
-
论文标题:Tiny Model, Big Logic: Diversity-Driven Optimization Elicits Large-Model Reasoning Ability in VibeThinker-1.5B -
论文链接:https://arxiv.org/pdf/2511.06221
TL;DR
今天介绍一篇来自 WeiboAI 的技术报告《Tiny Model, Big Logic: Diversity-Driven Optimization Elicits Large-Model Reasoning Ability in VibeThinker-1.5B》。该技术报告介绍了一款名为 VibeThinker-1.5B 的模型,它是一个仅有 15 亿参数的稠密模型。该报告的核心论点是,通过一种注重多样性驱动的后训练方法,小型模型同样可以在逻辑推理能力上达到甚至超过一些参数量远大于它的模型。其采用的后训练框架被称为“光谱-信号原理”(Spectrum-to-Signal Principle, SSP),在监督微调(SFT)阶段致力于拓宽解决方案的“光谱”(多样性),在强化学习(RL)阶段则专注于放大正确答案的“信号”。在 AIME24/25 和 HMMT25 等数学推理基准上,VibeThinker-1.5B 的表现超过了参数量是其 400 多倍的 DeepSeek R1 模型。整个后训练的成本被控制在 7800 美元以内,这为开发高效能、低成本的小型推理模型提供了实践示例。
1. 引言
当前,大型语言模型(LLM)领域在推理能力上的进步,很大程度上遵循着通过扩大模型参数规模来提升性能的路径。从 OpenAI 的 o1 模型开启长链思考(Long Chain-of-Thought)的推理范式,到 DeepSeek R1 的 671B 参数和 Kimi k2 的万亿级参数,模型规模的持续扩张已成为提升推理等高级认知能力的主流共识。这种趋势的背后逻辑是,更大的参数量意味着更强的模型容量,能够更好地学习和存储复杂的模式与知识,从而在数学、代码、科学推理等任务中表现更佳。
然而,这种依赖参数规模的路线带来了高昂的训练与推理成本、巨大的能源消耗以及对顶尖硬件的依赖,使得前沿的人工智能研究越来越集中在少数拥有大规模计算资源的科技公司手中。这在一定程度上限制了学术界和中小型企业在该领域的探索和创新。
在这样的背景下,一个值得探讨的问题是:强大的逻辑推理能力是否必然与巨大的模型规模绑定?小型模型(例如参数量在 3B 以下)的推理潜力是否已被充分挖掘?
WeiboAI 的这篇技术报告《Tiny Model, Big Logic: Diversity-Driven Optimization Elicits Large-Model Reasoning Ability in VibeThinker-1.5B》对上述问题提出了不同的看法。报告的主张是,通过在后训练阶段进行专门的算法设计,一个 1.5B 参数量的小型模型 VibeThinker-1.5B,也能够在多个具有挑战性的推理基准上,取得与顶尖大型模型相媲美的性能。
该模型不仅在 AIME24、AIME25 和 HMMT25 等数学竞赛基准上超越了 DeepSeek R1 (671B),还在 LiveCodeBench V6 编程基准上取得了有竞争力的分数。该工作的一个核心贡献是提出并实践了一套名为“光谱-信号原理”(Spectrum-to-Signal Principle, SSP)的后训练框架。这一框架重新定义了监督微调(SFT)和强化学习(RL)在提升推理能力任务中的角色,主张 SFT 阶段的核心目标应是最大化模型输出的多样性(光谱),而非传统的单点准确率;随后的 RL 阶段则从这个多样化的输出中学习,放大正确推理路径的概率(信号)。
本文将对该报告中提出的方法、实验设置、结果进行梳理与分析,并结合一些个人观点,探讨其对未来大模型研究,尤其是小型模型发展的潜在影响。
2. 光谱-信号原理 (SSP)
传统的 LLM 后训练流程通常是 SFT -> RL。其中,SFT 阶段的目标是让模型模仿高质量数据集中的特定回答,通常以最大化 Pass@1(单次生成正确率)为优化目标。随后,RL 阶段在此基础上,通过奖励信号进一步优化模型,使其生成更符合人类偏好或更高质量的答案。
该报告的作者认为,这种以 Pass@1 为中心的 SFT 策略存在局限性。它可能会过早地收窄模型的探索空间,让模型倾向于生成单一模式的“最优解”,从而限制了后续 RL 阶段的性能天花板。对于复杂的推理任务,正确的解题路径可能不止一条,过早地聚焦于单一路径会损害模型的泛化和鲁棒性。(这个我们也在之前的文章“Meta AI 揭示 SFT 陷阱:盲目追求高分,可能会损害模型在 RL 阶段的潜力”
也介绍过:https://www.mlpod.com/1181.html)
为了解决这个问题,报告提出光谱-信号原理 (Spectrum-to-Signal Principle, SSP) ,重新划分了 SFT 和 RL 的功能定位。
-
光谱阶段 (The Spectrum Phase - SFT) :SFT 的首要目标不再是追求单次回答的准确性,而是生成一个丰富且多样化的“候选答案光谱”。这个阶段旨在最大化模型的 Pass@K 指标,即在 K 次独立采样中,至少有一次采样能够得到正确答案的概率。
-
信号阶段 (The Signal Phase - RL) :RL 阶段的任务,则是从 SFT 阶段构建的宽广“光谱”中,识别并“放大”正确的“信号”。通过奖励机制,RL 算法学习提升那些能够导出正确答案的推理路径的生成概率,同时抑制错误路径。由于 SFT 阶段已经提供了足够多样化的正确候选,RL 阶段可以更高效地学习到什么是好的推理。
这个原理的核心在于,SFT 阶段的“多样性”是后续 RL 阶段“准确性”提升的先决条件。一个经过 Pass@K 优化的 SFT 模型,相比一个 Pass@1 优化的模型,为 RL 提供了更好的起点。
2.1 训练 pipeline 概览
为了将 SSP 原理付诸实践,作者设计了一个包含 SFT 和 RLVR 的训练流程。
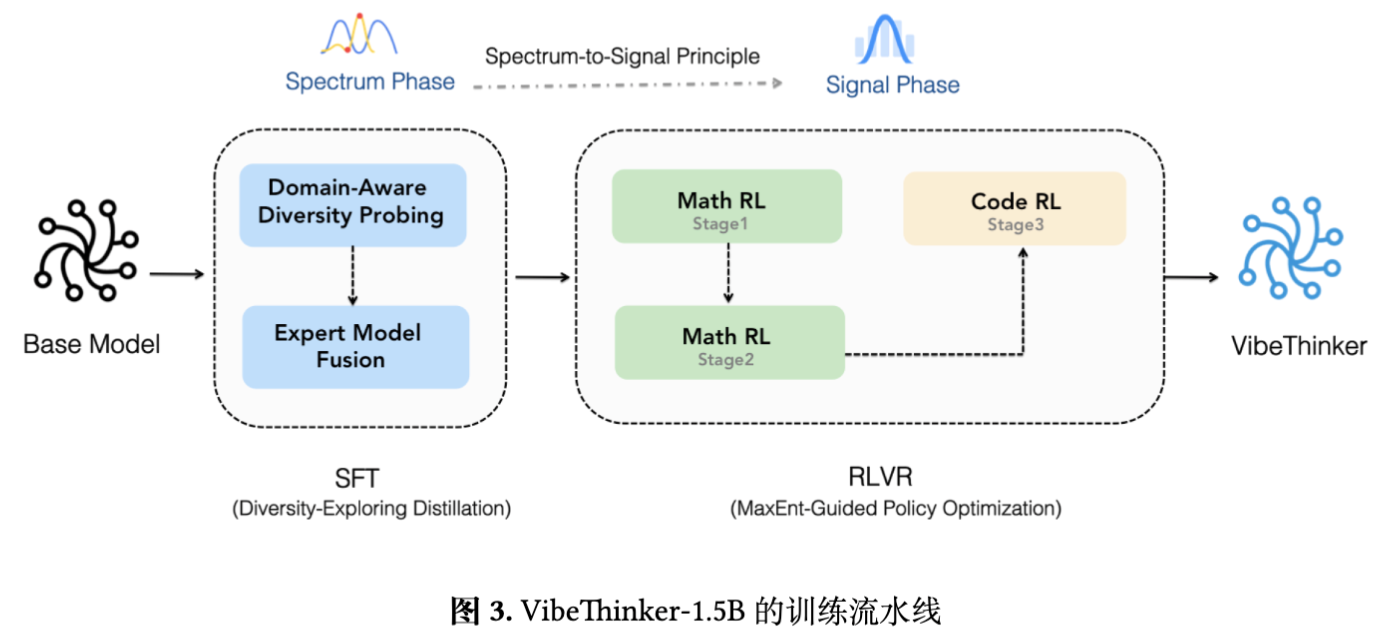
如上图所示,整个流程可以概括为:
-
SFT 阶段(光谱生成):这一阶段采用了一种名为“两阶段多样性探索蒸馏”的方法。它首先针对数学、代码等不同领域,通过“领域感知的多样性探测”找到在各个子领域 Pass@K 最高的 SFT 模型检查点。然后,通过“专家模型融合”技术(如模型合并),将这些在不同子领域表现出高多样性的“专家”检查点融合成一个统一的 SFT 模型。这个融合后的模型就具备了在多个领域生成多样化解决方案的能力。
-
RL 阶段(信号放大):这一阶段基于一个名为“最大熵引导的策略优化”(MaxEnt-Guided Policy Optimization, MGPO)的框架。MGPO 的核心思想是,在进行策略学习时,动态地将计算资源优先分配给那些模型表现最不确定的问题。作者认为,当模型对一个问题的回答正确率在 50% 左右时,该问题处于模型认知能力的“前沿”,对其进行学习的收益最大。MGPO 通过一个基于信息熵的机制来识别这些问题,并调整其在训练中的权重,从而实现一种隐式的课程学习,加速模型的收敛。
下面将对这两个阶段的具体技术细节进行展开。
2.2 SFT 阶段
为了实现一个最大化多样性的 SFT 模型,作者设计了以下两步流程:
1. 领域感知的多样性探测 (Domain-Aware Diversity Probing)
对于复杂的知识领域(如数学),作者首先将其划分为 个不同的子领域。以数学为例,可以划分为代数(Algebra)、几何(Geometry)、微积分(Calculus)、统计(Statistics)四个子领域,即 。
针对每一个子领域 ,使用一个能力较强的 LLM 自动构建一个专门的探测数据集 ,其中 是问题, 是标准答案。
在 SFT 训练过程中,会定期(例如每 k 步)保存一个模型检查点 。对于每个子领域 ,都会使用其对应的探测集 来评估所有检查点 的 Pass@K 指标,得到分数 。Pass@K 的形式化定义如下:
其中, 是一个二元奖励函数,用于判断模型生成的答案 对于问题 是否正确。这个指标衡量了模型在 次尝试中至少成功一次的概率。
最后,为每个子领域 挑选出在该领域 Pass@K 分数最高的检查点,作为该领域的“专家模型” :
通过这个过程,可以得到一组在各自数学子领域内生成多样化正确解能力最强的专家模型 。
2. 专家模型融合 (Expert Model Fusion)
在识别出各个子领域的专家模型后,下一步是将它们融合成一个单一的、全面的 SFT 模型。报告中采用了加权线性组合的方式来合并这些模型的参数。融合后的模型 定义为:
其中,权重 是非负的,并且 ,以保持模型参数的尺度。在 VibeThinker-1.5B 的实现中,作者采用了简单的平均权重,即对所有专家模型一视同仁,。
作者在文中指出,通过实验发现,这种以 Pass@K 最大化为目标合成的 模型,不仅在 Pass@K(多样性)指标上表现出色,同时在 Pass@1(准确性)指标上也达到了当时的最佳水平。这一发现支持了 SSP 原理的一个核心论点:优化生成光谱的广度,并不会以牺牲主信号的强度为代价,反而更宽的光谱似乎能够增强最正确的路径。这为后续的 RL 阶段提供了一个协同增效的基础。
2.3 RL 阶段
在传统的强化学习流程(如 RLHF)中,训练数据集通常是静态的,这意味着所有问题对模型的挑战是均等的。然而,随着模型能力的演进,一些简单问题不再具有学习价值,而一些过难的问题则可能无法提供有效的学习信号。
为了解决这个问题,作者提出了最大熵引导的策略优化 (MaxEnt-Guided Policy Optimization, MGPO)。该框架的核心假设是:当模型在某个问题上的表现处于最高不确定性状态时,该问题对训练的效用最大化。这个状态标志着模型能力的临界点,是模型最需要进行探索和改进的学习前沿。
1. 将最大熵作为探索的理想状态
对于一个给定的问题 ,通过 次采样(rollouts),可以得到一个经验上的正确率 :
其中 是指示函数, 表示第 次采样的答案是正确的。
根据最大熵原理,当一个二元分布的熵最大化时,其处于最“无信息”或最不确定的状态。对于正确与否的二元结果,最大熵发生在 时。在这个点上,模型既不能稳定地答对,也不能稳定地答错,完全处于一种不确定的状态。作者认为,这种状态的问题具有最高的“探索价值”,是策略优化的理想候选。
2. 熵偏差正则化 (Entropy Deviation Regularization)
为了将上述思想融入优化目标,作者设计了一种加权方案,该方案明确地衡量并惩罚与理想最大熵状态的偏差。这个方案被称为“熵偏差正则化”。
首先,定义了“最大熵偏差距离”(Max-Entropy Deviation Distance),即观测到的准确率分布 与目标最大熵分布 之间的 Kullback-Leibler (KL) 散度:
这个距离 量化了模型当前性能偏离最优不确定状态的程度。当 接近 0 或 1 时,距离增大;当 接近 0.5 时,距离减小。
基于这个距离,构建了一个权重函数 :
其中,, 是一个正则化系数,控制权重曲线的陡峭程度。
-
当 接近 0.5 时, 接近 0, 接近 1,问题获得最高权重。 -
当 趋向 0 或 1 时, 增大, 被指数级抑制,问题获得较低权重。 -
当 时,,算法退化为标准的 GRPO。
3. MGPO 优化目标
MGPO 将这个熵偏差权重 直接应用于 GRPO 框架中的优势项(advantage term)。对于问题 的一组 次采样中的第 次 rollout,其更新后的优势项为:
其中 是标准 GRPO 中的优势估计。MGPO 的最终优化目标函数被形式化为:
通过这种方式,MGPO 实现了一个隐式的课程学习机制。在训练的早期,许多问题的 可能接近 0,模型会优先学习那些它偶尔能答对(即 不为 0)的问题。随着模型能力的提升,原先困难问题的 会逐渐向 0.5 移动,从而获得更高的学习权重。当模型对某些问题已经掌握得很好( 接近 1)时,这些问题的权重又会降低,从而将计算资源动态地聚焦于最具学习价值的问题上。
3. 训练细节与成本
3.1 训练数据与去污染
模型的训练数据大部分来源于公开的开源数据集,同时辅以一小部分内部生成的专有合成数据,用以增强特定领域的覆盖和鲁棒性。
为了保证模型评估的公正性和泛化能力的真实性,作者在 SFT 和 RL 阶段都实施了严格的数据去污染流程。其目标是消除训练数据和评估数据集之间的语义重叠或信息泄露。具体操作包括:
-
文本标准化和预处理:在进行匹配前,对文本进行规范化,如移除无关标点、符号,统一字母大小写,以减少噪声干扰。 -
语义去污染:采用了 10-gram 匹配来识别并排除训练样本中与评估集潜在重叠的内容。使用较短的 n-gram 长度(n=10)可以增加匹配的敏感度,从而更精确地捕捉局部语义上的相似性。
作者特别提到,他们的模型构建于 Qwen2.5-Math-1.5B 这个基础模型之上(发布于2024年9月)。尽管基础模型可能存在一些数据污染的争议,但 VibeThinker-1.5B 在多个 2025 年才发布的基准(如 AIME25 和 HMMT25)上表现出色,这在时间线上排除了这些新基准被包含在基础模型训练数据中的可能性。这有力地说明了 VibeThinker-1.5B 的性能提升来自于其后训练方法,而非数据污染。
此外,基础模型本身在 LiveCodeBench v5 和 v6 上的得分为 0.0,而 VibeThinker-1.5B 通过后训练分别提升至 55.9 和 51.1,也进一步佐证了后训练方法的有效性。
3.2 训练成本
VibeThinker-1.5B 的一个突出特点是其极低的后训练成本。由于模型架构紧凑(1.5B 参数),整个 SFT 和 RLVR 阶段在 NVIDIA H800 GPU 上总共消耗了约 3900 个 GPU 小时。按照 H800 每小时 2 美元的市价计算,总计算成本不到 8000 美元。
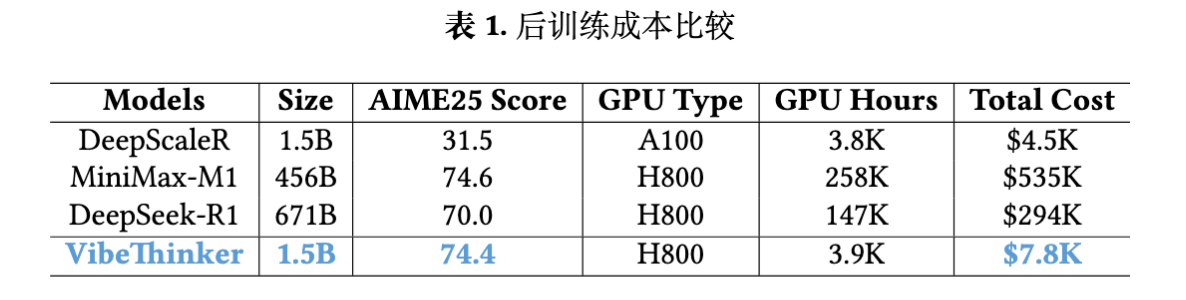
从上表中可以看到,VibeThinker-1.5B 在 AIME25 上取得了 74.4 的分数,超过了 DeepSeek-R1 的 70.0,与 MiniMax-M1 的 74.6 相当。然而,其训练成本(294K)和 MiniMax-M1($535K)相比,低了 1 到 2 个数量级。这种成本效益的突破,展示了在不依赖大规模参数扩展的前提下,通过算法创新提升模型能力的巨大潜力。
4. 实验评估与结果分析
4.1 评估基准与设置
为了全面评估 VibeThinker-1.5B 的推理能力,实验覆盖了数学、代码和知识三个关键领域。
-
数学:使用了 MATH-500、HMMT 2025、AIME 2024 和 AIME 2025 等一系列高难度数学竞赛基准。 -
代码:使用了 LiveCodeBench V5 和 V6 来评估通用编程能力。 -
知识:使用了 GPQA-Diamond,一个包含了生物、物理、化学等领域的博士级别问题的基准,来衡量模型在专业领域的知识和复杂推理能力。
评估时,数学推理采用 64 次采样计算 Pass@1,代码生成采用 8 次采样,领域知识问答采用 16 次采样。
4.2 与小型推理模型的比较
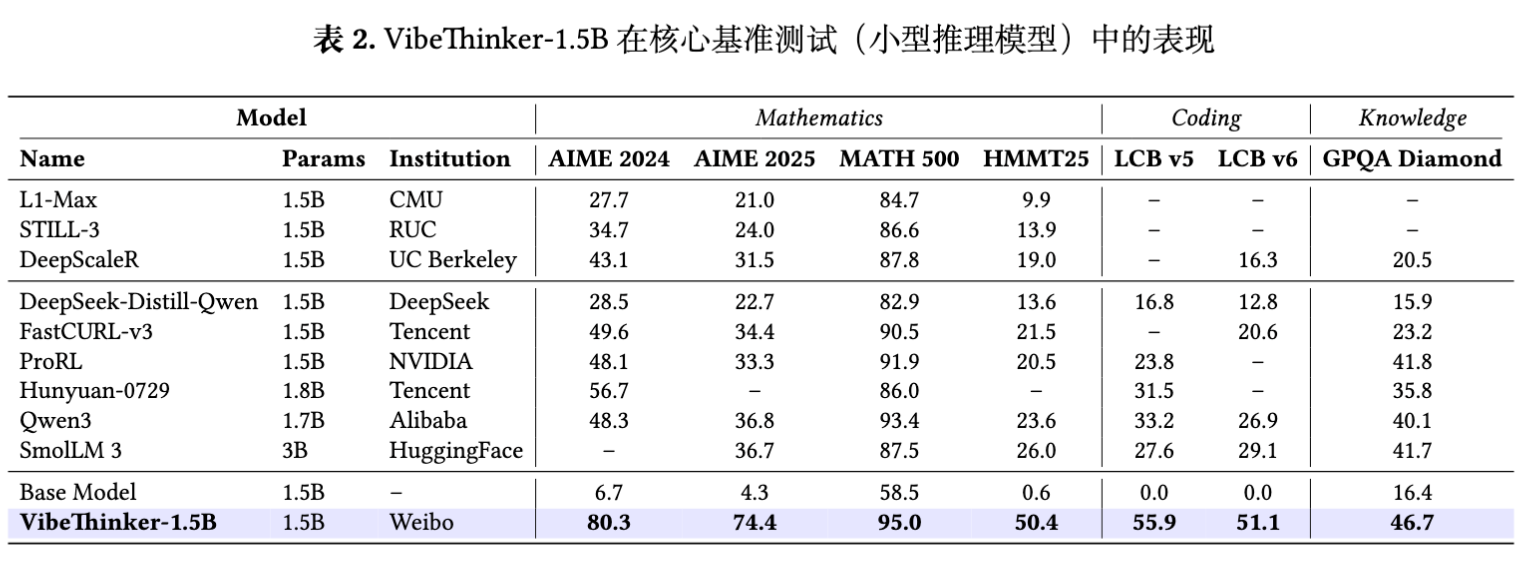
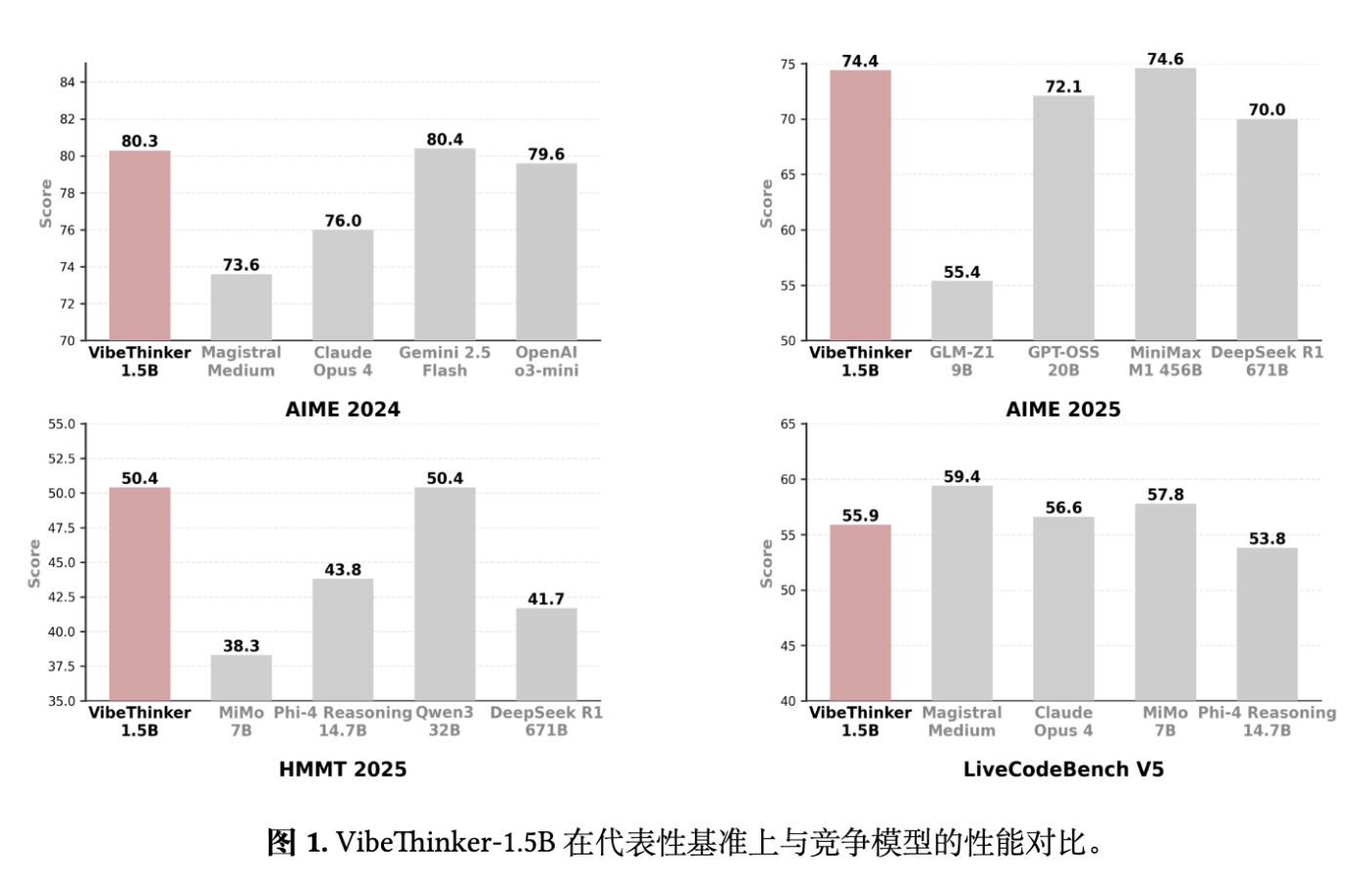
首先,在与同等规模(3B以下)的开源推理模型的比较中,VibeThinker-1.5B 表现出全面的性能优势。从表中数据可以看出,无论是与学术界(如 CMU, RUC, UC Berkeley)还是工业界(如 Tencent, NVIDIA, Alibaba)发布的小型模型相比,VibeThinker-1.5B 在所有数学、代码和知识基准上都取得了更高的分数。
特别值得注意的是,相较于其基础模型 (Base Model, 即 Qwen2.5-Math-1.5B),VibeThinker-1.5B 的性能提升是巨大的。例如,在 AIME25 上的得分从 4.3 提升到 74.4,在 HMMT25 上从 0.6 提升到 50.4,在 LiveCodeBench V5 上从 0.0 提升到 55.9。
4.3 与大型推理模型的比较
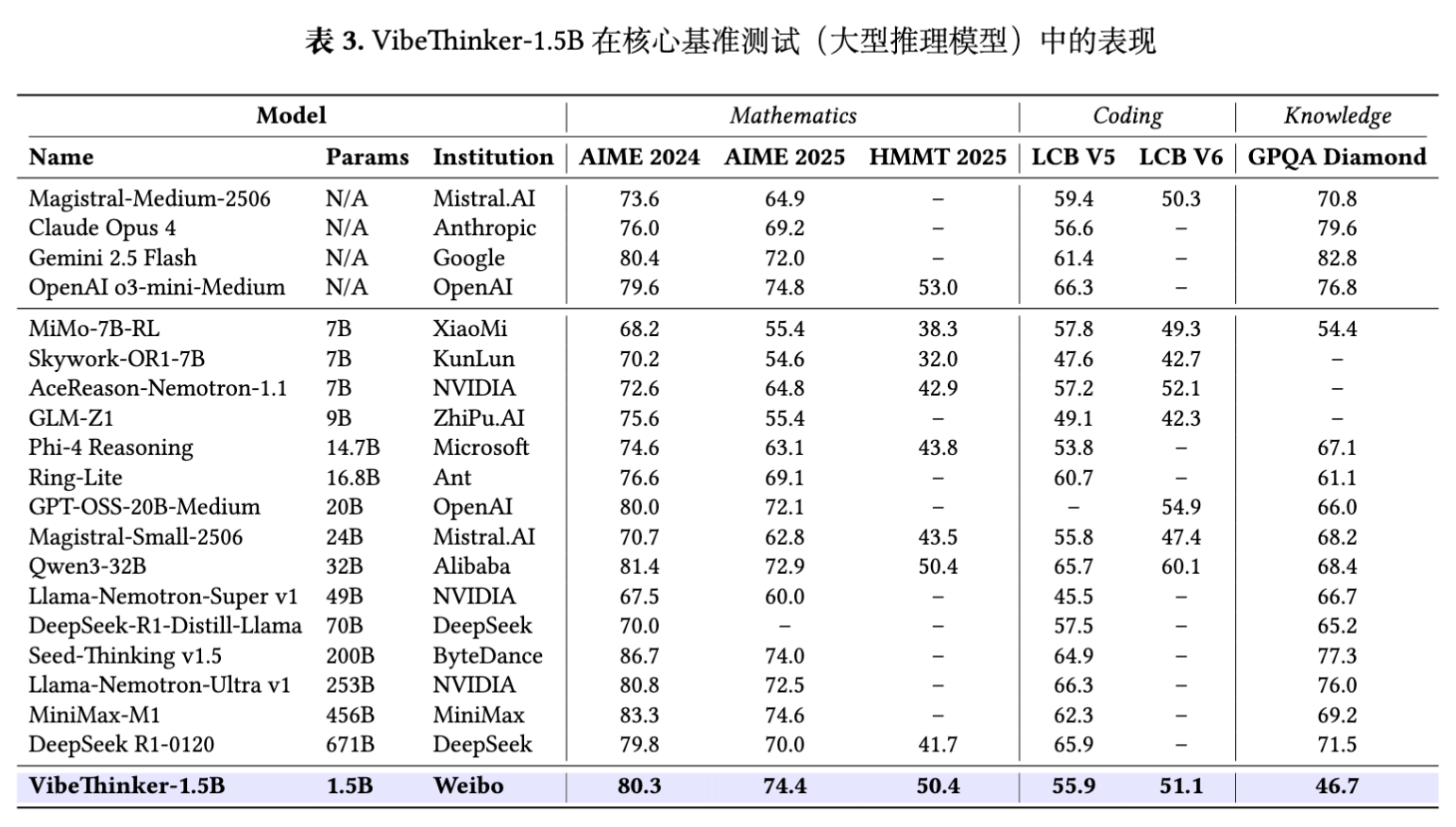
与大型推理模型的比较更能体现 VibeThinker-1.5B 的效率。尽管参数量存在 10 到数百倍的差距,VibeThinker-1.5B 在多个推理基准上依然展示了强大的竞争力。
-
与闭源模型对比:在 AIME24 和 AIME25 这两个数学基准上,VibeThinker-1.5B 的得分(80.3, 74.4)与 OpenAI o3-mini-Medium(79.6, 74.8)和 Gemini 2.5 Flash(80.4, 72.0)相当,并且超过了 Magistral Medium 和 Claude Opus 4。 -
与开源模型对比:VibeThinker-1.5B 在全部三个数学基准上都一致性地超越了 DeepSeek R1-0120 (671B)。其性能与 MiniMax-M1 (456B) 基本持平,并优于 MiMo 7B 和 Phi-4 Reasoning (14.7B) 等模型。
这些结果直接挑战了“推理性能主要由模型规模决定”的传统观念,表明一个经过精心设计的小规模模型,其推理能力可以达到甚至超过规模远大于自身的模型。
4.4 与顶级非推理模型的比较
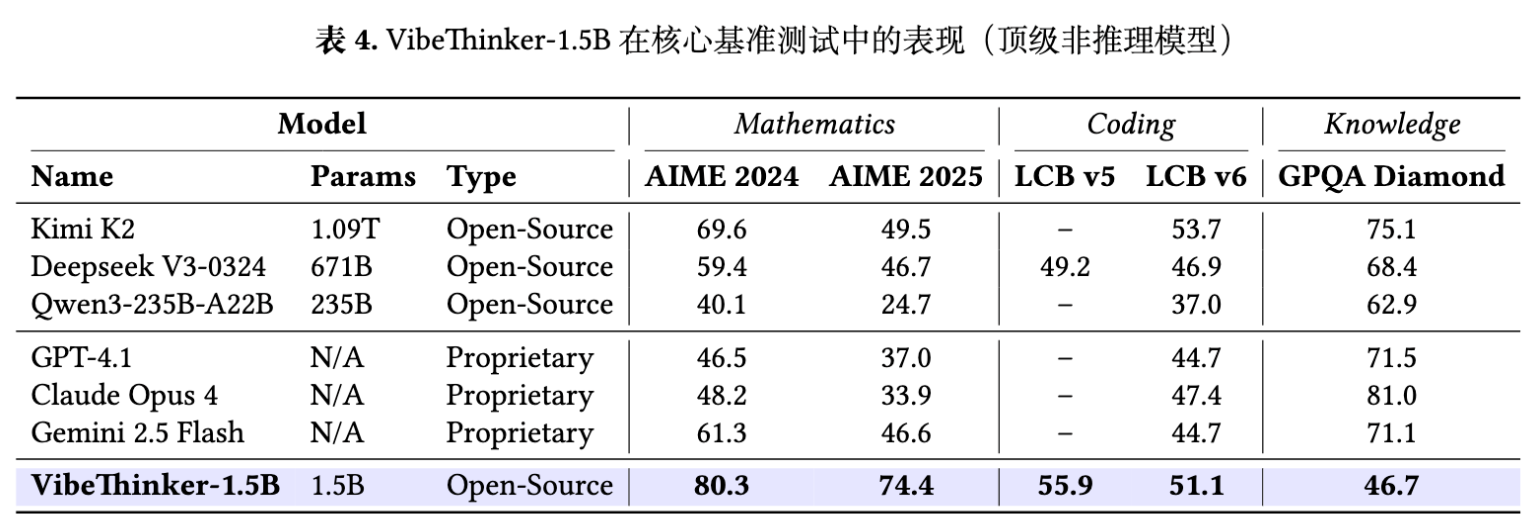
报告还将 VibeThinker-1.5B 与一些顶级的非推理模型进行了比较。这些模型(如 Kimi K2, Deepseek V3, GPT-4.1)虽然没有专门针对长链推理进行优化,但它们巨大的参数规模和海量的训练数据使其本身也具备了处理数学和代码任务的能力。
结果显示,尽管 VibeThinker-1.5B 的参数量只是这些模型的几百分之一甚至千分之一,它在所有数学基准上都显著优于这些顶级非推理模型。在代码生成任务上,其表现也超过了大部分对手。这进一步证明了小型模型在逻辑推理任务上的潜力,前提是采用正确的训练方法。
然而,在通识知识基准 GPQA 上,VibeThinker-1.5B 与这些大型模型之间存在 20-40 分的差距。这表明,虽然在逻辑推理上可以与大模型匹敌,但在需要广泛、百科全书式知识的存储和检索能力上,较小的参数规模可能确实构成了固有的限制。作者也坦诚了这一点,并呼吁研究社区关注提升小型模型的通用知识能力。
5. 讨论与个人看法
这篇报告展示了一个令人印象深刻的成果,即一个 1.5B 的小模型能够在高难度推理任务上比肩甚至超越百倍于其规模的大模型。其提出的 SSP 原理和 MGPO 框架为小型模型的优化提供了有价值的思路。然而,在肯定其贡献的同时,也有一些方面值得进一步审视和讨论。
5.1 关于数据去污染的思考
报告中提到,为了保证评估的可靠性,作者采用了 10-gram 匹配的方式进行数据去污染。这是一种基于字面文本重叠的去重方法。在实践中,这种方法对于移除完全相同或高度相似的文本片段是有效的。
然而,它的局限性也比较明显。它可能无法有效识别那些经过转述、句式变换或同义词替换但语义上完全一致的内容。例如,一个数学问题可以用多种不同的文字表述,但其核心的数学逻辑和解题步骤是相同的。基于 n-gram 的方法很可能无法捕获这种语义层面的重叠,从而可能存在信息泄露的风险。
在当前的研究中,更加严谨的去污染方法会结合使用基于 embedding 的语义去重技术。通过计算训练样本和测试样本在向量空间中的相似度,可以更鲁棒地识别出语义上相关的内容,即便它们的字面表达完全不同。报告中没有提及是否使用了这类方法,这使得其去污染的彻底性存在一定的不确定性。
5.2 关于合成数据与消融实验的缺失
报告中提到,训练数据中包含了一部分“专有合成数据”(proprietary synthetic data),但对其生成方法、数据规模、分布特征等没有做过多介绍。合成数据的质量和分布对模型性能有着直接且重要的影响。如果合成数据与评测基准在领域或问题类型上高度对齐,那么模型的出色表现可能部分归功于高质量、高相关性的训练数据,而不仅仅是算法的功劳。
这就引出了另一个关键问题:报告中没有提供消融实验。一个完整的技术报告,通常需要通过消融实验来验证其提出的各个模块的有效性。例如:
-
SSP 原理的有效性:可以通过对比实验来验证,一组使用传统的以 Pass@1 为目标的 SFT,另一组使用论文中提出的以 Pass@K 为目标的 SFT,后续都接上相同的 RL 阶段。通过比较最终性能,可以判断 SSP 中的“光谱”阶段是否真的带来了收益。 -
MGPO 的有效性:可以设计一组实验,在相同的 SFT 模型基础上,分别使用标准的 GRPO 和论文提出的 MGPO 进行 RL 训练。比较两者性能差异,可以判断 MGPO 的动态加权机制是否比标准 RL 算法更有效。 -
专家模型融合的有效性:可以比较融合后的 SFT 模型与单个最优的专家模型(例如在 AIME 综合得分最高的那个)的性能,来判断模型融合这一步骤是否带来了泛化能力的提升。
由于缺少这些消融实验,我们很难清晰地将 VibeThinker-1.5B 的性能提升归因于哪一个具体部分。究竟是 SSP 原理、MGPO 算法,还是未详细说明的合成数据,抑或是它们之间的某种组合效应,起到了决定性作用?这种归因上的模糊性,使得其他研究者在借鉴或复现这项工作时,难以判断哪些是关键组件,哪些是可选项。
总结来说,方法(SSP, MGPO)的创新和数据(特别是高质量的合成数据)的有效性,在这项工作中是耦合在一起的。如果没有消融实验来解耦这两者的贡献,就无法完全确认其算法创新的普适性和独立有效性。
6. 总结
《Tiny Model, Big Logic》这篇技术报告为小型语言模型的发展提供了一个有力的案例。它通过 VibeThinker-1.5B 的实践表明,逻辑推理能力并非大模型的专属,通过创新的后训练方法,小型模型同样可以在这一领域取得突破。
报告的核心贡献在于提出了“光谱-信号原理”(SSP),主张在后训练中将 SFT 用于生成多样性,RL 用于放大准确性,以及最大熵引导的策略优化(MGPO)框架,用于实现高效的课程学习。这些方法共同作用,使得一个 1.5B 的模型在多个高难度数学基准上超越了 671B 的对手,且训练成本极低。
尽管在数据去污染的彻底性和实验设计的完备性(如缺少消融研究)上存在一些可供探讨的空间,但该报告的方法也值得学习和参考。


