模型 和 Amateur 模型 接收相同的上文前缀 ,并输出下一个 token 的概率分布。
为了衡量两个模型在当前步骤(本文的“步骤”为 token 粒度)的认知差异,论文采用了 Kullback-Leibler (KL) 散度:
理论解释:
-
当 较小时,意味着 Expert 和 Amateur 对当前步骤的判断趋于一致。这种情况通常发生在简单的语法连接或浅显的逻辑推演上,此时 Amateur 也能处理得很好,因此该步骤的学习价值较低。 -
当 较大时,意味着 Expert 的分布与 Amateur 显著偏离。这通常发生在需要深层领域知识或复杂逻辑跳跃的时刻,Amateur 无法跟上 Expert 的思路。这些时刻即为“关键决策点”。
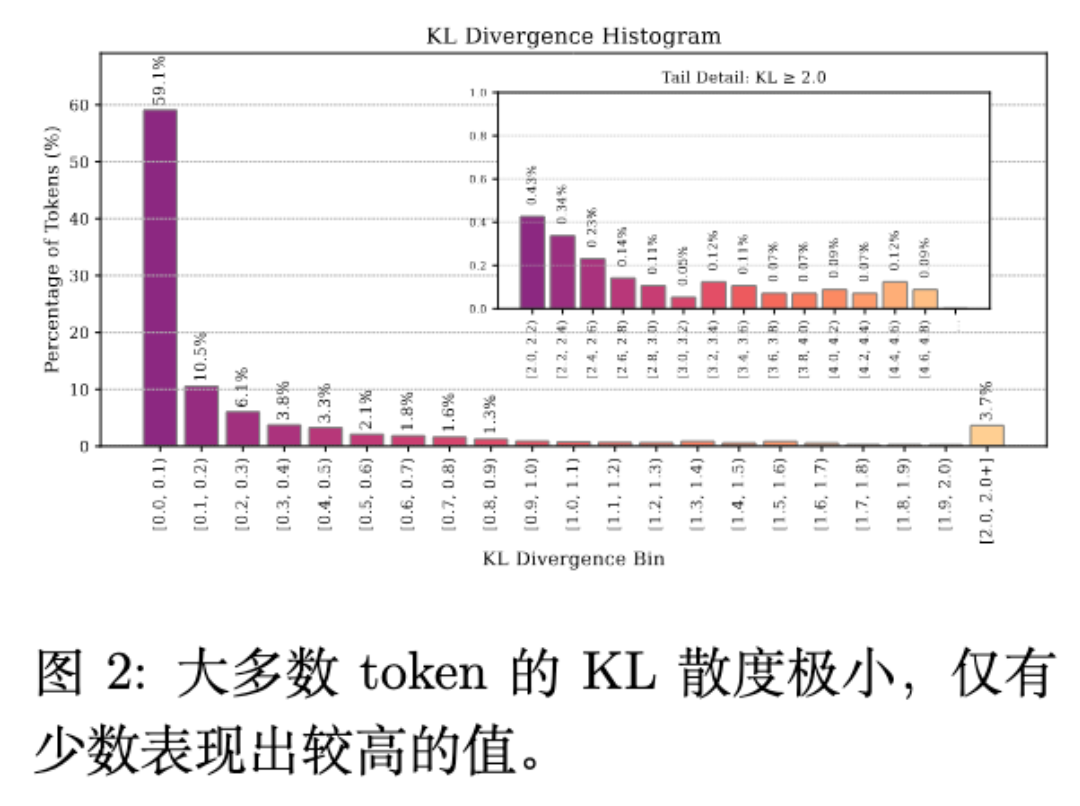
如图 2 所示,大部分 token 的 KL 散度都集中在 区间,证明了推理过程中信息分布的稀疏性。
2.2 阶段一:信息步筛选
基于上述观察,LightReasoner 引入了 -filtering 机制。对于生成的推理轨迹 ,仅保留满足以下条件的步骤 :
其中 是一个超参数阈值。这种筛选机制直接剔除了大量冗余的步骤,是该方法实现高效率的关键。实验中发现,仅保留约 20% 的 token 即可实现有效训练。
2.3 阶段二:对比分布监督
在筛选出关键步骤后,如何利用这些步骤训练 Expert?简单的做法是直接使用 Expert 自身的预测作为硬标签(One-hot Label)。但这样做会丢失 Expert 对其他候选 token 的概率分布信息,且无法显式地利用“Amateur 在此处犯错”这一信息。
LightReasoner 借鉴了对比解码(Contrastive Decoding, CD)的思想,构建了一个软标签(Soft Label)。
2.3.1 掩码支持集
为了防止 Amateur 的错误分布引入噪声,首先对词表进行 -masking 截断。只保留 Expert 认为概率较高的 token:
2.3.2 对比分数
在 集合内,定义对比分数 为 Expert 与 Amateur 的对数概率之差:
这一项直观地反映了 Expert 相对于 Amateur 的优势。如果 高而 低,则分数值大,表示这是 Expert 特有的正确决策;如果两者都高,则分数接近 0,表示这是共识知识。
2.3.3 归一化与分布构建
将对比分数通过 Softmax 归一化,构建最终的监督分布 :
对于不在掩码集中的 token,其概率置为 0。最终得到的 即为训练目标。
2.4 自蒸馏训练目标
在微调阶段,LightReasoner 冻结 Amateur,仅更新 Expert 参数 。目标是最小化 Expert 输出分布 与构建的对比分布 之间的 KL 散度:
展开该公式,忽略与 无关的常数项,等价于最小化交叉熵:
从梯度的视角解读:
根据论文附录的推导,该损失函数的梯度更新方向隐含地包含了“最大化 Expert 与 Amateur 差异”的动力。这实际上是一种自监督的强化过程,迫使 Expert 在那些它比 Amateur 强的领域变得更加自信。
算法伪代码:

3. 与强化学习及对比解码的关系
3.1 与强化学习 (RL) 的联系
如果我们将对比分数 视为一种“优势函数”(Advantage Function),LightReasoner 的更新公式与策略梯度算法(如 PPO 的 Policy Gradient)具有惊人的相似性。
在 RL 中,梯度通常形式为:
在 LightReasoner 中,虽然是监督学习形式,但 实际上充当了 的角色。不同之处在于:
-
信号源:RL 的信号来自外部奖励模型(Reward Model)或环境反馈;LightReasoner 的信号来自内部的 Expert-Amateur 差异。 -
优化方向:RL 最大化期望回报;LightReasoner 最小化与目标分布的距离。
这种相似性解释了为何 LightReasoner 能够在没有 Ground Truth 的情况下提升模型性能——它本质上是在执行一种隐式的、基于内在动机(Intrinsic Motivation)的策略优化。
3.2 与对比解码 (Contrastive Decoding) 的区别
Contrastive Decoding (Li et al., 2022) 是一种推理时(Inference-time)的技术,通过在解码过程中实时减去 Amateur 的 logits 来搜索更好的 token。
LightReasoner 将这一思想前置到了训练时(Training-time)。这样做的好处显而易见:
-
推理效率:部署后的模型不需要加载 Amateur 模型,推理速度不受影响。 -
泛化能力:通过训练,模型将这种对比优势内化为权重参数,可能泛化到未见过的场景,而不仅仅局限于解码时的局部调整。
4. 实验设置与结果分析
4.1 实验配置
-
Expert 模型:Qwen2.5-Math (1.5B, 7B), DeepSeek-R1-Distill 等。 -
Amateur 模型:Qwen2.5-0.5B (Base model,非 Math 专项训练)。 -
训练数据:仅使用 GSM8K 的训练集(约 7.5k 问题),旨在测试小样本下的泛化能力。 -
评估基准:GSM8K (分布内), MATH, SVAMP, ASDiv, Minerva Math, OlympiadBench (分布外泛化)。
4.2 核心结果 (RQ1)
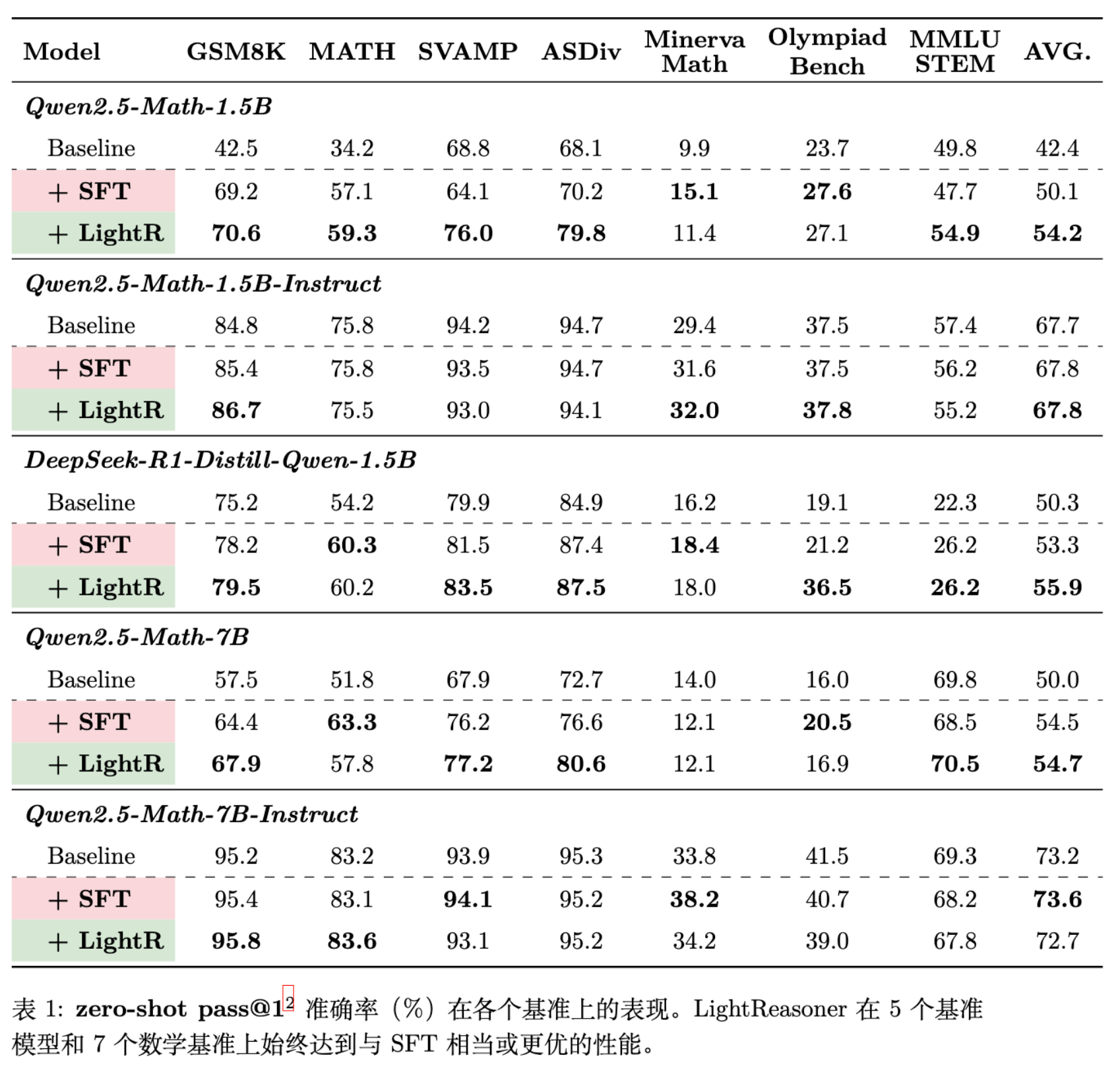
从表 1 可以看出:
-
全面超越 SFT:在 5 个不同的 Expert 模型和 7 个数据集上,LightReasoner 的平均表现均优于 SFT。例如,Qwen2.5-Math-1.5B 在 GSM8K 上从 Baseline 的 42.5% 提升至 70.6%(SFT 为 69.2%)。 -
泛化能力强:虽然只在 GSM8K(小学数学)上训练,但模型在 MATH(高中竞赛数学)上的提升依然显著(+2.2% vs SFT)。这表明 LightReasoner 学到的是通用的推理模式,而非简单的数据记忆。
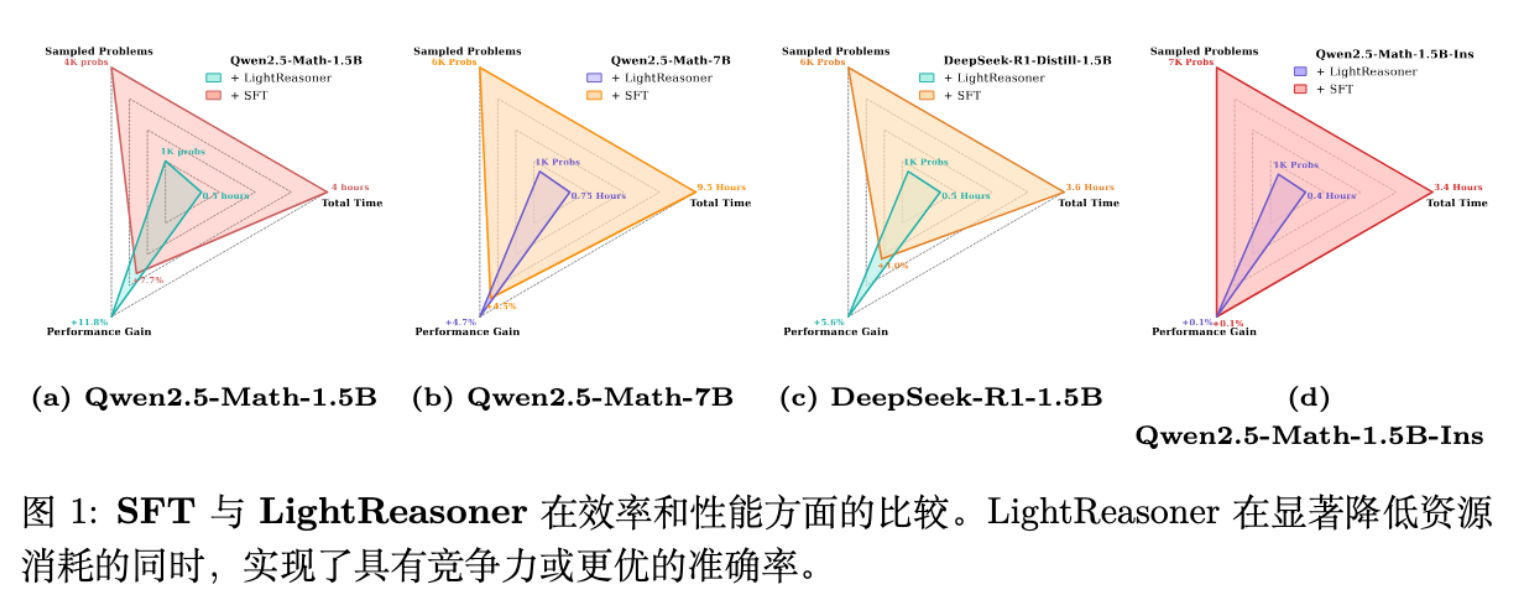
4.3 效率分析 (RQ2)
效率是该论文最大的卖点。
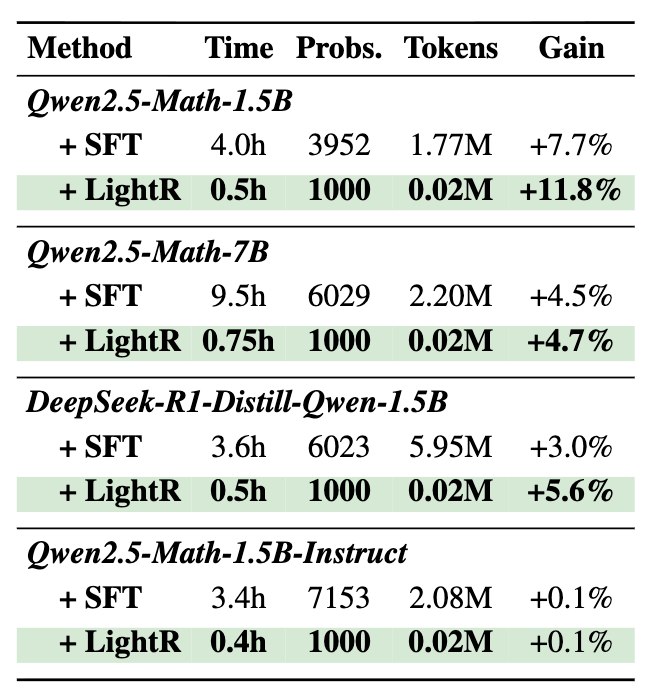
-
时间成本:SFT 需要 4.0 小时(以 1.5B 模型为例),LightReasoner 仅需 0.5 小时,减少 87.5% 。 -
样本利用率:SFT 通常需要通过拒绝采样生成数千个正确轨迹(约 4k-7k);LightReasoner 仅需采样 1000 个问题,且无需验证答案正确性。 -
Token 训练量:SFT 对全轨迹微调(~1.77M tokens);LightReasoner 经筛选后仅微调关键步骤(~0.02M tokens),减少 99% 。
这种数量级的效率提升,主要归功于 -filtering 过滤掉了 80% 的 token,以及不需要反复采样直到生成正确答案(Verification-Free)。
4.4 专家与业余者的差距 (Expertise Gap)
这是一个非常值得探讨的发现。传统的对比解码通常依赖模型规模的差异(如 70B vs 7B)。但 LightReasoner 的消融实验发现,领域知识的差异更为关键。
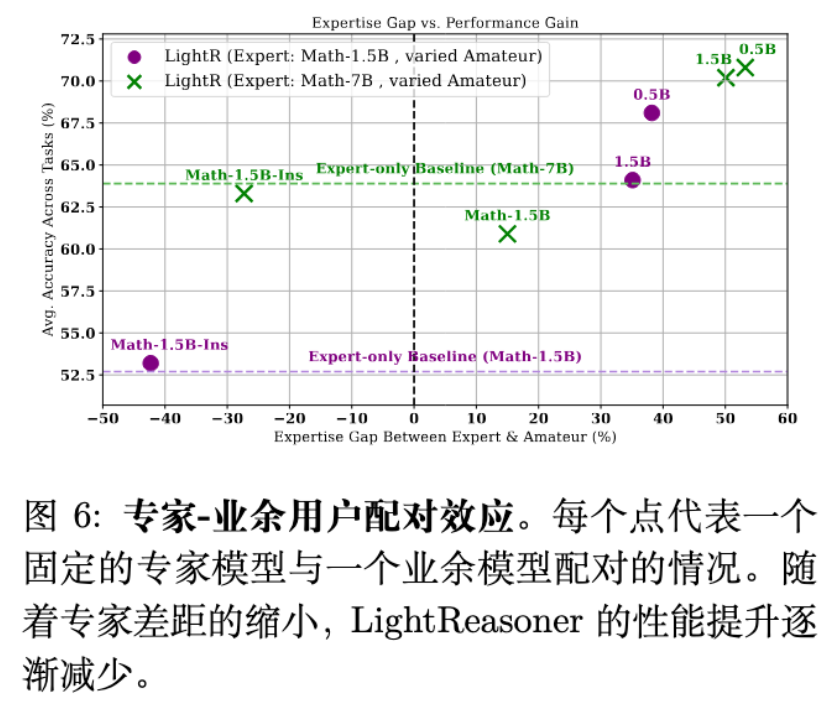
-
当使用一个数学能力较弱的通用模型(Qwen2.5-Base)作为 Amateur 时,效果最好。 -
如果使用一个经过指令微调的强模型(Instruct版)作为 Amateur,由于其与 Expert 的差距缩小,对比信号减弱,LightReasoner 的收益随之下降。 -
甚至,如果 Amateur 比 Expert 更强(负向差距),性能会倒退。
这验证了“教学”的隐喻:只有当老师(Expert)比学生(Amateur)懂得多时,差异才是由知识带来的;如果水平相当,差异可能只是噪声。
5. 深度消融与机制分析
为了验证框架中各个组件的必要性,论文进行了详尽的消融研究。
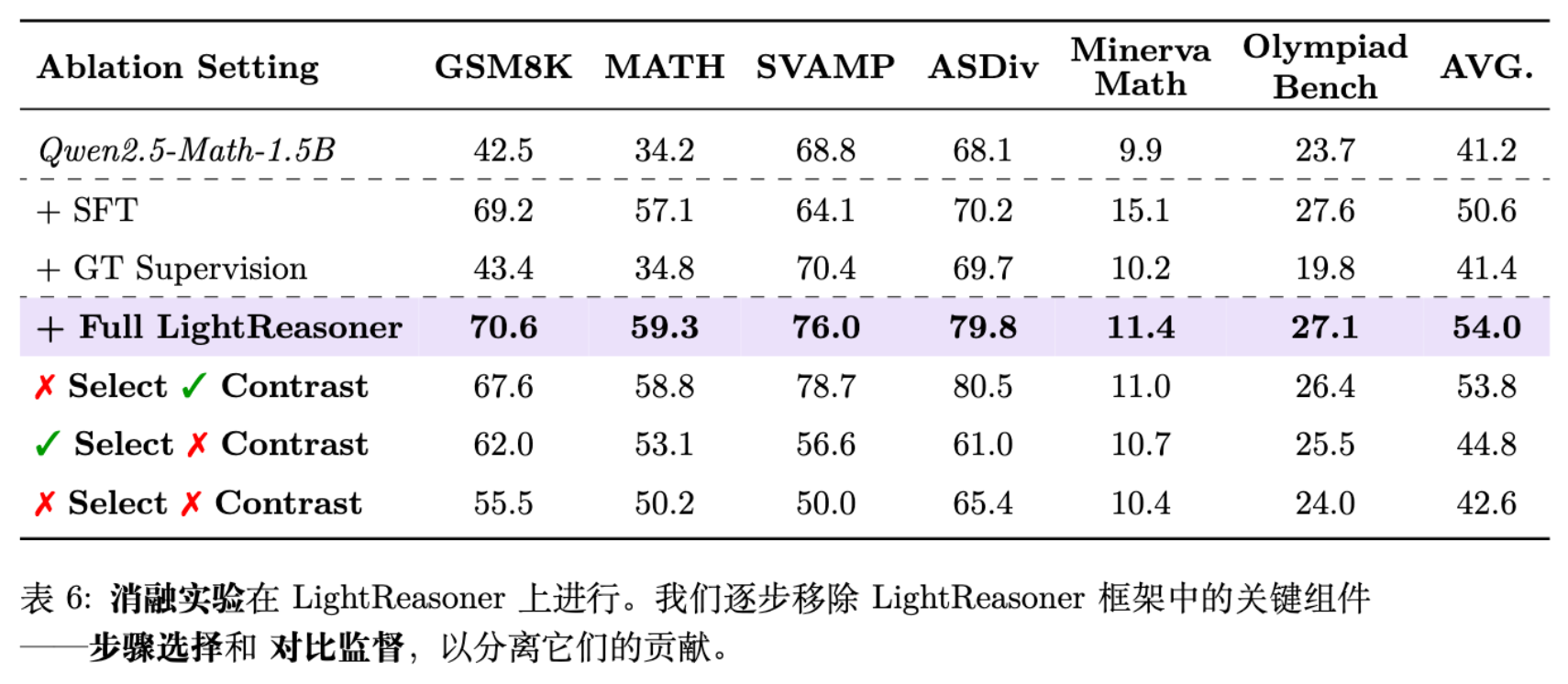
5.1 步骤筛选的必要性
如果移除 -filtering(即对所有 token 进行训练),性能会下降。这说明:
-
大量 token 确实是低价值的。 -
在非关键步骤上,Expert 和 Amateur 可能都预测正确,也可能都预测错误(共识性错误)。强制在这些步骤上进行对比训练可能会引入噪声,甚至破坏原有的语言模型分布。
5.2 对比监督的必要性
如果保留步骤筛选,但使用标准的 SFT Loss(即直接拟合 Expert 自身的 One-hot 分布),性能下降最为严重。
这表明,仅仅找到“关键点”是不够的,必须告诉模型“相对于 Amateur 应该向哪个方向优化”。 提供的 soft label 包含了比 hard label 更丰富的分布信息,起到了类似 Label Smoothing 或 Knowledge Distillation 的正则化作用。
5.3 无需真值标签
LightReasoner 声称不需要 Ground Truth。这是一个极其大胆的设计。
-
优势:可以使用海量无标签数据进行训练,不受限于拥有标准答案的数据集。 -
潜在风险:如果 Expert 在某个关键步骤上非常有信心但是错误的,而 Amateur 是困惑的,KL 散度依然会很高。此时,LightReasoner 会强化 Expert 的这个错误信念。
论文对此的辩解是:预训练模型在早期推理步骤中通常较为可靠(Ji et al., 2025),且设置了最大 token 长度限制(128),减少了错误累积。
这在短链条推理(如 GSM8K)上可能成立,但在长链条复杂推理中,模型产生幻觉的概率随长度指数增加,“盲目自信”的错误非常常见。完全脱离 GT 的监督在更复杂的场景下可能存在上限。
6. 讨论与个人看法
6.1 这种“自举”的上限在哪里?
LightReasoner 本质上是一种 Self-Improvement。它没有引入新的外部知识,而是通过抑制 Amateur 的模式来提纯 Expert 内部已有的潜在能力(Latent Capabilities)。
这意味着:LightReasoner 无法让模型学会它完全不知道的知识。 它只能让模型更稳定地发挥出已有的最佳水平。如果 Expert 本身的基础模型能力很差,根本产生不了正确的推理逻辑,那么无论怎么对比,都无法产生高质量的 。
6.2 对 Amateur 模型的依赖
Amateur 的选择至关重要且具有技巧性。论文中固定使用了 Qwen2.5-0.5B Base。
-
如果 Amateur 太弱(随机输出),KL 散度主要反映的是 Expert 的置信度,对比意义丧失。 -
如果 Amateur 太强(接近 Expert),KL 散度消失,无梯度。 -
在实际应用中,为每一个特定的 Expert 寻找一个“恰到好处”的 Amateur 可能需要大量的调参工作。
6.3 训练数据
论文强调了在 GSM8K 上训练。GSM8K 的特点是逻辑清晰、步骤明确。
如果在充满噪声、口语化或逻辑混乱的数据上进行采样,Expert 和 Amateur 的分歧可能源于对噪声的拟合差异,而非推理逻辑。此时强化高 KL 步骤可能会导致模型过拟合噪声。
6.4 熵
论文附录 E 讨论了熵的变化。RL 过程往往伴随着策略熵的降低(Collapse)。LightReasoner 通过 -masking 和 Softmax 温度控制,实际上在一定程度上维持了探索性。但在长周期的微调中,如何防止模型输出过于单一化(Mode Collapse)仍需进一步观察。
7. 结论
LightReasoner 提供了一个优雅且高效的框架,重新审视了“如何训练推理模型”这一问题。它挑战了 SFT 必须依赖昂贵标注和均匀训练的成见,证明了“差异即信息”。
一些启示:
-
数据筛选:除了困惑度(PPL)、错误率,模型间的认知差异(Divergence)是衡量数据价值的新指标。 -
弱监督的可能性:利用不同尺寸、不同训练阶段的模型进行互助或对抗,是具有潜力的方向。 -
训练目标的精细化:从全量微调转向针对关键 Token 的稀疏微调。
代码开源地址: https://github.com/HKUDS/LightReasoner
往期文章:


