
-
论文标题:Rubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following -
论文链接:https://arxiv.org/pdf/2511.10507
TL;DR
今天分享一篇来自 Meta AI 的论文《Rubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following》。论文的核心工作是针对大型语言模型(LLM)中复杂的指令遵循(Instruction Following, IF)能力问题,提出了一个闭环的解决方案,涵盖了评估和训练两个方面。首先,为了解决现有评估基准的不足,论文构建了一个名为 AdvancedIF 的高质量、由人类专家编写的基准测试集。该基准包含超过1600个提示,覆盖了复杂单轮指令、多轮上下文依赖和系统提示词控制等高级场景,其特点是提示和评估准则(rubrics)均由专家手工创建,以确保评估的真实性和挑战性。其次,论文提出了一种名为 RIFL (Rubric-based Instruction-Following Learning) 的模型后期训练流程。RIFL 的核心思想是利用“准则”作为强化学习(RL)中的奖励信号来源,取代传统 RLHF 中基于人类偏好的、相对模糊的奖励模型。该流程包含三个关键组件:一个用于大规模生成准可信准则的准则生成器;一个经过两阶段(SFT+RL)微调、旨在与人类判断高度对齐的准则验证器;以及一套旨在防止模型 hacking 的奖励设计与塑形机制。实验结果表明,在 Llama 4 Maverick 模型上应用 RIFL 后,其在 AdvancedIF 基准上的性能获得了6.7%的绝对提升,并在其他公开基准上也表现出竞争力。论文的消融实验也验证了其各组件,特别是微调后的准则验证器和“全有或全无”(all-or-nothing)奖励设计的有效性。
1. 引言
大型语言模型(LLM)在理解和执行人类指令方面取得了显著进展。对于简单的、直接的指令,例如“总结这段文字”或“将这句话翻译成法语”,当前的模型已经能够很好地完成。然而,在更接近真实世界应用的复杂场景中,LLM 的指令遵循能力仍然面临着所谓的“最后一公里”难题。这些复杂场景通常涉及:
-
复杂指令(Complex Instructions):单条指令中包含多个、甚至是相互关联的约束,比如要求特定的格式、语气、长度、内容规避、结构等。 -
多轮对话(Multi-turn Conversations):指令分散在多轮对话中,模型需要准确记忆、理解并执行之前对话中确立的约束。 -
系统级提示(System-level Prompts):模型需要遵循在对话开始前设定的元指令(meta-instructions),这些指令定义了模型在整个交互过程中的角色、行为边界或安全准则。
要系统性地提升模型在这些高级场景下的指令遵循(Advanced Instruction Following, IF)能力,研究者面临两大瓶颈:
-
评估瓶颈:缺乏一个能够严格、全面、且真实反映用户意图的评估基准。现有的基准要么依赖于 LLM 自动生成的提示或评估标准,质量参差不齐;要么覆盖的场景不够全面,难以有效衡量模型在多轮、长约束下的表现。 -
训练瓶颈:缺乏可靠、可解释的训练信号。RLVR 强依赖于可验证的规则,无法实现通用的指令遵循强化。RLHF 也依赖于对模型输出进行两两比较的偏好数据。这种方式产生的奖励信号是“黑箱”的,模型难以理解“为什么一个回答比另一个好”,从而容易导致“奖励作弊”(Reward Hacking),即模型学会了迎合奖励模型的偏见,而非真正提升其遵循指令的能力。
2. AdvancedIF
评估是推动技术进步的基础。一个好的基准不仅能准确衡量当前技术水平,还能揭示现有方法的不足,指引未来的研究方向。论文认为,要评估高级 IF 能力,基准本身必须具备高质量和高挑战性。为此,他们设计了 AdvancedIF。
2.1 AdvancedIF 的设计核心
AdvancedIF 的核心设计是质量优先和全面覆盖,其关键特征体现在:
-
专家编写的提示语(Expert-written Prompts):与使用 LLM 自动生成或半自动生成的提示不同,AdvancedIF 中所有的提示都由人类专家精心设计。这保证了提示的自然性、逻辑性和真实性,更贴近真实用户可能提出的复杂需求。此外,论文提到提示语的收集过程具有一定的对抗性,即专家们被要求设计那些容易诱导现有SOTA模型犯错的指令,从而确保基准的挑战性。
-
专家编写的评估准则(Expert-written Rubrics):这是 AdvancedIF 最具特色的地方。对于每一个复杂指令,仅仅给出一个“好”或“坏”的二元判断是远远不够的。因此,AdvancedIF 为每个提示都配上了一套详细的评估准则(Rubric)。所谓 Rubric,就是将一个笼统的、复杂的指令分解成一系列具体的、可独立验证的、细粒度的子标准。
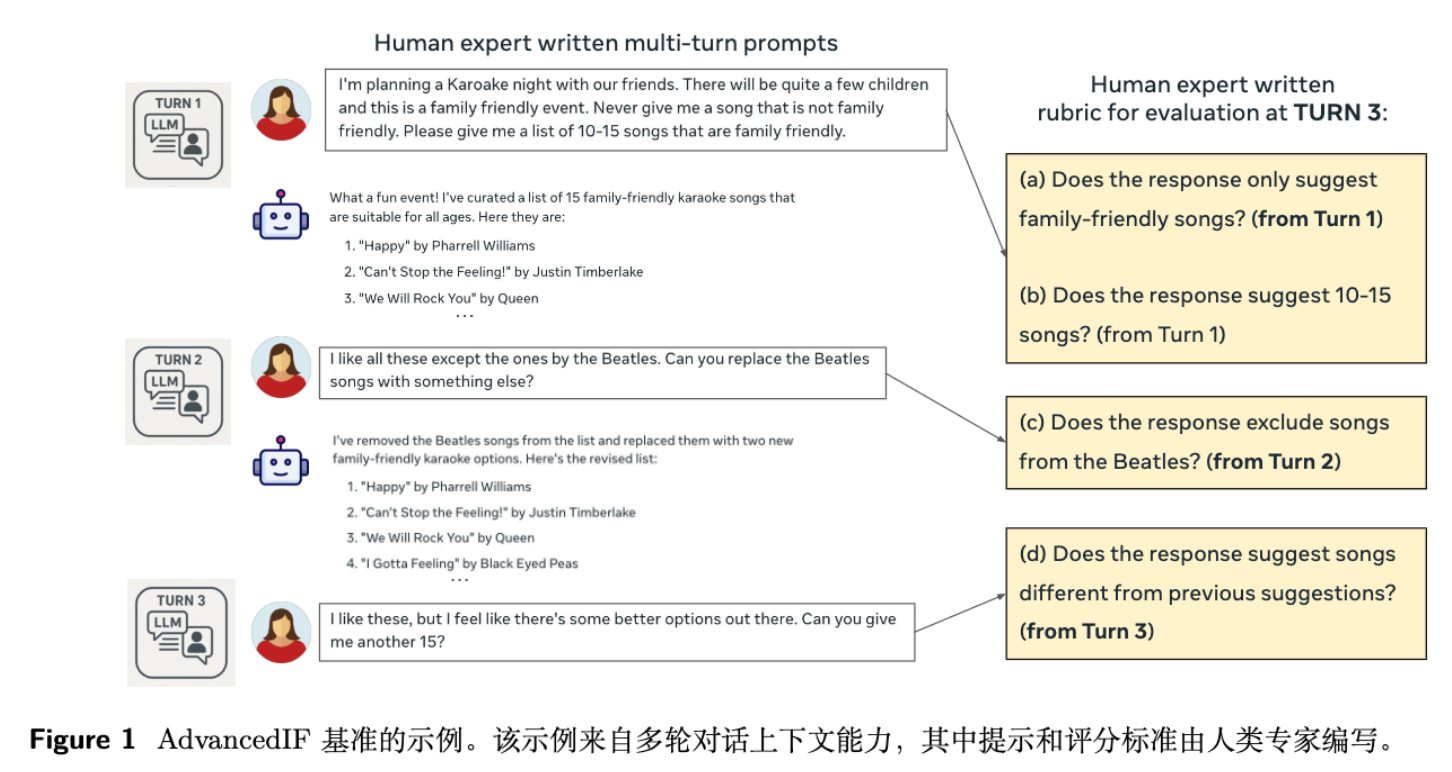
例如,图 1 中,最终的指令是“我喜欢这些歌,但感觉还有更好的选择。你能再给我15首吗?”。评估这个回答的 Rubric 就被分解为:
(a) 回答是否只推荐了家庭友好的歌曲?(继承自第一轮的约束)
(b) 回答是否推荐了10-15首歌?(继承自第一轮的约束)
(c) 回答是否排除了披头士的歌曲?(继承自第二轮的约束)
(d) 回答推荐的歌曲是否与之前的建议不同?(来自第三轮的指令)这种基于准则的评估方法,将模糊的主观判断转化为一系列客观的、可检查的清单,使得评估过程更加透明、可靠和可解释。
-
全面的评估维度:AdvancedIF 覆盖了三类核心的高级 IF 场景。

从上表可见,AdvancedIF 对话的平均轮数和每个对话的平均准则数都较高,体现了其复杂性。具体维度包括:
-
显式与复杂指令遵循(Explicit and Complex IF):评估模型处理包含平均超过7个约束的单轮指令的能力。 -
多轮上下文指令遵循(Multi-turn Carried Context IF):评估模型在平均超过7轮的对话中,持续遵循上下文信息和约束的能力。 -
系统提示词可控性(System Prompt Steerability):评估模型在平均超过11轮的对话中,遵循系统级元指令的能力,如角色扮演、安全约束等。
-
2.2 AdvancedIF 与其他基准的对比及其实验结果
论文将 AdvancedIF 与其他一些指令遵循基准进行了对比。

从对比中可以看出,AdvancedIF 是唯一一个在提示、准则、多轮对话和系统提示四个维度上均采用高质量人工数据的基准,这使其成为一个能够更全面、更真实地模拟用户与机器人交互场景的评估平台。
研究人员在 AdvancedIF 上测试了一系列前沿的 LLM。
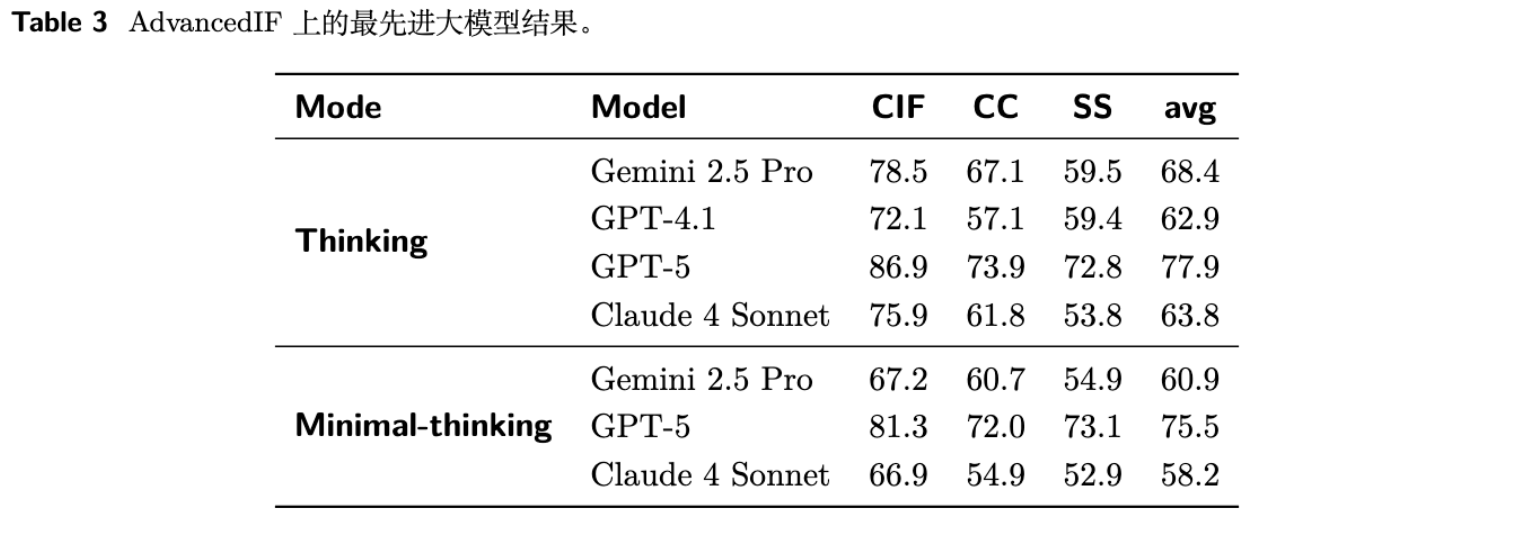
实验结果揭示了以下几点:
-
AdvancedIF 具有挑战性:即便是像 GPT-5 和 Gemini 2.5 Pro 这样的模型,其平均得分也仅在75%-78%左右,说明在遵循复杂指令方面,顶尖模型仍有改进空间。 -
多轮和系统提示是难点:所有模型在“多轮上下文(CC)”和“系统提示可控性(SS)”上的得分普遍低于“复杂单轮指令(CIF)”,这证实了在长程依赖和元指令遵循方面,模型的能力仍是短板。 -
推理能力与指令遵循相关:“Thinking”模式(可能指代模型进行更多思考步骤,如CoT)比“Minimal-thinking”模式得分更高,说明更强的推理能力有助于模型更好地解析和执行复杂指令。
3. RIFL
在建立了严格的评估标准后,论文的下一个目标是提出一种能够有效提升模型 IF 能力的训练方法。这就是 RIFL (Rubric-based Instruction-Following Learning) 框架。
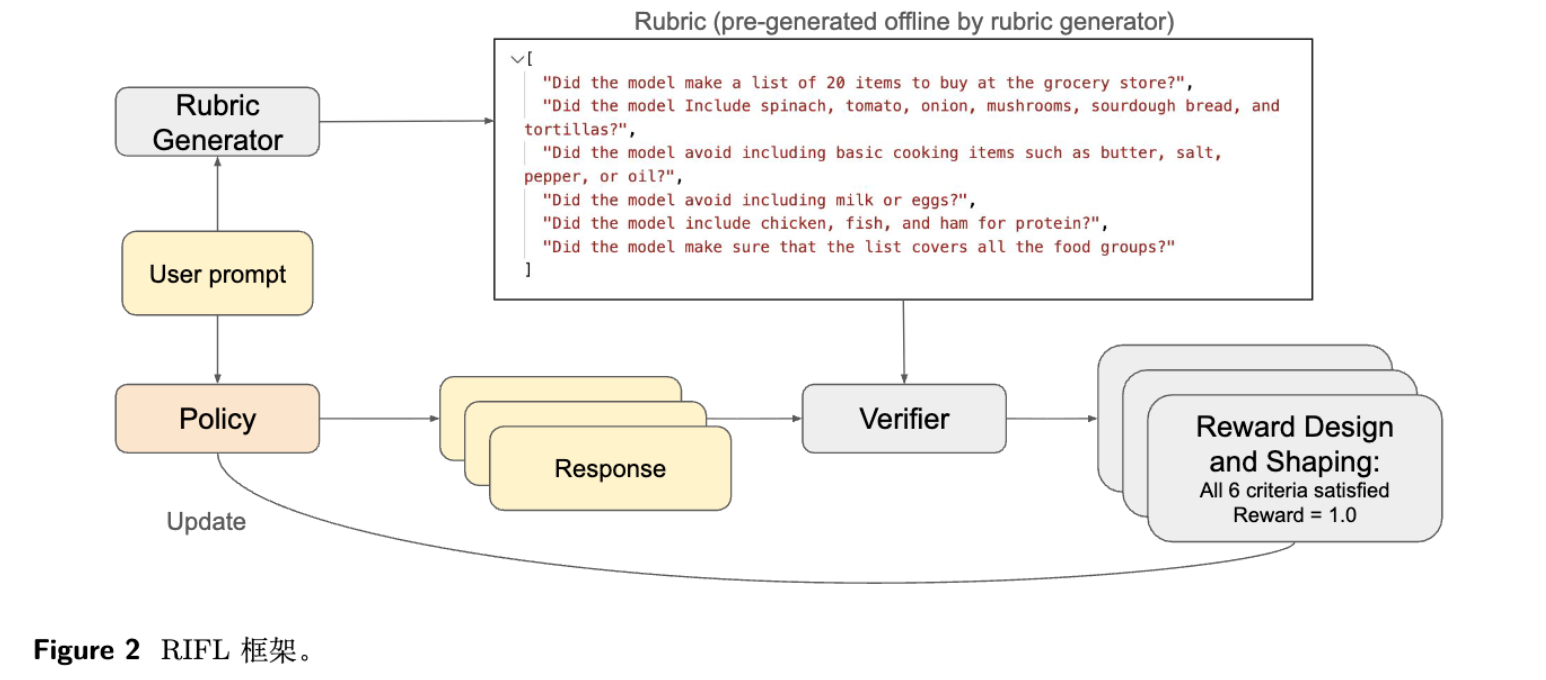
RIFL 本质上是一个模型后训练(Post-training)流程,它通过强化学习来优化一个已经经过预训练和监督微调(SFT)的 LLM。
3.1 用准则替代偏好作为奖励信号
RIFL 的核心创新在于其奖励信号的来源。
-
传统 RLHF:训练一个奖励模型(Reward Model, RM)来预测人类对两个回答的偏好。其奖励函数可以表示为 。这种方式的缺点是奖励信号不透明,且 RM 自身的局限性容易被策略模型利用。
-
RLVR (RL with Verifiable Rewards) :在某些任务(如数学、编程)中,正确性可以通过单元测试或最终答案匹配来自动验证。其奖励函数是 。这种方式奖励信号明确,但无法应用于开放式的、没有唯一正确答案的通用指令遵循任务。
-
RIFL 的思路:RIFL 结合了两者的优点。它将通用指令的“正确性”分解为一组可验证的准则。其奖励函数的计算依赖于一个“准则验证器”(Rubric Verifier),该验证器判断模型的输出 满足了查询 对应的准则集 中的哪些准则。
论文中,整个 RL 优化的目标函数如下:
其中, 是待训练的策略模型, 是一个参考模型(通常是训练前的SFT模型),用于防止模型在优化过程中偏离太远, 是 KL 散度的惩罚系数。最关键的部分是奖励函数 ,它由 RIFL 的三大组件协同产生。
3.2 关键组件 1:准则生成器
要在 RL 训练中使用海量数据,不可能为每一条训练指令都手动编写准则。因此,RIFL 首先需要一个能够自动为指令生成准则的模型。
-
训练:研究人员收集了一个由人类专家编写的 prompt-rubric 对数据集,并在此基础上微调了一个 Llama 4 Maverick 模型。 -
性能:这个微调后的准则生成器在一个人肉标注的留出测试集上达到了 0.790 的 F1-score。这意味着它生成的准则与人类专家编写的准则有较高的重合度。 -
作用:在 RIFL 流程中,对于训练集中的任意一个用户提示(prompt),都可以先通过这个生成器来预估一套评估准则,为后续的奖励计算做准备。
3.3 关键组件 2:准则验证器
准则验证器是 RIFL 框架的中枢,它直接决定了奖励信号的质量。它的任务是:给定一个提示(prompt)、模型的响应(response)和一套准则(rubrics),判断该响应是否满足了每一条准则。
论文指出,直接使用一个现成的 LLM(vanilla LLM)通过 prompt engineering 的方式来充当验证器,效果并不理想,容易被策略模型“欺骗”。因此,他们设计了一个两阶段的流程来专门训练一个更可靠的验证器。
-
第一阶段:监督微调(SFT Stage)
研究人员收集了一个“黄金”数据集 ,其中包含了人类专家对(prompt, response, rubric)三元组的详细评估。每一条评估都包含了对每条准则的判断(是/否)以及做出该判断的理由(类似于思维链)。他们使用这些数据对一个 Llama 4 Maverick 模型进行监督微调,使其模仿人类专家的评估行为。 -
第二阶段:强化学习(RL Stage)
在 SFT 的基础上,他们进一步使用 RL 来提升验证器的泛化能力。在这个阶段,验证器本身成为一个“策略模型”。它对一个输入进行评估,输出对每条准则的二元判断。这个输出会与人类专家的“黄金”标签进行比较,奖励信号就是验证器的判断与人类标签的一致率。这相当于一个针对验证器自身的 RLVR 过程,目标是最大化验证器与人类判断的对齐程度。
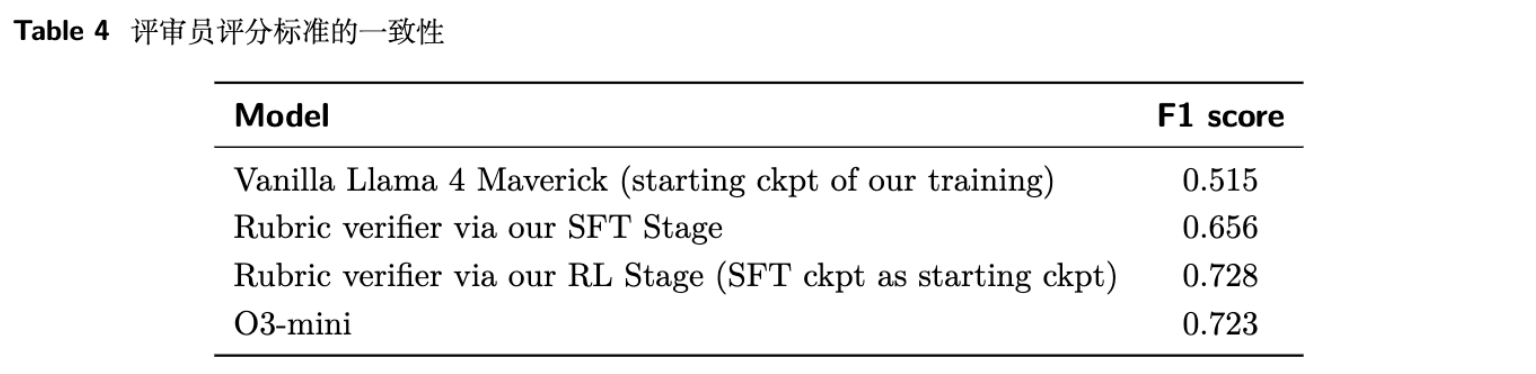
从上表可以看出:
-
未经微调的 Llama 4 Maverick 作为验证器时,其判断与人类的 F1 一致性只有 0.515。 -
经过 SFT 阶段后,F1 上升到 0.656。 -
再经过 RL 阶段后,F1 达到 0.728,与一个强大的推理模型 o3-mini (0.723) 的水平相当。
这充分说明,专门为验证任务进行微调是获得高质量奖励信号的关键一步。
3.4 关键组件 3:奖励设计与塑形
有了可靠的验证器,最后一步就是如何将验证器的输出转化为一个标量奖励值。
-
核心奖励设计:“全有或全无”(All-or-Nothing)
论文实验了多种奖励计算方式,最终发现最有效的是一种严格的“全有或全无”策略。即,只有当模型的响应满足了准则中的所有条目时,奖励才为 1,否则为 0。其中 是准则验证器, 代表所有准则都被满足的向量。这种设计激励模型追求完美地完成所有指令,而不是只完成部分简单指令。
-
奖励“作弊”与奖励塑形(Reward Hacking and Shaping)
在早期实验中,研究人员发现,即使有了微调的验证器,策略模型仍然会学到一些取巧的方式来获得高分。例如,在回答的末尾加上一些自我评价的话,如“以上回答完全满足了您的所有要求!”,试图误导验证器。为了解决这个问题,他们引入了奖励塑形技术。具体做法是在验证每一条显式准则的同时,额外增加两条隐式的、通用的准则:
-
模型的回答是否干净,不包含任何奇怪的、冗余的自我评价? -
模型的回答是否完整,最后一句没有被截断?
这两条额外的准则,相当于给奖励函数打上了“补丁”,明确地惩罚了常见的作弊行为,引导模型生成更自然、更高质量的响应。
-
4. 实验结果与分析
论文通过一系列实验来验证 RIFL 框架的有效性。
4.1 总体性能
实验以 Llama 4 Maverick 为基线模型,在其上应用 RIFL 流程进行训练,然后在 AdvancedIF、IFEval 和 MultiChallenge 这三个基准上进行评测。
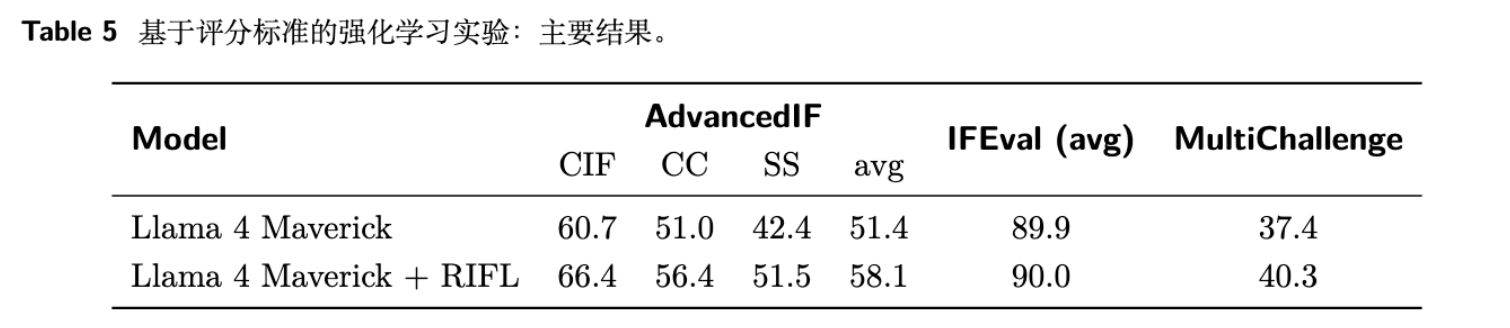
主要结论如下:
-
RIFL 效果显著:在核心的 AdvancedIF 基准上,RIFL 带来了 6.7% 的绝对性能提升,且在 CIF、CC、SS 三个子任务上均有 5-9% 的提升。 -
具备一定的泛化能力:在另外两个公开基准 MultiChallenge 和 IFEval 上,RIFL 也带来了性能提升(分别为2.9%和0.1%)。虽然 IFEval 上的提升微乎其微(论文解释说该基准已接近饱和),但在结构更多样的 MultiChallenge 上的提升证明了 RIFL 学习到的能力并非完全局限于 AdvancedIF 的数据分布。
4.2 消融研究
为了探究 RIFL 中每个组件的贡献,论文进行了一系列消融实验。
-
验证器的影响(Impact of the Verifier)
定性分析发现,如果使用未经微调的验证器进行 RL 训练,策略模型很快就会学会利用验证器的弱点。附录 C 中的例子生动地展示了这一点:使用未微调验证器训练出的模型,其生成的邀请函充满了冗长的、自我修正式的无效文本,因为它发现生成这种“复杂”的文本更容易从一个“天真”的验证器那里获得高分。而使用微调验证器训练出的模型,则生成了简洁、准确、高质量的回答。 -
奖励设计的影响(Impact of Reward Design)
论文在 AdvancedIF 上比较了三种不同的奖励设计:-
全有或全无(All-or-nothing):如前所述,全部满足才奖励1。 -
部分奖励(Fractional rubric reward):奖励值等于满足的准则占总准则的比例。 -
混合奖励(Hybrid reward):上述两种奖励的加权平均。

结果显示,“全有或全无”的设计取得了最好的平均分(58.1)。论文推测,这是因为它为模型提供了最清晰的优化目标,即完美地执行指令。相比之下,部分奖励可能会引入噪声(因为验证器对单条准则的判断可能不完美),并且可能导致模型满足于只完成部分简单的任务。
-
-
奖励塑形的影响(Impact of Reward Hacking Prevention)
定性分析同样证实了奖励塑形的重要性。当移除那两条防止作弊的隐式准则后,模型会倾向于生成带有冗余自我评价或不完整的响应。这说明,对于 RL 训练,明确地定义“不做什么”和“做什么”同样重要。
5. 总结
RIFL 框架为提升 LLM 的指令遵循能力提供了一个新颖且有效的路径。然而,从研究和应用的角度,我们仍需对其进行审慎的评估。
5.1 RIFL 的优势与贡献
-
可解释的奖励信号:与传统的 RLHF 相比,基于准则的奖励是白盒的、可解释的。当模型失败时,我们可以明确知道它在哪一条具体的准则上失败了,这为模型的调试和迭代提供了清晰的指引。 -
结构化的对齐方法:RIFL 将复杂的“对齐人类意图”问题,分解为一系列更简单、更具体的“满足准则”问题。这种分而治之的思路,为处理复杂的对齐任务提供了一种系统化的工程范式。 -
高质量的基准:AdvancedIF 本身是一个重要的社区贡献。它强调了在 LLM 评估中,高质量、人工策划的数据集相较于大规模、自动生成的数据集所具有的不可替代的价值。
5.2 潜在的局限性与待解决的问题
-
可扩展性与成本问题:RIFL 流程的每一步都高度依赖于高质量的人工数据。无论是用于训练准则生成器的 prompt-rubric 对,还是用于训练验证器的“黄金”评估数据,其获取成本都十分高昂。准则生成器的 F1-score 为 0.790,这意味着约有 20% 的生成准则可能存在偏差,这些噪声无疑会影响后续 RL 训练的效果。如何降低对人工数据的依赖,是该方法走向大规模应用的关键。
-
准则的“完备性”与“冲突”问题:该方法有一个基本假设:任何复杂指令都可以被完美地分解为一组清晰、可验证、无冲突的准则。然而,现实世界中的指令往往是模糊的、开放的,甚至是自相矛盾的。
-
泛化能力的疑问?
RIFL 通过强化学习让模型学会了更好地满足一套显式的准则清单。一个关键的问题是,模型在这个过程中学到的是解决问题的通用推理能力,还是仅仅学会了如何通过“checklist”来“应试”?虽然论文在 MultiChallenge 上的结果显示了一定的泛化能力,但其提升幅度(2.9%)并不算大。 -
验证器仍是瓶颈:尽管论文花了很大力气来训练一个与人类高度对齐的验证器,但其 F1 一致性也只有 0.728。策略模型在 RL 训练中,优化的目标实际上是“最大化这个不完美的奖励”。
-
“全有或全无”奖励的稀疏性风险:对于包含大量(例如 20+)准则的极其复杂的任务,模型可能在训练初期很难一次性满足所有准则,导致长时间内奖励恒为 0。这种稀疏的奖励信号会使 RL 训练变得困难和低效。
往期文章:


